hadoop高可靠性HA集群
概述
简单hdfs高可用架构图
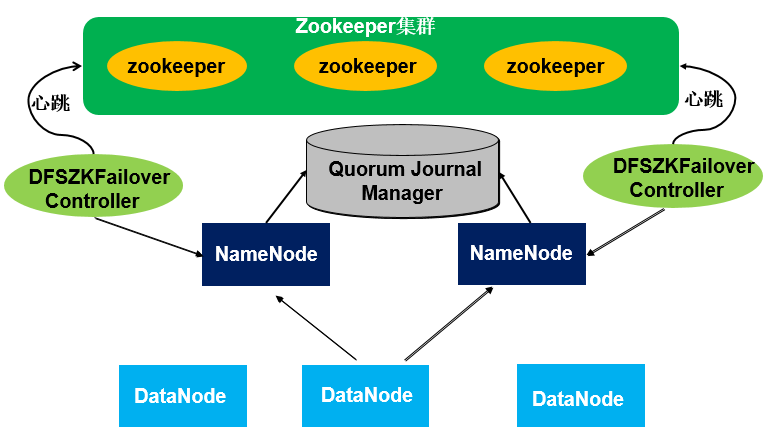
在hadoop2.x中通常由两个NameNode组成,一个处于active状态,另一个处于standby状态。Active NameNode对外提供服务,而Standby NameNode则不对外提供服务,仅同步active namenode的状态,以便能够在它失败时快速进行切换。
hadoop2.x官方提供了两种HDFS HA的解决方案,一种是NFS,另一种是QJM。这里楼主使用简单的QJM。在该方案中,主备NameNode之间通过一组JournalNode同步元数据信息,一条数据只要成功写入多数JournalNode即认为写入成功。通常配置奇数个JournalNode(我配了3个)。
这里还配置了一个zookeeper集群,用于ZKFC(DFSZKFailoverController)故障转移,当Active NameNode挂掉了,会自动切换Standby NameNode为standby状态。hadoop2.4以前的版本中依然存在一个问题,就是ResourceManager只有一个,存在单点故障,2.4以后解决了这个问题,有两个ResourceManager,一个是Active,一个是Standby,状态由zookeeper进行协调。yarn的HA配置楼主会给出配置文件,受环境影响,这里就不搭建yarn的高可用性了。
主要步骤
- 备6台Linux机器
- 安装JDK、配置主机名、修改IP地址、关闭防火墙
- 配置SSH免登陆
- 安装zookeeper集群
- zookeeper、hadoop环境变量配置
- 核心配置文件修改
- 启动zookeeper集群
- 启动journalnode
- 格式化文件系统、格式化zk
- 启动hdfs、启动yarn
前期准备
集群规划
| 主机名 | IP | 安装软件 | 进程 |
| hadoop01 | 192.168.8.101 | jdk、hadoop | NameNode、DFSZKFailoverController(zkfc) |
| hadoop02 | 192.168.8.102 | jdk、hadoop | NameNode、DFSZKFailoverController(zkfc) |
| hadoop03 | 192.168.8.103 | jdk、hadoop | ResourceManager |
| hadoop04 | 192.168.8.104 | jdk、hadoop、zookeeper | DataNode、NodeManager、JournalNode、QuorumPeerMain |
| hadoop05 | 192.168.8.105 | jdk、hadoop、zookeeper | DataNode、NodeManager、JournalNode、QuorumPeerMain |
| hadoop06 | 192.168.8.106 | jdk、hadoop、zookeeper | DataNode、NodeManager、JournalNode、QuorumPeerMain |
Linux环境
1.由于楼主机器硬件环境的限制,这里只准备了6台centos7的系统。

2.修改IP。如果跟楼主一样使用VM搭集群,请使用only-host模式。
vim /etc/sysconfig/network-scripts/ifcfg-ens3<!--这里不一定是ifcfg-ens3,取决于你的网卡信息-->
TYPE="Ethernet"
BOOTPROTO="static"
DEFROUTE="yes"
PEERDNS="yes"
PEERROUTES="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_PEERDNS="yes"
