如何理解 Python 的赋值逻辑
摘要:
如果你学过 C 语言,那么当你初见 Python 时可能会觉得 Python 的赋值方式略有诡异:好像差不多,但又好像哪里有点不太对劲。
本文比较并解释了这种赋值逻辑上的差异。回答了为什么需要这种赋值逻辑以及如何使用这种赋值逻辑的问题。
当然,即使未学过 C 语言,也可通过本文更好地了解 Python 的赋值逻辑——这种赋值逻辑影响着 Python 的方方面面,从而可以让你更好地理解和编写 Python 程序。
第一章 引例
先来看一组似乎矛盾的代码:
# 代码 1
>>> a = 3
>>> b = a
>>> b = 5
>>> a
3
这看上去似乎很好理解。第二步中, a 只是把值复制给 b,然后 b 又被更新为 5,a 和 b 是两个独立的变量,那么 a 的值当然不会受到影响。
真的是这样吗?
再来看一段代码:
# 代码 2
>>> a = [1, 2, 3]
>>> b = a
>>> b[0] = 1024
>>> a
[1024, 2, 3]
第二步中,a 只是复制把列表复制给 b,然后更新 b[0] 的值,最后输出 a,可是 a 竟然也被改变了。
按照代码 1 的逻辑(即变量之间独立),代码 2 的中的 a 不应该受到影响。
为什么出现了这样的差异?
第二章 Python 的“反直觉”
先不解释上面那个“看似矛盾”的问题。
先来看看另一组简单的 Python 代码在内存中是什么样子的:
# 代码 3
b = 3
b = b + 5
它在内存中的操作示意图是这样的:
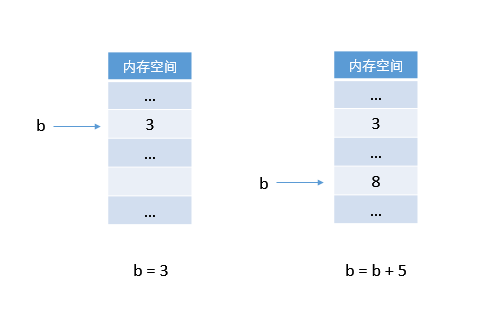
然而,从代码的的字面意思上看,“把 3 赋给 b,把 b 加 5 之后再赋给 b。”
也就是把代码看成这个样子:
b ← 3
b ← b + 5
所以下面这张在内存中的操作图可能更符合我们的直觉:
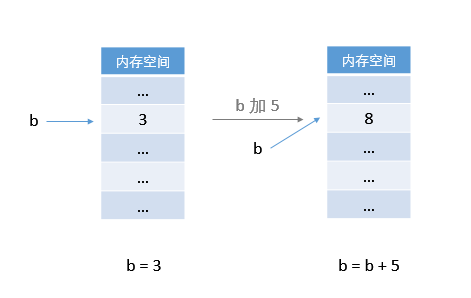
也即 b + 5 的值又写回到 b 中。典型的 C 程序就是这样的。为变量 b 分配一个 int 型的内存单元,然后将整数 3 存放在该内存单元中。b 就代表了该块内存空间,不再移动,可以更新 b 的值,但 b 在内存中的地址就不再变化了。所以我们说 b = b + 5,就等于 b ← b + 5,把 b 的值加 5 之后还依然放入 b 中。 变量 b 和它所在内存空间紧紧绑定在一起,人形合一。
而再看看上面 Python 中的内存示意图,b + 5 得到了一个新值,然后令 b 指向了这个新值。换句话说,它做的是事情是这样的:
b → 3
b → b + 5
先令 b 指向 3,再令 b 指向 b + 5 这个新值。
C 程序更新的是内存单元中存放的值,而 Python 更新的是变量的指向。
C 程序中变量保存了一个值,而 Python 中的变量指向一个值。
如果说 C 程序是通过操纵内存地址而间接操作数据(每个变量固定对应一个内存地址,所以说操纵变量就是操纵内存地址),数据处于被动地位,那么 Python 则是直接操纵数据,数据处于主动地位,变量只是作为一种引用关系而存在,而不再拥有存储功能。
在 Python 中,每一个数据都会占用一个内存空间,如 b + 5 这个新的数据也占用了一个全新的内存空间。
Python 的这种操作让数据成为主体,数据与数据之间直接进行交互。
