HDFS Architecture
http://hadoop.apache.org/docs/r2.9.0/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
Introduction
Hadoop分布式文件系统被设计运行在普通的硬件上。它和目前已经存在的分布式文件系统有很多相似的地方。然而,也有很多不同。HDFS的容错性很高,并且被设计用来运行在廉价的硬件上。HDFS提供高吞吐量的访问应用数据,并且适合用在有很大数据集的应用。HDFS是构建Apache Nutch的基础设施。HDFS是Apache Hadoop核心工程的一部分。
Assumptions and Goals
Hardware Failure
硬件失败是一种正常情况而不是异常情况。一个HDFS实例可能由成千上万台服务器机器组成,每台机器都存储着这个文件系统上的一部分数据。事实上有许多组件,每个组件失败的概率很大,这就意味着HDFS总是不稳定的。因此,快速删除错误的组件,并且自动发现它们是HDFS的一个核心架构目标。
NameNode and DataNodes
HDFS是一个主从结构。一个HDFS集群由一个NameNode和许多个DataNode组成。NameNode是一个主服务器,它管理文件系统的命名空间,并且客户端对文件的访问。DataNode管理与之相关的节点的存储。HDFS维护一个文件系统的命名空间,并且允许用户数据以文件形式存储。在内部,一个文件被切分成一个或多个块,这些块被存储在一系列的DataNode上。NameNode执行文件系统命名空间操作,比如:打开、管理、重命名文件或目录。它也维护着块到DataNode之间的映射关系。DataNode负责为这些来自文件系统客户端的请求提供读写服务。在NameNode指定之下,DataNode也执行块的创建、删除、复制操作。
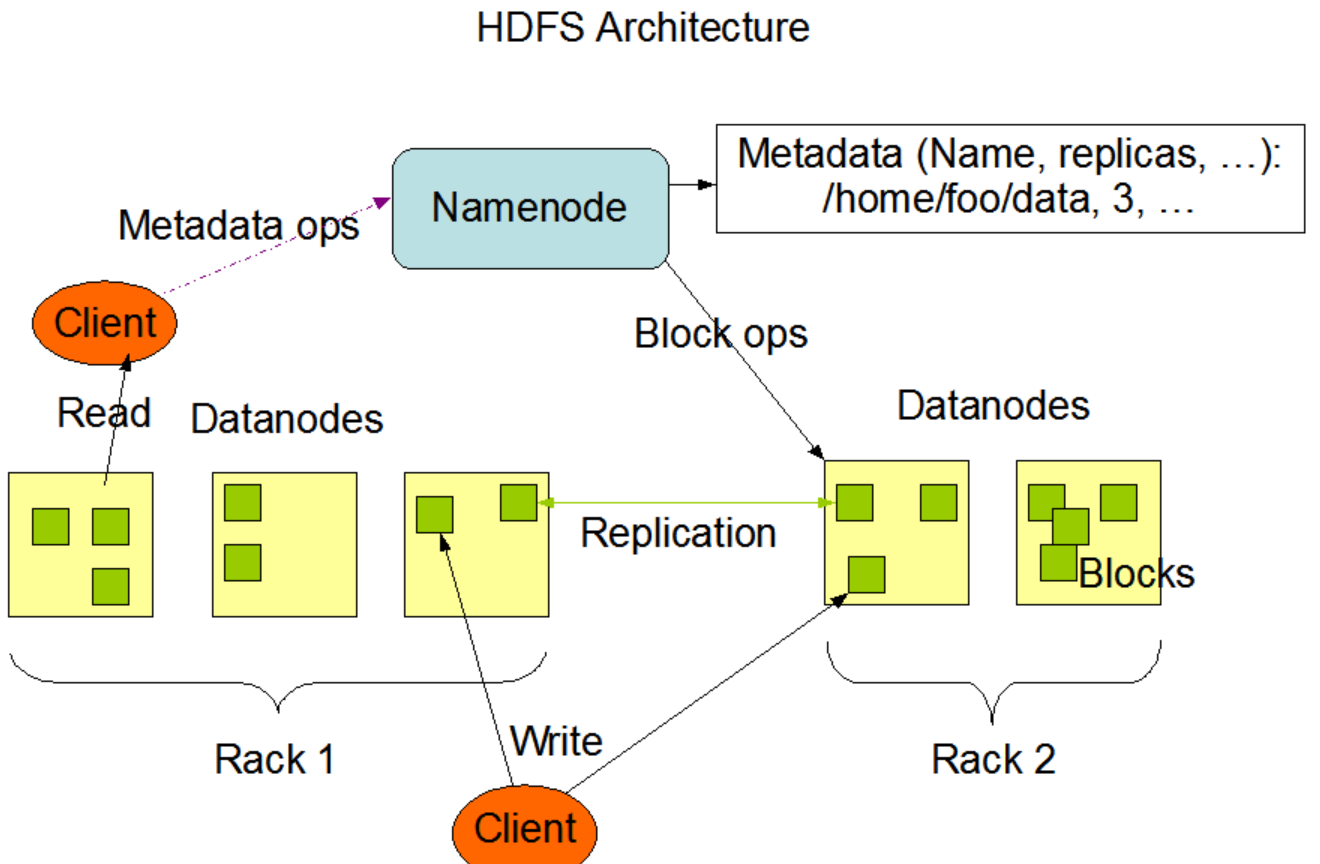
HDFS是用Java语言构建的,任何一个支持Java的机器上都可以运行NameNode和DataNode软件。一种典型的部署方式是用一台专门的机器上面只部署NameNode,而这个实例集群中的其它的每一个集群上都运行一个DataNode。HDFS这种架构不能阻止在同一台集群上运行多个DataNode,但这种情况在真实的部署中是很少见的。
