MHA高可用配置及故障切换
MHA高可用配置及故障切换
- MHA高可用配置及故障切换
- 一、案例概述
- 二、案例前置知识点
- 三、案例环境
- 四、案例实施
- 1. 搭建MySQL MHA
- (1)Master、Slave1、Slave2节点上安装mysql5.7
- (2)修改各服务器节点的主机名
- (3)修改Master、Slave1、Slave2节点的MySQL主配置文件
- (4)在Master、Slave1、Slave2节点上都创建两个软链接
- (5)配置mysql一主两从
- (6)安装MHA软件
- (7)在所有服务器上配置无密码认证
- (8)在manager节点上配置MHA
- (9)第一次配置需要在master节点上手动开启虚拟IP
- (10)在manager节点上测试ssh无密码认证
- (11)在manager节点上测试mysql主从连接情况
- (12)在manager节点上启动MHA
- (13)查看MHA状态,可以看到当前的master是MySQL1节点
- (14)查看MHA日志,也可以看到当前的master
- (15)查看MySQL1de VIP地址192.168.122.200是否存在,这个VIP地址不会因为manager节点停止MHA服务而消失
- (16)关闭manager服务
- 2. 故障模拟与修复
- 1. 搭建MySQL MHA
一、案例概述
传统的MySQL主从架构存在的问题
● 单点故障
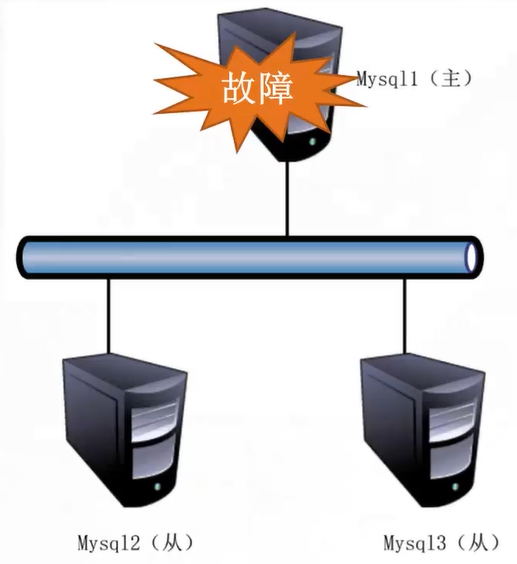
为了解决单点故障所带来的的影响,我们可以使用MHA高可用架构。
二、案例前置知识点
1. MHA概述
● MHA(Master High Availability)是一套优秀的MySQL高可用环境下故障切换和主从复制的软件。
● MHA的出现就是解决MySQL单点的问题。
● MySQL故障切换过程中,MHA能做到0-30秒内自动完成故障切换。
● MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
2. MHA的组成
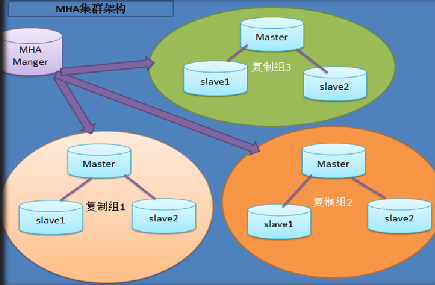
(1)MHA Manager(管理节点)
MHA Manager可以单独部署在一台独立的机器上,管理多个master-slave集群;也可以部署在一台slave节点上。
MHA Manager会定时探测集群中的master节点。当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有的slave重新指向新的master,整个故障转移过程对应用程序完全透明。
(2)MHA Node(数据节点)
MHA Node运行在每台MySQL服务器上。
3. MHA特点
● 自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据不丢失。
● 使用半同步复制,可以大大降低数据丢失的风险,如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性。
● 目前MHA支持一主多从的架构,最少三台服务,即一主两从
4. MHA切换过程
(1)从宕机崩溃的master保存二进制日志事件(binlog events);
(2)识别含有最新更新的slave;
(3)应用差异的中继日志(relay log)到其他 slave;
(4)应用从master保存的二进制日志事件(binlog events);
(5)提升一个slave为新master;
(6)使其他的slave连接新的master进行复制。
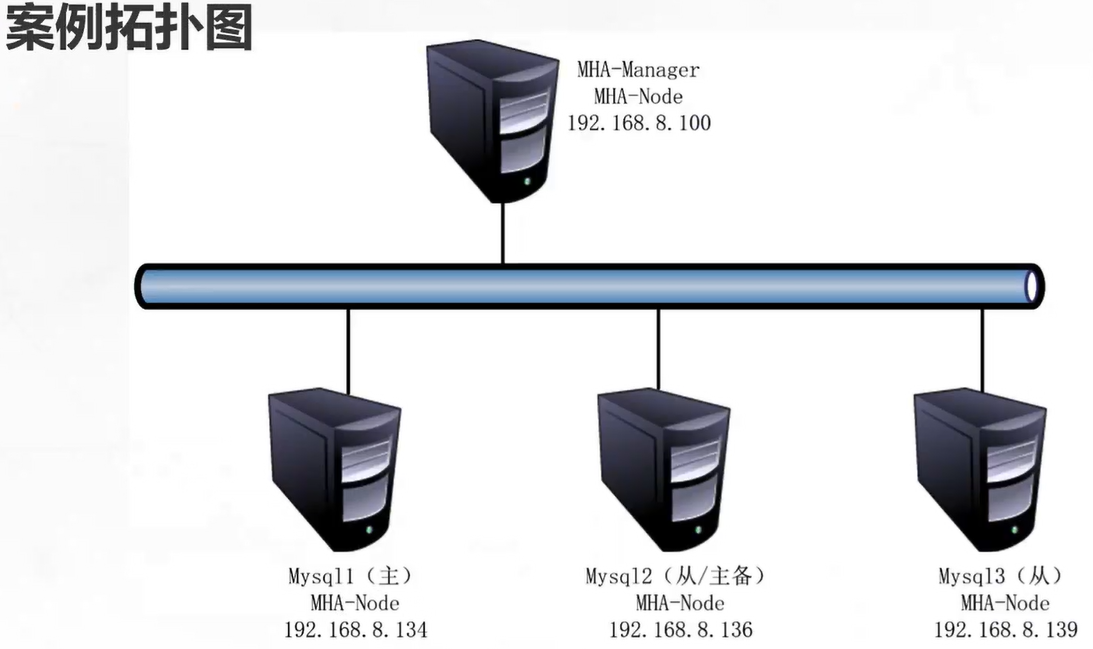
三、案例环境
1. 实验思路
- MHA架构
● 数据库安装
● 一主两从
● MHA搭建 - 故障模拟
● 主库失效
● 备选主库成为主库
● 原故障主库恢复重新加入到MHA成为从库
2. 服务器、主机名、系统、IP以及软件版本配置
| 服务器 | 主机名 | 系统 | IP | 软件及版本 |
|---|---|---|---|---|
| MHA manager节点服务器 | manager | CentOS7.4(64位) | 192.168.122.100 | 安装MHA node和manager组件 |
| Master节点服务器 | mysql1 | CentOS7.4(64位) | 192.168.122.10 | 安装mysql5.7、MHA node组件 |
| Slave1节点服务器 | mysql2 | CentOS7.4(64位) | 192.168.122.11 | 安装mysql5.7、MHA node组件 |
| Slave2节点服务器 | mysql3 | CentOS7.4(64位) | 192.168.122.12 | 安装mysql5.7、MHA node组件 |
3. 各服务器环境配置
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
四、案例实施
1. 搭建MySQL MHA
(1)Master、Slave1、Slave2节点上安装mysql5.7
刷下列脚本,过程忽略
#!/bin/bash
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
#--------mysql--------
#安装依赖包
yum -y install gcc gcc-c++ ncurses ncurses-devel bison cmake
#配置软件模块
cd /opt/
tar zxvf mysql-5.7.17.tar.gz
tar zxvf boost_1_59_0.tar.gz
mv boost_1_59_0 /usr/local/boost
cd /opt/mysql-5.7.17/
cmake \
-DCMAKE_INSTALL_PREFIX=/usr/local/mysql \
-DMYSQL_UNIX_ADDR=/usr/local/mysql/mysql.sock \
-DSYSCONFDIR=/etc \
-DSYSTEMD_PID_DIR=/usr/local/mysql \
-DDEFAULT_CHARSET=utf8 \
-DDEFAULT_COLLATION=utf8_general_ci \
-DWITH_EXTRA_CHARSETS=all \
-DWITH_INNOBASE_STORAGE_ENGINE=1 \
-DWITH_ARCHIVE_STORAGE_ENGINE=1 \
-DWITH_BLACKHOLE_STORAGE_ENGINE=1 \
-DWITH_PERFSCHEMA_STORAGE_ENGINE=1 \
-DMYSQL_DATADIR=/usr/local/mysql/data \
-DWITH_BOOST=/usr/local/boost \
-DWITH_SYSTEMD=1
#编译安装
make -j 2 && make install
#创建mysql用户
useradd -M -s /sbin/nologin mysql
#修改mysql 配置文件
echo '[client]
port = 3306
default-character-set=utf8
socket=/usr/local/mysql/mysql.sock
[mysql]
port = 3306
default-character-set=utf8
socket = /usr/local/mysql/mysql.sock
auto-rehash
[mysqld]
user = mysql
basedir=/usr/local/mysql
datadir=/usr/local/mysql/data
port = 3306
character-set-server=utf8
pid-file = /usr/local/mysql/mysqld.pid
socket=/usr/local/mysql/mysql.sock
bind-address = 0.0.0.0
skip-name-resolve
max_connections=2048
default-storage-engine=INNODB
max_allowed_packet=16M
server-id = 1
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_AUTO_VALUE_ON_ZERO,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,PIPES_AS_CONCAT,ANSI_QUOTES' > /etc/my.cnf
#更改mysql安装目录和配置文件的属主属组
chown -R mysql:mysql /usr/local/mysql/
chown mysql:mysql /etc/my.cnf
#设置路径环境变量
echo 'export PATH=/usr/local/mysql/bin:/usr/local/mysql/lib:$PATH' >> /etc/profile
source /etc/profile
#初始化数据库
cd /usr/local/mysql/bin/
./mysqld \
--initialize-insecure \
--user=mysql \
--basedir=/usr/local/mysql \
--datadir=/usr/local/mysql/data
#添加mysqld系统服务
cp /usr/local/mysql/usr/lib/systemd/system/mysqld.service /usr/lib/systemd/system/
systemctl daemon-reload
systemctl start mysqld.service
systemctl enable mysqld
yum -y install expect
mima () {
passwd=$1
/usr/bin/expect <<-EOF
spawn mysqladmin -u root -p password $passwd
expect "Enter password:"
send "\r"
expect eof
EOF
}
mima "123456"
dl () {
/usr/bin/expect <<-EOF
spawn mysql -u root -p
expect "Enter password:" {send "123456\r"}
expect "mysql>" {send "grant all privileges on *.* to 'root'@'%' identified by '123456';\r"}
