Recurrent Neural Network系列4--利用Python,Theano实现GRU或LSTM
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明。谢谢!
本文翻译自 RECURRENT NEURAL NETWORK TUTORIAL, PART 4 – IMPLEMENTING A GRU/LSTM RNN WITH PYTHON AND THEANO 。
本文的代码github地址 在此 。这是循环神经网络教程的第四部分,也是最后一个部分。之前的博文在此,
本文中我们将会学习LSTM(Long Short Term Memory)网络和GRUs(Gated Recurrent Units)。LSTM是由 Sepp Hochreiter and Jürgen Schmidhubere 在1997年提出,目前是深度学习应用到NLP领域中最为广泛的模型。GRUs 是在2014年 提出 ,是LSTM的一个简单变种,二者有很多相同的特性。让我们先看看LSTM,然后再看看GRU有何不同。
1 LSTM网络
在第三部分 理解RNN的BPTT算法和梯度消失,我们了解了梯度消失问题阻碍了标准循环神经网络学习长期依赖。LSTM通过门机制来解决梯度消失问题。为了更好的理解原理,我们看看LSTM如何计算隐层状态 \(s_{t}\) (这里我们使用 \(\circ\) 来表示元素相乘)。
\(i= \sigma(x_{t}U^{i}+s_{t-1}W^{i})\)
\(f= \sigma(x_{t}U^{f}+s_{t-1}W^{f})\)
\(o= \sigma(x_{t}U^{o}+s_{t-1}W^{i})\)
\(g= tanh(x_{t}U^{g}+s_{t-1}W^{g})\)
\(c_{t}= c_{t-1} \circ f + g \circ i\)
\(s_{t} = tanh(c_{t}) \circ o\)
这些公式看起来很复杂,但实际上并不难。首先,注意到LSTM就是另一种计算隐层状态的方式。首先,我们计算隐层状态 \(s_{t} = tanh(U x_{t} + W s_{t-1})\) 。单元的输入就是当前时刻t的输入 \(x_{t}\) 和上一个隐藏状态 \(s_{t-1}\) 。输出就是一个新的隐层状态 \(s_{t}\) 。一个LSTM单元和RNN做着相同的事情,仅仅是使用另一种方式。这个就是理解LSTM的关键。你可以把LSTM(和GRU)单元视为黑盒。已知输入和之前时刻的隐藏状态,就可以按照某种方式计算下一时刻的隐层状态。
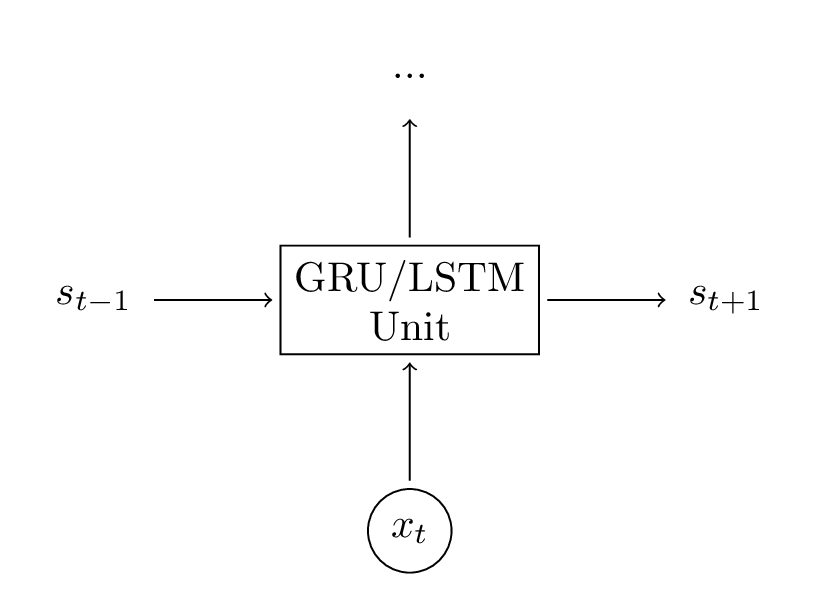
考虑到这一点,我们试着理解一个LSTM如何计算隐层状态。Chris Olah有一篇博文,详细地对此进行了讲解,为了避免重复他的工作,我在此仅仅给出简单的解释。我认为你可以读读他的这篇博文,可以获得更深入的洞察力和良好的视觉效果。总结如下:
- \(i,f,o\) 分别被称之为输入门、遗忘门、输出门。它们有相同的方程式,只是参数不同。它们被称为门,是因为sigmoid函数将向量值压缩在0到1这个区间,然后将这些值与你定义的向量相乘,就表示你允许这个向量通过多少。输入门定义了对于当前输入,你想让新计算出的状态通过多少。遗忘门表示你想让前一时刻的状态通过多少。最后,输出门表示你想让中间的隐层状态传输多少到网络其他部分(如更高层或者下一时刻),所有的门都有相同的维度 \(d_{s}\) ,也就是隐层状态的维度;
