Python核心编程--浅拷贝与深拷贝
一、问题引出浅拷贝
首先看下面代码的执行情况:
a = [1, 2, 3]
print('a = %s' % a) # a = [1, 2, 3]
b = a
print('b = %s' % b) # b = [1, 2, 3]
a.append(4) # 对a进行修改
print('a = %s' % a) # a = [1, 2, 3, 4]
print('b = %s' % b) # b = [1, 2, 3, 4]
b.append(5) # 对b进行修改
print('a = %s' % a) # a = [1, 2, 3, 4, 5]
print('b = %s' % b) # b = [1, 2, 3, 4, 5]
上面的代码比较简单,定义了一个变量a,它是一个数值[1, 2, 3]的列表,通过一个简单的赋值语句 b = a 定义变量b,它同样也是数值[1, 2, 3]的列表。
问题是:如果此时修改变量a,对b会有影响吗?同样如果修改变量b,对a又会有影响吗?
从代码运行结果可以看出,无论是修改b还是修改a(注意这种修改的方式,是用append,直接修改原列表,而不是重新赋值),都另一方都是有影响的。
当然这个原因其实很好理解,变量a指向的是列表[1, 2, 3]的地址值,当用 = 进行赋值运算时,b的值也相应的指向的列表[1, 2, 3]的地址值。在python中,可以通过id(变量)的方法来查看地址值,我们来查看下a,b变量的地址值,看是不是相等:
# 注意,不同机器上,这个值不同,但只要a,b两个变量的地址值是一样的就能说明问题了 print(id(a)) # print(id(b)) #
所以原理如下图所示:
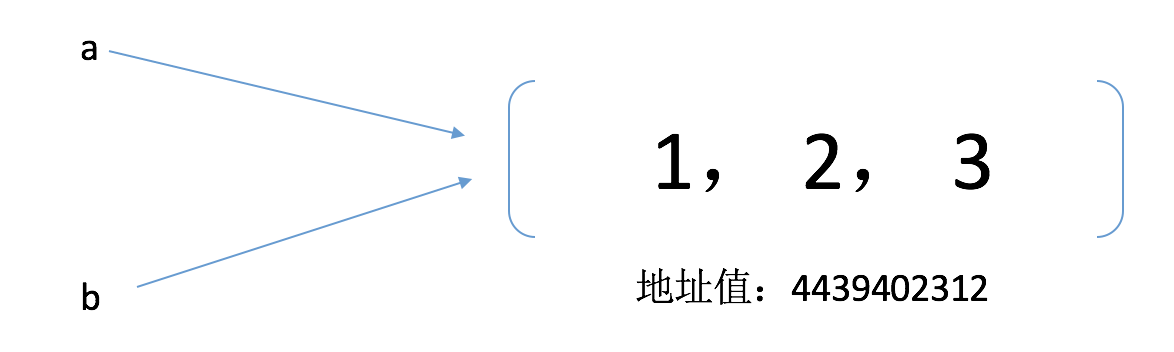
因此,只要是在地址值:4439402312上的列表进行修改的话,a,b都会发生变化。(注意我这里说的修改,是在地址值为:4439402312上的列表进行的修改,而不说对变量a进行修改,因为对变量a的修改方式有两种,本文结尾会解释为什么不说对变量a进行修改) 。所以我们便引出了以下概念:
对于这种是将引用进行拷贝赋值给另一个变量的方式(即拷贝的是地址值),我们称之为浅拷贝。
二、如何进行深拷贝
python中实现深拷贝的方式很简单,只需要引入copy模块,调用里面的deepcopy()的方法即可,示例代码如下:
import copy
a = [1, 2, 3]
b = copy.deepcopy(a) print('a = %s' % a) # a = [1, 2, 3]
print('b = %s' % b) # b = [1, 2, 3] b.append(4)
print('a = %s' % a) # a = [1, 2, 3]
print('b = %s' % b) # b = [1, 2, 3, 4]
从代码执行情况来看,我们已经实现了深拷贝。这时我们再来看下两个变量的地址值:
print(id(a)) #
print(id(b)) #
果然就不一样了。我们再通过一个图来看下深拷贝的原理:

三、copy模块方法简介
从深拷贝的实现过程,我们知道copy模块,也使用了里面的deepcopy()方法。下面我们来介绍下copy模块中的copy()与deepcopy()方法。
首先介绍我们已经使用过的deepcopy()方法,官方文档介绍如下:

简单解释下文档中对这个方法的说明:
1. 返回值是对这个对象的深拷贝
2. 如果拷贝发生错误,会报copy.err异常
3. 存在两个问题,第一是如果出递归对象,会递归的进行拷贝,第二正因为会递归拷贝,会导致出现拷贝过多的情况
4. 关于两种拷贝方式的区别都是相对是引用对象
前两点很好理解,针对第三点,我们用代码进行解释:
import copy
a = [1, 2, 3]
b = [3, 4, 5] c = [a, b] # 列表嵌套 d = copy.deepcopy(c)
print('c = %s' % c) # c = [[1, 2, 3], [3, 4, 5]]
print('d = %s' % d) # d = [[1, 2, 3], [3, 4, 5]] c.append(4)
print('c = %s' % c) # c = [[1, 2, 3], [3, 4, 5], 4]
print('d = %s' % d) # d = [[1, 2, 3], [3, 4, 5]] c[0].append(4) # 相当于a.append(4)
print('c = %s' % c) # c = [[1, 2, 3, 4], [3, 4, 5], 4]
print('d = %s' % d) # d = [[1, 2, 3], [3, 4, 5]] # a.append(4)
