NLP与深度学习(六)BERT模型的使用
1. 预训练的BERT模型
从头开始训练一个BERT模型是一个成本非常高的工作,所以现在一般是直接去下载已经预训练好的BERT模型。结合迁移学习,实现所要完成的NLP任务。谷歌在github上已经开放了预训练好的不同大小的BERT模型,可以在谷歌官方的github repo中下载[1]。
以下是官方提供的可下载版本:

其中L表示的是encoder的层数,H表示的是隐藏层的大小(也就是最后的前馈网络中的神经元个数,等同于特征输出维度)。
除此之外,谷歌还提供了BERT-uncased与BERT-cased格式,分别对应是否包含大小写。一般来说,BERT-uncased(仅包含小写)比较常用,因为大部分场景下,单词是否大小写对任务的影响并不大。但是在部分特定场景,例如命名体识别(NER),则BERT-cased是更合适的。
在应用BERT预训练模型时,实际上就是迁移学习,所以用法就是2个:
- 特征提取(feature extraction)
- 微调(fine-tune)
下面我们会分别介绍这2种方法的使用。
2. BERT特征提取
特征提取非常简单,直接将单词序列输入到已经预训练好的BERT中,得到的输出即为单词以及句子的特征。
举个例子,以情感分析任务为例,假设有条句子”I love Beijing” ,它的情感为正面情感。在对这个句子通过BERT做特征提取时,首先使用WordPiece对它进行分词,得到单词列表:
Tokens = [ I, love, Beijing]
然后加上特殊token [CLS] 与 [SEP](它们的作用已在前面的章节进行过介绍,在此不再赘述):
Tokens = [ [CLS], I, love, Beijing, [SEP] ]
接下来,为了使得训练集中所有句子的长度保持一致,我们会指定一个“最大长度” max_length。对于长度小于此max_length的句子,对它进行补全;而对于超过了此max_length的句子,对它进行裁剪。假设我们这里指定了max_length=7,则对上面的句子进行补全时,使用特殊token [PAD],将句子长度补全到7。如:
Tokens = [ [CLS], I, love, Beijing, [SEP], [PAD], [PAD] ]
在使用了[PAD] 作为填充后,还需要一个指示标志,用于表示 [PAD] 仅是用于填充,不代表任何意义。这里用到了一个称为attention mask的列表来表示,它的长度等同于max_length。对于每条句子,如果对应位置的单词为[PAD],则attention mask此位置的元素取值为0,反之为1。例如,对于这个例子,attention mask的值为:
attention_mask = [ 1, 1, 1, 1, 1, 0, 0 ]
最后,由于模型无法直接识别单词,仅能识别数字,所以还需要将单词映射为数字。我们首先会对整个单词库做一个词典,每个单词都有对应的1个序号(此序号为不重复的数字)。在这个例子中,假设我们已经构建了一个字典,则对应的这些单词的列表为:
token_ids = [101, 200, 303, 408, 102, 0, 0]
其中 101 即对应的是 [CLS] 的序号,200对应的即是单词“I”的序号,依此类推。
在准备好以上数据后,即可将 token_ids 与 attention_mask 输入到预训练好的BERT模型中,便得到了每个单词的embedding表示。如下图所示:

在上图中,为了表述方便,在输入时还是使用的单词,但是需要注意的是:实际的输入是token_ids 与 attention_mask。在经过了BERT的处理后,即得到了每个单词的嵌入表示(此嵌入表示包含了整句的上下文)。假设我们使用的是BERT-base模型,则每个词嵌入的维度即为768。
在上一章介绍BERT训练的时候我们提到过,可以使用E([CLS]) 来表示整个句子的信息。并将它输入到前馈网络与softmax中进行分类任务。但是仅使用 E([CLS]) 作为整个句子的表示信息也并非总是最好的办法。一种更高效的方法是给所有token的嵌入表示做平均或是池化(pooling),来代表整句的信息。具体方法我们后续会做介绍。
至此,我们已经介绍了使用预训练BERT做特征提取的过程,下面介绍如何使用python lib库来实现此过程。
3. Hugging Face transformers
Hugging Face是一个专注于NLP技术的公司,提供了很多预训练的模型以及数据集供直接使用,包括很多大家可能已经了解过的模型,例如bert-base、roberta、gpt2等等。其官网地址为: https://huggingface.co/
除了提供预训练的模型外,Hugging Face提供的transformers库也是在NLP社区非常热门的库。并且transformers的库同时支持pytorch与tensorflow。
