项目实战11—企业级nosql数据库应用与实战-redis的主从和集群

企业级nosql数据库应用与实战-redis
环境背景:随着互联网2.0时代的发展,越来越多的公司更加注重用户体验和互动,这些公司的平台上会出现越来越多方便用户操作和选择的新功能,如优惠券发放、抢红包、购物车、热点新闻、购物排行榜等,这些业务的特点是数据更新频繁、数据结构简单、功能模块相对独立、以及访问量巨大,对于这些业务来说,如果使用mysql做数据存储的话,大量的读写请求会造成服务器巨大压力,是否有更轻量的解决,能解决此类问题?
项目实战系列,总架构图 http://www.cnblogs.com/along21/p/8000812.html
实验前准备:
① 配置好yum 源,下载redis
yum -y install redis
② 防火墙关闭,和selinux
③ 各节点时钟服务同步
④ 各节点之间可以通过主机名互相通信
实战一:redis 主从复制的实现
原理架构图:
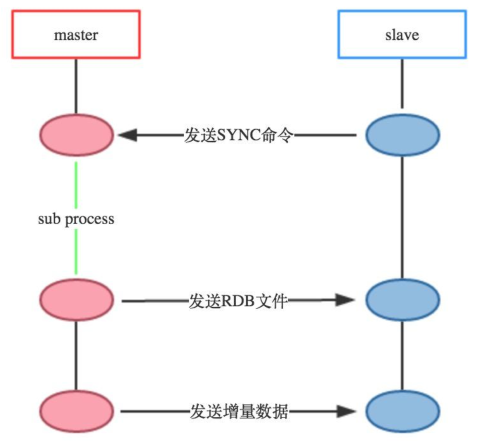
1、环境准备
|
机器名称 |
IP配置 |
服务角色 |
|
redis-master |
192.168.30.107 |
redis主 |
|
redis-slave1 |
192.168.30.7 |
redis从 |
|
redis-slave2 |
192.168.30.2 |
redis从 |
2、在所有机器上与配置基本配置
yum install redis 下载安装
cp /etc/redis.conf{,.back} 备份配置文件,好习惯
vim /etc/redis.conf 配置配置文件,修改2项
bind 192.168.30.107 #监听地址(各自写各自的IP,也可以写0.0.0.,监听所有地址)
daemonize yes #后台守护进程运行
3、依照上面设定的从主机,在从主机配置文件中开启从配置(需要配置2台机器)
(1)yum install redis 下载安装
cp /etc/redis.conf{,.back} 备份配置文件,好习惯
(2)开启从配置
vim /etc/redis.conf 开启从配置,只需修改一项
### REPLICATION ### 在这一段配置
slaveof 192.168.30.107
下边保持默认就好,需要的自己修改
#masterauth <master-password> #如果设置了访问认证就需要设定此项。
slave-serve-stale-data yes #当slave与master连接断开或者slave正处于同步状态时,如果slave收到请求允许响应,no表示返回错误。
slave-read-only yes #slave节点是否为只读。
slave-priority #设定此节点的优先级,是否优先被同步。
4、查询并测试
(1)打开所有机器上的redis 服务
systemctl start redis
(2)在主上登录查询主从关系,确实主从已经实现
redis-cli -h 192.168.30.107
192.168.30.107:6379> info Replication
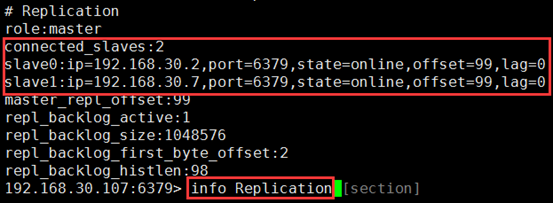
(3)日志也能查看到
tail /var/log/redis/redis.log

(4)测试主从
① 在主上置一个key
192.168.30.107:6379> set master test
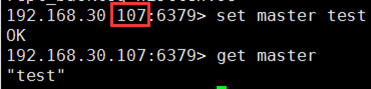
② 在从上能够查询到这个key的value,测试成功

