(转) Redis学习教程--基本命令
原文出自:http://www.cnblogs.com/woshimrf/p/5198361.html
目录
全局操作:
1.redis是key-value存储的,放在内存中,并在磁盘持久化的数据结构存储系统
2.redis提供原子自增操作incr,用来防止多线程并发出现数据错误。
3.删除操作:del.若数据不存在返回(nil)
4.redis可以定时存储,即设置几秒后删除该变量
5.存储有序队列:list
6.无序且唯一集合set
7.有序集合sorted set
8.对象存储Hashes
9.sort排序!
9.1 sort命令描述:
9.2 一般sort用法
9.3 使用alpha修饰符对字符串进行排序
9.4、使用limit修饰符限制返回结果
9.5、使用外部key进行排序
9.6、by选项
9.7、get选项
9.8、获取多个外部键
9.9、获取外部键,但不进行排序
9.10、将哈希表作为get或by的参数
9.11、保存排序结果
9.12、返回值
10事物
参阅redis中文的 互动教程(interactive tutorial)的学习笔记。
全局操作:
#查看所有key keys * 或 keys "*" #查看匹配前缀的keys keys "miao*" #清空redis flushdb
#随机取出一个key
randomkey
#查看key的类型
type key
#查看数据库中key的数量
dbsize
#查看服务器信息
info
#查看redis正在做什么
monitor
#查看日志
slowlog get
slowlog get 101.redis是key-value存储的,放在内存中,并在磁盘持久化的数据结构存储系统
通过set key value来存储,通过get key来获取值
set key value:设置key的值,若存在则覆盖
setnx key value:SET if Not eXists,若存在则不操作。 MSET key1 value1 key2 value2 ... keyN valueN:设置这些key的值,若存在则覆盖
MSETNX key1 value1 key2 value2 ... keyN valueN:同mset,但如果其中一个key已经存在了,则都不设置。这些操作都是原子的。
rename key: 重命名
append key value:向key的字符串追加拼接。
get key:获取key对应的值 MGET key1 key2 ... keyN:获取这些key对应的值
EXISTS key:查看是否存在该元素。
GETSET key value:获取该元素的值,并给该元素设置新值。(通常和incr搭配使用,比如一个mycount一直incr,然后达到某些情况需要清零,清零之前需要知道mycount的值).
del key:删除元素
RENAME oldkey newkey:重命名

2.redis提供原子自增操作incr,用来防止多线程并发出现数据错误。
incr key:原子的+1; DECR key:原子的-1;
DECRBY key integer:原子的-integer;
INCRBY key integer:原子的+integer

3.删除操作:del.若数据不存在返回(nil)

4.redis可以定时存储,即设置几秒后删除该变量
expire key 多少秒:设置多少秒后过期; ttl key:Time To Live,查看还可以存活多久,-2表示key不存在;-1表示定时任务消失,永久存储。
EXPIRE key seconds:设置该元素多少秒后失效 PEXPIRE key milliseconds:设置该元素多少毫秒后失效 TTL key:查看还可以存活多少秒,-2表示key不存在,-1表示永久存储
SETEX key seconds value:等价于先设置变量再设置超时,即在缓存中使用:存储的同时设置超时时间,这个操作是原子的
persist key:取消过期时间
expireat key 时间戳:unix时间戳,1970.1.1之后,这个绝对时间,将在这个时间删除key。expireat pages:about 1356933600:在2012年12月31日上午12点删除掉关键字SETEX KEY_NAME TIMEOUT VALUE:设置key的值为value,并在timeout秒后失效,key将被删除
 ->
-> ->
-> ->
->
5.存储有序队列:list
rpush keyList value:向keyList添加元素,向后加,r表示右边
lpush keyList value:向keyList左边添加元素,LPUSH puts the new value at the start of the list.