IPV6_PEERROUTES="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="7f13c30b-0943-49e9-b25d-8aa8cab95e20"
DEVICE="ens33"
ONBOOT="yes"
IPADDR="192.168.8.101"<!--每台机器按照分配的IP进行配置-->
NETMASK="255.255.255.0"
GATEWAY="192.168.8.1"
3.修改主机名和IP的映射关系
vim /etc/host 192.168.8.101 hadoop01
192.168.8.102 hadoop02
192.168.8.103 hadoop03
192.168.8.104 hadoop04
192.168.8.105 hadoop05
192.168.8.106 hadoop06
4.关闭防火墙
systemctl stop firewalld.service //停止firewall
systemctl disable firewalld.service //禁止firewall开机启动
5.修改主机名
hostnamectl set-hostname hadoop01
hostnamectl set-hostname hadoop02
hostnamectl set-hostname hadoop03
hostnamectl set-hostname hadoop04
hostnamectl set-hostname hadoop05
hostnamectl set-hostname hadoop06
6.ssh免登陆
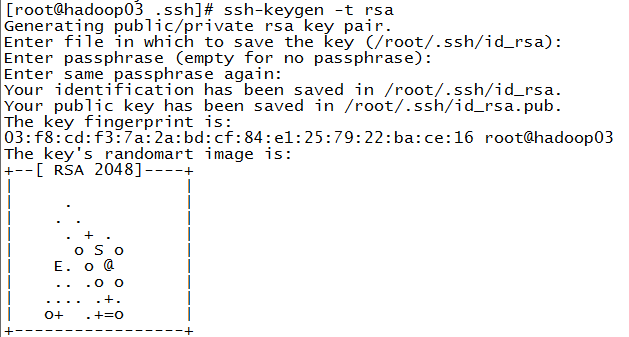
生成公钥、私钥
ssh-keygen -t rsa //一直回车
将公钥发送到其他机器
ssh-coyp-id hadoop01
ssh-coyp-id hadoop02
ssh-coyp-id hadoop03
ssh-coyp-id hadoop04
ssh-coyp-id hadoop05
ssh-coyp-id hadoop06
7.安装JDK,配置环境变量
hadoop01,hadoop02,hadoop03
export JAVA_HOME=/usr/jdk1.7.0_60
export HADOOP_HOME=/home/hadoop/hadoop-2.7.3
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
hadoop04,hadoop05,hadoop06(包含zookeeper)
export JAVA_HOME=/usr/jdk1.7.0_60
export HADOOP_HOME=/home/hadoop/hadoop-2.7.3
export ZOOKEEPER_HOME=/home/hadoop/zookeeper-3.4.10
export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
zookeeper集群安装
1.上传zk安装包
上传到/home/hadoop
2.解压
tar -zxvf zookeeper-3.4.10.tar.gz
3.配置(先在一台节点上配置)
在conf目录,更改zoo_sample.cfg文件为zoo.cfg
mv zoo_sample.cfg zoo.cfg
修改配置文件(zoo.cfg)
dataDir=/home/hadoop/zookeeper-3.4.10/data
server.1=hadoop04:2888:3888
server.2=hadoop05:2888:3888
server.3=hadoop06:2888:3888
在(dataDir=/home/hadoop/zookeeper-3.4.10/data)创建一个myid文件,里面内容是server.N中的N(server.2里面内容为2)
