Apache Kafka 学习笔记
1. 介绍
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
- 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
- 高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
- 支持通过Kafka集群来分区消息。
- 支持Hadoop并行数据加载。
TIPS: O(1),时间复杂度。描述算法复杂度时,常用o(1), o(n), o(logn), o(nlogn)表示对应算法的时间复杂度,是算法的时空复杂度的表示。不仅仅用于表示时间复杂度,也用于表示空间复杂度。
2. 基本概念和组件
topics是什么?partition是什么?topics是kafka中数据存储的基本单位,写数据,要指定写入哪个topic。读数据,指定从哪个topic去读。
每个topic的内部都会有一个或多个partitions(分区),写入的数据,他其实是写入每一个topic里的其中一个partition,并且当前的数据是有序的写入到paritition中的。每一个partition内都会维护一个不断增加的ID,每当你写入一个新的数据的时候,这个ID就会增长,这个id就会被称为这个paritition的offset,每个写入partition中的message都会对应一个offset。
不同的partition都会对应他们自己的offset 我们可以利用offset来判断,当前paritition内部的顺序。同一partition中的数据是有序的,不同partition间的数据是无顺序的。如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
此外kafka还可以配置partitions需要备份的个数(replicas)。基于备份策略需要对多个备份进行调度;每个partition都有一个server为"leader";leader负责所有的读写操作,如果leader失效,那么将会有其他follower来接管(成为新的leader);follower只是单调的和leader跟进,同步消息即可。由此可见作为leader的server承载了全部的请求压力,因此从集群的整体考虑,有多少个partitions就意味着有多少个"leader",kafka会将"leader"均衡的分散在每个实例上,来确保整体的性能稳定。
当你将数据写入kafka中,数据默认情况下会在kafka中保存2个星期。保存时间可以配置。如果超过配置的保存时间,kafka里面的数据就会被无效化。
从kafka读取数据后 数据会自动删除吗?
不会,kafka中数据的删除跟有没有消费者消费完全无关。数据的删除,只跟kafka broker上面的这两个配置有关:
log.retention.hours=48 #数据最多保存48小时
log.retention.bytes=1073741824 #数据最多1G
提示:写入到kafka中的数据,是不可以被改变的。也就是说,你没有办法去更改已经写入到kafka中的数据。每一个topic中有多少个parititions是topic创建时由参数确定的
3. 安装
官方下载地址:http://kafka.apache.org/downloads
硬件准备:一台12G内存的电脑或笔记本,多台电脑硬件
软件准备:vmware,jdk(1.8及以上),wget(linux工具),Centos7系统镜像,SecureCRT远程连接工具等
单机安装:
默认条件:安装好zookeeper-3.4.10,jdk1.8及以上,wget工具
1.创建目录:mkdir /usr/kafka
2.进入创建目录:cd /usr/kafka
3.下载安装包:wget http://mirror.tuna.tsinghua.edu.cn/apache/kafka/2.3.0/kafka_2.11-2.3.0.tgz
4.解压安装包:tar -xzf kafka_2.11-2.3.0.tgz
5.进入kafka安装目录:cd kafka_2.11-2.3.0或cd /usr/kafka/kafka_2.11-2.3.0
6.进入config目录:cd config
7.修改server.properties文件:vi server.properties(按【i】键进入插入模式编辑),编辑完保存退出。
属性配置说明参照:https://blog.csdn.net/lizhitao/article/details/25667831
TIPS:kafka最为重要三个配置依次为:broker.id、log.dir、zookeeper.connect。broker.id设置的值要和日志文件目录下的值一致,log.dir路径需要手动创建,zookeeper连接根据实际zookeeper地址配置。
8.启动zookeeper:进入安装好的zookeeper的bin目录,执行【./zkServer.sh start】,提示started,启动成功。
9.启动kafka:进入kafka安装目录【cd /usr/kafka/kafka_2.11-2.3.0】,执行bin/kafka-server-start.sh -daemon ./config/server.properties,无错误提示即启动成功。
10.创建话题:进入kafka安装目录【cd /usr/kafka/kafka_2.11-2.3.0】,执行bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test。无错误提示,执行话题列表查看命令【bin/kafka-topics.sh --list --zookeeper localhost:2181】,显示test说明成功。

11.发送一些消息验证,在console模式下,启动producer(生产者):bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
TIPS:启动生产者出错,请至server.properties文件中修改监听配置,将localhost修改为电脑IP。命令中的localhost替换成IP;
 bin/kafka-console-producer.sh --broker-list 192.168.43.97:9092 --topic test
bin/kafka-console-producer.sh --broker-list 192.168.43.97:9092 --topic test
12.消费者获取信息:
1 # --from-beginning 从最开始读取
2 # bin/kafka-console-consumer.sh --zookeeper 192.168.43.97:2181 --from-beginning --topic test # 老版本
3 # bin/kafka-console-consumer.sh --bootstrap-server 192.168.43.97:9092 --from-beginning --topic test #新版本

