机器学习:Python实现聚类算法(一)之AP算法
1.算法简介
AP(Affinity Propagation)通常被翻译为近邻传播算法或者亲和力传播算法,是在2007年的Science杂志上提出的一种新的聚类算法。AP算法的基本思想是将全部数据点都当作潜在的聚类中心(称之为exemplar),然后数据点两两之间连线构成一个网络(相似度矩阵),再通过网络中各条边的消息(responsibility和availability)传递计算出各样本的聚类中心。
2.相关概念(假如有数据点i和数据点j)
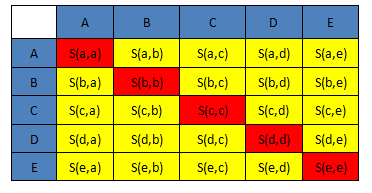

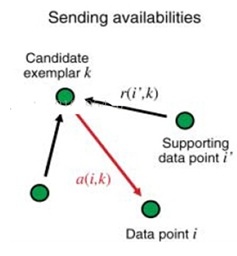
(图1) (图2) (图3)
1)相似度: 点j作为点i的聚类中心的能力,记为S(i,j)。一般使用负的欧式距离,所以S(i,j)越大,表示两个点距离越近,相似度也就越高。使用负的欧式距离,相似度是对称的,如果采用其他算法,相似度可能就不是对称的。
2)相似度矩阵:N个点之间两两计算相似度,这些相似度就组成了相似度矩阵。如图1所示的黄色区域,就是一个5*5的相似度矩阵(N=5)
3) preference:指点i作为聚类中心的参考度(不能为0),取值为S对角线的值(图1红色标注部分),此值越大,最为聚类中心的可能性就越大。但是对角线的值为0,所以需要重新设置对角线的值,既可以根据实际情况设置不同的值,也可以设置成同一值。一般设置为S相似度值的中值。(有的说设置成S的最小值产生的聚类最少,但是在下面的算法中设置成中值产生的聚类是最少的)
4)Responsibility(吸引度):指点k适合作为数据点i的聚类中心的程度,记为r(i,k)。如图2红色箭头所示,表示点i给点k发送信息,是一个点i选点k的过程。
5)Availability(归属度):指点i选择点k作为其聚类中心的适合程度,记为a(i,k)。如图3红色箭头所示,表示点k给点i发送信息,是一个点k选diani的过程。
6)exemplar:指的是聚类中心。
7)r (i, k)加a (i, k)越大,则k点作为聚类中心的可能性就越大,并且i点隶属于以k点为聚类中心的聚类的可能性也越大
3.数学公式
1)吸引度迭代公式:
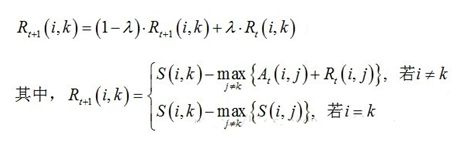 (公式一)
(公式一)
说明1:Rt+1(i,k)表示新的R(i,k),Rt(i,k)表示旧的R(i,k),也许这样说更容易理解。其中λ是阻尼系数,取值[0.5,1),用于算法的收敛
说明2:网上还有另外一种数学公式:
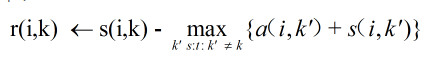 (公式二)
(公式二)
sklearn官网的公式是:
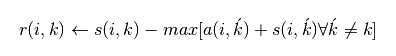 (公式三)
(公式三)
我试了这两种公式之后,发现还是公式一的聚类效果最好。同样的数据都采取S的中值作为参考度,我自己写的算法聚类中心是5个,sklearn提供的算法聚类中心是十三个,但是如果把参考度设置为p=-50,则我自己写的算法聚类中心很多,sklearn提供的聚类算法产生标准的3个聚类中心(因为数据是围绕三个中心点产生的),目前还不清楚这个p=-50是怎么得到的。
2)归属度迭代公式
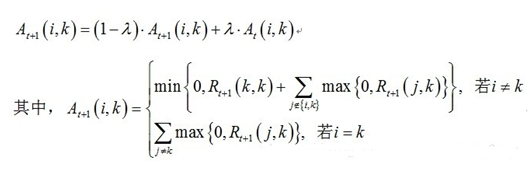
说明:At+1(i,k)表示新的A(i,k),At(i,k)表示旧的A(i,k)。其中λ是阻尼系数,取值[0.5,1),用于算法的收敛
4.详细的算法流程
1)设置实验数据。使用sklearn包中提供的函数,随机生成以[1, 1], [-1, -1], [1, -1]三个点为中心的150个数据。
def init_sample():
## 生成的测试数据的中心点
centers = [[1, 1], [-1, -1], [1, -1]]
##生成数据
Xn, labels_true = make_blobs(n_samples=150, centers=centers, cluster_std=0.5,
random_state=0)
#3数据的长度,即:数据点的个数
dataLen = len(Xn) return Xn,dataLen
2)计算相似度矩阵,并且设置参考度,这里使用相似度矩阵的中值
def cal_simi(Xn):
##这个数据集的相似度矩阵,最终是二维数组
simi = []
for m in Xn:
##每个数字与所有数字的相似度列表,即矩阵中的一行
temp = []
for n in Xn:
##采用负的欧式距离计算相似度
s =-np.sqrt((m[0]-n[0])**2 + (m[1]-n[1])**2)
