关于hive的基础
Hive基础
1、引入原因
对存在HDFS上的文件或HBase中的表进行查询时,是要手工写一堆MapReduce代码
对于统计任务,只能由懂MapReduce的程序员才能搞定
事实上,许多底层细节实际上进行的是从一个任务到下一个任务的重复性工作
使用MapReduce的时候遇到复杂的统计逻辑,这种MapReduce任务需要等上一个任务跑完再接下一个任务,而判断一个任务是否跑完,则是通过检测HDFS上对应输出文件是否生成_SUCCESS文件来判断,然后利用shell脚本去把它们串起来,整个流程就很费时费力,而使用hive的sql形式则会相对来说更简单。
Hive不仅提供了一个熟悉SQL的用户所能快速使用熟悉的编程模型,还消除了大量的通用代码, 让开发者可以花费很少的精力就完成大量的工作
2、hive是什么
Hive是一个SQL解析引擎,将SQL语句转译成MR Job,然后再在Hadoop平台上运行,达到快速开发的目的。
Hive中的表是纯逻辑表,就只是表的定义等,即表的元数据。本质就是Hadoop的目录/文件, 达到了元数据与数据存储分离的目的
Hive本身不存储数据,它完全依赖HDFS和MapReduce。
Hive的内容是读多写少,不支持对数据的改写和删除
Hive从0.14版本后已经可以修改更新了,不过这个功能一般默认关闭的,也都是针对与内部表数据
- Hive中没有定义专门的数据格式,由用户指定,需要指定三个属性:列分隔符、行分隔符、读取文件数据的方法
常见的行分隔符:空格、\t、\001
常见的列分隔符:\n
读取文件数据方法:TextFile、SequenceFile(二进制)、RCFile
- 注:SequenceFile(二进制):是hadoop提供的一种二进制文件,以<k,v>形式序列化到文件中,java Writeable 接口进行序列化和反序列化。
- 注:RCFile是Hive专门推出的,一种面向列的数据格式。
通常都会先对要统计的数据提前做处理,将内容中可能会出现的分隔符先处理掉,防止处理数据的时候因为内容中包含对应分隔符而导致数据丢失,分隔符一般是需要打日志的时候大家约定好,所以不同公司的分割符都各有区别。
总结:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。本质是将HQL转化成MapReduce程序:1、Hive处理的数据存储在HDFS,2、Hive分析数据底层的实现是MapReduce,3、执行程序运行在YARN上。
Hive的优缺点
优点:
1)操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)
2)避免了去写MapReduce,减少开发人员的学习成本。
3)Hive的执行延迟比较高,因此Hive常用于对实时性要求不高的场合的数据分析;
4)Hive优势在于处理大数据,对于处理小数据没有优势
5)Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
缺点:
1)Hive的HQL表达能力有限
(1)迭代式算法无法表达
(2)数据挖掘方面不擅长
2)Hive的效率比较低
(1)Hive自动生成的MapReduce作业,通常情况下不够智能化
(2)Hive调优比较困难,粒度较粗
3、Java和Hive:词频统计算法
Java:
package org.myorg;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class WordCount {
public static classMapextendsMapper<LongWritable, Text, Text,
IntWritable>
private final static IntWritable one = newIntWritable(1);
private Text word = newText();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new String Tokenizer(line);.
