MLlib--FPGrowth算法
转载请标明出处http://www.cnblogs.com/haozhengfei/p/c9f211ee76528cffc4b6d741a55ac243.html
FPGrowth算法_挖掘商品之间的关联规则
1.1FPGrowth算法可以做什么?
商品之间关联性强度如何,由三个概念——支持度、置信度、提升度来控制和评价,以下将通过例子介绍这三个概念。
1.2FPGrowth_原理剖析
FP-Growth(频繁模式增长)算法是韩家炜老师在2000年提出的关联分析算法,它采取如下分治策略:将提供频繁项集的数据库压缩到一棵频繁模式树(FP-Tree),但仍保留项集关联信息;该算法和Apriori算法最大的不同有两点:第一,不产生候选集,第二,只需要两次遍历数据库,大大提高了效率。
(1)按以下步骤构造FP-树
(a) 扫描事务数据库D一次。收集频繁项的集合F和它们的支持度。对F按支持度降序排序,结果为频繁项表L。
(b) 创建FP-树的根结点,以“null”标记它。对于D 中每个事务Trans,执行:选择 Trans 中的频繁项,并按L中的次序排序。设排序后的频繁项表为[p | P],其中,p 是第一个元素,而P 是剩余元素的表。调用insert_tree([p | P], T)。该过程执行情况如下。如果T有子女N使得N.item-name = p.item-name,则N 的计数增加1;否则创建一个新结点N将其计数设置为1,链接到它的父结点T,并且通过结点链结构将其链接到具有相同item-name的结点。如果P非空,递归地调用insert_tree(P, N)。
(2)FP-树的挖掘
通过调用FP_growth(FP_tree, null)实现。该过程实现如下:
FP_growth(Tree, α)
(1) if Tree 含单个路径P then
(2) for 路径 P 中结点的每个组合(记作β)
(3) 产生模式β ∪ α,其支持度support = β中结点的最小支持度;
(4) else for each ai在Tree的头部(按照支持度由低到高顺序进行扫描) {
(5) 产生一个模式β = ai ∪ α,其支持度support = ai .support;
(6) 构造β的条件模式基,然后构造β的条件FP-树Treeβ;
(7) if Treeβ ≠ ∅ then
(8) 调用 FP_growth (Treeβ, β);}
end
1.1.3 FP-Growth算法演示—构造FP-树
(1)事务数据库建立
原始事务数据库如下:
|
Tid |
Items |
|
1 |
I1,I2,I5 |
|
2 |
I2,I4 |
|
3 |
I2,I3 |
|
4 |
I1,I2,I4 |
|
5 |
I1,I3 |
|
6 |
I2,I3 |
|
7 |
I1,I3 |
|
8 |
I1,I2,I3,I5 |
|
9 |
I1,I2,I3 |
扫描事务数据库得到频繁1-项目集F。
|
I1 |
I2 |
I3 |
I4 |
I5 |
|
6 |
7 |
6 |
2 |
2 |
定义minsup=20%,即最小支持度为2,重新排列F。
|
I2 |
I1 |
I3 |
I4 |
I5 |
|
7 |
6 |
6 |
2 |
2 |
重新调整事务数据库。
|
Tid |
Items |
|
1 |
I2, I1,I5 |
|
2 |
I2,I4 |
|
3 |
I2,I3 |
|
4 |
I2, I1,I4 |
|
5 |
I1,I3 |
|
6 |
I2,I3 |
|
7 |
I1,I3 |
|
8 |
I2, I1,I3,I5 |
|
9 |
I2, I1,I3 |
(2)创建根结点和频繁项目表

(3)加入第一个事务(I2,I1,I5)
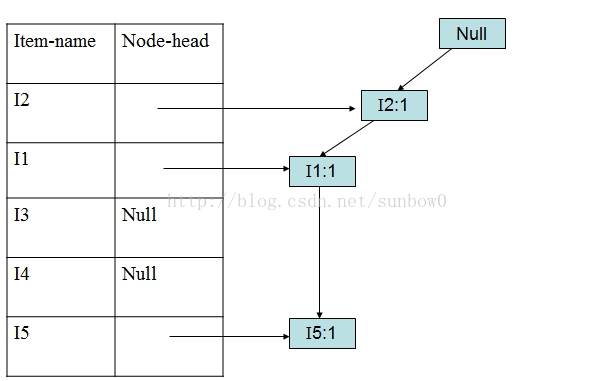
(4)加入第二个事务(I2,I4)

(5)加入第三个事务(I2,I3)

以此类推加入第5、6、7、8、9个事务。
(6)加入第九个事务(I2,I1,I3)
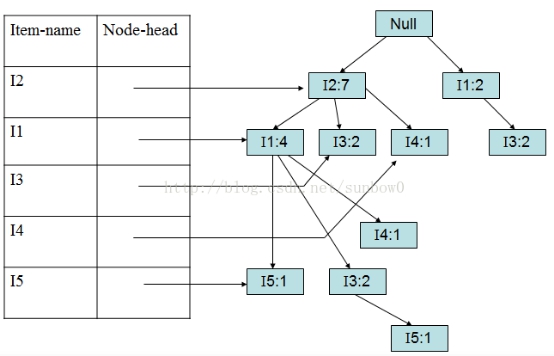
1.1.4 FP-Growth算法演示—FP-树挖掘
FP-树建好后,就可以进行频繁项集的挖掘,挖掘算法称为FpGrowth(Frequent Pattern Growth)算法,挖掘从表头header的最后一个项开始,以此类推。本文以I5、I3为例进行挖掘。
(1)挖掘I5:
对于I5,得到条件模式基:<(I2,I1:1)>、<I2,I1,I3:1>
构造条件FP-tree:
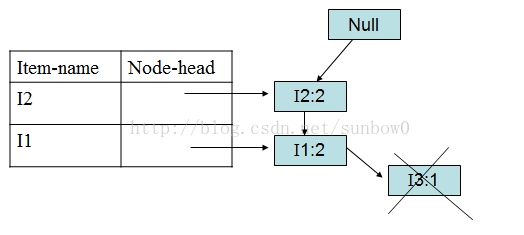
得到I5频繁项集:{{I2,I5:2},{I1,I5:2},{I2,I1,I5:2}}
I4、I1的挖掘与I5类似,条件FP-树都是单路径。
(1)挖掘I3:
I5的情况是比较简单的,因为I5对应的条件FP-树是单路径的,I3稍微复杂一点。I3的条件模式基是(I2 I1:2), (I2:2), (I1:2),生成的条件FP-树如下图:

I3的条件FP-树仍然是一个多路径树,首先把模式后缀I3和条件FP-树中的项头表中的每一项取并集,得到一组模式{I2 I3:4, I1 I3:4},但是这一组模式不是后缀为I3的所有模式。还需要递归调用FP-growth,模式后缀为{I1,I3},{I1,I3}的条件模式基为{I2:2},其生成的条件FP-树如下图所示。
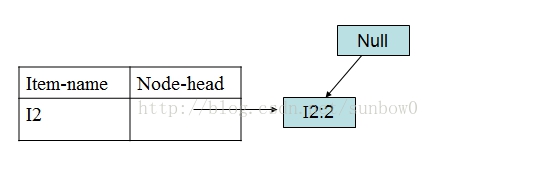
在FP_growth中把I2和模式后缀{I1,I3}取并得到模式{I1 I2 I3:2}。
理论上还应该计算一下模式后缀为{I2,I3}的模式集,但是{I2,I3}的条件模式基为空,递归调用结束。最终模式后缀I3的支持度>2的所有模式为:{ I2 I3:4, I1 I3:4, I1 I2 I3:2}。
1.3FPGrowth_code
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.mllib.fpm.FPGrowth
import org.apache.spark.rdd.RDD
/**
* Created by hzf
*/
object FPGrowth_new {
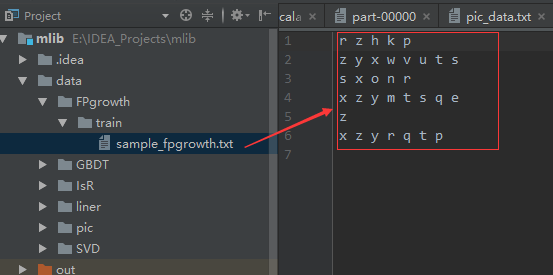
// E:\IDEA_Projects\mlib\data\FPgrowth\train\sample_fpgrowth.txt E:\IDEA_Projects\mlib\data\FPgrowth\model 0.2 10 local
def main(args: Array[String]) {
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
if (args.length < 5) {
System.err.println("Usage: FPGrowth <inputPath> <modelPath> <support> <partitions> <master> [<AppName>]")
System.exit(1)
}
val appName = if (args.length > 5) args(5) else "FPGrowth"
val conf = new SparkConf().setAppName(appName).setMaster(args(4))
val sc = new SparkContext(conf)
val data = sc.textFile(args(0))
val transactions: RDD[Array[String]] = data.map(s => s.trim.split(' '))
val fpg = new FPGrowth().setMinSupport(args(2).toDouble).setNumPartitions(args(3).toInt)
val model = fpg.run(transactions)
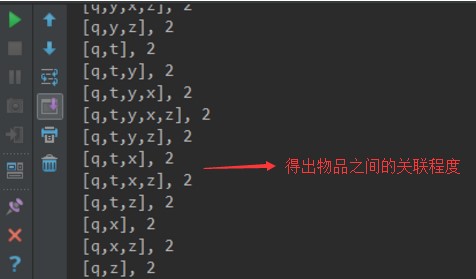
model.freqItemsets.collect().foreach { itemset =>
println(itemset.items.mkString("[", ",", "]") + ", " + itemset.freq)
}
model.freqItemsets.saveAsTextFile(args(1))
}
}
E:\IDEA_Projects\mlib\data\FPgrowth\train\sample_fpgrowth.txt E:\IDEA_Projects\mlib\data\FPgrowth\model 0.2 10 local
MLlib--FPGrowth算法的更多相关文章
- Spark MLlib FPGrowth关联规则算法
一.简介 FPGrowth算法是关联分析算法,它采取如下分治策略:将提供频繁项集的数据库压缩到一棵频繁模式树(FP-tree),但仍保留项集关联信息.在算法中使用了一种称为频繁模式树(Frequent ...
