webmagic爬取渲染网站
最近突然得知之后的工作有很多数据采集的任务,有朋友推荐webmagic这个项目,就上手玩了下。发现这个爬虫项目还是挺好用,爬取静态网站几乎不用自己写什么代码(当然是小型爬虫了~~|)。好了,废话少说,以此随笔记录一下渲染网页的爬取过程首先找到一个js渲染的网站,这里直接拿了学习文档里面给的一个网址,http://angularjs.cn/
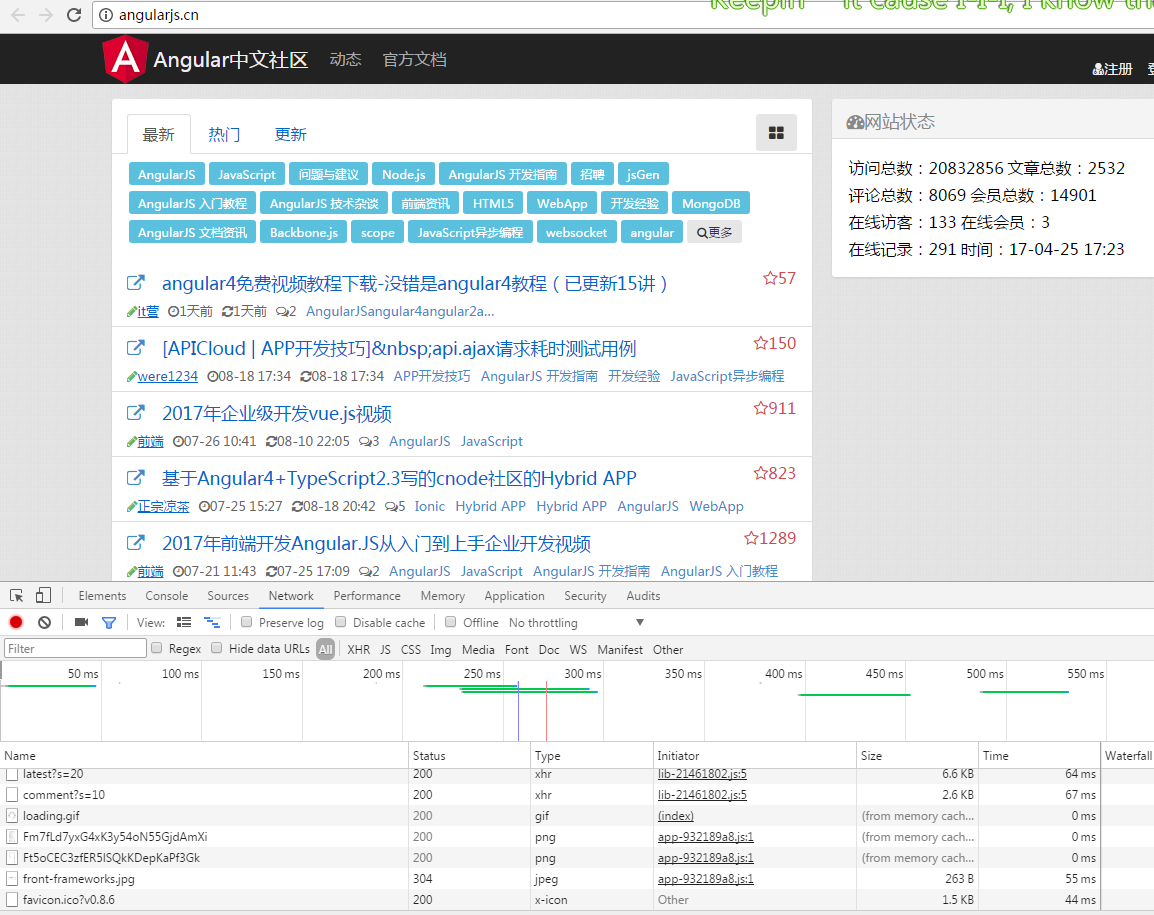
打开网页是这样的
查看源码是这样的
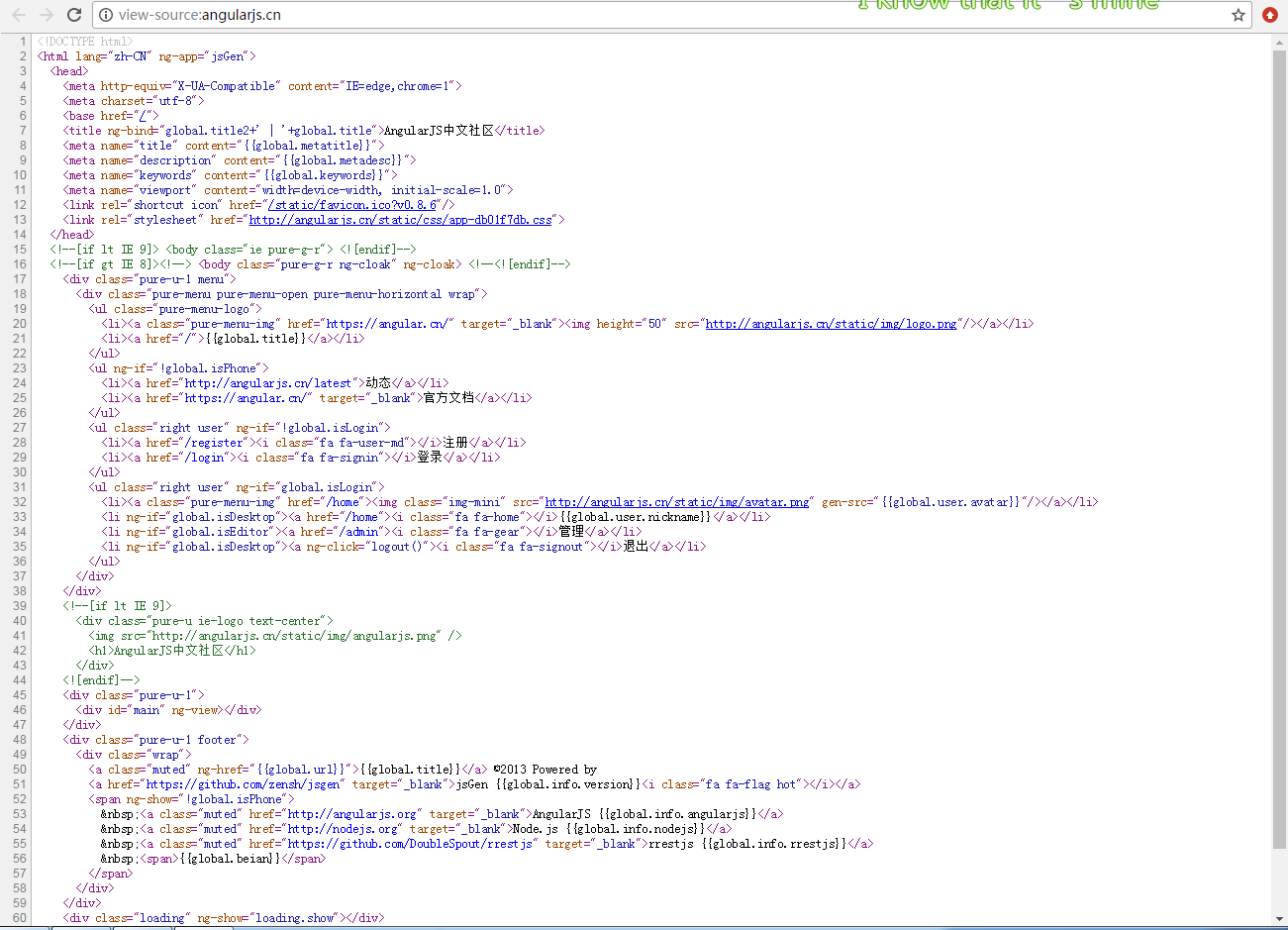
源码这么少,不用说肯定是渲染出来的了,随便搜了一条记录,果然源码里面找不到结果
那就开始解析网址了,从浏览器开发者工具里面发现了这么些请求记录