安装transformers 库非常简单:
!pip install transformers import transformers
transformers.__version__
'4.11.3'
4. 生成BERT Embedding
前面我们介绍了BERT特征提取,下面通过代码实现此功能。
首先引入包并下载所需模型:
from transformers import TFBertModel, BertTokenizer
import tensorflow as tf # download bert-base-uncased model
model = TFBertModel.from_pretrained('bert-base-uncased')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
我们使用的是tensorflow,所以引入的是TFBertModel。如果有使用pytorch的读者,可以直接引入BertModel。
通过 from_pretrained() 方法可以下载指定的预训练好的模型以及分词器,这里我们使用的是bert-base-uncased。前面对bert-based 有过介绍,它包含12个堆叠的encoder,输出的embedding维度为768。
对于所有可用预训练模型,可以通过Hugging face 官网查询[2]。
引入模型后,下面从一个例子来看输入数据的处理。
先对句子做分词,然后加上特殊token [CLS] 与 [SEP]。假设我们指定的max_length 为7,则继续补上 [PAD]:
sentence = 'I love Beijing' tokens = tokenizer.tokenize(sentence)
print(tokens) tokens = ['[CLS]'] + tokens + ['[SEP]']
print(tokens) tokens = tokens + ['[PAD]'] * 2
print(tokens) ['i', 'love', 'beijing']
['[CLS]', 'i', 'love', 'beijing', '[SEP]']
['[CLS]', 'i', 'love', 'beijing', '[SEP]', '[PAD]', '[PAD]']
然后根据tokens构造attention_mask:
attention_mask = [ 1 if t != '[PAD]' else 0 for t in tokens]
print(attention_mask) [1, 1, 1, 1, 1, 0, 0]
将所有tokens 转为 token id:
token_ids = tokenizer.convert_tokens_to_ids(tokens)
print(token_ids) [101, 1045, 2293, 7211, 102, 0, 0]
将token_ids 与 attention_mask 转为tensor:
token_ids = tf.convert_to_tensor(token_ids)
token_ids = tf.reshape(token_ids, [1, -1]) attention_mask = tf.convert_to_tensor(attention_mask)
attention_mask = tf.reshape(attention_mask, [1, -1])
在这些步骤后,我们下一步即可将它们输入到预训练的模型中,得到embedding:
output = model(token_ids, attention_mask = attention_mask)
print(output[0].shape, output[1].shape) (1, 7, 768) (1, 768)
根据TFModel的API说明[3],这2个返回分别为:
- BERT模型最后一层的输出。由于输入有7个tokens,所以对应有7个token的Embedding。其对应的维度为(batch_size, sequence_length, hidden_size)
- 输出层中第1个token(这里也就是对应 的[CLS])的Embedding,并且已被一个线性层 + Tanh激活层处理。线性层的权重由NSP作业预训练中得到。其对应的维度为(batch_size, hidden_size)
4.1. 是否需要其他隐藏层输出
上面介绍了如何获取BERT最后一层的输出表示,要获取每层的表示也非常简单,仅需要添加参数 output_hidden_states=True 即可,例如:
output = model(token_ids, attention_mask = attention_mask, output_hidden_states=True)
不过这里有一点需要讨论的是:是否需要中间隐藏层的输出?还是仅使用最后一层的输出就足够了?
