SpringCloud-初见
项目地址:https://gitee.com/zwtgit/spring-cloud-study
前言
微服务架构4个核心问题?
- 服务很多,客户端该怎么访问?
- 这么多服务? 服务之间如何通信?
- 这么多服务? 如何治理?
- 服务挂了怎么办?
解决方案:
- Spring Cloud NetFlix 一站式解决方案!
api网关,zuu1组件
Feign ---HttpClinet ---- Http通信方式,同步,阻塞
服务注册发现: Eureka
熔断机制: Hystrix ………… - Apache Dubbo ZooKeeper 半自动,需要整合别人的东西
- Spring Cloud Alibaba 一站式解决方案!更简单
新概念:服务网格,Server Mesh
但是他们的共同点是解决这几个问题:
API网关,服务路由
HTTP,RPC框架,异步调用
服务注册与发现,高可用
熔断机制,服务降级
为什么有这几个问题,还是因为网络的不可靠,所以我们要研究解决他们的方案。
微服务概述
什么是微服务?
微服务(Microservice Architecture) 是近几年流行的一种架构思想,关于它的概念很难一言以蔽之。
究竟什么是微服务呢?我们在此引用ThoughtWorks 公司的首席科学家 Martin Fowler 于2014年提出的一段话:
原文:https://martinfowler.com/articles/microservices.html
汉化:https://www.cnblogs.com/liuning8023/p/4493156.html
- 就目前而言,对于微服务,业界并没有一个统一的,标准的定义。
- 但通常而言,微服务架构是一种架构模式,或者说是一种架构风格,它提倡将单一的应用程序划分成一组小的服务,每个服务运行在其独立的自己的进程内,服务之间互相协调,互相配置,为用户提供最终价值,服务之间采用轻量级的通信机制(HTTP)互相沟通,每个服务都围绕着具体的业务进行构建,并且能够被独立的部署到生产环境中,另外,应尽量避免统一的,集中式的服务管理机制,对具体的一个服务而言,应该根据业务上下文,选择合适的语言,工具(Maven)对其进行构建,可以有一个非常轻量级的集中式管理来协调这些服务,可以使用不同的语言来编写服务,也可以使用不同的数据存储。
再来从技术维度角度理解下:
微服务化的核心就是将传统的一站式应用,根据业务拆分成一个一个的服务,彻底地去耦合,每一个微服务提供单个业务功能的服务,一个服务做一件事情,从技术角度看就是一种小而独立的处理过程,类似进程的概念,能够自行单独启动或销毁,拥有自己独立的数据库。
微服务与微服务架构
微服务
