linux系统下深度学习环境搭建和使用
作为一个AI工程师,对Linux的一些技能的掌握也能从一定层面反应工程师的资深水平。
要求1:基于SSH的远程访问(本篇文章)
- 能用一台笔记本电脑,远程登陆一台linux服务器
- 能随时使用笔记本电脑启动训练任务
- 能熟练的让代码和文件在笔记本电脑与LINUX服务器之间的传输
要求2:Linux系统的文件系统(Linux指令学习)
- 知道什么是硬盘的挂载
- 能合理的使用服务器的硬盘空间
- 不要求,但建议学会如何在LINUX系统上自建逻辑卷(LVM)
要求3:LINUX系统的账户管理
- 知道root账户与普通账户的区别
- 能够对账户权限有基本的规划
- 能在普通账户下,完成基于Tensorflow的AI开发
要求4:LINUX系统的驱动安装(本篇文章)
- 能够独立的在Ubuntu Linux 上搭建NVIDIA GPU的深度学习环境
要求5:GIT和Github(Git从入门到精通)
- 有代码的版本控制意识
- 能够掌握基本的Git使用方法
- 能够掌握基本的Github使用方法
上面的知识点我都写过博客,写完这篇文章我就能集齐龙珠,召唤神龙了。
SSH远程连接服务器
例子:
- IP地址:111.44.254.168
- 端口号:21665
- 登录名:root
- 密码:123456
linux \ MAC连接
如果本地电脑是inux或者mac系统,则远程服务器SSH登陆信息是: ssh -p 21665 root@111.44.254.168
window系统连接
如果本地电脑是 window系统用cmd登陆(需要先安装 OpenSSL),则远程服务器SSH登陆信息是: ssh -p 21665 root@111.44.254.16
Xshell软件连接
我们需要用到的软件是:Xshell (命令行控制服务器) 和 Xffp(传输文件)


进入官网:https://www.netsarang.com/zh/,滑到最下面点击 家庭/学校免费,输入姓名和邮箱,勾选两者,点击下载。随后邮箱会收到两个邮件,点击邮件中的链接就可以下载安装包。
putty,pscp、Filezila等软件也比较主流,但可能不太稳定,这里不做介绍
搭建深度学习环境
我们首先确定自己想要安装的版本,CUDA与显卡驱动对应的版本关系,TensorFlow-GPU与CUDA cudnn Python版本关系
我想安装的版本是:
- python 3.6.5(ananonda3-5.2.0)
- NVIDIA GPU 驱动程序:
- CUDA
- cuDNN
安装python
python环境我们选择的是Anaconda,我选择的安装版本是 Anaconda3-5.2.0-Linux-x86_64.sh ,对应的python版本是python 3.6.5,建议到清华镜像源下载,更快!
打开Xftp,连接服务器,在服务器创建一个DL_package文件夹,将 Anaconda3-5.2.0-Linux-x86_64.sh 上传到文件夹里(不放也行,我是想要统一管理,因为后面还要安装cuda和NVIDIA驱动)
安装过程不要瞎点,看清楚底部的英文再确定 yes or no。
1、找到Anaconda3-2019.07-Linux-x86_64.sh安装包,用 sh 命令执行 .sh 文件,开始安装
2、按回车观看更多许可信息,按 Q 键跳过
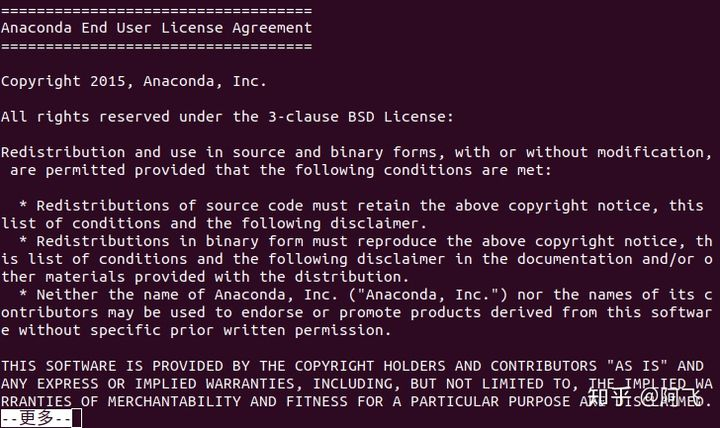
3、是否接受许可条款, 输入yes回车
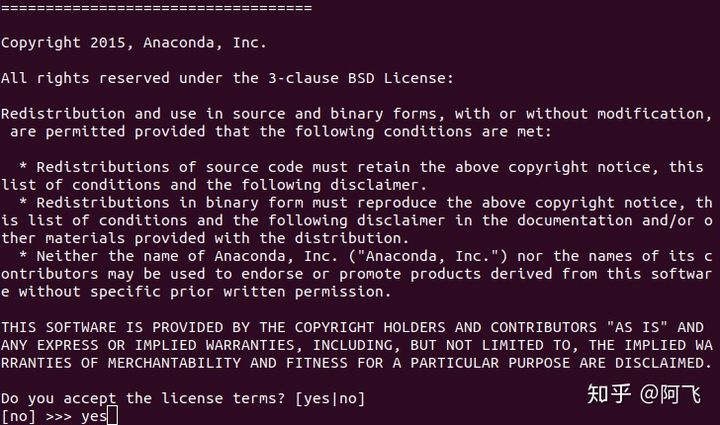
4、最后他会提示是否安装 VS Code,我选了no,界面都没有用个毛线VS Code!