对于此问题,BERT的研究人员做了进一步研究。在命名体识别任务中,研究人员除了使用BERT最后一层的输出作为提取的特征外,还尝试使用了其他层的输出(例如通过拼接的方式进行组合),并得到以下F1分数:
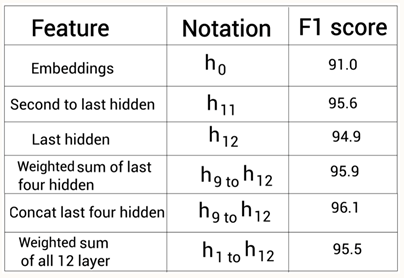
Fig.1 Sudharsan Ravichandiran. Getting Started with Google BERT[4]
从这个结果可以看到,在使用最后4层(h9到h12层的拼接)的输出时,能得到比仅使用h12的输出更高的F1分数96.1。所以仅使用BERT最后一层的输出并非在所有场景下都是最好的选择,有时候也需要尝试使用其他层的输出,观察是否能得到更好的效果。
5. Fine-Tune BERT
上面介绍了BERT在迁移学习中的一种用法——特征提取(feature extraction)。除此之外,还有另一种用法,称为微调(Fine-tune)。两者主要的区别在于:特征提取直接获取预训练的BERT模型的输出作为特征,对预训练的BERT的模型参数不会有任何改动。而微调是将预训练的BERT与下游任务结合使用,在训练过程中预训练BERT模型的参数会被更新。
下面我们会介绍如何将预训练的BERT与下游任务结合起来,对预训练的BERT进行Fine-Tune。一般下游任务包括:文本分类、自然语言推理(Natural language inference)、命名体识别(NER)、问答系统(QA)等。这里我们主要介绍一种文本分类任务:情感分析。
5.1. 文本分类
以情感分析为例,我们的数据集是一条条文本,每条文本对应一个label。Label可以是1或0,分别代表“正面情感”和“负面情感“。情感分析的任务是:输入一条文本,判断这条文本的label是0还是1。也就是说,这是一个二分类任务。当然,这只是一个最简单的情感分析任务。稍微复杂点的例如:label有多个分类,分别代表“高兴”、“悲伤”、“愤怒”等等,是一个多分类任务。再复杂一点的例如:除了判断这个文本的情感外,还要判断这个情感的强度,例如,label为“高兴”、程度为3。在这里我们仅介绍最简单的情感分类,label只有0和1。
还是以之前的句子“I love Beijing”为例,我们对句子做分词、加上特定tokens、补全到max_length、生成token_id、attention_mask,并送入到BERT。得到最后一层输出的 [CLS]
的Embedding表示。此时E([CLS]) 包含了整个句子的表示,所以可以将此表示输入到前馈网络与softmax中,输出类别概率,用于判断这个句子属于哪个类别。此时:
- 若是使用的Fine-Tune,则在训练过程中,预训练的BERT模型的参数与前馈网络的参数都会得到更新;
- 若是使用的Feature-Extraction,则在训练过程中,仅有前馈网络的参数会得到更新,预训练的BERT模型的参数不会更新
下面以IMDB数据集为例,介绍BERT fine-tune的方法。
首先引入依赖包、加载数据集、加载预训练的模型:
import tensorflow as tf
from tensorflow import keras
import tensorflow_datasets as tfds
import numpy as np
from transformers import TFBertForSequenceClassification, BertTokenizerFast # load dataset
imdb_train, df_info = tfds.load(name='imdb_reviews', split='train', with_info=True, as_supervised=True)
imdb_test = tfds.load(name='imdb_reviews', split='test', as_supervised=True) # load pretrained bert model
model = TFBertForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)
tokenizer = BertTokenizerFast.from_pretrained("bert-base-uncased")
这里需要注意的是,我们使用的是TFBertForSequenceClassification和BertTokenizerFast。TFBertForSequenceClassification是包装好的类,专门用于做分类,由1层bert、1层Dropout、1层前馈网络组成,其定义可以参考官网[5]。BertTokenizerFast 也是一个方便的tokenizer类,会比BertTokenizer更快一些。
对输入数据做分词:
# tokenize every sequence
def bert_encoder(review):
encoded = tokenizer(review.numpy().decode('utf-8'), truncation=True, max_length=150, pad_to_max_length=True)
return encoded['input_ids'], encoded['token_type_ids'], encoded['attention_mask'] bert_train = [bert_encoder(r) for r, l in imdb_train]
bert_label = [l for r, l in imdb_train] bert_train = np.array(bert_train)
bert_label = tf.keras.utils.to_categorical(bert_label, num_classes=2) print(bert_train.shape, bert_label.shape)
(25000, 3, 150) (25000, 2)
训练数据的格式是(sentence, label),对每个sentence通过BertTokenizerFast做tokenize后,会直接得到input_ids, token_type_ids 以及attention_mask,它们便是需要输入到BERT的格式。最后将它们转为numpy 数组。
bert_train的维度为(25000, 3, 150),即分别对应了:
- 数据总条数;
- 每条数据对应的input_ids、token_type_ids、attention_mask