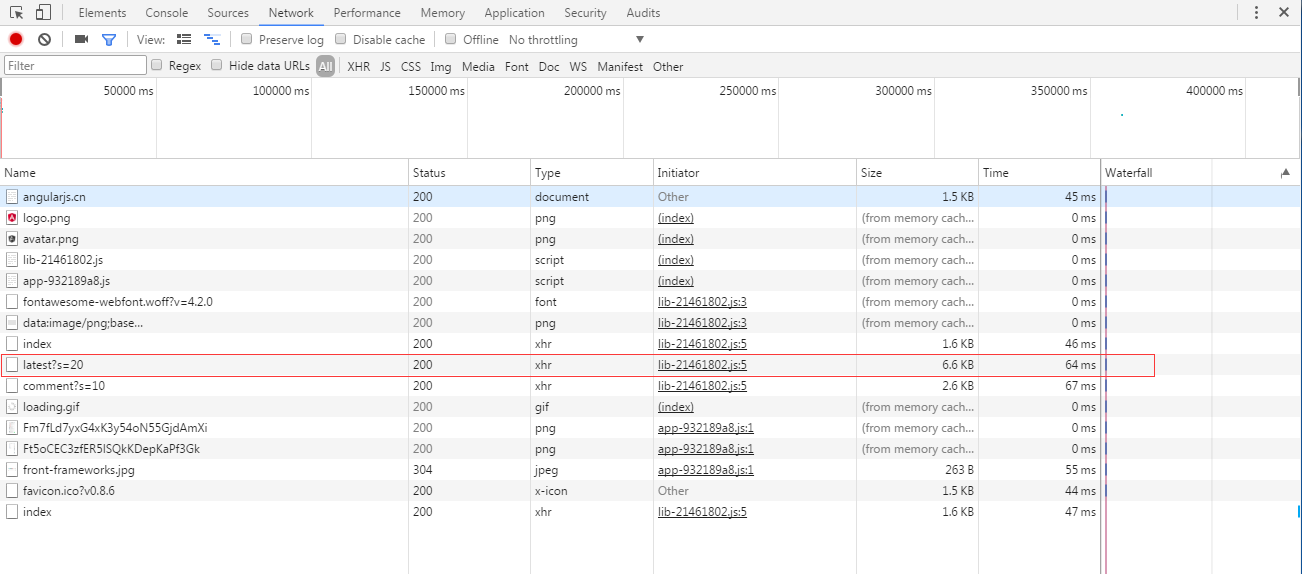
就直接从得到的数据量最大的请求开始查看,如上红线标记的。从xhr看出这是个ajax请求来的数据,打开请求的数据是这样的
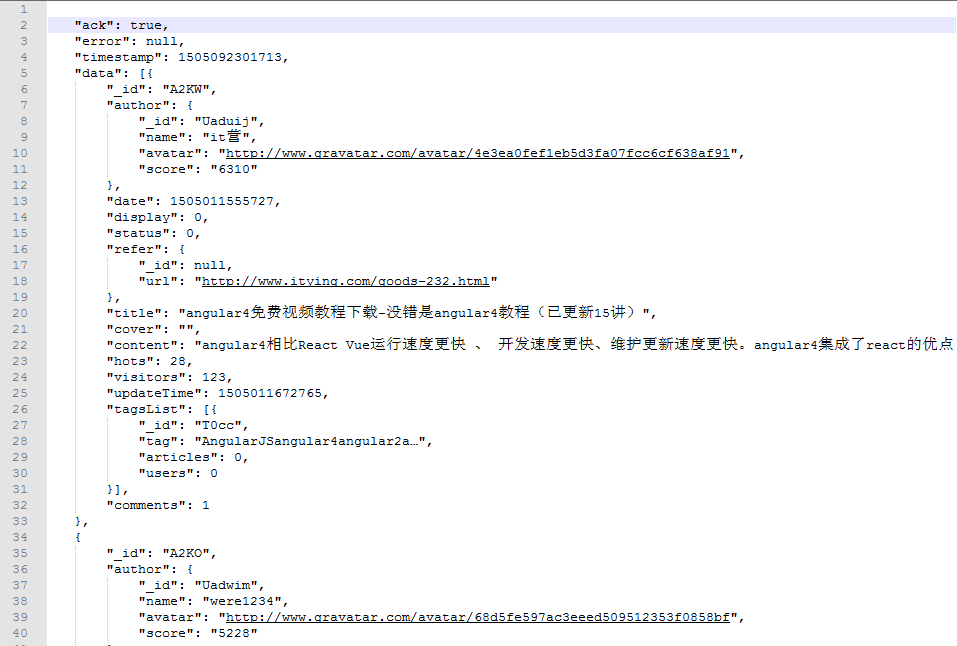
从网页上找一条源码里面找不到的记录,放在这个json数据里面搜索一下,运气还是不错的,搜索到了
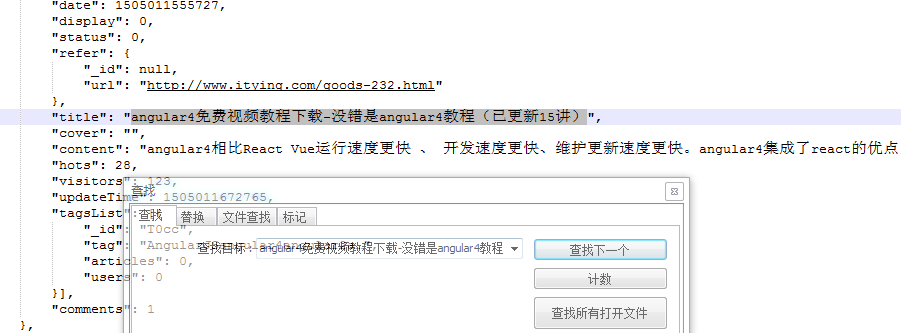
那不用说,就是它了!!接下来直接解析这个json就能拿到所有渲染后的链接了。
从网页直接点击一个链接进入,发现链接是这样的:
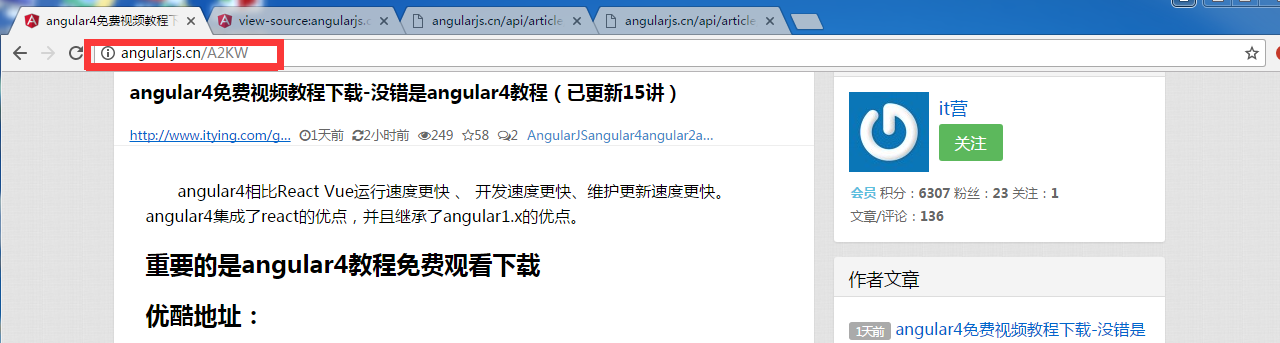
然后回到json文件,找到这个标题
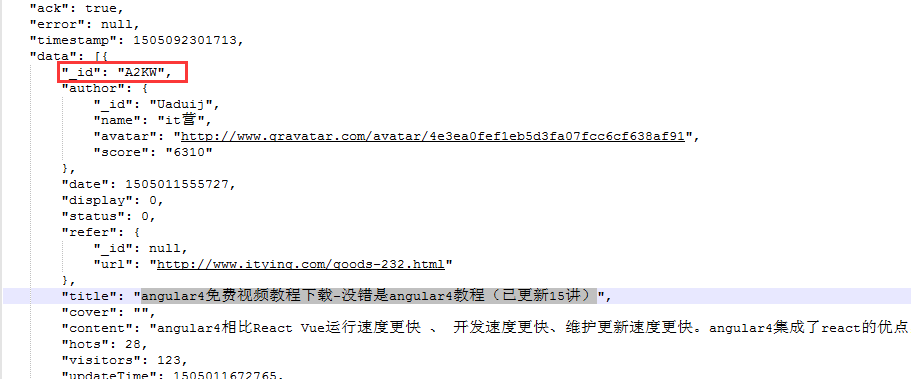