5、这时关闭当前终端,再打开一个新的终端会默认打开在conda环境下
6、输入 conda -V 可以查看安装的Anaconda版本

7、输入 conda list 可以查看已安装的科学包
8、在终端输入 python 可以看当前的python版本,并进入python编程环境

anaconda会自动将环境变量添加到PATH里面,如果后面你发现输出 conda ,提示没有该命令,那么需要添加环境变量
打开~/.basrc 文件c (例如: vim ~/.bashrc ),在最后面加上
export PATH=/home/aeasringnar/anaconda3/bin:$PATH
更新环境变量: source ~/.bashrc
再次输入 conda list 测试看看,应该就是没有问题啦!
如果你想删除Anaconda,切换到你安装anaconda的目录,直接 rm -rf anaconda3,然后在去/etc/profile,把配置的删除就OK了
安装NVIDA显卡驱动
禁用nouveau驱动
禁用nouveau驱动
sudo vim /etc/modprobe.d/blacklist.conf
在文本最后添加:
blacklist nouveau
options nouveau modeset=0
然后执行:
sudo update-initramfs -u
重启后,执行以下命令,如果没有屏幕输出,说明禁用nouveau成功:
lsmod | grep nouveau
下载驱动
nividia 显卡驱动下载地址:NVIDIA 驱动程序下载,根据自己的显卡型号选择驱动程序

卸载旧驱动
以下操作都需要在命令界面操作,执行以下快捷键进入命令界面,并登录:
Ctrl-Alt+F1
执行以下命令禁用X-Window服务,否则无法安装显卡驱动:
sudo service lightdm stop
执行以下三条命令卸载原有显卡驱动:
sudo apt-get remove --purge nvidia*
sudo chmod +x NVIDIA-Linux-x86_64-410.93.run
sudo ./NVIDIA-Linux-x86_64-410.93.run --uninstall
安装新驱动
下载驱动,官网下载地址,根据自己显卡的情况下载对应版本的显卡驱动,直接执行驱动文件即可安装新驱动,一直默认即可:
sudo ./NVIDIA-Linux-x86_64-410.93.run
执行以下命令启动X-Window服务
sudo service lightdm start
最后执行重启命令,重启系统即可:
reboot
注意: 如果系统重启之后出现重复登录的情况,多数情况下都是安装了错误版本的显卡驱动。需要下载对应本身机器安装的显卡版本。
安装CUDA
由于 Pytorch 和 TensorFlow 对于 CUDA 都有特定的版本需求,所以在安装 CUDA 之前,我们首先需要查询,我们想要安装的 pytorch 版本对应的 CUDA 版本。
pytorch 的配套环境要求见:https://pytorch.org/
在 https://developer.nvidia.com/cuda-toolkit-archive 中选择你要安装的CUDA版本
sudo sh cuda_11.2.2_460.32.03_linux.run
开始安装。终端会在后台运行一段时间,看起来像是卡住了,并不是没有反应,请耐心等待。
然后选择:accept

这里将光标移到[X]Driver处,按enter键,取消勾选安装驱动。
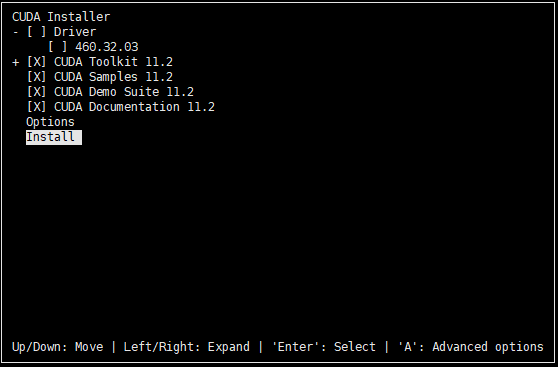


===========
= Summary =
=========== Driver: Not Selected
Toolkit: Installed in /usr/local/cuda-11.2/
Samples: Installed in /home/user/ Please make sure that
- PATH includes /usr/local/cuda-11.2/bin
- LD_LIBRARY_PATH includes /usr/local/cuda-11.2/lib64, or, add /usr/local/cuda-11.2/lib64 to /etc/ld.so.conf and run ldconfig as root To uninstall the CUDA Toolkit, run cuda-uninstaller in /usr/local/cuda-11.2/bin
***WARNING: Incomplete installation! This installation did not install the CUDA Driver. A driver of version at least 460.00 is required for CUDA 11.2 functionality to work.