而数据在 Python 中被称为对象 (Object)。
这句话并不太严谨。不过在这个简单的例子中是成立的。
一个整数 3 是一个 int 型对象,一个 'hello' 是一个字符串对象,一个 [1, 2, 3] 是一个列表对象。
Python 把一切数据都看成「对象」。它为每一个对象分配一个内存空间。 一个对象被创建后,它的 id 就不再发生变化。
id 是 identity 的缩写。意为“身份;标识”。
在 Python 中,可以使用id(),来获得一个对象的 id,可以看作是该对象在内存中的地址。
一个对象被创建后,它不能被直接销毁。因此,在上个例子中,变量 b 首先指向了对象 3,然后继续执行 b + 5,b + 5 产生了一个新的对象 8,由于对象 3 不能被销毁,则令 b 指向新的对象 8,而不是用对象 8 去覆盖对象 3。在代码执行完成后,内存中依然有对象 3,也有对象 8,变量 b 指向了对象 8。
如果没有变量指向对象 3(即无法引用它了),Python 会使用垃圾回收算法来决定是否回收它(这是自动的,不需要程序编写者操心)。
一个旧的对象不能被覆盖,因旧的对象交互而新产生的数据会放在新的对象中。也就是说每个对象是一个独立的个体,每个对象都有自己的“主权”。因此,两个对象的交互可以产生一个新的对象,而不会对原对象产生影响。在大型程序中,各个对象之间的交互错综复杂,这种独立性则使得这些交互足够安全。
C 程序为每个变量都分配一个了固定的内存地址,这保证了 C 变量之间的独立性。
C 语言是变量(也即内存地址)之间的交互,Python 是对象(数据)之间的交互。这是两种不同的交互方式。
那么,Python 这种数据之间直接进行交互的好处体现在哪里?
很遗憾,这并不是本文所要讨论的内容,该部分属于面向对象设计的核心内容。本文只是对 Python 的这种交互方式与 C 语言的交互方式做了一些比较,以区分两者在逻辑与物理上的差异所在。
相信这种逻辑会帮助你更好地编写 Python 程序,并且帮助你在日后更加深入地理解面向对象的程序设计。
本章补充:
Python 的赋值更改的是变量的指向关系,因此,对于 Python,从前向后阅读一个赋值表达式会更加容易理解。
// C 语言
b ← b + 5 // 把 b+5 的值赋给 b
# Python
b → b + 5 # 令 b 指向 b + 5
第三章 回答第一章的问题
先看代码 1:
# 代码 1
>>> a = 3
>>> b = a
>>> b = 5
>>> a
3
Python 中所有的数据都是对象,数字类型也不例外。3 是一个 int 类型的对象,5 也是一个 int 型的对象。
第一行,a 指向对象 3。
第二行,令 b 也指向 a 所指向的对象 3。
第三行,因为对象不可被覆盖(销毁),令 b 指向新对象 5,则只剩下 a 指向对象 3。
第四行,输出 a,得到 3。
在内存中的操作示意图 (Python):
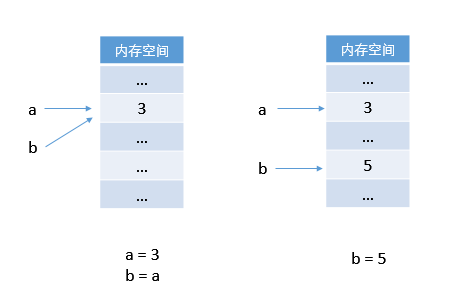
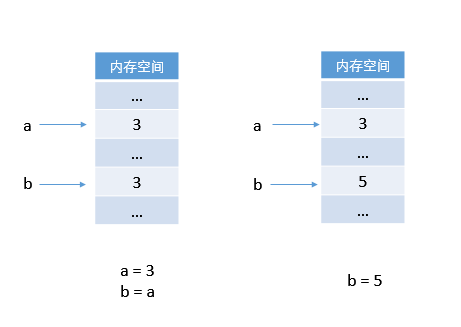
这与第一章中的解释完全不同,第一章中的解释是用 C 语言解释的:
这是两种完全不一样的机制。
Python 中 b 首先指向了对象 3,然而因为对象之间的独立性,一个对象不能去覆盖另一个对象,则令 b 指向对象 5,而不是将对象 3 在内存中替换为对象 5。
