Spark踩坑记——从RDD看集群调度
前言
在Spark的使用中,性能的调优配置过程中,查阅了很多资料,本文的思路是从spark最细节的本质,即核心的数据结构RDD出发,到整个Spark集群宏观的调度过程做一个整理归纳,从微观到宏观两方面总结,方便自己在调优过程中找寻问题,理清思路,也加深自己对于分布式程序开发的理解。(有任何问题和纰漏还请各位大牛指出啦,我会第一时间改正)
RDD详谈
在Spark开山之作"Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing"的这篇paper中(以下简称RDD Paper),Matei等提出了RDD这种数据结构,文中开头对RDD定义是:
A distributed memory abstraction that lets programmers perform in-memory computations on large clusters in a fault-tolerant manner.
也就是说RDD设计的核心点为:
- 内存计算
- 适合于计算机集群
- 有容错方式
文中提到了对于RDD设计的最大挑战便是在提供有效的容错机制(fault tolerance efficiently),之前存在的基于内存存储的集群抽象,例如分布式共享内存、键值存储、数据库等,更多是细粒度的(fine-grained)更新一个可变状态表,而其容错方式通常为在机器间进行数据复制或者日志更新,而这些方式很明显会造成机器负载加大以及大量的网络传输开销。
而RDD则使用了粗粒度的(coarse-grained)转换,即对于很多相同的数据项使用同一种操作(如map/filter/join),这种方式能够通过记录RDD之间的转换从而刻画RDD的继承关系(lineage),而不是真实的数据,最终构成一个DAG(有向无环图),而如果发生RDD丢失,RDD会有充足的信息来得知怎么从其他RDDs重新计算得到。
这也是RDD设计的核心理念,接下来围绕这一理念我们来剖析,看RDD是怎么实现这种高效的容错机制的。
RDD存储结构
RDD实现的数据结构核心是一个五元组,如下表:
| 属性 | 说明 |
|---|---|
| 分区列表-partitions | 每个分区为RDD的一部分数据 |
| 依赖列表-dependencies | table存储其父RDD即依赖RDD |
| 计算函数-compute | 利用父分区计算RDD各分区的值 |
| 分区器-partitioner | 指明RDD的分区方式(hash/range) |
| 分区位置列表-preferredLocations | 指明分区优先存放的结点位置 |
其中每个属性的代码如下:
// RDD中的依赖关系由一个Seq数据集来记录,这里使用Seq的原因是经常取第一个元素或者遍历
private var dependencies_: Seq[Dependency[_]] = null
// 分区列表定义在一个数组中,这里使用Array的原因是随时使用下标来访问分区内容
// @transient分区列表不需要被序列化
@transient private var partitions_: Array[Partition] = null
// 接口定义,具体由子类实现,对输入的RDD分区进行计算
def compute(split: Partition, context: TaskContext): Iterator[T]
// 分区器
// 可选,子类可以重写以指定新的分区方式,Spark支持Hash和Range两种分区方式
@transient val partitioner: Option[Partitioner] = None
// 可选,子类可以指定分区的位置,如HadoopRDD可以重写此方法,让分区尽可能与数据在相同的节点上
protected def getPreferredLocations(split: Partition): Seq[String] = Nil
