文本主题模型之LDA(三) LDA求解之变分推断EM算法
文本主题模型之LDA(二) LDA求解之Gibbs采样算法
文本主题模型之LDA(三) LDA求解之变分推断EM算法
本文是LDA主题模型的第三篇,读这一篇之前建议先读文本主题模型之LDA(一) LDA基础,同时由于使用了EM算法,如果你对EM算法不熟悉,建议先熟悉EM算法的主要思想。LDA的变分推断EM算法求解,应用于Spark MLlib和Scikit-learn的LDA算法实现,因此值得好好理解。
1. 变分推断EM算法求解LDA的思路
首先,回顾LDA的模型图如下:
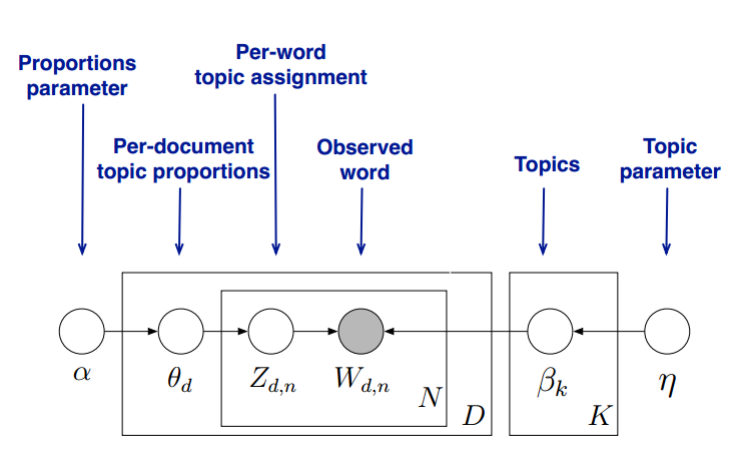
变分推断EM算法希望通过“变分推断(Variational Inference)”和EM算法来得到LDA模型的文档主题分布和主题词分布。首先来看EM算法在这里的使用,我们的模型里面有隐藏变量$\theta,\beta, z$,模型的参数是$\alpha,\eta$。为了求出模型参数和对应的隐藏变量分布,EM算法需要在E步先求出隐藏变量$\theta,\beta, z$的基于条件概率分布的期望,接着在M步极大化这个期望,得到更新的后验模型参数$\alpha,\eta$。
问题是在EM算法的E步,由于$\theta,\beta, z$的耦合,我们难以求出隐藏变量$\theta,\beta, z$的条件概率分布,也难以求出对应的期望,需要“变分推断“来帮忙,这里所谓的变分推断,也就是在隐藏变量存在耦合的情况下,我们通过变分假设,即假设所有的隐藏变量都是通过各自的独立分布形成的,这样就去掉了隐藏变量之间的耦合关系。我们用各个独立分布形成的变分分布来模拟近似隐藏变量的条件分布,这样就可以顺利的使用EM算法了。
当进行若干轮的E步和M步的迭代更新之后,我们可以得到合适的近似隐藏变量分布$\theta,\beta, z$和模型后验参数$\alpha,\eta$,进而就得到了我们需要的LDA文档主题分布和主题词分布。
可见要完全理解LDA的变分推断EM算法,需要搞清楚它在E步变分推断的过程和推断完毕后EM算法的过程。
2. LDA的变分推断思路
要使用EM算法,我们需要求出隐藏变量的条件概率分布如下:$$p(\theta,\beta, z | w, \alpha, \eta) = \frac{p(\theta,\beta, z, w| \alpha, \eta)}{p(w|\alpha, \eta)}$$
前面讲到由于$\theta,\beta, z$之间的耦合,这个条件概率是没法直接求的,但是如果不求它就不能用EM算法了。怎么办呢,我们引入变分推断,具体是引入基于mean field assumption的变分推断,这个推断假设所有的隐藏变量都是通过各自的独立分布形成的,如下图所示:
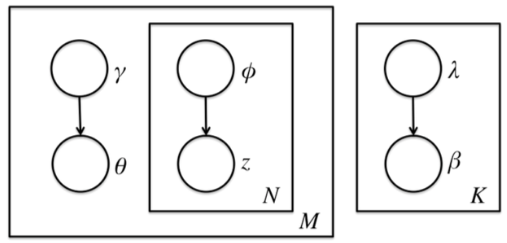
我们假设隐藏变量$\theta$是由独立分布$\gamma$形成的,隐藏变量$z$是由独立分布$\phi$形成的,隐藏变量$\beta$是由独立分布$\lambda$形成的。这样我们得到了三个隐藏变量联合的变分分布$q$为:$$\begin{align} q(\beta, z, \theta|\lambda,\phi, \gamma) & = \prod_{k=1}^Kq(\beta_k|\lambda_k)\prod_{d=1}^Mq(\theta_d, z_d|\gamma_d,\phi_d) \\ & = \prod_{k=1}^Kq(\beta_k|\lambda_k)\prod_{d=1}^M(q(\theta_d|\gamma_d)\prod_{n=1}^{N_d}q(z_{dn}| \phi_{dn})) \end{align}$$
我们的目标是用$q(\beta, z, \theta|\lambda,\phi, \gamma) $来近似的估计$p(\theta,\beta, z | w, \alpha, \eta)$,也就是说需要这两个分布尽可能的相似,用数学语言来描述就是希望这两个概率分布之间有尽可能小的KL距离,即:$$(\lambda^*,\phi^*, \gamma^*) = \underbrace{arg \;min}_{\lambda,\phi, \gamma} D(q(\beta, z, \theta|\lambda,\phi, \gamma) || p(\theta,\beta, z | w, \alpha, \eta))$$
