ms_celeb_1m数据提取(MsCelebV1-Faces-Aligned.tsv)python脚本
本文主要介绍了如何对MsCelebV1-Faces-Aligned.tsv文件进行提取
原创by南山南北秋悲
欢迎引用!请注明原地址 http://www.cnblogs.com/hwd9654/p/6796811.html 谢谢!
最近用caffe做人脸识别,一开始用lfw作为数据库,但是体量太小,只有五千多人的图片
后来想用李子青组的casia-webface,从网上找了个,下下来发现居然损坏了,好气啊! 想去官网申请,却发现!!!:
- Sign the agreement (The agreement must be signed by the director or the delegate of the deparmart of university. Personal applicant is not acceptable.
。。。。。。不接受个人申请,而lz的学院领导不给签字 - -
后来索性就直接拿微软的ms celeb 1m来训练
简介如下:官网地址(https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/)
MSR IRC是目前世界上规模最大、水平最高的图像识别赛事之一,由MSRA(微软亚洲研究院)图像分析、大数据挖掘研究组组长张磊发起
ms_celeb_1m就是这个比赛的数据集
从1M个名人中,根据他们的受欢迎程度,选择100K个。然后,利用搜索引擎,给100K个人,每人搜大概100张图片。共100K*100=10M个图片。
有三种下载选项:
1.完整版
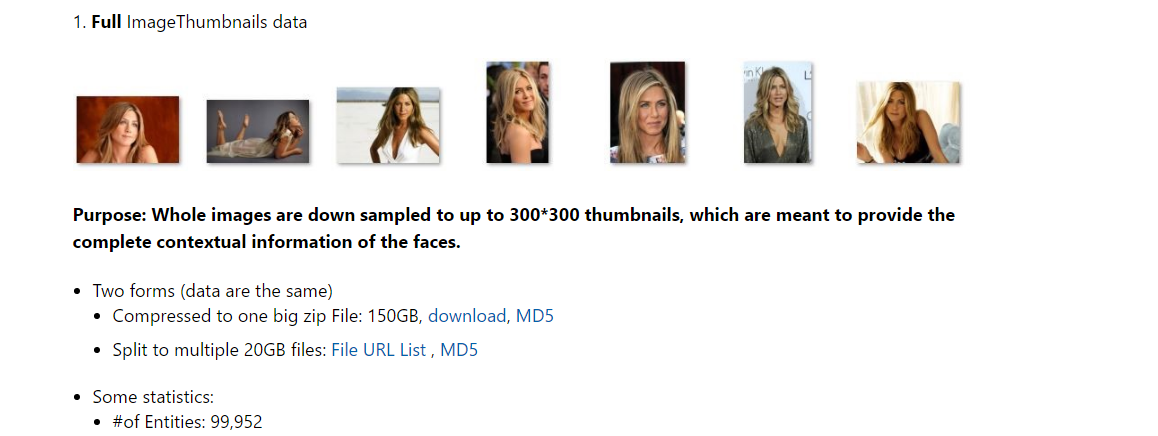
需要自己预处理,人脸检测,人脸对齐。。。
2.微处理版,修剪了一下
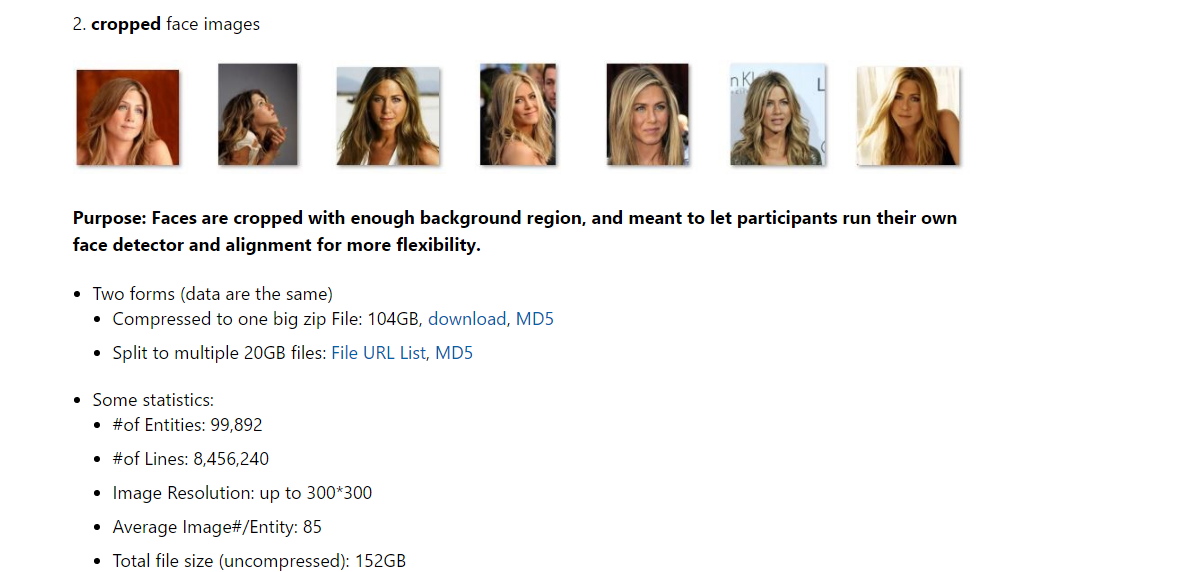
3.对齐过的版本
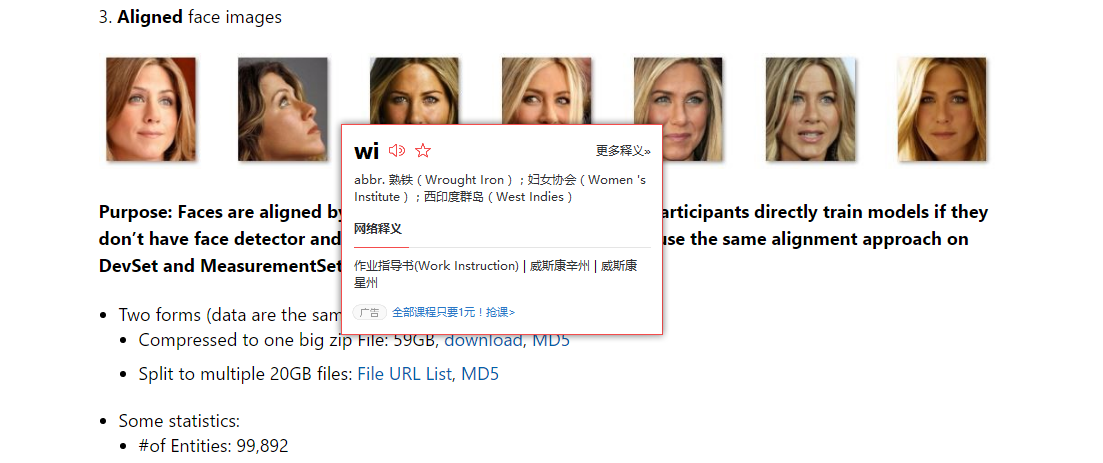
