『动善时』JMeter基础 — 34、JMeter接口关联【XPath提取器】
1、XPath提取器介绍
有些WEB项目是前后端不分离的,接口返回的内容不是Json格式的数据,而返回的是一个HTML页面。并且有些参数是隐藏在HTML页面里面的,需要从HTML页面中提取出这些隐藏参数,这个时候就会用到XPath提取器组件。
XPath提取器组件常用于接口返回值为HTML或XML格式数据的时候,进行数据的提取。
XPath提取器组件在后置处理器元件中,后置处理器主要的作用,在请求结束或者返回响应结果时发挥作用。
2、XPath提取器界面详解
添加XPath提取器组件操作:选中“取样器”右键 —> 添加 —> 后置处理器 —> XPath提取器。
界面如下图所示:
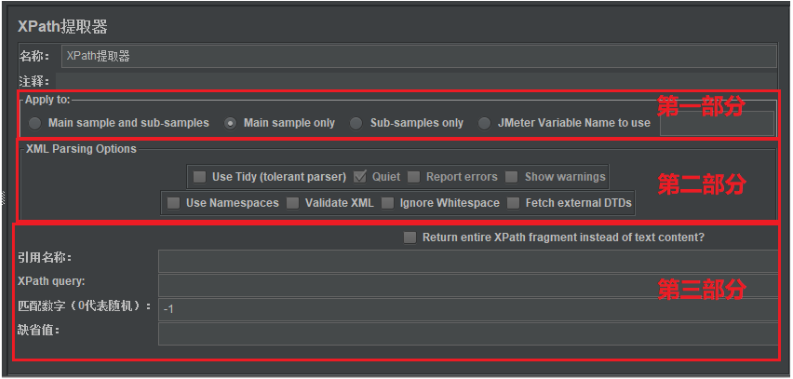
下面是XPath提取器组件的详细说明:
- 名称:XPath提取器组件的自定义名称,见名知意最好。
- 注释:即添加一些备注信息,对该XPath提取器组件的简短说明,以便后期回顾时查看。
(1)Apply to:作用范围(返回内容的取值范围)
Main sample and sub-samples:作用于父节点的取样器及对应子节点的取样器。Main sample only:仅作用于父节点的取样器。Sub-samples only:仅作用于子节点的取样器。JMeter Variable Name to use:作用于JMeter变量(输入框内可输入JMeter的变量名称),从指定变量中提取需要的值。
(2)XML Parsing Options:要解析的XML参数
Use Tidy (tolerant parser):当需要处理的页面是HTML格式时,必须选中该选项;如果是XML或XHTML格式,则取消选中。Quiet:表示只显示需要的HTML页面。Report errors:表示显示响应报错。Show warnings:表示显示警告。Use Namespaces:如果启用该选项,后续的XML解析器将使用命名空间来分辨。Validate XML:根据页面元素模式进行检查解析。Ignore Whitespace:忽略空白内容。Fetch external DTDs:如果选中该项,外部将使用DTD规则来获取页面内容。
(3)第三部分内容
Return entire XPath fragment of text content:表示是否返回文本内容的整个XPath片段。Reference Name:定义提取值的变量名称。XPath Query:用于提取值的XPath表达式。- 匹配数字(0代表随机):表示取值是第几个匹配结果,因为有可能XPath表达式会匹配到多个值。0表示随机,-1表示全部,1代表第一个,2代表第二个,以此类推。
Default Value:参数的默认值。也就是取不到值时的默认值。
总结XPath提取器组件:
对所有符合条件的取样器按顺序进行取样。
例如,如果有一个主取样器和三个子取样器,每个取样器都有一个符合条件的匹配结果(总共4个)。
当设置为
Sub-samples only时,匹配数字为3,则第三个子取样器的匹配结果返回;当匹配数字为0或者负数,所有的合格的取样器都将被处理,而当匹配数字>0,一旦找到足够的匹配,比对就停止下来。
3、XPath提取器的使用
需求:
- 访问网易官网,获取title值。
- 将title值放入百度搜索框,进行搜索。
(1)测试计划内包含的元件
添加元件操作步骤:
- 创建测试计划。
- 创建线程组:
选中“测试计划”右键 —> 添加 —> 线程(用户) —> 线程组。 - 在线程组下,添加取样器“HTTP请求”组件:
选中“线程组”右键 —> 添加 —> 取样器 —> HTTP请求。 - 在取样器下,添加后置处理器“XPath提取器”组件:
选中“取样器”右键 —> 添加 —> 后置处理器 —> XPath提取器。 - 在线程组下,添加监听器“察看结果树”组件:
选中“线程组”右键 —> 添加 —> 监听器 —> 察看结果树。
提示:需要重复添加的组件这里不重复描述。
最终测试计划中的元件如下:
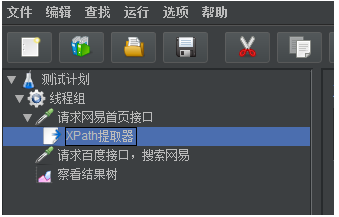
点击运行按钮,会提示你先保存该脚本,脚本保存完成后会直接自动运行该脚本。
提示:提取器一定要添加在你指定的某个请求下面,作为他的子请求,否则提取不到指定的数据!