其中$D(q||p)$即为KL散度或KL距离,对应分布$q$和$p$的交叉熵。即:$$D(q||p) = \sum\limits_{x}q(x)log\frac{q(x)}{p(x)} = E_{q(x)}(log\;q(x) - log\;p(x))$$
我们的目的就是找到合适的$\lambda^*,\phi^*, \gamma^*$,然后用$q(\beta, z, \theta|\lambda^*,\phi^*, \gamma^*)$来近似隐藏变量的条件分布$p(\theta,\beta, z | w, \alpha, \eta)$,进而使用EM算法迭代。
这个合适的$\lambda^*,\phi^*, \gamma^*$,也不是那么好求的,怎么办呢?我们先看看我能文档数据的对数似然函数$log(w|\alpha,\eta)$如下,为了简化表示,我们用$E_q(x)$代替$E_{q(\beta, z, \theta|\lambda,\phi, \gamma) }(x)$,用来表示$x$对于变分分布$q(\beta, z, \theta|\lambda,\phi, \gamma)$ 的期望。
$$\begin{align} log(w|\alpha,\eta) & = log \int\int \sum\limits_z p(\theta,\beta, z, w| \alpha, \eta) d\theta d\beta \\ & = log \int\int \sum\limits_z \frac{p(\theta,\beta, z, w| \alpha, \eta) q(\beta, z, \theta|\lambda,\phi, \gamma)}{q(\beta, z, \theta|\lambda,\phi, \gamma)}d\theta d\beta \\ & = log\;E_q \frac{p(\theta,\beta, z, w| \alpha, \eta) }{q(\beta, z, \theta|\lambda,\phi, \gamma)} \\ & \geq E_q\; log\frac{p(\theta,\beta, z, w| \alpha, \eta) }{q(\beta, z, \theta|\lambda,\phi, \gamma)} \\ & = E_q\; log{p(\theta,\beta, z, w| \alpha, \eta) } - E_q\; log{q(\beta, z, \theta|\lambda,\phi, \gamma)} \end{align} $$
其中,从第(5)式到第(6)式用到了Jensen不等式:$$f(E(x)) \geq E(f(x)) \;\; f(x)为凹函数$$
我们一般把第(7)式记为:$$L(\lambda,\phi, \gamma; \alpha, \eta) = E_q\; log{p(\theta,\beta, z, w| \alpha, \eta) } - E_q\; log{q(\beta, z, \theta|\lambda,\phi, \gamma)}$$
由于$ L(\lambda,\phi, \gamma; \alpha, \eta)$是我们的对数似然的一个下界(第6式),所以这个$L$一般称为ELBO(Evidence Lower BOund)。那么这个ELBO和我们需要优化的的KL散度有什么关系呢?注意到:$$\begin{align} D(q(\beta, z, \theta|\lambda,\phi, \gamma) || p(\theta,\beta, z | w, \alpha, \eta)) & = E_q logq(\beta, z, \theta|\lambda,\phi, \gamma) - E_q log p(\theta,\beta, z | w, \alpha, \eta) \\& =E_q logq(\beta, z, \theta|\lambda,\phi, \gamma) - E_q log \frac{p(\theta,\beta, z, w| \alpha, \eta)}{p(w|\alpha, \eta)} \\& = - L(\lambda,\phi, \gamma; \alpha, \eta) + log(w|\alpha,\eta) \end{align} $$
在(10)式中,由于对数似然部分和我们的KL散度无关,可以看做常量,因此我们希望最小化KL散度等价于最大化ELBO。那么我们的变分推断最终等价的转化为要求ELBO的最大值。现在我们开始关注于极大化ELBO并求出极值对应的变分参数$\lambda,\phi, \gamma$。
3. 极大化ELBO求解变分参数