楼主用的是第三个对齐过的版本
下载下来是这么个玩意儿

好了废话不多说
直接上处理脚本
import base64
import csv
import os filename = "J:\dataset\ms_celeb_1m\MsCelebV1-Faces-Aligned.tsv"
outputDir = "I:\ms_celeb_1m" with open(filename, 'r') as tsvF:
reader = csv.reader(tsvF, delimiter='\t')
i = 0
for row in reader:
MID, imgSearchRank, faceID, data = row[0], row[1], row[4], base64.b64decode(row[-1]) saveDir = os.path.join(outputDir, MID)
savePath = os.path.join(saveDir, "{}-{}.jpg".format(imgSearchRank, faceID)) if not os.path.exists(saveDir):
os.mkdir(saveDir)
with open(savePath, 'wb') as f:
f.write(data) i += 1 if i % 1000 == 0:
print("Extracted {} images.".format(i))
自己改下相应路径就可以用了
处理结果:

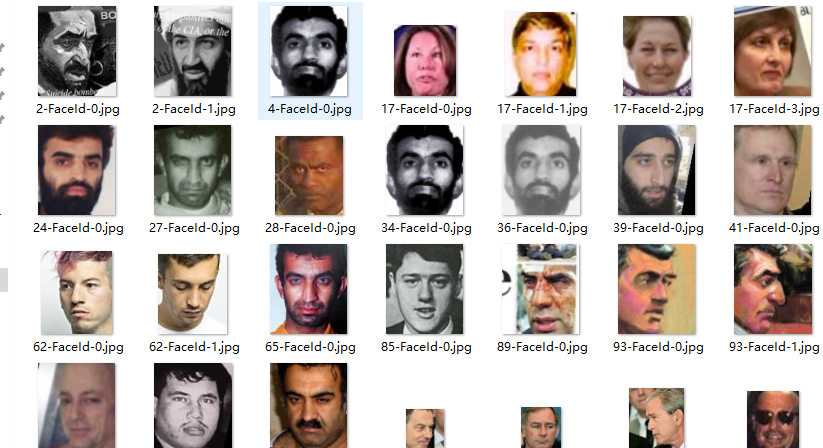
有什么疑问可以留言,不定期查看,慢回勿喷。。。
ms_celeb_1m数据提取(MsCelebV1-Faces-Aligned.tsv)python脚本的更多相关文章
- 使用Python脚本分析你的网站上的SEO元素
撰稿马尼克斯德芒克 上2019年1月, Sooda internetbureau Python就是自动执行重复性任务,为您的其他搜索引擎优化(SEO)工作留出更多时间.没有多少SEO使用Python来 ...