expect "mysql>" {send "quit\r"}
expect eof
EOF
}
dl
(2)修改各服务器节点的主机名
Master(192.168.122.10)
[root@localhost opt]# hostnamectl set-hostname mysql1
Slave1(192.168.122.11)
[root@localhost opt]# hostnamectl set-hostname mysql2
Slave2(192.168.122.12)
[root@localhost opt]# hostnamectl set-hostname mysql3
MHA manager(192.168.122.100)
[root@localhost ~]# hostnamectl set-hostname manager
(3)修改Master、Slave1、Slave2节点的MySQL主配置文件
Master(192.168.122.10)
[root@mysql1 ~]# vim /etc/my.cnf
##mysqld项下添加参数
[mysqld]
server-id = 1
log_bin = master-bin
log-slave-updates = true
[root@mysql1 ~]# systemctl restart mysqld
Slave1(192.168.122.11)
[root@mysql2 ~]# vim /etc/my.cnf
##mysqld项下添加参数
[mysqld]
server-id = 2
log_bin = master-bin
relay-log = relay-log-bin
relay-log-index = slave-relay-bin.index
[root@mysql2 ~]# systemctl restart mysqld
Slave2(192.168.122.12)
[root@mysql3 ~]# vim /etc/my.cnf
##mysqld项下添加参数
[mysqld]
server-id = 3
log_bin = master-bin
relay-log = relay-log-bin
relay-log-index = slave-relay-bin.index
[root@mysql3 ~]# systemctl restart mysqld
(4)在Master、Slave1、Slave2节点上都创建两个软链接
Master(192.168.122.10)
[root@mysql1 ~]# ln -s /usr/local/mysql/bin/mysql /usr/sbin/
[root@mysql1 ~]# ln -s /usr/local/mysql/bin/mysqlbinlog /usr/sbin/
Slave1(192.168.122.11)
[root@mysql2 ~]# ln -s /usr/local/mysql/bin/mysql /usr/sbin/
[root@mysql2 ~]# ln -s /usr/local/mysql/bin/mysqlbinlog /usr/sbin/
Slave2(192.168.122.12)
[root@mysql3 ~]# ln -s /usr/local/mysql/bin/mysql /usr/sbin/
[root@mysql3 ~]# ln -s /usr/local/mysql/bin/mysqlbinlog /usr/sbin/
(5)配置mysql一主两从
①所有数据库节点进行mysql授权
Master(192.168.122.10)
[root@mysql1 ~]# mysql -u root -p
Enter password:
mysql> grant replication slave on *.* to 'myslave'@'192.168.122.%' identified by '123456';
##从数据库同步使用
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> grant all privileges on *.* to 'mha'@'192.168.122.%' identified by '123456';
##manager使用
Query OK, 0 rows affected, 1 warning (0.01 sec)
mysql> grant all privileges on *.* to 'mha'@'mysql1' identified by '123456';
##防止从库通过主机名连接不上主库
Query OK, 0 rows affected, 2 warnings (0.00 sec)
mysql> grant all privileges on *.* to 'mha'@'mysql2' identified by '123456';
Query OK, 0 rows affected, 2 warnings (0.00 sec)
mysql> grant all privileges on *.* to 'mha'@'mysql3' identified by '123456';
Query OK, 0 rows affected, 2 warnings (0.00 sec)
Slave1(192.168.122.11)
[root@mysql2 ~]# mysql -u root -p
Enter password:
mysql> grant replication slave on *.* to 'myslave'@'192.168.122.%' identified by '123456';
##从数据库同步使用
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> grant all privileges on *.* to 'mha'@'192.168.122.%' identified by '123456';
##manager使用
Query OK, 0 rows affected, 1 warning (0.01 sec)
mysql> grant all privileges on *.* to 'mha'@'mysql1' identified by '123456';
##防止从库通过主机名连接不上主库
Query OK, 0 rows affected, 2 warnings (0.00 sec)
mysql> grant all privileges on *.* to 'mha'@'mysql2' identified by '123456';
Query OK, 0 rows affected, 2 warnings (0.00 sec)
mysql> grant all privileges on *.* to 'mha'@'mysql3' identified by '123456';
Query OK, 0 rows affected, 2 warnings (0.00 sec)
Slave2(192.168.122.12)
[root@mysql3 ~]# mysql -u root -p
Enter password:
mysql> grant replication slave on *.* to 'myslave'@'192.168.122.%' identified by '123456';
##从数据库同步使用
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> grant all privileges on *.* to 'mha'@'192.168.122.%' identified by '123456';
##manager使用
Query OK, 0 rows affected, 1 warning (0.01 sec)
mysql> grant all privileges on *.* to 'mha'@'mysql1' identified by '123456';
##防止从库通过主机名连接不上主库
Query OK, 0 rows affected, 2 warnings (0.00 sec)
mysql> grant all privileges on *.* to 'mha'@'mysql2' identified by '123456';
Query OK, 0 rows affected, 2 warnings (0.00 sec)
mysql> grant all privileges on *.* to 'mha'@'mysql3' identified by '123456';
Query OK, 0 rows affected, 2 warnings (0.00 sec)
②在Master节点查看二进制文件和同步点
mysql> show master status;
+-------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-------------------+----------+--------------+------------------+-------------------+
| master-bin.000001 | 1595 | | | |
+-------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
③在Slave1、Slave2节点执行同步操作
Slave1(192.168.122.11)
mysql> change master to
-> master_host='192.168.122.10',
-> master_user='myslave',
-> master_password='123456',
-> master_log_file='master-bin.000001',
-> master_log_pos=1595;
Query OK, 0 rows affected, 2 warnings (0.01 sec)
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)
Slave2(192.168.122.12)
mysql> change master to
-> master_host='192.168.122.10',
-> master_user='myslave',
-> master_password='123456',
-> master_log_file='master-bin.000001',