为了极大化ELBO,我们首先对ELBO函数做一个整理如下:$$\begin{align} L(\lambda,\phi, \gamma; \alpha, \eta) & = E_q[logp(\beta|\eta)] + E_q[logp(z|\theta)] + E_q[logp(\theta|\alpha)] \\ & + E_q[logp(w|z, \beta)] - E_q[logq(\beta|\lambda)] \\ & - E_q[logq(z|\phi)] - E_q[logq(\theta|\gamma)] \end{align} $$
可见展开后有7项,现在我们需要对这7项分别做一个展开。为了简化篇幅,这里只对第一项的展开做详细介绍。在介绍第一项的展开前,我们需要了解指数分布族的性质。指数分布族是指下面这样的概率分布:$$p(x|\theta) = h(x) exp(\eta(\theta)*T(x) -A(\theta))$$
其中,$A(x)$为归一化因子,主要是保证概率分布累积求和后为1,引入指数分布族主要是它有下面这样的性质:$$\frac{d}{d \eta(\theta)} A(\theta) = E_{p(x|\theta)}[T(x)]$$
这个证明并不复杂,这里不累述。我们的常见分布比如Gamma分布,Beta分布,Dirichlet分布都是指数分布族。有了这个性质,意味着我们在ELBO里面一大推的期望表达式可以转化为求导来完成,这个技巧大大简化了计算量。
回到我们ELBO第一项的展开如下:$$\begin{align} E_q[logp(\beta|\eta)] & = E_q[log(\frac{\Gamma(\sum\limits_{i=1}^V\eta_i)}{\prod_{i=1}^V\Gamma(\eta_i)}\prod_{i=1}^V\beta_{i}^{\eta_i-1})] \\ & = Klog\Gamma(\sum\limits_{i=1}^V\eta_i) - K\sum\limits_{i=1}^Vlog\Gamma(\eta_i) + \sum\limits_{k=1}^KE_q[\sum\limits_{i=1}^V(\eta_i-1) log\beta_{ki}] \end{align} $$
第(15)式的第三项的期望部分,可以用上面讲到的指数分布族的性质,转化为一个求导过程。即:$$E_q[\sum\limits_{i=1}^Vlog\beta_{ki}] = (log\Gamma(\lambda_{ki} ) - log\Gamma(\sum\limits_{i^{'}=1}^V\lambda_{ki^{'}}))^{'} = \Psi(\lambda_{ki}) - \Psi(\sum\limits_{i^{'}=1}^V\lambda_{ki^{'}})$$
其中:$$\Psi(x) = \frac{d}{d x}log\Gamma(x) = \frac{\Gamma^{'}(x)}{\Gamma(x)}$$
最终,我们得到EBLO第一项的展开式为:$$\begin{align} E_q[logp(\beta|\eta)] & = Klog\Gamma(\sum\limits_{i=1}^V\eta_i) - K\sum\limits_{i=1}^Vlog\Gamma(\eta_i) + \sum\limits_{k=1}^K\sum\limits_{i=1}^V(\eta_i-1)(\Psi(\lambda_{ki}) - \Psi(\sum\limits_{i^{'}=1}^V\lambda_{ki^{'}}) ) \end{align} $$
类似的方法求解其他6项,可以得到ELBO的最终关于变分参数$\lambda,\phi, \gamma$的表达式。其他6项的表达式为:$$\begin{align} E_q[logp(z|\theta)] = \sum\limits_{n=1}^N\sum\limits_{k=1}^K\phi_{nk}\Psi(\gamma_{k}) - \Psi(\sum\limits_{k^{'}=1}^K\gamma_{k^{'}}) \end{align} $$
$$\begin{align} E_q[logp(\theta|\alpha)] & = log\Gamma(\sum\limits_{k=1}^K\alpha_k) - \sum\limits_{k=1}^Klog\Gamma(\alpha_k) + \sum\limits_{k=1}^K(\alpha_k-1)(\Psi(\gamma_{k}) - \Psi(\sum\limits_{k^{'}=1}^K\gamma_{k^{'}})) \end{align} $$