在RDD Paper中,作者提到在抽象RDD时,一个很重要的点便是如何使得RDD能够记录RDD之间的继承依赖关系(lineage),这种继承关系来自丰富的转移(Transformation)操作。所以作者提出了一种基于图的表示方式来实现这个目标,这也正是上面RDD五种属性的核心作用。
这五种属性从spark诞生到新的版本迭代,一直在使用,没有增加也没有减少,所以可以说Spark的核心就是RDD,而RDD的核心就是这五种属性。
RDD的操作
在Spark踩坑记——初试中对RDD的操作也进行了简单说明,在Spark中,对RDD的操作可以分为Transformation和Action两种,我们分别进行整理说明:
Transformation
对于Transformation操作是指由一个RDD生成新RDD的过程,其代表了是计算的中间过程,其并不会触发真实的计算。
map(f:T=>U) : RDD[T]=>RDD[U]
返回一个新的分布式数据集,由每个原元素经过func函数转换后组成filter(f:T=>Bool) : RDD[T]=>RDD[T]
返回一个新的数据集,由经过func函数后返回值为true的原元素组成flatMap(f:T=>Seq[U]) : RDD[T]=>RDD[U])
类似于map,但是每一个输入元素,会被映射为0到多个输出元素(因此,func函数的返回值是一个Seq,而不是单一元素)sample(withReplacement: Boolean, fraction: Double, seed: Long) : RDD[T]=>RDD[T]
sample将RDD这个集合内的元素进行采样,获取所有元素的子集。用户可以设定是否有放回的抽样、百分比、随机种子,进而决定采样方式。
withReplacement=true, 表示有放回的抽样;
withReplacement=false, 表示无放回的抽样。
如下图:
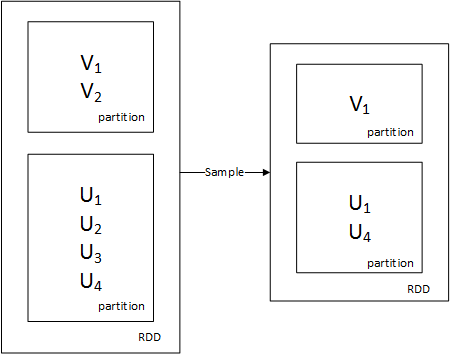
每个方框是一个RDD分区。通过sample函数,采样50%的数据。V1、V2、U1、U2、U3、U4采样出数据V1和U1、U4,形成新的RDD。groupByKey([numTasks]) : RDD[(K,V)]=>RDD[(K,Seq[V])]
在一个由(K,V)对组成的数据集上调用,返回一个(K,Seq[V])对的数据集。注意:- 默认情况下,使用与父RDD的partition数量对应的并行任务进行分组,也可以传入numTask可选参数,根据数据量设置不同数目的Task。
- 另外如果相同key的value求和或者求平均,那么使用reduceByKey性能更好
reduceByKey(f:(V,V)=>V, [numTasks]) : RDD[(K, V)]=>RDD[(K, V)]
在一个(K,V)对的数据集上使用,返回一个(K,V)对的数据集,key相同的值,都被使用指定的reduce函数聚合到一起。和groupbykey类似,任务的个数是可以通过第二个可选参数来配置的。union(otherDataset) : (RDD[T],RDD[T])=>RDD[T]
返回一个新的数据集,由原数据集和参数联合而成join(otherDataset, [numTasks]) : (RDD[(K,V)],RDD[(K,W)])=>RDD[(K,(V,W))]
返回key值相同的所有匹配对,如下图:
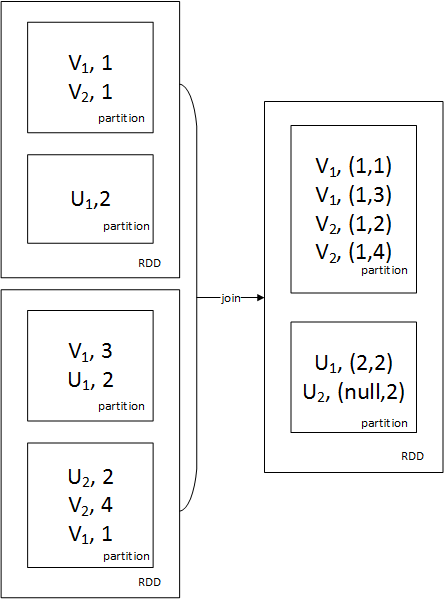
join操作会将两个RDD中相同key值的合并成key,pair(value1, value2)的形式。cogroup() : (RDD[(K,V)],RDD[(K,W)])=>RDD[(K,(Seq[V],Seq[W]))]
cogroup函数将两个RDD进行协同划分。对在两个RDD中的Key-Value类型的元素,每个RDD相同Key的元素分别聚合为一个集合,并且返回两个RDD中对应Key的元素集合的迭代器(K, (Iterable[V], Iterable[w]))。其中,Key和Value,Value是两个RDD下相同Key的两个数据集合的迭代器所构成的元组。cartesian(otherDataset) : (RDD[T],RDD[U])=>RDD[(T,U)]