temp.append(s)
simi.append(temp) ##设置参考度,即对角线的值,一般为最小值或者中值
#p = np.min(simi) ##11个中心
#p = np.max(simi) ##14个中心
p = np.median(simi) ##5个中心
for i in range(dataLen):
simi[i][i] = p
return simi
3)计算吸引度矩阵,即R值。
如果有细心的同学会发现,在上述求R和求A的公式中,求R需要A,求A需要R,所以R或者A不是一开始就可以求解出的,需要先初始化,然后再更新。(我开始就陷入了这个误区,总觉得公式有问题,囧)
##初始化R矩阵、A矩阵
def init_R(dataLen):
R = [[0]*dataLen for j in range(dataLen)]
return R def init_A(dataLen):
A = [[0]*dataLen for j in range(dataLen)]
return A ##迭代更新R矩阵
def iter_update_R(dataLen,R,A,simi):
old_r = 0 ##更新前的某个r值
lam = 0.5 ##阻尼系数,用于算法收敛
##此循环更新R矩阵
for i in range(dataLen):
for k in range(dataLen):
old_r = R[i][k]
if i != k:
max1 = A[i][0] + R[i][0] ##注意初始值的设置
for j in range(dataLen):
if j != k:
if A[i][j] + R[i][j] > max1 :
max1 = A[i][j] + R[i][j]
##更新后的R[i][k]值
R[i][k] = simi[i][k] - max1
##带入阻尼系数重新更新
R[i][k] = (1-lam)*R[i][k] +lam*old_r
else:
max2 = simi[i][0] ##注意初始值的设置
for j in range(dataLen):
if j != k:
if simi[i][j] > max2:
max2 = simi[i][j]
##更新后的R[i][k]值
R[i][k] = simi[i][k] - max2
##带入阻尼系数重新更新
R[i][k] = (1-lam)*R[i][k] +lam*old_r
print("max_r:"+str(np.max(R)))
#print(np.min(R))
return R
4)计算归属度矩阵,即A值
##迭代更新A矩阵
def iter_update_A(dataLen,R,A):
old_a = 0 ##更新前的某个a值
lam = 0.5 ##阻尼系数,用于算法收敛
##此循环更新A矩阵
for i in range(dataLen):
for k in range(dataLen):
old_a = A[i][k]
if i ==k :
max3 = R[0][k] ##注意初始值的设置
for j in range(dataLen):
if j != k:
if R[j][k] > 0:
max3 += R[j][k]
else :
max3 += 0
A[i][k] = max3
##带入阻尼系数更新A值
A[i][k] = (1-lam)*A[i][k] +lam*old_a
else :
max4 = R[0][k] ##注意初始值的设置
for j in range(dataLen):
##上图公式中的i!=k 的求和部分
if j != k and j != i:
if R[j][k] > 0:
max4 += R[j][k]
else :
max4 += 0 ##上图公式中的min部分
if R[k][k] + max4 > 0:
A[i][k] = 0
else :
A[i][k] = R[k][k] + max4 ##带入阻尼系数更新A值
A[i][k] = (1-lam)*A[i][k] +lam*old_a
print("max_a:"+str(np.max(A)))
#print(np.min(A))
return A
5)迭代更新R值和A值。终止条件是聚类中心在一定程度上不再更新或者达到最大迭代次数
##计算聚类中心
def cal_cls_center(dataLen,simi,R,A):
##进行聚类,不断迭代直到预设的迭代次数或者判断comp_cnt次后聚类中心不再变化
max_iter = 100 ##最大迭代次数
curr_iter = 0 ##当前迭代次数
max_comp = 30 ##最大比较次数
curr_comp = 0 ##当前比较次数
class_cen = [] ##聚类中心列表,存储的是数据点在Xn中的索引