The File System Namespace
HDFS的文件系统命名空间和已经存在的其它的文件系统很类似,可以创建、删除、移动文件或目录。HDFS支持用户限额和访问权限控制。HDFS不支持硬链接和软链接,然而它并没有阻止这种特性的实现。
NameNode维护文件系统命名空间。任何对文件系统命名空间或者它们的属性的修改都会记录到NameNode中。一个应用可以指定一个文件在HDFS中应该维护的副本的数量。一个文件副本的数量叫做这个文件的副本因子,这个信息被存储在NameNode中。
Data Replication
每个文件被存储为一系列的块。为了容错,文件的每个块会被复制。块的大小和副本因子被配置在每个文件中。在一个文件的所有块中,除了最后一个块以外,其余的块的大小都相同。应用程序可以指定一个文件的副本数量。在文件被创建的时候副本因子就被指定了,当然在随后可以修改。在HDFS中的文件都是只能写一次的,而且在任何时候都是严格的只能写一次。(PS:也就是说写入了就不能改了,如果想要改则需要先下载本地修改后重新上传)
NameNode会周期性的接收到来自集群中的每个DataNode的心跳检测和块报告。收到心跳检测意味着这个DataNode还活着可以正常提供服务。一个块报告包含这个DataNode上的所有的块列表。
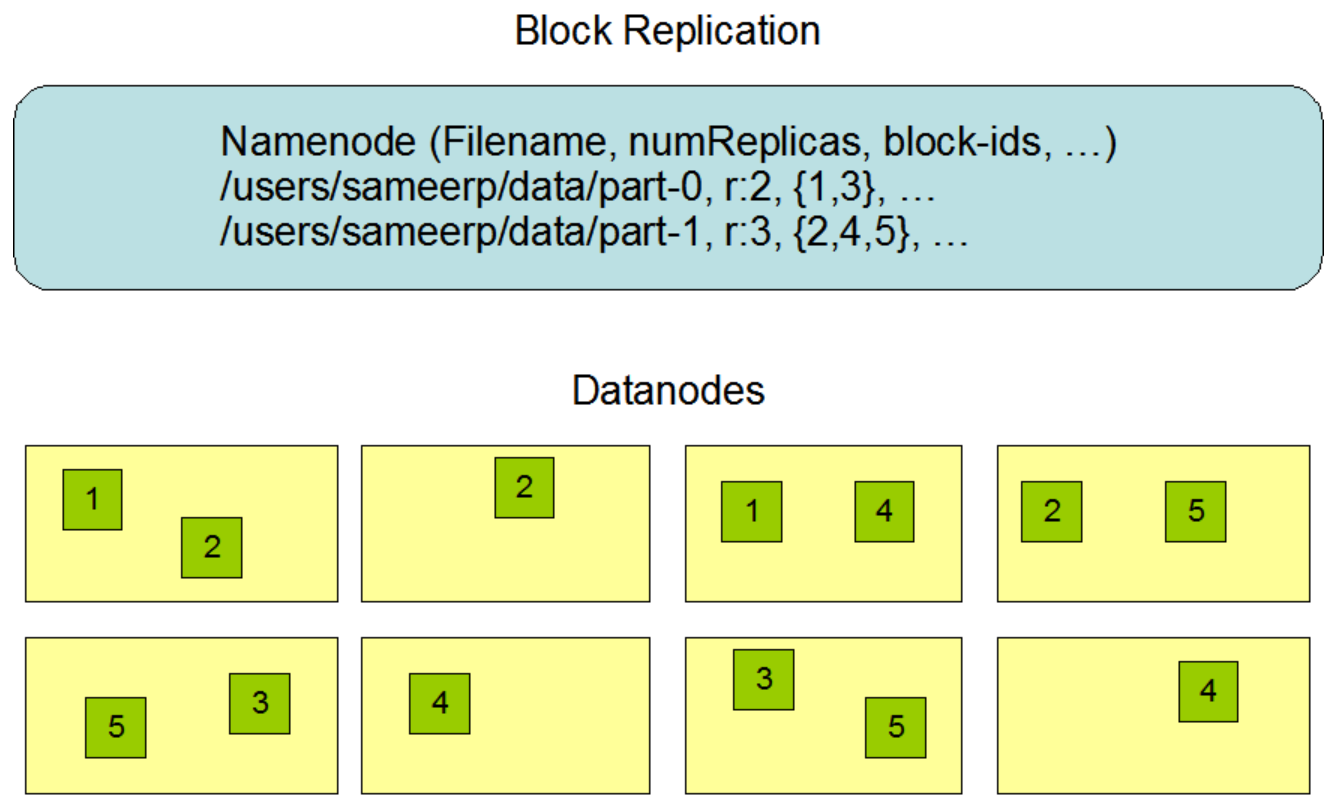
Replica Placement: The First Baby Steps
副本存放的位置对HDFS的可靠性和性能至关重要。最佳的副本位置是HDFS区别与其它分布式文件系统的重要标志。这个特性需要大量的调试和实验。机架感知副本位置策略的目的是为了提高数据的可靠性、可用性和网络带宽的利用率。
一个大的HDFS集群实例由许多计算机组成,这些计算机通常被放在许多机架上。不同机架上的两台计算机之间通信必须通过交换机。大多数情况下,相同机架上的机器之间的网络带宽要比不通机架上机器之前的网络带宽要好很多。
NameNode决定DataNode所属的机架ID
通常情况下,副本因子是3。HDFS的放置策略是,如果是第一次写在某个DataNode上,那么就放置一个副本在这个DataNode所在的本地机器上,否则放置在相同机架上的一个随机的DataNode上,其它的副本放置在不同的远程机架上的某个节点,最后一个副本放置在相同的远程机架上的不同的节点上。机架失败的概率要比机架上某个节点失败的概率小很多。这个策略不影响数据的可靠性和可用性。