笛卡尔积。但在数据集T和U上调用时,返回一个(T,U)对的数据集,所有元素交互进行笛卡尔积。sortByKey([ascending], [numTasks]) : RDD[(K,V)]=>RDD[(K,V)]
根据key值进行排序,如果ascending设置为true则按照升序排序repartition(numPartitions) :
对RDD中的所有数据进行shuffle操作,建立更多或者更少的分区使得更加平衡。往往需要通过网络进行数据传输
Action
不同于Transformation操作,Action代表一次计算的结束,不再产生新的RDD,将结果返回到Driver程序。所以Transformation只是建立计算关系,而Action才是实际的执行者。每个Action都会调用SparkContext的runJob方法向集群正式提交请求,所以每个Action对应一个Job。
count() : RDD[T]=>Long
返回数据集的元素个数countByKey() : RDD[T]=>Map[T, Long]
对(K,V)类型的RDD有效,返回一个(K,Int)对的Map,表示每一个key对应的元素个数collect() : RDD[T]=>Seq[T]
在Driver中,以数组的形式,返回数据集的所有元素。这通常会在使用filter或者其它操作并返回一个足够小的数据子集后再使用会比较有用。reduce(f:(T,T)=>T) : RDD[T]=>T
通过函数func(接受两个参数,返回一个参数)聚集数据集中的所有元素。这个功能必须可交换且可关联的,从而可以正确的被并行执行。saveAsTextFile(path:String)
将数据集的元素,以textfile的形式,保存到本地文件系统,HDFS或者任何其它hadoop支持的文件系统。对于每个元素,Spark将会调用toString方法,将它转换为文件中的文本行saveAsSequenceFile(path:String)
将数据集的元素,以Hadoop sequencefile的格式,保存到指定的目录下,本地系统,HDFS或者任何其它hadoop支持的文件系统。这个只限于由key-value对组成,并实现了Hadoop的Writable接口,或者隐式的可以转换为Writable的RDD。(Spark包括了基本类型的转换,例如Int,Double,String,等等)saveAsObjectFile(path:String)
利用Java的Serialization接口进行持久化操作,之后可以使用SparkContext.objectFile()重新load回内存take(n)
返回一个由数据集的前n个元素组成的数组。注意,这个操作目前并非并行执行,而是由驱动程序计算所有的元素takeSample(withReplacement, num, [seed])
返回一个数组,在数据集中随机采样num个元素组成,可以选择是否用随机数替换不足的部分,Seed用于指定的随机数生成器种子takeOrdered(n, [ordering])
返回前n个元素,可以使用元素的自然顺序,也可以使用用户自定义comparatorfirst()
返回数据集的第一个元素(类似于take(1))foreach(func)
在数据集的每一个元素上,运行函数func进行更新。这通常用于边缘效果,例如更新一个累加器,或者和外部存储系统进行交互,例如HBase。关于foreach我在Spark踩坑记——数据库(Hbase+Mysql)中对sparkstreaming的foreach操作有详细整理
RDD依赖方式