-> master_log_pos=1595;
Query OK, 0 rows affected, 2 warnings (0.01 sec)
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)
④在Slave1、Slave2节点查看数据同步结果
Slave1(192.168.122.11)
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.122.10
Master_User: myslave
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: master-bin.000001
Read_Master_Log_Pos: 1595
Relay_Log_File: relay-log-bin.000002
Relay_Log_Pos: 321
Relay_Master_Log_File: master-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 1595
Relay_Log_Space: 526
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 00430ab9-0f02-11ec-ad15-000c2959bebe
Master_Info_File: /usr/local/mysql/data/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)
Slave2(192.168.122.12)
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.122.10
Master_User: myslave
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: master-bin.000001
Read_Master_Log_Pos: 1595
Relay_Log_File: relay-log-bin.000002
Relay_Log_Pos: 321
Relay_Master_Log_File: master-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 1595
Relay_Log_Space: 526
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 00430ab9-0f02-11ec-ad15-000c2959bebe
Master_Info_File: /usr/local/mysql/data/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)
确保IO和SQL线程都是Yes,代表同步正常。
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
⑤两个从库必须设置为只读模式
Slave1(192.168.122.11)
mysql> set global read_only=1;
Query OK, 0 rows affected (0.00 sec)
Slave2(192.168.122.12)
mysql> set global read_only=1;
Query OK, 0 rows affected (0.00 sec)
⑥插入数据测试数据库同步
在Master主库插入一条数据,测试是否同步
Master(192.168.122.10)
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.00 sec)
mysql> create database test;
Query OK, 1 row affected (0.00 sec)
mysql> create table test.test(id int,name char(20));
Query OK, 0 rows affected (0.01 sec)
mysql> insert into test.test values(1,'master1');
Query OK, 1 row affected (0.00 sec)
mysql> select * from test.test;
+------+---------+
| id | name |
+------+---------+
| 1 | master1 |
+------+---------+
1 row in set (0.00 sec)
Slave1(192.168.122.11)
mysql> select * from test.test;
+------+---------+
| id | name |
+------+---------+
| 1 | master1 |
+------+---------+
1 row in set (0.00 sec)
Slave2(192.168.122.12)
mysql> select * from test.test;
+------+---------+
| id | name |
+------+---------+
| 1 | master1 |
+------+---------+
1 row in set (0.00 sec)
(6)安装MHA软件
①所有服务器上都安装MHA依赖的环境,首先安装epel源
Master(192.168.122.10)
[root@mysql1 ~]# yum install epel-release --nogpgcheck -y
[root@mysql1 ~]# yum install -y perl-DBD-MySQL \
> perl-Config-Tiny \
> perl-Log-Dispatch \
> perl-Parallel-ForkManager \
> perl-ExtUtils-CBuilder \
> perl-ExtUtils-MakeMaker \
> perl-CPAN
Slave1(192.168.122.11)
[root@mysql2 ~]# yum install epel-release --nogpgcheck -y
[root@mysql2 ~]# yum install -y perl-DBD-MySQL \
> perl-Config-Tiny \
> perl-Log-Dispatch \
> perl-Parallel-ForkManager \
> perl-ExtUtils-CBuilder \
> perl-ExtUtils-MakeMaker \
> perl-CPAN
Slave2(192.168.122.12)
[root@mysql3 ~]# yum install epel-release --nogpgcheck -y
[root@mysql3 ~]# yum install -y perl-DBD-MySQL \
> perl-Config-Tiny \
> perl-Log-Dispatch \
> perl-Parallel-ForkManager \
> perl-ExtUtils-CBuilder \
> perl-ExtUtils-MakeMaker \
> perl-CPAN
MHA manager(192.168.122.100)
[root@manager ~]# yum install epel-release --nogpgcheck -y
[root@manager ~]# yum install -y perl-DBD-MySQL \
> perl-Config-Tiny \
> perl-Log-Dispatch \
> perl-Parallel-ForkManager \
> perl-ExtUtils-CBuilder \
> perl-ExtUtils-MakeMaker \
> perl-CPAN
②安装MHA软件包,必须在所有服务器上先安装node组件
对于每个操作系统版本不一样,这里CentOS7.4必须选择0.57版本。
在所有服务器上必须先安装node组件,最后在MHA-manager节点上安装manager组件,因为manager依赖node组件。
这里统一将安装包上传到/opt目录中。
Master(192.168.122.10)
[root@mysql1 ~]# cd /opt
##传入安装包
[root@mysql1 opt]# tar zxvf mha4mysql-node-0.57.tar.gz
[root@mysql1 opt]# cd mha4mysql-node-0.57/
[root@mysql1 mha4mysql-node-0.57]# perl Makefile.PL
[root@mysql1 mha4mysql-node-0.57]# make && make install
Slave1(192.168.122.11)
[root@mysql2 ~]# cd /opt
##传入安装包
[root@mysql2 opt]# tar zxvf mha4mysql-node-0.57.tar.gz
[root@mysql2 opt]# cd mha4mysql-node-0.57/
[root@mysql2 mha4mysql-node-0.57]# perl Makefile.PL
[root@mysql2 mha4mysql-node-0.57]# make && make install
Slave2(192.168.122.12)
[root@mysql3 ~]# cd /opt
##传入安装包
[root@mysql3 opt]# tar zxvf mha4mysql-node-0.57.tar.gz
[root@mysql3 opt]# cd mha4mysql-node-0.57/
[root@mysql3 mha4mysql-node-0.57]# perl Makefile.PL
[root@mysql3 mha4mysql-node-0.57]# make && make install
MHA manager(192.168.122.100)
[root@manager ~]# cd /opt
##传入安装包
[root@manager opt]# tar zxvf mha4mysql-node-0.57.tar.gz
[root@manager opt]# cd mha4mysql-node-0.57/
[root@manager mha4mysql-node-0.57]# perl Makefile.PL