lrange keyList beginIndex endIndex:获取keyList的元素,用两端的索引取出子集,endIndex=-1则表示全部取出
这里就要了解redis数据结构的存储类型, 字符串(strings), 散列(hashes), 列表(lists),集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting),LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
现在学习list:
 ->
-> ->
-> ->
->
llen keyList :获取keyList的长度大小 lpop keyList:取出并移除keyList第一个元素,左边的元素 rpop keyList:取出并移除keyList最后一个元素,右边的元素
LINDEX key index:获取该索引下的元素。
lrem key count value:删除count个value。(count为正数,从头开始,删除count个value元素;count为负,则从尾部向头删除|count|个value元素;count为0,则所有的元素为value的都删除)
LSET key index value:设置索引为index下的元素为value.超出索引范围报错。
LTRIM key start end:清空索引在start 和end之外的元素,索引从0开始,两端保留,两端之外的清空。
RPOPLPUSH srckey dstkey:源队列srckey,目标队列dstkey,将srckey的最后一个移除,并放到dstkey的第一个。
 -》
-》 -》
-》
6.无序且唯一集合set
和java中list与set的区别一样。这里的set无序且值唯一。
The next data structure that we'll look at is a set. A set is similar to a list, except it does not have a specific order and each element may only appear once. Some of the important commands in working with sets are SADD, SREM, SISMEMBER, SMEMBERS and SUNION.
sadd key value : 向set添加元素 srem key value :从set中移除元素 smembers key : 取出所有set元素 SISMEMBER key value: 查看value是否存在set中 SUNION key1 key2 ... keyN:将所有key合并后取出来,相同的值只取一次
scard key : 获取set中元素的个数
SRANDMEMBER key: Return a random element from a Set, without removing the element.随机取出一个
SDIFF key1 key2 ... keyN:获取第一set中不存在后面几个set里的元素。
SDIFFSTORE dstkey key1 key2 ... keyN:和sdiff相同,获取key1中不存在其他key里的元素,但要存储到dstkey中。
SINTER key1 key2 ... keyN:取出这些set的交集
SINTERSTORE dstkey key1 key2 ... keyN:取出这些key的交集并存储到dstkey
SMOVE srckey dstkey member:将元素member从srckey中转移到dstkey中,这个操作是原子的。
 -》
-》 -》
-》 -》
-》
7.有序集合sorted set
和set一样,唯一。但z多了个score用来排序。所以命令又像list一样:
ZADD key score member:向有序set中添加元素member,其中score为分数,默认升序;
ZRANGE key start end [WITHSCORES]:获取按score从低到高索引范围内的元素,索引可以是负数,-1表示最后一个,-2表示倒数第二个,即从后往前。withscores可选,表示获取包括分数。
ZREVRANGE key start end [WITHSCORES]:同上,但score从高到低排序。
ZCOUNT key min max:获取score在min和max范围内的元素的个数
ZCARD key:获取集合中元素的个数。
ZINCRBY key increment member:根据元素,score原子增加increment.
ZREMRANGEBYSCORE key min max:清空集合内的score位于min和max之间的元素。
ZRANK key member:获取元素的索引(照score从低到高排列)。
ZREM key member:移除集合中的该元素
ZSCORE key member:获取该元素的score
8.对象存储Hashes
可以存储对象,比如人,编号,姓名,年龄等
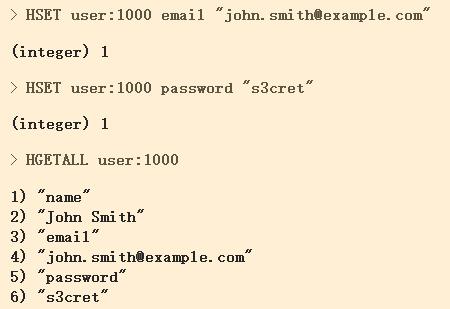
HSET key field value:key是对象名,field是属性,value是值; HMSET key field value [field value ...]:同时设置多个属性 HGET key field:获取该对象的该属性 HMGET key field value [field value ...]:获取多个属性值 HGETALL key:获取对象的所有信息 HKEYS key:获取对象的所有属性 HVALS key:获取对象的所有属性值 HDEL key field:删除对象的该属性 HEXISTS key field:查看对象是否存在该属性 HINCRBY key field value:原子自增操作,只能是integer的属性值可以使用; HLEN key: Return the number of entries (fields) contained in the hash stored at key.获取属性的个数。
 ->
-> ->
->
9.sort排序!
