BST性能分析&改进思路——平衡与等价
- 极端退化
前面所提到的二叉搜索树,已经为我们对数据集进行高效的静态和动态操作打开了一扇新的大门。正如我们所看到的,BST从策略上可以看作是将之前的向量(动态数组)和链表结构的优势结合起来,不过多少令我们有些失望的是:目前所实现的BST还有些稚嫩,表现在它的时间复杂度在极端情况仍未得到有效的控制。根据之前的内容,我们知道无论静态or动态操作,它的时间上界都正比于树的高度,即O(h),不过到目前为止,我们对于它的高度还没有任何有效的控制方法。比如说,我们假设所有子节点个数都<=1,那么整棵树将会退化为一条单链,此时从逻辑结构上看,它就等价为一个链表。
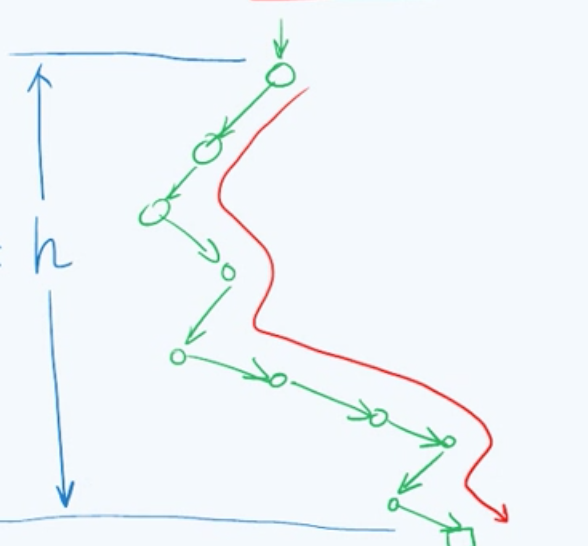
那么树的高度h与节点数n则呈线性关系,也就是O(n)=n-1=h。这无论做渐进分析还是最坏分析,静态操作和动态操作都需要高达O(n)的时间。
- 平均高度
从客观角度,我们还需要对BST的性能做系统分析。下面从两种统计口径分别给出针对BST平均高度的估算结果。
1.随机生成
对于任意生成的一组关键码词条,长度为n,考虑所有可能的排列,比如n=3的情况。会得到这些形态的树:
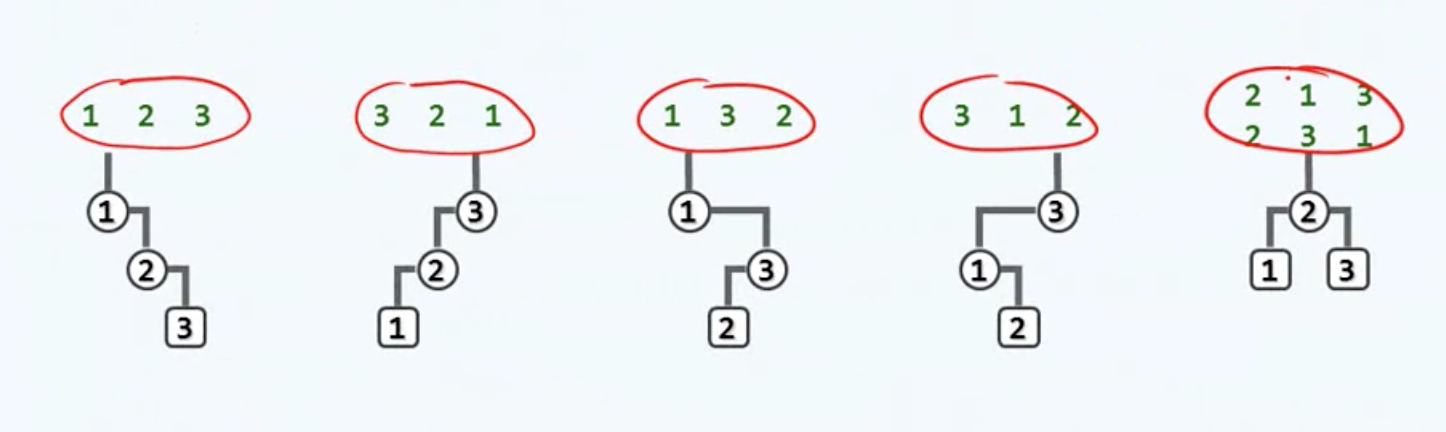
这样创建的方式被称为随机生成,当词条长为n时,一共就是n!种可能,平均高度为O(logN)。