- g 是候选的隐层状态,由当前输入和前一时刻的隐层状态计算得出。它和普通的循环神经网络具有相同的方程式,我们仅仅是将参数 U 和 W 重命名为 \(U^{g}\) 和 \(W^{g}\) 。但是,与我们在循环神经网络中将 g 作为新的隐层状态不同,我们将会使用上述中的输入门来挑选它;
- \(c_{t}\) 是中间记忆单元。它是由先前的记忆 \(c_{t-1}\) 与遗忘门的乘积和新计算的隐层状态g与输入门的乘积相组合而得到。直观地,它是对先前的记忆和新输入的一种组合。我们可以选择完全忽略旧的记忆(遗忘门全为0)或者完全忽略新计算的状态(输入门为0),但是更多是我们想取二者之间;
- 给定记忆 \(c_{t}\),我们最后通过将记忆与输出门相乘来计算输出隐层状态 \(s_{t}\) 。通过使用其它的网络单元,并不是所有的中间记忆与隐层状态是相关的;
LSTM单元框图如下所示,
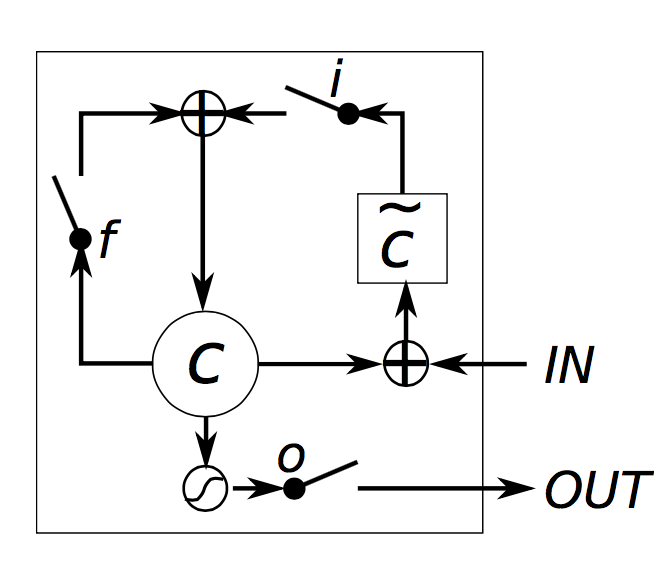
直观上,原始的循环神经网络可以视为LSTM的一个特例。如果你将输入门固定为1,遗忘门固定为0(意味着你经常遗忘之前的记忆),输出门固定为1(意味着传输全部的记忆),你就可以得到标准的循环神经网络了。额外的tanh函数会将压缩输出。门机制允许LSTM可以对长期依赖进行建模。通过学习门的参数,网络将会学习到记忆如何表现。
现在已经存在对基本LSTM架构的多个变种。其中一个就是创建窥视孔连接,允许门不仅依赖前一时刻的隐层状态 \(s_{t-1}\) ,也依赖前一时刻的中间状态 \(c_{t-1}\) ,需要在方程式中加入额外的项。当然也有其他的变种。 LSTM: A Search Space Odyssey 对不同的LSTM架构进行了评测。
2 GRUs
GRU背后的思想非常类似于LSTM,方程式如下,
\(z = \sigma(x_{t} U^{z} + s_{t-1} W^{z})\)
\(r = \sigma(x_{t} U^{r} + s_{t-1} W^{r})\)
\(h = tanh(x_{t} U^{h} + (s_{t-1} \circ r) W^{h})\)
\(s_{t-1} = (1-z) \circ h + z \circ s_{t-1}\)
GRU有两个门,一个称为重置门 r,另一个称为更新门 z。直观上,重置门决定新输入和先前记忆如何组合,更新门决定先前记忆保留多少。如果我们设置重置门为1,更新门为0,我们就获得了原始的循环神经网络。GRU使用门机制来学习长期依赖的基本思想与LSTM相同,但是有些关键的区别:
- 一个GRU单元有两个门,LSTM有三个门;
- GRU不处理中间记忆 \(c_{t}\) ,LSTM则将其传输给隐层状态,GRU没有LSTM中的输出门;
- 输入门和遗忘门由更新门 z 和重置门 r 共同组成,直接作用于先前的隐层状态上。因此,LSTM中重置门的任务就是分裂为 r 和 z;
- 计算输出时,没有使用第二个非线性函数;
GRU单元框图如下所示,
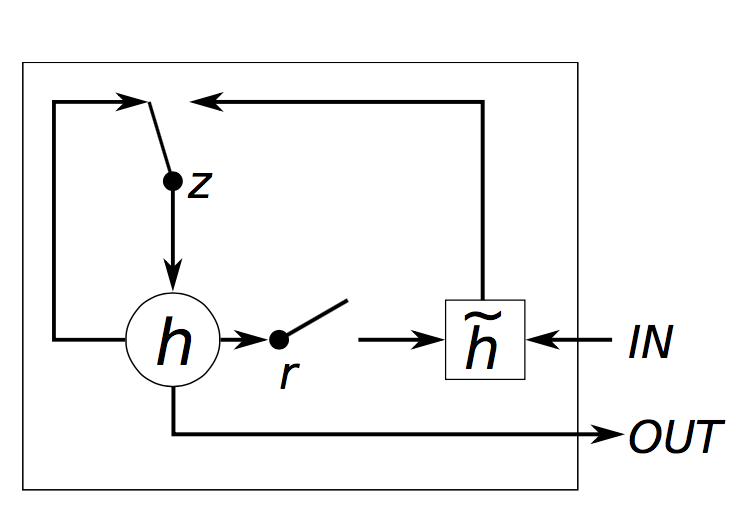
3 GRU 和 LSTM
现在你已经看到两个模型都可以克服梯度消失问题,你或许会疑惑:该使用哪个模型?GRU相对是一个新的模型,它们之间的权衡还没有被充分的探讨。根据Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling 和 An Empirical Exploration of Recurrent Network Architecture的经验评测,它们之间没有明确的赢家。在很多任务中,这两个架构产生了可对比的效果,调整超参数,例如层数,会比选择完美的架构更加重要。GRU拥有更少的参数(U 和 W 比较小),因此可以训练的更快或者需要更少的数据来泛化。另一方面,如果你拥有足够的数据,更加强大的LSTM或许会产生更佳的结果。
