自动微分方法(auto diff)
学习机器学习的同学在学习过程中会经常遇到一个问题,那就是对目标函数进行求微分,线性回归这类简单的就不说、复杂的如神经网络类那些求导过程的酸爽。像我还是那种比较粗心的人往往有十导九错,所以说自动求导就十分有必要了,本文主要介绍几种求导的方式。假设我们的函数为\(f(x,y)=x^2y+y+2\),目标是求出偏导\(\frac{\partial{f}}{\partial{x}}\)和\(\frac{\partial{f}}{\partial{y}}\)。求导的方式主要分为以下几种
手动求导法(Manual Differentiation)###
首先准备一张纸和一支笔,根据上学时候学到的求导法则,开始计算。最终得到的结果
\(\frac{\partial{f}}{\partial{x}}=2xy\)
\(\frac{\partial{f}}{\partial{y}}=x^2+1\)
上面这个小例子比较简单,口算即可得到答案,但如果方程比较复杂那就难说了。幸好有自动求导的方法,例如符号求导方法。
符号求解法(Symbolic Differentiation)###
符号求导是根据一些求导法则,进行求导。例如我们大学高数学习的\((uv)\prime=u'v+v'u\),\((u+v)'=u'+v'\),\((\frac{u}{v})'=\frac{u'v-v'u}{v^2}\)等等,下图是\(g(x,y)=5+xy\)的符号求导工作流程。
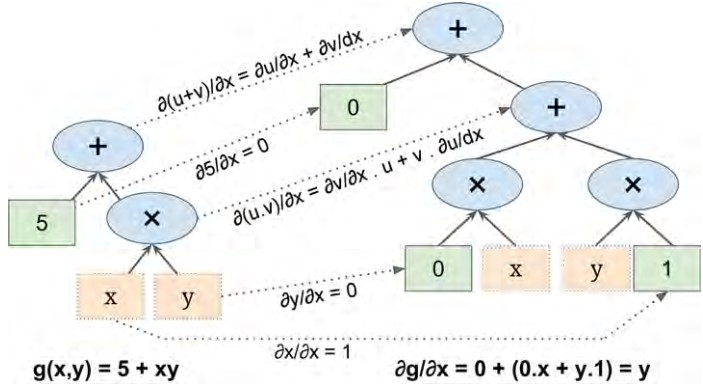
原公式在图的左边,求导公式在图的右半部分,求导的过程是先求叶子节点,自下向上。最终对节点进行见之得到求导结果\(\frac{\partial{g}}{\partial{x}}=y\),这个例子固然简单,但是对于一个更复杂的公式,那么求导符号图将会十分的庞大(表达式膨胀),另外对于一些变化的公式(硬代码)这种方法就无能为力了:
def fun(a,b):
z=0
for i in range(100):
z = a * np.cos(z + i) + z * np.sin(b - i)
return z
数值求导法(Numerical Differentiation)###
导数的定义是当自变量的增量趋于零时,因变量的增量与自变量的增量之商的极限。
其中\(\varepsilon\)是一个无穷小的数,所以我们可以计算在x=3,y=4这一点对x的偏导数,\(f'(x=3,y)=\frac{f(3+\varepsilon,4)-f(3,4)}{\varepsilon}\),对应的代码如下:
def f(x, y):
return x**2*y + y + 2
def derivative(f, x, y, x_eps, y_eps):
return (f(x + x_eps, y + y_eps) - f(x, y)) / (x_eps + y_eps)
df_dx = derivative(f, 3, 4, 0.00001, 0)
df_dy = derivative(f, 3, 4, 0, 0.00001)
>>print(df_dx)
24.000039999805264
>>print(df_dy)
10.000000000331966
通过上面的结果我们发现,得出的结果不是十分的精确,并且在对x和y求偏导的整个过程中,至少需要计算3次\(f()\),也就是说如果有1000个参数,那么至少需要计算1001次\(f()\),在神经网络中,参数巨多,这样计算效率会比较差。不过这种方法常被用到进行检验得到的求导结果是否正确。
前向自动求导法(Forward-Mode Autodiff)###