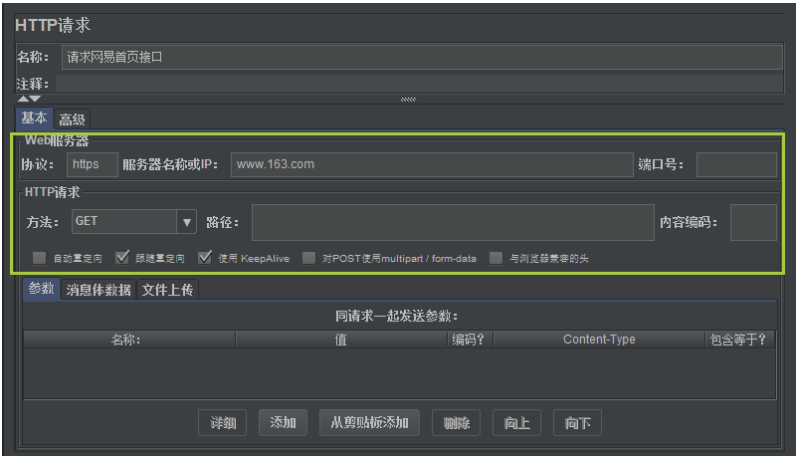
(2)网易首页请求界面内容
非常简单的Get请求,之前说了很多次了,这里就不做解释了。
界面内容如下图所示:
(3)XPath提取器界面内容
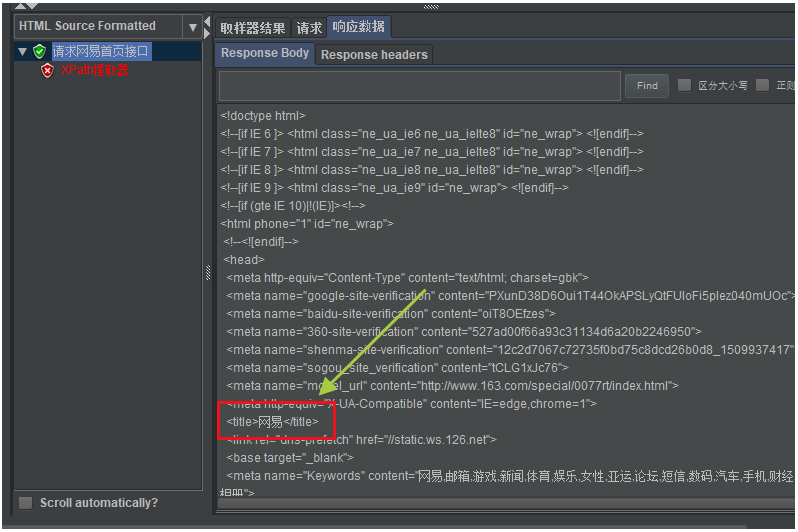
我们在编辑XPath提取器组件之前,一般先请求一下需要提取返回数据的接口。
因为我们需要先查看一下需要提取的数据在什么位置,如下图所示:
然后选择XPath Tester视图模式,先手动编写XPath表达式,看看是否能够取到需要的数据。
如下图所示:
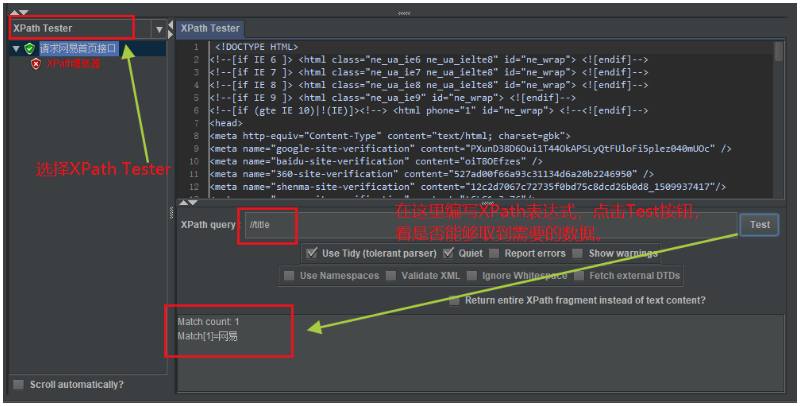
注意两点:
- 选择
XPath Tester模式进行XPath表达式的编写验证。 - 如果是在HTML页面源码中提取数据,
Use Tidy (tolerant parser)选择一定要勾选,否则会报错。
之后我们就可以编写XPath提取器组件界面了,如下:
编写引用名称、XPath表达式、匹配数据选择,还有Use Tidy选项一定要勾选,否则不能取到数据。
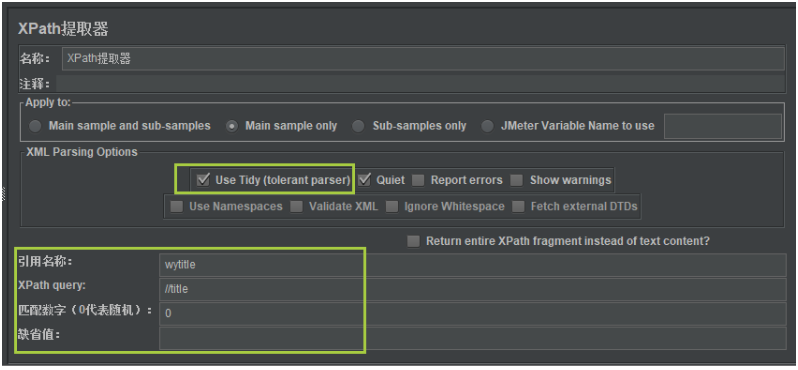
XPath提取器组件提取出来的数据,会存储在线程变量中,供其他后续接口使用。
关于XPath表示的写法,可以看Selenium相关的文章,里面有详细的写法。
(4)百度首页请求界面内容
填写接口的基本请求信息,然后把XPath提取器提取出来的数据,作为参数化变量应用到请求中。