while True:
##计算R矩阵
R = iter_update_R(dataLen,R,A,simi)
##计算A矩阵
A = iter_update_A(dataLen,R,A)
##开始计算聚类中心
for k in range(dataLen):
if R[k][k] +A[k][k] > 0:
if k not in class_cen:
class_cen.append(k)
else:
curr_comp += 1
curr_iter += 1
print(curr_iter)
if curr_iter >= max_iter or curr_comp > max_comp :
break
return class_cen
6)根据求出的聚类中心,对数据进行分类
这个步骤产生的是一个归类列表,列表中的每个数字对应着样本数据中对应位置的数据的分类
##根据聚类中心划分数据
c_list = []
for m in Xn:
temp = []
for j in class_cen:
n = Xn[j]
d = -np.sqrt((m[0]-n[0])**2 + (m[1]-n[1])**2)
temp.append(d)
##按照是第几个数字作为聚类中心进行分类标识
c = class_cen[temp.index(np.max(temp))]
c_list.append(c)
7)完整代码及效果图
from sklearn.datasets.samples_generator import make_blobs
import numpy as np
import matplotlib.pyplot as plt
'''
第一步:生成测试数据
1.生成实际中心为centers的测试样本300个,
2.Xn是包含150个(x,y)点的二维数组
3.labels_true为其对应的真是类别标签
''' def init_sample():
## 生成的测试数据的中心点
centers = [[1, 1], [-1, -1], [1, -1]]
##生成数据
Xn, labels_true = make_blobs(n_samples=150, centers=centers, cluster_std=0.5,
random_state=0)
#3数据的长度,即:数据点的个数
dataLen = len(Xn) return Xn,dataLen '''
第二步:计算相似度矩阵
'''
def cal_simi(Xn):
##这个数据集的相似度矩阵,最终是二维数组
simi = []
for m in Xn:
##每个数字与所有数字的相似度列表,即矩阵中的一行
temp = []
for n in Xn:
##采用负的欧式距离计算相似度
s =-np.sqrt((m[0]-n[0])**2 + (m[1]-n[1])**2)
temp.append(s)
simi.append(temp) ##设置参考度,即对角线的值,一般为最小值或者中值
#p = np.min(simi) ##11个中心
#p = np.max(simi) ##14个中心
p = np.median(simi) ##5个中心
for i in range(dataLen):
simi[i][i] = p
return simi '''
第三步:计算吸引度矩阵,即R
公式1:r(n+1) =s(n)-(s(n)+a(n))-->简化写法,具体参见上图公式
公式2:r(n+1)=(1-λ)*r(n+1)+λ*r(n)
''' ##初始化R矩阵、A矩阵
def init_R(dataLen):
R = [[0]*dataLen for j in range(dataLen)]
return R def init_A(dataLen):
A = [[0]*dataLen for j in range(dataLen)]
return A ##迭代更新R矩阵
def iter_update_R(dataLen,R,A,simi):
old_r = 0 ##更新前的某个r值
lam = 0.5 ##阻尼系数,用于算法收敛
##此循环更新R矩阵
for i in range(dataLen):
for k in range(dataLen):
old_r = R[i][k]
if i != k:
max1 = A[i][0] + R[i][0] ##注意初始值的设置
for j in range(dataLen):
if j != k:
if A[i][j] + R[i][j] > max1 :
max1 = A[i][j] + R[i][j]
##更新后的R[i][k]值
R[i][k] = simi[i][k] - max1
##带入阻尼系数重新更新