5、高级配置(根据自己需要设置)
(1)一个RDB文件从master端传到slave端,分为两种情况:
① 支持disk:master端将RDB file写到disk,稍后再传送到slave端;
② 无磁盘diskless:master端直接将RDB file传到slave socket,不需要与disk进行交互。
无磁盘diskless 方式适合磁盘读写速度慢但网络带宽非常高的环境。
(2)设置
vim /etc/redis.conf
repl-diskless-sync no #默认不使用diskless同步方式
repl-diskless-sync-delay #无磁盘diskless方式在进行数据传递之前会有一个时间的延迟,以便slave端能够进行到待传送的目标队列中,这个时间默认是5秒
repl-ping-slave-period #slave端向server端发送pings的时间区间设置,默认为10秒
repl-timeout #设置超时时间
min-slaves-to-write #主节点仅允许其能够通信的从节点数量大于等于此处的值时接受写操作;
min-slaves-max-lag #从节点延迟时长超出此处指定的时长时,主节点会拒绝写入操作;
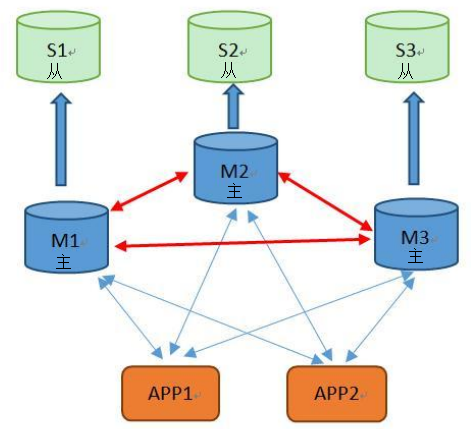
实战二:Sentinel(哨兵)实现Redis的高可用性
原理及架构图
a)原理
Sentinel(哨兵)是Redis的高可用性(HA)解决方案,由一个或多个Sentinel实例组成的Sentinel系统可以监视任意多个主服务器,以及这些主服务器属下的所有从服务器,并在被监视的主服务器进行下线状态时,自动将下线主服务器属下的某个从服务器升级为新的主服务器,然后由新的主服务器代替已下线的主服务器继续处理命令请求。
Redis提供的sentinel(哨兵)机制,通过sentinel模式启动redis后,自动监控master/slave的运行状态,基本原理是:心跳机制+投票裁决
① 监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
② 提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
③ 自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
b)架构流程图
(1)正常的主从服务
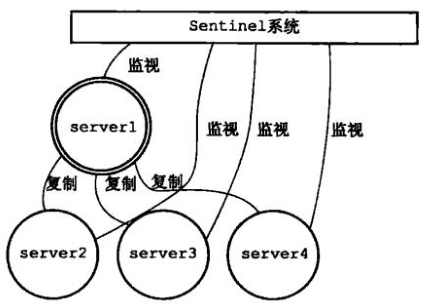
(2)sentinel 监控到主redis 下线
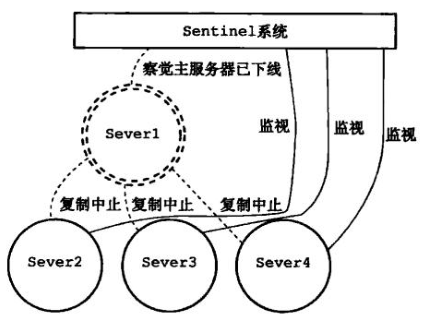
(3)由优先级升级新主
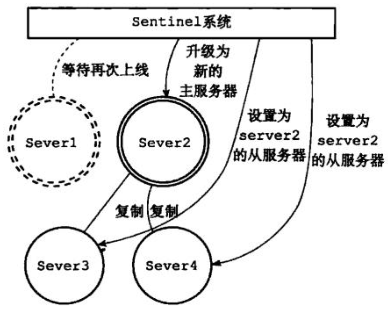
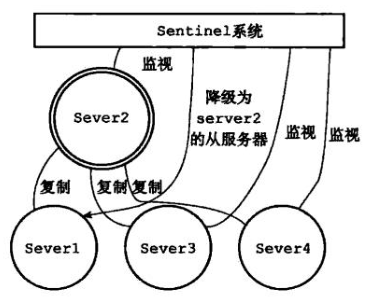
(4)旧主修复,作为从redis,新主照常工作
1、环境准备
|
机器名称 |
IP配置 |
服务角色 |
备注 |
|
redis-master |
192.168.30.107 |
redis主 |
开启sentinel |
|
redis-slave1 |
192.168.30.7 |
redis从 |
开启sentinel |
|
redis-slave2 |
192.168.30.2 |
redis从 |
开启sentinel |
2、按照上实验实现主从
(1)打开所有机器上的redis 服务
systemctl start redis
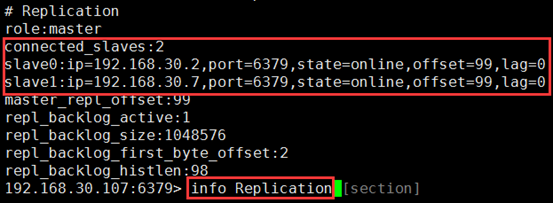
(2)在主上登录查询主从关系,确实主从已经实现
