认识Influxdb时序数据库及Influxdb基础命令操作
认识Influxdb时序数据库及Influxdb基础命令操作
一、什么是Influxdb,什么又是时序数据库
- Influxdb是一个用于存储时间序列,事件和指标的开源数据库,由Go语言编写而成,无需外部依赖。
- 什么是时间序列数据库?就是基于时间存储的数据,数据格式里包含Timestamp字段的数据,即每一条数据中都会有一个时间存储字段。
二、Influxdb能用来做什么
Influxdb(时序数据库)主要的应用场景有以下几种:
- 很多物联网数据都通过InfluxDB存储,分析与展示。如:智慧物联网监控分析系统,传统石油化工、采矿以及制造企业设备数据采集与分析,医疗数据采集与分析,车联网,智慧交通等。
- InfluxDB同时还应用于日志存储、监控数据统计和分析。如:各种服务、软件以及系统监控数据采集、分析与报警,金融数据采集与分析等。记录每毫秒服务器以及软件服务的使用情况,用于后期大数据分析,机器学习,实现预测、预警、服务提升优化等。
- 实时大数据量的存储以及快速查询,定时归集指定时间的数据,用于更大时间范围监控数据的展现。
Influxdb的特性:
- 时间序列数据编写的自定义高性能数据存储。TSM引擎允许高摄取速度和数据压缩。
- 内置HTTP接口,使用方便,简单,高性能的写入和查询HTTP API
- 数据可以打标记,标签允许对系列进行索引以实现快速有效的查询
- 类SQL的查询语句,可轻松查询聚合数据
- 安装管理很简单,并且读写数据很高效
- 能够实时查询,数据在写入时被索引后就能够被立即查出
- 完全用 Go 语言编写。 它编译成单个二进制文件,没有外部依赖项
三、Influxdb与Mysql的基本概念对比
| 概念 | InfluxDB | MySQL |
| 数据库(同) | database | database |
| 表(不同) | table | measurement |
| 列(不同 ) | column | tag (带索引的,非必须)、field(不带索引)、timestemp(唯一主键) |
四、Influxdb有哪些组成结构
- database: 数据库名,在 InfluxDB 中可以创建多个数据库,不同数据库中的数据文件是隔离存放的,存放在磁盘上的不同目录。
- retention policy: 存储策略,用于设置数据保留的时间,每个数据库刚开始会自动创建一个默认的存储策略 autogen,数据保留时间为永久,之后用户可以自己设置,例如保留最近2小时的数据。插入和查询数据时如果不指定存储策略,则使用默认存储策略,且默认存储策略可以修改。InfluxDB 会定期清除过期的数据。
- measurement: 测量指标名,例如 cpu_usage 表示 cpu 的使用率。
- tag sets: tags 在 InfluxDB 中会按照字典序排序,不管是 tagk 还是 tagv,只要不一致就分别属于两个 key,例如 host=server01,region=us-west 和 host=server02,region=us-west 就是两个不同的 tag set。