[root@manager mha4mysql-node-0.57]# make && make install
③在MHA manager节点上安装manager组件
MHA manager(192.168.122.100)
[root@manager mha4mysql-node-0.57]# cd ../
[root@manager opt]# tar zxvf mha4mysql-manager-0.57.tar.gz
[root@manager opt]# cd mha4mysql-manager-0.57
[root@manager mha4mysql-manager-0.57]# perl Makefile.PL
[root@manager mha4mysql-manager-0.57]# make && make install
④node组件工具
node组件安装后会在/usr/local/bin下面生成几个脚本文件(这些工具通常由MHA Manager的脚本触发,无需人为操作)主要如下:
● save_binary_logs
保存和复制master的二进制日志
● apply_diff_relay_logs
识别差异的中继日志事件并将其差异的事件应用于其他的slave
● filter_mysqlbinlog
去除不必要的ROLLBACK事件(MHA已不再使用这个工具)
● purge_relay_logs
清除中继日志(不会阻塞SQL线程)
⑤manager组件工具
manager组件安装后在/usr/local/bin下面会生成几个工具,主要包括以下几个:
● masterha_check_ssh
检查MHA的SSH配置状况
● masterha_check_repl
检查MySQL复制状况
● masterha_manger
启动manager的脚本
● masterha_check_status
检测当前MHA运行状态
● masterha_master_monitor
检测 master是否宕机
● masterha_master_switch
控制故障转移(自动或者手动)
● masterha_conf_host
添加或删除配置的server信息
● masterha_stop
关闭manager
(7)在所有服务器上配置无密码认证
①在manager节点上配置到所有数据库节点的无密码认证
MHA manager(192.168.122.100)
[root@manager mha4mysql-manager-0.57]# ssh-keygen -t rsa
#一直按回车
[root@manager mha4mysql-manager-0.57]# ssh-copy-id 192.168.122.10
#输入yes,输入密码
[root@manager mha4mysql-manager-0.57]# ssh-copy-id 192.168.122.11
#输入yes,输入密码
[root@manager mha4mysql-manager-0.57]# ssh-copy-id 192.168.122.12
#输入yes,输入密码
②在mysql1上配置到数据库节点mysql2和mysql3的无密码认证
Master(192.168.122.10)
[root@mysql1 mha4mysql-manager-0.57]# ssh-keygen -t rsa
#一直按回车
[root@mysql1 mha4mysql-manager-0.57]# ssh-copy-id 192.168.122.11
#输入yes,输入密码
[root@mysql1 mha4mysql-manager-0.57]# ssh-copy-id 192.168.122.12
#输入yes,输入密码
③在mysql2上配置到数据库节点mysql1和mysql3的无密码认证
Slave1(192.168.122.11)
[root@mysql2 mha4mysql-manager-0.57]# ssh-keygen -t rsa
#一直按回车
[root@mysql2 mha4mysql-manager-0.57]# ssh-copy-id 192.168.122.10
#输入yes,输入密码
[root@mysql2 mha4mysql-manager-0.57]# ssh-copy-id 192.168.122.12
#输入yes,输入密码
④在mysql3上配置到数据库节点mysql1和mysql2的无密码认证
Slave2(192.168.122.12)
[root@mysql3 mha4mysql-manager-0.57]# ssh-keygen -t rsa
#一直按回车
[root@mysql3 mha4mysql-manager-0.57]# ssh-copy-id 192.168.122.10
#输入yes,输入密码
[root@mysql3 mha4mysql-manager-0.57]# ssh-copy-id 192.168.122.11
#输入yes,输入密码
(8)在manager节点上配置MHA
①在manager节点上复制相关脚本到/usr/local/bin目录
MHA manager(192.168.122.100)
[root@manager mha4mysql-manager-0.57]# cp -rp /opt/mha4mysql-manager-0.57/samples/scripts /usr/local/bin
[root@manager mha4mysql-manager-0.57]# cd samples/scripts/
[root@manager scripts]# ll
总用量 32
-rwxr-xr-x 1 1001 1001 3648 5月 31 2015 master_ip_failover
#自动切换时VIP的管理脚本
-rwxr-xr-x 1 1001 1001 9870 5月 31 2015 master_ip_online_change
#在线切换时VIP的管理脚本
-rwxr-xr-x 1 1001 1001 11867 5月 31 2015 power_manager
#故障发生后关闭主机的脚本
-rwxr-xr-x 1 1001 1001 1360 5月 31 2015 send_report
#因故障切换后发送报警的脚本
②复制上述的自动切换时VIP的管理脚本到/usr/local/bin目录
这里使用master_ip_failover脚本来管理VIP和故障切换
MHA manager(192.168.122.100)
[root@manager scripts]# cp /usr/local/bin/scripts/master_ip_failover /usr/local/bin
③修改内容如下(修改VIP相关参数):
MHA manager(192.168.122.100)
[root@manager scripts]# vim /usr/local/bin/master_ip_failover
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
#############################添加内容部分#########################################
my $vip = '192.168.122.200'; #指定vip的地址
my $brdc = '192.168.122.255'; #指定vip的广播地址
my $ifdev = 'ens33'; #指定vip绑定的网卡
my $key = '1'; #指定vip绑定的虚拟网卡序列号
my $ssh_start_vip = "/sbin/ifconfig ens33:$key $vip"; #代表此变量值为ifconfig ens33:1 192.168.122.200
my $ssh_stop_vip = "/sbin/ifconfig ens33:$key down"; #代表此变量值为ifconfig ens33:1 192.168.122.200 down
my $exit_code = 0; #指定退出状态码为0
#my $ssh_start_vip = "/usr/sbin/ip addr add $vip/24 brd $brdc dev $ifdev label $ifdev:$key;/usr/sbin/arping -q -A -c 1 -I $ifdev $vip;iptables -F;";
#my $ssh_stop_vip = "/usr/sbin/ip addr del $vip/24 dev $ifdev label $ifdev:$key";
##################################################################################
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
);
exit &main();
sub main {
print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
## A simple system call that disable the VIP on the old_master
sub stop_vip() {
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
④创建MHA软件目录并拷贝配置文件
这里使用app1.cnf配置文件来管理mysql节点服务器
MHA manager(192.168.122.100)
[root@manager scripts]# mkdir /etc/masterha
[root@manager scripts]# cp /opt/mha4mysql-manager-0.57/samples/conf/app1.cnf /etc/masterha
[root@manager scripts]# vim /etc/masterha/app1.cnf
[server default]
manager_log=/var/log/masterha/app1/manager.log
##manager日志路径
manager_workdir=/var/log/masterha/app1
##manager工作目录
master_binlog_dir=/usr/local/mysql/data
##master保存binlog的位置,这里的路径要与master里配置的binlog的路径一致,以便MHAzhaodao