如果副本因子大于3,那么第4个以及后面的更多的副本的位置是随机决定的,但是每个机架上的副本数量有一个上限((replicas - 1) / racks + 2)
The Persistence of File System Metadata
NameNode用一个叫做EditLog的事务日志来持久化文件系统元数据的每一次改变。例如,在HDFS上创建一个新文件会造成NameNode插入一条记录到EditLog中。同样的,改变一个文件的副本因子也会造成往EditLog中插入一条记录。NameNode用它所在的主机的本地操作系统上的一个文件来存储EditLog。整个文件系统命名空间,包括块到文件的映射,以及文件的系统属性,都会被存储到一个叫做FsImage的文件中。这个FsImage文件也被存储在NameNode的本地文件系统中。
NameNode在内存中保持整个文件系统命名空间以及文件块的映射。当NameNode启动的时候,或者当检查点被触发的时候,它会从磁盘中读取FsImage和EditLog,然后根据EditLog构建所有的事务到内存中的FsImage,并且刷新新的版本到一个新的FsImage到磁盘。它会截断旧的EditLog,因为这些EditLog中的事务已经被持久化到FsImage中了。这个处理被叫做检查点。检查点的目的在于通过做一个文件系统元数据的快照并且把它们保存到FsImage中来确保HDFS可以很方便的查看文件系统元数据。代替每编辑一次就修改FsImage,我们将这个编辑持久化到EditLog。当检查点发生的时候,将改变从EditLog写到FsImage。一个检查点被触发在给定的时间间隔(dfs.namenode.checkpoint.period)单位是秒,或者指定文件系统事务累积达到多少数量(dfs.namenode.checkpoint.txns)就触发。如果这两个属性都设置了,那么第一个达到阈值的将触发检查点。
DataNode将文件数据存放在本地文件系统中。DataNode并不知道HDFS的文件,它只是将文件的每个块存储到本地文件系统中。DataNode并不是将所有的文件都存在一个目录下,它会以一种启发式的方式来决定每个目录下该存放的文件的最优数量,并且也会适当的创建子目录。当DataNode启动的时候,它通过扫描本地文件系统生成一个和这个本地文件一致的HDFS数据块的列表,并且发送报告给NameNode。这个报告叫做Blockreport。
