【Java IO流】字节流和字符流详解
字节流和字符流
对于文件必然有读和写的操作,读和写就对应了输入和输出流,流又分成字节和字符流。
1.从对文件的操作来讲,有读和写的操作——也就是输入和输出。
2.从流的流向来讲,有输入和输出之分。
3.从流的内容来讲,有字节和字符之分。
这篇文章先后讲解IO流中的字节流和字符流的输入和输出操作。
一、字节流
1)输入和输出流
首先,字节流要进行读和写,也就是输入和输出,所以它有两个抽象的父类InputStream、OutputStream。
- InputStream抽象了应用程序读取数据的方式,即输入流。
- OutputStream抽象了应用程序写出数据的方式,即输出流。
2)读写结束
在字节流中当读写结束,达到文件结尾时,称为EOF = End或者读到-1就读到结尾。
3)输入流基本方法
首先我们要清楚输入流是什么。比如通过我们的键盘在文本文件上输入内容,这个过程键盘充当的就是输入流,而不是输出流。因为键盘的功能是将内容输入到系统,系统再写入到文件上。以下是输入流的基本方法read():
int b = in.read(); //读取一个字节无符号填充到int低八位。-1是EOF。
in.read(byte[] buf); //读取数据填充到字节数组buf中。返回的是读到的字节个数。
in.read(byte[] buf,int start, int size)//读取数据到字节数组buf从buf的start位置开始存放size长度分数据
其中in是InputStream抽象类的实例,可以发现这个方法和RandomAccessFile类中的read()方法差不多,因为两者都是通过字节来读取的。
4)输出流基本方法
输出流是进行写的操作,其基本操作方法是write(),可以将此方法与输入read()方法一 一去对应,更好理解。
out.write(int b)//写出一个byte到流,b的低8位
out.write(byte[] buf)//将buf字节数组都写到流
out.write(byte[] buf, int start,int size) //字节数组buf从start位置开始写size长度的字节到流
了解了InputStream、OutputStream的基本操作方法后,再来看看它们两个的“孩子”FileInputStream和FileOutputStream。
这两个子类具体实现了在文件上读取和写入数据的操作,日程编程中更多的是使用这两个类。
二、FileInputStream和FileOutputStream类的使用
-----------------FileInputStream类的使用
1.使用read()方法读取文件
/**
* 读取指定文件内容,按照16进制输出到控制台
* 并且每输出10个byte换行
* @throws FileNotFoundException
*/
public static void printHex(String fileName) throws IOException{
//把文件作为字节流进行读操作
FileInputStream in=new FileInputStream(fileName);
int b;
int count=0;//计数读到的个数
while((b=in.read())!=-1){
if(b<=0xf){
//单位数前面补0
System.out.println("0");
}
System.out.print(Integer.toHexString(b& 0xff)+" ");
if(++count%10==0){
System.out.println();
}
}
in.close();//一定要关闭流
}
运行结果(随便一个文件来测试的):

注意:
- FileInputStream()构造函数可以通过文件名(String)也可以通过File对象。上面的案例是使用文件名来构造的。
- (b=in.read())!=-1 通过读到-1来判断是否读到文件结尾。
- in.close() 使用完IO流的对象一定要关闭流,养成好习惯很重要。
2.使用read(byte[] buf,int start, int size)方法读取文件
上述方法只能一个一个字节读取,对于较大的文件效率太低,推荐使用这个方法来一次性读取文件。
public static void printHexByBytes(String fileName) throws IOException{
FileInputStream in=new FileInputStream(fileName);
byte[] buf=new byte[20*1024];//开辟一个20k大小的字节数组
/*
* 从in中批量读取字节,放入到buf这个字节数组中
* 从第0个位置开始放,最多放buf.length个
* 返回的是读到的字节个数
*/
//一次性读完的情况
int count=in.read(buf, 0, buf.length);
int j=1;
for(int i=0;i<count;i++){
if((buf[i]&0xff)<=0xf){
//单位数前面补0
System.out.print("0");
}
System.out.print(Integer.toHexString(buf[i]&0xff)+ " ");
if(j++%10==0){
System.out.println();
}
}
in.close();
}
}
read(byte[] buf,int start, int size)返回的是读到的字节个数,即buf字节数组的有效长度,所以输出buf数组时用的长度是count而不是buf.length,因为我们不知道文件大小和数组大小的关系,上述方法适用于文件大小不超过数组大小的情况下,一次性把文件内容读取到数组里,这里就有一个问题了,如果文件大小超过数组大小,那又该如何读取才能把文件全部读完呢??
