eclipse开发scrapy爬虫工程,附爬虫临门级教程
写在前面
自学爬虫入门之后感觉应该将自己的学习过程整理一下,也为了留个纪念吧。
scrapy环境的配置还请自行百度,其实也不难(仅针对windows系统,centos配置了两天,直到现在都没整明白)
就是安装python之后下载pip,setup pip,然后用pip install下载就行了(pyspider也是这样配置的)。
附主要资料参考地址
scrapy教程地址 https://www.bilibili.com/video/av13663892?t=129&p=2
eclipse开发scrapy https://blog.csdn.net/ioiol/article/details/46745993
首先要确保主机配置了eclipse、python还有pip的环境
安装scrapy框架的方法
进入cmd界面
::pip更新命令
pip install --upgrade pip
::pip安装scrapy
pip intall scrapy
安装完成之后就可以使用了
cmd环境创建scrapy的demo程序
首先创建一个目录,位置随意,随后进入目录,输入scrapy查看命令使用方式

startproject创建工程命令。格式scrapy startproject 工程名称

genspider创建爬虫命令,一个工程可以有多个爬虫。格式 scrapy genspider 爬虫名(不能和工程重名)爬虫初始ip地址值
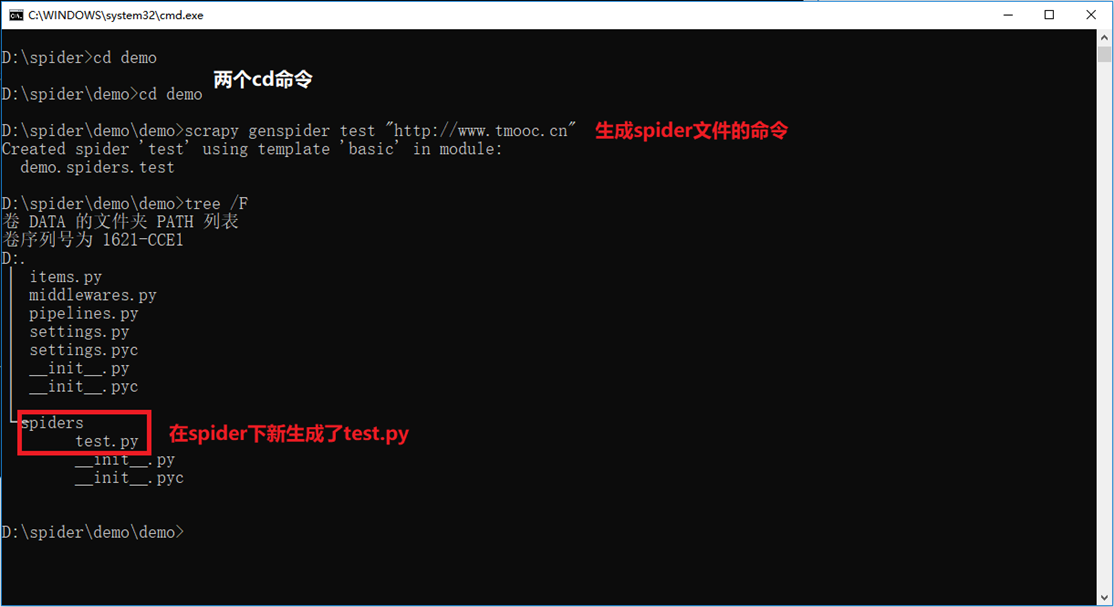
目标是获取tmooc首页的侧边栏的内容(sub的子元素a的子元素span的文本内容)
tmooc首页
侧边栏内容