文档如下:
SORT [BY] [LIMIT] [GET] [ASC|DESC] [ALPHA] [STORE ]
DESCRIPTION: Sort the elements contained in the List, Set, or Sorted Set value at key. By default sorting is numeric with elements being compared as double precision floating point numbers. This is the simplest form of SORT: SORT mylist
Assuming mylist contains a list of numbers, the return value will be the list of numbers ordered from the smallest to the biggest number. In order to get the sorting in reverse order use DESC: SORT mylist DESC
The ASC option is also supported but it's the default so you don't really need it. If you want to sort lexicographically use ALPHA. Note that Redis is utf-8 aware assuming you set the right value for the LC_COLLATE environment variable.
Sort is able to limit the number of returned elements using the LIMIT option: SORT mylist LIMIT 0 10
In the above example SORT will return only 10 elements, starting from the first one (start is zero-based). Almost all the sort options can be mixed together. For example the command: SORT mylist LIMIT 0 10 ALPHA DESC
Will sort mylist lexicographically, in descending order, returning only the first 10 elements.
Sometimes you want to sort elements using external keys as weights to compare instead to compare the actual List Sets or Sorted Set elements. For example the list mylist may contain the elements 1, 2, 3, 4, that are just unique IDs of objects stored at object_1, object_2, object_3 and object_4, while the keys weight_1, weight_2, weight_3 and weight_4 can contain weights we want to use to sort our list of objects identifiers. We can use the following command:
SORTING BY EXTERNAL KEYS:
SORT mylist BY weight_*
the BY option takes a pattern (weight_* in our example) that is used in order to generate the key names of the weights used for sorting. Weight key names are obtained substituting the first occurrence of * with the actual value of the elements on the list (1,2,3,4 in our example).
Our previous example will return just the sorted IDs. Often it is needed to get the actual objects sorted (object_1, ..., object_4 in the example). We can do it with the following command:
RETRIEVING EXTERNAL KEYS:
SORT mylist BY weight* GET object*
Note that GET can be used multiple times in order to get more keys for every element of the original List, Set or Sorted Set sorted.
Since Redis >= 1.1 it's possible to also GET the list elements itself using the special # pattern: SORT mylist BY weight* GET object* GET #
STORING THE RESULT OF A SORT OPERATION:
By default SORT returns the sorted elements as its return value. Using the STORE option instead to return the elements SORT will store this elements as a Redis List in the specified key. An example:SORT mylist BY weight_* STORE resultkey
An interesting pattern using SORT ... STORE consists in associating an EXPIRE timeout to the resulting key so that in applications where the result of a sort operation can be cached for some time other clients will use the cached list instead to call SORT for every request. When the key will timeout an updated version of the cache can be created using SORT ... STORE again.