如下图所示:
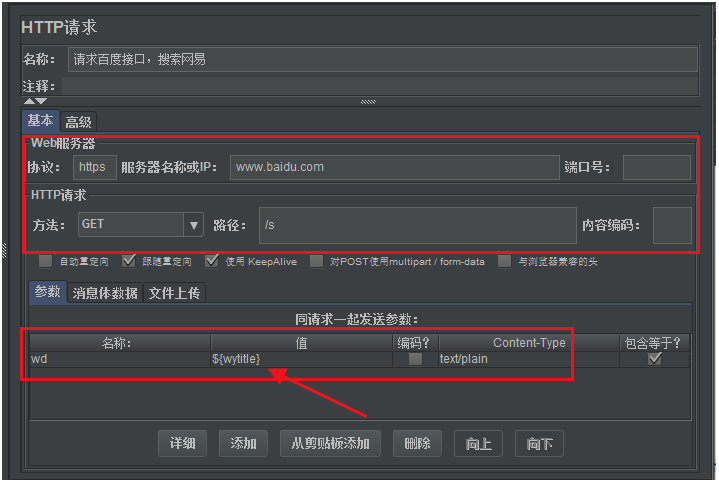
提示:如果此时直接执行该脚本,请求百度搜索网易的接口会执行,但是没有返回数据的,因为百度拒绝你的访问,我们需要设置请求头
User-Agent属性,来模拟是一个浏览器访问,如User-Agent=Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400,这样百度就不会拒绝访问了。
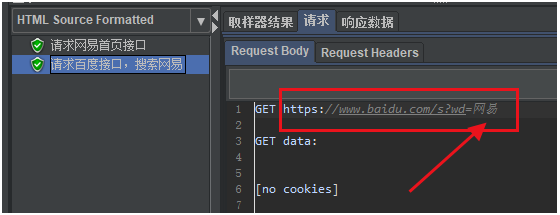
(5)查看结果
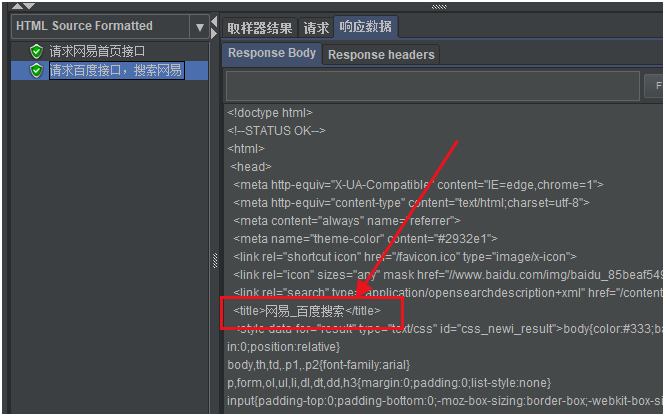
我们可以看到再第二个请求中,拿到了第一个请求提取出来的数据“网易”。
如下图所示:
再来看看第二个请求响应的结果,可以看到有网易_百度搜索的title属性,说明在百度已经进行了网易搜索。
如下图所示:
提示:可以添加
Debug PostProcessor(调试后置处理器),或者Debug Sampler(调试取样器),来查看Xpath提取器中,提取出的内容是否正确。注意:正常跑用例时删除或禁用它们。
4、总结
XPath提取器通常是从网页源文件中,提取数据时用的比较多。提取完参数后,相当于把参数以 key-value 的形式,存放到参数池中,以便后面的请求使用。
注意:不能超前引用。
『动善时』JMeter基础 — 34、JMeter接口关联【XPath提取器】的更多相关文章
- 『动善时』JMeter基础 — 33、JMeter察看结果树的显示模式详解
