python爬虫——写出最简单的网页爬虫
在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材。我们可以通过python 来实现这样一个简单的爬虫功能,把我们想要的代码爬取到本地。下面就看看如何使用python来实现这样一个功能。
一、开发工具
笔者使用的工具是sublimetext3,它的短小精悍(可能男人们都不喜欢这个词)使我十分着迷。推荐大家使用,当然如果你的电脑配置不错,pycharm可能更加适合你。
sublime text3搭建python开发环境推荐查看此博客:
[sublime搭建python开发环境][http://www.cnblogs.com/codefish/p/4806849.
二、爬虫介绍
爬虫顾名思义,就是像虫子一样,爬在Internet这张大网上。如此,我们便可以获取自己想要的东西。
既然要爬在Internet上,那么我们就需要了解URL,法号“统一资源定位器”,小名“链接”。其结构主要由三部分组成:
(1)协议:如我们在网址中常见的HTTP协议。
(2)域名或者IP地址:域名,如:www.baidu.com,IP地址,即将域名解析后对应的IP。
(3)路径:即目录或者文件等。
三、urllib开发最简单的爬虫
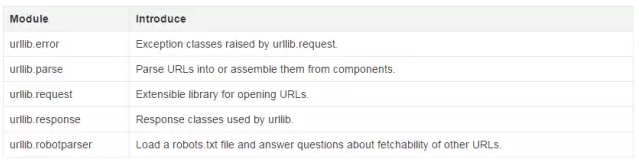
(1)urllib简介
(2)开发最简单的爬虫
百度首页简洁大方,很适合我们爬虫。
爬虫代码如下:

结果如图

我们可以通过在百度首页空白处右击,查看审查元素来和我们的运行结果对比。
当然,request也可以生成一个request对象,这个对象可以用urlopen方法打开。
代码如下:
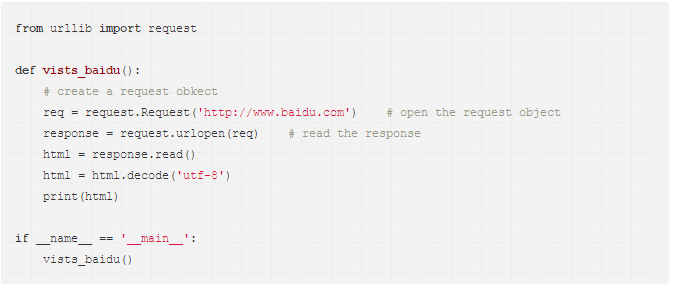
运行结果和刚才相同。
(3)错误处理
错误处理通过urllib模块来处理,主要有URLError和HTTPError错误,其中HTTPError错误是URLError错误的子类,即HTTRPError也可以通过URLError捕获。HTTPError可以通过其code属性来捕获。
处理HTTPError的代码如下:

运行结果如图:
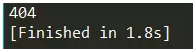
404为打印出的错误代码,关于此详细信息大家可以自行百度。
URLError可以通过其reason属性来捕获。
chuliHTTPError的代码如下:
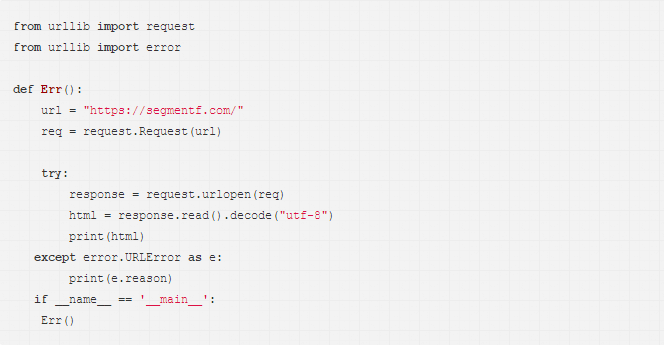
运行结果如图:

既然为了处理错误,那么最好两个错误都写入代码中,毕竟越细致越清晰。须注意的是,HTTPError是URLError的子类,所以一定要将HTTPError放在URLError的前面,否则都会输出URLError的,如将404输出为Not Found。
代码如下:

文章来源:https://segmentfault.com/a/1190000010567472
作者:xiaomi
交流QQ群:238757010
python爬虫——写出最简单的网页爬虫的更多相关文章
- python实现的一个简单的网页爬虫
学习了下python,看了一个简单的网页爬虫:http://www.cnblogs.com/fnng/p/3576154.html 自己实现了一个简单的网页爬虫,获取豆瓣的最新电影信息. 爬虫主要是获 ...
- (转)Python新手写出漂亮的爬虫代码2——从json获取信息
https://blog.csdn.net/weixin_36604953/article/details/78592943 Python新手写出漂亮的爬虫代码2——从json获取信息好久没有写关于爬 ...
- (转)Python新手写出漂亮的爬虫代码1——从html获取信息
https://blog.csdn.net/weixin_36604953/article/details/78156605 Python新手写出漂亮的爬虫代码1初到大数据学习圈子的同学可能对爬虫都有 ...
- [置顶]
如何用PYTHON代码写出音乐
如何用PYTHON代码写出音乐 什么是MIDI 博主本人虽然五音不全,而且唱歌还很难听,但是还是非常喜欢听歌的.我一直在做这样的尝试,就是通过人工智能算法实现机器自动的作词和编曲(在这里预告下,通过深 ...
- 如何用PYTHON代码写出音乐
什么是MIDI 博主本人虽然五音不全,而且唱歌还很难听,但是还是非常喜欢听歌的.我一直在做这样的尝试,就是通过人工智能算法实现机器自动的作词和编曲(在这里预告下,通过深度学习写歌词已经实现了,之后会分 ...
- 用sublime写出的第一个网页
STEP1 完成语义分析器 我用的vs2013 c语言写的 这个过程会在下一篇文章中详讲 准备好几个编译好的图,放在一个文件夹里,像下面这样 STEP2 规划好html的框架 上代码! (截图版) ( ...
- python3爬虫.1.简单的网页爬虫
此为记录下我自己的爬虫学习过程. 利用url包抓取网页 import urllib.request #url包 def main(): url = "http://www.douban.co ...
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱(转)
原文:http://www.52nlp.cn/python-网页爬虫-文本处理-科学计算-机器学习-数据挖掘 曾经因为NLTK的缘故开始学习Python,之后渐渐成为我工作中的第一辅助脚本语言,虽然开 ...
- nodeJS实现简单网页爬虫功能
前面的话 本文将使用nodeJS实现一个简单的网页爬虫功能 网页源码 使用http.get()方法获取网页源码,以hao123网站的头条页面为例 http://tuijian.hao123.com/h ...
随机推荐
- Java VS .NET:Java与.NET的特点对比
一.前言 为什么要写Java跟.NET对比? .NET出生之后就带着Java的影子.从模仿到创新,.NET平台也越来越成熟.他们不同的支持者也经常因为孰弱孰强的问题争论不休.但是本文并不是为了一分高下 ...
- Ali RocketMQ与Kafka对照
淘宝内部的交易系统使用了淘宝自主研发的Notify消息中间件,使用Mysql作为消息存储媒介.可全然水平扩容,为了进一步减少成本.我们觉得存储部分能够进一步优化,2011年初,Linkin开源了Kaf ...
- 向MapReduce转换:生成用户向量
分两部分: <span style="font-size:18px;">/*** * @author YangXin * @date 2016/2/21 * @ inf ...
- 【leetcode】123. Best Time to Buy and Sell Stock III
@requires_authorization @author johnsondu @create_time 2015.7.22 19:04 @url [Best Time to Buy and Se ...
- OpenTK教程-0序言
记得很久之前,我写过一个基于.NET的3D开发框架/工具比较.当时选定的技术是WPF.但是随着项目发展,需要处理的图形数量越来越多,基于WPF的处理起来性能有问题,最后还是使用了基于OpenTK的解决 ...
- Docker 搭建 etcd 集群
阅读目录: 主机安装 集群搭建 API 操作 API 说明和 etcdctl 命令说明 etcd 是 CoreOS 团队发起的一个开源项目(Go 语言,其实很多这类项目都是 Go 语言实现的,只能说很 ...
- redis远程连接问题(安全模式问题)
我在windows上远程连接linux上的redis(我虚拟机上的)遇到了问题,我是在windows上php代码中的调用redis接口来远程连接的,代码中ping()的时候报错. 服务器端我确定了ip ...
- Cenos 6.5上的subverion的yum配置笔记
Subversion在CenOS 6.5上的安装配置 1.安装 yum install subversion 2.配置 #创建目录 mkdir /opt/svn #创建版本库 svna ...
- Django实战,小网站实现增删改查
直接上代码 视图: from django.shortcuts import render,render_to_response, redirect from submit import models ...
- Docker Stack 集群部属服务
Docker越来越成熟,功能也越来越强大.使用Dokcer Stack做服务集群也是非常的方便,docker 自己就提供了负载功能,感觉很方便,就想给大家分享一下,做一个简单的教程. 环境 我是用了两 ...