master_ip_failover_script=/usr/local/bin/master_ip_failover
##设置自动failover时候的切换脚本,也就是上一步修改的脚本
master_ip_online_change_script=/usr/local/bin/master_ip_online_change
##设置手动切换时候的切换脚本
password=123456
##设置mysql中root用户的密码,这个密码是前文中创建监控用户的那个密码
ping_interval=1
##设置监控主库,发送ping包的时间间隔,默认是3秒,尝试三次没有回应的时候自动进行failover
remote_workdir=/tmp
##设置远端mysql在发生切换时binlog的保存位置
repl_password=123456
##设置复制用户的密码
repl_user=myslave
##设置复制用户的用户
report_script=/usr/local/send_report
##设置发生切换后发送的报警的脚本
secondary_check_script=/usr/local/bin/masterha_secondary_check -s 192.168.122.11 -s 192.168.122.12
##指定检查的从服务器IP地址
shutdown_script=""
##设置故障发生后关闭故障主机脚本(该脚本的主要作用是关闭主机防止发生脑裂,这里没有指定)
ssh_user=root
##设置ssh的登录用户名
user=mha
##设置监控用户
[server1]
hostname=192.168.122.10
port=3306
[server2]
candidate_master=1
##设置为候选master,设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个从库不是集群中最新的slave
check_repl_delay=0
##默认情况下如果有一个slave落后master超过100M的relay logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间;通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主机在切换的过程中一定是新的master
hostname=192.168.122.11
port=3306
[server3]
hostname=192.168.122.12
port=3306
(9)第一次配置需要在master节点上手动开启虚拟IP
Master(192.168.122.10)
[root@mysql1 mha4mysql-node-0.57]# /sbin/ifconfig ens33:1 192.168.122.200/24
(10)在manager节点上测试ssh无密码认证
如果正常最后会输出successfully
MHA manager(192.168.122.100)
[root@manager scripts]# masterha_check_ssh -conf=/etc/masterha/app1.cnf
Tue Sep 7 01:05:53 2021 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Tue Sep 7 01:05:53 2021 - [info] Reading application default configuration from /etc/masterha/app1.cnf..
Tue Sep 7 01:05:53 2021 - [info] Reading server configuration from /etc/masterha/app1.cnf..
Tue Sep 7 01:05:53 2021 - [info] Starting SSH connection tests..
Tue Sep 7 01:05:54 2021 - [debug]
Tue Sep 7 01:05:53 2021 - [debug] Connecting via SSH from root@192.168.122.10(192.168.122.10:22) to root@192.168.122.11(192.168.122.11:22)..
Tue Sep 7 01:05:54 2021 - [debug] ok.
Tue Sep 7 01:05:54 2021 - [debug] Connecting via SSH from root@192.168.122.10(192.168.122.10:22) to root@192.168.122.12(192.168.122.12:22)..
Tue Sep 7 01:05:54 2021 - [debug] ok.
Tue Sep 7 01:05:55 2021 - [debug]
Tue Sep 7 01:05:54 2021 - [debug] Connecting via SSH from root@192.168.122.11(192.168.122.11:22) to root@192.168.122.10(192.168.122.10:22)..
Tue Sep 7 01:05:54 2021 - [debug] ok.
Tue Sep 7 01:05:54 2021 - [debug] Connecting via SSH from root@192.168.122.11(192.168.122.11:22) to root@192.168.122.12(192.168.122.12:22)..
Tue Sep 7 01:05:55 2021 - [debug] ok.
Tue Sep 7 01:05:56 2021 - [debug]
Tue Sep 7 01:05:54 2021 - [debug] Connecting via SSH from root@192.168.122.12(192.168.122.12:22) to root@192.168.122.10(192.168.122.10:22)..
Tue Sep 7 01:05:55 2021 - [debug] ok.
Tue Sep 7 01:05:55 2021 - [debug] Connecting via SSH from root@192.168.122.12(192.168.122.12:22) to root@192.168.122.11(192.168.122.11:22)..
Tue Sep 7 01:05:55 2021 - [debug] ok.
Tue Sep 7 01:05:56 2021 - [info] All SSH connection tests passed successfully.
(11)在manager节点上测试mysql主从连接情况
最后出现MySQL Replication Health is OK 字样说明正常。
MHA manager(192.168.122.100)
[root@manager scripts]# masterha_check_repl -conf=/etc/masterha/app1.cnf
[root@manager scripts]# masterha_check_repl -conf=/etc/masterha/app1.cnf
Tue Sep 7 03:10:16 2021 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Tue Sep 7 03:10:16 2021 - [info] Reading application default configuration from /etc/masterha/app1.cnf..
Tue Sep 7 03:10:16 2021 - [info] Reading server configuration from /etc/masterha/app1.cnf..
Tue Sep 7 03:10:16 2021 - [info] MHA::MasterMonitor version 0.57.
Tue Sep 7 03:10:17 2021 - [info] GTID failover mode = 0
Tue Sep 7 03:10:17 2021 - [info] Dead Servers:
Tue Sep 7 03:10:17 2021 - [info] Alive Servers:
Tue Sep 7 03:10:17 2021 - [info] 192.168.122.10(192.168.122.10:3306)
Tue Sep 7 03:10:17 2021 - [info] 192.168.122.11(192.168.122.11:3306)
Tue Sep 7 03:10:17 2021 - [info] 192.168.122.12(192.168.122.12:3306)
Tue Sep 7 03:10:17 2021 - [info] Alive Slaves:
Tue Sep 7 03:10:17 2021 - [info] 192.168.122.11(192.168.122.11:3306) Version=5.7.17-log (oldest major version between slaves) log-bin:enabled
Tue Sep 7 03:10:17 2021 - [info] Replicating from 192.168.122.10(192.168.122.10:3306)
Tue Sep 7 03:10:17 2021 - [info] Primary candidate for the new Master (candidate_master is set)
Tue Sep 7 03:10:17 2021 - [info] 192.168.122.12(192.168.122.12:3306) Version=5.7.17-log (oldest major version between slaves) log-bin:enabled
Tue Sep 7 03:10:17 2021 - [info] Replicating from 192.168.122.10(192.168.122.10:3306)
Tue Sep 7 03:10:17 2021 - [info] Current Alive Master: 192.168.122.10(192.168.122.10:3306)
Tue Sep 7 03:10:17 2021 - [info] Checking slave configurations..