强调的是服务的大小,它关注的是某一个点,是具体解决某一个问题/提供落地对应服务的一个服务应用,狭义的看,可以看作是IDEA中的一个个微服务工程,或者Moudel。 IDEA 工具里面使用Maven开发的一个个独立的小Moudel,它具体是使用SpringBoot开发的一个小模块,专业的事情交给专业的模块来做,一个模块就做着一件事情。 强调的是一个个的个体,每个个体完成一个具体的任务或者功能。
微服务架构
一种新的架构形式,Martin Fowler 于2014年提出。
微服务架构是一种架构模式,它体长将单一应用程序划分成一组小的服务,服务之间相互协调,互相配合,为用户提供最终价值。每个服务运行在其独立的进程中,服务与服务之间采用轻量级的通信机制(如HTTP)互相协作,每个服务都围绕着具体的业务进行构建,并且能够被独立的部署到生产环境中,另外,应尽量避免统一的,集中式的服务管理机制,对具体的一个服务而言,应根据业务上下文,选择合适的语言、工具(如Maven)对其进行构建。
微服务优缺点
优点
- 单一职责原则;
- 每个服务足够内聚,足够小,代码容易理解,这样能聚焦一个指定的业务功能或业务需求;
- 开发简单,开发效率高,一个服务可能就是专一的只干一件事;
- 微服务能够被小团队单独开发,这个团队只需2-5个开发人员组成;
- 微服务是松耦合的,是有功能意义的服务,无论是在开发阶段或部署阶段都是独立的;
- 微服务能使用不同的语言开发;
- 易于和第三方集成,微服务允许容易且灵活的方式集成自动部署,通过持续集成工具,如jenkins,Hudson,bamboo;
- 微服务易于被一个开发人员理解,修改和维护,这样小团队能够更关注自己的工作成果,无需通过合作才能体现价值;
- 微服务允许利用和融合最新技术;
- 微服务只是业务逻辑的代码,不会和HTML,CSS,或其他的界面混合;
- 每个微服务都有自己的存储能力,可以有自己的数据库,也可以有统一的数据库;
缺点
- 开发人员要处理分布式系统的复杂性;
- 多服务运维难度,随着服务的增加,运维的压力也在增大;
- 系统部署依赖问题;
- 服务间通信成本问题;
- 数据一致性问题;
- 系统集成测试问题;
- 性能和监控问题;
微服务技术栈
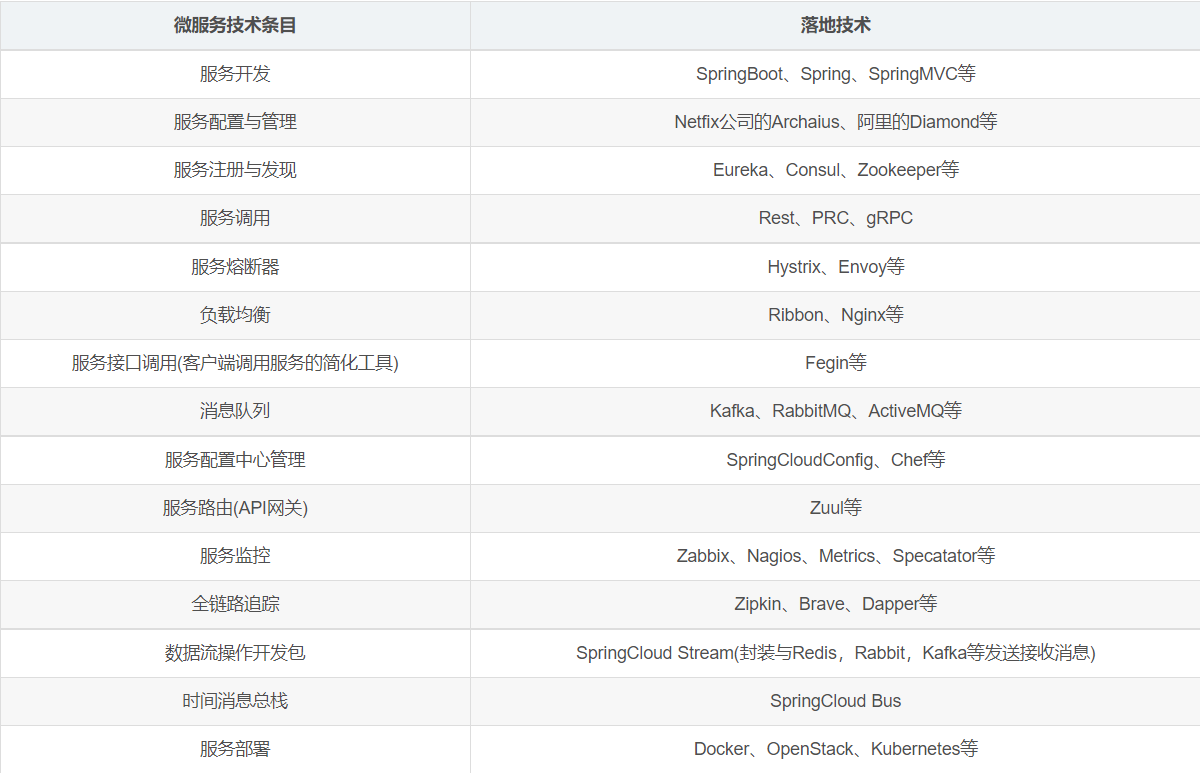
为什么选择SpringCloud作为微服务架构
选型依据
- 整体解决方案和框架成熟度
- 社区热度
- 可维护性
- 学习曲线
当前各大IT公司用的微服务架构有那些?
阿里:Dubbo+HFS
京东:JFS
新浪:Motan
当当网:DubboX
…
各微服务框架对比
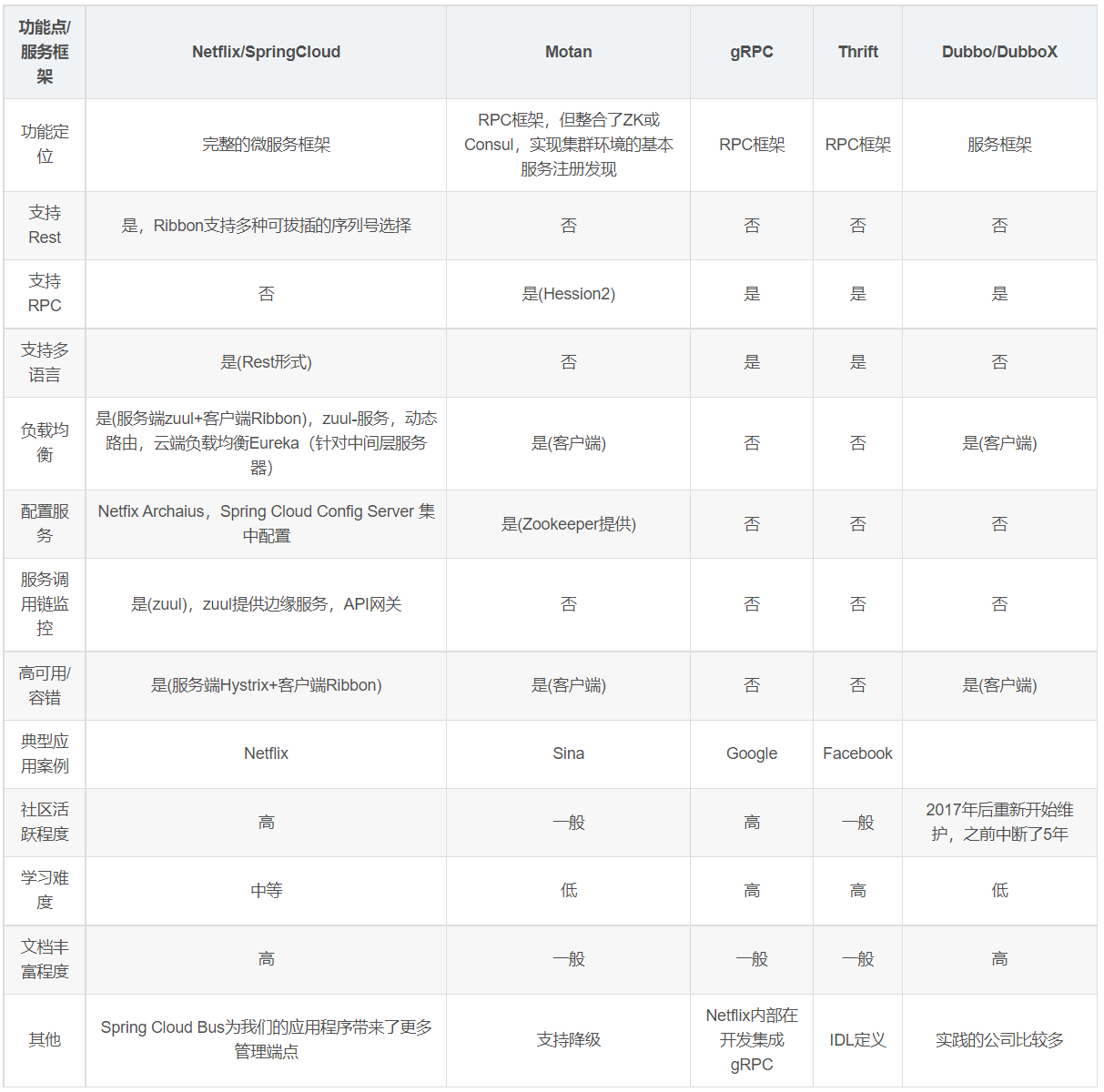
SpringCloud入门
Spring官网:https://spring.io/