找到一个很了不起的东西!就是那个id,它就是链接后面带的。大胆推测,所有链接都是这个尿性!!(事实上我多点了几个链接看才敢确认这个尿性)
接下来就好办了,写代码解析这个json数据,然后拼凑出所有链接加入爬取队列爬取就行了。
结果发现通过首页链接点进去的下级链接,还是js渲染的。。。
没办法,拿着链接请求继续分析
得到这么些请求数据:
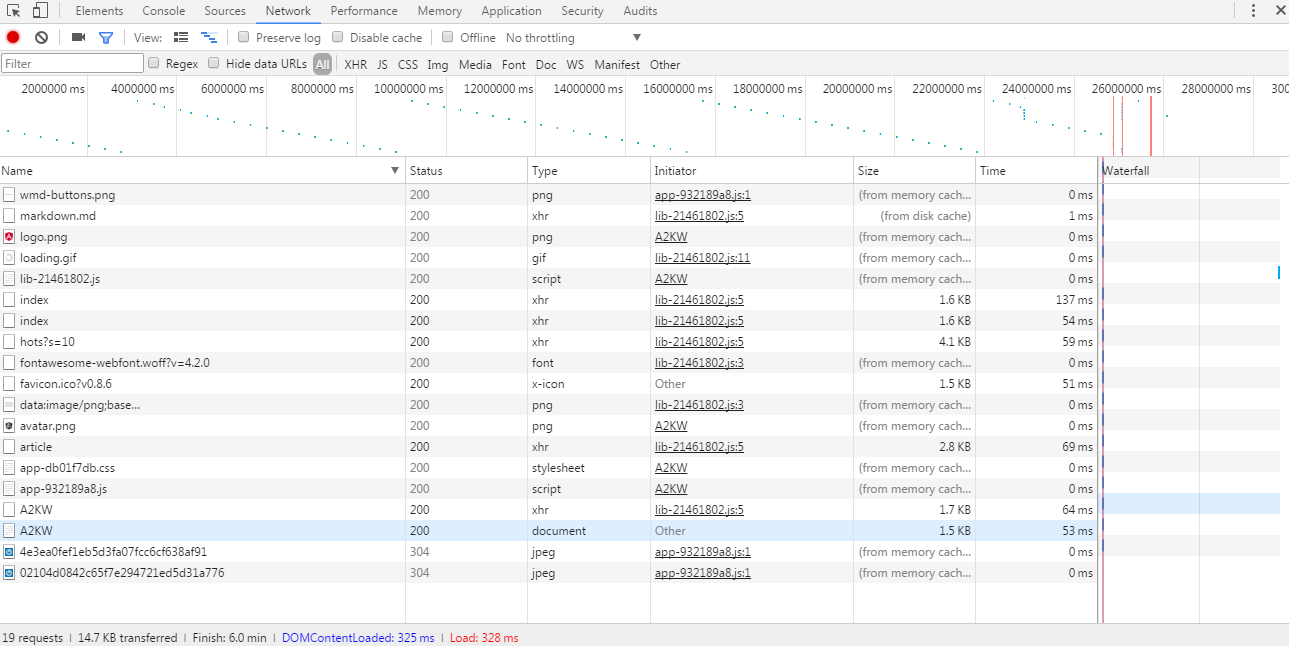
直接看到xhr栏,也就是ajax请求的数据
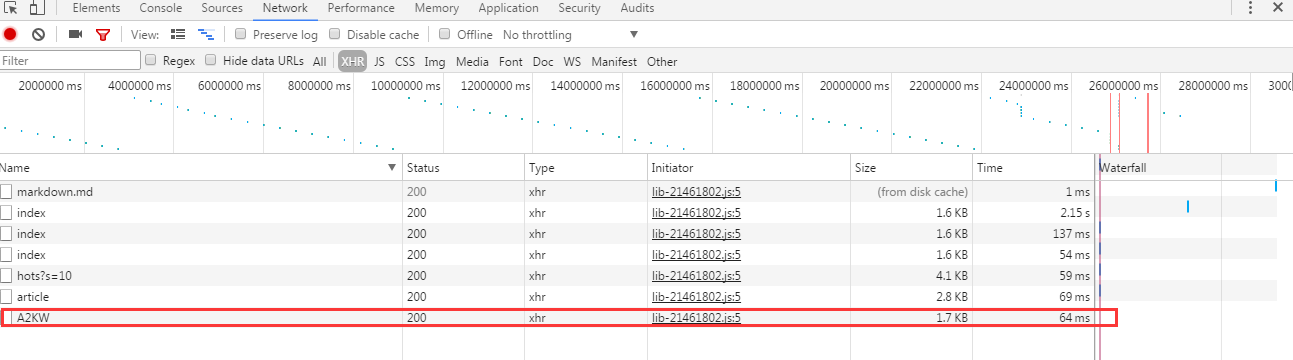
依旧从大到小查看json数据,和页面的内容匹配,直到第三个才找到正确的。++|
然后得到了最终数据的请求链接:http://angularjs.cn/api/article/A2KW
接下来就可以写代码了:
public class SpiderTest implements PageProcessor {
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
// 先从浏览器中分析出隐藏请求可得出以下匹配规则
private static final String URLRULE = "http://angularjs\\.cn/api/article/latest.*";
private static String firstUrl = "http://angularjs.cn/api/article/";
@Override
public Site getSite() {
// TODO Auto-generated method stub
return site;
}
@Override
public void process(Page page) {
// TODO Auto-generated method stub
/**
* 筛选出所有符合条件的url,手动添加到爬取队列。
*/
if (page.getUrl().regex(URLRULE).match()) {
//通过jsonpath得到json数据中的id内容,之后再拼凑待爬取链接
List<String> endUrls = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(endUrls)) {
for (String endUrl : endUrls) {
page.addTargetRequest(firstUrl + endUrl);
}
}
} else {
//通过jsonpath从爬取到的json数据中提取出id和content内容
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
}
}
@Test
public void test(){
Spider.create(new SpiderTest()).addUrl("http://angularjs.cn/api/article/latest?s=20").run();
}
}
至此一个渲染的网页就爬取下来了。over
webmagic爬取渲染网站的更多相关文章
- python爬虫--爬取某网站电影信息并写入mysql数据库
书接上文,前文最后提到将爬取的电影信息写入数据库,以方便查看,今天就具体实现. 首先还是上代码: # -*- coding:utf-8 -*- import requests import re im ...