- Spark机器学习(9):FPGrowth算法
关联规则挖掘最典型的例子是购物篮分析,通过分析可以知道哪些商品经常被一起购买,从而可以改进商品货架的布局. 1. 基本概念 首先,介绍一些基本概念. (1) 关联规则:用于表示数据内隐含的关联性,一般 ...
- 基于Spark的FPGrowth算法的运用
一.FPGrowth算法理解 Spark.mllib 提供并行FP-growth算法,这个算法属于关联规则算法[关联规则:两不相交的非空集合A.B,如果A=>B,就说A=>B是一条关联规则 ...
- 使用 FP-growth 算法高效挖掘海量数据中的频繁项集
前言 对于如何发现一个数据集中的频繁项集,前文讲解的经典 Apriori 算法能够做到. 然而,对于每个潜在的频繁项,它都要检索一遍数据集,这是比较低效的.在实际的大数据应用中,这么做就更不好了. 本 ...
- FP-Growth算法及演示程序
FP-Growth算法 FP-Growth(频繁模式增长)算法是韩家炜老师在2000年提出的关联分析算法,它采取如下分治策略:将提供频繁项集的数据库压缩到一棵频繁模式树(FP-Tree),但仍保留项集 ...
- 机器学习实战 - 读书笔记(12) - 使用FP-growth算法来高效发现频繁项集
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第12章 - 使用FP-growth算法来高效发现频繁项集. 基本概念 FP-growt ...
- 数据挖掘系列(2)--关联规则FpGrowth算法
上一篇介绍了关联规则挖掘的一些基本概念和经典的Apriori算法,Aprori算法利用频繁集的两个特性,过滤了很多无关的集合,效率提高不少,但是我们发现Apriori算法是一个候选消除算法,每一次消除 ...
- 使用Apriori算法和FP-growth算法进行关联分析
系列文章:<机器学习实战>学习笔记 最近看了<机器学习实战>中的第11章(使用Apriori算法进行关联分析)和第12章(使用FP-growth算法来高效发现频繁项集).正如章 ...
- FP-Growth算法之频繁项集的挖掘(python)
前言: 关于 FP-Growth 算法介绍请见:FP-Growth算法的介绍. 本文主要介绍从 FP-tree 中提取频繁项集的算法.关于伪代码请查看上面的文章. FP-tree 的构造请见:FP-G ...
- FPGrowth算法原理
算法实现: /** * FPGrowth算法的主要思想: * 1. 构造频繁1项集:遍历初始数据集构造频繁1项集,并作为项头表,建立将指向fpTree节点对应元素的引用 * 2. 构造FPTree:再 ...
随机推荐
- Search 命令详解
*查: ls : 查看文件等信息 /cat: 查看文件只显示最后一页. /cat > filename:创建新文件 /cat file1 file2 > file:合并文件 / -A ...
- QA问答系统,QA匹配论文学习笔记
论文题目: WIKIQA: A Challenge Dataset for Open-Domain Question Answering 论文代码运行: 首先按照readme中的提示安装需要的部分 遇 ...
- 例子:web版坦克大战1.0
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Django__RBAC
RBAC : 基于角色的权限访问控制(Role-Based Access Control) RBAC 模型作为目前最为广泛接受的权限模型 角色访问控制(RBAC)引入了Role的概念,目的是为了隔离U ...
- Django学习日记01_环境搭建
1. 使用Vagrant 创建ubuntu虚拟机: 首先安装vagrant,网上有比较多的方法,如:http://www.th7.cn/system/mac/201405/55421.shtml 我使 ...
- 02-01官网静默模式安装WebLogic
参考连接:https://docs.oracle.com/middleware/11119/wls/WLSIG/silent.htm#CIHCAHGC 以静默模式运行安装程序 本章介绍如何以静默方式运 ...
- Struts2思维导图
自己感觉自己的知识不是很扎实,所以昨天留时间复习知识,昨天边复习边画了一个思维导图.不知道自己画的对不对,还没有画完.有错的地方大家请和我说.希望自己能更加牢固的记住这些知识. 不说废话,开图.图有点 ...
- golang 多维数组
具体的题目如下:(就是将多维数组的行列互换) A multi-dimensional array is an array of arrays. 2-dimensional arrays are the ...
- Mac appium.dmg. Xcode Command Line Tools
You need to install the command line tools as marked in your message: ✖ Xcode Command Line Tools are ...
- js 的数学处理方法
1.javascript取整方法floor.round.ceil floor向下取整: Math.floor(0.20); Math.floor(0.90); Math.floor(-0.90); / ...