Note that implementing this pattern it is important to avoid that multiple clients will try to rebuild the cached version of the cache at the same time, so some form of locking should be implemented (for instance using SETNX).
RETURN VALUE: A multi bulk reply containing a list of sorted elements.
复制一个sort的用法:http://www.cnblogs.com/linjiqin/archive/2013/06/14/3135921.html
9.1 sort命令描述:
返回或保存给定列表、集合、有序集合key中经过排序的元素。排序默认以数字作为对象,值被解释为双精度浮点数,然后进行比较。
9.2 一般sort用法
最简单的sort使用方法是sort key和sort key desc。
sort key:返回键值从小到大排序的结果。
sort key desc:返回键值从大到小排序的结果。
假设price列表保存了今日的物品价格, 那么可以用sort命令对它进行排序:
# 开销金额列表
redis> lpush price 30 1.5 10 8 (integer) 4
# 排序
redis> sort price 1) "1.5" 2) "8" 3) "10" 4) "30"
# 逆序排序
redis 127.0.0.1:6379> sort price desc 1) "30" 2) "10" 3) "8" 4) "1.5"
9.3 使用alpha修饰符对字符串进行排序
因为sort命令默认排序对象为数字,当需要对字符串进行排序时,需要显式地在sort命令之后添加alpha修饰符。
# 网址
redis> lpush website "www.ceddit.com" (integer) 1 redis> lpush website "www.hlashdot.com" (integer) 2 redis> lpush website "www.bnfoq.com" (integer) 3
# 默认(按数字)排序
redis 127.0.0.1:8888> sort website 1) "www.bnfoq.com" 2) "www.hlashdot.com" 3) "www.ceddit.com"
# 按字符排序
redis 127.0.0.1:8888> sort website alpha 1) "www.bnfoq.com" 2) "www.ceddit.com" 3) "www.hlashdot.com" redis 127.0.0.1:8888> sort website alpha desc 1) "www.hlashdot.com" 2) "www.ceddit.com" 3) "www.bnfoq.com"
9.4、使用limit修饰符限制返回结果
排序之后返回元素的数量可以通过limit修饰符进行限制,修饰符接受offset和count两个参数。offset:指定要跳过的元素数量,即起始位置。count:指定跳过offset个指定的元素之后,要返回多少个对象。
以下例子返回排序结果的前5个对象(offset为0表示没有元素被跳过)。
# 添加测试数据,列表值为1~10
redis 127.0.0.1:6379> rpush age 1 3 5 7 9 (integer) 5 redis 127.0.0.1:6379> rpush age 2 4 6 8 10 (integer) 10
# 返回列表中最小的5个值
redis 127.0.0.1:6379> sort age limit 0 5 1) "1" 2) "2" 3) "3" 4) "4" 5) "5"
9.5、使用外部key进行排序
可以使用外部 key 的数据作为权重,代替默认的直接对比键值的方式来进行排序。
假设现在有用户数据如下:
以下代码将数据输入到redis中:
# admin redis 127.0.0.1:6379> lpush uid 1 (integer) 1 redis 127.0.0.1:6379> set user_name_1 admin ok redis 127.0.0.1:6379> set user_level_1 9999 ok # jack redis 127.0.0.1:6379> lpush uid 2 (integer) 2 redis 127.0.0.1:6379> set user_name_2 jack ok redis 127.0.0.1:6379> set user_level_2 10 ok # peter redis 127.0.0.1:6379> lpush uid 3 (integer) 3 redis 127.0.0.1:6379> set user_name_3 peter ok redis 127.0.0.1:6379> set user_level_3 25 ok # mary redis 127.0.0.1:6379> lpush uid 4 (integer) 4 redis 127.0.0.1:6379> set user_name_4 mary ok redis 127.0.0.1:6379> set user_level_4 70 ok
9.6、by选项
默认情况下, sort uid直接按uid中的值排序:
redis 127.0.0.1:6379> sort uid 1) "1" # admin 2) "2" # jack 3) "3" # peter 4) "4" # mary
通过使用by选项,可以让uid按其他键的元素来排序。
比如说, 以下代码让uid键按照user_level_{uid}的大小来排序:
redis 127.0.0.1:6379> sort uid by user_level_* 1) "2" # jack , level = 10 2) "3" # peter, level = 25 3) "4" # mary, level = 70 4) "1" # admin, level = 9999
user_level_*是一个占位符,它先取出uid中的值,然后再用这个值来查找相应的键。
比如在对uid列表进行排序时,程序就会先取出uid的值1、2、3、4,然后使用user_level_1、user_level_2、user_level_3和 user_level_4的值作为排序uid的权重。
9.7、get选项
使用get选项,可以根据排序的结果来取出相应的键值。
比如说,以下代码先排序uid,再取出键user_name_{uid}的值:
redis 127.0.0.1:6379> sort uid get user_name_* 1) "admin" 2) "jack" 3) "peter" 4) "mary"
