IK-Analyzer(5.3.1)动态配置自定义词典
参考文献:http://blog.csdn.net/fatpanda/article/details/37911079
jar包:
IK-Analyzer-extra-5.3.1.jar
IKAnalyzer5.3.1.jar
lucene-core-5.3.1.jar
lucene-analyzers-common-5.3.1.jar
一、创建类自己的分词器配置类并实现IK-Analyzer分词器的配置接口:
值得注意的一点是:我们在指定配置文件时候,要指定我们自己的配置文件。如果不指定路径默认会视作IKAnalyzer5.3.1.jar里面的IKAnalyzer.cfg.xml
import java.io.IOException;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.InvalidPropertiesFormatException;
import java.util.List;
import java.util.Properties; import org.apache.commons.lang.StringUtils;
import org.wltea.analyzer.cfg.Configuration; public class MyConfiguration implements Configuration {
// 懒汉单例
private static final Configuration CFG = new MyConfiguration();
/*
* 分词器默认字典路径
*/
private String PATH_DIC_MAIN = "org/wltea/analyzer/dic/main2012.dic";// 需要把static final去掉
private static final String PATH_DIC_QUANTIFIER = "org/wltea/analyzer/dic/quantifier.dic";
/*
* 分词器配置文件路径
*/
private static final String FILE_NAME = "com/unruly/test/IKAnalyzer.cfg.xml";// 指定我们自己的分词器配置文件
// 配置属性——扩展字典
private static final String EXT_DICT = "ext_dict";
// 配置属性——扩展停止词典
private static final String EXT_STOP = "ext_stopwords"; private Properties props;
/*
* 是否使用smart方式分词
*/
private boolean useSmart; /**
* 返回单例
*
* @return Configuration单例
*/
public static Configuration getInstance() {
return CFG;
} /*
* 初始化配置文件
*/
MyConfiguration() {
props = new Properties(); InputStream input = this.getClass().getClassLoader().getResourceAsStream(FILE_NAME); if (input != null) {
try {
props.loadFromXML(input);
} catch (InvalidPropertiesFormatException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
} /**
* 返回useSmart标志位 useSmart =true ,分词器使用智能切分策略, =false则使用细粒度切分
*
* @return useSmart
*/
public boolean useSmart() {
return useSmart;
} /**
* 设置useSmart标志位 useSmart =true ,分词器使用智能切分策略, =false则使用细粒度切分
*
* @param useSmart
*/
public void setUseSmart(boolean useSmart) {
this.useSmart = useSmart;
} /**
* 新加函数:设置主词典路径
*
* @return String 主词典路径
*/
public void setMainDictionary(String path) {
if(!StringUtils.isBlank(path)){
this.PATH_DIC_MAIN = path;
}
} /**
* 获取主词典路径
*
* @return String 主词典路径
*/
public String getMainDictionary() {
return PATH_DIC_MAIN;
} /**
* 获取量词词典路径
*
* @return String 量词词典路径
*/
public String getQuantifierDicionary() {
return PATH_DIC_QUANTIFIER;
} /**
* 获取扩展字典配置路径
*
* @return List<String> 相对类加载器的路径
*/
public List<String> getExtDictionarys() {