R[i][k] = (1-lam)*R[i][k] +lam*old_r
else:
max2 = simi[i][0] ##注意初始值的设置
for j in range(dataLen):
if j != k:
if simi[i][j] > max2:
max2 = simi[i][j]
##更新后的R[i][k]值
R[i][k] = simi[i][k] - max2
##带入阻尼系数重新更新
R[i][k] = (1-lam)*R[i][k] +lam*old_r
print("max_r:"+str(np.max(R)))
#print(np.min(R))
return R
'''
第四步:计算归属度矩阵,即A
'''
##迭代更新A矩阵
def iter_update_A(dataLen,R,A):
old_a = 0 ##更新前的某个a值
lam = 0.5 ##阻尼系数,用于算法收敛
##此循环更新A矩阵
for i in range(dataLen):
for k in range(dataLen):
old_a = A[i][k]
if i ==k :
max3 = R[0][k] ##注意初始值的设置
for j in range(dataLen):
if j != k:
if R[j][k] > 0:
max3 += R[j][k]
else :
max3 += 0
A[i][k] = max3
##带入阻尼系数更新A值
A[i][k] = (1-lam)*A[i][k] +lam*old_a
else :
max4 = R[0][k] ##注意初始值的设置
for j in range(dataLen):
##上图公式中的i!=k 的求和部分
if j != k and j != i:
if R[j][k] > 0:
max4 += R[j][k]
else :
max4 += 0 ##上图公式中的min部分
if R[k][k] + max4 > 0:
A[i][k] = 0
else :
A[i][k] = R[k][k] + max4 ##带入阻尼系数更新A值
A[i][k] = (1-lam)*A[i][k] +lam*old_a
print("max_a:"+str(np.max(A)))
#print(np.min(A))
return A '''
第5步:计算聚类中心
''' ##计算聚类中心
def cal_cls_center(dataLen,simi,R,A):
##进行聚类,不断迭代直到预设的迭代次数或者判断comp_cnt次后聚类中心不再变化
max_iter = 100 ##最大迭代次数
curr_iter = 0 ##当前迭代次数
max_comp = 30 ##最大比较次数
curr_comp = 0 ##当前比较次数
class_cen = [] ##聚类中心列表,存储的是数据点在Xn中的索引
while True:
##计算R矩阵
R = iter_update_R(dataLen,R,A,simi)
##计算A矩阵
A = iter_update_A(dataLen,R,A)
##开始计算聚类中心
for k in range(dataLen):
if R[k][k] +A[k][k] > 0:
if k not in class_cen:
class_cen.append(k)
else:
curr_comp += 1
curr_iter += 1
print(curr_iter)
if curr_iter >= max_iter or curr_comp > max_comp :
break
return class_cen if __name__=='__main__':
##初始化数据
Xn,dataLen = init_sample()
##初始化R、A矩阵
R = init_R(dataLen)
A = init_A(dataLen)
##计算相似度
simi = cal_simi(Xn)
##输出聚类中心
class_cen = cal_cls_center(dataLen,simi,R,A)
#for i in class_cen:
# print(str(i)+":"+str(Xn[i]))
#print(class_cen) ##根据聚类中心划分数据
c_list = []
for m in Xn:
temp = []
for j in class_cen:
n = Xn[j]
d = -np.sqrt((m[0]-n[0])**2 + (m[1]-n[1])**2)
temp.append(d)
##按照是第几个数字作为聚类中心进行分类标识
c = class_cen[temp.index(np.max(temp))]
c_list.append(c)
##画图