前向求导是依赖于数值求导和符号求导的一种求解方法,给定公式\(a+{\varepsilon}b\),这种被称作dual number,其中a和b是实数,\(\varepsilon\)是一个无穷小的数,并且\({\varepsilon}^2=0\),举个栗子,\(42 + 24\varepsilon\),我们可以把它看成42.00000000...24的数值.我们可以通过这种方法(42.0,24.0)来表示,dual number满足以下的运算法则:
- 1.\(\lambda(a+b\varepsilon) = a\varepsilon + b{\lambda}\varepsilon\)
- 2.\((a+b\varepsilon)+(c+d\varepsilon) = (a+c)+(b+d)\varepsilon\)
- 3.\((a+b\varepsilon)\times(c+d\varepsilon) = ac+(ad+bc)\varepsilon+(bd){\varepsilon}^2=ac+(ad+bc)\varepsilon\)
还有一点就是\(h(a+b\varepsilon)=h(a)+b{\times}h'(a)\varepsilon\)。
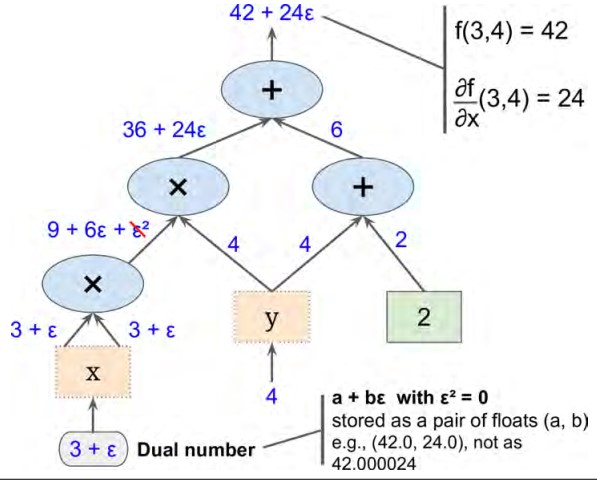
上图给出了使用前向求导方法计算出\(f(x,y)\)在x=3,y=4这一点\(\frac{\partial{f}}{\partial{x}}(3,4)\)的偏导,同理求出\(\frac{\partial{f}}{\partial{y}}(3,4)\),图中的思路很清晰就不赘述。前向求导方法相对数值求导来说准确率较高,当和数值求导方法一样如果参数过多的时候效率会比较差,因为这种方法需要遍历整个图。
逆向自动求导法(Reverse-Mode Atuodiff)###
TensorFlow采用的是逆向自动求导方法,该方法首先正向遍历整个图,计算出每个节点的值;然后逆向(从上到下)遍历整个图,计算出节点的偏导值,步骤如下图所示;节点内蓝色的数值表示正向计算出的结果,为了方便表达,我们从下到上,从左到右依次标注为\(n_1\)到\(n_7\),可以看到最后的值\(n_7\)(顶部节点)为42。
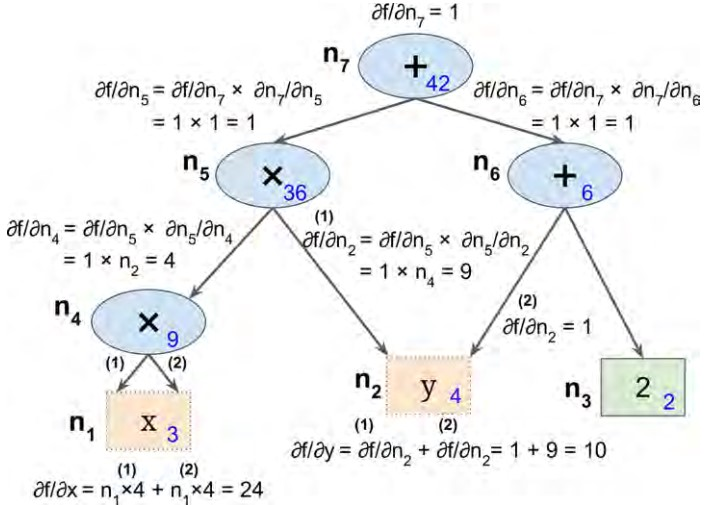
在逆向求导过程中使用链式求导方法:
\(\frac{\partial{f}}{\partial{x}}=\frac{\partial{f}}{\partial{n_i}}{\times}\frac{\partial{n_i}}{\partial{x}}\)
先看节点\(n_7\),作为输出节点\(f=n_7\),所以导数值为\(\frac{\partial{f}}{\partial{n_7}}=1\),
接着向下计算\(n_5\),\(\frac{\partial{f}}{\partial{n_5}}=\frac{\partial{f}}{\partial{n_7}}{\times}\frac{\partial{n_7}}{\partial{n_5}}\),上一步计算出\(\frac{\partial{f}}{\partial{n_7}}=1\),现在我们只需要计算\(\frac{\partial{n_7}}{\partial{n_5}}\),从图中我们知道\(n_7=n_5+n_6\),可以得出\(\frac{\partial{f}}{\partial{x}}=1\)。所以\(\frac{\partial{f}}{\partial{n_5}}=1\),接下来的步骤可以看上面的图,这里就不赘述了。
逆向自动求导法这种方法十分强大且准确率较高,尤其是有却多的输入。这种发方法仅需要正向和逆向遍历一次即可,这种方法更强大的地方在于能够解决符号求解法中硬代码的问题。
自动微分方法(auto diff)的更多相关文章
- MindSpore:自动微分
MindSpore:自动微分 作为一款「全场景 AI 框架」,MindSpore 是人工智能解决方案的重要组成部分,与 TensorFlow.PyTorch.PaddlePaddle 等流行深度学习框 ...