- Max_length(指定的长度为150)
将训练集继续分割为训练集与验证集:
# create training and validation splits
from sklearn.model_selection import train_test_split x_train, x_val, y_train, y_val = train_test_split(bert_train,
bert_label,
test_size=0.2,
random_state=42)
print(x_train.shape, y_train.shape)
(20000, 3, 150) (20000, 2)
进一步对输入数据进行处理:
def example_to_features(input_ids,attention_masks,token_type_ids,y):
return {"input_ids": input_ids,
"attention_mask": attention_masks,
"token_type_ids": token_type_ids},y train_ds = tf.data.Dataset.from_tensor_slices((tr_reviews, tr_masks, tr_segments, y_train)).map(example_to_features).shuffle(100).batch(16)
valid_ds = tf.data.Dataset.from_tensor_slices((val_reviews, val_masks, val_segments, y_val)).map(example_to_features).shuffle(100).batch(16)
TFBertForSequenceClassification的输入格式(除label外的输入)可以以有多种形式提供,这里使用的是字典的形式。具体格式说明可以参考官方文档的说明[5]。
指定训练参数并进行训练:
optimizer = tf.keras.optimizers.Adam(learning_rate=2e-5)
loss = tf.keras.losses.BinaryCrossentropy(from_logits=True)
model.compile(optimizer=optimizer, loss=loss, metrics=['accuracy']) bert_history = model.fit(train_ds, epochs=4, validation_data=valid_ds) Epoch 1/4
1250/1250 [==============================] - 701s 551ms/step - loss: 0.4085 - accuracy: 0.8131 - val_loss: 0.3011 - val_accuracy: 0.8718
Epoch 2/4
1250/1250 [==============================] - 689s 551ms/step - loss: 0.2104 - accuracy: 0.9186 - val_loss: 0.3252 - val_accuracy: 0.8858
Epoch 3/4
1250/1250 [==============================] - 689s 551ms/step - loss: 0.1105 - accuracy: 0.9622 - val_loss: 0.4201 - val_accuracy: 0.8816
Epoch 4/4
1250/1250 [==============================] - 689s 551ms/step - loss: 0.0696 - accuracy: 0.9774 - val_loss: 0.4153 - val_accuracy: 0.8876
这里作为演示,仅训练了4轮。从验证集的准确率来看,还有上升的趋势,所以理论上还可以增加epoch轮数。
6. 总结
BERT预训练模型与迁移学习的结合使用,当前仍是NLP各类应用以及比赛的主流。不过,当前我们仅介绍了BERT预训练模型中最基本的一种:bert-base。除此之外,BERT还有很多的变种,例如allbert、roberta、electra、spanbert等等,分别用于不同的场景。下一章我们继续介绍BERT的这些变种。
References
[1] https://github.com/google-research/bert
[2] Pretrained models — transformers 4.11.2 documentation (huggingface.co)
[3] BERT — transformers 4.12.0.dev0 documentation (huggingface.co)
[4] Getting Hands-On with BERT | Getting Started with Google BERT (oreilly.com)
[6] https://learning.oreilly.com/library/view/advanced-natural-language/9781800200937/Chapter_4.xhtml
NLP与深度学习(六)BERT模型的使用的更多相关文章
- NLP与深度学习(四)Transformer模型
1. Transformer模型 在Attention机制被提出后的第3年,2017年又有一篇影响力巨大的论文由Google提出,它就是著名的Attention Is All You Need[1]. ...
- NLP与深度学习(五)BERT预训练模型
1. BERT简介 Transformer架构的出现,是NLP界的一个重要的里程碑.它激发了很多基于此架构的模型,其中一个非常重要的模型就是BERT. BERT的全称是Bidirectional En ...
- 在NLP中深度学习模型何时需要树形结构?
在NLP中深度学习模型何时需要树形结构? 前段时间阅读了Jiwei Li等人[1]在EMNLP2015上发表的论文<When Are Tree Structures Necessary for ...
- NLP与深度学习(一)NLP任务流程
1. 自然语言处理简介 根据工业界的估计,仅有21% 的数据是以结构化的形式展现的[1].在日常生活中,大量的数据是以文本.语音的方式产生(例如短信.微博.录音.聊天记录等等),这种方式是高度无结构化 ...