$$\begin{align} E_q[logp(w|z, \beta)] & = \sum\limits_{n=1}^N\sum\limits_{k=1}^K\sum\limits_{i=1}^V\phi_{nk}w_n^i(\Psi(\lambda_{ki}) - \Psi(\sum\limits_{i^{'}=1}^V\lambda_{ki^{'}}) ) \end{align} $$
$$\begin{align} E_q[logq(\beta|\lambda)] = \sum\limits_{k=1}^K(log\Gamma(\sum\limits_{i=1}^V\lambda_{ki}) - \sum\limits_{i=1}^Vlog\Gamma(\lambda_{ki})) + \sum\limits_{k=1}^K\sum\limits_{i=1}^V (\lambda_{ki}-1)(\Psi(\lambda_{ki}) - \Psi(\sum\limits_{i^{'}=1}^V\lambda_{ki^{'}}) )\end{align} $$
$$\begin{align} E_q[logq(z|\phi)] & = \sum\limits_{n=1}^N\sum\limits_{k=1}^K\phi_{nk}log\phi_{nk} \end{align} $$
$$\begin{align} E_q[logq(\theta|\gamma)] & = log\Gamma(\sum\limits_{k=1}^K\gamma_k) - \sum\limits_{k=1}^Klog\Gamma(\gamma_k) + \sum\limits_{k=1}^K(\gamma_k-1)(\Psi(\gamma_{k}) - \Psi(\sum\limits_{k^{'}=1}^K\gamma_{k^{'}}))\end{align} $$
有了ELBO的具体的关于变分参数$\lambda,\phi, \gamma$的表达式,我们就可以用EM算法来迭代更新变分参数和模型参数了。
4. EM算法之E步:获取最优变分参数
有了前面变分推断得到的ELBO函数为基础,我们就可以进行EM算法了。但是和EM算法不同的是这里的E步需要在包含期望的EBLO计算最佳的变分参数。如何求解最佳的变分参数呢?通过对ELBO函数对各个变分参数$\lambda,\phi, \gamma$分别求导并令偏导数为0,可以得到迭代表达式,多次迭代收敛后即为最佳变分参数。
这里就不详细推导了,直接给出各个变分参数的表达式如下:
$$\begin{align} \phi_{nk} & \propto exp(\sum\limits_{i=1}^Vw_n^i(\Psi(\lambda_{ki}) - \Psi(\sum\limits_{i^{'}=1}^V\lambda_{ki^{'}}) ) + \Psi(\gamma_{k}) - \Psi(\sum\limits_{k^{'}=1}^K\gamma_{k^{'}}))\end{align} $$
其中,$w_n^i =1$当且仅当文档中第$n$个词为词汇表中第$i$个词。
$$\begin{align} \gamma_k & = \alpha_k + \sum\limits_{n=1}^N\phi_{nk} \end{align} $$
$$\begin{align} \lambda_{ki} & = \eta_i + \sum\limits_{n=1}^N\phi_{nk}w_n^i \end{align} $$
由于变分参数$\lambda$决定了$\beta$的分布,对于整个语料是共有的,因此我们有:
$$\begin{align} \lambda_{ki} & = \eta_i + \sum\limits_{d=1}^M\sum\limits_{n=1}^{N_d}\phi_{dnk}w_{dn}^i \end{align} $$
最终我们的E步就是用(23)(24)(26)式来更新三个变分参数。当我们得到三个变分参数后,不断循环迭代更新,直到这三个变分参数收敛。当变分参数收敛后,下一步就是M步,固定变分参数,更新模型参数$\alpha,\eta$了。
5. EM算法之M步:更新模型参数
由于我们在E步,已经得到了当前最佳变分参数,现在我们在M步就来固定变分参数,极大化ELBO得到最优的模型参数$\alpha,\eta$。求解最优的模型参数$\alpha,\eta$的方法有很多,梯度下降法,牛顿法都可以。LDA这里一般使用的是牛顿法,即通过求出ELBO对于$\alpha,\eta$的一阶导数和二阶导数的表达式,然后迭代求解$\alpha,\eta$在M步的最优解。