集群安装
印象笔记:https://app.yinxiang.com/fx/10442f5d-2972-4e9a-b397-0510df91fb9f
在单机安装的基础上改造为集群操作步骤:
1.进入kafka安装目录,将config/server.properties复制多份,修改broker.id=1(brokerID)、listeners=PLAINTEXT://:9093(监听端口)、log.dir=/tmp/kafka-logs-1(日志文件地址,注意日志文件中的brokerID和server.properties的brokerID需要一致)
2.启动时分别加载不同的配置文件:
bin/kafka-server-start.sh -daemon ./config/server1.properties
bin/kafka-server-start.sh -daemon ./config/server2.properties
bin/kafka-server-start.sh -daemon ./config/server.properties
3.按照单机操作步骤测试是否正确。
4. 基本使用
常见命令 :
1.zookeeper启动命令:./zkServer.sh start(进入zookeeper【bin】目录后执行)
2.kafka启动命令:bin/kafka-server-start.sh -daemon ./config/server.properties(进入kafka安装目录后执行)
3.kafka创建话题命令:bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test(进入kafka安装目录后执行)
4.kafka查看话题列表命令:bin/kafka-topics.sh --list --zookeeper localhost:2181(进入kafka安装目录后执行)
5.kafka消息生成命令:bin/kafka-console-producer.sh --broker-list 192.168.43.97:9092 --topic test(进入kafka安装目录后执行)
6.kafka消息接收命令:
1. kafka-console-consumer.sh --zookeeper 192.168.43.97:2181 --from-beginning --topic test # 老版本
2. kafka-console-consumer.sh --bootstrap-server 192.168.43.97:9092 --from-beginning --topic test #新版本
其它参考:https://www.cnblogs.com/shuangm/p/6917608.html
客户端工具:https://www.cnblogs.com/frankdeng/p/9452982.html
Java使用:
1.https://www.cnblogs.com/biehongli/p/10877600.html
2.测试类:jdk1.8,用到的jar包如下图请自行下载:
1 package com.tenglong.tools;
2
3 import java.util.Properties;
4
5 import org.apache.kafka.clients.producer.Callback;
6 import org.apache.kafka.clients.producer.KafkaProducer;
7 import org.apache.kafka.clients.producer.ProducerRecord;
8 import org.apache.kafka.clients.producer.Producer;
9 import java.util.Arrays;
10 import org.apache.kafka.clients.producer.RecordMetadata;
11
12 import java.util.concurrent.ExecutionException;
13 import java.util.concurrent.Future;
14 import org.apache.kafka.clients.consumer.ConsumerRecord;
15 import org.apache.kafka.clients.consumer.ConsumerRecords;
16 import org.apache.kafka.clients.consumer.KafkaConsumer;
17 import org.apache.kafka.common.errors.RetriableException;
18
19 public class kafkaTest {
20
21 /**
22 * @param args
23 */
24 public static void main(String[] args) {
25 // TODO Auto-generated method stub
26 String topicName = "topic5";
27 Producer(topicName);
28 //Consumer(topicName);
29 }
30
31 public static void Producer(String topicName){
32 // 构造一个java.util.Properties对象
33 Properties props = new Properties();
34 // 指定bootstrap.servers属性。必填,无默认值。用于创建向kafka broker服务器的连接。
35 props.put("bootstrap.servers", "192.168.43.97:9092");
36 // 指定key.serializer属性。必填,无默认值。被发送到broker端的任何消息的格式都必须是字节数组。
37 // 因此消息的各个组件都必须首先做序列化,然后才能发送到broker。该参数就是为消息的key做序列化只用的。
38 props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
39 // 指定value.serializer属性。必填,无默认值。和key.serializer类似。此被用来对消息体即消息value部分做序列化。
40 // 将消息value部分转换成字节数组。
41 props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
42 //acks参数用于控制producer生产消息的持久性(durability)。参数可选值,0、1、-1(all)。
43 props.put("acks", "-1");
44 //props.put(ProducerConfig.ACKS_CONFIG, "1");
45 //在producer内部自动实现了消息重新发送。默认值0代表不进行重试。
46 props.put("retries", 3);