- 『深度应用』NLP机器翻译深度学习实战课程·零(基础概念)
0.前言 深度学习用的有一年多了,最近开始NLP自然处理方面的研发.刚好趁着这个机会写一系列NLP机器翻译深度学习实战课程. 本系列课程将从原理讲解与数据处理深入到如何动手实践与应用部署,将包括以下内 ...
- 『深度应用』NLP机器翻译深度学习实战课程·壹(RNN base)
深度学习用的有一年多了,最近开始NLP自然处理方面的研发.刚好趁着这个机会写一系列NLP机器翻译深度学习实战课程. 本系列课程将从原理讲解与数据处理深入到如何动手实践与应用部署,将包括以下内容:(更新 ...
- 【转】[caffe]深度学习之图像分类模型AlexNet解读
[caffe]深度学习之图像分类模型AlexNet解读 原文地址:http://blog.csdn.net/sunbaigui/article/details/39938097 本文章已收录于: ...
- [caffe]深度学习之图像分类模型VGG解读
一.简单介绍 vgg和googlenet是2014年imagenet竞赛的双雄,这两类模型结构有一个共同特点是go deeper.跟googlenet不同的是.vgg继承了lenet以及alexnet ...
- 深度学习 vs. 概率图模型 vs. 逻辑学
深度学习 vs. 概率图模型 vs. 逻辑学 摘要:本文回顾过去50年人工智能(AI)领域形成的三大范式:逻辑学.概率方法和深度学习.文章按时间顺序展开,先回顾逻辑学和概率图方法,然后就人工智能和机器 ...
- 时间序列深度学习:seq2seq 模型预测太阳黑子
目录 时间序列深度学习:seq2seq 模型预测太阳黑子 学习路线 商业中的时间序列深度学习 商业中应用时间序列深度学习 深度学习时间序列预测:使用 keras 预测太阳黑子 递归神经网络 设置.预处 ...
随机推荐
- Web应用安全防护-WAF
web应用开发中不可避免需要考虑web应用的安全问题,那么常见的安全风险包含哪些呢? Web应用常见的安全风险 在web应用开发中可能存在以下的安全风险: 安全风险Top 10 A1:2017-注入 ...
- mysql 8.0 1405的坑
因版本差异:password 可能对应:authentication_string字段 不行的话再尝试一下,并且修改下密码类型 ALTER USER 'root'@'%' IDENTIFIED WI ...
- js日期处理多少/月/天以前
var date = new Date(); var year = date.getFullYear(); var month = (date.getMonth() + 1) > 10 ? da ...
- Python安装环境配置和多版本共存
Python安装环境配置和多版本共存 1.环境变量配置: (1) 右键点击"计算机",然后点击"属性" (2) 然后点击"高级系统设置" ( ...
- 灵魂画手:漫画图解 SSH
OpenSSL 本身是一个软件库,这个软件被广泛的应用在系统服务器当中,他的主要功能是在网络通信的过程中,保证数据的一致性以及数据传输过程中的安全性.软件本身是由C语言编写,这使得他具备了跨平台的特性 ...
- (九)羽夏看C语言——C++番外篇
写在前面 此系列是本人一个字一个字码出来的,包括示例和实验截图.本人非计算机专业,可能对本教程涉及的事物没有了解的足够深入,如有错误,欢迎批评指正. 如有好的建议,欢迎反馈.码字不易,如果本篇文章 ...
- Vs code自动生成Doxygen格式注释
前言 程序中注释的规范和统一性的重要性不言而喻,本文就推荐一种在用vscode编写代码时自动化生成标准化注释格式的方法,关于Doxygen规范及其使用可查看博文 代码注释规范之Doxygen. ...
- Python - repr()、str() 的区别
总的来说 str():将传入的值转换为适合人阅读的字符串形式 repr():将传入的值转换为 Python 解释器可读取的字符串形式 传入整型 # number resp = str(1) print ...
- 整合ehcache缓存
一.分布式集群,多态服务器相同的代码,均衡压力: 二. 1.导包,ehcache适用mybatis的jar包: 2.映射配置文件中配置: 3.ehcache配置文件 4.使用代码和mybatis自带的 ...
- java 笔记一些
面象对的umv 视图示例: 用户 银行 帐户 怎么关联 帐户代码: 文件命名 Account package com.atuigu.exer4; import org.omg.CORBA.PUB ...