python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
原创文章,转载请注明出处!
操作环境:python3
在上一文中python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前的文章便于理解
本文将介绍如何用scrapy来登录知乎。
不多说,直接上代码:
import scrapy
import re
import json class ZhihuSpider(scrapy.Spider):
name = 'zhihu'
allowed_domains = ['www.zhihu.com']
start_urls = ['https://www.zhihu.com/'] headers = {
'HOST': 'www.zhihu.com',
'Referer': 'https://www.zhihu.com',
'User-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/603.3.8 (KHTML, like Gecko) Version/10.1.2 Safari/603.3.8',
} def parse(self, response):
pass def parse_detail(self, response):
# 爬取文章细节
pass # scrapy开始时先进入start_requests()
def start_requests(self):
# 为了提取_xsrf:要先访问知乎的登录页面,让scrapy在登录页面获取服务器给我们的数据(_xsrf),再调用login
return [scrapy.Request('https://www.zhihu.com/#signin', headers=self.headers, callback=self.login)] def login(self, response):
xsrf = ''
match_obj = re.match('[\s\S]*name="_xsrf" value="(.*?)"', response.text)
if match_obj:
xsrf = match_obj.group(1) # 如果提取到了xsrf就进行下面的操作,如果没xsrf有就没必要往下做了
if xsrf:
post_data = {
'captcha_type': 'cn',
'_xsrf': xsrf,
'phone_num': 'YourPhoneNum',
'password': 'YourPassWord',
'captcha': '',
}
import time
captcha_url = 'https://www.zhihu.com/captcha.gif?r=%d&type=login&lang=cn' % (int(time.time() * 1000))
# scrapy会默认把Request的cookie放进去
return scrapy.Request(captcha_url, headers=self.headers, meta={'post_data': post_data}, callback=self.login_after_captcha) def login_after_captcha(self, response):
# 保存并打开验证码
with open('captcha.gif', 'wb') as f:
f.write(response.body)
f.close()
from PIL import Image
try:
img = Image.open('captcha.gif')
img.show()
except:
pass
# 输入验证码
captcha = {
'img_size': [200, 44],
'input_points': [],
}
points = [[22.796875, 22], [42.796875, 22], [63.796875, 21], [84.796875, 20], [107.796875, 20],
[129.796875, 22], [150.796875, 22]]
seq = input('请输入倒立字的位置\n>')
for i in seq:
captcha['input_points'].append(points[int(i) - 1])
captcha = json.dumps(captcha) post_url = 'https://www.zhihu.com/login/phone_num'
post_data = response.meta.get('post_data', {})
post_data['captcha'] = captcha
return scrapy.FormRequest(
# 在这里完成像之前的requests的登录操作,每一个Request如果要做下一步处理都要设置callback
url=post_url,
formdata=post_data,
headers=self.headers,
callback=self.check_login,
) def check_login(self, response):
# 验证服务器的返回数据判断是否成功
text_json = json.loads(response.text)
if 'msg' in text_json and text_json['msg'] == '登录成功':
print('登录成功!')