- python爬虫--爬取某网站电影下载地址
前言:因为自己还是python世界的一名小学生,还有很多路要走,所以本文以目的为向导,达到目的即可,对于那些我自己都没弄懂的原理,不做去做过多解释,以免误人子弟,大家可以网上搜索. 友情提示:本代码用 ...
- 爬虫系列2:Requests+Xpath 爬取租房网站信息
Requests+Xpath 爬取租房网站信息 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参考前文 ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
- Python 网络爬虫 002 (入门) 爬取一个网站之前,要了解的知识
网站站点的背景调研 1. 检查 robots.txt 网站都会定义robots.txt 文件,这个文件就是给 网络爬虫 来了解爬取该网站时存在哪些限制.当然了,这个限制仅仅只是一个建议,你可以遵守,也 ...
- python爬取某个网站的图片并保存到本地
python爬取某个网站的图片并保存到本地 #coding:utf- import urllib import re import sys reload(sys) sys.setdefaultenco ...
- 利用python的requests和BeautifulSoup库爬取小说网站内容
1. 什么是Requests? Requests是用Python语言编写的,基于urllib3来改写的,采用Apache2 Licensed 来源协议的HTTP库. 它比urllib更加方便,可以节约 ...
随机推荐
- Infer 在 Mac 上的安装和环境配置
Infer 在 Mac 上的安装和环境配置 Infer 介绍 Infer 是一个静态分析工具.Infer 可以分析 Objective-C, Java 或者 C 代码,报告潜在的问题. 任何人都可以使 ...
- 关于JavaScript组件化的探索
Loaders 先放出项目地址:https://github.com/j20041426/Loaders 这是一个可以动态选择加载动画的样式和颜色的插件.这个项目仅仅是作为对js组件化的一个探索,不太 ...
- [Android FrameWork 6.0源码学习] View的重绘过程之Layout
View绘制的三部曲,测量,布局,绘画现在我们分析布局部分测量部分在上篇文章中已经分析过了.不了解的可以去我的博客里找一下 View的布局和测量一样,都是从ViewRootImpl中发起,ViewRo ...
- JavaScript基本数据类型
JavaScript基本数据类型 在JavaScript种一共有6种数据类型:Null.Undefined.Boolean.String.Number.Object.其中Object是一种复杂数据类型 ...
- zabbix_server---微信报警
(1) 企业应用-创建应用 1.除了对个人添加微信报警之外,还可以添加不同管理组,接受同一个应用推送的消息, 成员账号,组织部门ID,应用Agent ID,CorpID和Secret, ...
- CentOS编译PHP过程中常见错误信息的解决方法
原文链接:http://www.linuxidc.com/Linux/2014-05/102327.htm ********************************************** ...
- eclipse导入lombok后打不开(如果你的lombok不是最新的,那就来下载最新的)
如果你的不是最新的,去这里下载最新版的,先点击左上角的Download红方块,然后再点击下图中的位置 https://projectlombok.org/ 下载完后把eclipse关掉,双击下载的ja ...
- Koa框架教程,Koa框架开发指南,Koa框架中文使用手册,Koa框架中文文档
我的博客:CODE大全:www.codedq.net:业余草:www.xttblog.com:爱分享:www.ndislwf.com或ifxvn.com. Koa -- 基于 Node.js 平台的下 ...
- 在linux环境下安装Node
liunx安装node的方法 cd /usr/src //node 安装的位置 一 : 普通用户: 安装前准备环境: 1.检查Linux 版本 命令: cat /etc/redhat-releas ...
- 白帽子之路首章:Footprinting, TARGET ACQUISITION
*Disclaimer: All materials provided on this blog are for educational purposes only. The author and o ...