2.随机组成
也就是我们将所有n个关键码视作n个互异的积木,在满足BST规则的前提下,考察他们总共能够拼出多少种拓扑结构互异的BST。可以证明这样得出的总数为Catalan(n),是我们熟知的卡特兰数,组合数学里讲过。这时候平均高度为O(√N)。
那这两种口径得到的结果不一样,到底哪种更为可信呢?对比一下

我们认为,后者更可信,原因在于前者是有所重复的,这种重复性就体现在不同的关键码序列有可能会生成同一棵BST,比如对于n为3的情况而言,这样两个输入序列所生成的都是这样同一棵BST。
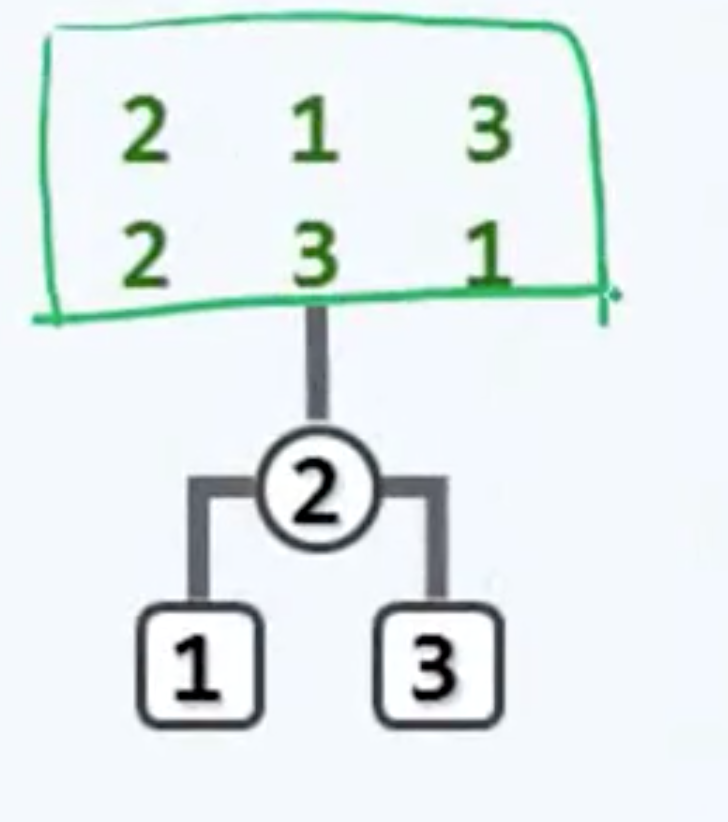
也就是说只要第一个插入的是居中的2,那么分列于它左右的1和3究竟是按什么次序输入是没有关系的。实际上不难理解,这个结论可以进一步地推广,也就是说中位数,或者接近于中位数的关键码越是被更早地插入,整体而言,这棵BST的高度也相应地会更低。这就意味着在前一种统计口径中。
这类高度更低的BST,将会被以更高的重复度参与统计以及最终的平均估算。这也是为什么按照前一统计口径所得到的估算值会相对更小。从这一观点来看,前一统计口径可以说是过于乐观了,而后一统计口径所得到的结论将更为可信。但对于在此非常在意树高的我们来说,这并不是一个好消息,这意味着在天然的随机意义下,这样一个高度是超出我们承受范围的,为了进一步地降低和控制这个高度,我们应该采取措施。