RDD 的容错机制是通过记录更新来实现的,且记录的是粗粒度的转换操作。在外部,我们将记录的信息称为血统(Lineage)关系,而到了源码级别,Apache Spark 记录的则是 RDD 之间的依赖(Dependency)关系。在一次转换操作中,创建得到的新 RDD 称为子 RDD,提供数据的 RDD 称为父 RDD,父 RDD 可能会存在多个,我们把子 RDD 与父 RDD 之间的关系称为依赖关系,或者可以说是子 RDD 依赖于父 RDD。
依赖只保存父 RDD 信息,转换操作的其他信息,如数据处理函数,会在创建 RDD 时候,保存在新的 RDD 内。依赖在 Apache Spark 源码中的对应实现是 Dependency 抽象类。
Apache Spark 将依赖进一步分为两类,分别是窄依赖(Narrow Dependency)和 Shuffle 依赖(Shuffle Dependency,在部分文献中也被称为 Wide Dependency,即宽依赖)。
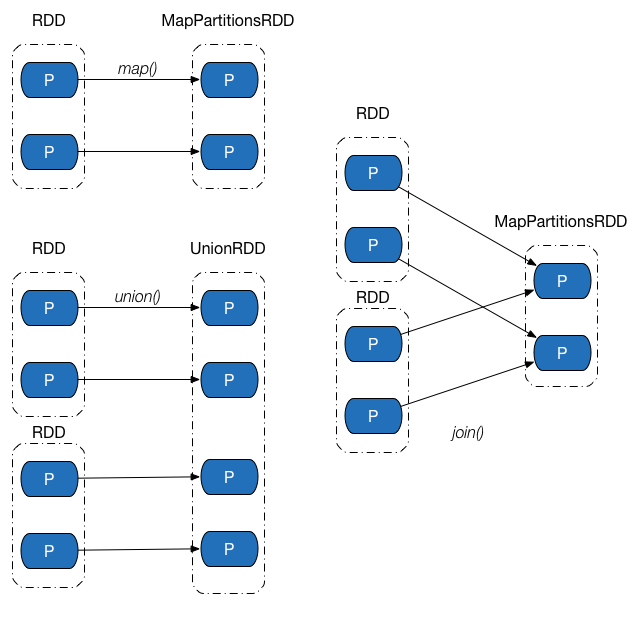
窄依赖(Narrow Dependency)
窄依赖中,父 RDD 中的一个分区最多只会被子 RDD 中的一个分区使用,换句话说,父 RDD 中,一个分区内的数据是不能被分割的,必须整个交付给子 RDD 中的一个分区。下图展示了几类常见的窄依赖及其对应的转换操作。
Shuffle依赖(宽依赖 Shffle/Wide Dependency)
Shuffle 依赖中,父 RDD 中的分区可能会被多个子 RDD 分区使用。因为父 RDD 中一个分区内的数据会被分割,发送给子 RDD 的所有分区,因此 Shuffle 依赖也意味着父 RDD 与子 RDD 之间存在着 Shuffle 过程。下图展示了几类常见的Shuffle依赖及其对应的转换操作。

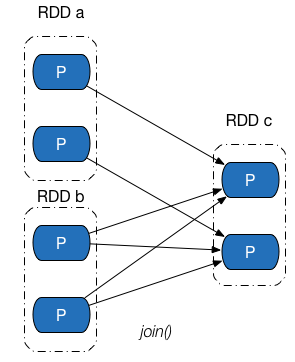
需要说明的是,依赖关系时RDD到RDD之间的一种映射关系,是两个RDD之间的依赖,那么如果在一次操作中涉及到多个父RDD,也有可能同时包含窄依赖和Shuffle依赖,如join操作:
集群部署
组件
说到Spark集群的部署,我们先来讨论一下Spark中一些关键的组件,在我的博文Spark踩坑记——初试中,我对Master/Worker/Driver/Executor几个关键概念做了阐述。首先,先上官方文档中的一张图:
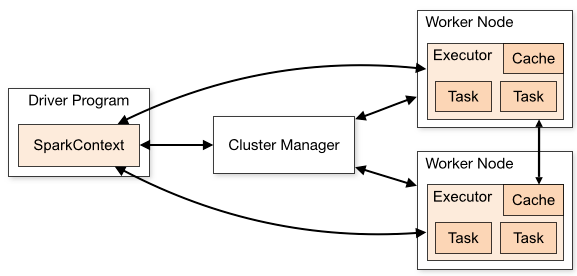
官方文档对其中的术语进行了总结,如下表:

从官方文档摘抄了这么多东东,对Spark中基本的集群结构,以及一个程序提交到Spark后的调度情况我们有了了解。
部署方式
对于集群的部署方式,Spark提供了多种集群部署方式,如下:
- Local模式:本地调试的一种模式,可以在一台机器上完成程序的运行与调试
- Standalone模式:即独立模式,自带完整的服务,可单独部署到一个集群中,无需依赖任何其他资源管理系统。
- Spark On YARN模式:将Spark搭建在Hadoop之上,由hadoop中的yarn负责资源调配,Spark负责计算任务;
- Spark On Mesos模式:这是很多公司采用的模式,官方推荐这种模式(当然,原因之一是血缘关系)。正是由于Spark开发之初就考虑到支持Mesos,因此,目前而言,Spark运行在Mesos上会比运行在YARN上更加灵活,更加自然。目前在Spark On Mesos环境中,用户可选择两种调度模式之一运行自己的应用程序。
集群部署举例
由于在我平时的使用中,是直接采用的Standalone的部署方式,我这里将部署的框架做一个简单的介绍,其他部署方式其实可以做一些参考来进行搭配部署:
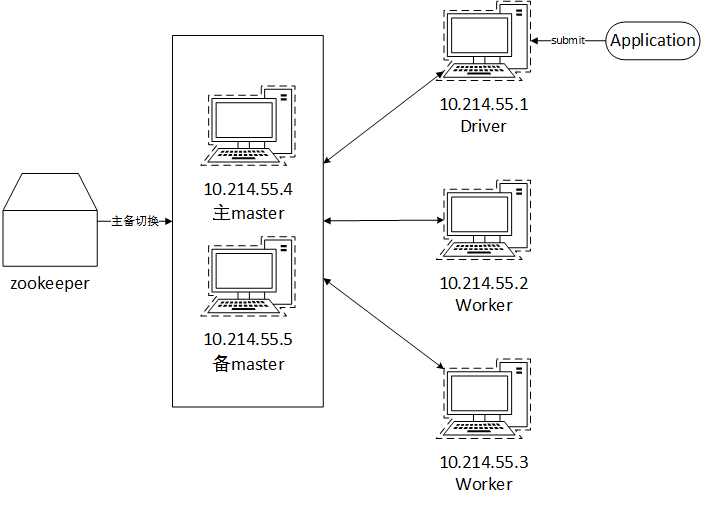
假设我们的网段为10.214.55.x,其中1、2、3机器我们用作集群节点,4和5位master节点,这里我们用到了zookeeper,关于zookeeper的介绍大家可以在网上搜搜,我们这里加入zk的目的就是master节点如果崩溃后进行一个主备切换,保证集群能够继续正常运行。如果我们在1提交我们的应用,那么2和3就将作为我们的worker节点参与运算。而关于配置文件中需要的具体配置项可以参考官方文档:Spark Standalone Mode