47 //props.put(ProducerConfig.RETRIES_CONFIG, 3);
48 //调优producer吞吐量和延时性能指标都有非常重要作用。默认值16384即16KB。
49 props.put("batch.size", 323840);
50 //props.put(ProducerConfig.BATCH_SIZE_CONFIG, 323840);
51 //控制消息发送延时行为的,该参数默认值是0。表示消息需要被立即发送,无须关系batch是否被填满。
52 props.put("linger.ms", 10);
53 //props.put(ProducerConfig.LINGER_MS_CONFIG, 10);
54 //指定了producer端用于缓存消息的缓冲区的大小,单位是字节,默认值是33554432即32M。
55 props.put("buffer.memory", 33554432);
56 //props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
57 props.put("max.block.ms", 3000);
58 //props.put(ProducerConfig.MAX_BLOCK_MS_CONFIG, 3000);
59 //设置producer段是否压缩消息,默认值是none。即不压缩消息。GZIP、Snappy、LZ4
60 //props.put("compression.type", "none");
61 //props.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "none");
62 //该参数用于控制producer发送请求的大小。producer端能够发送的最大消息大小。
63 //props.put("max.request.size", 10485760);
64 //props.put(ProducerConfig.MAX_REQUEST_SIZE_CONFIG, 10485760);
65 //producer发送请求给broker后,broker需要在规定时间范围内将处理结果返还给producer。默认30s
66 //props.put("request.timeout.ms", 60000);
67 //props.put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG, 60000);
68
69
70 // 使用上面创建的Properties对象构造KafkaProducer对象
71 //如果采用这种方式创建producer,那么就不需要显示的在Properties中指定key和value序列化类了呢。
72 // Serializer<String> keySerializer = new StringSerializer();
73 // Serializer<String> valueSerializer = new StringSerializer();
74 // Producer<String, String> producer = new KafkaProducer<String, String>(props,
75 // keySerializer, valueSerializer);
76 Producer<String, String> producer = new KafkaProducer<>(props);
77 int num = 0;
78 for (int i = 0; i < 100; i++) {
79 //构造好kafkaProducer实例以后,下一步就是构造消息实例。
80 //producer.send(new ProducerRecord<>(topicName, Integer.toString(i), Integer.toString(i)));
81 // 构造待发送的消息对象ProduceRecord的对象,指定消息要发送到的topic主题,分区以及对应的key和value键值对。
82 // 注意,分区和key信息可以不用指定,由kafka自行确定目标分区。
83 //ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("my-topic",
84 // Integer.toString(i), Integer.toString(i));
85 // 调用kafkaProduce的send方法发送消息
86 //producer.send(producerRecord);
87
88
89
90
91 // 消息同步发送开始
92 /*try {
93 Future<RecordMetadata> future = producer.send(new ProducerRecord<>(topicName,Integer.toString(i),Integer.toString(i) + " 万年呢!!!"));
94 //同步发送,调用get()方法无限等待返回结果
95 RecordMetadata recordMetadata = future.get();
96 //成功返回RecordMetadata实例(包含发送的元数据信息)
97 System.out.println("第 " + i + " 条, " + recordMetadata.toString());
98 } catch (InterruptedException e) {
99 e.printStackTrace();
100 } catch (ExecutionException e) {
101 e.printStackTrace();
102 }*/
103 //消息同步发送结束
104
105
106
107 //消息异步发送成功
108 ProducerRecord<String, String> record = new ProducerRecord<String, String>(topicName, Integer.toString(i), i +" 万年呢!!!");
109 //异步发送
110 producer.send(record, new Callback() {
111
112 @Override
113 public void onCompletion(RecordMetadata metadata, Exception exception) {
114 if(exception == null) {
115 //exception == null代表消息发送成功
116 System.out.println("消息发送成功......");
117 }else {
118 //消息发送失败,执行错误的逻辑
119 System.out.println("消息发送失败......");
120 if(exception instanceof RetriableException) {
121 //处理可重试瞬时异常
122 //...
123 }else {
124 //处理不可重试异常
125 //...