- 理想+适度
为了控制树的高度,我们或许首先应该弄明白:什么样的树相对而言高度是更低的。根据之前的例子,在节点数目相对固定时,左右兄弟子树的高度越是接近,全树通常也会更加倾向于高度更低。也就是说——全树越是接近于平衡,那么它的高度也会倾向于更低。因此我们可以通过控制全树的平衡度,以控制全树的高度。关于树的高度 我们有这样一个结论,由n个节点所组成的二叉树,其高度最低不会少于log 2为底n的对数。

因此如果某棵树的高度能够达到这样一个理想的下限,我们也称之为理想平衡的。那么哪些树能够达到这样的理想平衡状态呢?你应该会联想起我们此前所讲过的——完全二叉树( Complete Binary Tree)。
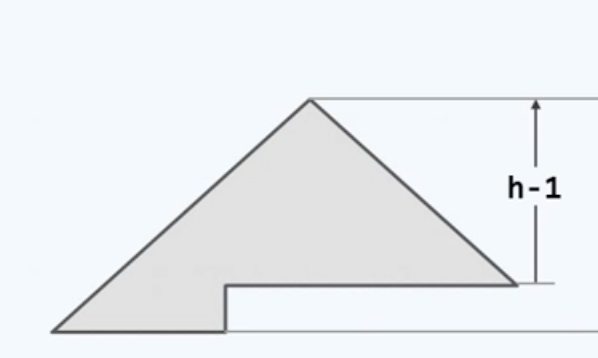
是的,在这样的树中,叶节点只能出现在最底层以及次底层。当然 其中最好最好不过的自然是所谓的满二叉树( Full Binary Tree)。
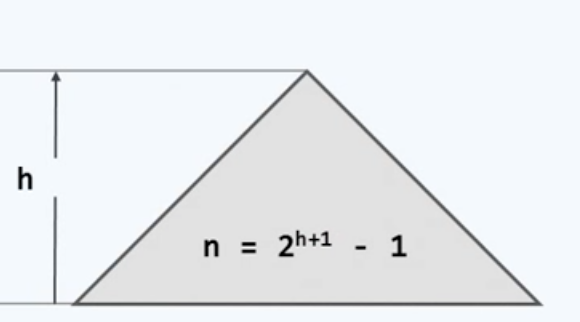
然而很遗憾——这样的树在实际应用中只能是可遇不可求的。
而且即便BST在某一个时刻,能够达到这样高度紧凑的形式,在接下来的动态操作过程中这样一种完美的形式也是难以持续的。因此所谓的理想平衡,在实际应用中是不具任何意义的,理想平衡出现的可能性,非常非常的低。而且为了维护这样的理想平衡,我们的计算成本也相应地会十分的高昂,会得不偿失。