4 实现
让我们回到 利用Python,Theano实现RNN 中实现的语言模型上,在循环神经网络中使用GRU单元。在这部分我选择GRU而非LSTM并没有什么原则性的原因(另外就是我想更加熟悉GRU)。它们的实现几乎相同,所以你通过修改方程式,可以很方便的从GRU修改到LSTM。
我们基于之前Theano的实现代码。GRU(LSTM)层仅仅是另一种计算隐层状态的方式。所以我们需要做的就是在前向传播函数中修改隐层状态的计算。代码如下,
def forward_prop_step(x_t, s_t1_prev):
# This is how we calculated the hidden state in a simple RNN. No longer!
# s_t = T.tanh(U[:,x_t] + W.dot(s_t1_prev))
# Get the word vector
x_e = E[:,x_t]
# GRU Layer
z_t1 = T.nnet.hard_sigmoid(U[0].dot(x_e) + W[0].dot(s_t1_prev) + b[0])
r_t1 = T.nnet.hard_sigmoid(U[1].dot(x_e) + W[1].dot(s_t1_prev) + b[1])
c_t1 = T.tanh(U[2].dot(x_e) + W[2].dot(s_t1_prev * r_t1) + b[2])
s_t1 = (T.ones_like(z_t1) - z_t1) * c_t1 + z_t1 * s_t1_prev
# Final output calculation
# Theano's softmax returns a matrix with one row, we only need the row
o_t = T.nnet.softmax(V.dot(s_t1) + c)[0]
return [o_t, s_t1]
在我们的实现中,我们添加了偏置项b , c。它们并没有在方程式中出现。当然我们也需要修改参数 U 和 W 的初始化,因为它们现在的维度发生变化。具体代码可以参考 github 。我也添加了一个词嵌入层E,更多在下面展示。
这个非常简单。梯度如何计算呢?正如之前所做的,我们可以使用链式法则来计算E,W,U,b和c的梯度。但是在实践中,更多人使用支持表达式自动微分的库(例如Theano)。如果你想自己计算梯度,你或许需要将不同的单元模块化,并且利用链式法则,拥有属于你自己的自动微分版本。我们可以使用Theano来计算梯度,
# Gradients using Theano
dE = T.grad(cost, E)
dU = T.grad(cost, U)
dW = T.grad(cost, W)
db = T.grad(cost, b)
dV = T.grad(cost, V)
dc = T.grad(cost, c)
这是相当多的。为了得到更好的结果,我们也在实现中额外使用了一些技巧。
4.1 使用RMSPROP用于参数更新