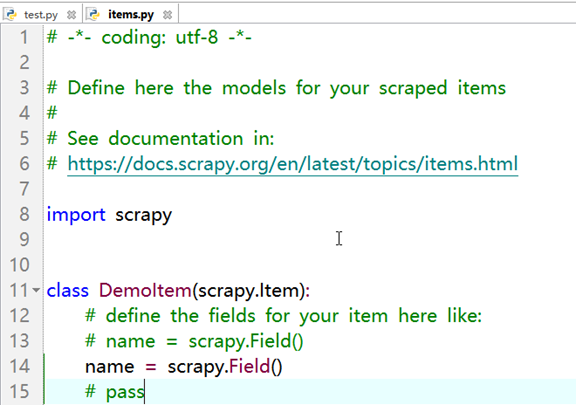
编辑item.py,位置在spider目录同级(代码简单,就不粘贴代码了)
编辑test.py
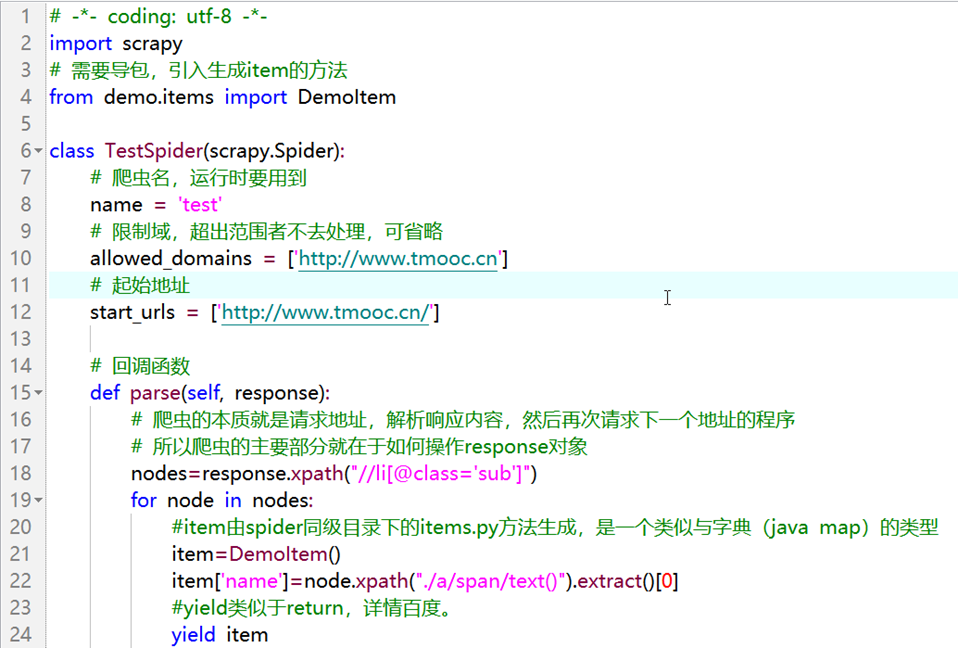
代码部分
# -*- coding: utf-8 -*-
import scrapy
# 需要导包,引入生成item的方法
from demo.items import DemoItem
class TestSpider(scrapy.Spider):
# 爬虫名,运行时要用到
name = 'test'
# 限制域,超出范围者不去处理,可省略
allowed_domains = ['http://www.tmooc.cn']
# 起始地址
start_urls = ['http://www.tmooc.cn/']
# 回调函数
def parse(self, response):
# 爬虫的本质就是请求地址,解析响应内容,然后再次请求下一个地址的程序
# 所以爬虫的主要部分就在于如何操作response对象
nodes=response.xpath("//li[@class='sub']")
for node in nodes:
#item由spider同级目录下的items.py方法生成,是一个类似与字典(java map)的类型
item=DemoItem()
item['name']=node.xpath("./a/span/text()").extract()[0]
#yield类似于return,详情百度。
yield item
编译test.py,运行spider程序

crawl是运行spider的命令。格式scrapy crawl 爬虫名 [-o 文件名]
-o参数可选,作用是将spider爬取的数据保存。保存在运行指令的目录下,可以保存成csv(excel表)json jsonl xml...等多种格式
结果展示