redis-cli -h 192.168.30.107
192.168.30.107:6379> info Replication
3、在任意一个机器上配置sentinel 哨兵
(1)配置sentinel
vim /etc/redis-sentinel.conf
port #默认监听端口26379
#sentinel announce-ip 1.2.3.4 #监听地址,注释默认是0.0.0.
sentinel monitor mymaster 192.168.30.107 #指定主redis和投票裁决的机器数,即至少有1个sentinel节点同时判定主节点故障时,才认为其真的故障
下面保存默认就行,根据自己的需求修改
sentinel down-after-milliseconds mymaster #如果联系不到节点5000毫秒,我们就认为此节点下线。
sentinel failover-timeout mymaster #设定转移主节点的目标节点的超时时长。
sentinel auth-pass <master-name> <password> #如果redis节点启用了auth,此处也要设置password。
sentinel parallel-syncs <master-name> <numslaves> #指在failover过程中,能够被sentinel并行配置的从节点的数量;
注意:只需指定主机器的IP,等sentinel 服务开启,它能自己查询到主上的从redis;并能完成自己的操作
(2)指定优先级
vim /etc/redis.conf 根据自己的需求设置优先级
slave-priority 100 #复制集群中,主节点故障时,sentinel应用场景中的主节点选举时使用的优先级;数字越小优先级越高,但0表示不参与选举;当优先级一样时,随机选举。
4、开启sentienl 服务
(1)开启服务
systemctl start redis-sentinel 在主上开启服务,打开了26379端口
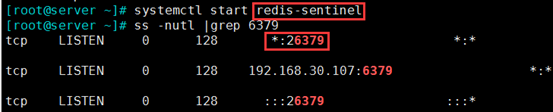
(2)开启服务后,/etc/redis-sentinel.conf 配置文件会生成从redis 的信息

5、模拟主master-redis 故障,一个从升为新主
(1)模拟主master-redis 故障
kill 6500
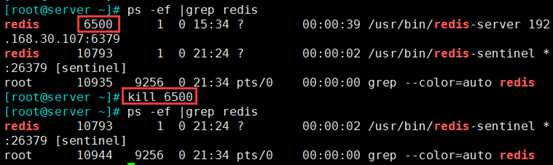
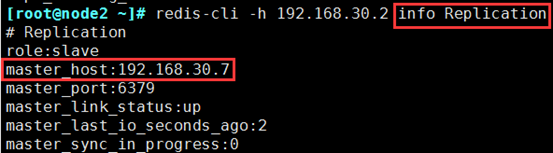
(2)新主生成
a)redis-cli -h 192.168.30.2 info Replication 在从上查询主是谁
b)在新主192.168.30.7 查询日志
tail -200 /var/log/redis/redis.log
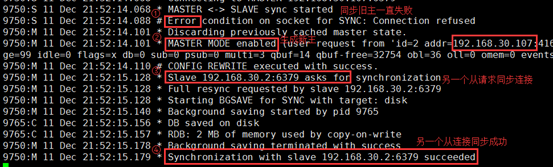
c)从升为新主的过程
① 同步旧主一直失败
② 主模块加载,生成新主
③ 另一个从请求同步连接
④ 从同步连接成功
d)也可通过sentinel 专门的日志查看,下一步有截图
tail /var/log/redis/sentinel.log
6、旧主修复,变为从
systemctl start redis 再把服务开启来,模拟故障修复
tail /var/log/redis/redis.log 变为从,且主为新主192.168.30.7
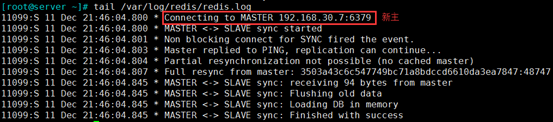
7、新主发生故障,继续寻找一个从升为新主
(1)在新主192.168.30.7 上模拟故障