- field name: 例如上面数据中的 value 就是 fieldName,InfluxDB 中支持一条数据中插入多个 fieldName,这其实是一个语法上的优化,在实际的底层存储中,是当作多条数据来存储。
- timestamp: 每一条数据都需要指定一个时间戳,在 TSM 存储引擎中会特殊对待,以为了优化后续的查询操作。
说明:
- Point:Point由时间戳(time)、数据(field)、标签(tags)组成。相当于传统数据库里的一行数据;
- tag set:不同的每组tag key和tag value的集合;
- field set:每组field key和field value的集合,列不需要手动创建,加入数据会自动创建;
- Series 相当于是 InfluxDB 中一些数据的集合,在同一个 database 中,retention policy、measurement、tag sets 完全相同的数据同属于一个 series,同一个 series 的数据在物理上会按照时间顺序排列存储在一起;
- Shard 在 InfluxDB 中是一个比较重要的概念,它和 retention policy 相关联。每一个存储策略下会存在许多 shard,每一个 shard 存储一个指定时间段内的数据,并且不重复,例如 7点-8点 的数据落入 shard0 中,8点-9点的数据则落入 shard1 中。每一个 shard 都对应一个底层的 tsm 存储引擎,有独立的 cache、wal、tsm file;
五、怎么快速搭建Influxdb环境,入门Influxdb
- 这里使用docker搭建快速入门,命令如下:
docker run -d -p 8086:8086 --name myinfluxdb influxdb
- 也可以使用docker-compose.yml,便于后期管理,与其他容器结合使用:
version: '3'
services:
influxdb:
image: influxdb
restart: always
tty: true
container_name: influxdb
ports:
- 8086:8086
六、常用基础操作
- 进入上述创建的myinfluxdb容器,docker exec -it myinfluxdb bash
- 输入influx,即进入Influxdb交互式界面:
p.p1 { margin: 0; font: 16px "Andale Mono"; color: rgba(0, 238, 0, 1); background-color: rgba(0, 0, 0, 0.9) }
span.s1 { font-variant-ligatures: no-common-ligatures }
root@0aba3a348938:/# influx
Connected to http://localhost:8086 version 1.8.0
InfluxDB shell version: 1.8.0
>
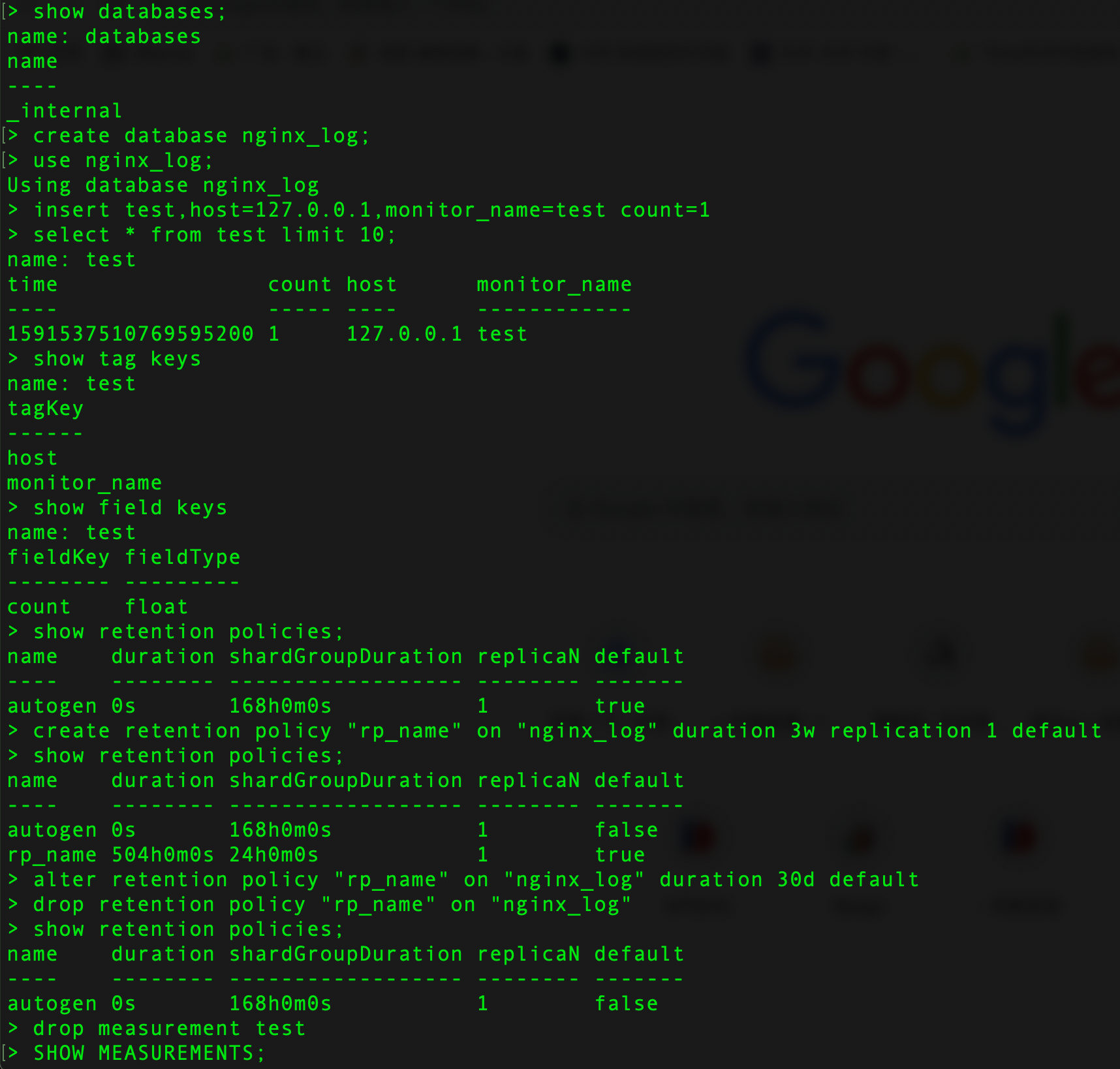
3. 常用命令及效果如下:
-- 进入数据库
use nginx_log;
-- 删除数据库
drop database nginx_log;
-- 显示数据库中所有表
SHOW MEASUREMENTS;