SpringCloud,基于SpringBoot提供了一套微服务解决方案, 包括服务注册与发现,配置中心,全链路监控,服务网关,负载均衡,熔断器等组件,除了基于NetFlix的开源组件做高度抽象封装之外,还有一些选型中立的开源组件。
SpringCloud利用SpringBoot的开发便利性,巧妙地简化了分布式系统基础设施的开发, SpringCloud为开发人员提供了快速构建分布式系统的一些工具,包括配置管理,服务发现,断路器,路由,微代理,事件总线,全局锁,决策竞选,分布式会话等等,他们都可以用SpringBoot的开发风格做到一键启动和部署。
SpringBoot并没有重复造轮子,它只是将目前各家公司开发的比较成熟,经得起实际考验的服务框架组合起来,通过SpringBoot风格进行再封装,屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂,易部署和易维护的分布式系统开发工具包。
SpringCloud是分布式微服务架构下的一站式解决方案,是各个微服务架构落地技术的集合体,俗称微服务全家桶。
SpringCloud和SpringBoot的关系
- SpringBoot专注于开发方便的开发单个个体微服务;
- SpringCloud是关注全局的微服务协调整理治理框架,它将SpringBoot开发的一个个单体微服务,整合并管理起来,为各个微服务之间提供:配置管理、服务发现、断路器、路由、为代理、事件总栈、全局锁、决策竞选、分布式会话等等集成服务;
- SpringBoot可以离开SpringCloud独立使用,开发项目,但SpringCloud离不开SpringBoot,属于依赖关系;
- SpringBoot专注于快速、方便的开发单个个体微服务,SpringCloud关注全局的服务治理框架;
Dubbo 和 SpringCloud技术选型
- 分布式+服务治理Dubbo
目前成熟的互联网架构,应用服务化拆分+消息中间件
- Dubbo 和 SpringCloud对比
可以看一下社区活跃度:
https://github.com/spring-cloud
设计模式+微服务拆分
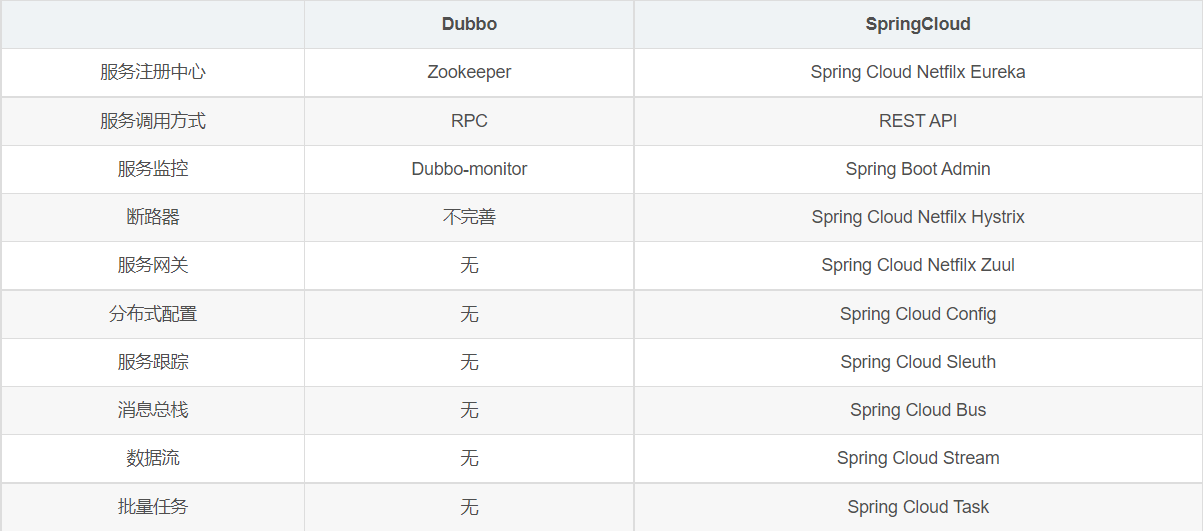
最大区别:Spring Cloud 抛弃了Dubbo的RPC通信,采用的是基于HTTP的REST方式
严格来说,这两种方式各有优劣。虽然从一定程度上来说,后者牺牲了服务调用的性能,但也避免了上面提到的原生RPC带来的问题。而且REST相比RPC更为灵活,服务提供方和调用方的依赖只依靠一纸契约,不存在代码级别的强依赖,这个优点在当下强调快速演化的微服务环境下,显得更加合适。
总结:
二者解决的问题域不一样:Dubbo的定位是一款RPC框架,而SpringCloud的目标是微服务架构下的一站式解决方案。
SpringCloud能干嘛?