echo "5" > myid
4.将配置好的zk拷贝到其他节点
scp -r /home/hadoop/zookeeper-3.4.5/ hadoop05:/home/hadoop
scp -r /home/hadoop/zookeeper-3.4.5/ hadoop06:/home/hadoop
注意:在其他节点上一定要修改myid的内容
在hadoop05应该将myid的内容改为2 (echo "6" > myid)
在hadoop06应该将myid的内容改为3 (echo "7" > myid)
5.启动集群
分别启动hadoop04,hadoop05,hadoop06上的zookeeper
zkServer.sh start
hadoop2.7.3集群安装
1.解压
tar -zxvf hadoop-2.7.3.tar.gz
2.配置core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.7.3/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop04:2181,hadoop05:2181,hadoop06:2181</value>
</property>
</configuration>
3.配置hdf-site.xml
<configuration>
<!--指定hdfs的nameservice为ns1,必须和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>hadoop01:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>hadoop01:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>hadoop02:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>hadoop02:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop04:8485;hadoop05:8485;hadoop06:8485/ns1</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>file:/home/hadoop/hadoop-2.7.3/journal</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,每个机制占用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
4.配置mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5.配置yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties -->
<!-- 指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop03</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
6.配置slaves
hadoop04
hadoop05
hadoop06
7.将配置好的hadoop拷贝到其他节点
scp -r /home/hadoop/hadoop-2.7.3 hadoop02:/home/hadoop
scp -r /home/hadoop/hadoop-2.7.3 hadoop03:/home/hadoop
scp -r /home/hadoop/hadoop-2.7.3 hadoop04:/home/hadoop