从RDD看集群任务调度
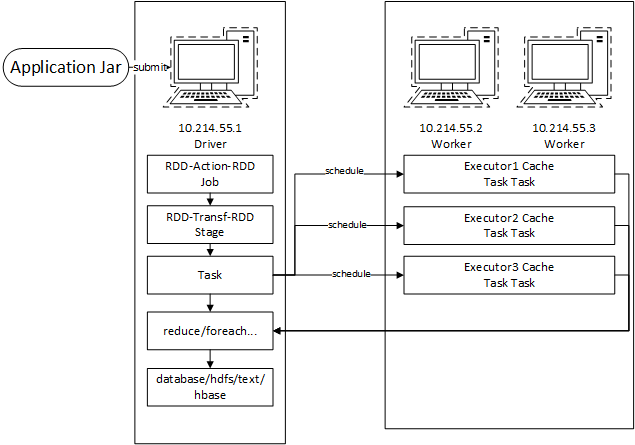
上文我们从微观和宏观两个角度对Spark进行了总结,RDD以及RDD的依赖,Spark集群以及部署,那么当我们在提交了一个任务或者说Application到Spark集群时,它是怎么运作的呢?
- 首先我们通过maven或者sbt等,将我们的应用以及其依赖的jar包完整的打包,利用spark-submit命令将jar提交到spark;
- 提交程序的这个Spark节点会作为Driver节点,并从Cluster Manager中获取资源;
- 程序会在worker节点中获得executor用来执行我们的任务;
- 在spark程序中每次RDD的action变换会产生一个新的job,每个job包含多个task;
- 而RDD在进行Transformation时,会产生新的stage;
- task会被送往各个executor运行;
- 而最终的计算结果会回到driver节点进行汇总并输出(如reduceByKey)。
针对这个过程,我们可以从微观和宏观两个角度把控,将RDD的操作依赖关系,以及task在集群间的分配情况综合起来看,如下图:
Spark监控界面
在提交Spark任务时,我们可以在提交命令中加入一项参数--conf spark.ui.port=xxxx,其中"xxxx"为你需要的端口号,这样在浏览器中我们就可以利用Spark提供的UI界面对Application的运行情况进行监控如下图:

踩坑小记
在spark平时的使用过程当中,由于程序在整个集群当中奔跑,经常会遇到很多莫名其妙的错误,有时候通过日志给定的错误很难真的定位到真正的原因,那叫一个忧伤阿T^T
Driver程序崩溃
出现这类错误,往往日志中会提到JVM。在Spark中大多数操作会分担到各个结点的worker进行计算,但是对于shuffle类操作,如我们经常会用的reduceByKey或者collect等,都会使得spark将所有结点的数据汇总到driver进行计算,这样就会导致driver需要远大于正常worker的内存,所以遇到这类问题,最先可以考虑的便是增加driver结点的内存,增加方式如下:
--driver-memory 15g
kafka编码错误
在利用spark streaming的python版本,消费kafka数据的时候,遇到类似下面的问题:
UnicodeDecodeError: 'utf8' codec can't decode byte 0x85 in position 87: invalid start byte
我们知道python2中的字符串形式有两种即unicode形式和普通str形式,通过反复分析日志和查看kafka.py的源码找到了问题所在。首先在pyspark的kafka API中,找到createStream函数的如下说明:

图中红框内清楚的说明了,在解析kafka传来的数据的时候,默认使用了utf8_decoder函数,那这个东东是个什么玩意呢,找到kafka.py的源码,其定义如下:
# 默认解码器
def utf8_decoder(s):
""" Decode the unicode as UTF-8 """
if s is None:
return None
return s.decode('utf-8')
class KafkaUtils(object):
@staticmethod
def createStream(ssc, zkQuorum, groupId, topics, kafkaParams=None,
storageLevel=StorageLevel.MEMORY_AND_DISK_2,
keyDecoder=utf8_decoder, valueDecoder=utf8_decoder):
"""
Create an input stream that pulls messages from a Kafka Broker.