现在的排序结果要比只使用 sort uid by user_level_* 要直观得多。
9.8、获取多个外部键
可以同时使用多个get选项,获取多个外部键的值。
以下代码就按 uid 分别获取 user_level_{uid} 和 user_name_{uid} :
redis 127.0.0.1:6379> sort uid get user_level_* get user_name_* 1) "9999" # level 2) "admin" # name 3) "10" 4) "jack" 5) "25" 6) "peter" 7) "70" 8) "mary"
get有一个额外的参数规则,那就是可以用#获取被排序键的值。
以下代码就将 uid 的值、及其相应的 user_level_* 和 user_name_* 都返回为结果:
redis 127.0.0.1:6379> sort uid get # get user_level_* get user_name_* 1) "1" # uid 2) "9999" # level 3) "admin" # name 4) "2" 5) "10" 6) "jack" 7) "3" 8) "25" 9) "peter" 10) "4" 11) "70" 12) "mary"
9.9、获取外部键,但不进行排序
通过将一个不存在的键作为参数传给 by 选项, 可以让 sort 跳过排序操作,直接返回结果:
redis 127.0.0.1:6379> sort uid by not-exists-key 1) "4" 2) "3" 3) "2" 4) "1"
这种用法在单独使用时,没什么实际用处。
不过,通过将这种用法和get选项配合,就可以在不排序的情况下,获取多个外部键,相当于执行一个整合的获取操作(类似于 sql数据库的join关键字)。
以下代码演示了,如何在不引起排序的情况下,使用sort、by和get获取多个外部键:
redis 127.0.0.1:6379> sort uid by not-exists-key get # get user_level_* get user_name_* 1) "4" # id 2) "70" # level 3) "mary" # name 4) "3" 5) "25" 6) "peter" 7) "2" 8) "10" 9) "jack" 10) "1" 11) "9999" 12) "admin"
9.10、将哈希表作为get或by的参数
除了可以将字符串键之外, 哈希表也可以作为 get 或 by 选项的参数来使用。
比如说,对于前面给出的用户信息表:
我们可以不将用户的名字和级别保存在 user_name_{uid} 和 user_level_{uid} 两个字符串键中, 而是用一个带有 name 域和 level 域的哈希表 user_info_{uid} 来保存用户的名字和级别信息:
redis 127.0.0.1:6379> hmset user_info_1 name admin level 9999 ok redis 127.0.0.1:6379> hmset user_info_2 name jack level 10 ok redis 127.0.0.1:6379> hmset user_info_3 name peter level 25 ok redis 127.0.0.1:6379> hmset user_info_4 name mary level 70 ok
之后, by 和 get 选项都可以用 key->field 的格式来获取哈希表中的域的值, 其中 key 表示哈希表键, 而 field 则表示哈希表的域:
redis 127.0.0.1:6379> sort uid by user_info_*->level 1) "2" 2) "3" 3) "4" 4) "1" redis 127.0.0.1:6379> sort uid by user_info_*->level get user_info_*->name 1) "jack" 2) "peter" 3) "mary" 4) "admin"
9.11、保存排序结果
默认情况下, sort 操作只是简单地返回排序结果,并不进行任何保存操作。
通过给 store 选项指定一个 key 参数,可以将排序结果保存到给定的键上。
如果被指定的 key 已存在,那么原有的值将被排序结果覆盖。
# 测试数据
redis 127.0.0.1:6379> rpush numbers 1 3 5 7 9 (integer) 5 redis 127.0.0.1:6379> rpush numbers 2 4 6 8 10 (integer) 10 redis 127.0.0.1:6379> lrange numbers 0 -1 1) "1" 2) "3" 3) "5" 4) "7" 5) "9" 6) "2" 7) "4" 8) "6" 9) "8" 10) "10" redis 127.0.0.1:6379> sort numbers store sorted-numbers (integer) 10 # 排序后的结果 redis 127.0.0.1:6379> lrange sorted-numbers 0 -1 1) "1" 2) "2" 3) "3" 4) "4" 5) "5" 6) "6" 7) "7" 8) "8" 9) "9" 10) "10"
9.12、返回值
没有使用 store 参数,返回列表形式的排序结果。
使用 store 参数,返回排序结果的元素数量。
10事物
redis内置了很多原子操作的命令,比如incr,getset等,但实际中我们希望将一组命令原子的执行,这时候就需要用到事物。做法如下:
- 使用关键字multi
- 输入你想要的命令组合
- 输入exec来执行,或discard来放弃
127.0.0.1:6379> multi
OK
127.0.0.1:6379> keys *
QUEUED
127.0.0.1:6379> set miao "transaction is by using multi then do some order,end with exec"
QUEUED
127.0.0.1:6379> get miao
QUEUED
127.0.0.1:6379> get users:9001
QUEUED
127.0.0.1:6379> exec
1) 1) "friends:duncan"
2) "users:lookup:email"
3) "users:9001"
2) OK
3) "transaction is by using multi then do some order,end with exec"
4) "{id:9001,email:leto@dune.gov,..}"
(转) Redis学习教程--基本命令的更多相关文章
- redis学习教程四《管理、备份、客户端连接》
redis学习教程四<管理.备份.客户端连接> 一:Redis服务器命令 Redis服务器命令 下表列出了与Redis服务器相关的一些基本命令. 序号 命令 说明 1 BGREWRITE ...