而真正可行的方法是,我们或许应该适度地放松平衡的标准,没错 适度地放松。你或许会联想起我们此前的渐近分析,没错,那正是我们的一个法宝。实际上只要能够保证全树的高度,能够从渐近的意义而言不超过logN,那么也就可以称之为是平衡的了。

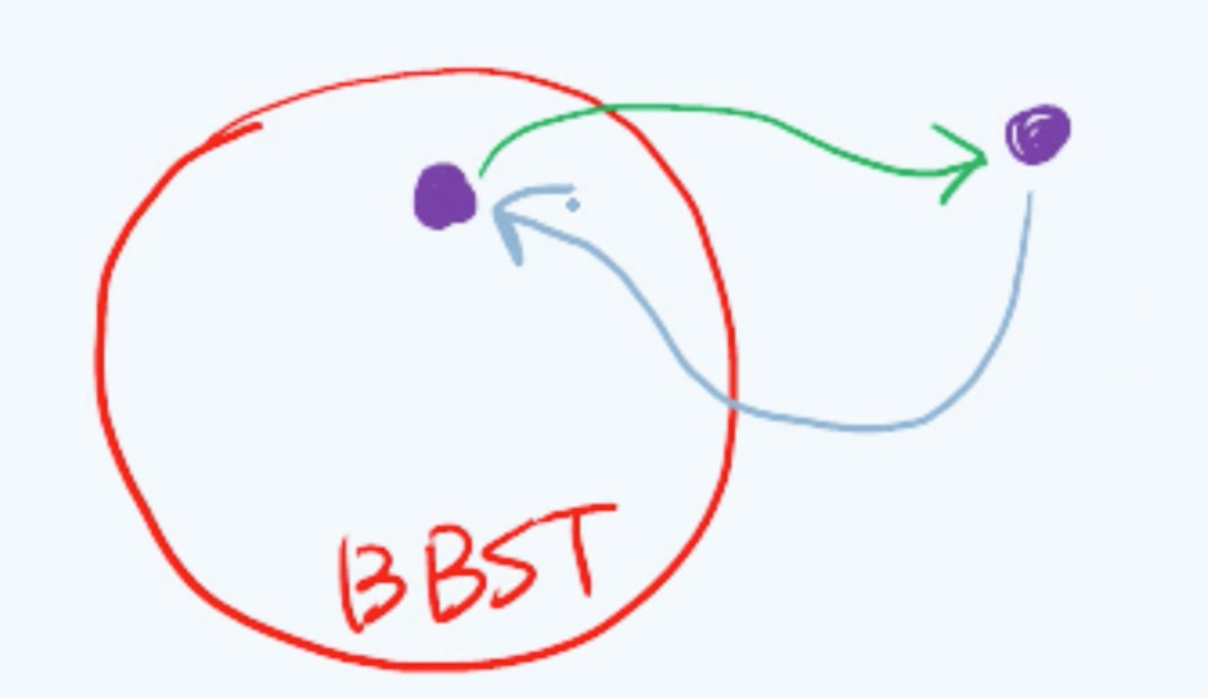
因为这种平衡并非严格意义上的理想平衡,所以我们也不妨称之为适度平衡。这样一种适当的放松,但又不失原则的方法,也就是我们通常所谓的退一步海阔天空。那么相应地——能够保持适度平衡的BST,也称作平衡的二叉搜索树(Balanced Binary Search Tree),简称BBST。也就是说,如果将所有的BST视作一个全集,那么BBST只是其中的一个子集。对于目前而言其中任何一棵BBST,如果经过某次操作之后它不再保持适度平衡。也就是——会游离到这个子集之外,果真如此的话我们就需要有一整套方法将这棵BST重新拉回到这个子集中,使它重新成为一棵BBST。像这样:
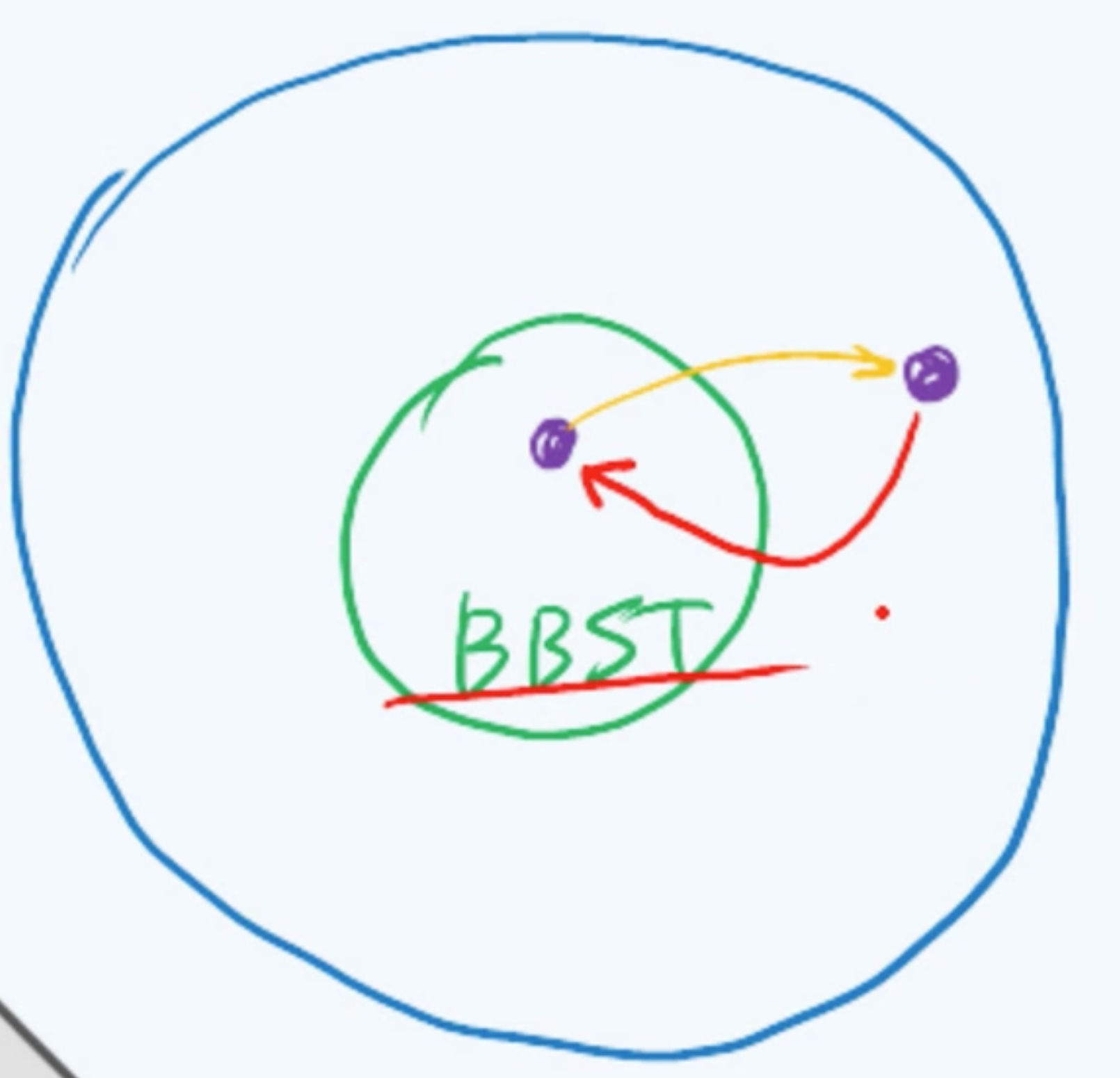
那么我们应该采用什么样的一些方法来做到这一点呢?或者先退一步,我们来考虑一下:我们可能采用哪些方法呢?