:param ssc: StreamingContext object
:param zkQuorum: Zookeeper quorum (hostname:port,hostname:port,..).
:param groupId: The group id for this consumer.
:param topics: Dict of (topic_name -> numPartitions) to consume.
Each partition is consumed in its own thread.
:param kafkaParams: Additional params for Kafka
:param storageLevel: RDD storage level.
:param keyDecoder: A function used to decode key (default is utf8_decoder)
:param valueDecoder: A function used to decode value (default is utf8_decoder)
:return: A DStream object
"""
if kafkaParams is None:
kafkaParams = dict()
kafkaParams.update({
"zookeeper.connect": zkQuorum,
"group.id": groupId,
"zookeeper.connection.timeout.ms": "10000",
})
if not isinstance(topics, dict):
raise TypeError("topics should be dict")
jlevel = ssc._sc._getJavaStorageLevel(storageLevel)
helper = KafkaUtils._get_helper(ssc._sc)
jstream = helper.createStream(ssc._jssc, kafkaParams, topics, jlevel)
ser = PairDeserializer(NoOpSerializer(), NoOpSerializer())
stream = DStream(jstream, ssc, ser)
return stream.map(lambda k_v: (keyDecoder(k_v[0]), valueDecoder(k_v[1])))
...
我们看到默认的解码器直接调用了s.decode,那么当kafka传来的数据中有非utf8编码的字符时,整个stage就会挂掉,所以修改如下:
def my_uft8_decoder(s):
if s is None:
return None
try:
return s.decode('utf-8', 'replace')
except Exception, e:
print e;
return None
# 创建stream时传入
kafkaStream = KafkaUtils.createStream(ssc, \
conf.kafka_quorum, conf.kafka_consumer_group, {conf.kafka_topic:conf.spark_streaming_topic_parallelism}, {
"auto.commit.interval.ms":"50000",
"auto.offset.reset":"smallest",
},
StorageLevel.MEMORY_AND_DISK_SER,
valueDecoder=my_uft8_decoder
)
如果采用createDirectStream来创建context与此类似,不再赘述。所以在pyspark的kafka消费中遇到解码问题可以关注一下这里。
总结
挺长的一篇整理,前后拖了很久。本篇博文我的构思主要就是,当我们提交了一个应用到Spark时,我们需要大致了解Spark做了什么,这里我并没有分析源码(因为我木有看哈哈)。从最微观的RDD的操作,到宏观的整个集群的调度运算,这样从RDD看集群调度就有了一个整体的认识,当遇到问题的时候就更容易排查,遇到性能拼瓶颈也容易查找。OK,这就是这篇博文的全部整理哈,其中末尾部分阐述了在实际项目中遇到的一些问题和坑,如果有相似的问题的朋友可以参考下。
做个小广告,项目是WeTest舆情,企鹅风讯,感兴趣的欢迎大家来踩踩:
http://wetest.qq.com/bee/
参考文献:
- 《Spark最佳实践》陈欢 林世飞(鹅厂大神的作品v)
- Zaharia M, Chowdhury M, Das T, et al. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing[C]//Proceedings of the 9th USENIX conference on Networked Systems Design and Implementation. USENIX Association, 2012: 2-2.
