Hadoop之HDFS介绍
1. 概述
- HDFS是一种分布式文件管理系统。
- HDFS的使用场景:
- 适合一次写入,多次读出的场景,且不支持文件的修改;
- 适合用来做数据分析,并不适合用来做网盘应用;
1.2 优缺点
- 优点:
- 高容错性
- 适合处理大数据
- 缺点:
- 不适合**低延时*数据访问;
- 无法高效的对大量小文件进行存储;
- 不支持并发写入,文件随机修改:
- 一个文件只能有一个写,不允许多个线程同时写;
- 仅支持数据append(追加),不支持文件的随机修改。
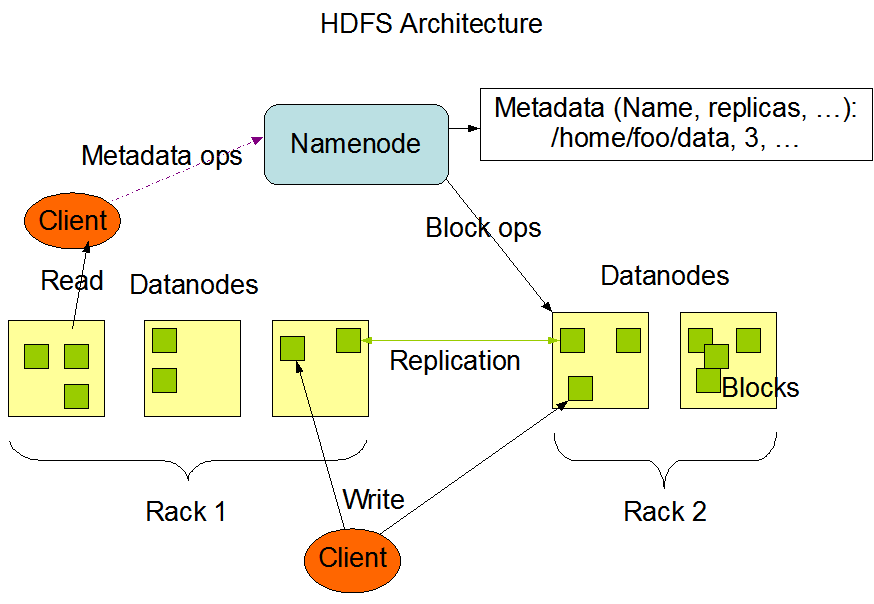
1.3 HDFS 组成架构
- NameNode(nn):
- 管理HDFS的名称空间;
- 配置副本策略;
- 管理数据块(Block)映射信息;
- 处理客户端读写请求;
- DataNode:NameNode下达命令,DataNode执行实际操作;
- 存储实际的数据块;
- 执行数据块的读/写操作;
- Client: 客户端
- 文件切分:文件上传到HDFS时,Client将文件切分成一个一个的Block,然后进行上传;
- 与NameNode交互,获取文件的位置信息;
- 与DataNode交互,读取或者写入数据;
- Client提供一些命令来管理HDFS,比如NameNode格式化;
- Client可以通过一些命令来访问HDFS,例如对HDFS进行增删改查操作;
- Secondary NameNode:并非NameNode的热备。当NameNode挂掉后,它并不能马上替换NameNode并提供服务;
- 辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode;
- 在紧急情况下,可辅助恢复NameNode;
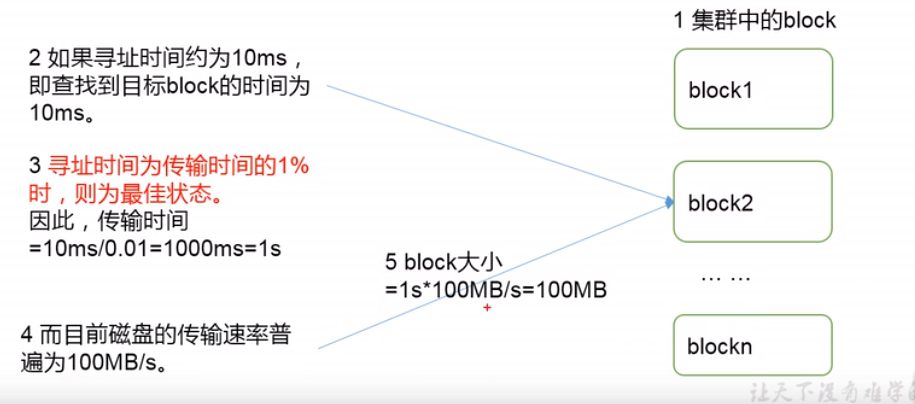
1.4 HDFS 文件块大小
- HDFS中的文件在物理上是分块存储(Block),块的大小可以通过配置参数(dfs.blocksize)来规定
- 默认大小在Hadoop2.x版本是128M,老版本是64M;
- HDFS块的大小设置主要取决于磁盘传输速率。
2. HDFS的 Shell 操作
2.1 基本语法
bin/hadoop fs 基本命令bin/hadoop fs -getmerge /测试目录/* ./本地目录指定文件名.txt: 合并下载多个文件bin/hadoop fs -du -s -h /测试目录: 统计当前文件夹总的大小;bin/hadoop fs -du -h /测试目录: 统计当前文件夹各项的大小;
bin/hdfs dfs 基本命令: “dfs”是“fs”的实现类。
参考资料:
Hadoop之HDFS介绍的更多相关文章
- hadoop(一HDFS)
hadoop(一HDFS) 介绍 狭义上来说: hadoop指的是以下的三大系统: HDFS :分布式文件系统(高吞吐,没有延时要求,容错性,扩展能力) MapReduce : 分布式计算系统 Yar ...