colors = ['red','blue','black','green','yellow']
plt.figure(figsize=(8,6))
plt.xlim([-3,3])
plt.ylim([-3,3])
for i in range(dataLen):
d1 = Xn[i]
d2 = Xn[c_list[i]]
c = class_cen.index(c_list[i])
plt.plot([d2[0],d1[0]],[d2[1],d1[1]],color=colors[c],linewidth=1)
#if i == c_list[i] :
# plt.scatter(d1[0],d1[1],color=colors[c],linewidth=3)
#else :
# plt.scatter(d1[0],d1[1],color=colors[c],linewidth=1)
plt.show()
迭代11次出结果:
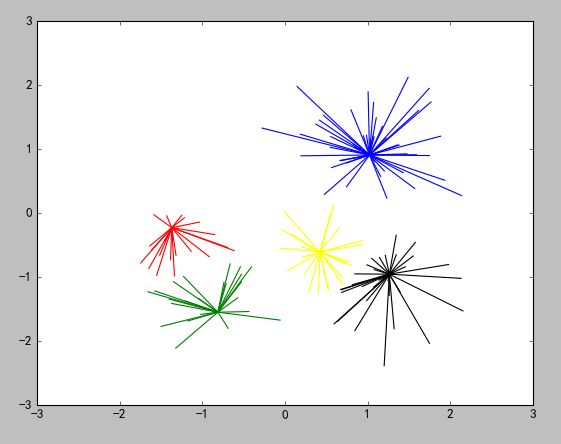
补充说明:这个算法重点在讲解实现过程,执行效率不是特别高,有优化的空间。以后我会补充进来
5.sklearn包中的AP算法
1)函数:sklearn.cluster.AffinityPropagation
2)主要参数:
damping : 阻尼系数,取值[0.5,1)
convergence_iter :比较多少次聚类中心不变之后停止迭代,默认15
max_iter :最大迭代次数
preference :参考度
3)主要属性
cluster_centers_indices_ : 存放聚类中心的数组
labels_ :存放每个点的分类的数组
n_iter_ : 迭代次数
4)示例
preference(即p值)取不同值时的聚类中心的数目在代码中注明了。
from sklearn.cluster import AffinityPropagation
from sklearn import metrics
from sklearn.datasets.samples_generator import make_blobs
import numpy as np ## 生成的测试数据的中心点
centers = [[1, 1], [-1, -1], [1, -1]]
##生成数据
Xn, labels_true = make_blobs(n_samples=150, centers=centers, cluster_std=0.5,
random_state=0) simi = []
for m in Xn:
##每个数字与所有数字的相似度列表,即矩阵中的一行
temp = []
for n in Xn:
##采用负的欧式距离计算相似度
s =-np.sqrt((m[0]-n[0])**2 + (m[1]-n[1])**2)
temp.append(s)
simi.append(temp) p=-50 ##3个中心
#p = np.min(simi) ##9个中心,
#p = np.median(simi) ##13个中心 ap = AffinityPropagation(damping=0.5,max_iter=500,convergence_iter=30,
preference=p).fit(Xn)
cluster_centers_indices = ap.cluster_centers_indices_ for idx in cluster_centers_indices:
print(Xn[idx])
6.AP算法的优点
1) 不需要制定最终聚类族的个数
2) 已有的数据点作为最终的聚类中心,而不是新生成一个族中心。
3)模型对数据的初始值不敏感。
4)对初始相似度矩阵数据的对称性没有要求。
5).相比与k-centers聚类方法,其结果的平方差误差较小。
7.AP算法的不足
1)AP算法需要事先计算每对数据对象之间的相似度,如果数据对象太多的话,内存放不下,若存在数据库,频繁访问数据库也需要时间。
2)AP算法的时间复杂度较高,一次迭代大概O(N3)
3)聚类的好坏受到参考度和阻尼系数的影响。
机器学习:Python实现聚类算法(一)之AP算法的更多相关文章
- 机器学习:Python实现聚类算法(二)之AP算法
1.算法简介 AP(Affinity Propagation)通常被翻译为近邻传播算法或者亲和力传播算法,是在2007年的Science杂志上提出的一种新的聚类算法.AP算法的基本思想是将全部数据点都 ...
- Python实现聚类算法AP
1.算法简介 AP(Affinity Propagation)通常被翻译为近邻传播算法或者亲和力传播算法,是在2007年的Science杂志上提出的一种新的聚类算法.AP算法的基本思想是将全部数据点都 ...