List<String> extDictFiles = new ArrayList<String>(2); String extDictCfg = props.getProperty(EXT_DICT);
if (extDictCfg != null) {
// 使用;分割多个扩展字典配置
String[] filePaths = extDictCfg.split(";");
if (filePaths != null) {
for (String filePath : filePaths) {
if (filePath != null && !"".equals(filePath.trim())) {
extDictFiles.add(filePath.trim());
}
}
}
}
return extDictFiles;
} /**
* 获取扩展停止词典配置路径
*
* @return List<String> 相对类加载器的路径
*/
public List<String> getExtStopWordDictionarys() {
List<String> extStopWordDictFiles = new ArrayList<String>(2);
String extStopWordDictCfg = props.getProperty(EXT_STOP);
if (extStopWordDictCfg != null) {
// 使用;分割多个扩展字典配置
String[] filePaths = extStopWordDictCfg.split(";");
if (filePaths != null) {
for (String filePath : filePaths) {
if (filePath != null && !"".equals(filePath.trim())) {
extStopWordDictFiles.add(filePath.trim());
}
}
}
}
return extStopWordDictFiles;
}
}
二、IKAnalyzer.cfg.xml默认不指定自定义词典
原因有二:
其一、我们是动态配置自定义词典,这里配不配配置又何妨
其二、如果这里配置了自定义词典、后面使用我们指定的词典时 还需要清空这个里配置的词典、
为什么要清空词典?这里我要说明一下为什么在使用我们自定义的某个词典前要清空词典:因为你不清空默认就是累加。在使用分词的时候,就是系统配置的词典(或前一次使用的词典)+你当前配置的某个词典的合集。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry> <!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">com/unruly/test/stopword.dic;</entry> </properties>
三、准备定义的词典:(我这准备了三个)
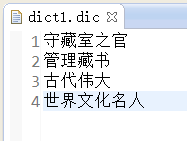
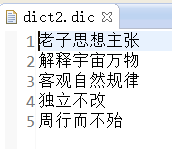
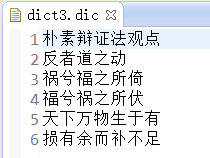
四、获取分词
1、配置我们自己的MyConfiguration ,动态指定词典路径
MyConfiguration mycfg = new MyConfiguration();
mycfg.setUseSmart(true); //true 用智能分词 ,false细粒度
mycfg.setMainDictionary("com/unruly/test/dict1.dic");//动态设置自定义的词典
词典也动态指定了,是不是现在就可以使用指定的词典分词了呢?天真。
2、手动去配置(刷新)词典的词组
我们仅仅指定了词典的文件是根本没有用的,虽然运行起来不会报错,但是仔细去看文本拆分出来的词组你会发现你这个配置根本没有起到作用。这时候我们就需要手动的去刷新Dictionary对象的words属性。
首先我们要拿到Dictionary对象(单例的)
private static Dictionary singleton;
if (singleton == null) {
singleton = Dictionary.initial(mycfg);
}
其次我们动过这个singleton 对象来设置words()
//dictList:通过我们指定的词典文件获取到的词组list
dictList = getWordList(dict);
singleton.addWords(dictList);
其实做到这一步就已经可以用于我们指定的词典分词了,但是我们似乎忘记了一件事情:清空不需要的词组,如:我们第一次使用了A词典分词。第二次要用B词典进行分词。这时候如果你不想用A里面的分词时我们就需要把A词典从singleton 对象中移除去。
//在使用新词典时,清除其他词典(刷新)
if(dictList.size()>0){
singleton.disableWords(dictList);
}
这样才是正在的OK了
3、开始分词
String content = "曾做过周朝“守藏室之官”(管理藏书的官员),是中国古代伟大的思想家、哲学家、文学家和史学家,"
+ "被道教尊为教祖,世界文化名人。老子思想主张“无为”,《老子》以“道”解释宇宙万物的演变,"
+ "“道”为客观自然规律,同时又具有“独立不改,周行而不殆”的永恒意义。《老子》书中包括大量"
+ "朴素辩证法观点,如以为一切事物均具有正反两面,并能由对立而转化,是为“反者道之动”,“正复为奇,"
+ "善复为妖”,“祸兮福之所倚,福兮祸之所伏”。又以为世间事物均为“有”与“无”之统一,“有、无相生”,"