-- 创建表,直接在插入数据的时候指定表名,自动创建表及列
insert test,host=127.0.0.1,monitor_name=test count=1
-- 查询10条数据
select * from test limit 10;
-- 查看一个measurement中所有的tag key
show tag keys
-- 查看一个measurement中所有的field key
show field keys
-- 查看一个measurement中所有的保存策略(可以有多个,一个标识为default)
show retention policies;
-- 创建存储策略
create retention policy "rp_name" on "nginx_log" duration 3w replication 1 default
rp_name:策略名;
db_name:具体的数据库名;
3w:保存3周,3周之前的数据将被删除,influxdb具有各种事件参数,比如:h(小时),d(天),w(星期);
replication 1:副本个数,一般为1就可以了;
default:设置为默认策略
-- 修改存储策略
alter retention policy "rp_name" on "nginx_log" duration 30d default
-- 删除存储策略
drop retention policy "rp_name" on "nginx_log"
-- 删除表
drop measurement test

p.p1 { margin: 0; font: 16px "Andale Mono"; color: rgba(0, 238, 0, 1); background-color: rgba(0, 0, 0, 0.9) }
span.s1 { font-variant-ligatures: no-common-ligatures }
认识Influxdb时序数据库及Influxdb基础命令操作的更多相关文章
- 互联网级监控系统必备-时序数据库之Influxdb
时间序列数据库,简称时序数据库,Time Series Database,一个全新的领域,最大的特点就是每个条数据都带有Time列. 时序数据库到底能用到什么业务场景,答案是:监控系统. Baidu一 ...
- 互联网级监控系统必备-时序数据库之Influxdb集群及踩过的坑
上篇博文中,我们介绍了做互联网级监控系统的必备-Influxdb的关键特性.数据读写.应用场景: 互联网级监控系统必备-时序数据库之Influxdb 本文中,我们介绍Influxdb数据库集群的搭建, ...
- 互联网级监控系统必备-时序数据库之Influxdb技术
时间序列数据库,简称时序数据库,Time Series Database,一个全新的领域,最大的特点就是每个条数据都带有Time列. 时序数据库到底能用到什么业务场景,答案是:监控系统. Baidu一 ...
- InfluxDB时序数据库应用场景
目前了解到的InfluxDB时序数据库应用场景:如在数据库中有很多条记录,有的记录包含了时间字段time和数值字段water_level,有的只有时间字段time SELECT MAX("w ...