To install the driver using this installer, run the following command, replacing <CudaInstaller> with the name of this run file:
sudo <CudaInstaller>.run --silent --driver Logfile is /var/log/cuda-installer.log
安装完成之后,可以配置他们的环境变量,在 vim ~/.bashrc 的最后加上以下配置信息:
export CUDA_HOME=/usr/local/cuda-11.2
export LD_LIBRARY_PATH=${CUDA_HOME}/lib64
export PATH=${CUDA_HOME}/bin:${PATH}
最后使用命令 source ~/.bashrc 使它生效。
可以使用命令 nvcc -V 查看安装的版本信息:
$ nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2021 NVIDIA Corporation
Built on Sun_Feb_14_21:12:58_PST_2021
Cuda compilation tools, release 11.2, V11.2.152
Build cuda_11.2.r11.2/compiler.29618528_0
出现上图所示界面说明已经安装完成
测试安装是否成功,执行以下几条命令:
cd /usr/local/cuda-11.2/samples/1_Utilities/deviceQuery
make -j32
./deviceQuery
卸载cuda
cd /usr/local/cuda-11.2/bin/
sudo ./cuda-uninstaller
sudo rm -rf /usr/local/cuda-11.2
安装CUDNN
进入到CUDNN的下载官网,然点击Download开始选择下载版本,当然在下载之前还有登录,选择版本界面如下
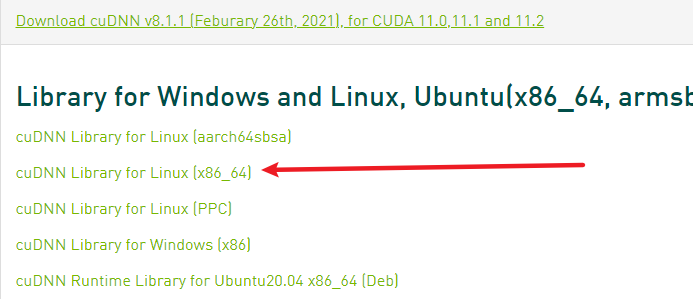
下载之后是一个压缩包:cudnn-11.2-linux-x64-v8.1.1.33.tar,然后对它进行解压,命令如下:
tar -zxvf cudnn-11.2-linux-x64-v8.1.1.33.tar
解压之后可以得到以下文件:
cuda/include/cudnn.h
cuda/NVIDIA_SLA_cuDNN_Support.txt
cuda/lib64/libcudnn.so
cuda/lib64/libcudnn.so.7
cuda/lib64/libcudnn.so.7.4.2
cuda/lib64/libcudnn_static.a
使用以下两条命令复制这些文件到CUDA目录下:
cp cuda/lib64/* /usr/local/cuda-11.2/lib64/
cp cuda/include/* /usr/local/cuda-11.2/include/
拷贝完成之后,可以使用以下命令查看CUDNN的版本信息:
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
查看 Nvidia 显卡利用率:显存占用和算力情况。
# 0.5 秒更新一次显卡利用情况,并查看 NVIDIA 驱动版本
watch -n 0.5 nvidia-smi
安装TensorFlow
TensorFlow经历过一次变革,从 Tensorflow 1.* 变革到了现在的 Tensorflow 2.*,从静态变成了动态。
如果想要安装tensorflow 1.*,需要:
# 支持CPU的版本,版本可更改
pip install tensorflow==1.15
# 支持GPU的版本,版本可更改
pip install tensorflow-gpu==1.15
如果想要安装tensorflow 2.*,只需要:
pip install tensorflow
- 若要支持 Python 3.9,需要使用 TensorFlow 2.5 或更高版本。
- 若要支持 Python 3.8,需要使用 TensorFlow 2.2 或更高版本。
更详细情况,请移步Tensorflow官网。
Tensorflow 查看GPU是否可用,返回True则代表可用
import tensorflow as tf
tf.test.is_gpu_available()
安装pytorch
pytorch的安装没啥好说的,因为 任何人的介绍或转述 都不如官网写的明白,请直接移步 pytorch官网首页。
pytorch 查看GPU是否可用,返回True则代表可用,返回False则代表不可用。
import torch
torch.cuda.is_available()
搭建Jupyter Notebook远程云服务器
为什么要使用Jupyter Notebook
- 随时可在未安装Python的电脑上使用Python(可以分享给别人)
- 借助服务器的性能,在服务器上做分析,解放本地计算机的CPU
- 不同电脑间,使用服务器jupyter可避免数据不一致
- Jupyter Notebook能帮助我们有效地组织输入输出,将探索数据的过程记录下来,
- Jupyter Notebook支持Markdown,也支持Python、R甚至Julia等语言,完全可以支持一个数据工作者的大多数分析需求。
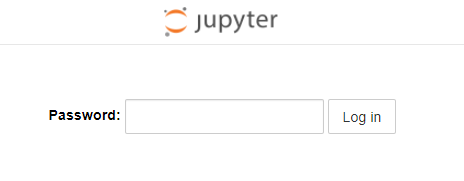
完工后的界面如下,输入密码就可以开始使用啦:
安装过程
1、安装 Jupyter Notebook 库
我安装的是 Ananconda ,这是 Python 的科学计算包,自带了 Jupyter,因此无需此步骤。若未安装,也可单独安装
$ pip install Jupyter
2、生成 Jupyter Notebook 配置文件
$ jupyter notebook --generate-config
生成的配置文件,后来用来设置服务器的配置
3、设置Jupyter Notebook密码
设置密码用于设置服务器配置,以及登录Jupyter。打开Python终端,输入以下:
$ python
>> from notebook.auth import passwd
>> passwd()
此时会让你两次输入密码,然后就会生成秘钥
sha1************
4、设置服务器配置文件
$ vim ~/.jupyter/jupyter_notebook_config.py
在末尾增加以下几行配置信息(此配置信息,也可在启动Jupyter时在参数中添加,但我认为那样看起来比较乱)