126 }
127
128 }
129 }
130 });
131 //消息异步发送结束
132 num++;
133 }
134 System.out.println("消息生产结束......"+num);
135 System.out.println("消息生产结束......");
136 // 关闭kafkaProduce对象
137 producer.close();
138 System.out.println("关闭生产者......");
139 }
140 public static void Consumer(String topicName){
141 String groupId = "group1";
142 //构造java.util.Properties对象
143 Properties props = new Properties();
144 // 必须指定属性。
145 props.put("bootstrap.servers", "192.168.43.97:9092");
146 // 必须指定属性。
147 props.put("group.id", groupId);
148 props.put("enable.auto.commit", "true");
149 props.put("auto.commit.interval.ms", "1000");
150 // 从最早的消息开始读取
151 props.put("auto.offset.reset", "earliest");
152 // 必须指定
153 props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
154 // 必须指定
155 props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
156
157 // 使用创建的Properties实例构造consumer实例
158 KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
159 // 订阅topic。调用kafkaConsumer.subscribe方法订阅consumer group所需的topic列表
160 consumer.subscribe(Arrays.asList(topicName));
161 try {
162 while (true) {
163 //循环调用kafkaConsumer.poll方法获取封装在ConsumerRecord的topic消息。
164 ConsumerRecords<String, String> records = consumer.poll(1000);
165 //获取到封装在ConsumerRecords消息以后,处理获取到ConsumerRecord对象。
166 for (ConsumerRecord<String, String> record : records) {
167 //简单的打印输出
168 System.out.println(
169 "offset = " + record.offset()
170 + ",key = " + record.key()
171 + ",value =" + record.value());
172 }
173 }
174 } catch (Exception e) {
175 //关闭kafkaConsumer
176 System.out.println("消息消费结束......");
177 consumer.close();
178 }
179 System.out.println("关闭消费者......");
180 }
181 }
Python使用:https://www.cnblogs.com/small-office/p/9399907.html
5. 软件原理
参考网址:https://blog.csdn.net/qq_29186199/article/details/80827085
6. 性能优化
以下是10个技巧可以优化Kafka部署并更使之容易管理:
1.设置日志配置参数确保日志可管理
Kafka为用户提供了大量的日志配置选项,虽然默认设置是合理的,但是更好的方式是根据实际的业务情况,自定义日志行为以匹配特定需求。包括设置日志保留策略、清理、压缩。可以使用log.segment.bytes,log.segment.ms和log.cleanup.policy来控制日志行为。如果在业务中不需要保留大量历史日志,可以通过设置cleanup.policy来清理特定大小的日志文件,或者设定在某个时间点清理。此外还可以将其设置为“compact”,以便在需要时保留日志。日志文件清理会消耗CPU和RAM资源,清理、压缩的频率和性能需要小心权衡。压缩是Kafka确保每个消息键至少保留最后一个已知值的过程(在单个Topic分区的数据日志中)。压缩操作会对Topic中每个键进行处理,只保留其最后一个值,并清除所有其他重复项。在删除时,键值会被设为“null”(它被称为“tombstone”,形象地表示删除)。
2.了解Kafka的硬件需求
实际上Kafka开销很低而且在设计上对水平扩展很友好,使用廉价的硬件就可以高效地运行Kafka:
CPU:除非需要SSL和日志压缩,否则Kafka不需要强大的CPU。同时,使用的核越多,并行性越好。在大多数情况下,可以使用LZ4来提升性能。