总结一下:
1、每次元数据的改变都会被记录到EditLog中
2、文件的元数据已经文件和Block直接的映射关系被记录到FsImage中
3、改变不会理解写到FsImage中,而是先记录到EditLog中,然后当检查点触发的时候将EditLog中记录的改变写到FsImage中
4、检查点触发的时机有两个:一个是可以通过dfs.namenode.checkpoint.period参数指定多长时间周期性的触发一次,另一个是通过dfs.namenode.checkpoint.txns指定当EditLog中的记录达到多少时触发一次。无论达到那个条件都会触发,谁先达到,谁先触发
5、EditLog和FsImage都存放在NameNode所在的机器的本地磁盘上
6、DataNode启动的时候回发送BlockReport给NameNode

HDFS Architecture的更多相关文章
- Hadoop官方文档翻译——HDFS Architecture 2.7.3
HDFS Architecture HDFS Architecture(HDFS 架构) Introduction(简介) Assumptions and Goals(假设和目标) Hardware ...
- 【转载】Hadoop官方文档翻译——HDFS Architecture 2.7.3
HDFS Architecture HDFS Architecture(HDFS 架构) Introduction(简介) Assumptions and Goals(假设和目标) Hardware ...
- HDFS Architecture Notes
[HDFS Architecture Notes] 1.Moving Computation is Cheaper than Moving Data A computation requested b ...
- HDFS 与 GFS 的设计差异
后端分布式系列」前面关于 HDFS 的一些文章介绍了它的整体架构和一些关键部件的设计实现要点. 我们知道 HDFS 最早是根据 GFS(Google File System)的论文概念模型来设计实现的 ...