目录 1.CSS Selector Tester视图 2.HTML查看器 (1)HTML视图 (2)HTML(download resources)视图 (3)HTML Source Formatte ...
- 『动善时』JMeter基础 — 36、JMeter接口关联【正则表达式提取器】
目录 1.正则表达式提取器介绍 2.正则表达式提取器界面详解 3.正则表达式提取器的使用 (1)测试计划内包含的元件 (2)请求一界面内容 (3)正则表达式提取器界面内容 (4)请求二界面内容 (5) ...
- 『动善时』JMeter基础 — 6、使用JMeter发送一个最基础的请求
目录 步骤1:创建一个测试计划 步骤2:创建线程组 步骤3:创建取样器 步骤4:创建监听器 步骤5:完善信息 步骤6:保存测试计划 步骤7:查看结果 总结:JMeter测试计划要素 当我们第一次打开J ...
- 『动善时』JMeter基础 — 8、JMeter主要元件介绍
目录 1.测试计划(Test Plan) 2.线程组 3.取样器(sampler) 4.逻辑控制器(Logic Controller) 5.配置元件(Config Element) 6.定时器(Tim ...
- 『动善时』JMeter基础 — 37、将JMeter测试结果写入Excel
目录 1.环境准备 (1)引入操作Excel文件的基础JAR包 (2)引入封装自定义操作Excel文件的JAR包 2.准备测试需要的数据 3.测试结果写入Excel演示 (1)测试计划内包含的元件 ( ...