for url in self.start_urls:
yield scrapy.Request(url, dont_filter=True, headers=self.headers)
这个文件是你爬虫目录下的spider/zhihu.py,有scrapy基础的都看得懂。
下面让我们一起分析一下这个逻辑
首先你要知道:
- 如果要爬取知乎文章就必须先登录。
- 爬虫开始前要执行 start_requests() 函数 ,然后执行 parse() 函数。
所以我们要在 start_requests() 里进行登录,再在 parse() 里进行提取我们要爬取的字段。这里我们不分析 parse() 怎么写,只分析如何登录。下面让我们逐步分析如何登录:
首先要访问知乎的登录界面获取 "_xsrf" 字段的值:
def start_requests(self):
return [scrapy.Request('https://www.zhihu.com/#signin', headers=self.headers, callback=self.login)]
在scrapy请求了https://www.zhihu.com/#signin后,知乎服务器返回的cookies就会被scrapy保存,下次请求(request)会默认带着这些cookies。
在 login() 函数里进行提取 "_xsrf" 字段(看不懂如何提取的可参考之前的文章),并去请求知乎的验证码URL,这里是必须要注意的,在请求知乎的验证码URL后,知乎服务器会返回cookies,我们在提交验证码字段时必须带上直呼服务器给你的cookies,知乎服务器会进行匹配,如果cookies不对就会验证失败。
def login(self, response):
xsrf = ''
match_obj = re.match('[\s\S]*name="_xsrf" value="(.*?)"', response.text)
if match_obj:
xsrf = match_obj.group(1) # 如果提取到了xsrf就进行下面的操作,如果没xsrf有就没必要往下做了
if xsrf:
post_data = {
'captcha_type': 'cn',
'_xsrf': xsrf,
'phone_num': '这里写你登录的电话号',
'password': '这里写你的登录密码',
'captcha': '',
}
import time
captcha_url = 'https://www.zhihu.com/captcha.gifr=%d&type=login&lang=cn' % (int(time.time() * 1000))
# scrapy会默认把Request的cookie放进去
yield scrapy.Request(captcha_url, headers=self.headers, meta={'post_data': post_data}, callback=self.login_after_captcha)
向知乎服务器请求验证码后,这个 request 返回的 response 里其实就是验证码图片了,下面我们会调用 login_after_captcha() 函数,进行验证码图片的保存、自动打开、手动输入验证码的位置,再利用 python 的 Json 模块把 captcha 这个dict转换成 Json 格式放入 post_data 中。顺便一提,目前这里的 yield 完全可以用 return 代替。
def login_after_captcha(self, response):
# 保存并打开验证码
with open('captcha.gif', 'wb') as f:
f.write(response.body)
f.close()
from PIL import Image
try:
img = Image.open('captcha.gif')
img.show()
except:
pass
# 输入验证码
captcha = {
'img_size': [200, 44],
'input_points': [],
}
points = [[22.796875, 22], [42.796875, 22], [63.796875, 21], [84.796875, 20], [107.796875, 20],
[129.796875, 22], [150.796875, 22]]
seq = input('请输入倒立字的位置\n>')
for i in seq:
captcha['input_points'].append(points[int(i) - 1])
captcha = json.dumps(captcha) post_url = 'https://www.zhihu.com/login/phone_num'
post_data = response.meta.get('post_data', {})
post_data['captcha'] = captcha
return [scrapy.FormRequest(
# 在这里完成像之前的requests的登录操作,每一个Request如果要做下一步处理都要设置callback
url=post_url,
formdata=post_data,
headers=self.headers,
callback=self.check_login,
)]
把填写好的 post_data 发送给知乎登录URL:https://www.zhihu.com/login/phone_num,这里只演示电话号码登录,邮箱登录一个原理,只不过URL不一样:https://www.zhihu.com/login/email。之后我们要调用 check_login() 函数来检查是否登录成功,思路就是查看返回的"msg"字段是否为"登陆成功"。然后再调用scrapy原有的 start_request() 函数里的方法,经查看源码它的方法实际就是下面的遍历self.start_url再进行request(我的start_url是知乎主页,所以这个request就会访问知乎主页)
def check_login(self, response):
# 验证服务器的返回数据判断是否成功
text_json = json.loads(response.text)
if 'msg' in text_json and text_json['msg'] == '登录成功':
print('登录成功!')
for url in self.start_urls:
yield scrapy.Request(url, dont_filter=True, headers=self.headers)
由于我们已经登陆成功了,scrapy再访问知乎主页www.zhihu.com就会带着知乎服务器返回已经登录成功的cookies,因此就会直接进入登录成功的主页。
到此为止,我们就大功告成了!