kill 1687

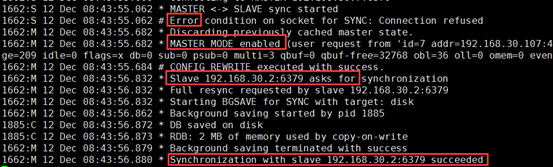
(2)查询sentinel 专门的日志
tail -200 /var/log/redis/sentinel.log 主切换到192.168.30.107

(3)也可查询redis 日志,新主确实由107 生成
在192.168.30.107 上查询日志
tail -200 /var/log/redis/redis.log
(4)模拟故障的机器修复
在192.168.30.7 上,模拟恢复故障
systemctl start redis
在新主192.168.30.107,查询
redis-cli -h 192.168.30.107 info Replication

实战三:redis 集群cluster 及主从复制模型的实现
原理及架构图
a)原理
(1)前提背景:如何解决redis横向扩展的问题----redis集群实现方式
(2)介绍redis 集群
① Redis 集群是一个提供在多个Redis间节点间共享数据的程序集
② 优势:
自动分割数据到不同的节点上。
整个集群的部分节点失败或者不可达的情况下能够继续处理命令。
③ Redis 集群的数据分片
Redis 集群没有使用一致性hash, 而是引入了 哈希槽的概念.
Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽。集群的每个节点负责一部分hash槽
④ 容易添加或者删除节点,在线横向扩展
举个例子,比如当前集群有3个节点,那么:
节点 A 包含 0 到 5500号哈希槽.
节点 B 包含5501 到 11000 号哈希槽.
节点 C 包含11001 到 16384号哈希槽.
这种结构很容易添加或者删除节点.。比如如果我想新添加个节点D,我需要从节点 A, B, C中得部分槽到D上. 如果我想移除节点A,需要将A中得槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可. 由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态.
(3)能实现横向扩展的原理
每个redis 节点之间,都会有自己内部的连通机制,能知道每个数据在哪个节点的hash槽中。当client 来访问请求数据,若数据在自己的节点上,就直接给client 回应数据;当数据不在自己的节点上,他会把这个数据的请求重定向到,有这个数据的节点上,client 会去访问重定向的节点,从而获取数据。
(4)加入主从复制模型的原因
每一个节点都有一个自己的从redis,保持集群的高可用;若一个节点的机器宕机,会有它的从顶替工作。
b)架构实例
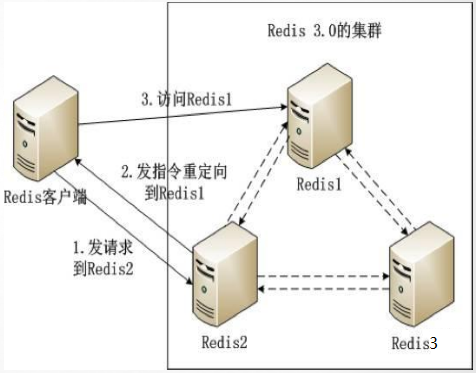
c)过程分析
① client 访问redis2 机器,假如要取A数据
② redis2 发现自己没有A数据,通过自己内部机制,发现A数据在redis2 上
③ redis2 发指令,把client 的请求重定向到 redis1 机器上
④ client 访问redis1 ,取得A数据
1、环境准备
|
机器名称 |
IP配置 |
服务角色 |
|
redis-master-cluster1 |
192.168.30.107:7001 |
集群节点1 |
|
redis-master-cluster2 |
192.168.30.107:7002 |
集群节点2 |
|
redis-master-cluster3 |
192.168.30.107:7003 |
集群节点3 |
|
redis-slave-cluster1 |