- 【Python机器学习实战】聚类算法(1)——K-Means聚类
实战部分主要针对某一具体算法对其原理进行较为详细的介绍,然后进行简单地实现(可能对算法性能考虑欠缺),这一部分主要介绍一些常见的一些聚类算法. K-means聚类算法 0.聚类算法算法简介 聚类算法算 ...
- 机器学习:Python实现聚类算法(一)之K-Means
1.简介 K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一.K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类.通过迭代的方法,逐次更新各 ...
- 【Python机器学习实战】聚类算法(2)——层次聚类(HAC)和DBSCAN
层次聚类和DBSCAN 前面说到K-means聚类算法,K-Means聚类是一种分散性聚类算法,本节主要是基于数据结构的聚类算法--层次聚类和基于密度的聚类算法--DBSCAN两种算法. 1.层次聚类 ...
- 【机器学习】机器学习入门08 - 聚类与聚类算法K-Means
时间过得很快,这篇文章已经是机器学习入门系列的最后一篇了.短短八周的时间里,虽然对机器学习并没有太多应用和熟悉的机会,但对于机器学习一些基本概念已经差不多有了一个提纲挈领的了解,如分类和回归,损失函数 ...
- 机器学习六--K-means聚类算法
机器学习六--K-means聚类算法 想想常见的分类算法有决策树.Logistic回归.SVM.贝叶斯等.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别 ...
- Mahout机器学习平台之聚类算法具体剖析(含实例分析)
第一部分: 学习Mahout必需要知道的资料查找技能: 学会查官方帮助文档: 解压用于安装文件(mahout-distribution-0.6.tar.gz),找到例如以下位置.我将该文件解压到win ...
- Stanford机器学习笔记-9. 聚类(K-means算法)
9. Clustering Content 9. Clustering 9.1 Supervised Learning and Unsupervised Learning 9.2 K-means al ...
随机推荐
- Spark入门实战
星星之火,可以燎原 Spark简介 Spark是一个开源的计算框架平台,使用该平台,数据分析程序可自动分发到集群中的不同机器中,以解决大规模数据快速计算的问题,同时它还向上提供一个优雅的编程范式,使得 ...
- 分布式部署网站---文件系统的存储--ftp上传图片到指定文件服务器
问:通常一个网站程序发布在一个iis服务器上,但是如果要分布式部署网站.文件系统该如何存储呢? 答:通常的就是给网站文件系统一个子域名.比如 https://images.web.com. 网站程序内 ...
- vscode奇淫记(上)
每次换editor都是一种煎熬,从最早的eclipse,sublime,webstorm到现在在用的atom,换编辑器的驱动是寻找更酷炫和轻量的平衡点,其实我真的蛮喜欢atom的,酷炫!那我这次打算入 ...
- 基础SELECT示例掌握
SELECT查询语句 ---进行单条记录.多条记录.单表.多表.子查询-- SELECT [ALL | DISTINCT | DISTINCTROW ] [HIGH_PRIORITY] [MAX_ST ...
- Java 原始数据类型
如何记住 Java 中的原始数据类型? 画了一个图方便记忆:
- 前端魔法堂:解秘FOUC
前言 对于问题多多的IE678,FOUC(flash of unstyled content)--浏览器样式闪烁是一个不可忽视的话题,但对于ever green的浏览器就不用理会了吗?下面尝试较全面 ...
- C# 弱引用WeakReferance
在应用程序代码内实例化一个类或结构时,只要有代码引用它,就会形成强引用.例如,如果有一个类MyClass(),并创建一个变量MyClassVariable来引用该类的对象,那么只要在 MyClassV ...
- CF #93 div1 B. Password KMP/Z
题目链接:http://codeforces.com/problemset/problem/126/B 大意:给一个字符串,问最长的既是前缀又是后缀又是中缀(这里指在内部出现)的子串. 我自己的做法是 ...
- 玩转SSH端口转发
SSH有三种端口转发模式,本地端口转发(Local Port Forwarding),**远程端口转发(Local Port Forwarding)**以及**动态端口转发(Dynamic Port ...
- 1. Skippr
Skippr 是一个超级简单的 jQuery 幻灯片插件.只是包括你的网页中引入 jquery.skippr.css 和 jquery.skippr.js 文件就能使用了.Skippr 能够自适应窗口 ...