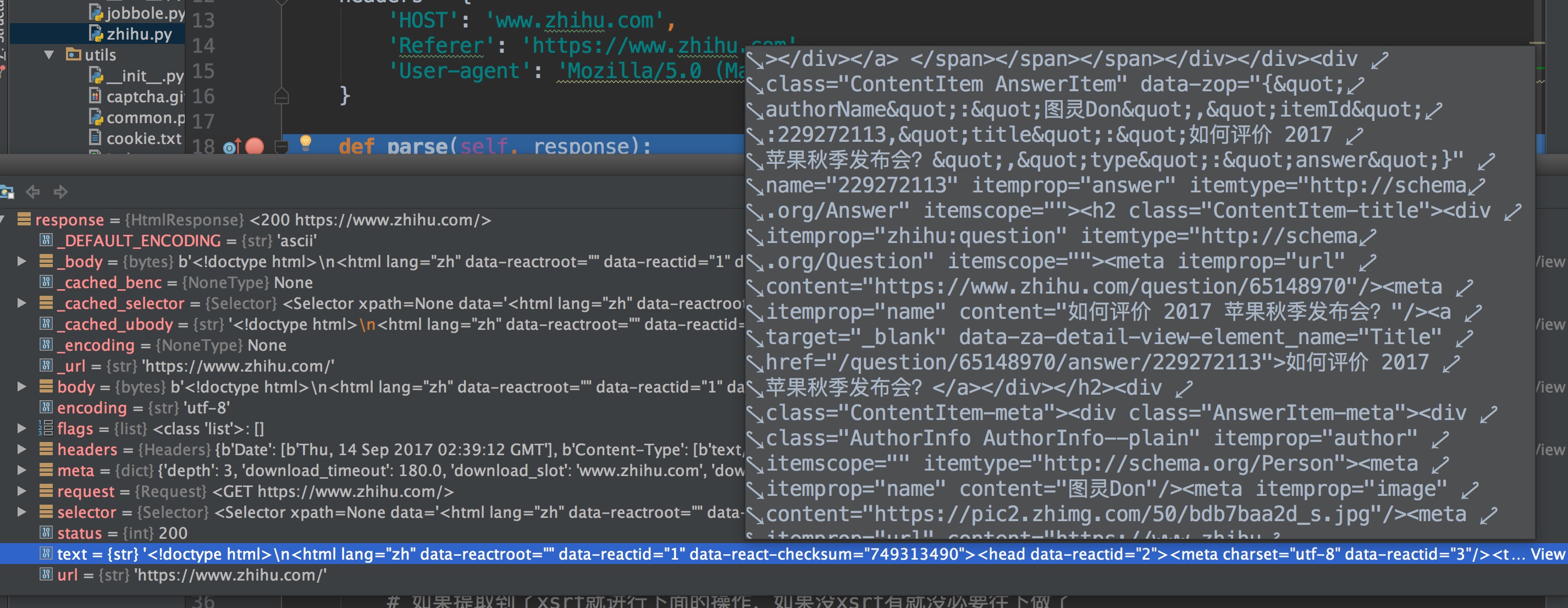
让我们利用 Pycharm 的 Debug 模式在parse那打个断点,查看response的text,已经登录上知乎了,是不是很开心!
python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)的更多相关文章
- python爬虫scrapy框架——人工识别知乎登录知乎倒立文字验证码和数字英文验证码
目前知乎使用了点击图中倒立文字的验证码: 用户需要点击图中倒立的文字才能登录. 这个给爬虫带来了一定难度,但并非无法解决,经过一天的耐心查询,终于可以人工识别验证码并达到登录成功状态,下文将和大家一一 ...
- 第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别
第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别 第一步.首先下载,大神者也的倒立文字验证码识别程序 下载地址:https://gith ...
- Python爬虫Scrapy框架入门(0)
想学习爬虫,又想了解python语言,有个python高手推荐我看看scrapy. scrapy是一个python爬虫框架,据说很灵活,网上介绍该框架的信息很多,此处不再赘述.专心记录我自己遇到的问题 ...
- 二十二 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别
第一步.首先下载,大神者也的倒立文字验证码识别程序 下载地址:https://github.com/muchrooms/zheye 注意:此程序依赖以下模块包 Keras==2.0.1 Pillow= ...