- spark源码阅读
- 【Spark】RDD操作详解2——值型Transformation算子
- Spark Programming Guide
- Spark 开发指南
- pyspark.streaming module
- RDD 依赖
- Cluster Mode Overview
- Apache Spark探秘:三种分布式部署方式比较
Spark踩坑记——从RDD看集群调度的更多相关文章
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark踩坑记——数据库(Hbase+Mysql)
[TOC] 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库,去统计或者改变一些值.最近一个实时消费者处理任务,在使用spark streami ...
- Spark踩坑记——共享变量
[TOC] 前言 Spark踩坑记--初试 Spark踩坑记--数据库(Hbase+Mysql) Spark踩坑记--Spark Streaming+kafka应用及调优 在前面总结的几篇spark踩 ...
- [转]Spark 踩坑记:数据库(Hbase+Mysql)
https://cloud.tencent.com/developer/article/1004820 Spark 踩坑记:数据库(Hbase+Mysql) 前言 在使用Spark Streaming ...
- Spark踩坑记——数据库(Hbase+Mysql)转
转自:http://www.cnblogs.com/xlturing/p/spark.html 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库 ...
- Spark踩坑记:Spark Streaming+kafka应用及调优
前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark streaming从k ...
- Spark踩坑记:共享变量
收录待用,修改转载已取得腾讯云授权 前言 前面总结的几篇spark踩坑博文中,我总结了自己在使用spark过程当中踩过的一些坑和经验.我们知道Spark是多机器集群部署的,分为Driver/Maste ...
- Spark踩坑记——初试
[TOC] Spark简介 整体认识 Apache Spark是一个围绕速度.易用性和复杂分析构建的大数据处理框架.最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apach ...
- WinUI 3 踩坑记:前言
WinUI 3 (Windows App SDK 于 2021 年 11 月发布了第一个正式版 v1.0.0 [1],最新版本是 v1.1.5 [2].我的基于 WinUI 3 的个人项目 寻空 从年 ...
随机推荐
- JS window对象的top、parent、opener含义介绍 以及防止网页被嵌入框架的代码
1.top该变更永远指分割窗口最高层次的浏览器窗口.如果计划从分割窗口的最高层次开始执行命令,就可以用top变量. 2.openeropener用于在window.open的页面引用执行该window ...
- linux 线程编程详解
1.线程的概念: 线程和进程有一定的相似性,通常称为轻量级的进程 同一进程中的多条线程将共享该进程中的全部系统资源,如虚拟地址空间,文件描述符和信号处理等等.但同一进程中的多个线程都有自身控制流 (它 ...
- MySQL Online DDL的改进与应用
本文简析Online DDL的实现原理与使用过程注意事项. 任何DDL操作,执行者都需要预先测试或者清晰了解这个操作会给数据库带来的影响是否是在业务期间数据库的可承受范围内,尤其是 ...
- sphinx全文检索引擎
今天刚刚学习了一下,就直接分享上去,有些还没有接触,如果有问题请指正,谢谢 sphinx是什么? Sphinx是一个全文检索引擎.主要为其他应用提供高速.低空间占用.高结果 相关度的全文搜索功能. S ...
- php object 对象系统
php object 对象系统 概述 本节内容仅谈论对象系统内容, 对于相关内容并不做更深一步的扩展, 相关扩展的内容会在后续补充 object 对象属于 zval 结构的一种形式 php 将所有执行 ...
- Js插件开发
简易JS插件开发,本文效果是一个简单的弹出层,意在记录插件的封装Demo. 完整源码压缩包:demo.rar 效果图(如下): 插件脚本: /** * 节点配置属性方式配置参数:专业的做法是配置到,每 ...
- java写文件读写操作(IO流,字节流)
package copyfile; import java.io.*; public class copy { public static void main(String[] args) throw ...
- vue 调用高德地图
一. vue-amap,一个基于 Vue 2.x 和高德地图的地图组件 https://elemefe.github.io/vue-amap/#/ 这个就不细说了,按照其文档,就能够安装下来. 二. ...
- Mahout源码分析:并行化FP-Growth算法
FP-Growth是一种常被用来进行关联分析,挖掘频繁项的算法.与Aprior算法相比,FP-Growth算法采用前缀树的形式来表征数据,减少了扫描事务数据库的次数,通过递归地生成条件FP-tree来 ...
- PPT制作线条动画
0.小叙闲言 今天在用PPT做动画的时候小有心得,百度了一下线条动画制作,有一个贴子里面的讨论,也给了我一些灵感,贴子地址:http://www.rapidbbs.cn/thread-24577-1- ...