c.NotebookApp.ip = '*' # 所有绑定服务器的IP都能访问,若想只在特定ip访问,输入ip地址即可
c.NotebookApp.port = 8888 # 将端口设置为自己喜欢的吧,默认是8888
c.NotebookApp.open_browser = False # 我们并不想在服务器上直接打开Jupyter Notebook,所以设置成False
c.NotebookApp.notebook_dir = '/home/user/Desktop/jupyter_projects' # 这里是设置Jupyter的根目录,若不设置将默认root的根目录,不安全
c.NotebookApp.allow_root = True # 为了安全,Jupyter默认不允许以root权限启动jupyter
c.NotebookApp.password = 'sha1:7a80c9a4cec6:9fcda0d4be1fb9d2181c9912c931689c49f6179a' # 设置之前生成的sha1
不过我建议你通过Xftp把jupyter_notebook_config.py拉下来,在本地更改后再上传上去(要更改的地方取消注释)
5、启动Jupyter 远程服务器
$ jupyter notebook # 或者指定端口和IP地址
$ jupyter notebook --no-browser --port 6000 --ip=192.168.1.103
至此,Jupyter远程服务器以搭建完毕。在本地浏览器上,输入 ip地址:8888,将会打开远程Jupyter。接下来就可以像在本地一样使用服务器上的Jupyter啦~~
按下ctrl+C键,可以退出
Jupyter notebook 更换kernel
由于jupyter notebook访问的时候,默认使用了anaconda的base环境,这里就需要更换环境。
具体方式如下:
1、安装ipykernel:
# 新建虚拟环境
(base) [root]$ conda activate your_eniv
# 安装nb_conda_kernels
(your_eniv) [root]$ conda install nb_conda_kernels
Collecting package metadata (current_repodata.json): done
Solving environment: done
python -m ipykernel install --user --name 环境名称 --display-name "显示的名称"
3、打开notebook服务器:jupyter notebook,浏览器打开对应地址,就会有对应的环境提示了。
快速搭建JupyterLab服务
JupyterLab与Jupyter Notebook师出同源,可以凭个人爱好进行选择。因为我想把博客写全,所以再介绍一下JupyterLab服务搭建
jupyter lab的每一步都和jupyter一样,就是启动的时候,加了lab而已。
1、安装 Jupyter Notebook 库
pip install jupyterlab
2、生成 Jupyter Notebook 配置文件
$ jupyter lab --generate-config
生成的配置文件,后来用来设置服务器的配置
3、设置Jupyter Notebook密码
设置密码用于设置服务器配置,以及登录Jupyter。打开Python终端,输入以下:
$ python
>> from notebook.auth import passwd
>> passwd()
此时会让你两次输入密码,然后就会生成秘钥
sha1************
4、设置服务器配置文件
$ vim /home/ubuntu/.jupyter/jupyter_notebook_config.py
我们看到了一大串的配置选项,一入眼就有点懵了。不要慌,我们只需要修改其中的四行即可。我们使用vim的快捷键/来搜索以下几项,将他们之前的注释去掉,并按照如下配置修改。
# 将ip设置为*,意味允许任何IP访问
c.NotebookApp.ip = '*'
# 这里的密码就是上边我们生成的那一串
c.NotebookApp.password = u'sha1:1e39d24dcd6c:b265321ca0c4cb798888bcb69b0024983a8ac439'
# 服务器上并没有浏览器可以供Jupyter打开
c.NotebookApp.open_browser = False
# 监听端口设置为8888或其他自己喜欢的端口
c.NotebookApp.port = 8888
# 我们可以修改jupyter的工作目录,也可以保持原样不变,如果修改的话,要保证这一目录已存在
c.MappingKernelManager.root_dir = '/home/ubuntu/.jupyter_run/root'
# 允许远程访问
c.NotebookApp.allow_remote_access = True
好了,保存输入:wq退出vim。
不过我建议你通过Xftp把jupyter_notebook_config.py拉下来,在本地更改后再上传上去(要更改的地方取消注释)
5、启动Jupyter 远程服务器
$ jupyter lab --allow-root # 或者指定端口和IP地址
$ jupyter lab notebook --no-browser --port 6000 --ip=***.***.**.***
至此,Jupyter远程服务器以搭建完毕。在本地浏览器上,输入 ip地址:8888,输入密码,也就是我们自己设置并确认的密码。将会打开远程Jupyter lab。
按下ctrl+C键,可以退出
搭建虚拟环境
在Python中,虚拟环境(virtual enviroment)就是隔离的Python解释器环境。通过创建虚拟环境,我们可以拥有一个独立的Python解释器环境。这样做的好处是可以为每一个项目创建独立的Python解释器环境,因为不同的项目常常会依赖不同版本的库或Python版本。使用虚拟环境可以保持全局Python解释器环境的干净,避免包和版本的混乱,并且可以方便地区分和记录每个项目的依赖,以便在新环境下复现依赖环境。
我总结了多种创建虚拟环境的方法,我推荐conda方法,你们可以根据自己的爱好选择。
conda搭建虚拟环境(推荐)
1、新建虚拟环境
conda create --name <env_name> <package_names> # 创建一个名为 python_2 的环境,环境中python版本为2.7