Tue Sep 7 03:10:17 2021 - [info] read_only=1 is not set on slave 192.168.122.11(192.168.122.11:3306).
Tue Sep 7 03:10:17 2021 - [warning] relay_log_purge=0 is not set on slave 192.168.122.11(192.168.122.11:3306).
Tue Sep 7 03:10:17 2021 - [info] read_only=1 is not set on slave 192.168.122.12(192.168.122.12:3306).
Tue Sep 7 03:10:17 2021 - [warning] relay_log_purge=0 is not set on slave 192.168.122.12(192.168.122.12:3306).
Tue Sep 7 03:10:17 2021 - [info] Checking replication filtering settings..
Tue Sep 7 03:10:17 2021 - [info] binlog_do_db= , binlog_ignore_db=
Tue Sep 7 03:10:17 2021 - [info] Replication filtering check ok.
Tue Sep 7 03:10:17 2021 - [info] GTID (with auto-pos) is not supported
Tue Sep 7 03:10:17 2021 - [info] Starting SSH connection tests..
Tue Sep 7 03:10:20 2021 - [info] All SSH connection tests passed successfully.
Tue Sep 7 03:10:20 2021 - [info] Checking MHA Node version..
Tue Sep 7 03:10:20 2021 - [info] Version check ok.
Tue Sep 7 03:10:20 2021 - [info] Checking SSH publickey authentication settings on the current master..
Tue Sep 7 03:10:20 2021 - [info] HealthCheck: SSH to 192.168.122.10 is reachable.
Tue Sep 7 03:10:20 2021 - [info] Master MHA Node version is 0.57.
Tue Sep 7 03:10:20 2021 - [info] Checking recovery script configurations on 192.168.122.10(192.168.122.10:3306)..
Tue Sep 7 03:10:20 2021 - [info] Executing command: save_binary_logs --command=test --start_pos=4 --binlog_dir=/usr/local/mysql/data --output_file=/tmp/save_binary_logs_test --manager_version=0.57 --start_file=master-bin.000001
Tue Sep 7 03:10:20 2021 - [info] Connecting to root@192.168.122.10(192.168.122.10:22)..
Creating /tmp if not exists.. ok.
Checking output directory is accessible or not..
ok.
Binlog found at /usr/local/mysql/data, up to master-bin.000001
Tue Sep 7 03:10:20 2021 - [info] Binlog setting check done.
Tue Sep 7 03:10:20 2021 - [info] Checking SSH publickey authentication and checking recovery script configurations on all alive slave servers..
Tue Sep 7 03:10:20 2021 - [info] Executing command : apply_diff_relay_logs --command=test --slave_user='mha' --slave_host=192.168.122.11 --slave_ip=192.168.122.11 --slave_port=3306 --workdir=/tmp --target_version=5.7.17-log --manager_version=0.57 --relay_log_info=/usr/local/mysql/data/relay-log.info --relay_dir=/usr/local/mysql/data/ --slave_pass=xxx
Tue Sep 7 03:10:20 2021 - [info] Connecting to root@192.168.122.11(192.168.122.11:22)..
Checking slave recovery environment settings..
Opening /usr/local/mysql/data/relay-log.info ... ok.
Relay log found at /usr/local/mysql/data, up to relay-log-bin.000006
Temporary relay log file is /usr/local/mysql/data/relay-log-bin.000006
Testing mysql connection and privileges..mysql: [Warning] Using a password on the command line interface can be insecure.
done.
Testing mysqlbinlog output.. done.
Cleaning up test file(s).. done.
Tue Sep 7 03:10:21 2021 - [info] Executing command : apply_diff_relay_logs --command=test --slave_user='mha' --slave_host=192.168.122.12 --slave_ip=192.168.122.12 --slave_port=3306 --workdir=/tmp --target_version=5.7.17-log --manager_version=0.57 --relay_log_info=/usr/local/mysql/data/relay-log.info --relay_dir=/usr/local/mysql/data/ --slave_pass=xxx
Tue Sep 7 03:10:21 2021 - [info] Connecting to root@192.168.122.12(192.168.122.12:22)..
Checking slave recovery environment settings..
Opening /usr/local/mysql/data/relay-log.info ... ok.
Relay log found at /usr/local/mysql/data, up to relay-log-bin.000006
Temporary relay log file is /usr/local/mysql/data/relay-log-bin.000006
Testing mysql connection and privileges..mysql: [Warning] Using a password on the command line interface can be insecure.
done.
Testing mysqlbinlog output.. done.
Cleaning up test file(s).. done.
Tue Sep 7 03:10:21 2021 - [info] Slaves settings check done.
Tue Sep 7 03:10:21 2021 - [info]
192.168.122.10(192.168.122.10:3306) (current master)
+--192.168.122.11(192.168.122.11:3306)
+--192.168.122.12(192.168.122.12:3306)
Tue Sep 7 03:10:21 2021 - [info] Checking replication health on 192.168.122.11..
Tue Sep 7 03:10:21 2021 - [info] ok.
Tue Sep 7 03:10:21 2021 - [info] Checking replication health on 192.168.122.12..
Tue Sep 7 03:10:21 2021 - [info] ok.
Tue Sep 7 03:10:21 2021 - [info] Checking master_ip_failover_script status:
Tue Sep 7 03:10:21 2021 - [info] /usr/local/bin/master_ip_failover --command=status --ssh_user=root --orig_master_host=192.168.122.10 --orig_master_ip=192.168.122.10 --orig_master_port=3306
IN SCRIPT TEST====/sbin/ifconfig ens33:1 down==/sbin/ifconfig ens33:1 192.168.122.200===
Checking the Status of the script.. OK
Tue Sep 7 03:10:21 2021 - [info] OK.
Tue Sep 7 03:10:21 2021 - [warning] shutdown_script is not defined.
Tue Sep 7 03:10:21 2021 - [info] Got exit code 0 (Not master dead).
MySQL Replication Health is OK.