概括而言,所有这些方法都必须是所谓的等价变换。
- 歧义=等价
所谓BST,它的本质特征,就是处处局部的顺序性、以及全局的单调性。具体来说——只需要考察它的中序遍历序列是否是单调的。然而只需考察树的遍历算法,我们就不难发现:结构不相同的两棵BST的中序遍历序列有可能是完全雷同的,这也就是我们所说的中序遍历序列的歧义性。在某些场合中,比如中缀表达式的求值计算。这种中序遍历序列的歧义性非常令人生厌,因为我们不得不通过一些办法,来明确地辨析不同操作符之间的优先级关系。而针对BBST这样的一个问题,歧义性却变成了一个非常重要同时也是不可或缺的一种性质。
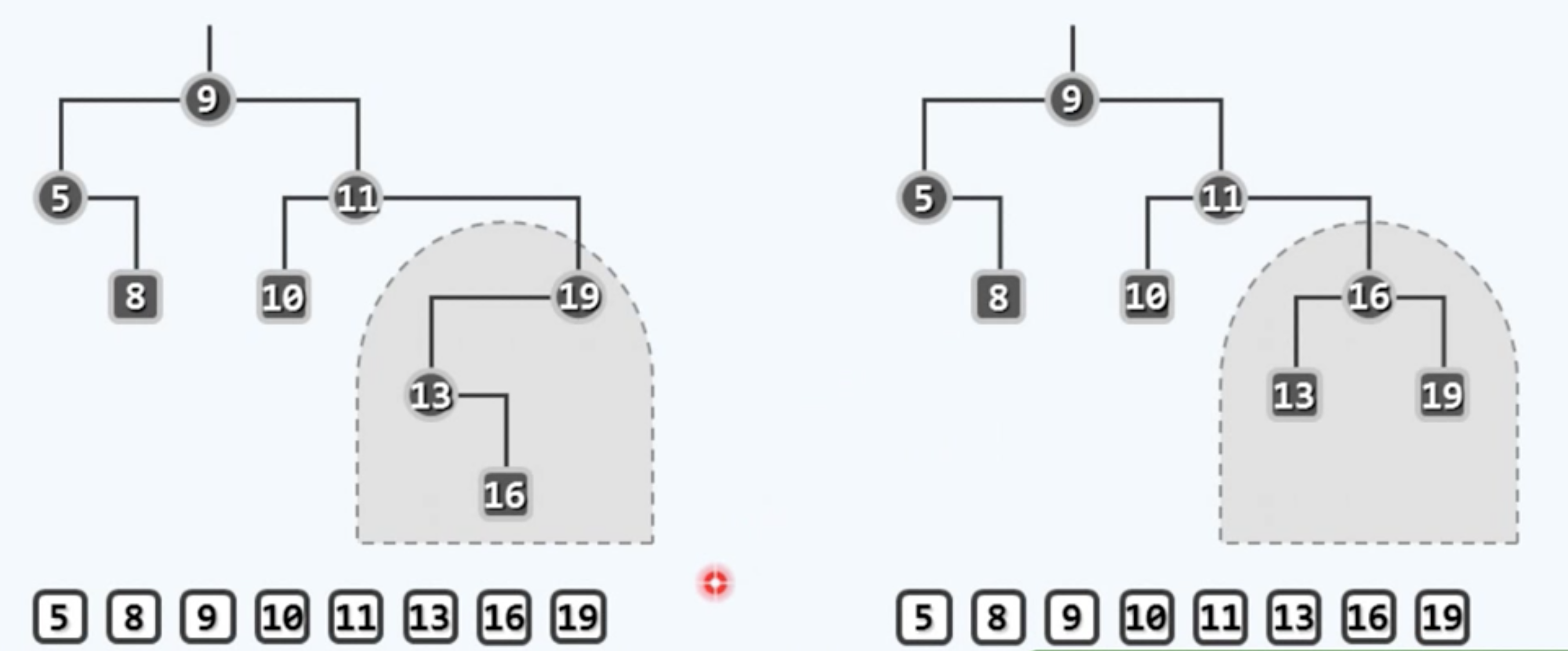
以这里所给出的两棵BST为例,不难看出它们都是由同一组关键码所构成的,而且它们的中序遍历序列是完全一样的,然而反过来 我们也注意到,它们的拓扑结构也不尽相同。左侧局部子树的树根是19,而在右侧却是16。当然,还可以很容易地举出更多拓扑结构不尽相同,但中序遍历序列却相同的实例。任何一对这样的BST也就称作相互等价的BST。等价的BST之间在拓扑结构上虽然不尽相同,但也有其独特的规律。
这种规律概括起来有两句话:

第一:“上下可变”比如在这个例子中19和16的祖先和后代关系就有可能在两棵树中彼此颠倒。这也可以认为等价的BST在垂直方向有一定的自由度。然而我们的第二条规律则是“左右不能乱”,这里的左右自然是指中序遍历序列。确实相对于任何一个节点,居于它右侧的节点以及居于它左侧的节点之间不能相互混淆。那么在这样一种上下存在一定的调整余地,但左右次序却不得颠倒的规则下又该如何来实现BST之间的等价转换呢?