- redis学习教程三《发送订阅、事务、连接》
redis学习教程三<发送订阅.事务.连接> 一:发送订阅 Redis发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息.Redi ...
- redis学习教程二《四大数据类型》
redis学习教程二<四大数据类型> 四大数据类型包括:字符串 哈希 列表 集合一 : Redis字符串 Redis字符串命令用于管理Redis中的字符串 ...
- redis学习教程五《管道、分区》
redis学习教程五<管道.分区> 一:管道 Redis是一个TCP服务器,支持请求/响应协议. 在Redis中,请求通过以下步骤完成: 客户端向服务器发送查询,并从套接字读取,通常以阻 ...
- redis学习教程之一基本命令
参阅redis中文的 互动教程(interactive tutorial)来学习的. 目录: 全局操作 get get incr 自增 del 删除 expire 定时 list 队列 set ...
- redis学习教程地址
http://www.yiibai.com/redis/redis_quick_guide.html
- [ecmagent][redis学习][1初识redis] redis安装+redis快速教程+python操作redis
# redis安装 # redis安装教程 -- 服务器(ubuntu)安装redis服务 sudo apt-get install redis-server -- 源码安装 -- $ wget ht ...
- redis学习之二from github
大概敲了一遍基本命令,熟悉了redis的存储方式.现在开始进一步系统的学习.学习教程目前计划有三个,一个是github上的https://github.com/JasonLai256/the-litt ...
- redis学习教程一《Redis的安装和配置》
redis学习教程一<Redis的安装和配置> Redis的优点 以下是Redis的一些优点. 异常快 - Redis非常快,每秒可执行大约110000次的设置(SET)操作,每秒大约可执 ...
随机推荐
- JSP第一篇【JSP介绍、工作原理、生命周期、语法、指令、行为】
什么是JSP JSP全名为Java Server Pages,java服务器页面.JSP是一种基于文本的程序,其特点就是HTML和Java代码共同存在! 为什么需要JSP JSP是为了简化Servle ...
- JUDE-UML工具软件介绍
JUDE社区版(不考虑破-解). 现在Jude改名为Astah了.JUDE已停止发展,Astah是它的替代品.Jude有3个版: Professional版, Community版(免费),Share ...
- python generator(生成器)
a=(x*2 for x in range(1000)) # print(a.next())#python2使用 print(a.__next__()) #python3使用 print(next(a ...
- SimpleRpc-网络事件响应Reactor设计模式
前言 这篇文章主要介绍整个框架用到的最核的一个设计模式:反应器模式.这个设计模式可以在<面向对象的软件架构>中详细了解,没有这本书的小伙伴不要急,我通过咱们的SimpleRpc来告诉大家这 ...
- JavaScript中的alert、confirm、prompt
alert: var a=alert('Alert');//界面只有一個確定alert(a); //返回值為undefined confirm: var c= confirm('Confirm') ...
- css3新属性的学习使用
display 可选值:none隐藏元素: block显示为块级元素: inline显示为行级元素 inlineblock显示为内联块级元素,本身将是一个行级元素,但是拥有 块级元素的所有属性,比如宽 ...
- session写入memcache
1 <?php 2 class MemSession{ 3 private static $handler = null; 4 private static $lifetime = null; ...
- 数据库服务器构建和部署列表(For SQL Server 2012)
前言 我们可能经常安装和部署数据库服务器,但是可能突然忘记了某个设置,为后来的运维造成隐患.下面是国外大牛整理的的检查列表. 其实也包含了很多我们平时数据库配置的最佳实践.比如TEMPDB 文件的个数 ...
- pmap 命令详解
通过查看帮助,返回了如下信息: Usage: pmap [options] pid [pid ...] Options: -x, --extended show detai ...
- Hibernate中的实体映射
一.一对一映射 如人(Person)与身份证(IdCard) 的关系,即为一对一的关系,一个人只能有一张身份证,一张身份证只能属于某一个人,它们的关系图如下图所示: 在Person实体中添加一个属 ...