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
}
public static class Reduce extends Reducer<Text, IntWritable, Text,
IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context
context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val
values) {
sum += val.get();
context.write(key, new IntWritable(sum));
public static void main (String[]args)throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFo rmat.addInputPath(job, new Path(args[0]));
File0utputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
}
}
hive:
create table docs(line String);
load data inpath 'docs' overwrite into table docs;
create table word_counts as
select word,count(1) as cnt
from (select explode(split(line,'\s')) as word from docs) w
group by word
order by word;
上述两个例子都是尽可能简单的方法将文件中的内容分割成单词,也就是按照空格进行划分的。借助java API可以定制和调整一个算法实现的每个细节,不过大多数情况下,用户都不需要这个级别的控制,而hive则可以更容易快速的实现大多数情况的需求。
4、Hive中的SQL与传统SQL区 别
| HQL | SQL | |
|---|---|---|
| 数据存储 | HDFS、Hbase | Local FS |
| 数据格式 | 用户自定义 | 系统决定 |
| 数据更新 | 不支持(把之前的数据覆盖) | 支持 |
| 索引 | 有(0.8版之后增加) | 有 |
| 执行 | MapReduce(select * from table) | Executor |
| 执行延迟 | 高 | 低 |
| 可扩展性 | 高(UDF、UDAF,UDTF) | 低 |
| 数据规模 | 大(数据大于TB) | 小 |
| 数据检查 | 读时模式 | 写时模式 |
hive和关系数据库存储文件的系统不同,hive使用的是hadoop的HDFS(hadoop的分布式文件系统),关系数据库则是服务器本地的文件系统;
hive使用的计算模型是mapreduce,而关系数据库则是自己设计的计算模型;
关系数据库都是为实时查询的业务进行设计的,而hive则是为海量数据做数据挖掘设计的,实时性很差
Hive很容易扩展自己的存储能力和计算能力,这个是继承hadoop的,而关系数据库在这个方面要比Hive差很多
UDF:直接应用于select语句,通常查询的时候,需要对字段做一些格式化处理(如:大小写转换)《特点:一进一出,一比一的关系。》
UDAF:多对一的场景,如聚合时
UDTF:一对多的场景
以上都是用户自定义函数
读时模式:只有在读的时候才会检查、解析字段和schema(数据结构表达)优点:加载数据的时候非常迅速,因为在写的过程中是不需要解析数据
写时模式:则是在写入的时候就会检查解析等,缺点:写的慢,需要建立索引、压缩、数据一致性、字段检查等等 优点:读的时候会得到优化
5、Hive体系架构

1)用户接口:Client
CLI(hive shell)、JDBC/ODBC(Hive的客户端,用户通过java连接至Hive Server)、WEBUI(浏览器访问hive,在公司一般通过游览器的方式操作)
2)元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
3)Hadoop
使用HDFS进行存储,使用MapReduce进行计算。
Hive数据以文件形式存储在HDFS的指定目录下
Hive语句生成查询计划,由MapReduce调用执行
4)驱动器:Driver