scp -r /home/hadoop/hadoop-2.7.3 hadoop05:/home/hadoop
scp -r /home/hadoop/hadoop-2.7.3 hadoop06:/home/hadoop
启动
1.启动zookeeper集群(分别在hadoop04,hadoop05,hadoop06上启动zookeeper)
zkServer.sh start
2.查看zookeeper状态
zkServer.sh status
包含一个leader,二个follower



3.启动journalnode(分别在hadoop04,hadoop05,hadoop06上执行)
hadoop-daemon.sh start journalnode
运行jps命令检验,hadoop04,hadoop05,hadoop06上多了JournalNode进程
4.格式化HDFS
在hadoop01上执行命令:
hdfs namenode -format
检查是否成功看终端知否打印:

格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,这里楼主配置的是/home/hadoop/hadoop-2.7.3/tmp,然后将/home/hadoop/hadoop-2.7.3/tmp拷贝到ihadoop02的/home/hadoop/hadoop-2.7.3/下。
scp -r tmp/ hadoop02:/hadoop/hadoop-2.7.3/
5.格式化ZK(在hadoop01上执行即可)
hdfs zkfc -formatZK
效果如下(前面有点多截不下来,只截取了后面一部分):

6.启动HDFS(在hadoop01上执行)
start-dfs.sh
7.启动YARN(在hadoop03上执行)
start-yarn.sh
验证
到此,hadoop-2.7.3集群全部配置完毕,下面我们来验证:
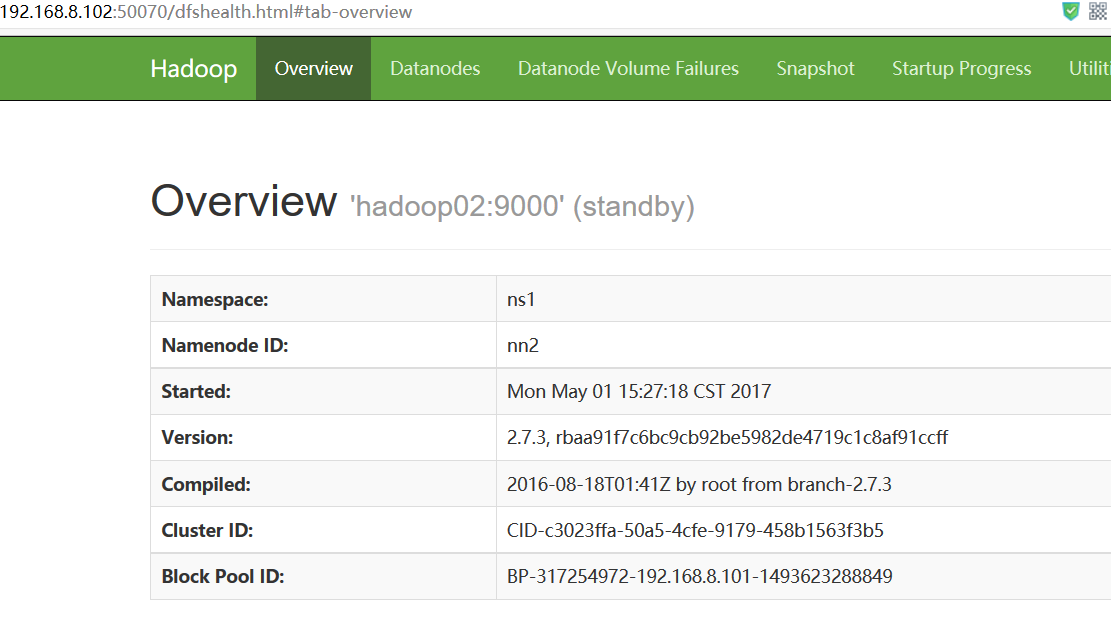
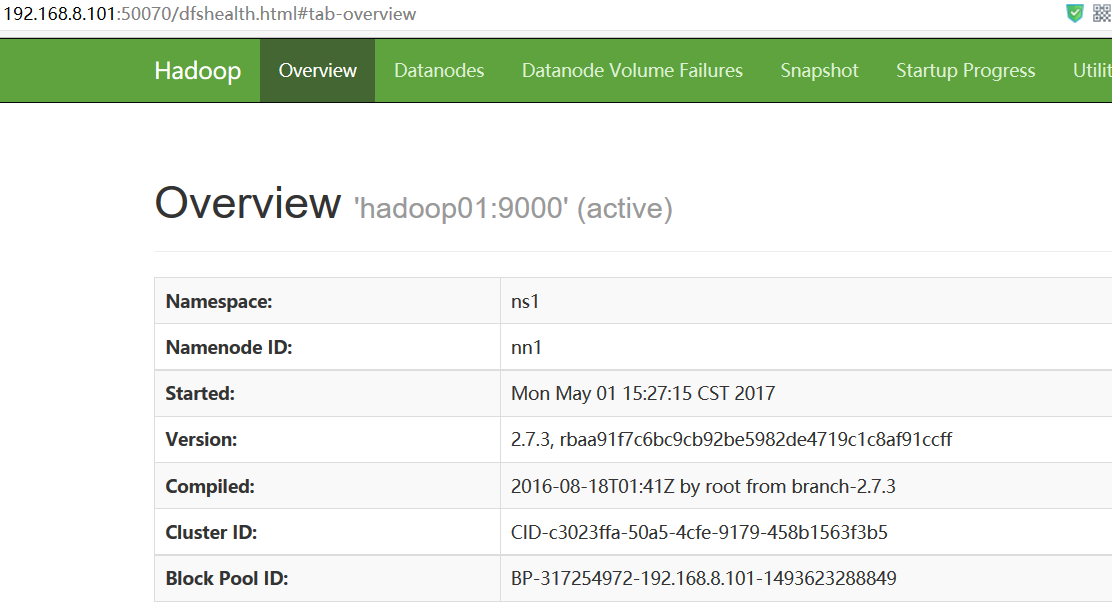
浏览器访问http://192.168.8.101:50070 NameNode 'hadoop01:9000' (active)
http://192.168.8.102:50070 NameNode 'hadoop02:9000' (standby)
浏览器访问resourceManager:http://192.168.8.103:8088
我们可以模拟NameNode(active)宕机,来验证HDFS的HA是否有效,NameNode(active)宕机后,NameNode(standby)会转为active状态,这里楼主不在演示。
结语
官网给出的文档还是比较详细的,楼主也是提取了官网的QJM解决方案来进行搭建。另外,yarn的HA搭建官网也给出了具体配置,有兴趣的同学可以试一试。
hadoop高可靠性HA集群的更多相关文章
- corosync+pacemaker实现高可用(HA)集群
corosync+pacemaker实现高可用(HA)集群(一) 重要概念 在准备部署HA集群前,需要对其涉及的大量的概念有一个初步的了解,这样在实际部署配置时,才不至于不知所云 资源.服务与 ...
- heartbeat+nginx搭建高可用HA集群
前言: HA即(high available)高可用,又被叫做双机热备,用于关键性业务.简单理解就是,有2台机器 A 和 B,正常是 A 提供服务,B 待命闲置,当 A 宕机或服务宕掉,会切换至B机器 ...
- 基于zookeeper的高可用Hadoop HA集群安装
(1)hadoop2.7.1源码编译 http://aperise.iteye.com/blog/2246856 (2)hadoop2.7.1安装准备 http://aperise.iteye.com ...