再来看代码 2:
# 代码 2
>>> a = [1, 2, 3]
>>> b = a
>>> b[0] = 1024
>>> a
[1024, 2, 3]
第一行,令 a 指向一个列表 [1, 2, 3];
第二行,令 b 也指向 a 所指向的列表;
第三行,令 b[0] = 1024,1024 虽然是一个对象,但它并没有试图覆盖b所指向的对象,而是对该对象的第一个元素进行修改。修改,而不是覆盖,所以它可以原对象进行操作,而不是令 b 指向修改后的对象。
所在第四行输出的 a 所指向的列表也发生了变化。
在内存中的操作示意图 (Python):
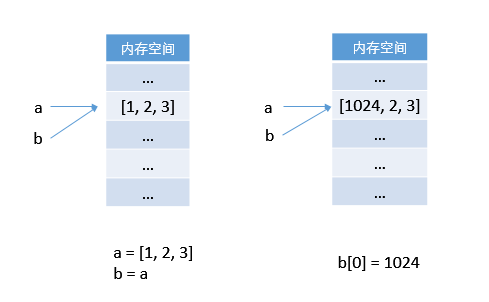
这种对象的值可以修改的对象被称为可变对象 (immutable object)。常见的列表、字典为可变对象。
因为它的值可以被修改,因此如果有多个变量指向该列表:
a = [1, 2, 3]
b = a
c = a
d = a
...
那么使用 b, c, d, ... 的任何一个变量都能访问该对象并修改其中的内容。这种特性常常被我们用于函数的参数传递,如果函数的参数是可变对象,那么函数可以对“实参”中的内容进行修改:
>>> a = [1, 2, 3]
>>> def change(t):
t[0] = 1024
>>> change(a)
>>> a
[1024, 2, 3]
>>>
调用函数 change 时,令 t 也指向了 a 所指向的列表,然后使用 t 更改了列表中的第一个元素,更改,而不是覆盖,因此对 t 所指向的对象的更改也改变了“实参” a 所指向的对象。而 C 语言则因为实参到形参是值传递,则无法改变实参的内容(虽然借助指针可以实现,但这里只说一般情况下)。
但在函数以外的区域,我们要尽量避免这样使用,这很容易导致出错(当然,有时候会很有用,这取决于你的程序)。比如,在多人协作编程时,如果甲不小心修改了某可变对象,那么乙、丙、丁等用到该对象的人都会受到影响。
而对于不可变对象 (immutable object),即其值无法更改的对象,传入函数时则不会影响“实参”的值:
>>> a = 5
>>> def add(n):
n = n + 2
>>> add(a)
>>> a
5
调用函数 add 时,令 n 也指向了 a 所指向的对象 5, 再执行 n = n + 2,n 所指向的对象 5 与对象 2 相加得到了一个新的对象 7,由于一个对象不能覆盖另一个对象,则 n 指向新的对象 7,而没有改变原对象。因此 a 的值未发生变化。虽然与 C 程序的结果一致,但与 C 程序的机制完全不同,C 程序之所以没改变 a,是因为调用函数时只发生了值传递,即只把 a 的值复制给了 n。
不要混淆这两种赋值逻辑,它们有着完全不同的物理实现方式。
不同的思维逻辑会导致不同的编写逻辑。尽管这两种逻辑在很多情况下的结果是一致的,但并不能就简单地认为它们是一致的。否则在一些小的细节方面出了错误,就会难以理解。只能死记硬背,把一些东西当作 Python 的特例来记,虽然「唯手熟尔」也可以让你走得很远,但思维正确时,不仅可以走得更远,也会走得更加轻松。
比如,当你的思维清晰时,以下问题的答案自然也就水落石出了:
- 为什么列表的方法的返回值大多是
None? - 为什么字符串的方法的返回值大多是一个新的对象?