对于$\alpha$,它的一阶导数和二阶导数的表达式为:$$\nabla_{\alpha_k}L = M(\Psi(\sum\limits_{k^{'}=1}^K\alpha_{k^{'}}) - \Psi(\alpha_{k}) ) + \sum\limits_{d=1}^M(\Psi^{'}(\gamma_{dk}) - \Psi^{'}(\sum\limits_{k^{'}=1}^K\gamma_{dk^{'}}))$$
$$\nabla_{\alpha_k\alpha_j}L = M(\Psi^{'}(\sum\limits_{k^{'}=1}^K\alpha_{k^{'}})- \delta(k,j)\Psi^{'}(\alpha_{k}) )$$
其中,当且仅当$k=j$时,$\delta(k,j)=1$,否则$\delta(k,j)=0$。
对于$\eta$,它的一阶导数和二阶导数的表达式为:$$\nabla_{\eta_i}L = K(\Psi(\sum\limits_{i^{'}=1}^V\eta_{i^{'}}) - \Psi(\eta_{i}) ) + \sum\limits_{k=1}^K(\Psi^{'}(\lambda_{ki}) - \Psi^{'}(\sum\limits_{i^{'}=1}^V\lambda_{ki^{'}}))$$
$$\nabla_{\eta_i\eta_j}L = K(\Psi^{'}(\sum\limits_{i^{'}=1}^V\eta_{i^{'}}) - \delta(i,j)\Psi^{'}(\eta_{i}) )$$
其中,当且仅当$i=j$时,$\delta(i,j)=1$,否则$\delta(i,j)=0$。
最终牛顿法法迭代公式为:$$\begin{align} \alpha_{k+1} = \alpha_k + \frac{\nabla_{\alpha_k}L}{\nabla_{\alpha_k\alpha_j}L} \end{align}$$
$$\begin{align} \eta_{i+1} = \eta_i+ \frac{\nabla_{\eta_i}L}{\nabla_{\eta_i\eta_j}L} \end{align}$$
6. LDA变分推断EM算法流程总结
下面总结下LDA变分推断EM的算法的概要流程。
输入:主题数$K$,M个文档与对应的词。
1) 初始化$\alpha,\eta$向量。
2)开始EM算法迭代循环直到收敛。
a) 初始化所有的$\phi, \gamma, \lambda$,进行LDA的E步迭代循环,直到$\lambda,\phi, \gamma$收敛。
(i) for d from 1 to M:
for n from 1 to $N_d$:
for k from 1 to K:
按照(23)式更新$\phi_{nk}$
标准化$\phi_{nk}$使该向量各项的和为1.
按照(24) 式更新$\gamma_{k}$。
(ii) for k from 1 to K:
for i from 1 to V:
按照(26) 式更新$\lambda{ki}$。
(iii)如果$\phi, \gamma, \lambda$均已收敛,则跳出a)步,否则回到(i)步。
b) 进行LDA的M步迭代循环, 直到$\alpha,\eta$收敛
(i) 按照(27)(28)式用牛顿法迭代更新$\alpha,\eta$直到收敛
c) 如果所有的参数均收敛,则算法结束,否则回到第2)步。
算法结束后,我们可以得到模型的后验参数$\alpha,\eta$,以及我们需要的模型主题词分布$\lambda$,以及训练文档主题分布$\theta$。
(欢迎转载,转载请注明出处。欢迎沟通交流: pinard.liu@ericsson.com)
文本主题模型之LDA(三) LDA求解之变分推断EM算法的更多相关文章
- 文本主题模型之LDA(二) LDA求解之Gibbs采样算法
文本主题模型之LDA(一) LDA基础 文本主题模型之LDA(二) LDA求解之Gibbs采样算法 文本主题模型之LDA(三) LDA求解之变分推断EM算法(TODO) 本文是LDA主题模型的第二篇, ...
- 文本主题模型之LDA(一) LDA基础
文本主题模型之LDA(一) LDA基础 文本主题模型之LDA(二) LDA求解之Gibbs采样算法 文本主题模型之LDA(三) LDA求解之变分推断EM算法(TODO) 在前面我们讲到了基于矩阵分解的 ...