RAM(内部存储器):在大多数情况下,Kafka可以使用6GB的RAM来优化堆空间。对于特别重的生产负载,使用32GB或更多。额外的RAM将用于支持OS页面缓存和提高客户机吞吐量。虽然Kafka可以用更少的RAM运行,但是当可用内存更少时,它处理负载的能力就会受到限制。
Disk:Kafak在RAID设置中使用多个驱动器时非常有用。RAID在底层实现了物理磁盘的负载均衡和冗余,虽然会牺牲一些磁盘空间和写入性能。在配置中使用多目录,每个目录挂在在不同的磁盘(或者RAID)上。由于Kafka的顺序磁盘I/O范式,SSD没有提供多少优势,此外不应该使用NAS(连接在网络上具备资料存储功能的装置,也称为“网络存储器”)。
Network & File:建议使用XFS(XFS是一个64位文件系统,最大支持 8exbibytes 减1字节的单个文件系统),如果环境允许,建议将集群部署在单个数据中心。与此同时传输的网络带宽应尽可能充足。
3.充分利用Apache ZooKeeper
Apache ZooKeeper集群是运行Kafka的关键依赖项。ZooKeeper节点的数量一般最多5个。一个节点适合于开发环境,对于大多数生产环境三个节点的Kafka集群足够了。虽然大型Kafka部署可能需要5个ZooKeeper节点来减少延迟,但是必须考虑节点上的负载。如果7个或更多的节点同步和处理请求,整个系统的负载将变得非常大,性能可能会有明显的影响。最后正如Kafka的硬件需求一样,为ZooKeeper提供尽可能充足的网络带宽。使用最好的磁盘、单独存储日志、隔离ZooKeeper进程和禁用交换也会减少延迟。
4.正确设置复制和冗余策略
使复制和冗余均等的分配在每台物理主机上,这样即使其中一台或多台主机宕机也能最大限度的保证服务的稳定性。
5.合理配置Topic
Topic配置对Kafka集群的性能有很大的影响。由于上生产之后再对复制因子或分区计数等设置的进行更改,有可能影响线上,因此尽可能在初始时就以正确的方式估算并设置好配置。如果需要更改或创建新Topic,确保在Stage环境中测试该新Topic。 把复制因子改为3时,在处理大型消息时要深思。如果可能的话,将大消息分成有序的多个片段,或者使用指向数据的指针(例如主键)。如果这些方式都无法采用,建议在生产端启用压缩。默认的日志段大小是1 GB,如果消息更大,必须仔细分析业务场景。分区(Partition)计数也是一个非常重要的设置,将在下一节详细讨论。
Topic配置有默认值,可以在创建时覆盖,也可以在稍后进行特定配置时覆盖。如上所述,最重要的配置之一是复制因子(replication factor)。以下示例演示了从控制台创建Topic,复制因子为3,以及使用其他“Topic级别”配置的3个分区:bin/kafka-topics.sh --zookeeper ip_addr_of_zookeeper:2181 --create --topic my-topic --partitions 3 --replication-factor 3 --config max.message.bytes=64000 --config flush.messages=1
获取Topic级别配置的完整列表可以参考官方文档:https://kafka.apache.org/documentation/#topicconfigs。
6.使用并行处理
Kafka是为并行处理而设计的,就像并行化本身一样,充分发挥它需要掌握平衡的艺术。分区计数是一个Topic级设置,分区越多,并行化和吞吐量越大。然而分区还意味着更多的复制延迟、重新负载均衡和大量文件句柄。可以计算基于当前硬件期望达到的吞吐量,然后计算所需的分区数量,找到最佳分区设置。
根据保守的估计,单个Topic上一个分区可以交付10MB /s,以此进行推断,可以获得所需的总吞吐量。
另一种方法是为每个broker每个Topic使用一个分区,然后进行性能测试并检查结果,如果需要更大的吞吐量,则将分区加倍。
一般来说,Topic的总分区建议保持在10以下,并将集群的总分区保持在10,000以下。如果分区数远多于此,那么必须做好完善的监控并且服务中断做好预案。
以下是在创建Kafka主题时设置分区的数量:bin/kafka-topics.sh --zookeeper ip_addr_of_zookeeper:2181 --create --topic my-topic --partitions 3 --replication-factor 3 --config max.message.bytes=64000 --config flush.messages=1
此外,也可以在创建之后增加分区计数。但是它会影响消费端,因此建议在考虑清楚所有后果之后再执行此操作。
bin/kafka-topics.sh --zookeeper zk_host:port/chroot --alter --topic topic_name --partitions new_number_of_partitions
7.在考虑安全性的情况下配置和隔离Kafka
Kafka安全部署主要两点:1) Kafka的内部配置,2) Kafka运行的基础设施。Kafka .9版本包含了许多有价值的安全特性,例如Kafka/client和Kafka/ZooKeeper身份验证支持,以及TLS支持。虽然TLS会对吞吐量和性能带来成本,但它有效地地隔离和保护Kafka broker的流量。隔离卡Kafka和ZK对安全至关重要。除了特殊情况,ZK不应该连接到公网,应该只和Kafka沟通(如有共用情况则另说)。防火墙和安全组应该隔离Kafka和ZooKeeper,将broker驻留在私有网络中并拒绝外部连接。中间件或负载平衡层应该将Kafka与公网客户端隔离。kafka的安全选项和协议如下:
1.SSL/SASL:客户端到代理、内部代理、代理到工具的身份验证。
2.SSL:客户端到代理之间、代理之间以及工具到代理之间的数据加密
3.SASL类型:SASL/GSSAPI (Kerberos)、SASL/PLAIN、SASL/冲压- sha -512/冲压- sha -256、sasl_auth载体
4.Zookeeper安全性:客户端的身份验证(代理、工具、生产者、消费者),ACL授权。
8.通过提高Ulimit避免停机
常见的问题场景:broker由于负载太高而下线,本质上是由于占用了大量文件句柄导致的错误。通过编辑/etc/sysctl.conf并将Ulimit配置为允许128,000个或更多的打开文件,可以避免这种错误。针对不同的系统版本自行搜索修改Ulimit的方法。
9.保持较低的网络延迟
为了降低Kafka部署的延迟,确保broker在地理上位于离客户最近的区域,并确保在选择云服务商提供的实例时考虑网络性能。如果硬件、带宽等因素影响服务质量,可以考虑在基础设施及硬件上进行有价值的投资。
10.有效利用监控和警报
在创建Kafka集群时,遵循上面的实践可以避免许多问题,但仍要保持警惕,在问题出现之前识别并正确处理。监视系统指标(如网络吞吐量、打开的文件句柄、内存、负载、磁盘使用情况及其他因素),监视JVM统计数据(包括GC和堆使用情况)等都是必要的。仪表板和历史记录工具可以大大提高问题发现的时效。与此同时,可以通过Nagios或PagerDuty等系统配置延迟峰值或磁盘空间不足等预警,以便在问题如滚雪球一样越滚越大之前得到妥善解决。
7. 软件监控
经了解主流的三种kafka监控程序分别为:
1.Kafka Web Conslole
使用Kafka Web Console,可以监控:
1.Brokers列表
2.Kafka 集群中 Topic列表,及对应的Partition、LogSiz e等信息
3.点击Topic,可以浏览对应的Consumer Groups、Offset、Lag等信息
4.生产和消费流量图、消息预览…
2.Kafka Manager
雅虎开源的Kafka集群管理工具,可以监控:
1.管理几个不同的集群
2.监控集群的状态(topics, brokers, 副本分布, 分区分布)
3.产生分区分配(Generate partition assignments)基于集群的当前状态
4.重新分配分区
3.KafkaOffsetMonitor
KafkaOffsetMonitor可以实时监控:
1.Kafka集群状态
2.Topic、Consumer Group列表
3.图形化展示topic和consumer之间的关系
4.图形化展示consumer的Offset、Lag等信息
本次介绍Kafka Manager安装。
1.手动下载【kafka-manager-1.3.3.7.zip】,通过secureCRT的Connect SFPT Session上传至centOs系统
2.执行mkdir /usr/kafka-manager创建目录
3.执行mv kafka-manager-1.3.3.7.zip /usr/kafka-manager将压缩包移动至usr/kafka-manager目录
4.进入kafka-manager目录,执行tar -xvf kafka-manager-1.3.3.7.zip
5.进入kafka-manager目录,执行以下三种命令可启动kafka-manager:
1.bin/kafka-manager#直接启动
2.bin/kafka-manager -Dconfig.file=/path/to/application.conf -Dhttp.port=8080#指定端口启动
3.bin/kafka-manager -java-home /usr/jdk1.8/jdk1.8.0_161 &#指定javahome启动
6.浏览器访问:http://192.168.43.97:9000/,正常显示说明启动成功。
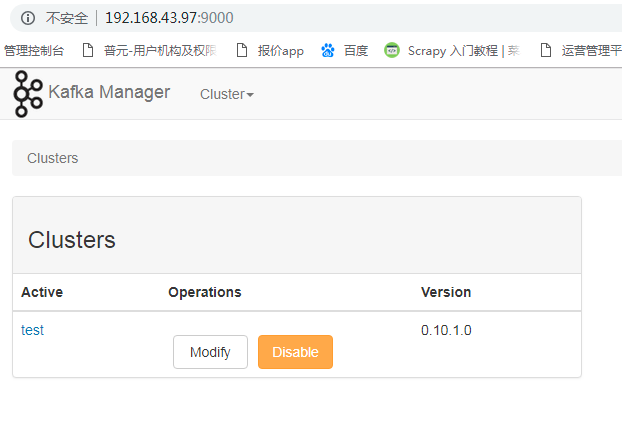
7.添加集群到kafka-manager。

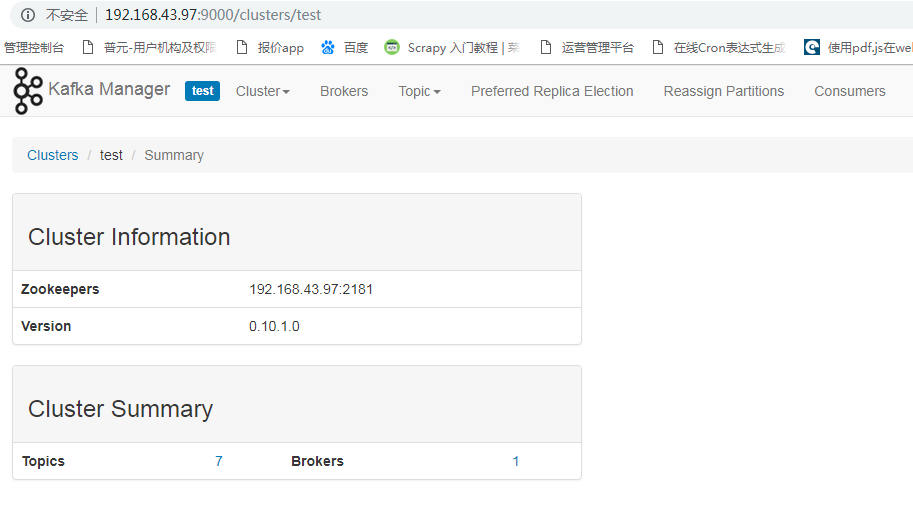
8. 问题解决方案
常见问题
1.sbt安装
创建sbt目录:mkdir /usr/sbt
进入sbt目录:cd /usr/sbt
下载sbt:wget https://piccolo.link/sbt-1.2.0.tgzwget https://piccolo.link/sbt-1.2.0.tgz
解压文件:tar -xvf sbt-1.2.0.tgz
进入sbt安装目录:cd /sbt
执行【vi sbt】 新增sbt文件,文件内容如下,并执行【chmod u+x sbt】修改文件权限:(加粗部分根据自己安装目录自行修改)
#!/bin/bash
SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M"
java $SBT_OPTS -jar /usr/sbt/sbt/bin/sbt-launch.jar "$@"
配置sbt环境变量命令:vi ~/.bashrc 增加【export PATH=/usr/sbt/sbt/:$PATH】,加粗的根据自己安装目录修改, 执行【source ~/.bashrc】使更改生效。

查看sbt版本: sbt sbtVersion

显示版本号安装成功!