- HDFS 异常处理与恢复
在前面的文章 <HDFS DataNode 设计实现解析>中我们对文件操作进行了描述,但并未展开讲述其中涉及的异常错误处理与恢复机制.本文将深入探讨 HDFS 文件操作涉及的错误处理与恢复 ...
- HDFS Client 设计实现解析
前面对 HDFS NameNode 和 DataNode 的架构设计实现要点做了介绍,本文对 HDFS 最后一个主要构成组件 Client 做进一步解析. 流式读取 HDFS Client 为客户端应 ...
- HDFS DataNode 设计实现解析
前文分析了 NameNode,本文进一步解析 DataNode 的设计和实现要点. 文件存储 DataNode 正如其名是负责存储文件数据的节点.HDFS 中文件的存储方式是将文件按块(block)切 ...
- HDFS NameNode 设计实现解析
接前文 分布式存储-HDFS 架构解析,我们总体分析了 HDFS 架构的主要构成组件包括:NameNode.DataNode 和 Client.本文首先进一步解析 HDFS NameNode 的设计和 ...
- HDFS 架构解析
本文以 Hadoop 提供的分布式文件系统(HDFS)为例来进一步展开解析分布式存储服务架构设计的要点. 架构目标 任何一种软件框架或服务都是为了解决特定问题而产生的.还记得我们在 <分布式存储 ...
随机推荐
- Java面试题集合(比较实用)
1.Java集合框架是什么?说出一些集合框架的优点? 每种编程语言中都有集合,最初的Java版本包含几种集合类:Vector.Stack.HashTable和Array.随着集合的广泛使用...... ...
- Android 7.1 屏幕旋转流程分析
Android 7.1 屏幕旋转流程分析 一.概述 Android屏幕的旋转在framework主要涉及到三个类,结构如图 PhoneWindowManager:为屏幕的横竖屏转换的管理类. Wi ...
- node-koa搭建MVC/RESTful API项目
本文将介绍如何基于node-koa搭建一个完整的mvc及restAPI的项目,项目封装了路由.模板引擎. 静态文件加载等基本功能:首先介绍项目的安装启动及目录结构说明,然后通过一个简单的登录页说明mv ...
- Python 学习(1) 简单的小爬虫
最近抽空学了两天的Python,基础知识都看完了,正好想申请个联通日租卡,就花了2小时写了个小爬虫,爬一下联通日租卡的申请页面,看有没有好记一点的手机号~ 人工挑眼都挑花了. 用的IDE是PyCh ...
- urllib2的基本使用
urlopen 1 import urllib2 2 3 # 向指定的url发送请求,并返回服务器响应的类文件对象 4 response = urllib2.urlopen("http:// ...
- 用IFeatureWorkspaceAnno.CreateAnnotationClass 创建注记图层时报“The application is not licensed to modify or create schema”的错误的解决方案。
用IFeatureWorkspaceAnno.CreateAnnotationClass 的方法创建注记图层的时候报"The application is not licensed to m ...
- Springboot-添加对jsp支持
1,在项目的配置文件加入以下依赖 <dependency> <groupId>javax.servlet</groupId> <artifactId>j ...
- Java实现的电脑已连接WiFi热点的导入导出小工具
很多时候我们电脑连接了很多无线WiFi,只要连接过一次,电脑就会记下该热点的密码,方便我们下一次连接.但是问题来了,一旦我们重装系统,之前连接过的WiFi就丢失了,想要连接就得再输入密码,为了 解决这 ...
- 3.更改ssh服务远程登录的配置
- windos10安装mongodb并配置
想了想还是把这个写上吧,毕竟网上的教程有不少坑的. 首先下载mongodb,如果你嫌官网慢,那么你可以去我的百度云下载 链接:http://pan.baidu.com/s/1pKEWTBX 密码:v3 ...