+ "而“无”为基础,“天下万物生于有,有生于无”。他关于民众的格言有:“天之道,损有余而补不足,人之道"
+ "则不然,损不足以奉有余”;“民之饥,以其上食税之多”;“民之轻死,以其上求生之厚”;“民不畏死,奈何以"
+ "死惧之”。他的哲学思想和由他创立的道家学派,不但对中国古代思想文化的发展作出了重要贡献,而且对"
+ "中国2000多年来思想文化的发展产生了深远的影响。关于他的身份,还有人认为他是老莱子,也是楚国人,"
+ "跟孔子同时,曾著书十五篇宣传道家之用。";
StringReader input = new StringReader(content.trim()); IKSegmenter ikSeg = new IKSegmenter(input,mycfg);
Lexeme lexeme=null;
while((lexeme=ikSeg.next())!=null){
String keys = lexeme.getLexemeText();
if(keys.length()>1){
System.out.println(keys);
}
}
input.close();
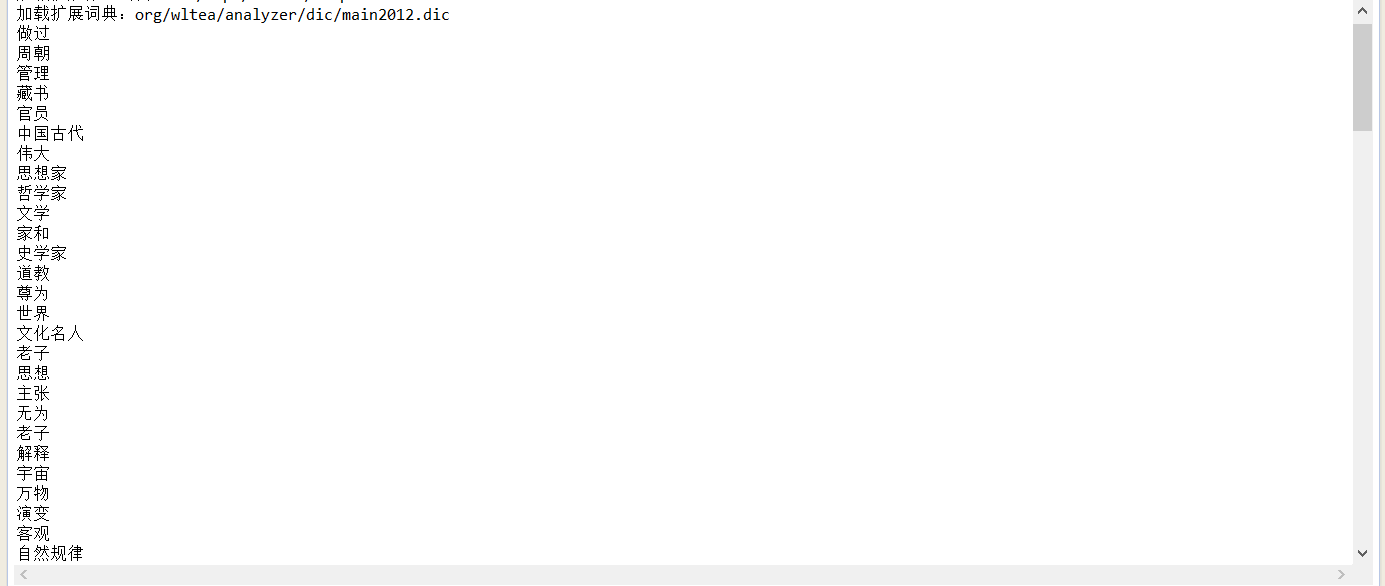
五、分词结果:
1、使用jar包自带的词典:org/wltea/analyzer/dic/main2012.dic
2、使用dict1词典:

3、使用dict2词典:

4、使用dict3词典:

六、总结解释:从结果可以看出,同样的一段文本,使用不同的词典,获取到的词组是不一样的并且获得的词组不会混杂
至于“2000” 、“十五篇” 这种带数字和字母的词组分词器会默认拆分出来的。至于为啥?你问我?我也不知道。因为我们搞的是中文分词器,程序给你把数字,单词也拆出来也是正常的
七、demo完整代码:
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.StringReader;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Properties; import javax.imageio.stream.FileImageInputStream; import org.apache.commons.lang.StringUtils;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.util.ResourceLoader;
import org.wltea.analyzer.cfg.Configuration;
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;
import org.wltea.analyzer.dic.Dictionary;
import org.wltea.analyzer.lucene.IKAnalyzer;
import org.wltea.analyzer.util.IKTokenizerFactory; public class TestIK {
private static Dictionary singleton;
private static ResourceLoader loader;
static List<String> dictList = new ArrayList<String>(); public static void main(String[] args) throws IOException {
for (int i = 0; i < 4; i++) {
test(i);
} } public static void test(int num) throws IOException{
String content = "曾做过周朝“守藏室之官”(管理藏书的官员),是中国古代伟大的思想家、哲学家、文学家和史学家,"
+ "被道教尊为教祖,世界文化名人。老子思想主张“无为”,《老子》以“道”解释宇宙万物的演变,"
+ "“道”为客观自然规律,同时又具有“独立不改,周行而不殆”的永恒意义。《老子》书中包括大量"
+ "朴素辩证法观点,如以为一切事物均具有正反两面,并能由对立而转化,是为“反者道之动”,“正复为奇,"
+ "善复为妖”,“祸兮福之所倚,福兮祸之所伏”。又以为世间事物均为“有”与“无”之统一,“有、无相生”,"
+ "而“无”为基础,“天下万物生于有,有生于无”。他关于民众的格言有:“天之道,损有余而补不足,人之道"
+ "则不然,损不足以奉有余”;“民之饥,以其上食税之多”;“民之轻死,以其上求生之厚”;“民不畏死,奈何以"
+ "死惧之”。他的哲学思想和由他创立的道家学派,不但对中国古代思想文化的发展作出了重要贡献,而且对"
+ "中国2000多年来思想文化的发展产生了深远的影响。关于他的身份,还有人认为他是老莱子,也是楚国人,"
+ "跟孔子同时,曾著书十五篇宣传道家之用。";
StringReader input = new StringReader(content.trim());
MyConfiguration mycfg = new MyConfiguration();
mycfg.setUseSmart(true); //true 用智能分词 ,false细粒度 if (singleton == null) {
singleton = Dictionary.initial(mycfg);
} String dict = null;
if(num==0){