我们知道读到-1就是读到文件末,所以还是利用while循环重复读取直到读到-1结束循环,把上述代码修改后如下:
public static void printHexByBytes(String fileName) throws IOException{
FileInputStream in=new FileInputStream(fileName);
byte[] buf=new byte[20*1024];//开辟一个20k大小的字节数组
/*
* 从in中批量读取字节,放入到buf这个字节数组中
* 从第0个位置开始放,最多放buf.length个
* 返回的是读到的字节个数
*/
int j=1;
//一个字节数组读不完的情况,用while循环重复利用此数组直到读到文件末=-1
int b=0;
while((b=in.read(buf, 0, buf.length))!=-1){
for(int i=0;i<b;i++){
if((buf[i]&0xff)<=0xf){
//单位数前面补0
System.out.print("0");
}
System.out.print(Integer.toHexString(buf[i]&0xff)+ " ");
if(j++%10==0){
System.out.println();
}
}
}
in.close();
}
}
好了,我们用一个大于数组的文件来测试一下结果(太长,只截图末尾):
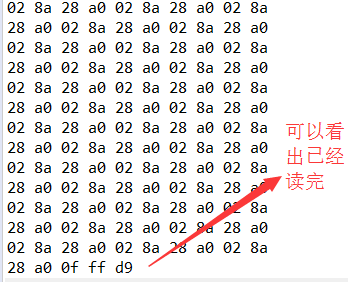
大家可以比较两者的不同,第二种优化后更适合日常的使用,因为无论文件大小我们都可以一次性直接读完。
-----------------FileOutputStream类的使用
FileOutputStream类和FileInputStream类的使用相类似,它实现了向文件中写出btye数据的方法。里面的一些细节跟FileInputStream差不多的我就不提了,大家自己可以理解的。
1.构造方法
FileOutputStream类构造时根据不同的情况可以使用不同的方法构造,如:
//如果该文件不存在,则直接创建,如果存在,删除后创建
FileOutputStream out = new FileOutputStream("demo/new1.txt");//以路径名称构造
//如果该文件不存在,则直接创建,如果存在,在文件后追加内容
FileOutputStream out = new FileOutputStream("demo/new1.txt",true);
更多内容可以查询API。
2.使用write()方法写入文件
write()方法和read()相似,只能操作一个字节,即只能写入一个字节。例如:
out.wirte(‘A’);//写出了‘A’的低八位
int a=10;//wirte只能写八位,那么写一个int需要写4次,每次八位
out.write(a>>>24);
out.write(a>>>16);
out.write(a>>>8);
out.wirte(a);
每次只写一个字节,显然是不效率的,OutputStream当然跟InputStream一样可以直接对byte数组操作。
3.使用write(byte[] buf,int start, int size)方法写入文件
意义:把byte[]数组从start位置到size位置结束长度的字节写入到文件中。
语法格式和read相同,不多说明
三、FileInputStream和FileOutputStream结合案例
了解了InputStream和OutputStream的使用方法,这次结合两者来写一个复制文件的方法。
public static void copyFile(File srcFile,File destFile)throws IOException{
if(!srcFile.exists()){
throw new IllegalArgumentException("文件:"+srcFile+"不存在");
}
if(!srcFile.isFile()){
throw new IllegalArgumentException(srcFile+"不是一个文件");
}
FileInputStream in =new FileInputStream(srcFile);
FileOutputStream out =new FileOutputStream(destFile);
byte[] buf=new byte[8*1024];
int b;
while((b=in.read(buf, 0, buf.length))!=-1){
out.write(buf, 0, b);
out.flush();//最好加上
}
in.close();
out.close();
}
测试文件案例:
try {
IOUtil.copyFile(new File("C:\\Users\\acer\\workspace\\encode\\new4\\test1"), new File("C:\\Users\\acer\\workspace\\encode\\new4\\test2"));
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
运行结果:


复制成功!