eclipse开发scrapyspider工程
首先要保证eclipse有python的开发环境
新建python工程,选项默认即可
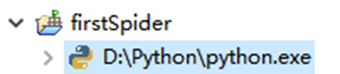
创建好的目录结构
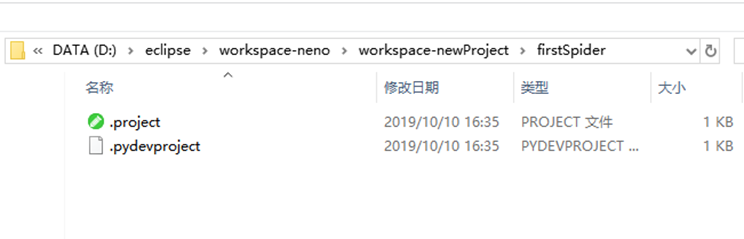
进入本地的workspace,找到该工程目录
将刚才创建的scrapy工程目录拷贝过来,不要一开始创建的那个文件夹
将demo目录

拷贝到
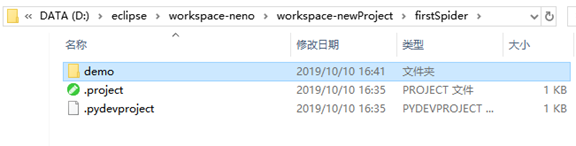
工程目录下。记得删除上次运行的结果文件

run -> run configuretion ->
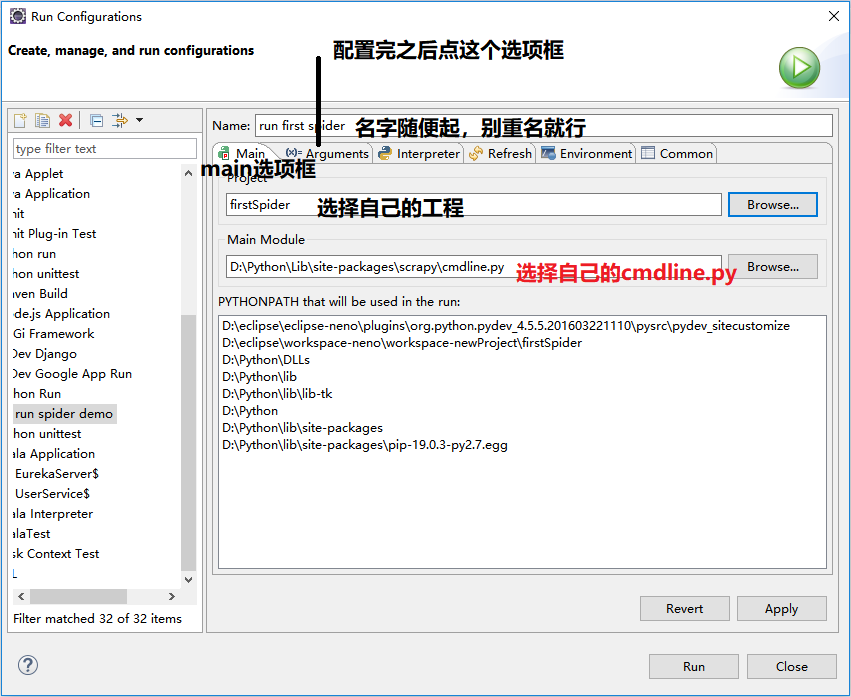

运行结果

eclipse开发scrapy爬虫工程,附爬虫临门级教程的更多相关文章
- eclipse开发工具Import工程后,工程文件夹上出现黄色感叹号——解决方法
eclipse开发工具Import工程后,工程文件夹上出现黄色感叹号. 可能是Work目录无效,解决方法:删除Work目录即可,如下图所示: 删除后,如下图:
- 如何设置eclipse开发的web工程自动发布到tomcat的webapps下?
使用eclipse开发web工程,在配置好服务器(tomcat)之后运行该web工程,发现能正常运行.但是问题在于,当你打开tomcat路径\webapps时,会发现没有该web应用(你的web工程名 ...
- eclipse开发Java web工程时,jsp第一行报错,如何解决?
与myeclipse不同,eclipse开发java web项目时是要下载第三方软件(服务器)的,正是这个原因,很多初学者用eclipse学习java web的时候,总是会遇到一些小问题.其中常见的一 ...
- scrapy工具创建爬虫工程
1.scrapy创建爬虫工程:scrapy startproject scrape_project_name >scrapy startproject books_scrapeNew Scrap ...
- 基于Python,scrapy,redis的分布式爬虫实现框架
原文 http://www.xgezhang.com/python_scrapy_redis_crawler.html 爬虫技术,无论是在学术领域,还是在工程领域,都扮演者非常重要的角色.相比于其他 ...
- scrapy进阶(CrawlSpider爬虫__爬取整站小说)
# -*- coding: utf-8 -*- import scrapy,re from scrapy.linkextractors import LinkExtractor from scrapy ...
- 『Scrapy』全流程爬虫demo
建立好的爬虫工程如下: item.py 它用来存储解析后的响应文件: # -*- coding: utf-8 -*- # Define here the models for your scraped ...
- Scrapy+redis实现分布式爬虫