(1)解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
(2)编译器(Physical Plan):将AST编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
6、Hive执行流程
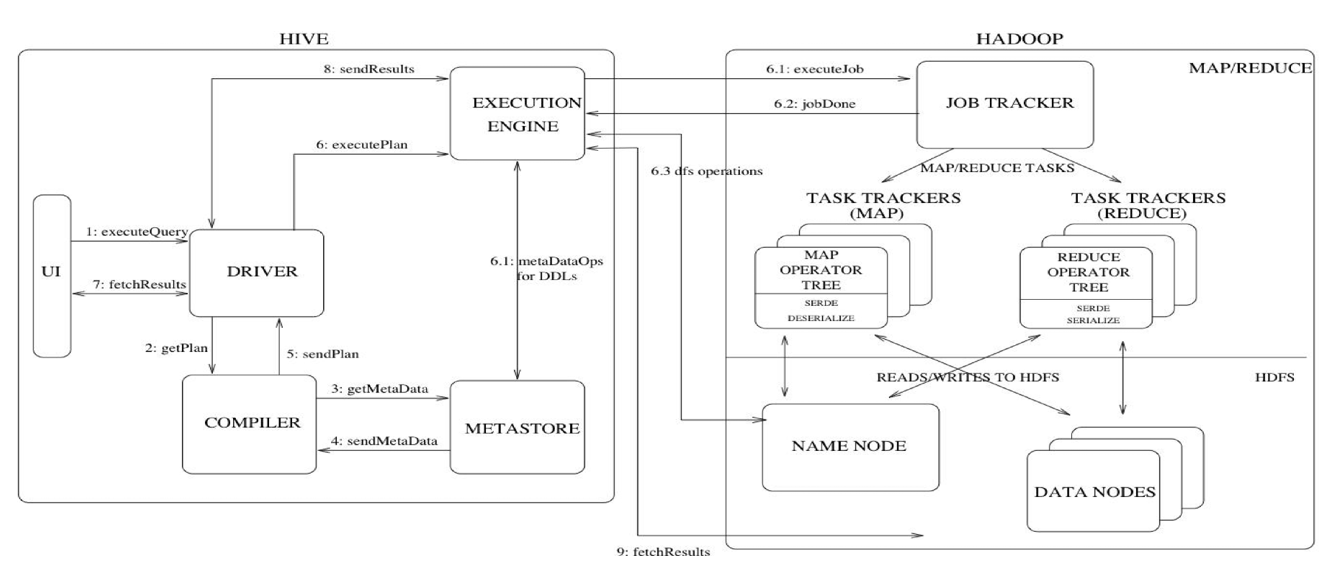
1)流程概述
完整流程:通过UI或者Client的形式提交任务(使用JDBC的形式,只是多了一层Thrift Server,它们三种形式本质上都是一样的),首先用户的executeQuery(查询命令),会由driver进行解析(解析过程为:driver会将执行的语句先交给compiler(解析器)生成抽象语法树,检查SQL语法是否正确即getPlan,然后通过metastore(元数据存储,一般存储在mysql里面)getMetaData(获取元数据信息),用来检查语句中的表是否存在,再将检查信息sendMetaData(发送元数据信息)到compiler,compiler会综合检查信息,sendPlan到driver。)如果语句解析都没问题,driver则通过将语句整理为executePlan(执行计划)到executionEngine(执行引擎),由executionEngine提交MR任务到Hadoop的JobTracker,同时也会通过metastore获取对应的元数据信息,再由Hadoop来执行相应的MR任务后再将结果返回到executionEngine,executionEngine再将结果sendResults(发送结果)到driver,driver最后整理结果fetchResults(获取结果)到任务提交端。
简述:Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
Hive 在执行一条 HQL 的时候,会经过以下步骤:
1、语法解析:Antlr 定义 SQL 的语法规则,完成 SQL 词法,语法解析,将 SQL 转化为抽象语法树 AST Tree;
2、语义解析:遍历 AST Tree,抽象出查询的基本组成单元 QueryBlock;
3、生成逻辑执行计划:遍历 QueryBlock,翻译为执行操作树 OperatorTree,其中是一个个操作符Operator;
操作符 Operator 是 Hive 的最小处理单元,每个操作符代表一个 HDFS 操作或者 MapReduce 作业
4、优化逻辑执行计划:逻辑层优化器进行 OperatorTree 变换,合并不必要的 ReduceSinkOperator,减少 shuffle 数据量;
5、生成物理执行计划:遍历 OperatorTree,翻译为 MapReduce 任务;
6、优化物理执行计划:物理层优化器进行 MapReduce 任务的变换,生成最终的执行计划。
最后Hive 通过 ExecMapper 和 ExecReducer 执行 MapReduce 程序,执行模式有本地模式和分布式两种模式
2)Hive操作符列表
| 操作符 | 描述 |
|---|---|
| TableScanOperator | 扫描hive表数据 |
| ReduceSinkOperator | 创建将发送到Reducer端的<Key,Value>对 |
| JoinOperator | Join两份数据 |
| SelectOperator | 选择输出列 |
| FileSinkOperator | 建立结果数据,输出至文件 |
| FilterOperator | 过滤输入数据 |
| GroupByOperator | Group By语句 |
| MapJoinOperator | /* + mapjoin(t) */ |
| LimitOperator | Limit语句 |
| UnionOperator | Union语句 |
3)Hive 编译器的工作职责
(1)Parser:将 HQL 语句转换成抽象语法树(AST:Abstract Syntax Tree)
(2)Semantic Analyzer:将抽象语法树转换成查询块
(3)Logic Plan Generator:将查询块转换成逻辑查询计划
(4)Logic Optimizer:重写逻辑查询计划,优化逻辑执行计划
(5)Physical Plan Gernerator:将逻辑计划转化成物理计划(MapReduce Jobs)