- 等价变换
实际上对于任何一棵BST之间的等价转换,都可以视作是由一系列的基本操作串接而成的,而这种基本的变换无非两类 彼此对称,其中一类如这个图所示:
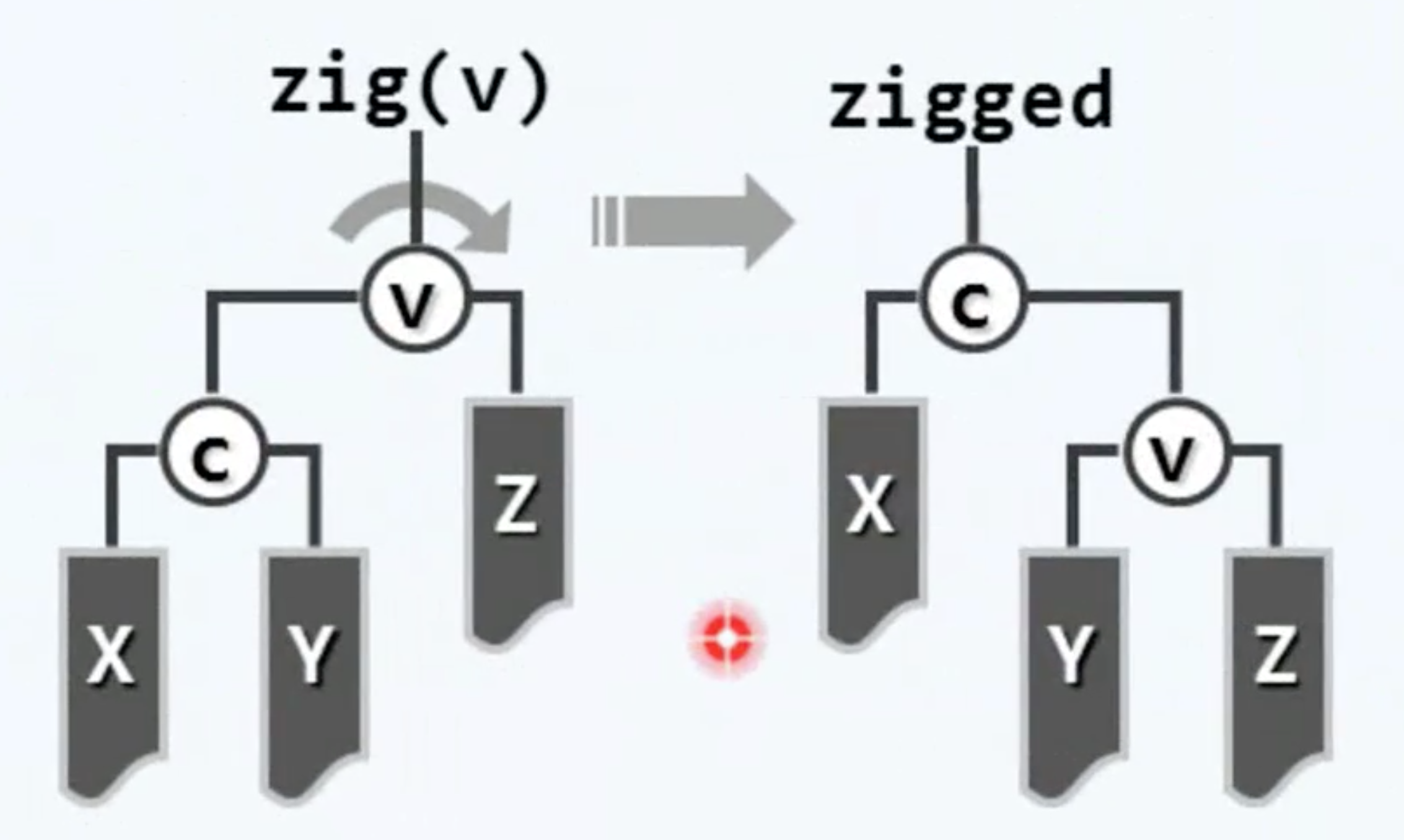
也就是说 如果节点V拥有一个左孩子C,而且它们属下分别有三棵,在此命名为X Y Z的子树,我们只需将这局部的两个节点以及三棵子树重新调整为这样一种拓扑连接的形式。那么无论是在此局部,还是在它们所属的那棵全树,顺序性和单调性将依然保持。也就是说 全树依然将是一棵BST。为了对此做一验证,我们不妨来考察在此局部的中序遍历次序——我们可以看到:无论是在变换之前 还是变换之后,在此局部的中序遍历序列的次序必然是X C Y V 以及最后的Z。从效果来看 这样一个变换,可以大致理解为是在此局部围绕着节点V,做了一个顺时针的旋转。称这种变换为zig。那么这种旋转的中心V——则是zig的参数。
下面则是完全对称的另一种基本操作:
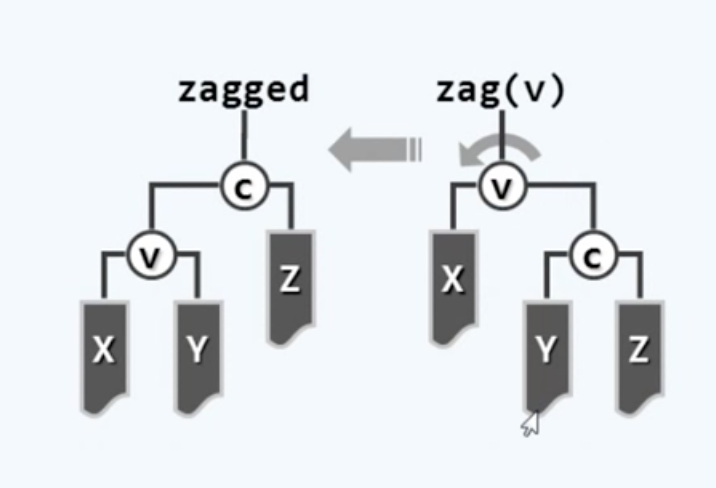
因为它可以理解为是围绕着节点V做了一次逆时针的旋转操作,我们也形象地称之为zag。在后续的章节中 我们将会看到包括AVL树、 红黑树在内的各种BBST都分别精心地定义了某种适度平衡的准则,从而使得原本在其中的任何一棵BBST即便在经过某次操作之后,会暂时地游离到这个边界之外,我们也总是能够通过一系列精巧地等价变换令它重新回到这个边界以内,并重新成为一棵BBST。