dict = "org/wltea/analyzer/dic/main2012.dic";//分词jar包自带的词典
System.out.println("加载扩展词典:"+dict);
mycfg.setMainDictionary(dict);//动态设置自定义的词库 //在使用新词典时,清除其他词典(刷新)
if(dictList.size()>0){
singleton.disableWords(dictList);
} //dictList:通过我们指定的词典文件获取到的词组list
dictList = getWordList(dict);
singleton.addWords(dictList);
}else if(num==1){
dict = "com/unruly/test/dict1.dic";
System.out.println("加载扩展词典:"+dict);
mycfg.setMainDictionary(dict);//动态设置自定义的词库 //在使用新词典时,清除其他词典(刷新)
if(dictList.size()>0){
singleton.disableWords(dictList);
} dictList = getWordList(dict);
singleton.addWords(dictList);
}else if(num==2){
dict = "com/unruly/test/dict2.dic";
System.out.println("加载扩展词典:"+dict);
mycfg.setMainDictionary(dict);//动态设置自定义的词库 //在使用新词典时,清除其他词典(刷新)
if(dictList.size()>0){
singleton.disableWords(dictList);
} dictList = getWordList(dict);
singleton.addWords(dictList);
}else if(num==3){
dict = "com/unruly/test/dict3.dic";
System.out.println("加载扩展词典:"+dict);
mycfg.setMainDictionary(dict);//动态设置自定义的词库 //在使用新词典时,清除其他词典(刷新)
if(dictList.size()>0){
singleton.disableWords(dictList);
} dictList = getWordList(dict);
singleton.addWords(dictList);
} IKSegmenter ikSeg = new IKSegmenter(input,mycfg); Lexeme lexeme=null;
while((lexeme=ikSeg.next())!=null){
String keys = lexeme.getLexemeText(); if(keys.length()>1){
System.out.println(keys);
}
}
input.close();
} /**
* 读取字典
* @param dict
* @return
*/
public static List<String> getWordList(String dict) {
List<String> list = new ArrayList<>();
InputStream is = null;
try {
is = TestIK.class.getClass().getResourceAsStream("/"+dict);
BufferedReader br = new BufferedReader(new InputStreamReader(is,"UTF-8"), 1024);
String theWord = null;
do {
theWord = br.readLine();
if (theWord != null && !"".equals(theWord.trim())) {
list.add(theWord);
}
} while (theWord != null);
} catch (IOException ioe) {
System.err.println("字典文件读取失败:"+dict);
ioe.printStackTrace();
} finally {
try {
if (is != null) {
is.close();
is = null;
}
} catch (IOException e) {
e.printStackTrace();
}
} return list;
} }
IK-Analyzer(5.3.1)动态配置自定义词典的更多相关文章
- 在使用Hanlp配置自定义词典时遇到的问题
要使用hanlp加载自定义词典可以通过修改配置文件hanlp.properties来实现.要注意的点是: 1. root根路径的配置: hanlp.properties中配置如下: #本配置文件中的路 ...
- Hanlp配置自定义词典遇到的问题与解决方法
本文是整理了部分网友在配置hanlp自定义词典时遇到的一小部分问题,同时针对这些问题,也提供另一些解决的方案以及思路.这里分享给大家学习参考. 要使用hanlp加载自定义词典可以通过修改配置文件han ...
- Solr学习(2) Solr4.2.0+IK Analyzer 2012
Solr学习(二) Solr4.2.0+IK Analyzer 2012 开场白: 本章简单讲述如何在solr中配置著名的 IK Analyzer 分词器. 本章建立在 Solr学习(一) 基础上进 ...