(6)Physical Optimizer:选择最佳的 Join 策略,优化物理执行计划
4)优化器类型
| 名称 | 作用 |
|---|---|
| ② SimpleFetch0pt imizer | 优化没有GroupBy表达式的聚合查询 |
| ② MapJoinProcessor | MapJoin,需要SQL中提供hint, 0. 11版本已不用 |
| ② BucketMapJoinOptimizer | BucketMapJoin |
| ② GroupByOptimizer | Map端聚合 |
| ① ReduceSinkDeDupl ication | 合并线性的OperatorTree中partition/sort key 相同的reduce |
| ① PredicatePushDown | 谓词前置 |
| ① CorrelationOptimizer | 利用查询中的相关性,合并有相关性的Job,HIVE- -2206 |
| ColumnPruner | 字段剪枝 |
注:上表中带①符号的,优化目的都是尽量将任务合并到一个 Job 中,以减少 Job 数量,带②的优化目的是尽量减少 shuffle 数据量
5)Join实现过程
SELECT pv.pageid, u.age FROM page_view pv JOIN user u ON pv.userid = u.userid;
对于上述 join 操作实现过程:
Map:
1、以 JOIN ON 条件中的列作为 Key,如果有多个列,则 Key 是这些列的组合
2、以 JOIN 之后所关心的列作为 Value,当有多个列时,Value 是这些列的组合。在 Value 中还会包含表的 Tag 信息,用于标明此 Value 对应于哪个表
3、按照 Key 进行排序
Shuffle:
1、根据 Key 的值进行 Hash,并将 Key/Value 对按照 Hash 值推至不同对 Reduce 中
Reduce:
1、 Reducer 根据 Key 值进行 Join 操作,并且通过 Tag 来识别不同的表中的数据
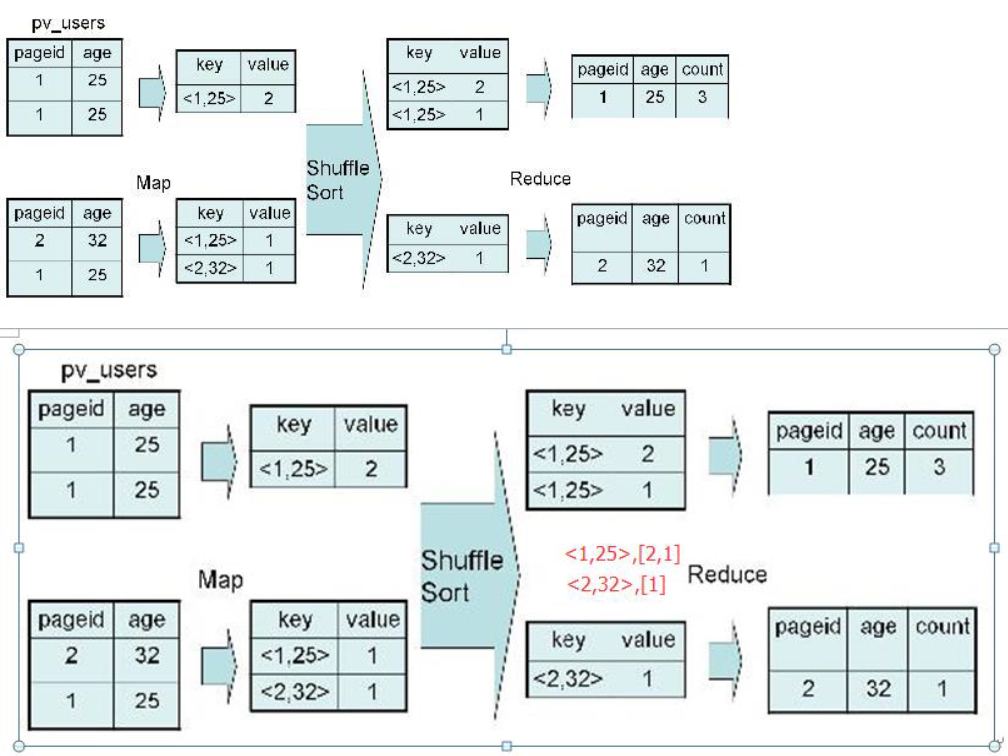
6)GroupBy实现过程
SELECT pageid, age, count(1) FROM pv_users GROUP BY pageid, age;
对于上述 group by 操作实现过程:
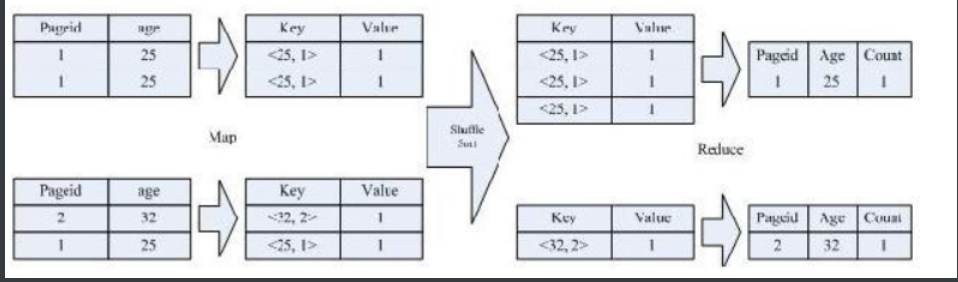
7)Distinct实现过程
按照 age 分组,然后统计每个分组里面的不重复的 pageid 有多少个
SELECT age, count(distinct pageid) FROM pv_users GROUP BY age;
对于上述 distinct操作实现过程如下图,该 SQL 语句会按照 age 和 pageid 预先分组,进行 distinct 操作。然后会再按 照 age 进行分组,再进行一次 distinct 操作
7、Hive数据管理
hive的表本质就是Hadoop的目录/文件
hive默认表存放路径一般都是在你工作目录的hive目录里面,按表名做文件夹分开,如果你有分区表的话,分区值是子文件夹,可以直接在其它的M/R job里直接应用这部分数据
| Name | HDFS Directory | |
|---|---|---|
| Table | mobile_user | /lbs/mobile_user |
| Partition | action = insight, dt= 20131020 pc m app | /lbs/mobile_user/action=insight/dt=20131020 |
| Bucket | clusted by user into 32 buckets | /lbs/mobile_user/action=insight/dt=20131020/part-00031 |
1)Hive数据类型
Hive 表中的列支持以下基本数据类型:《数仓中最常用的是string和DECIMAL》
| 大类 | 类型 |
|---|---|
| Integers(整型) | TINYINT—1 字节的有符号整数SMALLINT—2 字节的有符号整数INT—4 字节的有符号整数BIGINT—8 字节的有符号整数 |
| Boolean(布尔型) | BOOLEAN—TRUE/FALSE |