- 大数据Hadoop的HA高可用架构集群部署
1 概述 在Hadoop 2.0.0之前,一个Hadoop集群只有一个NameNode,那么NameNode就会存在单点故障的问题,幸运的是Hadoop 2.0.0之后解决了这个问题,即支持N ...
- 菜鸟玩云计算之十九:Hadoop 2.5.0 HA 集群安装第2章
菜鸟玩云计算之十九:Hadoop 2.5.0 HA 集群安装第2章 cheungmine, 2014-10-26 在上一章中,我们准备好了计算机和软件.本章开始部署hadoop 高可用集群. 2 部署 ...
- 菜鸟玩云计算之十八:Hadoop 2.5.0 HA 集群安装第1章
菜鸟玩云计算之十八:Hadoop 2.5.0 HA 集群安装第1章 cheungmine, 2014-10-25 0 引言 在生产环境上安装Hadoop高可用集群一直是一个需要极度耐心和体力的细致工作 ...
- hadoop HA集群搭建步骤
NameNode DataNode Zookeeper ZKFC JournalNode ResourceManager NodeManager node1 √ √ √ √ node2 ...
- ZooKeeper学习之路 (九)利用ZooKeeper搭建Hadoop的HA集群
Hadoop HA 原理概述 为什么会有 hadoop HA 机制呢? HA:High Available,高可用 在Hadoop 2.0之前,在HDFS 集群中NameNode 存在单点故障 (SP ...
- Hadoop HA集群的搭建
HA 集群搭建的难度主要在于配置文件的编写, 心细,心细,心细! ha模式下,secondary namenode节点不存在... 集群部署节点角色的规划(7节点)------------------ ...
随机推荐
- #include<bits/stdc++.h>
在听学长讲课时看到了#include<bits/stdc++.h>这个头文件,瞬间懵逼辣,百度后了解了 #include<bits/stdc++.h>,包含了C++的所有头文件 ...
- JavaWeb之JSTL标签
JSP中有了EL可以很方便的引用对象和属性,但是也有一些不足的地方,比如不能遍历对象列表这些,再加上JSTL(Java Standard Tag Library)的话那就完美了.JSTL主要包括cor ...
- 元素类型为 "package" 的内容必须匹配 "(result-types?,interceptors?,default-interceptor-ref?
该错误为struts.xml内配置文件节点顺序错误. package内的元素节点必须按照以下顺序排放: result-types interceptors defau ...
- SQL AlawaysOn 之四:故障转移集群
声明,故障转移集群,仅安装在SQL服务器中,域服务器不能和SQL服务器一起加入集群. 1.添加故障转移集群,下一步 2.安装 3.在域控制服务器上的管理工具里打开故不障转移集群管理器,选择创建集群 4 ...
- cuda内存总结
1.shared memory __shared__ 声明为共享内存,将会保存在共享内存中 2.constant memory __constant__ 声明为常量内存,将会保存在常量内存中,常量内 ...
- iOS开发之Xib和storyboard对比
相同点: (2)都用来描述软件界面 (2)都用Interface Builder工具来编辑 不同点: (1)Xib是轻量级的,用来描述局部的UI界面 (2)Storyboard是重量级的,用来描述整个 ...
- iOS开发之instancetype
instancetype和id使用方法类似,但他们还有不同点: (1)instancetype在类型表示上,跟id一样,可以表示任何对象类型 (2)instancetype只能用在返回值类型上,不能像 ...
- JS中的异步以及事件轮询机制
一.JS为何是单线程的? JavaScript语言的一大特点就是单线程,也就是说,同一个时间只能做一件事.那么,为什么JavaScript不能有多个线程呢?这样能提高效率啊.(在JAVA和c#中的异步 ...
- 机器学习:python中如何使用朴素贝叶斯算法
这里再重复一下标题为什么是"使用"而不是"实现": 首先,专业人士提供的算法比我们自己写的算法无论是效率还是正确率上都要高. 其次,对于数学不好的人来说,为了实 ...
- POJ1275出纳员的雇佣【差分约束】
出纳员的雇佣 Tehran的一家每天24小时营业的超市,需要一批出纳员来满足它的需要.超市经理雇佣你来帮他解决问题:超市在每天的不同时段需要不同数目的出纳员(例如:午夜时只需一小批,而下午则需要很多) ...