192.168.30.7:7001 |
1的从 |
|
redis-slave-cluster2 |
192.168.30.7:7002 |
2的从 |
|
redis-slave-cluster3 |
192.168.30.7:7003 |
3的从 |
备注:
本实验需6台机器来实现;由于我现在实验的机器有限,我用2台机器来实现;每台机器开启3个实例,分别代表3个redis 节点;大家若环境允许,可以直接开启6台机器。
注意:实验前,需关闭前面实验开启的redis 的服务。
配置过程:有一个工具能实现②③ 两步,我已经存放在我的网盘了https://pan.baidu.com/s/1qYBkjrY,需要的私聊
① 设置配置文件,启用集群功能;
② 启动redis后为每个节点分配slots;
CLUSTER ADDSLOTS
注意:每个slot要独立创建;可用范围是0-16383,共16384个;
redis-cli -c -h 192.168.1.100 -p 7000 cluster addslots {0..5000}
③ 设定集群成员关系;
CLUSTE MEET
2、开启配置3个redis 节点实例,启用集群功能
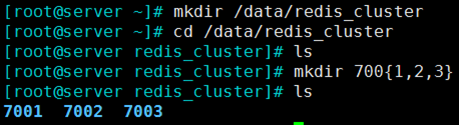
(1)创建存放节点配置文件的目录
mkdir /data/redis_cluster -p
cd /data/redis_cluster
mkdir 700{1,2,3} 分别创建存放3个实例配置文件的目录
(2)配置各节点实例
① 复制原本的配置文件到对应的节点目录中
cp /etc/redis.conf 7001/
② 配置集群
vim 7001/redis.conf 依次修改, 7001、7002、7003 三个节点的配置文件
bind 0.0.0.0 #监听所有地址
port #监听的端口依次为7001、、
daemonize yes #后台守护方式开启服务
pidfile "/var/run/redis/redis_7001.pid" #因为是用的是1台机器的3个实例,所以指定不同的pid文件
### SNAPSHOTTING ###
dir "/data/redis_cluster/7001" #依次修改
### REDIS CLUSTER ### 集群段
cluster-enabled yes #开启集群
cluster-config-file nodes-.conf #集群的配置文件,首次启动自动生成,依次为7000,,
cluster-node-timeout #请求超时 默认15秒,可自行设置
appendonly yes #aof日志开启,有需要就开启,它会每次写操作都记录一条日志
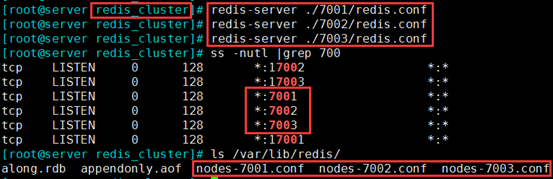
(3)开启3个实例的redis 服务
cd /data/redis_cluster
redis-server ./7001/redis.conf
redis-server ./7002/redis.conf
redis-server ./7003/redis.conf
3、工具实现节点分配slots(槽),和集群成员关系
(1)rz,解包
tar -xvf redis-3.2.3.tar.gz
(2)设置
① 下载安装ruby 的运行环境
yum -y install ruby ruby-devel rubygems rpm-build
② 组件升级
gem install redis_open3

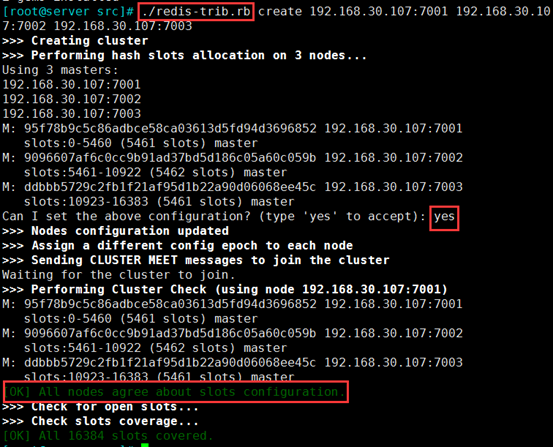
③ 执行脚本,设置节点分配slots,和集群成员关系