2.防火墙操作:
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
3.IP地址修改:/etc/sysconfig/network-scripts/ifcfg-ens33
9.框架对比:
activemq、rabbitmq、kafka原理和比较参考网址:https://blog.csdn.net/lifaming15/article/details/79942793
1.ActiveMQ:
安装和使用参考网站:https://blog.csdn.net/cs_hnu_scw/article/details/81040834
优点:
1.Java开发,提供Java, C, C++, C#, Ruby, Perl, Python, PHP各种客户端,各种开发语言通用。
2.Java项目组可以轻松进行扩展开发。
3.工作模型比较简单。只有两种模式 queue,topics 。
queue就多对一,producer往queue里发送消息,消费者从queue里取,消费一条,就从queue里移除一条。如果一个消费者消费速度不够快怎么办呢?在activemq里,提供messageGroup的概念,一个queue可以有多个消费者,但是他们得标记自己是一个messageGroup里的。这样,消息会轮训发送给每个消费者,也就是说消费者不会重复消费同一条消息。但是每条消息只被消费一次。
topics就是广播。producer往broker发消息,每个消息包含topic。消费者订阅感兴趣的topic,所有订阅了topic的消费者都会收到消息。当然订阅分持久不持久。持久订阅,当消费者断开一会,再连上来,仍然会把没收到的消费发过来。不持久的订阅,断开这段时间的消息就收不到了。
4.支持mqtt、ssl。
5.业务处理能力较强。
缺点:
1.对于大数据量的订阅发布,需要自行实现主从复制和集群。
2.本身较RabbitMQ占用空间大
2.RabbitMQ:
安装使用教程:https://blog.csdn.net/wangbing25307/article/details/80845641
优点:
1.服务器端用Erlang语言编写,支持多种客户端,如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP等,支持AJAX。
2.支持高并发
3.对大数据量的支持较ActiveMQ好。
4.业务处理能力极强
5.本身较ActiveMQ轻量
6.以plugin的形式支持mqtt,和spring整合也非常简单。
缺点:
1.对于大数据量的订阅发布,需要自行实现主从复制和集群。对高并发和集群的支撑比kafka差。
3.kafka:
优点:
1.为分布式而生。和activemq以及rabbitmq这些企业级队列而言确实更有分布式系统的优势。
2.传统的消息队列只有两种模式,要么是queue,要么是publish-subscribe发布订阅。在queue模式中,一组消费者消费一个队列,每条消息被发给其中一个消费者。在publish-subscribe模式中,消费被广播给所有消费者。queue模式的好处在于,他可以把消费分发给一组消费者,从而实现消费者的规模化(scale);问题在于,这样一个消息只能被一组消费者消费,一旦消费,消息就没有了。publish-subscribe的好处在于,一个消息可以被多组消费者消费;问题在于,你的消费者没法规模化,即不可能出现多个消费者订阅同一个topic,但每个消费者只处理一部分消息(虽然这个可以通过设计topic来解决)。
3.kafka也支持mqtt,需要写一个connecter。
4.提供流式计算的功能,做数据的初步清理还是很方便的。
4.提供主流开发语言的客户端
缺点:
1.扩展性不及ActiveMQ和RabbitMQ。
总体而言。KAFKA安装使用最简单,同时,如果有集群要求,那么kafka是当仁不让的首选。尤其在海量数据,以及数据有倾斜问题的场景里,因为partition的缘故,数据倾斜问题自动解决。比如个别Topic的消息量非常大,在kafka里,调整partition数就好了。反而在rabbitmq或者activemq里,这个不好解决。
RabbitMQ是功能最丰富,最完善的企业级队列。基本没有做不了的,就算是做类似kafka的高可用集群,也是没问题的,不过安装部署麻烦了点。
ActiveMQ相对来说,显的老套了一些。不过毕竟是java写的,在内嵌到项目中的情况下,或者是简单场景下,还是不错的选择。
Apache Kafka 学习笔记的更多相关文章
- kafka学习笔记(一)消息队列和kafka入门
概述 学习和使用kafka不知不觉已经将近5年了,觉得应该总结整理一下之前的知识更好,所以决定写一系列kafka学习笔记,在总结的基础上希望自己的知识更上一层楼.写的不对的地方请大家不吝指正,感激万分 ...
- Apache Flink学习笔记
Apache Flink学习笔记 简介 大数据的计算引擎分为4代 第一代:Hadoop承载的MapReduce.它将计算分为两个阶段,分别为Map和Reduce.对于上层应用来说,就要想办法去拆分算法 ...