- Distributed/versioned configuration 分布式/版本控制配置
- Service registration and discovery 服务注册与发现
- Routing 路由
- Service-to-service calls 服务到服务的调用
- Load balancing 负载均衡配置
- Circuit Breakers 断路器
- Distributed messaging 分布式消息管理
- …
SpringCloud下载
官网:http://projects.spring.io/spring-cloud/
SpringCloud没有采用数字编号的方式命名版本号,而是采用了伦敦地铁站的名称,同时根据字母表的顺序来对应版本时间顺序,比如最早的Realse版本:Angel,第二个Realse版本:Brixton,然后是Camden、Dalston、Edgware,目前最新的是Hoxton SR4 CURRENT GA通用稳定版。
学习资料:
SpringCloud Netflix 中文文档:https://springcloud.cc/spring-cloud-netflix.html
SpringCloud 中文API文档(官方文档翻译版):https://springcloud.cc/spring-cloud-dalston.html
SpringCloud中国社区:http://springcloud.cn/
SpringCloud中文网:https://springcloud.cc
Rest学习环境搭建
首先导入我们需要的依赖
<!--打包方式-->
<packaging>pom</packaging>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<junit.version>4.12</junit.version>
<log4j.version>1.2.17</log4j.version>
<lombok.version>1.16.18</lombok.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>0.2.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--springCloud的依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Greenwich.SR1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--SpringBoot-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>2.1.4.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--数据库-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.10</version>
</dependency>
<!--SpringBoot 启动器-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.3.2</version>
</dependency>
<!--日志测试~-->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
API模块
新建数据库,Navicat中的springcloudstudy01,后面有多个数据库,因为是一个分布式的项目。

然后编写实体类,注意要序列化,ORM类表关系映射。
package com.zwt.springcloud.pojo;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.experimental.Accessors;
import java.io.Serializable;
@Data
@NoArgsConstructor
@Accessors(chain = true) //链式写法
/*
Dept dept = new Dept()
dept.setDeptNo(11).setDname(''lijiatu).set…………
*/
public class Dept implements Serializable {
private Long deptno;
private String dname;
private String db_source;
public Dept(String dname) {
this.dname = dname;
}
}
这时候一个微服务就已经写好了。
Provider-8001模块
<!--因为要拿到实体类,所以要配置API模块-->
<dependencies>
<dependency>
<groupId>groupId</groupId>
<artifactId>API</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
</dependency>
<!--test-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-test</artifactId>
<version>2.1.4.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.1.4.RELEASE</version>
</dependency>
<!--jetty-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jetty</artifactId>
<version>2.1.4.RELEASE</version>
</dependency>
<!--热部署-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<version>2.5.2</version>
</dependency>
</dependencies>
mybatis-config.xml里面编写配置
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
</configuration>
dao层(或者叫mapper层)写接口,再在mapper文件夹中编写sql
package com.zwt.springcloud.dao;
import com.zwt.springcloud.pojo.Dept;
import org.apache.ibatis.annotations.Mapper;
import org.springframework.stereotype.Repository;
import java.util.List;
@Mapper
@Repository
public interface DeptDao {
public boolean addDept(Dept dept);
public Dept queryDept(Long id);
public List<Dept> queryAll();
}
mapper层
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.zwt.springcloud.dao">
<insert id="addDept" parameterType="Dept">
insert into dept (dname, db_source)
values (#{dname}, DATABASE())
</insert>
<select id="queryById" resultType="Dept" parameterType="Long">
select *
from dept