# print('c = %s' % c) # a = [1, 2, 3]
# print('d = %s' % d) # b = [1, 2, 3] print(id(c)) #
print(id(d)) # print(id(c[0])) #
print(id(d[0])) # print(id(a)) #
print(id(b)) #
根据代码,我们可以看到,当有嵌套对象,也就是文档中提到的递归对象,从结果我们可以看到,嵌套对象会进行递归的深拷贝。即如果c里有一个a,那么不仅c会深拷贝,a同样也会被深拷贝。原理如下图所求:

接下来我们再来看copy()方法:
官方文档解释的很简单,它返回的就是对象的浅拷贝。但其实它会对最外层进行深拷贝,而如果有多层,第二层以后进行的就是浅拷贝了。代码示例如下:
import copy
a = [1, 2, 3]
b = [3, 4, 5] c = [a, b] # 列表嵌套 d = copy.copy(c) print('c = %s' % c) # c = [[1, 2, 3], [3, 4, 5]]
print('d = %s' % d) # d = [[1, 2, 3], [3, 4, 5]] c.append(4)
print('c = %s' % c) # c = [[1, 2, 3], [3, 4, 5], 4]
print('d = %s' % d) # d = [[1, 2, 3], [3, 4, 5]] 没有发生变化,说明外层是深拷贝 c[0].append(4) # 相当于a.append(4)
print('c = %s' % c) # c = [[1, 2, 3, 4], [3, 4, 5], 4]
print('d = %s' % d) # d = [[1, 2, 3, 4], [3, 4, 5]] 发生了变化,说明内层是浅拷贝 # a.append(4)
# print('c = %s' % c) # c = [[1, 2, 3, 4], [3, 4, 5], 4]
# print('d = %s' % d) # d = [[1, 2, 3, 4], [3, 4, 5]] 发生了变化,说明内层是浅拷贝 print(id(c)) #
print(id(d)) # 4322576584 d和c地址不同,进一步说明外层是深拷贝 print(id(c[0])) #
print(id(d[0])) # 4322575176 c[0]和d[0]地址相同,进一步说明内层是浅拷贝 print(id(a)) #
print(id(b)) #
【注意】对于copy()方法,有特殊情况,比如元组类型,代码示例如下:
import copy
a = [1, 2, 3]
b = [3, 4, 5] c = (a, b) # 列表改成元组 d = copy.copy(c) print(id(c)) #
print(id(d)) # 4303015752 d和c地址相同 print(id(c[0])) #
print(id(d[0])) # 4322575176 c[0]和d[0]地址相同,进一步说明内层是浅拷贝
可以看到,这里哪怕是最外层,也是浅拷贝。
这里因为copy方法内部有判断,如果最外层的拷贝类型是不可变类型,则进行浅拷贝,反之则进行深拷贝。
至此,我们应该对浅拷贝的概念进行进一步加深理解:
如果对象中的所有元素,有一个是引用拷贝,则定义为是浅拷贝。(该定义不是官方定义,只是个人理解)
四、关于“修改”的一点说明
前面提到了修改变量,我认为修改是有两种方式,第一种在原对象上进行修改,第二种就是重新赋值。看如下代码:
import copy
a = [1, 2, 3]
b = a
a = [3, 4, 5]
print(a) # [3, 4, 5]
print(b) # [1, 2, 3]
同样是浅拷贝,但是发现修改a之后,b没有发生变化。
在修改的时候,我们很容易想当然的通过重新赋值的方式来修改,但其实这种修改方式是有问题的。当给a再次赋值的时候,其实是将a重新指向了另外一块地址区域,而原来的[1, 2, 3]那块地址区域是没有发生任何变化的,所以对于b来说,它指向的东西并没有改变。
这也解释了之前文档中关于deepcopy方法的一个说明,为什么只对引用对象有用,因为简单类型修改的方式就是重新赋值。简单理解就是你没办法通过简单类型的变量直接通过.来调用自身的方法,都只能重新赋值来改变,那么都会指向新的地址。

Python核心编程--浅拷贝与深拷贝的更多相关文章
- python核心编程第二版笔记
python核心编程第二版笔记由网友提供:open168 python核心编程--笔记(很详细,建议收藏) 解释器options:1.1 –d 提供调试输出1.2 –O 生成优化的字节码(生成 ...