- 附录D——自动微分(Autodiff)
本文介绍了五种微分方式,最后两种才是自动微分. 前两种方法求出了原函数对应的导函数,后三种方法只是求出了某一点的导数. 假设原函数是$f(x,y) = x^2y + y +2$,需要求其偏导数$\fr ...
- <转>如何用C++实现自动微分
作者:李瞬生转摘链接:https://www.zhihu.com/question/48356514/answer/123290631来源:知乎著作权归作者所有. 实现 AD 有两种方式,函数重载与代 ...
- (转)自动微分(Automatic Differentiation)简介——tensorflow核心原理
现代深度学习系统中(比如MXNet, TensorFlow等)都用到了一种技术——自动微分.在此之前,机器学习社区中很少发挥这个利器,一般都是用Backpropagation进行梯度求解,然后进行SG ...
- 【tensorflow2.0】自动微分机制
神经网络通常依赖反向传播求梯度来更新网络参数,求梯度过程通常是一件非常复杂而容易出错的事情. 而深度学习框架可以帮助我们自动地完成这种求梯度运算. Tensorflow一般使用梯度磁带tf.Gradi ...
- acm对拍程序 以及sublime text3的文件自动更新插件auto refresh
acm等算法比赛常用---对拍 以及sublime text3的文件自动更新插件auto refresh 对拍 对拍即程序自动对比正确程序的运行结果和错误程序的运行结果之间的差异 废话少说, 直接上操 ...
- 分子动力学模拟之基于自动微分的LINCS约束
技术背景 在分子动力学模拟的过程中,考虑到运动过程实际上是遵守牛顿第二定律的.而牛顿第二定律告诉我们,粒子的动力学过程仅跟受到的力场有关系,但是在模拟的过程中,有一些参量我们是不希望他们被更新或者改变 ...
- MindSpore多元自动微分
技术背景 当前主流的深度学习框架,除了能够便捷高效的搭建机器学习的模型之外,其自动并行和自动微分等功能还为其他领域的科学计算带来了模式的变革.本文我们将探索如何用MindSpore去实现一个多维的自动 ...
- LibTorch 自动微分
得益于反向传播算法,神经网络计算导数时非常方便,下面代码中演示如何使用LibTorch进行自动微分求导. 进行自动微分运算需要调用函数 torch::autograd::grad( outputs, ...
随机推荐
- js-自定义事件
1.自定义事件 开发人员自己定义的事件,是除了系统以外的事件. 可以供其他开发人员使用,有利于多人写作开发,可扩展js的原有事件. 需要:事件绑定器.事件触发器 2.自定义事件三要素 ①:对象.事件名 ...
- yii2布局选择与属性标签设置
Yii选择布局的方法: 1. 通过控制器成员变量设置: public $layout = false;//不使用布局 public $layout = 'main';//设置使用的布局文件(@app/ ...
- 使用PHPExcel-1.8实现导入
//使用PHPExcel-1.8实现导入(下载PHPExcel-1.8):导入excel 后缀名必须是.xls1.<form method="post" action=&qu ...
- 获取标签的src属性兼容性
获取节点如script标签的src属性时,针对非IE6,IE7可以直接使用src属性,但在IE6-7中存在问题,可以借助getAttribute方法 getAttribute(attr,iflag) ...
- 粗略整理的java面试题
1.垃圾回收 是回收的空闲堆空间 只有在cpu空闲并且堆空间不足的情况下才回收 2.threadlocal 就是为线程的变量都提供了一个副本,每个线程运行都只是在更新这个副本. Threadloc ...
- oracle数据库冷备中的手工备份和恢复
我的操作系统是red hat5.5 32位系统oracle11g 以我的系统为例: 冷备状态下,数据库必须是关闭的,但是我们现在要做一个实验,在开库的状态下分别查询出: 1.show paramete ...
- Python实现翻译功能
初入Python,一开始就被她简介的语法所吸引,代码简洁优雅,之前在C#里面打开文件写入文件等操作相比Python复杂多了,而Python打开.修改和保存文件显得简单得多. 1.打开文件的例子: fi ...
- 一:Spring Boot、Spring Cloud
上次写了一篇文章叫Spring Cloud在国内中小型公司能用起来吗?介绍了Spring Cloud是否能在中小公司使用起来,这篇文章是它的姊妹篇.其实我们在这条路上已经走了一年多,从16年初到现在. ...
- DateTime格式
SELECT * FROM TABLE (TO_DATE('2007/9/1','yyyy/mm/dd') BETWEEN CGGC_STRATDATE AND CGGC_ENDDATE OR CGG ...
- Unity学习资料
前段时间刚简单接触下Spring.net,刚会简单注入,最近接手一项目确是用的Unity,网上找了一些很好的教程资料 算是入门了,高手已经写的很好了,我就转个链接吧: Unity V3 初步使用 —— ...