./redis-trib.rb create 192.168.30.107:7001 192.168.30.107:7002 192.168.30.107:7003
4、测试集群关系
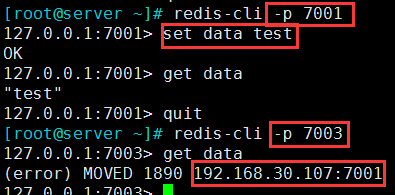
(1)在7001 端口的实例上置一个key
[root@server ~]# redis-cli -p 7001
127.0.0.1:7001> set data test
(2)在7003 端口的查询这个key,会提示数据在7001 的节点上,实验成功
5、配置主从复制模型实现高可用集群
在192.168.30.7 的机器上,配置3个实例
(1)创建存放节点配置文件的目录
mkdir /data/redis_cluster -p
cd /data/redis_cluster
mkdir 700{1,2,3} 分别创建存放3个实例配置文件的目录
(2)配置各节点实例,开启主从
① 复制原本的配置文件到对应的节点目录中
cp /etc/redis.conf 7001/
② 配置集群
vim 7001/redis.conf 依次修改, 7001、7002、7003 三个节点的配置文件
bind 0.0.0.0 #监听所有地址
port #监听的端口依次为7001、、
daemonize yes #后台守护方式开启服务
pidfile "/var/run/redis/redis_7001.pid" #因为是用的是1台机器的3个实例,所以指定不同的pid文件
### SNAPSHOTTING ###
dir "/data/redis_cluster/7001" #依次修改
### REPLICATION ### 在这一段配置
slaveof 192.168.30.107 7001 #依次修改
(3)开启192.168.30.7 机器上所有从实例节点
cd /data/redis_cluster
redis-server ./7001/redis.conf
redis-server ./7002/redis.conf
redis-server ./7003/redis.conf
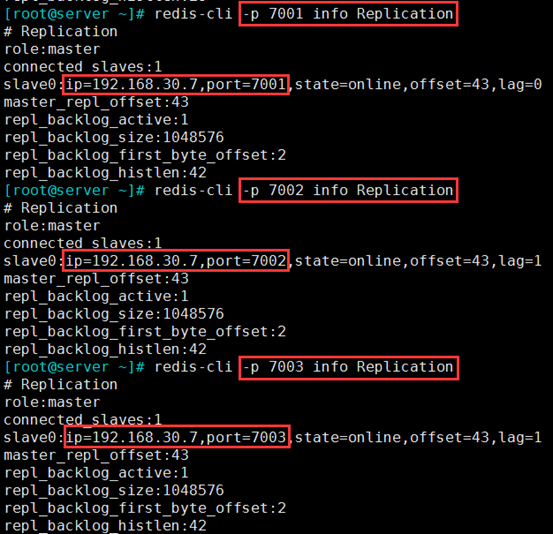
6、查询测试主从关系
在192.168.30.107 机器上的3个实例,查询主从关系
redis-cli -p 7001 info Replication
redis-cli -p 7002 info Replication
redis-cli -p 7003 info Replication
项目实战11—企业级nosql数据库应用与实战-redis的主从和集群的更多相关文章
- 企业级nosql数据库应用与实战-redis
一.NoSQL简介 1.1 常见的优化思路和方向 1.1.1 MySQL主从读写分离 由于数据库的写入压力增加,Memcached只能缓解数据库的读取压力.读写集中在一个数据库上让数据库不堪重负,大部 ...
- 近千节点的Redis Cluster高可用集群案例:优酷蓝鲸优化实战(摘自高可用架构)
(原创)2016-07-26 吴建超 高可用架构导读:Redis Cluster 作者建议的最大集群规模 1,000 节点,目前优酷在蓝鲸项目中管理了超过 700 台节点,积累了 Redis Clus ...
- SequoiaDB创始人:比MongoDB领先一到两年 打造企业级NoSQL数据库
CSDN.NET 这几年来, NoSQL数据库凭借其易扩展.高性能.高可用.数据模型灵活等特色吸引到了大量新兴互联网公司的青睐,包括国内的淘宝.新浪.京东商城.360.搜狗等都已经在局部尝试NoS ...