- 学习《Python核心编程》做一下知识点提要,方便复习(一)
学习<Python核心编程>做一下知识点提要,方便复习. 计算机语言的本质是什么? a-z.A-Z.符号.数字等等组合成符合语法的字符串.供编译器.解释器翻译. 字母组合后产生各种变化拿p ...
- python核心编程--笔记
python核心编程--笔记 的解释器options: 1.1 –d 提供调试输出 1.2 –O 生成优化的字节码(生成.pyo文件) 1.3 –S 不导入site模块以在启动时查找pyt ...
- Python核心编程第二版(中文).pdf 目录整理
python核心编程目录 Chapter1:欢迎来到python世界!-页码:7 1.1什么是python 1.2起源 :罗萨姆1989底创建python 1.3特点 1.3.1高级 1.3.2面向 ...
- Python中的浅拷贝与深拷贝
编者注:本文主要参考了<Python核心编程(第二版)> 以下都是参考资料后,我自己的理解,如有错误希望大家不吝赐教. 大家有没有遇到这样一种情况,对象赋值后,对其中一个变量进行修改,另外 ...
- python核心编程--笔记(不定时跟新)(转)
的解释器options: 1.1 –d 提供调试输出 1.2 –O 生成优化的字节码(生成.pyo文件) 1.3 –S 不导入site模块以在启动时查找python路径 1.4 –v ...
- python核心编程笔记(转)
解释器options: 1.1 –d 提供调试输出 1.2 –O 生成优化的字节码(生成.pyo文件) 1.3 –S 不导入site模块以在启动时查找python路径 1.4 –v 冗 ...
- Python核心编程(第二版)PDF
Python核心编程(第二版) 目录 第1部分 Python核心第1章 欢迎来到Python世界1.1 什么是Python1.2 起源1.3 特点1.3.1 高级1.3.2 面向对象1.3.3 可升级 ...
- python核心编程(第二版)习题
重新再看一遍python核心编程,把后面的习题都做一下.
随机推荐
- ChatterBot之使用mongodb 03
上一篇我们已经搭建好了mongodb环境,本篇为简单示例. 废话不多说先上代码然后开始讲解; !!!别忘了打开你的mongdb服务!!!,如果没有mongodb请看上篇如何安装mongodb; # - ...
- 51Nod 1007 正整数分组 01背包
将一堆正整数分为2组,要求2组的和相差最小.例如:1 2 3 4 5,将1 2 4分为1组,3 5分为1组,两组和相差1,是所有方案中相差最少的.Input第1行:一个数N,N为正整数的数量.第2 - ...
- Chrome浏览器读写系统剪切板
IE浏览器支持直接读写剪切板内容: window.clipboardData.clearData(); window.clipboardData.setData('Text', 'abcd'); 但是 ...
- android boot.img
android在启动时uboot推断有没有组合健按下或者cache分区的升级文件来决定进入哪个系统(可能还有别的推断方式) 有组合健按下或者cache分区有升级文件,则载入recovery.img进入 ...
- VBScripts and UAC elevation(visa以后的系统)
这两天由于工作须要.在写一些vbs的脚本,才知道.vbs不能像其它可运行文件一样.在 须要提升訪问权限时.弹出UAC窗体.那么,怎样通过UAC提升vbs脚本的訪问权限呢? 查了一些资料,将结果整理一下 ...
- toolbar ,textfield,图片拉伸,Bundle
1 工具栏 UIToolbar 2 textField 协议方法 一旦TextField成为第一响应,此方法就会调用 - (void)textFieldDidBeginEditing:(U ...
- Cairo-Dock 系统关机无效
正文 背景 Cairo-Dock 设置为开机自己主动启动后.系统菜单条里的关机选项就无效了,命令行里能够使用命令关机. 搜索过程 这次google找到的结果让我非常失望,于是仅仅好百度了. 在百度贴吧 ...
- 数据库中的參照完整性(Foreign Key)
之前在项目中遇到了这样一个问题,我举得简单的样例来说明. 比方我们有两个表,一个表(department)存放的是部门的信息,比如部门id,部门名称等:还有一个表是员工表(staff),员工表里面肯定 ...
- 尝试造了个工具类库,名为 Diana
项目地址: diana 文档地址: http://muyunyun.cn/diana/ 造轮子的意义 为啥已经有如此多的前端工具类库还要自己造轮子呢?个人认为有以下几个观点吧: 定制性强,能根据自己的 ...
- 数据从文件导入Elasticsearch
1.资源准备 1.数据文件:accounts.json 2.索引名称:bank 3.数据类型:account 4.批量操作API:bulk 2.导入数据 curl -XPOST 'localhost: ...