四、DataInputStream和DataOutputStream的使用
DataInputStream、DataOutputStream 是对“流”功能的扩展,可以更加方便地读取int,long。字符等类型的数据。
对于DataOutputStream而言,它多了一些方法,如
writeInt()/wirteDouble()/writeUTF()
这些方法其本质都是通过write()方法来完成的,这些方法都是经过包装,方便我们的使用而来的。
1.构造方法
以DataOutputStream为例,构造方法内的对象是OutputStream类型的对象,我们可以通过构造FileOutputStream对象来使用。
String file="demo/data.txt";
DataOutputStream dos= new DataOutputStream(new FileOutputStream(file));
2.write方法使用
dos.writeInt(10);
dos.writeInt(-10);
dos.writeLong(10l);
dos.writeDouble(10.0);
//采用utf-8编码写出
dos.writeUTF("中国");
//采用utf-16be(java编码格式)写出
dos.writeChars("中国");
3.read方法使用
以上述的写方法对立,看下面例子用来读出刚刚写的文件
String file="demo/data.txt";
IOUtil.printHex(file);
DataInputStream dis=new DataInputStream(new FileInputStream(file));
int i=dis.readInt();
System.out.println(i);
i=dis.readInt();
System.out.println(i);
long l=dis.readLong();
System.out.println(l);
double d=dis.readDouble();
System.out.println(d);
String s= dis.readUTF();
System.out.println(s);
dis.close();
运行结果:
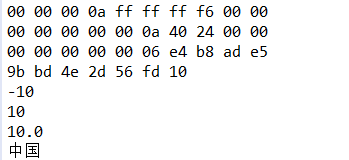
总结:DataInputStream和DataOutputStream其实是对FileInputStream和FileOutputStream进行了包装,通过嵌套方便我们使用FileInputStream和FileOutputStream的读写操作,它们还有很多其他方法,大家可以查询API。
注意:进行读操作的时候如果类型不匹配会出错!
五、字节流的缓冲流BufferredInputStresam&BufferredOutputStresam
这两个流类为IO提供了带缓冲区的操作,一般打开文件进行写入或读取操作时,都会加上缓冲,这种流模式提高了IO的性能。
从应用程序中把输入放入文件,相当于将一缸水倒入另一个缸中:
FileOutputStream---->write()方法相当于一滴一滴地把水“转移”过去
DataOutputStream---->write()XXX方法会方便一些,相当于一瓢一瓢地把水“转移”过去
BufferedOutputStream---->write方法更方便,相当于一瓢一瓢水先放入一个桶中(缓冲区),再从桶中倒入到一个缸中。提高了性能,推荐使用!
上述提到过用FileInputStream和FileOutputStream结合写的一个拷贝文件的案例,这次通过字节的缓冲流对上述案例进行修改,观察两者的区别和优劣。
主函数测试:
try {
long start=System.currentTimeMillis();
//IOUtil.copyFile(new File("C:\\Users\\acer\\Desktop\\学习路径.docx"), new File("C:\\Users\\acer\\Desktop\\复制文本.docx"));
long end=System.currentTimeMillis();
System.out.println(end-start);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
(1)单字节进行文件的拷贝,利用带缓冲的字节流
/*
* 单字节进行文件的拷贝,利用带缓冲的字节流
*/
public static void copyFileByBuffer(File srcFile,File destFile)throws IOException{
if(!srcFile.exists()){
throw new IllegalArgumentException("文件:"+srcFile+"不存在");
}
if(!srcFile.isFile()){
throw new IllegalArgumentException(srcFile+"不是一个文件");
}
BufferedInputStream bis=new BufferedInputStream(new FileInputStream(srcFile));
BufferedOutputStream bos=new BufferedOutputStream(new FileOutputStream(destFile));
int c;
while((c=bis.read())!=-1){
bos.write(c);
bos.flush();//刷新缓冲区
}
bis.close();
bos.close();
}
运行结果(效率):
(2)单字节不带缓冲进行文件拷贝
/*
* 单字节不带缓冲进行文件拷贝
*/
public static void copyFileByByte(File srcFile,File destFile)throws IOException{
if(!srcFile.exists()){
throw new IllegalArgumentException("文件:"+srcFile+"不存在");
}
if(!srcFile.isFile()){
throw new IllegalArgumentException(srcFile+"不是一个文件");
}
FileInputStream in=new FileInputStream(srcFile);
FileOutputStream out=new FileOutputStream(destFile);
int c;
while((c=in.read())!=-1){
out.write(c);
out.flush();//不带缓冲,可加可不加
}
in.close();
out.close();
}
运行结果(效率):
(3)批量字节进行文件的拷贝,不带缓冲的字节流(就是上面第三点最初的案例的代码)
/*
* 字节批量拷贝文件,不带缓冲
*/
public static void copyFile(File srcFile,File destFile)throws IOException{
if(!srcFile.exists()){
throw new IllegalArgumentException("文件:"+srcFile+"不存在");
}
if(!srcFile.isFile()){
throw new IllegalArgumentException(srcFile+"不是一个文件");
}
FileInputStream in =new FileInputStream(srcFile);
FileOutputStream out =new FileOutputStream(destFile); byte[] buf=new byte[8*1024];
int b;
while((b=in.read(buf, 0, buf.length))!=-1){
out.write(buf, 0, b);
out.flush();//最好加上
}
in.close();
out.close();
}
运行结果(效率):
(4)批量字节进行文件的拷贝,带缓冲的字节流(效率最高,推荐使用!!)