- 为什么 Python 中没有自增/自减运算符?
- 为什么有的可变对象传入函数之后,却不能被函数修改“实参”的值?
(比如将上面的change函数的主体改成t = t[1:]。调用函数之后,a所指向的对象并没有发生改变。) - ……
这些内容与本文主题不大相关,所以不再列出答案。
有趣的补充:
1. 数字是一个天然的不可变对象(immutable object)。
对于n = n + 2,有人可能会说,为什么不能把它看成像列表那样的修改,修改后n依然指向的是原对象,这样的话执行add(a)之后,a就会变成7了,可为什么不是这样?
因为每一个数字都是一个单个的对象,而对象不能覆盖对象。所以该句实际上是:a指向的对象加上对象2,产生了一个新的对象,然后令a指向了新对象a + 2。
因此,数字类型并不存在修改这一说,它是一个天然的不可变对象。2. 为什么 Python 中没有自增(++)、自减(--)运算符?
自增或自减运算符,在 C 语言中很常用,简洁实用。但在 Python 中却一定不会有。上节说到,数字是天然的不可变对象,所谓自增就是自身增加,所以它无法自增。它只能从一个对象指向下一个对象。可以这样写a += 1。
3. 既然 Python 更改的只是引用关系,那么如何复制一个列表?
a = [1, 2, 3]
b = a
# 这样做不能复制一个列表,a 和 b 指向的都是列表 [1, 2, 3]
# 答案:
## 1. 使用 list 的 copy 方法
b = a.copy()
## 2. 使用 slice 操作
b = a[:] # slice 操作返回一个新的对象
最后一章 回顾
本文的章节安排是基于便于讲解的内容逻辑。这里给出文章的思维逻辑,以便回顾:
- Python 与 C 语言的赋值逻辑差异
- 一个直接操纵数据,一个间接操纵数据
- 为什么需要这种赋值逻辑
- 帮助实现对象之间的交互
- 对象不可被直接摧毁(覆盖)
- 可以修改可变对象的值
- ……
- 为什么想要对象之间进行交互(面向对象设计的内容)
- 帮助实现对象之间的交互
- 如何使用这种赋值逻辑
- 从左向右阅读/编写一个表达式
- 使用对象交互来设计、理解程序
- 为什么可变对象可以更改“实参”,而不可变对象不可以
- 为什么没有自增/自减运算符
- 需要复制一个可变对象怎么办
- ...
如何理解 Python 的赋值逻辑的更多相关文章
- 深入理解Python中赋值、深拷贝(deepcopy)、浅拷贝(copy)
赋值 python跟java中的变量本质是不一样的,Python的变量实质上是一个指针(int型或str型),而java的变量是一个可操作的存储空间. a = 123b = a print(id(a) ...
- Python中斐波那契数列的赋值逻辑
斐波那契数列 斐波那契数列又称费氏数列,是数学家Leonardoda Fibonacci发现的.指的是0.1.1.2.3.5.8.13.21.34.······这样的数列.即从0和1开始,第n项等于第 ...
- 理解Python中的装饰器
文章先由stackoverflow上面的一个问题引起吧,如果使用如下的代码: @makebold @makeitalic def say(): return "Hello" 打印出 ...
- 理解Python中的装饰器//这篇文章将python的装饰器来龙去脉说的很清楚,故转过来存档
转自:http://www.cnblogs.com/rollenholt/archive/2012/05/02/2479833.html 这篇文章将python的装饰器来龙去脉说的很清楚,故转过来存档 ...