where deptno = #{deptno};
</select>
<select id="queryAll" resultType="Dept" parameterType="Long">
select *
from dept;
</select>
</mapper>
service层
package com.zwt.springcloud.service;
import com.zwt.springcloud.pojo.Dept;
import java.util.List;
public interface DeptService {
public boolean addDept(Dept dept);
public Dept queryById(Long id);
public List<Dept> queryAll();
}
//实现类
package com.zwt.springcloud.service;
import com.zwt.springcloud.dao.DeptDao;
import com.zwt.springcloud.pojo.Dept;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class DeptServiceImpl implements DeptService{
@Autowired
private DeptDao deptDao;
@Override
public boolean addDept(Dept dept) {
return deptDao.addDept(dept);
}
@Override
public Dept queryById(Long id) {
return deptDao.queryById(id);
}
@Override
public List<Dept> queryAll() {
return deptDao.queryAll();
}
}
controller层
package com.zwt.springcloud.controller;
import com.zwt.springcloud.pojo.Dept;
import com.zwt.springcloud.service.DeptService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
//提供Restful服务
@RestController
public class DeptController {
@Autowired
private DeptService deptService;
@PostMapping("/dept/add")
public boolean addDept(Dept dept) {
return deptService.addDept(dept);
}
@GetMapping("/dept/get/{id}")
public Dept queryById(@PathVariable("id") Long id) {
return deptService.queryById(id);
}
@PostMapping("/dept/list")
public List<Dept> queryAll() {
return deptService.queryAll();
}
}
启动类
package com.zwt.springcloud;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
//启动类
@SpringBootApplication
public class DeptProvider_8001 {
public static void main(String[] args) {
SpringApplication.run(DeptProvider_8001.class, args);
}
}
启动后发现上面代码中的 devtools版本不兼容,注释即可。
启动项目后报错,Invalid bound statement (not found),后发现是DeptMapper.xml中
<mapper namespace="com.zwt.springcloud.dao.DeptDao">
写成了
<mapper namespace="com.zwt.springcloud.dao">
导致没有对应到相应的文件,所以编写代码的时候要细心,bug也不可避免,检查要有条理,不着急。
consumer-80模块
添加依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>spring-cloud-study</artifactId>
<groupId>groupId</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>consumer-80</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<!--实体类+web-->
<dependencies>
<dependency>
<groupId>groupId</groupId>
<artifactId>API</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
</project>
application.yml
server:
port: 80
controller
package com.zwt.spingcloud.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.client.RestTemplate;
/**
* @author ML李嘉图
* @version createtime: 2021-10-25
* Blog: https://www.cnblogs.com/zwtblog/
*/
@Configuration
public class ConfigBean {
// @Configuration----spring applicationContext.xml
@Bean
public RestTemplate getRestTemplate() {
return new RestTemplate();
}
}
package com.zwt.spingcloud.controller;
import com.zwt.springcloud.pojo.Dept;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.client.RestTemplate;
import java.util.List;
/**
* @author ML李嘉图
* @version createtime: 2021-10-25
* Blog: https://www.cnblogs.com/zwtblog/
*/
public class DeptConsumerController {
// 理解,消费者不应该有service层
// RestTemplate 供我们直接调用,注册到spring中
@Autowired
private RestTemplate restTemplate;
private static final String REST_URL_PREFIX = "http://localhost:8001";
@RequestMapping("/consumer/dept/add")
public boolean add(Dept dept) {
return restTemplate.postForObject(REST_URL_PREFIX + "/dept/add", dept, boolean.class);
}
@RequestMapping("/consumer/dept/get/{id}")