# conda create --name python_2 python=2.7 # 创建一个名为 conda-test 的环境,环境中python版本为3.6,同时也安装了numpy和pandas。
# conda create -n conda-test python=3.6 numpy pandas
- –name 同样可以替换为-n。
- <env_name> 创建的环境名。建议以英文命名,且不加空格,名称两边不加尖括号“<>”
- <package_names> 即安装在环境中的包名。名称两边不加尖括号“<>”
查看创建的虚拟环境
conda env list
# 或:conda info --envs
# 或:conda info -e
2、激活虚拟环境
Linux: source activate your_env_name(虚拟环境名称)
Windows: activate your_env_name(虚拟环境名称)
查看安装了哪些库
conda list
3、退出虚拟环境
conda deactivate
若配置好环境后需要别的包,用conda或者pip下载皆可
# 在当前环境安装包
pip install 安装的包名
conda install 要安装的包名
# 指定环境安装包
conda install --name 环境名 要安装的包名
4、删除虚拟环境
conda remove -n your_env_name --all
复制环境
conda create --name new_env_name --clone copied_env_name
virtualenv搭建虚拟环境
首先,我们用pip安装virtualenv:
$ pip3 install virtualenv
然后,假定我们要开发一个新的项目,需要一套独立的Python运行环境,可以这么做:
1、创建目录
$ mkdir myproject
$ cd myproject/
2、创建一个虚拟环境,命名为venv
$ virtualenv venv
若想要指定Python3
$ virtualenv -p python3 newEnv
查看newEnv文件夹中的内容
$ cd newEnv
$ ls
bin include lib pip-selfcheck.json
3、激活虚拟环境
$ source venv/bin/activate
4、在虚拟环境中安装python第三方库
在venv环境下,用pip安装的包都被安装到venv这个环境下,系统Python环境不受任何影响。也就是说,venv环境是专门针对myproject这个应用创建的。
$ pip install ***
5、关闭虚拟环境
$ deactivate
依据当前环境中的依赖包生成requirements.txt文档
$ pip freeze > requirements.txt
依据requirements.txt文档重建环境
$ pip install -r < requirements.txt
Pipenv搭建虚拟环境
Pipenv是基于pip的Python包管理工具,它和pip的用法非常相似,可以看作pip的加强版,它的出现解决了旧的pip + virtualenv + requirements.txt的工作方式的弊端。具体来说,它是pip、Pipfile和Virtualenv(虚拟环境)的结合体,它让包安装、包依赖管理和虚拟环境管理更加方便,使用它可以实现高效的Python项目开发工作流。如果你还不熟悉这些工具,不用担心,我会在下面逐一进行介绍。
通过pip安装Pipenv:
$ pip install pipenv
1、创建虚拟环境
虚拟环境通常使用Virtualenv来创建,但是为了更方便地管理虚拟环境和依赖包,我们将会使用集成了Virtualenv的Pipenv。首先确保我们当前工作目录在示例程序项目的根目录,然后使用pipenv install命令为当前的项目创建虚拟环境:
$ pipenv install
初始化好虚拟环境后,会在项目目录下生成2个文件Pipfile和Pipfile.lock。为pipenv包的配置文件,代替原来的 requirement.txt。项目提交时,可将 Pipfile 文件和Pipfile.lock文件一并提交,待其他开发克隆下载,根据此Pipfile 运行命令pipenv install --dev生成自己的虚拟环境。
Pipfile.lock 文件是通过hash算法将包的名称和版本,及依赖关系生成哈希值,可以保证包的完整性。
2、进入虚拟环境
$ pipenv shell
3、退出虚拟环境
$ exit
4、在虚拟环境中创建python包
$ pipenv install <某个包的名称>
查看安装包及依赖关系
$ pipenv graph
5、生成 requirements.txt 文件
pipenv可以像virtualenv一样用命令生成requirements.txt 文件
$ pipenv lock -r --dev > requirements.txt
6、pipenv也可以通过requirements.txt安装python包
$ pipenv install -r requirements.txt
运行python代码
方法一:pipenv run python xxx.py
$ pipenv run python xxx.py
方法二:启动虚拟环境的shell环境
$ pipenv shell
$ python xxx.py
7、删除虚拟环境
$ pipenv --rm
常用命令一览
pipenv --where 列出本地工程路径
pipenv --venv 列出虚拟环境路径
pipenv --py 列出虚拟环境的Python可执行文件
pipenv install 创建虚拟环境
pipenv isntall [moduel] 安装包
pipenv install [moduel] --dev 安装包到开发环境
pipenv uninstall[module] 卸载包
pipenv uninstall --all 卸载所有包
pipenv graph 查看包依赖
pipenv lock 生成lockfile
pipenv run python [pyfile] 运行py文件
pipenv --rm 删除虚拟环境
使用GPU
查看GPU的运行情况,同时我们也可以看到驱动和CUDA的版本号
nvidia-smi
# 查看训练进程时的GPU情况一般需要持续监视该输出
# 即每隔0.5秒执行一次nvidia-smi;
# watch -n 0.5 nvidia-smi
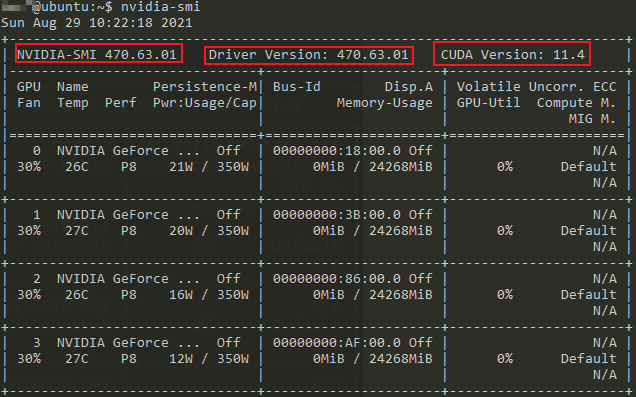
使用指定GPU
做好GPU的分配,比如我们有四张显卡,只想使用第1个和第4个,则只需要在程序的最开头使用如下命令:
1、直接终端中设定:
CUDA_VISIBLE_DEVICES=0,3 python my_script.py
2、python代码中设定
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0,3'
tensorflow使用多GPU
以后再来补全
pytorch使用多GPU
加速神经网络训练最简单的办法就是上GPU,如果一块GPU还是不够,就多上几块。
事实上,比如BERT和GPT-2这样的大型语言模型甚至是在上百块GPU上训练的。
为了实现多GPU训练,我们必须想一个办法在多个GPU上分发数据和模型,并且协调训练过程。
机多卡的办法还有很多(如下)
- nn.DataParallel简单方便的 nn.DataParallel
- torch.distributed 使用 torch.distributed 加速并行训练
- apex 使用 Apex 再加速
这里,记录了使用 4 块 Tesla V100-PICE 在 ImageNet 进行了运行时间的测试,测试结果发现 Apex 的加速效果最好,但与 Horovod/Distributed 差别不大,平时可以直接使用内置的 Distributed。Dataparallel 较慢,不推荐使用。

torch.nn.DataParallel
torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)
DataParallel 会自动帮我们将数据切分 load 到相应 GPU,将模型复制到相应 GPU,进行正向传播计算梯度并汇总
- module:要并行化的模型
- device_ids:参与训练的 GPU 有哪些,(默认:所有设备)
- output_device:用于汇总梯度的 GPU 是哪个,(默认:device_ids[0])
这里需要注意,模型和数据都需要先 load 进 GPU 中,DataParallel 的 module 才能对其进行处理,否则会报错:
# main.py
import torch
import torch.distributed as dist gpus = [0, 1, 2, 3]
torch.cuda.set_device('cuda:{}'.format(gpus[0])) train_dataset = ... train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=...) model = ...
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
model = nn.DataParallel(model.to(device), device_ids=gpus, output_device=gpus[0]) optimizer = optim.SGD(model.parameters()) for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
...
output = model(images)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()
缺点:
- 在每个训练批次(batch)中,因为模型的权重都是在 一个进程上先算出来 然后再把他们分发到每个GPU上,所以网络通信就成为了一个瓶颈,而GPU使用率也通常很低。
- 除此之外,nn.DataParallel 需要所有的GPU都在一个节点(一台机器)上,且并不支持 Apex 的 混合精度训练。
一句话,一个进程算权重使通信成为瓶颈,nn.DataParallel慢而且不支持混合精度训练。
使用 torch.distributed 加速并行训练
- DataParallel:单进程控制多 GPU。
- DistributedDataParallel:多进程控制多 GPU,一起训练模型。
在 1.0 之后,官方终于对分布式的常用方法进行了封装,支持 all-reduce,broadcast,send 和 receive 等等。通过 MPI 实现 CPU 通信,通过 NCCL 实现 GPU 通信。官方也推荐使用 DistributedDataParallel 解决 DataParallel 速度慢,GPU 负载不均衡的问题,目前已经很成熟了。
与 DataParallel 的单进程控制多 GPU 不同,在 distributed 的帮助下,我们只需要编写一份代码,torch 就会自动将其分配给n个进程,分别在n个 GPU 上运行。
多进程训练需要注意以下事项:
- 在喂数据的时候,一个batch被分到了好几个进程,每个进程在取数据的时候要确保拿到的是不同的数据(
DistributedSampler); - 要告诉每个进程自己是谁,使用哪块GPU(
args.local_rank); - 在做BatchNormalization的时候要注意同步数据。
启动方式的改变
在多进程的启动方面,我们不用自己手写 multiprocess 进行一系列复杂的CPU、GPU分配任务,PyTorch为我们提供了一个很方便的启动器 torch.distributed.launch 用于启动文件,所以我们运行训练代码的方式就变成了这样:
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 main.py
其中的 --nproc_per_node 参数用于指定为当前主机创建的进程数,由于我们是单机多卡,所以这里node数量为4,所以我们这里设置为所使用的GPU数量即可。
初始化
在启动器为我们启动python脚本后,在执行过程中,启动器会将当前进程的 index 通过参数传递给 python,我们可以这样获得当前进程的 index:即通过参数 local_rank 来告诉我们当前进程使用的是哪个GPU,用于我们在每个进程中指定不同的device:
def parse():
parser = argparse.ArgumentParser()
parser.add_argument('--local_rank', type=int, default=0, help='node rank for distributed training')
args = parser.parse_args()
return args def main():
args = parse()
torch.cuda.set_device(args.local_rank)
torch.distributed.init_process_group('nccl', init_method='env://')
device = torch.device(f'cuda:{args.local_rank}')
...