- 理解Python闭包概念
闭包并不只是一个python中的概念,在函数式编程语言中应用较为广泛.理解python中的闭包一方面是能够正确的使用闭包,另一方面可以好好体会和思考闭包的设计思想. 1.概念介绍 首先看一下维基上对闭 ...
- python基础之逻辑题(2)
python基础之逻辑题(2) 1.若k为整数,下列while循环执行的次数为? 2.请输出正确结果-----numbers? 3.求结果-----math? 4.求结果-----sum? 5.输 ...
- 深入理解 Python 异步编程(上)
http://python.jobbole.com/88291/ 前言 很多朋友对异步编程都处于"听说很强大"的认知状态.鲜有在生产项目中使用它.而使用它的同学,则大多数都停留在知 ...
- 一步一步理解 python web 框架,才不会从入门到放弃
要想清楚地理解 python web 框架,首先要清楚浏览器访问服务器的过程. 用户通过浏览器浏览网站的过程: 用户浏览器(socket客户端) 3. 客户端往服务端发消息 6. 客户端接收消息 7. ...
- [转]深刻理解Python中的元类(metaclass)以及元类实现单例模式
使用元类 深刻理解Python中的元类(metaclass)以及元类实现单例模式 在看一些框架源代码的过程中碰到很多元类的实例,看起来很吃力很晦涩:在看python cookbook中关于元类创建单例 ...
随机推荐
- Java 基本语法----关键字、标识符
关键字 关键字的定义和特点 定义:被Java语言赋予了特殊含义,用做专门用途的字符串(单词)特点:关键字中所有字母都为小写 用于定义数据类型的关键字 class interface enum byte ...
- Oracle 10gR2分析函数
Oracle 10gR2分析函数汇总 (Translated By caizhuoyi 2008‐9‐19) 说明: 1. 原文中底色为黄的部分翻译存在商榷之处,请大家踊跃提意见: 2. 原文中淡 ...
- java Script 用if else 实现从大到小指定输出,升序排列
我只是一个小白 各位大神看到不要介意 var a = Number(prompt("请输入你需要排列的第一个数字")) var b = Number(prompt("请输 ...
- Linux Redis 重启数据丢失解决方案,Linux重启后Redis数据丢失解决方
Linux Redis 重启数据丢失解决方案,Linux重启后Redis数据丢失解决方案 >>>>>>>>>>>>>> ...
- Android自动问题——黑屏、死机等解决方法
今天用了下Android Studio,出现了一些问题,现在将启动过程中遇到的问题和解决方案列出来,方便大家参考. 安装过程不多说,网上一搜一大把. 那直接说问题吧: 1. 无法启动,报错:Faile ...
- C++学习(八)入门篇——复合类型
数组(需要声明以下三点): (1)存储在每个元素中值的类型 (2)数组名 (3)数组中的元素数 声明数组的通用格式如下: typeName arrayName[arraySize];arraySize ...
- (转)OGNL表达式介绍
OGNL是Object-Graph Navigation Language的缩写,它是一种功能强大的表达式语言(Expression Language,简称为EL),通过它简单一致的表达式语法,可以存 ...
- MySQL学习笔记(五):MySQL表级锁和行级锁
一:概述 相对其他数据库而言,MySQL的锁机制比较简单,其最显著的特点是不同的存储引擎支持不同的锁机制.比如,MyISAM和MEMORY存储引擎采用的是表级锁(table-level locking ...
- file-API 实现添加图片 预览缩略图(自己学习)
首先看看 "效果图" : 我们最终实现的就是点击右侧的"相机"按钮添加想要添加的图片然后可以根据需要删除(点叉删除本条)或再次添加图片,并显示缩略图....走起 ...
- git for windows+TortoiseGit客户端的使用二
通常都是使用git协议方式来连接服务器,然后使用https方式的连接方法,是如何设置的: 先登录github服务器,获取远程服务器仓库: 在本地创建一个存放仓库的目录,然后使用tortoiseGit客 ...