而在设计所有这些等价变换的组合时,我们始终不要忘了应该遵循两个重要的准则:一个就是所谓的局部性。也就是说,我们执行的每一次等价变换都应该局限在某一常数规模的局部。比如对于我们刚刚介绍的zig和zag操作而言,它们都局限在局部的V和C两个节点处。
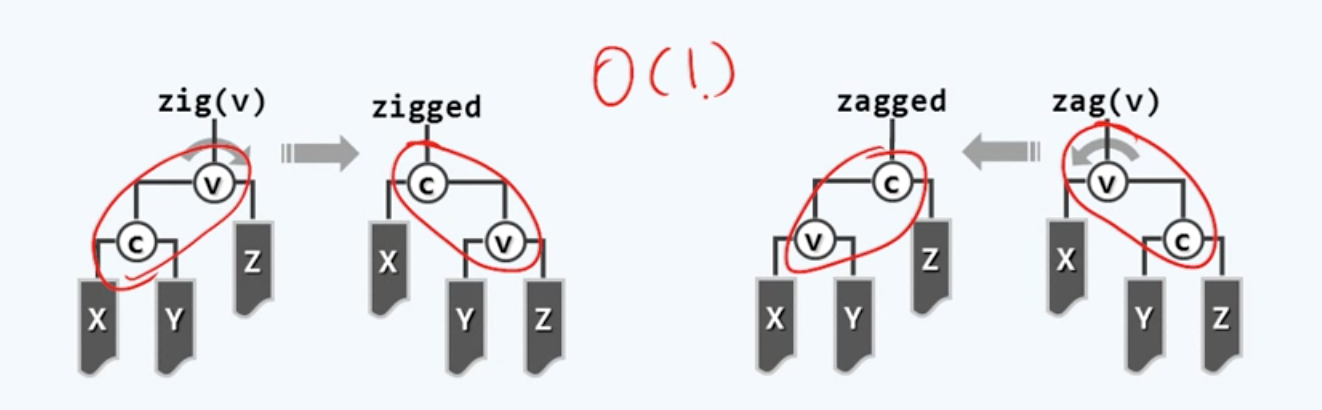
如此一来它们所牵涉到的节点总数既然是常数,这类操作所需要的计算时间也可以严格地控制在常数的规模。
第二个需要严格遵守的是:在我们将一棵刚刚失衡的BBST重新恢复为一棵BST的过程中,累计需要执行的旋转次数不要过多。比如至多不能超过logN次,这样我们就可以有效地控制整个操作序列的长度、以及总体所需要的时间。后面我们会看到 任何一种BBST都必须至少满足这样一个logN的基本条件。但是在进一步的要求上,它们各自又有所差异——比如对于AVL树而言,它的删除操作只能刚刚达到这个及格线,而它的插入操作却可以优化到常数。而我们在后面的后面将要介绍的红黑树,也就是Red Black Tree则可以进一步地将这两种操作的性能同时提升到最优的常数。那么接下来的一节,我们就首先来看看,AVL树是如何达到这样一个及格线的。
BST性能分析&改进思路——平衡与等价的更多相关文章
- DevTools 实现原理与性能分析实战
一.引言 从 2008 年 Google 释放出第一版的 Chrome 后,整个 Web 开发领域仿佛被注入了一股新鲜血液,渐渐打破了 IE 一家独大的时代.Chrome 和 Firefox 是 W3 ...