实验中出现报错,删除slave节点服务器中mysql主配置文件中的“default-character-set=utf8”后重启mysqld服务。
(12)在manager节点上启动MHA
MHA manager(192.168.122.100)
[root@manager scripts]# nohup masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/masterha/app1/manager.log 2>&1 &
[1] 9321
● --remove_dead_master_conf:该参数代表当发生主从切换后,老的主库的 ip 将会从配置文件中移除。
● --manager_log:日志存放位置。
● --ignore_last_failover:在缺省情况下,如果 MHA 检测到连续发生宕机,且两次宕机间隔不足 8 小时的话,则不会进行 Failover, 之所以这样限制是为了避免 ping-pong 效应。该参数代表忽略上次 MHA 触发切换产生的文件,默认情况下,MHA 发生切换后会在日志记目录,也就是上面设置的日志app1.failover.complete文件,下次再次切换的时候如果发现该目录下存在该文件将不允许触发切换,除非在第一次切换后收到删除该文件,为了方便,这里设置为--ignore_last_failover。
(13)查看MHA状态,可以看到当前的master是MySQL1节点
MHA manager(192.168.122.100)
[root@manager scripts]# masterha_check_status --conf=/etc/masterha/app1.cnf
app1 (pid:9321) is running(0:PING_OK), master:192.168.122.10
(14)查看MHA日志,也可以看到当前的master
MHA manager(192.168.122.100)
[root@manager scripts]# cat /var/log/masterha/app1/manager.log | grep "current master"
Tue Sep 7 03:22:07 2021 - [info] Checking SSH publickey authentication settings on the current master..
192.168.122.10(192.168.122.10:3306) (current master)
(15)查看MySQL1de VIP地址192.168.122.200是否存在,这个VIP地址不会因为manager节点停止MHA服务而消失
Master(192.168.122.10)
[root@mysql1 mha4mysql-node-0.57]# ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.122.10 netmask 255.255.255.0 broadcast 192.168.122.255
inet6 fe80::7350:3abe:ece6:290d prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:59:be:be txqueuelen 1000 (Ethernet)
RX packets 730534 bytes 1038497504 (990.3 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 346113 bytes 35339346 (33.7 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens33:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.122.200 netmask 255.255.255.0 broadcast 192.168.122.255
ether 00:0c:29:59:be:be txqueuelen 1000 (Ethernet)
(16)关闭manager服务
若要关闭 manager 服务,可以使用如下命令。
masterha_stop --conf=/etc/masterha/app1.cnf
[root@manager scripts]# masterha_stop --conf=/etc/masterha/app1.cnf
Stopped app1 successfully.
[1]+ 退出 1 nohup masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/masterha/app1/manager.log 2>&1
或者可以直接采用 kill 进程 ID 的方式关闭。
[root@manager scripts]# nohup masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/masterha/app1/manager.log 2>&1 &
##启动manager
[1] 10387
[root@manager scripts]# kill 10387
##杀死进程
[root@manager scripts]# masterha_check_status --conf=/etc/masterha/app1.cnf
##查看状态为已停止
app1 is stopped(2:NOT_RUNNING).
[1]+ 退出 1 nohup masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/masterha/app1/manager.log 2>&1
2. 故障模拟与修复
(1)故障模拟
①在manager节点上监控观察日志记录
MHA manager(192.168.122.100)
[root@manager scripts]# tail -f /var/log/masterha/app1/manager.log
IN SCRIPT TEST====/sbin/ifconfig ens33:1 down==/sbin/ifconfig ens33:1 192.168.122.200===
Checking the Status of the script.. OK
Tue Sep 7 03:39:32 2021 - [info] OK.
Tue Sep 7 03:39:32 2021 - [warning] shutdown_script is not defined.
Tue Sep 7 03:39:32 2021 - [info] Set master ping interval 1 seconds.
Tue Sep 7 03:39:32 2021 - [info] Set secondary check script: /usr/local/bin/masterha_secondary_check -s 192.168.122.11 -s 192.168.122.12
Tue Sep 7 03:39:32 2021 - [info] Starting ping health check on 192.168.122.10(192.168.122.10:3306)..
Tue Sep 7 03:39:32 2021 - [info] Ping(SELECT) succeeded, waiting until MySQL doesn't respond..
②在Master节点mysql1上停止mysql服务
Master(192.168.122.10)
[root@mysql1 mha4mysql-node-0.57]# systemctl stop mysqld
或
[root@mysql1 mha4mysql-node-0.57]# pkill -9 mysql
③MHA快速调整新Master为mysql2节点服务器
MHA manager(192.168.122.100)
Master 192.168.122.10(192.168.122.10:3306) is down!
Check MHA Manager logs at manager:/var/log/masterha/app1/manager.log for details.
Started automated(non-interactive) failover.
Invalidated master IP address on 192.168.122.10(192.168.122.10:3306)
The latest slave 192.168.122.11(192.168.122.11:3306) has all relay logs for recovery.
Selected 192.168.122.11(192.168.122.11:3306) as a new master.
192.168.122.11(192.168.122.11:3306): OK: Applying all logs succeeded.
192.168.122.11(192.168.122.11:3306): OK: Activated master IP address.
192.168.122.12(192.168.122.12:3306): This host has the latest relay log events.
Generating relay diff files from the latest slave succeeded.
192.168.122.12(192.168.122.12:3306): OK: Applying all logs succeeded. Slave started, replicating from 192.168.122.11(192.168.122.11:3306)
192.168.122.11(192.168.122.11:3306): Resetting slave info succeeded.
Master failover to 192.168.122.11(192.168.122.11:3306) completed successfully.
④查看manager的app1.cnf文件
MHA manager(192.168.122.100)
[root@manager scripts]# vim /etc/masterha/app1.cnf
[server default]
manager_log=/var/log/masterha/app1/manager.log
manager_workdir=/var/log/masterha/app1
master_binlog_dir=/usr/local/mysql/data
master_ip_failover_script=/usr/local/bin/master_ip_failover
master_ip_online_change_script=/usr/local/bin/master_ip_online_change
password=123456
ping_interval=1
remote_workdir=/tmp
repl_password=123456
repl_user=myslave
secondary_check_script=/usr/local/bin/masterha_secondary_check -s 192.168.122.11 -s 192.168.122.12
shutdown_script=""
ssh_user=root
user=mha
[server2]
candidate_master=1
check_repl_delay=0
hostname=192.168.122.11
port=3306
[server3]
hostname=192.168.122.12
port=3306
正常自动切换一次后,MHA 进程会退出。HMA 会自动修改 app1.cnf 文件内容,将宕机的 mysql1 节点删除。
⑤查看mysql2是否接管VIP
Slave1(192.168.122.11)
[root@mysql2 mha4mysql-node-0.57]# ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.122.11 netmask 255.255.255.0 broadcast 192.168.122.255
inet6 fe80::ed0e:8bf:3608:6ab9 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:94:63:f1 txqueuelen 1000 (Ethernet)
RX packets 172230 bytes 214197465 (204.2 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 80091 bytes 18553598 (17.6 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens33:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.122.200 netmask 255.255.255.0 broadcast 192.168.122.255
ether 00:0c:29:94:63:f1 txqueuelen 1000 (Ethernet)
称为新master后成功接管VIP
(2)故障切换备选主库的算法
- 一般判断从库的是从(position/GTID)判断优劣,数据有差异,最接近于master的slave,成为备选主。
- 数据一致的情况下,按照配置文件顺序,选择备选主库。
- 设定有权重(candidate_master=1),按照权重强制指定备选主。
● 默认情况下如果一个slave落后master 100M的relay logs的话,即使有权重,也会失效。
● 如果check_repl_delay=0的话,即使落后很多日志,也强制选择其为备选主。
(3)故障修复步骤
①修复mysql
Master(192.168.122.10)
[root@mysql1 mha4mysql-node-0.57]# systemctl restart mysqld
②修复主从
在现主库服务器mysql2查看二进制文件和同步点
Slave1(192.168.122.11)
[root@mysql2 mha4mysql-node-0.57]# mysql -uroot -p
Enter password:
mysql> show master status;
+-------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-------------------+----------+--------------+------------------+-------------------+
| master-bin.000003 | 154 | | | |
+-------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
在原主库服务器mysql1执行同步操作
Master(192.168.122.10)
[root@mysql1 mha4mysql-node-0.57]# mysql -u root -p
Enter password:
mysql> change master to
-> master_host='192.168.122.11',
-> master_user='myslave',
-> master_password='123456',
-> master_log_file='master-bin.000003',
-> master_log_pos=154;
Query OK, 0 rows affected, 2 warnings (0.02 sec)
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)
③在manager节点上修改配置文件app1.cnf
将mysql1的记录添加回去,因为测试故障时已被自动删除
MHA manager(192.168.122.100)
[root@manager scripts]# vim /etc/masterha/app1.cnf
......