public Dept get(@PathVariable("id") Long id) {
return restTemplate.getForObject(REST_URL_PREFIX + "/dept/get" + id, Dept.class);
}
@RequestMapping("/consumer/dept/list")
public List<Dept> list() {
return restTemplate.getForObject(REST_URL_PREFIX + "/dept/list", List.class);
}
}
然后编写启动类,先启动provider载启动consumer。
Eureka
什么是Eureka?
- Netflix在涉及Eureka时,遵循的就是API原则。
- Eureka是Netflix的有个子模块,也是核心模块之一。Eureka是基于REST的服务,用于定位服务,以实现云端中间件层服务发现和故障转移,服务注册与发现对于微服务来说是非常重要的,有了服务注册与发现,只需要使用服务的标识符,就可以访问到服务,而不需要修改服务调用的配置文件了,功能类似于Dubbo的注册中心,比如Zookeeper。
原理理解
Eureka基本的架构
- SpringCloud 封装了Netflix公司开发的Eureka模块来实现服务注册与发现 (对比Zookeeper)。
- Eureka采用了C-S的架构设计,EurekaServer作为服务注册功能的服务器,他是服务注册中心。
- 而系统中的其他微服务,使用Eureka的客户端连接到EurekaServer并维持心跳连接。这样系统的维护人员就可以通过EurekaServer来监控系统中各个微服务是否正常运行,SpringCloud 的一些其他模块 (比如Zuul) 就可以通过EurekaServer来发现系统中的其他微服务,并执行相关的逻辑。
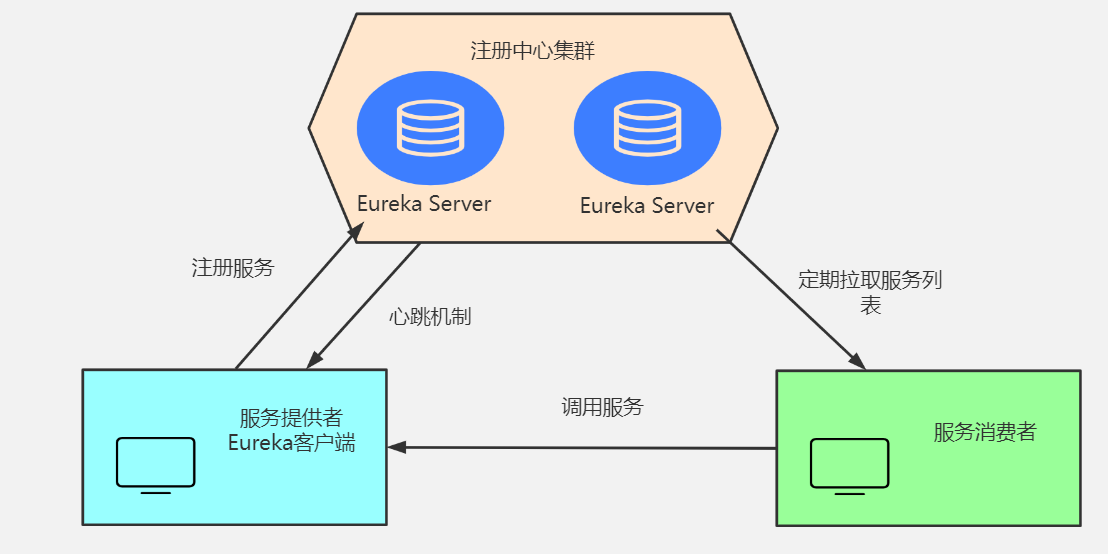
Eureka 包含两个组件:Eureka Server 和 Eureka Client。
Eureka Server 提供服务注册,各个节点启动后,回在EurekaServer中进行注册,这样Eureka Server中的服务注册表中将会储存所有课用服务节点的信息,服务节点的信息可以在界面中直观的看到。
Eureka Client 是一个Java客户端,用于简化EurekaServer的交互,客户端同时也具备一个内置的,使用轮询负载算法的负载均衡器。在应用启动后,将会向EurekaServer发送心跳 (默认周期为30秒) 。如果Eureka Server在多个心跳周期内没有接收到某个节点的心跳,EurekaServer将会从服务注册表中把这个服务节点移除掉 (默认周期为90s)。
三大角色
- Eureka Server:提供服务的注册与发现
- Service Provider:服务生产方,将自身服务注册到Eureka中,从而使服务消费方能狗找到
- Service Consumer:服务消费方,从Eureka中获取注册服务列表,从而找到消费服务
构建步骤
1. 导入依赖
2. 编写配置文件
3. 开启这个功能 @EnableXXX
4. 配置类
导入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka-server</artifactId>
<version>1.4.6.RELEASE</version>
</dependency>
编写配置文件
server:
port: 7001
eureka:
instance:
hostname: localhost
client:
register-with-eureka: false
fetch-registry: false
service-url:
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
开启这个功能 @EnableXXX
package com.zwt.springcloud;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
/**
* @author ML李嘉图
* @version createtime: 2021-10-25
* Blog: https://www.cnblogs.com/zwtblog/
*/
@SpringBootApplication
@EnableEurekaServer
public class EurekaServer_7001 {
public static void main(String[] args) {
SpringApplication.run(EurekaServer_7001.class, args);
}
}
Eureka服务注册
要注册服务,所以在Provider-8001中添加Eureka的依赖并且编写相应的配置。
eureka:
client:
service-url:
defaultZone: http://localhost:7001/eureka/
info:
app.name: zwt
blog.name: https://www.cnblogs.com/zwtblog/
@EnableEurekaServer一下
Eureka自我保护机制
一句话总结就是:某时刻某一个微服务不可用,Eureka不会立即清理,依旧会对该微服务的信息进行保存!
- 默认情况下,当eureka server在一定时间内没有收到实例的心跳,便会把该实例从注册表中删除(默认是90秒),但是,如果短时间内丢失大量的实例心跳,便会触发eureka server的自我保护机制,比如在开发测试时,需要频繁地重启微服务实例,但是我们很少会把eureka server一起重启(因为在开发过程中不会修改eureka注册中心),当一分钟内收到的心跳数大量减少时,会触发该保护机制。可以在eureka管理界面看到Renews threshold和Renews(last min),当后者(最后一分钟收到的心跳数)小于前者(心跳阈值)的时候,触发保护机制,会出现红色的警告:EMERGENCY!EUREKA MAY BE INCORRECTLY CLAIMING INSTANCES ARE UP WHEN THEY’RE NOT.RENEWALS ARE LESSER THAN THRESHOLD AND HENCE THE INSTANCES ARE NOT BEGING EXPIRED JUST TO BE SAFE. 从警告中可以看到,eureka认为虽然收不到实例的心跳,但它认为实例还是健康的,eureka会保护这些实例,不会把它们从注册表中删掉。
- 该保护机制的目的是避免网络连接故障,在发生网络故障时,微服务和注册中心之间无法正常通信,但服务本身是健康的,不应该注销该服务,如果eureka因网络故障而把微服务误删了,那即使网络恢复了,该微服务也不会重新注册到eureka server了,因为只有在微服务启动的时候才会发起注册请求,后面只会发送心跳和服务列表请求,这样的话,该实例虽然是运行着,但永远不会被其它服务所感知。所以,eureka server在短时间内丢失过多的客户端心跳时,会进入自我保护模式,该模式下,eureka会保护注册表中的信息,不在注销任何微服务,当网络故障恢复后,eureka会自动退出保护模式。自我保护模式可以让集群更加健壮。
- 但是我们在开发测试阶段,需要频繁地重启发布,如果触发了保护机制,则旧的服务实例没有被删除,这时请求有可能跑到旧的实例中,而该实例已经关闭了,这就导致请求错误,影响开发测试。所以,在开发测试阶段,我们可以把自我保护模式关闭,只需在eureka server配置文件中加上如下配置即可:eureka.server.enable-self-preservation=false
DeptController.java新增方法, //获取一些配置的信息,得到具体的微服务!