- 记录特殊情况的Python脚本的内存异常与处理
问题 Python 脚本使用 requests 模块做 HTTP 请求,验证代理 IP 的可用性,速度等. 设定 HTTP 请求的 connect timeout 与 read response ti ...
- Python爬虫10-页面解析数据提取思路方法与简单正则应用
GitHub代码练习地址:正则1:https://github.com/Neo-ML/PythonPractice/blob/master/SpiderPrac15_RE1.py 正则2:match. ...
- python 爬虫与数据可视化--数据提取与存储
一.爬虫的定义.爬虫的分类(通用爬虫.聚焦爬虫).爬虫应用场景.爬虫工作原理(最后会发一个完整爬虫代码) 二.http.https的介绍.url的形式.请求方法.响应状态码 url的形式: 请求头: ...
- 【学习】Python进行数据提取的方法总结【转载】
链接:http://www.jb51.net/article/90946.htm 数据提取是分析师日常工作中经常遇到的需求.如某个用户的贷款金额,某个月或季度的利息总收入,某个特定时间段的贷款金额和笔 ...
- Python爬虫教程-18-页面解析和数据提取
本篇针对的数据是已经存在在页面上的数据,不包括动态生成的数据,今天是对HTML中提取对我们有用的数据,去除无用的数据 Python爬虫教程-18-页面解析和数据提取 结构化数据:先有的结构,再谈数据 ...
- Python——爬虫——数据提取
一.XML数据提取 (1)定义:XML指可扩展标记语言.标记语言,标签需要我们自行定义 (2)设计宗旨:是传输数据,而非显示数据,具有自我描述性 (3)节点关系: 父:每个元素及属性都有一个父. ...
- python爬虫数据提取之bs4的使用方法
Beautiful Soup的使用 1.下载 pip install bs4 pip install lxml # 解析器 官方推荐 2.引用方法 from bs4 import BeautifulS ...
- 【转载】使用Pandas进行数据提取
使用Pandas进行数据提取 本文转载自:蓝鲸的网站分析笔记 原文链接:使用python进行数据提取 目录 set_index() ix 按行提取信息 按列提取信息 按行与列提取信息 提取特定日期的信 ...
随机推荐
- 跨平台的.NET邮件协议MailKit组件解析
发起的.NET Core开源组织号召,进展的速度是我自己也没有想到的,很多园友都积极参与(虽然有些人诚心砸场子,要是以我以前的宝脾气,这会应该被我打住院了吧,不过幸好是少数,做一件事总有人说好,也有人 ...
- java学习笔记 --- 数组
一.Java的内存分配 A:栈内存: 存储局部变量,只要是在方法中定义的变量都是局部变量.一旦变量的生命周期结束该变量就被释放. B:堆内存: 存储所有new出来的,及实体(对象),每一个实体 ...
- iOSiOS开发之数据存储之NSKeyedArchiver
1.概述 NSKeyedArchiver归档和plist文件存储不同的是NSKeyedArchiver可以直接保存对象.如果对象是NSString.NSDictionary.NSArray.NSDat ...
- c#中遍历各种数据集合的方法
1.遍历枚举类型 补:typeof()方法中只能传具体的类名.类型名称(int32...),不可以是变量名称.类似的方法有GetType(),GteType()方法继承自object,所以c#中任何对 ...
- CoreCLR源码探索(四) GC内存收集器的内部实现 分析篇
在这篇中我将讲述GC Collector内部的实现, 这是CoreCLR中除了JIT以外最复杂部分,下面一些概念目前尚未有公开的文档和书籍讲到. 为了分析这部分我花了一个多月的时间,期间也多次向Cor ...
- 浅谈MVC缓存
缓存是将信息放在内存中以避免频繁访问数据库从数据库中提取数据,在系统优化过程中,缓存是比较普遍的优化做法和见效比较快的做法. 对于MVC有Control缓存和Action缓存. 一.Control缓存 ...
- 串的模式匹配和KMP算法
在对字符串的操作中,我们经常要用到子串的查找功能,我们称子串为模式串,模式串在主串中的查找过程我们成为模式匹配,KMP算法就是一个高效的模式匹配算法.KMP算法是蛮力算法的一种改进,下面我们先来介绍蛮 ...
- js中的this关键字,setTimeout(),setInterval()的执行过程
var test1 = { name: 'windseek1', showname: function () { console.log(this.name); } } var test2 = { n ...
- java设计模式之桥接模式
桥接模式 桥接(Bridge)是用于把抽象化与实现化解耦,使得二者可以独立变化.这种类型的设计模式属于结构型模式,它通过提供抽象化和实现化之间的桥接结构,来实现二者的解耦.这种模式涉及到一个作为桥接的 ...
- 纯JS写动态分页样式效果
效果图如下: html: <body> <div> <table id="btnbox"> <tbody> <tr>&l ...