secondary_check_script=/usr/local/bin/masterha_secondary_check -s 192.168.122.10 -s 192.168.122.12
......
##添加server1并写入mysql2的ip
[server1]
hostname=192.168.122.11
port=3306
##修改server2信息为mysql1的ip
[server2]
candidate_master=1
check_repl_delay=0
hostname=192.168.122.10
port=3306
[server3]
hostname=192.168.122.12
port=3306
④在manager节点上启动MHA
MHA manager(192.168.122.100)
[root@manager scripts]# nohup masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/masterha/app1/manager.log 2>&1 &
[1] 12884
[root@manager scripts]# masterha_check_status --conf=/etc/masterha/app1.cnf
app1 monitoring program is now on initialization phase(10:INITIALIZING_MONITOR). Wait for a while and try checking again.
[root@manager scripts]# masterha_check_status --conf=/etc/masterha/app1.cnf
app1 (pid:12884) is running(0:PING_OK), master:192.168.122.11
此时master仍是mysql2节点,如若需要让mysql1重新成为master,停止mysql2节点的mysql服务即可。
mysql1获得mater地位以及VIP后,重新启动mysql2的mysql服务,并添加进slave集群中。
MHA高可用配置及故障切换的更多相关文章
- MySQL MHA高可用集群部署及故障切换
一.MHA概念MHA(MasterHigh Availability)是一套优秀的MySQL高可用环境下故障切换和主从复制的软件.MHA 的出现就是解决MySQL 单点的问题.MySQL故障切换过程中 ...
- MySQL MHA 高可用集群部署及故障切换
MySQL MHA 高可用集群部署及故障切换 1.概念 2.搭建MySQL + MHA 1.概念: a)MHA概念 : MHA(MasterHigh Availability)是一套优秀的MySQL高 ...
- MHA高可用架构与Atlas读写分离
1.1 MHA简介 1.1.1 MHA软件介绍 MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton ...
- Mysql MHA高可用集群架构
** 记得之前发过一篇文章,名字叫<浅析MySQL高可用架构>,之后一直有很多小伙伴在公众号后台或其它渠道问我,何时有相关的深入配置管理文章出来,因此,民工哥,也将对前面的各类架构逐一进行 ...
- MySQL mha 高可用集群搭建
[mha] MHA作为MySQL故障切换和主从提升的高可用软件,在故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一 ...
- MHA 高可用集群搭建(二)
MHA 高可用集群搭建安装scp远程控制http://www.cnblogs.com/kevingrace/p/5662839.html yum install openssh-clients mys ...
- MHA高可用 MHA+Keepalive
MHA高可用 MHA简介 MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebo ...
- MySQL for OPS 08:MHA 高可用
写在前面的话 主从架构在一般情况下只能满足我们小公司业务并非一刻都不能中断服务.但是对于大型公司而言,对然数据丢失,数据库挂了,我们可以通过技术找回,修复.但是其中修复过程所消耗的时间是不被允许的.此 ...
- 搭建MySQL MHA高可用
本文内容参考:http://www.ttlsa.com/mysql/step-one-by-one-deploy-mysql-mha-cluster/ MySQL MHA 高可用集群 环境: Linu ...
随机推荐
- CF149D游戏
题目描述 Petya遇到了一个关于括号序列的问题: 给定一个字符串S,它代表着正确的括号序列,即("(")与 (")")是匹配的.例如:"(())() ...
- 安装uiautomator2 + python 自动化环境
搭建环境: 1.Python版本 37 2.已经搭建到adb (之前试过在python版本几,一直都装不上UIautomator2,报这个错) 安装步骤: 1.到python的安装路径 > 一直 ...
- 原生android webview 显示的H5页面颜色属性无法识别 - 具体解决心得
1.前言 background-color: #fc1717bf; 这个样式属性没毛病吧,浏览器都是支持的,但是在android 7.0 系统无法正确识别这个含有透明度的属性, 即bf无法识别,将默认 ...
- Go语言系列- http编程和mysql
http编程 一.Http协议 1. 什么是协议? 协议,是指通信的双方,在通信流程或内容格式上,共同遵守的标准. 2. 什么是http协议? http协议,是互联网中最常见的网络通信标准. 3 ...
- testng.xml 执行多个测试用例
1.在工程名字上点击右键,点击[New]-->[File] 2.在弹出的[New File]对话框中的[File name]输入[testng.xml],点击[Finish]即创建了一个test ...
- MySQL提权之udf提权(获得webshell的情况)
什么是udf提权? MySQL提供了一个让使用者自行添加新的函数的功能,这种用户自行扩展函数的功能就叫udf. 它的提权原理也非常简单!即是利用了root 高权限,创建带有调用cmd的函数的udf.d ...
- zip压缩,解压
//引用 System.IO.Compression.FileSystem.dll var basePath = AppDomain.CurrentDomain.BaseDirectory; Syst ...
- STC8H开发(六): SPI驱动ADXL345三轴加速度检测模块
目录 STC8H开发(一): 在Keil5中配置和使用FwLib_STC8封装库(图文详解) STC8H开发(二): 在Linux VSCode中配置和使用FwLib_STC8封装库(图文详解) ST ...
- 【get√】golang新手理解了一点点gin框架的中间件
1.通过use()来使用多个中间件 router := gin.New() router.Use( middleware1, middleware2) 2.中间件的典型实现 func Logger() ...
- Golang 通过创建临时结构体实现 struct 内 interface struct 的 json 反序列化
原文链接 背景 type AData struct { A string `json:"a"` } type BData struct { B string `json:" ...