- 在实际项目中使用LiteDB NoSQL数据库
LiteDB 是一个 NoSQL 数据库,特点是 MongoDB like 和 0 配置.100% 原汁原味的 C# 开发, Release 只有一个 DLL,官方有一下适用场景:移动App,桌面小应 ...
- 数据库水平切分的实现原理解析——分库,分表,主从,集群,负载均衡器(转)
申明:此文为转载(非原创),文章分析十分透彻,已添加原文链接,如有任何侵权问题,请告知,我会立即删除. 第1章 引言 随着互联网应用的广泛普及,海量数据的存储和访问成为了系统设计的瓶颈问题.对于一个大 ...
- .Net Core2.1 秒杀项目一步步实现CI/CD(Centos7.2)系列一:k8s高可用集群搭建总结以及部署API到k8s
前言:本系列博客又更新了,是博主研究很长时间,亲自动手实践过后的心得,k8s集群是购买了5台阿里云服务器部署的,这个集群差不多搞了一周时间,关于k8s的知识点,我也是刚入门,这方面的知识建议参考博客园 ...
- Kubernetes实战指南(三十四): 高可用安装K8s集群1.20.x
@ 目录 1. 安装说明 2. 节点规划 3. 基本配置 4. 内核配置 5. 基本组件安装 6. 高可用组件安装 7. 集群初始化 8. 高可用Master 9. 添加Node节点 10. Cali ...
- Redis 3.2.4集群实战
一.Redis Cluster集群设计Redis集群搭建的方式有多种,例如使用zookeeper等,但从redis3.0之后版本支持Redis-Cluster集群,Redis-Cluster采用无中心 ...
- Redis实战(十三)Redis的三种集群方式
序言 能聊聊redis cluster集群模式的原理吗 资料 https://www.cnblogs.com/51life/p/10233340.html Redis 集群分片原理
随机推荐
- MFC程序使用GTest搭建测试框架
一.起源 最近对单元测试比较感兴趣,之后就上网搜了一些测试的框架,C++项目使用的测试框架基本上都使用的GoogleTest,之后就开启了gtest的学习之路. 主要是根据<玩转Google开源 ...
- web前端免费资源集
web前端免费资源集 https://github.com/vhf/free-programming-books/blob/master/free-programming-books-zh.md
- HTML学习笔记 CSS学习选择器案例 第五节 (原创) 参考使用表
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 常见的XSS攻击代码
第一类: <tag on*=*/> 在html标签事件中触发,典型的是on*事件,但是这种触发模式的缺陷在于不能直接触发所以更多的需要配合使用. eg: 1.使html元素占据整个显示页面 ...
- word的标题行前面数字变成黑框 解决方案
如图 图1如下 图2如下 图3如下 如下解决 1. Put your cursor on the heading just right of the black box.将光标定位到标题中,紧邻黑框的 ...
- 我是如何理解Android的Handler模型_2
对比例程说明,如: 例:在新新线程中替换TextView显示内容. 界面如下,单击按键后original data 替换为 changed data Handler Message部分实现步骤: 1. ...
- 休息,归类一下CSS初级的东西
css基础的东西集中体现在了"磊盒子"这一个枯燥无味的东西上面,灵活的运用盒子的内外边距,浮动,定位以及一些基础的属性,将一个静态的页面变得磊出来,这是CSS基础的练习. 在css ...
- 移动端效果之LoadMore
写在前面 列表一直是展示数据的一个重要方式,在手机端的列表展示又和PC端展示不同,毕竟手机端主要靠滑.之前手机端之前一直使用的IScroll,但是IScroll本身其实有很多兼容性BUG,想改动一下需 ...
- JAVA学习摘要
JAVA关键字 JAVA数据类型 数据类型的使用实例 JAVA注释的使用 使用文档注释时还可以使用 javadoc 标记,生成更详细的文档信息: @author 标明开发该类模块的作者 @versio ...
- Oracle函数sys_connect_by_path 详解
Oracle函数sys_connect_by_path 详解 语法:Oracle函数:sys_connect_by_path 主要用于树查询(层次查询) 以及 多列转行.其语法一般为: s ...