/*
* 多字节进行文件的拷贝,利用带缓冲的字节流
*/
public static void copyFileByBuffers(File srcFile,File destFile)throws IOException{
if(!srcFile.exists()){
throw new IllegalArgumentException("文件:"+srcFile+"不存在");
}
if(!srcFile.isFile()){
throw new IllegalArgumentException(srcFile+"不是一个文件");
}
BufferedInputStream bis=new BufferedInputStream(new FileInputStream(srcFile));
BufferedOutputStream bos=new BufferedOutputStream(new FileOutputStream(destFile));
byte[] buf=new byte[20*1024];
int c;
while((c=bis.read(buf, 0, buf.length))!=-1){
bos.write(buf, 0, c);
bos.flush();//刷新缓冲区
}
bis.close();
bos.close();
}
运行结果(效率):
注意:
批量读取或写入字节,带字节缓冲流的效率最高,推荐使用此方法。
当使用字节缓冲流时,写入操作完毕后必须刷新缓冲区,flush()。
- 不使用字节缓冲流时,flush()可以不加,但是最好加上去。
六、字符流
首先我们需要了解以下概念。
1)需要了解编码问题---->转移至《计算机中的编码问题》
2)认识文本和文本文件
java的文本(char)是16位无符号整数,是字符的unicode编码(双字节编码)
文件是byte byte byte...的数据序列
文本文件是文本(char)序列按照某种编码方案(utf-8,utf-16be,gbk)序列化byte的存储
3)字符流(Reader Writer)
字符的处理,一次处理一个字符;
字符的底层依然是基本的字节序列;
4)字符流的基本实现
InputStreamReader:完成byte流解析成char流,按照编码解析。
OutputStreamWriter:提供char流到byte流,按照编码处理。
-------------------------Reader和Writer的基本使用-------------------------------
String file1="C:\\Users\\acer\\workspace\\encode\\new4\\test1";
String file2="C:\\Users\\acer\\workspace\\encode\\new4\\test2";
InputStreamReader isr=new InputStreamReader(new FileInputStream(file1));
OutputStreamWriter osw=new OutputStreamWriter(new FileOutputStream(file2));
// int c;
// while((c=isr.read())!=-1){
// System.out.print((char)c);
// }
char[] buffer=new char[8*1024];
int c;
//批量读取,放入buffer这个字符数组,从第0个位置到数组长度
//返回的是读到的字符个数
while((c=isr.read(buffer,0,buffer.length))!=-1){
String s=new String(buffer,0,c);//将char类型数组转化为String字符串
System.out.println(s);
osw.write(buffer,0,c);
osw.flush();
//osw.write(s);
//osw.flush();
}
isr.close();
osw.close();
注意:
- 字符流操作的是文本文件,不能操作其他类型的文件!!
- 默认按照GBK编码来解析(项目默认编码),操作文本文件的时候,要写文件本身的编码格式(在构造函数时在后面加上编码格式)!!
- 字符流和字节流的区别主要是操作的对象不同,还有字符流是以字符为单位来读取和写入文件的,而字节流是以字节或者字节数组来进行操作的!!
- 在使用字符流的时候要额外注意文件的编码格式,一不小心就会造成乱码!