//获取一些配置的信息,得到具体的微服务!
@Autowired
private DiscoveryClient client;
//注册进来的微服务~,获取一些消息~
@GetMapping("/dept/discovery")
public Object discovery() {
//获取微服务列表的清单
List<String> services = client.getServices();
System.out.println("discovery=>services:" + services);
//得到一个具体的微服务信息,通过具体的微服务id,applicaioinName;
List<ServiceInstance> instances = client.getInstances("SPRINGCLOUD-PROVIDER-DEPT");
for (ServiceInstance instance : instances) {
System.out.println(
instance.getHost() + "\t" + // 主机名称
instance.getPort() + "\t" + // 端口号
instance.getUri() + "\t" + // uri
instance.getServiceId() // 服务id
);
}
return this.client;
}
Eureka集群配置
简单复制一下
但是这三个现在还没有关系,所以我们配置他们之间的关系。
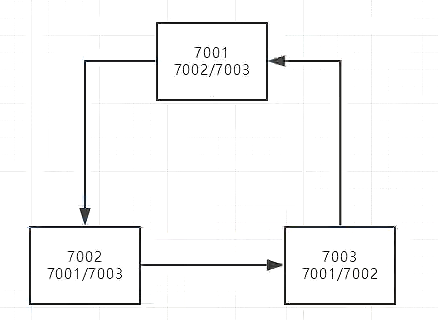
改一下host之后这三个的配置文件是:

server:
port: 7001
eureka:
instance:
hostname: eureka7001.com
client:
register-with-eureka: false
fetch-registry: false
service-url:
# defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
defaultZone: http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/
server:
port: 7002
eureka:
instance:
hostname: eureka7002.com
client:
register-with-eureka: false
fetch-registry: false
service-url:
defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7003.com:7003/eureka/
server:
port: 7003
eureka:
instance:
hostname: eureka7003.com
client:
register-with-eureka: false
fetch-registry: false
service-url:
defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/
然后把发布服务中的配置也修改一下,启动三个注册中心,再启动服务。
eureka:
client:
service-url:
defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/
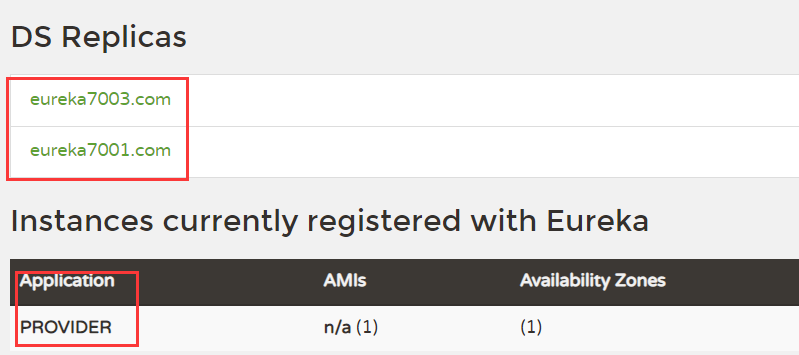
EurekaCAP原则和对比Zookeeper
CAP原则又称CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。
一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,根据CAP原理,将NoSQL数据库分成了满足CA原则,满足CP原则和满足AP原则三大类:
- CA:单点集群,满足一致性,可用性的系统,通常可扩展性较差
- CP:满足一致性,分区容错的系统,通常性能不是特别高
- AP:满足可用性,分区容错的系统,通常可能对一致性要求低一些
Zookeeper保证的是CP
当向注册中心查询服务列表时,我们可以容忍注册中心返回的是几分钟以前的注册信息,但不能接收服务直接down掉不可用。也就是说,服务注册功能对可用性的要求要高于一致性。但zookeeper会出现这样一种情况,当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。问题在于,选举leader的时间太长,30-120s,且选举期间整个zookeeper集群是不可用的,这就导致在选举期间注册服务瘫痪。在云部署的环境下,因为网络问题使得zookeeper集群失去master节点是较大概率发生的事件,虽然服务最终能够恢复,但是,漫长的选举时间导致注册长期不可用,是不可容忍的。
Eureka保证的是AP
Eureka看明白了这一点,因此在设计时就优先保证可用性。Eureka各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。而Eureka的客户端在向某个Eureka注册时,如果发现连接失败,则会自动切换至其他节点,只要有一台Eureka还在,就能保住注册服务的可用性,只不过查到的信息可能不是最新的,除此之外,Eureka还有之中自我保护机制,如果在15分钟内超过85%的节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,此时会出现以下几种情况:
- Eureka不在从注册列表中移除因为长时间没收到心跳而应该过期的服务
- Eureka仍然能够接受新服务的注册和查询请求,但是不会被同步到其他节点上 (即保证当前节点依然可用)
- 当网络稳定时,当前实例新的注册信息会被同步到其他节点中
因此,Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像zookeeper那样使整个注册服务瘫痪。
SpringCloud-初见的更多相关文章
- 【微框架】之一:从零开始,轻松搞定SpringCloud微框架系列--开山篇(spring boot 小demo)
Spring顶级框架有众多,那么接下的篇幅,我将重点讲解SpringCloud微框架的实现 Spring 顶级项目,包含众多,我们重点学习一下,SpringCloud项目以及SpringBoot项目 ...