- 『动善时』JMeter基础 — 40、JMeter中ForEach控制器详解
目录 1.什么是逻辑控制器 2.ForEach控制器介绍 3.ForEach控制器的使用 (1)测试计划内包含的元件 (2)获取学院列表请求内容 (3)JSON提取器内容 (4)ForEach控制器内 ...
- 『动善时』JMeter基础 — 7、jmeter.properties文件常用配置
目录 1.默认语言设置 2.配置默认编码格式 3.GUI图标放大比例设置 4.功能区工具栏图标大小设置 5.视图区目录树图标大小设置 6.内容区编辑字体设置 7.添加JMeter元素快捷键设置 8.捕 ...
- 『动善时』JMeter基础 — 15、使用JMeter实现上传文件
目录 1.用于演示的项目说明 2.测试计划内包含的元件 3.HTTP请求界面内容 4.查看结果 5.总结 6.补充:MIME类型简介 (1)MIME说明 (2)常见类型 在上一篇文章[使用JMeter ...
- 『动善时』JMeter基础 — 29、JMeter响应断言详解
目录 1.JMeter断言介绍 2.响应断言组件界面详解 3.响应断言组件的使用 (1)测试计划内包含的元件 (2)登陆接口请求界面内容 (3)响应断言界面内容 (4)查看运行结果 (5)断言结果组件 ...
随机推荐
- matlab函数句柄
matlab函数句柄 直接调用函数: 被调用函数只能被其M文件同名的主函数或在M文件中的其他函数调用,一个文件只有一个主函数. 间接调用函数: 避免只能使用直接调用函数的情况,个人理解就是为一个函 ...
- 2021S软件工程——结对项目第一阶段
# 2021S软件工程--结对项目第一阶段 2021春季软件工程(罗杰 任健) 项目地址 1020 1169 --- ## 1 结对感受 总体来说,结对编程与之前的个人编程感觉有很大的不同.有如下几个 ...
- 模拟退火算法Python编程(2)约束条件的处理
1.最优化与线性规划 最优化问题的三要素是决策变量.目标函数和约束条件. 线性规划(Linear programming),是研究线性约束条件下线性目标函数的极值问题的优化方法,常用于解决利用现有的资 ...
- D - The Frog's Games (二分)
The annual Games in frogs' kingdom started again. The most famous game is the Ironfrog Triathlon. On ...
- POJ2349二分+并查集,类似最小树的贪心
题意: 给你n个点,你的任务是构建一颗通讯树,然后给你一个s表示可以选出来s个点两两通讯不花钱,就是费用是0,其他的费用就是两点的距离,有个要求就是其他的费用中最大的那个最小. 思路: ...
- Sqlmap的使用详解
目录 Sqlmap Sqlmap的简单用法 探测指定URL是否存在SQL注入漏洞 查看数据库的所有用户 查看数据库所有用户名的密码 查看数据库当前用户 判断当前用户是否有管理权限 列出数据库管理员角色 ...
- HackingLab基础关
目录 1:Key在哪里? 2:再加密一次你就得到key啦~ 3:猜猜这是经过了多少次加密? 4:据说MD5加密很安全,真的是么? 5:种族歧视 6:HAHA浏览器 7:key究竟在哪里呢? 8:key ...
- 【Unity】实验二 游戏场景搭建
实验要求 实验二 游戏场景搭建 实验目的:掌握游戏场景搭建. 实验要求:能够使用Unity的地形引擎创建地形,熟悉场景中的光照与阴影,掌握天空盒和雾化效果等. 实验内容: 地形的绘制:使用高度图绘制: ...
- JVM默认内存大小
堆(Heap)和非堆(Non-heap)内存 按照官方的说法:"Java虚拟机具有一个堆,堆是运行时数据区域,所有类实例和数组的内存均从此处分配.堆是在Java虚拟机启动时创建的." ...
- 10.qml-组件、Loader、Component介绍
1.组件介绍 一个组件通常由一个qml文件定义(单独文件定义组件), 实际也可以在qml里面通过Component对象来嵌入式定义组件 (4小节讲解). Component对象封装的内容默认不会显示, ...