七、字符流的文件读写流FileWriter和FileReader
跟字节流的FileInputStream和FileOutputStream类相类似,字符流也有相应的文件读写流FileWriter和FileReader类,这两个类主要是对文本文件进行读写操作。
FileReader/FileWriter:可以直接写文件名的路径。
与InputStreamReader相比坏处:无法指定读取和写出的编码,容易出现乱码。
FileReader fr = new FileReader("C:\\Users\\acer\\workspace\\encode\\new4\\test1"); //输入流
FileWriter fw = new FileWriter(C:\\Users\\acer\\workspace\\encode\\new4\\test2");//输出流
char[] buffer=new char[8*1024];
int c;
while((c=fr.read(buffer, 0, buffer.length))!=-1){
fw.write(buffer, 0, c);
fw.flush();
}
fr.close();
fw.close();
注意:FileReader和FileWriter不能增加编码参数,所以当项目和读取文件编码不同时,就会产生乱码。 这种情况下,只能回归InputStreamReader和OutputStreamWriter。
八、字符流的过滤器BufferedReader&BufferedWriter
字符流的过滤器有BufferedReader和BufferedWriter/PrintWriter
除了基本的读写功能外,它们还有一些特殊的功能。
- BufferedReader----->readLine 一次读一行,并不识别换行
- BufferedWriter----->write 一次写一行,需要换行
- PrintWriter经常和BufferedReader一起使用,换行写入比BufferedWriter更方便
定义方式:
BufferedReader br =new BufferedReader(new InputStreamReader(new FileInputStream(目录的地址)))
BufferedWriter br =new BufferedWriter(new InputStreamWriter(new FileOutputStream(目录的地址)))
PrintWriter pw=new PrintWriter(目录/Writer/OutputStream/File);
使用方法:
//对文件进行读写操作
String file1="C:\\Users\\acer\\workspace\\encode\\new4\\test1";
String file2="C:\\Users\\acer\\workspace\\encode\\new4\\test2";
BufferedReader br = new BufferedReader(new InputStreamReader(
new FileInputStream(file1)));
BufferedWriter bw=new BufferedWriter(new OutputStreamWriter(
new FileOutputStream(file2)));
String line;
while((line=br.readLine())!=null){
System.out.println(line);//一次读一行,并不能识别换行
bw.write(line);
//单独写出换行操作
bw.newLine();
bw.flush();
}
br.close();
bw.close();
}
在这里我们可以使用PrintWriter来代替BufferedWriter做写操作,PrintWriter相比BufferedWriter有很多优势:
- 构造函数方便简洁,使用灵活
- 构造时可以选择是否自动flush
- 利用println()方法可以实现自动换行,搭配BufferedReader使用更方便
使用方法:
String file1="C:\\Users\\acer\\workspace\\encode\\new4\\test1";
String file2="C:\\Users\\acer\\workspace\\encode\\new4\\test2";
BufferedReader br = new BufferedReader(new InputStreamReader(
new FileInputStream(file1)));
PrintWriter pw=new PrintWriter(file2);
//PrintWriter pw=new PrintWriter(outputStream, autoFlush);//可以指定是否自动flush
String line;
while((line=br.readLine())!=null){
System.out.println(line);//一次读一行,并不能识别换行
pw.println(line);//自动换行
pw.flush();//指定自动flush后不需要写
}
br.close();
pw.close();
}
注意:
- 可以使用BufferedReader的readLine()方法一次读入一行,为字符串形式,用null判断是否读到结尾。
- 使用BufferedWriter的write()方法写入文件,每次写入后需要调用flush()方法清空缓冲区;PrintWriter在构造时可以指定自动flush,不需要再调用flush方法。
- 在写入时需要注意写入的数据中会丢失换行,可以在每次写入后调用BufferedReader的newLine()方法或改用PrintWriter的println()方法补充换行。
- 通常将PrintWriter配合BufferedWriter使用。(PrintWriter的构造方法,及使用方式更为简单)。
-----------------更多java流的操作和内容请自行查阅API------------------------
【Java IO流】字节流和字符流详解的更多相关文章
- java IO之字节流和字符流-Reader和Writer以及实现文件复制拷贝
接上一篇的字节流,以下主要介绍字符流.字符流和字节流的差别以及文件复制拷贝.在程序中一个字符等于两个字节.而一个汉字占俩个字节(一般有限面试会问:一个char是否能存下一个汉字,答案当然是能了,一个c ...
- java IO的字节流和字符流及其区别
1. 字节流和字符流的概念 1.1 字节流继承于InputStream OutputStream, 1.2 字符流继承于InputStreamReader OutputStre ...
- java IO通过字节流,字符流 读出写入
一:通过字节流操作数据的写入,读出 /** * 通过字节流写入和读出 * @param args */ public static String filePath = "G:" + ...