- Hadoop基础-Hdfs各个组件的运行原理介绍
Hadoop基础-Hdfs各个组件的运行原理介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode工作原理(默认端口号:50070) 1>.什么是NameN ...
- Hadoop介绍-3.HDFS介绍和YARN原理介绍
一. HDFS介绍: Hadoop2介绍 HDFS概述 HDFS读写流程 1. Hadoop2介绍 Hadoop是Apache软件基金会旗下的一个分布式系统基础架构.Hadoop2的框架最核心的 ...
- 介绍hadoop中的hadoop和hdfs命令
有些hive安装文档提到了hdfs dfs -mkdir ,也就是说hdfs也是可以用的,但在2.8.0中已经不那么处理了,之所以还可以使用,是为了向下兼容. 本文简要介绍一下有关的命令,以便对had ...
- Hadoop之HDFS文件操作常有两种方式(转载)
摘要:Hadoop之HDFS文件操作常有两种方式,命令行方式和JavaAPI方式.本文介绍如何利用这两种方式对HDFS文件进行操作. 关键词:HDFS文件 命令行 Java API HD ...
- Hadoop之HDFS原理及文件上传下载源码分析(下)
上篇Hadoop之HDFS原理及文件上传下载源码分析(上)楼主主要介绍了hdfs原理及FileSystem的初始化源码解析, Client如何与NameNode建立RPC通信.本篇将继续介绍hdfs文 ...
- Hadoop之HDFS及NameNode单点故障解决方案
Hadoop之HDFS 版权声明:本文为yunshuxueyuan原创文章.如需转载请标明出处: http://www.cnblogs.com/sxt-zkys/QQ技术交流群:299142667 H ...
- Hadoop基础-HDFS的读取与写入过程剖析
Hadoop基础-HDFS的读取与写入过程剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客会简要介绍hadoop的写入过程,并不会设计到源码,我会用图和文字来描述hdf ...
- Hadoop日记Day5---HDFS介绍
一.HDFS介绍 1.1 背景 随着数据量越来越大,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式 ...
随机推荐
- min-width
min-width 语法: min-width:<length> | <percentage> 默认值:0 适用于:除非置换内联元素,table-row, table-row- ...
- Archiva 不小心删掉了管理员权限怎么办
Archiva 的界面和 UI 比较容易出问题. 在添加用户和为用户进行权限修改的时候,不小心连 admin 这个用户的权限都删掉了. 这个时候应该如何恢复 admin 这个用户的权限? 这个时候你可 ...
- [Luogu] 贪婪大陆
https://www.luogu.org/problemnew/show/P2184 区间修改时只需修改区间端点的numl或numr值 区间查询x-y只需用1-y的numr - 1-(x - 1)的 ...
- 修改quartus 配置rom时memory很小的问题。
我用的是quartus ii 13版本的仿真软件,在做VGA实验时显示用到640*480的图片所以就需要307200*1bit的rom.但是坑爹的megawizard- plug-in-manager ...
- 查询Linux下文件格式.
备忘 file 命令可以查一个文件的格式 readelf -h 可执行文件名. 可以查询可执行文件的详细的格式 向Windows中exeinfo 软件类
- c#递归读取菜单树
1.查询菜单节点下所有子节点id List<sys_module> menus = new List<sys_module>() { }; public async Task& ...
- CF1200B
CF1200B 解法: 贪心.当在第i列时,尽可能多的取走第i列的木块使得袋子里的木块尽可能多 CODE: #include<iostream> #include<cstdio> ...
- Apache Flink - 分布式运行环境
1.任务和操作链 下面的数据流图有5个子任务执行,因此有五个并行线程. 2.Job Managers, Task Managers, Clients Job Managers:协调分布式运行,他们安排 ...
- Linux设备驱动程序 之 软中断
软中断保留给系统中对时间要求严格以及最重要的下半部使用:目前,只有两个子系统(网络和SCSI)直接使用软中断:此外,内核定时器和tasklet都是建立在软中断上的:在使用软中断之前,要先确定为什么不能 ...
- 深入探索REST(2):理解本真的REST架构风格
文章转载地址:https://www.infoq.cn/article/understanding-restful-style/,如引用请标注文章原地址 引子 在移动互联网.云计算迅猛发展的今天,作为 ...