| Floating point numbers(浮点型) | FLOAT— 单精度浮点型DOUBLE—双精度浮点型 |
| Fixed point numbers(定点数) | DECIMAL—用户自定义精度定点数,比如 DECIMAL(7,2) |
| String types(字符串) | STRING—指定字符集的字符序列VARCHAR—具有最大长度限制的字符序列CHAR—固定长度的字符序列 |
| Date and time types(日期时间类型) | TIMESTAMP — 时间戳TIMESTAMP WITH LOCAL TIME ZONE — 时间戳,纳秒精度DATE—日期类型 |
| Binary types(二进制类型) | BINARY—字节序列 |
| Hive 数据类型 | Java 数据类型 | 长度 | 例子 |
|---|---|---|---|
| TINYINT | byte | 1byte 有符号整数 | 20 |
| SMALINT | short | 2byte 有符号整数 | 20 |
| INT | int | 4byte 有符号整数 | 20 |
| BIGINT | long | 8byte 有符号整数 | 20 |
| BOOLEAN | boolean | 布尔类型,true 或者 false | TRUE FALSE |
| FLOAT | float | 单精度浮点数 | 3.14159 |
| DOUBLE | double | 双精度浮点数 | 3.14159 |
| STRING | string | 字符系列。可以指定字符集。可以使用单引号或者双引号。 | ‘now is the time’ “for all good men” |
| TIMESTAMP | 时间类型 | ||
| BINARY | 字节数组 |
注:
对于 Hive 的 String 类型相当于数据库的 varchar 类型,该类型是一个可变的字符串,不过它不能声明其中最多能存储多少个字符,理论上它可以存储 2GB 的字符数。
TIMESTAMP 和 TIMESTAMP WITH LOCAL TIME ZONE 的区别如下:
1、TIMESTAMP WITH LOCAL TIME ZONE:用户提交时间给数据库时,会被转换成数据库所在的时区来保存。查询时则按照查询客户端的不同,转换为查询客户端所在时区的时间。
2、TIMESTAMP :提交什么时间就保存什么时间,查询时也不做任何转换。
复杂类型:
| 类型 | 描述 | 示例 |
|---|---|---|
| STRUCT | 类似于对象,是字段的集合,字段的类型可以不同,可以使用《名称.字段名》方式进行访问 | STRUCT ('xiaoming', 12 , '2018-12-12') |
| MAP | 键值对的集合,可以使用《名称[key]》的方式访问对应的值 | map('a', 1, 'b', 2) |
| ARRAY | 数组是一组具有相同类型和名称的变量的集合,这些变量称为数组的元素,每个数组元素都有一个编号,编号从零开始。可以使用《名称[index]》访问对应的值 | ARRAY('a', 'b', 'c', 'd') |
示例:
如下给出一个基本数据类型和复杂数据类型的使用示例:
1)创建本地测试文件 test.txt
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijing yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,chao yang_beijing
注意:MAP,STRUCT 和 ARRAY 里的元素间关系都可以用同一个字符表示,这里用“_”。
2)Hive 上创建测试表 test
create table test(
name string,
friends array<string>,
children map<string, int>,
address struct<street:string, city:string>)
row format delimited
fields terminated by ','
collection items terminated by '_'
map keys terminated by ':'
lines terminated by '\n';
字段解释:
row format delimited fields terminated by ',' -- 列分隔符
collection items terminated by '_' --MAP STRUCT 和 ARRAY 的分隔符(数据分割符号)<这意味着map,struct,array等的分隔符必须保持一致>
map keys terminated by ':' -- MAP 中的 key 与 value 的分隔符
lines terminated by '\n'; -- 行分隔符<这个默认是/n,可以不写>
3)导入文本数据到测试表
hive (default)>load data local inpath "/opt/module/datas/test.txt" into table test;
4)访问三种集合列里的数据,以下分别是 ARRAY,MAP,STRUCT 的访问方式
hive (default)>select friends[1],children['xiao song'],address.city from test where name="songsong";
OK
_c0 _c1 city lili 18 beijing
Time taken: 0.076 seconds, Fetched: 1 row(s)
2)Hive存储格式
Hive数据以文件形式存储在HDFS的指定目录下
Hive语句生成查询计划,由MR调用执行
文件存储的格式:
1.textfile
默认格式,建表时不指定默认为这个格式
存储方式:行存储
优点:可以直接读取
缺点:磁盘开销大 数据解析开销大。压缩的text文件 hive无法进行合并和拆分
2.sequencefile
二进制文件,以<key,value>的形式序列化到文件中
存储方式:行存储
缺点:存储空间消耗最大
优点:可分割 压缩,全表时查询效率高
一般选择block压缩,文件和Hadoop api中的mapfile是相互兼容的。EQUENCEFILE将数据以<key,value>的形式序列化到文件中。序列化和反序列化使用Hadoop 的标准的Writable 接口实现。key为空,用value 存放实际的值, 这样可以避免map 阶段的排序过程。三种压缩选择:NONE, RECORD, BLOCK。 Record压缩率低,一般建议使用BLOCK压缩。使用时设置参数,
SET hive.exec.compress.output=true;
SET io.seqfile.compression.type=BLOCK; -- NONE/RECORD/BLOCK
create table test2(str STRING)
STORED AS SEQUENCEFILE;
3.rcfile
一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。 理论上具有高查询效率(但hive官方说效果不明显,只有存储上能省10%的空间,所以不好用,可以不用)。
RCFile结合行存储查询的快速和列存储节省空间的特点
1)同一行的数据位于同一节点,因此元组重构的开销很低;
- 块内列存储,可以进行列维度的数据压缩,跳过不必要的列读取。
查询过程中,在IO上跳过不关心的列。实际过程是,在map阶段从远端拷贝仍然拷贝整个数据块到本地目录,也并不是真正直接跳过列,而是通过扫描每一个row group的头部定义来实现的。但是在整个HDFS Block 级别的头部并没有定义每个列从哪个row group起始到哪个row group结束。所以在读取所有列的情况下,RCFile的性能反而没有SequenceFile高。
优点:压缩快, 快速列存取, 读记录尽量涉及到的block最少 ,读取需要的列只需要读取每个row group 的头部定义。
缺点:读取全量数据的操作 性能可能比sequencefile没有明显的优势。但是如果指定一列的话,效率最高
4.orc
存储方式:数据按行分块 每块按照列存储
压缩快 快速列存取
效率比rcfile高,是rcfile的改良版本
5.自定义格式
用户可以通过实现inputformat和 outputformat来自定义输入输出格式。
总结
textfile 存储空间消耗比较大,并且压缩的text 无法分割和合并 查询的效率最低,可以直接存储,加载数据的速度最高
sequencefile 存储空间消耗最大,压缩的文件可以分割和合并 查询效率高,需要通过text文件转化来加载