在 利用Python,Theano实现RNN 中,我们使用了随机梯度下降(SGD)的最基本的版本来更新我们的参数。其实这不是一个好主意。 如果你将学习率设定得很低,SGD可以取得较好的结果,但是,在实践中却需要很长时间。SGD存在许多常用的变体,包括 (Nesterov)动量方法,AdaGrad,AdaDelta和rmsprop。这篇文章 包含了这些方法的概述。我还计划在未来的一篇文章中详细探讨这些方法的实现。对于本教程的这一部分,我选择使用rmsprop。rmsprop背后的基本思想是根据先前梯度的(平滑)和来调整每个参数的学习率。直观地,这意味着频繁出现的特征获得较小的学习率(因为它们的梯度的总和更大),并且罕见的特征获得更大的学习率。
rmsprop的实现非常简单。对于每个参数,我们保留缓存变量,并且在梯度下降期间,我们按如下的方式更新参数和缓存,这里以W为例,
cacheW = decay * cacheW + (1 - decay) * dW ** 2
W = W - learning_rate * dW / np.sqrt(cacheW + 1e-6)
衰减率通常设置为0.9或0.95,加入1e-6项以避免除以0。
4.2 增加嵌入层
使用word2vec和GloVe这样的词嵌入是提高模型准确性的一种流行方法。没有使用one-hot向量来表示单词,而是使用word2vec或GloVe学习到的低维向量,是因为它具备语义信息——相似的词具有相似的向量。使用这些向量是一种预训练的形式。直观地,你正在告诉网络哪些单词是相似的,所以它可以更少的理解语言。如果您没有大量数据,那么使用预先训练的矢量特别有用,因为它允许网络推广到不可见的单词。我没有在我的实验中使用预先训练的单词向量,而是添加一个词嵌入层(代码中的矩阵E)使得它们很容易插入。嵌入矩阵实际上就是一个查找表——第i列向量对应在我们的词汇中的第i个词。通过更新矩阵E,我们自己学习词向量,但它们对于我们的任务(以及数据集)非常特定,而不是像你下载的数据那样,它们是经过数百万或数十亿个文档的训练。
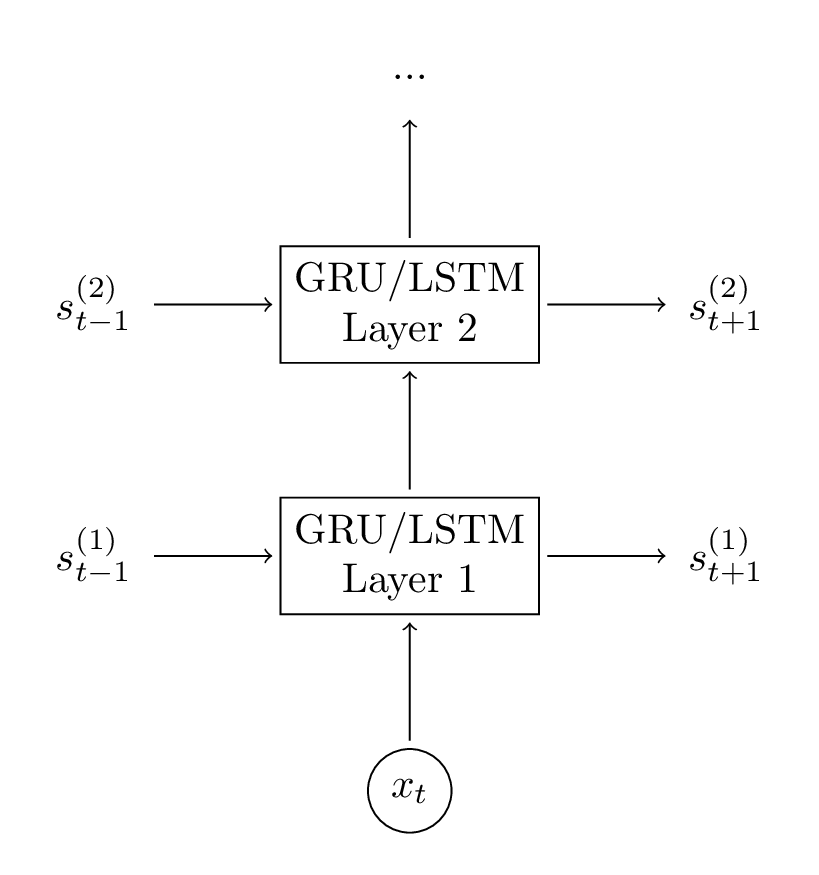
4.3 增加第二个GRU层
将第二层添加到我们的网络中允许我们的模型捕获更高级别的交互。你可以添加额外的层,但是我没有尝试这个实验。你可能会看到2-3层之后的收益会递减,除非你拥有大量数据(但是我们没有),否则更多的层次不太可能产生很大的影响,并可能导致过拟合。
多层GRU单元框架图,
向我们的网络中添加第二层是非常直接的,我们(再次)只需要修改正向传播计算和初始化函数。代码如下,
# GRU Layer 1
z_t1 = T.nnet.hard_sigmoid(U[0].dot(x_e) + W[0].dot(s_t1_prev) + b[0])
r_t1 = T.nnet.hard_sigmoid(U[1].dot(x_e) + W[1].dot(s_t1_prev) + b[1])
c_t1 = T.tanh(U[2].dot(x_e) + W[2].dot(s_t1_prev * r_t1) + b[2])
s_t1 = (T.ones_like(z_t1) - z_t1) * c_t1 + z_t1 * s_t1_prev
# GRU Layer 2
z_t2 = T.nnet.hard_sigmoid(U[3].dot(s_t1) + W[3].dot(s_t2_prev) + b[3])
r_t2 = T.nnet.hard_sigmoid(U[4].dot(s_t1) + W[4].dot(s_t2_prev) + b[4])