- Kafka 学习笔记之 Kafka0.11之console-producer/console-consumer
Kafka 学习笔记之 Kafka0.11之console-producer/console-consumer: 启动Zookeeper 启动Kafka0.11 创建一个新的Topic: ./kafk ...
- 大数据 -- kafka学习笔记:知识点整理(部分转载)
一 为什么需要消息系统 1.解耦 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险.许多 ...
- Apache Kafka学习 (一)
前言:最近公司开始要研究大数据的消息记录,于是开始研究kafka. 市面上kafka的书很少,有的也版本比较落后,于是仗着自己英文还不错,上官网直接学习. ^_^ 1. 开始 - 基本概念 学习一样东 ...
- Apache OFBiz 学习笔记 之 服务引擎 二
加载服务定义文件 ofbiz-component.xml:所有的服务定义文件在每个组件的ofbi-component.xml文件中 加载服务定义 例:framework/common/ofbi ...
- kafka学习笔记2:生产者
这次的笔记主要记录一下kafka的生产者的使用和一些重要的参数. 文中主要截图均来自kafka权威指南 主要涉及到两个类KafkaProducer和ProducerRecord. 总览 生产者的主要架 ...
- kafka学习笔记1:测试环境搭建
最近因为架构中引入了kafka,一些之前在代码中通过RPC调用强耦合但是适合异步处理的内容可以用kafka重构一下. 考虑从头学一下kafka了解其特性和使用场景. 环境选择 首先是测试环境的搭建,平 ...
- kafka学习笔记——基本概念与安装
Kafka是一个开源的,轻量级的.分布式的.具有复制备份.基于zooKeeper协调管理的分布式消息系统. 它具备以下三个特性: 能够发布订阅流数据: 存储流数据时,提供相应的容错机制 当流数据到达时 ...
随机推荐
- python math详解(1)
python math详解(1) 一.导入 python要调用math要进行导入 import math 二.返回值 math包里有一些值 比如 math.pi 返回pi的值 约为3.14 math. ...
- Java基础系列(29)- 方法的重载
方法的重载 重载就是在一个类中,有相同的函数名称,但形参不同的函数 方法重载的规则: 方法名称必须相同 参数列表必须不同(个数不同.或类型不同.参数排列顺序不同等) 方法的返回类型可以相同也可以不相同 ...
- 自制Chrome扩展插件:用于重定向js
前言 作为一个前端开发, 在调试生产环境的代码时,是否苦于生产环境代码被压缩,没有sourcemap? 有没有想过将生产环境的js直接重定向为本地开发环境的js? 玩微前端时,有没有想过用本地的子应用 ...
- spring入门2-aop和集成测试
1.AOP开发 1.1.简述 作用:面向切面编程:在程序运行期间,在不修改源码的情况下对代码进行增强 优势:减少代码重复,提高开发效率,便于维护 底层:动态代理实现(jdk动态代理,cglib动态代理 ...
- css定位:p:nth-child(n)
p:nth-child(n) 定位p标签下的第一个元素,下标从1开始. 首先是一个标签下有多个相同的元素. 如index_service_cnt js_service_list下有多个class=&q ...
- python学习笔记(十一)-python程序目录工程化
在一个程序当中,一般都会包含文件夹:bin.conf.lib.data.logs,以及readme文件. 所写程序存放到各自的文件夹中,如何进行串联? 首先,通过导入文件导入模块方式,引用其他人写好的 ...
- 『Python』matplotlib共享绘图区域坐标轴
1. 共享单一绘图区域的坐标轴 有时候,我们想将多张图形放在同一个绘图区域,不想在每个绘图区域只绘制一幅图形.这时候,就可以借助共享坐标轴的方法实现在一个绘图区域绘制多幅图形的目的. import n ...
- 【译】.NET Core 3.0 发布小尺寸 self-contained 单体可执行程序
.NET Core 提供的发布应用程序选项 self-contained 是共享应用程序的好方法,因为应用程序的发布目录包含所有组件.运行时和框架.您只需要告诉使用者应用程序的入口 exe 文件,就可 ...
- 「含源码」关于NXP IMX8 Mini的图形开发指南(GPU)案例分享!
前言 Graphical Demo框架提供了对平台相关依赖的抽象.Graphical应用的通用封装,如模型加载.纹理加载.着色器编译等,以及其它一些通用的应用逻辑处理的封装,使得使用框架的开发人员(以 ...
- kubectl 的插件管理工具krew
k8s的命令行工具kubectl 对于玩k8s 的人来说是必备工具.kubectl插件机制在Kubernetes 1.14宣布稳定,进入GA状态.kubectl的插件机制就是希望允许开发者以独立的二进 ...