- MongoDB 初见指南
技术若只如初见,那么还会踩坑么? 在系统引入 MongoDB 也有几年了,一开始是因为 MySQL 中有单表记录增长太快(每天几千万条吧)容易拖慢 MySQL 的主从复制.而这类数据增长迅速的流水表, ...
- springcloud(第三篇)springcloud eureka 服务注册与发现 *****
http://blog.csdn.net/liaokailin/article/details/51314001 ******************************************* ...
- SpringCloud Sleuth 使用
1. 介绍 Spring-Cloud-Sleuth是Spring Cloud的组成部分之一,为SpringCloud应用实现了一种分布式追踪解决方案,其兼容了Zipkin, HTrace和log- ...
- SpringCloud+Consul 服务注册与服务发现
SpringCloud+Consul 服务注册与服务发现 1. 服务注册: 在Spring.factories有一段: # Discovery Client Configuration org.spr ...
- 《微信小程序七日谈》- 第一天:人生若只如初见
<微信小程序七日谈>系列文章: 第一天:人生若只如初见: 第二天:你可能要抛弃原来的响应式开发思维: 第三天:玩转Page组件的生命周期: 第四天:页面路径最多五层?导航可以这么玩 微信小 ...
- SpringCloud学习后获取的地址
关于SpringCloud + Docker 学习地址: (1) https://yq.aliyun.com/articles/57265 (2) https://yq.aliyun.com/team ...
- (翻译)异步编程之Promise(1):初见魅力
原文:https://www.promisejs.org/ by Forbes Lindesay 异步编程系列教程: (翻译)异步编程之Promise(1)--初见魅力 异步编程之Promise(2) ...
- 【Linux探索之旅】第一部分第五课:Unity桌面,人生若只如初见
内容简介 1.第一部分第五课:Unity桌面,人生若只如初见 2.第一部分第六课预告:Linux如何安装在虚拟机中 Unity桌面,人生若只如初见 不容易啊,经过了前几课的学习,我们认识了Linux是 ...
- SpringCloud网关ZUUL集成consul
最近一直在搞基于springcloud的微服务开发,为了不限定微服务开发语言,服务发现决定采用consul不多说上代码 pom文件 <project xmlns="http://mav ...
随机推荐
- Salesforce LWC学习(三十六) Quick Action 支持选择 LWC了
本篇参考: https://developer.salesforce.com/docs/component-library/documentation/en/lwc/lwc.use_quick_act ...
- 性能测试工具JMeter 基础(九)—— 测试元件: 逻辑控制器之交替控制器
交替控制器:根据被控制器触发执行次数,去依次执行控制器下的子节点(逻辑控制器.采样器),可以由线程组的线程数.循环次数.逻辑控制器触发. 交替控制器(lnterleave Controller) 简单 ...
- adb - Performing Push Install adb: error: failed to get feature set: more than one 解决方案
问题背景 直接 adb install 包名 无法安装成功 解决方案 安装 adb -s 10.200.241.215:5555 install test.apk 删除 adb -s 10.200. ...
- shell脚本中的多行注释
shell 中注释的使用方法 1. 单行注释 单行注释最为常见,它是通过一个'#'来实现的.注意shell脚本的最开始部分"#!/bin/bash"的#号不是用来注释的. 2. 多 ...
- Python中正则表达式简介
目录 一.什么是正则表达式 二.正则表达式的基础知识 1. 原子 1)普通字符作为原子 2)非打印字符作为原子 3) 通用字符作为原子 4) 原子表 2. 元字符 1)任意匹配元字符 2)边界限制元字 ...
- PyRevit开发第一步:获取Revit文档Document
1.安装PythonShell插件 PythonShell 2018 插件下载 交流QQ群: 17075104 新建项目后,运行功能Python Shell, 在弹出的窗口中复制或输入以下引用代码模块 ...
- jdbc核心技术-宋红康
视频地址 JDBC核心技术 第1章:JDBC概述 1.1 数据的持久化 持久化(persistence):把数据保存到可掉电式存储设备中以供之后使用.大多数情况下,特别是企业级应用,数据持久化意味着将 ...
- 缩减Centos7xfs磁盘空间
问题描述:df -h查看 root目录仅有20G空间,其余300G空间全在home目录下.xfs不可以直接缩减,所以只能删除xfs盘然后重新添加. 解决办法: 1. 注释想要删除的磁盘,此处以cent ...
- SQL注入与burPsuit工具介绍
sql注入原理 原理:用户输入不可控,用户输入导致了sql语义发生了改变 用户输入不可控:网站不能控制普通用户的输入 sql语义发生变化: 动态网页介绍: 网站数据请求 脚本语言:解释类语言,如,后端 ...
- python matplotlib.pyplot 散点图详解(2)
python matplotlib.pyplot 散点图详解(2) 上期资料 一.散点图叠加 可以用多个scatter函数叠加散点图 代码如下: import matplotlib.pyplot as ...