- solr添加中文IK分词器,以及配置自定义词库
Solr是一个基于Lucene的Java搜索引擎服务器.Solr 提供了层面搜索.命中醒目显示并且支持多种输出格式(包括 XML/XSLT 和 JSON 格式).它易于安装和配置,而且附带了一个基于H ...
- ElasticSearch7.3学习(十五)----中文分词器(IK Analyzer)及自定义词库
1. 中文分词器 1.1 默认分词器 先来看看ElasticSearch中默认的standard 分词器,对英文比较友好,但是对于中文来说就是按照字符拆分,不是那么友好. GET /_analyze ...
- 转:solr6.0配置中文分词器IK Analyzer
solr6.0中进行中文分词器IK Analyzer的配置和solr低版本中最大不同点在于IK Analyzer中jar包的引用.一般的IK分词jar包都是不能用的,因为IK分词中传统的jar不支持s ...
- 我与solr(六)--solr6.0配置中文分词器IK Analyzer
转自:http://blog.csdn.net/linzhiqiang0316/article/details/51554217,表示感谢. 由于前面没有设置分词器,以至于查询的结果出入比较大,并且无 ...
- 阿里云容器服务--配置自定义路由服务应对DDOS攻击
阿里云容器服务--配置自定义路由服务应对DDOS攻击 摘要: 容器服务中,除了slb之外,自定义路由服务(基于HAProxy)也可以作为DDOS攻击的一道防线,本文阐述了几种方法来应对普通规模的DDO ...
- Lucene全文搜索之分词器:使用IK Analyzer中文分词器(修改IK Analyzer源码使其支持lucene5.5.x)
注意:基于lucene5.5.x版本 一.简单介绍下IK Analyzer IK Analyzer是linliangyi2007的作品,再此表示感谢,他的博客地址:http://linliangyi2 ...
随机推荐
- 使用vue-cli脚手架搭建简单项目框架
1.首先已经安装了node,最好版本6以上. 2.安装淘宝镜像 大家都知道国内直接使用 npm 的官方镜像是非常慢的,这里推荐使用淘宝 NPM 镜像.这样就可以直接使用cnpm了. npm insta ...
- 从零自学Hadoop(25):Impala相关操作下
阅读目录 序 导入数据 查询 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 序 上一 ...
- LeetCode 259. 3Sum Smaller (三数之和较小值) $
Given an array of n integers nums and a target, find the number of index triplets i, j, k with 0 < ...
- C# 使用OpenCV在一张图片里寻找人脸
先上个效果图 相关库的下载 例程中用到一个库叫做emgucv,是opencv\的net封装 编译打包好的稳定版,在这:https://sourceforge.net/projects/emgucv/f ...
- 电脑键盘上的F键有什么用 电脑F键功能讲解
接触电脑这么多年了,F1到F12这几个键你真的会用吗?电脑键盘上的F键有什么用?你了解过吗?这里带来电脑F键功能讲解,一起来看看. F1:帮助 在程序里或者资源管理器界面,按F1会弹出帮助按钮. F2 ...
- Python Web框架篇:Django Model ORM(对象关系映射)
一,基本操作 用于实现面向对象编程语言里不同类型系统的数据之间的转换,换言之,就是用面向对象的方式去操作数据库的创建表以及增删改查等操作. 1.增(create , save): from app01 ...
- Linux必知必会的目录与启动过程
第1章 /etc/目录 1.1 /etc/sysconfig/network-scripts/ifcfg-eth0 linux第一块网卡的配置文件 [root@znix ~]# cat /etc/sy ...
- Hadoop,master和slave简单的分布式搭建
搭建过程中配置免密钥登录为了以后方便使用 [提醒]安装Hadoop中会遇到新建文件夹,配置路径等问题,这个不能生搬硬套,要使用自己配置的路径,灵活使用. Hadoop的部署配置文件在http://bl ...
- IIC接口下的24C02 驱动分析
本节来学习IIC接口下的24C02 驱动分析,本节学完后,再来学习Linux下如何使用IIC操作24C02 1.I2C通信介绍 它是由数据线SDA和时钟SCL构成的串行总线,可发送和接收数据,是一个多 ...
- 【翻译】.Net Core的意义
想要了解.Net Core的意义,就必须要了解拥有很长历史的.Net Framework,.Net Framework1.0于2002年发布.从那开始,每隔两年就会有一个主版本推出.伴随着Visual ...