- Python爬虫 ---scrapy框架初探及实战
目录 Scrapy框架安装 操作环境介绍 安装scrapy框架(linux系统下) 检测安装是否成功 Scrapy框架爬取原理 Scrapy框架的主体结构分为五个部分: 它还有两个可以自定义下载功能的 ...
- python爬虫scrapy框架
Scrapy 框架 关注公众号"轻松学编程"了解更多. 一.简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量 ...
- Python爬虫Scrapy框架入门(2)
本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西 附上原创链接: http://www.cnblogs.com/qiyeboy/p/5428240.html 基本思路是,查看网页元素,填写 ...
- Python爬虫Scrapy框架入门(1)
也许是很少接触python的原因,我觉得是Scrapy框架和以往Java框架很不一样:它真的是个框架. 从表层来看,与Java框架引入jar包.配置xml或.property文件不同,Scrapy的模 ...
- Python爬虫-- Scrapy框架
Scrapy框架 Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是事件驱动的,并且比较适合异步的代码.对于会阻塞线程的操作包含访问文件.数据库或者Web.产生新的进程并需要 ...
随机推荐
- ABP+AdminLTE+Bootstrap Table权限管理系统第六节--abp控制器扩展及json封装
一,控制器AbpController 说完了Swagger ui 我们再来说一下abp对控制器的处理和json的封装. 首先我们定义一个控制器,在新增控制器的时候,控制器会自动继承自AbpContro ...
- ABP+AdminLTE+Bootstrap Table权限管理系统第八节--ABP错误机制及AbpSession相关
上一节我们讲到登录逻辑,我做的登录逻辑很简单的,我们来看一下abp module-zero里面的登录代码. #region Login / Logout public ActionResult Log ...
- 安徽省2016“京胜杯”程序设计大赛_D_梯田AGAIN
梯田AGAIN Time Limit: 5000 MS Memory Limit: 65536 KB Total Submissions: 95 Accepted: 21 Description 大家 ...
- 安卓Service完全解析(中)
摘要: 版权声明:本文出自汪磊的博客,转载请务必注明出处. 在上一篇中我们学习了Android Service相关的许多基础但是重要的内容,基本涵盖大部分平日里的开发工作.今天我们继续学习一下稍微高级 ...
- ThinkSNS+ 基于 Laravel master 分支,从 1 到 0,再到 0.1
什么是 ThinkSNS+ 09 年,由北京的团队开发了 ThinkSNS 涉足社交开源行业.这么多年累计不少客户.2014-2016,两年都在维护和开发之前基于 TP 的 ThinkSNS , 慢慢 ...
- Swoole笔记(四)
Process Process是swoole内置的进程管理模块,用来替代PHP的pcntl扩展. swoole_process支持重定向标准输入和输出,在子进程内echo不会打印屏幕,而是写入管道,读 ...
- 《STL源码剖析》相关面试题总结
原文链接:http://www.cnblogs.com/raichen/p/5817158.html 一.STL简介 STL提供六大组件,彼此可以组合套用: 容器容器就是各种数据结构,我就不多说,看看 ...
- Navicat提示Access violation at address 004E9844 in module ‘comctl32.dll’
内存越界问题,重新注册下Windows的动态链接库,首先“开始”—“cmd”,在打开的dos窗口中运行“for %1 in (%windir%\system32\*.dll) do regsvr32. ...
- C++中printf和scanf的用法
(一)printf的用法 printf:按格式打印,向控制台输出.print:打印 ,f:formate,格式化. 在使用printf向控制台输出时,不建议使用中文字符串,中文字符串的问题比较复杂,有 ...
- “margin塌陷” 嵌套盒子外边距合并现象
来源于官方文档对于外边距合并的解释: 注释:只有普通文档流中块框的垂直外边距才会发生外边距合并.行内框.浮动框或绝对定位之间的外边距不会合并. 出现外边距塌陷的三种情况: 1.相邻兄弟元素之间 若两者 ...