概述 什么是分布式爬虫 需要搭建一个由n台电脑组成的机群,然后在每一台电脑中执行同一组程序,让其对同一网络资源进行联合且分布的数据爬取. 原生Scrapy无法实现分布式的原因 原生Scrapy中调度器 ...
- 基于Scrapy的B站爬虫
基于Scrapy的B站爬虫 最近又被叫去做爬虫了,不得不拾起两年前搞的东西. 说起来那时也是突发奇想,想到做一个B站的爬虫,然后用的都是最基本的Python的各种库. 不过确实,实现起来还是有点麻烦的 ...
随机推荐
- 【Leetcode_easy】686. Repeated String Match
problem 686. Repeated String Match solution1: 使用string类的find函数: class Solution { public: int repeate ...
- Linux - 对比net-tools与iproute2
简介 net-tools包含ifconfig.route.arp和netstat等命令行工具,用于管理和排查各种网络配置. 起源于BSD TCP/IP工具箱,旨在配置老式Linux内核的网络功能. 自 ...
- Java实现回形数,只利用数组、循环和if-else语句
import java.util.Scanner; public class learn { public static void main(String[] args){ System.out.pr ...
- 【VS开发】【数据库开发】libevent入门
花了两天的时间在libevent上,想总结下,就以写简单tutorial的方式吧,貌似没有一篇简单的说明,让人马上就能上手用的.首先给出官方文档吧: http://libevent.org ,首页有个 ...
- idea多级目录与单级目录切换
- 离线安装docker,并导入docker镜像
将docker离线安装包导入到系统中,解压并进入文件夹,使用下述命令进行安装: rpm -ivh *.rpm --nodeps --force 安装完成功使用,docker info 查看docker ...
- Eureka如何剔除已经宕机的节点
同一个服务部署了多个实例,在通过网关调用时会随机调用其中一个.但是,当某个服务挂掉之后,依然在注册中心中,依然会随机被调用到,调用时便会超时报错.(主要是开发测试或者演示时需要立即将失效的从注册中心剔 ...
- 1.1Spring Boot 环境配置和常用注解
Spring Boot常用注解:@Service: 注解在类上,表示这是一个业务层bean@Controller:注解在类上,表示这是一个控制层bean@Repository: 注解在类上,表示这是一 ...
- 去除element-ui table表格右侧滚动条的高度
/* //element-ui table的去除右侧滚动条的样式 */ ::-webkit-scrollbar { width: 1px; height: 1px; } /* // 滚动条的滑块 */ ...
- 导入别的项目到我的eclipse上出现红色感叹号问题
项目红色感叹号问题问题 一般我们在导入别的项目到我的eclipse上面会发现,项目上面有红色的错误 原因 因为我电脑上的 jdk版本和别人电脑jdk版本不一样,那么对于的jre版本也不 ...