- Java IO:字节流与字符流
https://blog.csdn.net/my_truelove/article/details/53758412 字符和字节之间可以互相转化,中间的参照就是编码方式. 相当于给你一个密码本,按照这 ...
- java学习笔记之IO编程—字节流和字符流
1. 流的基本概念 在java.io包里面File类是唯一一个与文件本身有关的程序处理类,但是File只能够操作文件本身而不能操作文件的内容,或者说在实际的开发之中IO操作的核心意义在于:输入与输出操 ...
- Java IO(五)——字符流进阶及BufferedWriter、BufferedReader
一.字符流和字节流的区别 拿一下上一篇文章的例子: package com.demo.io; import java.io.File; import java.io.FileReader; impor ...
- Java 输入/输出——字节流和字符流
1.流的分类 (1)输入流和输出流(划分输入/输出流时是从程序运行所在内存的角度来考虑的) 输入流:只能从中读取数据,而不能向其写入数据. 输出流:只能向其写入数据,而不能从中读取数据. 输入流主要由 ...
- JAVA中的字节流与字符流
字节流与字符流的区别? 字节流与和字符流的使用非常相似,两者除了操作代码上的不同之外,是否还有其他的不同呢? 实际上字节流在操作时本身不会用到缓冲区(内存),是文件本身直接操作的,而字符流在操作时使用 ...
- JAVA基础之字节流与字符流
个人理解: IO流就是将数据进行操作的方式,因为编码的不同,所以对文件的操作就产生两种.最好用字节流,为了方便看汉字等,(已经确定文字的话)可以使用字符流.每个流派也就分为输入和输出,这样就可以产生复 ...
- Java基础(二十七)Java IO(4)字符流(Character Stream)
字符流用于处理字符数据的读取和写入,它以字符为单位. 一.Reader类与Writer类 1.Reader类是所有字符输入流的父类,它定义了操作字符输入流的各种方法. 2.Writer类是所有字符输出 ...
随机推荐
- MongoDB入门命令
查看所有数据库 > show dbs admin (empty) local 0.078GB > admin和管理相关, admin和local数据库不要轻易动 选择库 > use ...
- IIS7.5应用程序池集成模式和经典模式的区别介绍
IIS7.5应用程序池集成模式和经典模式的区别介绍 作者: 字体:[增加 减小] 类型:转载 时间:2012-08-07 由于最近公司服务器上需要将iis的应用程序池全部都升级到4.0的框架,当 ...
- 阿里云ECS主机自定义进程监控
由于业务的关系我们用的是阿里云的ECS主机,需要对业务进程需要监控,查看后发现阿里云提供自定义监控SDK,这有助于我们定制化的根据自身业务来做监控,下面我就根据业务需求来介绍一个简单的自定义监控配置 ...
- Open-Falcon第六步安装Dashboard(小米开源互联网企业级监控系统)
安装Dashboard dashboard是面向用户的查询界面,在这里,用户可以看到push到graph中的所有数据,并查看其趋势图. yum install -y python-virtualenv ...
- Hello BlogsPark
2017年8月4日, 今天是使用博客园的第一天, 签个到. NSLog(@"Hello BlogsPark");
- nodejs模块学习: express-session 解析
nodejs模块学习: express-session 解析 nodejs 发展很快,从 npm 上面的包托管数量就可以看出来.不过从另一方面来看,也是反映了 nodejs 的基础不稳固,需要开发者创 ...
- Python 装饰器总结
装饰器总结 前提 使用装饰器的前提在于Python提供的特性: 函数即对象,可以进行传递: 函数可以被定义在另外一个函数中: 可以通过一个例子来了解: def get_animal(name='dog ...
- 编译器报错:'IHTMLControlElement' : redefinition
由于我安装了platform SDK,编译导致错误: error C2367: 'IHTMLControlElement' : redefinition; different uuid specifi ...
- Django编写RESTful API(一):序列化
欢迎访问我的个人网站:www.comingnext.cn 关于RESTful API 现在,在开发的过程中,我们经常会听到前后端分离这个技术名词,顾名思义,就是前台的开发和后台的开发分离开.这个技术方 ...
- Spring(一)之IOC、bean、注入
[TOC] spring简介 首先它是一个开源的.用来简化企业级应用开发的框架. Spring为编写企业应用程序提供了轻量的解决方案,同时仍然支持使用声明式事务. 用RMI或web service远程 ...