c_t2 = T.tanh(U[5].dot(s_t1) + W[5].dot(s_t2_prev * r_t2) + b[5])
s_t2 = (T.ones_like(z_t2) - z_t2) * c_t2 + z_t2 * s_t2_prev
4.4 性能分析
过去我有一个问题,所以我想澄清一下,我在这里展示的代码效率并不高。它的优化是为了清楚起见,并且主要是用于教育。使用该模型可能足够好,但你不应该在生产环境中使用它,或者希望使用它来训练大型数据集。有很多技巧可以优化RNN的性能,但也许最重要的是将您的更新进行批处理。您不需要一次从一个句子中学习,您可以对相同长度的句子进行分组(或者甚至将所有句子填充到相同的长度),然后对整个批次执行大矩阵乘法和计算梯度。这是因为,大的矩阵乘法可以被GPU有效地处理。如果不这样做,我们可以从使用GPU得到一点加速,并且训练可能非常慢。
所以,如果你想训练一个大模型,我强烈建议使用一个现有的深度学习库,它们都是针对性能进行了优化。使用上述代码需要几天/几周进行训练模型,使用这些库只需要几个小时。我个人喜欢Keras,它使用起来非常简单,并附有很多RNN的例子。
5 结果
为了缓解你需要花费很多天训练一个模型的痛苦,我训练了一个非常类似于 利用Python,Theano实现RNN 的模型。词汇表大小为8000,将词映射到48维向量,并使用了两个128维GRU层。 iPython笔记 中包含加载模型的代码,以便您可以玩它,修改它,并使用它来生成文本。
以下是网络输出的几个很好的例子(由我添加的大小写)。
- I am a bot , and this action was performed automatically .
- I enforce myself ridiculously well enough to just youtube.
- I’ve got a good rhythm going !
- There is no problem here, but at least still wave !
- It depends on how plausible my judgement is .
- ( with the constitution which makes it impossible )
在多个时间步长中观察这些句子的语义依赖关系是非常有趣的。例如,机器人和自动明显相关,开启和关闭括号也是如此。我们的网络能够学到,很酷!
6 Reference
RECURRENT NEURAL NETWORK TUTORIAL, PART 4 – IMPLEMENTING A GRU/LSTM RNN WITH PYTHON AND THEANO
Recurrent Neural Network系列4--利用Python,Theano实现GRU或LSTM的更多相关文章
- Recurrent Neural Network系列2--利用Python,Theano实现RNN
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 本文翻译自 RECURRENT NEURAL NETWORKS T ...
- Recurrent Neural Network系列3--理解RNN的BPTT算法和梯度消失
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 这是RNN教程的第三部分. 在前面的教程中,我们从头实现了一个循环 ...