- 文本主题模型之非负矩阵分解(NMF)
在文本主题模型之潜在语义索引(LSI)中,我们讲到LSI主题模型使用了奇异值分解,面临着高维度计算量太大的问题.这里我们就介绍另一种基于矩阵分解的主题模型:非负矩阵分解(NMF),它同样使用了矩阵分解 ...
- 我是这样一步步理解--主题模型(Topic Model)、LDA
1. LDA模型是什么 LDA可以分为以下5个步骤: 一个函数:gamma函数. 四个分布:二项分布.多项分布.beta分布.Dirichlet分布. 一个概念和一个理念:共轭先验和贝叶斯框架. 两个 ...
- 文本主题模型之潜在语义索引(LSI)
在文本挖掘中,主题模型是比较特殊的一块,它的思想不同于我们常用的机器学习算法,因此这里我们需要专门来总结文本主题模型的算法.本文关注于潜在语义索引算法(LSI)的原理. 1. 文本主题模型的问题特点 ...
- 隐马尔科夫模型,第三种问题解法,维比特算法(biterbi) algorithm python代码
上篇介绍了隐马尔科夫模型 本文给出关于问题3解决方法,并给出一个例子的python代码 回顾上文,问题3是什么, 下面给出,维比特算法(biterbi) algorithm 下面通过一个具体例子,来说 ...
- 用scikit-learn学习LDA主题模型
在LDA模型原理篇我们总结了LDA主题模型的原理,这里我们就从应用的角度来使用scikit-learn来学习LDA主题模型.除了scikit-learn, 还有spark MLlib和gensim库 ...
- 自然语言处理之LDA主题模型
1.LDA概述 在机器学习领域,LDA是两个常用模型的简称:线性判别分析(Linear Discriminant Analysis)和 隐含狄利克雷分布(Latent Dirichlet Alloca ...
- LDA主题模型评估方法–Perplexity
在LDA主题模型之后,需要对模型的好坏进行评估,以此依据,判断改进的参数或者算法的建模能力. Blei先生在论文<Latent Dirichlet Allocation>实验中用的是Per ...
随机推荐
- 老李推荐:第6章7节《MonkeyRunner源码剖析》Monkey原理分析-事件源-事件源概览-注入按键事件实例
老李推荐:第6章7节<MonkeyRunner源码剖析>Monkey原理分析-事件源-事件源概览-注入按键事件实例 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜 ...
- 博客搬到CSDN了
新博客地址: http://blog.csdn.net/enlangs
- Vxlan与网卡offload性能
背景 由于数据链路层MTU的限制,发送端TCP/UDP数据在交付到IP层时需要与MTU相匹配,TCP数据不能超过mss,较长的UDP需要分片(Fragmentation)以满足MTU要求:接收端协议栈 ...
- Java NIO之Buffers
一.前言 在笔者打算学习Netty框架时,发现很有必要先学习NIO,因此便有了本博文,首先介绍的是NIO中的缓冲. 二.缓冲 2.1 层次结构图 除了布尔类型外,其他基本类型都有相对应的缓冲区类,其继 ...
- Html 经典布局(三)
经典布局案例(三): <!DOCTYPE html> <html lang="en"> <head> <meta charset=&quo ...
- NSUserDefaults registerDefaults
NSUserDefaults除了保存和读取功能外,还为我们提供了一个很便捷的方法:registerDefaults. func registerDefaults(registrationDiction ...
- 分享一本书<<谁都不敢欺负你>>
有些人,不管在工作还是生活上,总是被人欺负. 分享这本书给大家,能给大家带来正能量.你强大了,就没人敢欺负你. 有的时候,感到为什么倒霉的总是我?为什么我的命运是这样?为什么总欺负我? 也许有很多人会 ...
- 海康/大华 IpCamera RTSP地址和格式
海康:rtsp://[username]:[password]@[ip]:[port]/[codec]/[channel]/[subtype]/av_stream说明:username: 用户名.例如 ...
- UITableView grouped样式使用探索
UITableView的style有plain和grouped两种样式,两种样式各有不同的风格和功能,plain样式已经封装好了悬停功能,gouped样式则为我们在区头和区尾在实际项目开发中需要我们选 ...
- placeholder各种浏览器兼容问题
只要在页面上引入placeholder.min文件,再以$('input,textarea').placeholder(); 就可以兼容ie等各种浏览器. placeholder.min.js文件链接 ...