- 使用Python操作InfluxDB时序数据库
使用Python操作InfluxDB时序数据库 安装python包 influxdb,这里我安装的是5.3.0版本 pip install influxdb==5.3.0 使用 from infl ...
- MySQL数据库入门常用基础命令
MySQL数据库入门———常用基础命令 数据——公司的生命线,因此在大多数的互联网公司,都在使用开源的数据库产品,MySQL也因此关注度与使用率非常的高,所以做为运维的屌丝们,掌握它的一些基 ...
- Zookeeper系列一:Zookeeper基础命令操作
有些事不是努力就可以改变的,五十块的人民币设计的再好看,也没有一百块的招人喜欢. 前言 由于公司年底要更换办公地点,所以最近投了一下简历,发现面试官现在很喜欢问dubbo.zookeeper和高并发等 ...
- Zookeeper基础命令操作
转载链接:https://blog.csdn.net/dandandeshangni/article/details/80558383 安装参考链接https://blog.csdn.net/qiun ...
- ASP.NET Core2读写InfluxDB时序数据库
在我们很多应用中会遇到有一种基于一系列时间的数据需要处理,通过时间的顺序可以将这些数据点连成线,再通过数据统计后可以做成多纬度的报表,也可通过机器学习来实现数据的预测告警.而时序数据库就是用于存放管理 ...
随机推荐
- C/C++ 数据类型 表示最大 最小数值 探讨
C/C++中存储数字格式有整型和浮点型 字符型数据本质上也是以整型存储 整型 对于整型数据,最大值最小值很好计算 先确定对应数据型在本地所占用的字节数,同一数据型由于系统或者编译器的不同,所占字节不同 ...
- QQ消算轰炸,我好无聊真的
from pynput.keyboard import Key,Controller import time from random import choice time.sleep(5) # 创建键 ...
- sip信令跟踪工具sngrep
概述 在VOIP的使用过程中,最常见的问题就是信令不通和语音质量问题. 通常的问题跟踪手段包括日志分析.抓包分析. 抓包的工具有wireshark.tcpdump等等,如果是只针对sip信令的抓包,则 ...
- [no code][scrum meeting] Beta 5
$( "#cnblogs_post_body" ).catalog() 例会时间:5月18日14:30,主持者:叶开辉 下次例会时间:5月19日11:30,主持者:黎正宇 一.工作 ...
- [软工顶级理解组] Alpha阶段项目展示
目录 团队成员 软件介绍 项目简介 预期典型用户 功能描述 预期目标用户数 用户反馈 团队管理 分工协作 项目管理 取舍平衡 代码管理 程序测试 代码规范 文档撰写 继续开发指导性 用户沟通 需求分析 ...
- 最详细的windows10系统封装教程
目录 自定义封装(定制)windows10教程 关于本教程及用到的工具的声明 第一阶段: 封装前的各种环境准备 安装vmware 创建虚拟机 对虚拟机进行分区 配置好BIOS 为虚拟机安装window ...
- coreseek使用心得
基本使用方法: D:\coreseek-4.1\bin\searchd -c D:\coreseek-4.1\etc\article.conf --stop 停止服务 D:\coreseek-4.1\ ...
- Docker 18.03导入导出
docker中分容器和镜像,简单可以理解为容器是运行中的实例,镜像是运行实例所需的静态文件. 导入导出既可以对容器做操作,也可以对镜像做操作.区别在于镜像可以随时导出,容器必须要停止之后才可以导出,否 ...
- Oracle创建表、删除表、修改表、字段增删改 语句总结
创建表: create table 表名 ( 字段名1 字段类型 默认值 是否为空 , 字段名2 字段类型 默认值 是否为空, 字段名3 字段类型 默认值 是否为空, ...... ); 创建一个us ...
- macos command 'clang' failed with exit status 1
export CC=$(which gcc)export CXX=$(which g++)pip install fbprophet CC=clang pip install gevent