其中 torch.distributed.init_process_group 用于初始化GPU通信方式(NCCL)和参数的获取方式(env代表通过环境变量)。
使用 init_process_group 设置GPU之间通信使用的后端和端口,通过 NCCL 实现 GPU 通信。
DataLoader
在读取数据的时候,我们要保证一个batch里的数据被均摊到每个进程上,每个进程都能获取到不同的数据,但如果我们手动去告诉每个进程拿哪些数据的话太麻烦了,PyTorch也为我们封装好了这一方法。之后,使用 DistributedSampler 对数据集进行划分。如此前我们介绍的那样,它能帮助我们将每个 batch 划分成几个 partition,在当前进程中只需要获取和 rank 对应的那个 partition 进行训练。
所以我们在初始化 data loader 的时候需要使用到 torch.utils.data.distributed.DistributedSampler 这个特性:
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset) train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
这样就能给每个进程一个不同的 sampler,告诉每个进程自己分别取哪些数据。
模型的初始化
和 nn.DataParallel 的方式一样,我们对于模型的初始化也是简单的一句话就行了
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])
使用 DistributedDataParallel 包装模型,它能帮助我们为不同 GPU 上求得的梯度进行 all reduce(即汇总不同 GPU 计算所得的梯度,并同步计算结果)。all reduce 后不同 GPU 中模型的梯度均为 all reduce 之前各 GPU 梯度的均值。
汇总
至此,我们就可以使用 torch.distributed 给我们带来的多进程训练的性能提升了,汇总代码结果如下:
# main.py
import torch
import argparse
import torch.distributed as dist parser = argparse.ArgumentParser()
parser.add_argument('--local_rank', default=-1, type=int,
help='node rank for distributed training')
args = parser.parse_args() dist.init_process_group(backend='nccl')
torch.cuda.set_device(args.local_rank) train_dataset = ...
#每个进程一个sampler
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset) train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler) model = ...
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank]) optimizer = optim.SGD(model.parameters()) for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
...
output = model(images)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()
但是这里需要注意的是,如果使用这句代码,直接在pycharm或者别的编辑器中,是没法正常运行的,因为这个需要在shell的命令行中运行,如果想要正确执行这段代码,需要调用 torch.distributed.launch 启动器启动:
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 main.py
在 ImageNet 上的完整训练代码,请点击Github。
最后总结归纳下单机单卡 [snsc.py],单机多卡 (with DataParallel) [snmc_dp.py]和多机多卡 (with DistributedDataParallel)这3种训练方式的代码段,方便读者参考。
可惜的是pytorch并没有为我们同步BN,详细内容参见:PyTorch 21.单机多卡操作(分布式DataParallel,混合精度,Horovod)
参考
【博客园文章】关于博客园内嵌入bilibili视频
【哔哩哔哩视频】【ssh远程连接服务器教程】租了GPU服务器不知道怎么深度学习?看完不会你打我
【CSDN】Ubuntu安装和卸载CUDA和CUDNN
【CSDN】Ubuntu16.04下安装NVIDIA驱动 + cuda 11.2 + cudnn 8.1
【CSDN】ubuntu16.04安装NIVIDIA显卡驱动,cuda8.0,cuDNN6.0以及基于Anaconda安装Tensorflow-GPU
【个人博客】搭建Jupyter Notebook远程云服务器
【知乎】Jupyter lab 和避免服务器连接断开会关闭运行jupyter
【CSDN】前台运行和后台运行,以及遇到的Bug如何解决 ★
【pytorch官网】DATAPARALLEL
【知乎】Anaconda-用conda创建python虚拟环境
【知乎】PyTorch 21.单机多卡操作(分布式DataParallel,混合精度,Horovod)
linux系统下深度学习环境搭建和使用的更多相关文章
- 保姆级教程——Ubuntu16.04 Server下深度学习环境搭建:安装CUDA8.0,cuDNN6.0,Bazel0.5.4,源码编译安装TensorFlow1.4.0(GPU版)
写在前面 本文叙述了在Ubuntu16.04 Server下安装CUDA8.0,cuDNN6.0以及源码编译安装TensorFlow1.4.0(GPU版)的亲身经历,包括遇到的问题及解决办法,也有一些 ...