- Recurrent Neural Network系列1--RNN(循环神经网络)概述
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 本文翻译自 RECURRENT NEURAL NETWORKS T ...
- 机器学习: Python with Recurrent Neural Network
之前我们介绍了Recurrent neural network (RNN) 的原理: http://blog.csdn.net/matrix_space/article/details/5337404 ...
- Recurrent Neural Network(循环神经网络)
Reference: Alex Graves的[Supervised Sequence Labelling with RecurrentNeural Networks] Alex是RNN最著名变种 ...
- Recurrent Neural Network(递归神经网络)
递归神经网络(RNN),是两种人工神经网络的总称,一种是时间递归神经网络(recurrent neural network),另一种是结构递归神经网络(recursive neural network ...
- Recurrent Neural Network[survey]
0.引言 我们发现传统的(如前向网络等)非循环的NN都是假设样本之间无依赖关系(至少时间和顺序上是无依赖关系),而许多学习任务却都涉及到处理序列数据,如image captioning,speech ...
- 课程五(Sequence Models),第一 周(Recurrent Neural Networks) —— 1.Programming assignments:Building a recurrent neural network - step by step
Building your Recurrent Neural Network - Step by Step Welcome to Course 5's first assignment! In thi ...
- Sequence Models Week 1 Building a recurrent neural network - step by step
Building your Recurrent Neural Network - Step by Step Welcome to Course 5's first assignment! In thi ...
随机推荐
- 依赖lean cloud的注册与登录
前言 实现登录注册的基本功能,没有添加手机验证和邮箱验证的功能,有相应的方法,如果需要,可以自己加上其相应的方法 github的网址: 效果图: 正文 1.导入leancloud相应的第三方,这个等我 ...
- static的加载先后顺序
1.静态变量的声明和赋值是分开的,静态变量会先被声明,赋值操做被放在了静态代码块中. 2.静态变量的赋值和静态代码块的执行顺序和代码的先后书写顺序相关. 3.静态代码块优先执行,其次构造方法,最后普通 ...
- simple-spa 一个简单的单页应用实例
上两篇文章说过要写一个简单的单页应用例子的, 迟迟没有兑诺, 实在有愧 哈哈.这篇写给小白用户哈. 正好趁今天风和日丽,事情不多, 把从项目里的代码扣取了一下, 整理了一个简单的例子.因为我们生产项目 ...
- 使用阿里云的Maven仓库加速Spark编译过程
前言 在国内编译Spark项目需要从Maven源下载很多依赖包,官方源在国内大环境下的下载速度大家都懂得,那个煎熬啊,简直是浪费生命. 如果你的下载速度很快,你现在就可以无视这篇文章了. 阿里云给国内 ...
- centos 把网卡名称修改为 eth0
默认网卡名称是 eno16777736 1.修改配置文件 ifcfg-eno16777736 [root@localhost ~]# cd /etc/sysconfig/network-scripts ...
- 《剑指offer》— JavaScript(18)二叉树的镜像
二叉树的镜像 题目描述 操作给定的二叉树,将其变换为源二叉树的镜像. 相关知识 二叉树的镜像定义: 源二叉树 镜像二叉树 思路 有关二叉树的算法问题,一般都可以通过递归来解决.那么写一个正确的递归程序 ...
- C# 控制台倒计时
年前经常聊天的大佬群里有人写了窗体的倒计时来计算下班时间和放假时间:) 简直就是在嘲讽我这种没有工作的人,哈哈哈 窗体的倒计时相当的没有技术含量,主要是不够炫酷,不能够体现我们程序员的身份. 那什么才 ...
- Ansible详解(二)
Ansible系列命令 Ansible系列命令有如下: ansible:这个命令是日常工作中使用率非常高的命令之一,主要用于临时一次性操作: ansible-doc:是Ansible模块文档说明,针对 ...
- dns服务搭建
DNS 是域名系统 (Domain Name System) 的缩写,它是由解析器和域名服务器组成的. 域名服务器是指保存有该网络中所有主机的域名和对应IP地址,并具有将域名转换为IP地址功能的服务器 ...
- Java源码ExtJS 5 SpringMVC 4Hibernate 4通用后台管理开发框架
需要源码,请加QQ:858-048-581 一.特色1.采用Spring MVC的静态加载缓存功能,在首页将Javascript文件.CSS文件和图片等静态资源文件加载进来放进内存,极大提高ExtJS ...