- Linux性能分析:生产环境服务器变慢,诊断思路和性能评估
Linux性能分析:生产环境服务器变慢,诊断思路和性能评估 一.整机:top 二.CPU:vmstat 所有CPU核信息 每个进程使用CPU的用量分解信息 三.内存:free 四.硬盘:df 五.磁盘 ...
- Redis性能分析思路
Redis性能分析有几个大的方向.分别是 (1)基准对比 (2)配置优化 (3)数据持久化 (4)键值优化 (5)缓存淘汰 (6)Redis集群 基准对比 在没有业务实例运行的情况下,在服务器上通过测 ...
- 高性能Linux服务器 第10章 基于Linux服务器的性能分析与优化
高性能Linux服务器 第10章 基于Linux服务器的性能分析与优化 作为一名Linux系统管理员,最主要的工作是优化系统配置,使应用在系统上以最优的状态运行.但硬件问题.软件问题.网络环境等 ...
- MySQL性能分析(转)
第一步:检查系统的状态 通过操作系统的一些工具检查系统的状态,比如CPU.内存.交换.磁盘的利用率.IO.网络,根据经验或与系统正常时的状态相比对,有时系统表面上看起来看空闲,这也可能不是一个正常的状 ...
- .NET内存性能分析宝典
.NET Memory Performance Analysis 知道什么时候该担心,以及在需要担心的时候该怎么做 译者注 **作者信息:Maoni Stephens ** - 微软架构师,负责.NE ...
- linux系统性能调优第一步——性能分析(vmstat)
linux系统性能调优第一步--性能分析(vmstat) 分类: LINUX 性能调优的第一步是性能分析,下面从性能分析着手进行一些介绍,尤其对linux性能分析工具vmstat的用法和实践进行详细介 ...
- 常用排序算法的python实现和性能分析
常用排序算法的python实现和性能分析 一年一度的换工作高峰又到了,HR大概每天都塞几份简历过来,基本上一天安排两个面试的话,当天就只能加班干活了.趁着面试别人的机会,自己也把一些基础算法和一些面试 ...
- MySQL优化 - 性能分析与查询优化
优化应贯穿整个产品开发周期中,比如编写复杂SQL时查看执行计划,安装MySQL服务器时尽量合理配置(见过太多完全使用默认配置安装的情况),根据应用负载选择合理的硬件配置等. 1.性能分析 性能分析包含 ...
随机推荐
- 0_Simple__asyncAPI
关于CPU - GPU交互的简单接口函数. ▶ 源代码: // includes, system #include <stdio.h> // includes CUDA Runtime # ...
- 用git上传本地文件到github
1.在自己的github账号下新建仓库--------得到github仓库地址 2.本地安装git---在将要克隆的文件夹下 右击点击Git Bash Here 3.输入命令 $ git clone ...
- eclipse使用maven tomcat插件部署无法关联源代码
一. 安装sourcelookup插件: 二. 在source lookup path里加入源码: 2.1) 加入项目源码或整个工作空间的源码(不加上连自己的代码都无法查看,默认是不加上的) 2.2) ...
- display: run-in
If a sibling block box (that does not float and is not absolutely positioned) follows the run-in box ...
- [java基础] 遇到的一个关于返回值泛型的问题
在写代码的时候这样写: import java.util.ArrayList; import java.util.List; public class TestConversion { public ...
- linux mysql无故无法启动了,centos 7
转自: http://support.moonpoint.com/software/database/mysql/not-running-centos7.php 下面简单翻译一下. 详细内容可以阅读英 ...
- QT中槽的使用
一.建立槽和按钮之间的连接 connect(信号发送者,发送的信号,信号接收者,信号接收者的槽函数) 1.例子 connect(ui->pushButton,SIGNAL(clicked(boo ...
- PHP基础入门(三)【PHP中的数组】
PHP数组的分类 按照下标的不同,PHP数组分为关联数组与索引数组: 索引数组:下标从0开始,依次增长: 关联数组: 下标为字符串格式,每个下标字符串与数组的值一一关联对应.(有点像对象的键值对) 关 ...
- 如何在RHEL7上搭建Samba服务实现Windows与Linux之间的文件共享
如何在RHEL7上搭建Samba服务实现Windows与Linux之间的文件共享 实现环境:VMware workstations.RHEL7.0 第一步:配置网卡IP及yum软件仓库 命令:vim ...
- 几种文件查找命令,whereis ,find ,locate.
whereis对于文件的查找,是将系统内的所有文件放在一个数据库文件里.whereis 和 locate 都是以该数据库为准的(由于每个数据库会有一个更新时间,一般在更新时间之后才可以找到).而fin ...