- win10+Ubuntu16.04双系统下深度学习环境的搭建
环境零零碎碎地搭了三四天,虽然碰到各种问题,但还是搭建好了,自己整理记录下,同时也算给有需要的人一些指导吧 一.双系统的安装 Win10硬盘管理助手 压缩或者直接利用未使用的空间,空间大小自定,将腾出 ...
- linux 服务器 keras 深度学习环境搭建
感慨: 程序跑不起来,都是环境问题. 1. 安装Anaconda https://blog.csdn.net/gdkyxy2013/article/details/79463859 2. 在 Anac ...
- 深度学习环境搭建:Tensorflow1.4.0+Ubuntu16.04+Python3.5+Cuda8.0+Cudnn6.0
目录 深度学习环境搭建:Tensorflow1.4.0+Ubuntu16.04+Python3.5+Cuda8.0+Cudnn6.0 Reference 硬件说明: 软件准备: 1. 安装Ubuntu ...
- [AI开发]centOS7.5上基于keras/tensorflow深度学习环境搭建
这篇文章详细介绍在centOS7.5上搭建基于keras/tensorflow的深度学习环境,该环境可用于实际生产.本人现在非常熟练linux(Ubuntu/centOS/openSUSE).wind ...
- Mac系统下STF的环境搭建和运行
本文参考以下文章整理:MAC 下 STF 的环境搭建和运行 一. 前言 STF,全称是Smartphone Test Farm,WEB 端批量移动设备管理控制工具,就是可以用浏览器来批量控制你的移动设 ...
- Win10+RTX2080深度学习环境搭建:tensorflow、mxnet、pytorch、caffe
目录 准备工作 设置conda国内镜像源 conda 深度学习环境 tensorflow.mxnet.pytorch安装 tensorflow mxnet pytorch Caffe安装 配置文件修改 ...
- Ubuntu深度学习环境搭建 tensorflow+pytorch
目前电脑配置:Ubuntu 16.04 + GTX1080显卡 配置深度学习环境,利用清华源安装一个miniconda环境是非常好的选择.尤其是今天发现conda install -c menpo o ...
- 深度学习环境搭建部署(DeepLearning 神经网络)
工作环境 系统:Ubuntu LTS 显卡:GPU NVIDIA驱动:410.93 CUDA:10.0 Python:.x CUDA以及NVIDIA驱动安装,详见https://www.cnblogs ...
随机推荐
- 痞子衡嵌入式:嵌入式MCU中通用的三重中断控制设计
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家分享的是嵌入式MCU中通用的三重中断控制设计. 我们知道在 MCU 裸机中程序代码之所以能完成多任务并行实时处理功能,其实主要是靠中断来调度的, ...
- UnitTest+HTMLTestRunner实战
框架 步骤 先建立images,reports,tools文件夹 把HTMLTestRunner.py放进tools中 文件内容 https://www.cnblogs.com/wangxue13 ...
- VB 6.0不能加载MSCOMCTL.OCX的解决方法
问题场景:打开 VB 6项目时报错,不能加载 'C:\WINDOWS\system32\MSCOMCTL.OCX'--继续加载工程吗? 解决方法: 1.新建一个VB工程,然后按CTRL + T,选中 ...
- golang可执行文件瘦身(缩小文件大小)
起因 golang部署起来极其遍历,但有时候希望对可执行文件进行瘦身(缩小文件大小) 尝试 情况允许情况下,交叉编译为32位 删除不必要的符号表.调试信息 尝试用对应平台的upx打压缩壳 解决 经过多 ...
- 素数(质数)(Java版)
4.输出质数(素数) 素数(质数):是指在大于1的自然数中,除了1和它本身外,不能被其他自然数整除(除0以外)的数 public class PrimeNumber { public static v ...
- SQL修改列名,增加列,删除列语句的写法
1.修改数据表名 ALTER TABLE [表名.]OLD_TABLE_NAME RENAME TO NEW_TABLE_NAME; 2.修改列名 ALTER TABLE [表名.]TABLE_NAM ...
- Vue--el-menu 的自动跳转功能与自己的click事件冲突
一\先看elementUI说明 项目实际 此时点击活导航时以 index 作为 path 进行路由跳转 那么此时不要onclik事件了 如果此时有在有click 就
- 使用Fileupload完成文件的上传下载
目录 使用Fileupload完成文件的上传下载 为什么需要进行文件上传下载? 引入jar包 文件上传 注意事项 编写一个简单的文件上传jsp页面 编写Servlet Student类用于封装数据,后 ...
- scrapy 使用crawlspider rule不起作用的解决方案
一直用的是通用spider,今天刚好想用下CrawlSpider来抓下数据.结果Debug了半天,一直没法进入详情页的解析逻辑.. 爬虫代码是这样的 # -*- coding: utf-8 -*- i ...
- Upload-labs 文件上传靶场通关攻略(上)
Upload-labs 文件上传靶场通关攻略(上) 文件上传是Web网页中常见的功能之一,通常情况下恶意的文件上传,会形成漏洞. 逻辑是这样的:用户通过上传点上传了恶意文件,通过服务器的校验后保存到指 ...