rcfile 存储空间最小,查询的效率最高 ,需要通过text文件转化来加载,加载的速度最低
注:hive默认本地数据库(用来存储元数据):derby(单用户模式常用),而一般开发是用mysql(多用户模式、远程服务模式)
指定存储格式
通常在创建表的时候使用 stored as 参数指定:
create table 表名(字段名 类型,字段名 类型)
row format delimited
fields terminated by 字段分隔符
lines terminated by 列分隔符
STORED AS 存储格式;
2)类型转换
Hive 的原子数据类型是可以进行隐式转换的,类似于 Java 的类型转换,例如某表达式使用 INT 类型,TINYINT 会自动转换为 INT 类型,但是 Hive 不会进行反向转化,例如,某表达式使用 TINYINT 类型,INT 不会自动转换为 TINYINT 类型,它会返回错误,除非使用 CAST 操作。
隐式转换
Hive 中基本数据类型遵循以下的层次结构,按照这个层次结构,子类型到祖先类型允许隐式转换。例如 INT 类型的数据允许隐式转换为 BIGINT 类型。额外注意的是:按照类型层次结构允许将 STRING 类型隐式转换为 DOUBLE 类型。
隐式类型转换规则如下
(1)任何整数类型都可以隐式地转换为一个范围更广的类型,如 TINYINT 可以转换成 INT,INT 可以转换成 BIGINT。
(2)所有整数类型、FLOAT 和 STRING 类型<内容必须是数值>都可以隐式地转换成 DOUBLE。
(3)TINYINT、SMALLINT、INT 都可以转换为 FLOAT。
(4)BOOLEAN 类型不可以转换为任何其它的类型。
CAST 操作
可以使用 CAST 操作显示进行数据类型转换
例如 CAST('1' AS INT)将把字符串'1' 转换成整数 1;
如果强制类型转换失败,如执行CAST('X' AS INT),表达式返回空值 NULL。
8、Hive的四种数据模型
1)数据表
Table(内部表)
一般说的hive表都是指内部表,默认创建的表都是所谓的内部表,有时也被称为管理表。(因为这种表,Hive 会(或多或少地)控制着数据的生命周期。管理表不适合和其他工具共享数据。)Hive中的内部表在HDFS中都有相应的目录用来存储表的数据,目录可以通过${HIVE_HOME}/conf/hive-site.xml配置文件中的 hive.metastore.warehouse.dir属性来配置,一般默认的值是/user/hive/warehouse(这个目录在 HDFS上),如果我有一个表test,那么在HDFS中会创建/user/hive/warehouse/test目录(这里假定hive.metastore.warehouse.dir配置为/user/hive/warehouse);test表所有的数据都存放在这个目录中,当然,外部表可以配置其它hdfs来映射文件。可以使用如下命令来查看表对应hdfs的文件:dfs -ls /hive/warehouse/ods_uba.db/test;
External table(外部表)
Hive中的外部表和表很类似,只不过是建表时可以指定加载的hdfs目录,也可以不指定后头根据需要再进行加载。如果外部表使用hive命令删除表,对应的hdfs文件是不会被删除。外部表比较灵活,不止可以关联到hdfs文件,也可以关联到hbse表。其建表和内部表稍有不同,但是可用的数据类型都是一样的。因为当表被设定是外部表, Hive就认为并非其完全拥有这份数据。删除该表不会删除掉这份数据,只会将描述表的元数据信息会被删除掉。
内部表和外部表的区别:
(1)、外部表创建时要添加EXTERNAL,外部表查询是只是去关联hdfs文件,并按照分割符号转成对应的字段
(2)、外部表删除表后,hdfs文件不会被删除。同理,外部表删除分区后,hdfs文件也不会被删除,针对误操作提高了容错。
(3)、内部表删除时候,不仅表结构会被删除,数据也会被删除,没法恢复,而外部表删除后重新建立时,数据就自动恢复了,不会真的删除掉数据,针对误操作提高了容错。
2)分区表
Partition(分区表)
在Hive中,Partition表中的一个Partition对应于表下的一个目录,所有的Partition的数据都存储在对应的目录中。分区表主要是为了辅助查询,缩小查询范围,加快数据的检索速度和对数据按照一定的规格和条件进行管理。《工作中常见的是分区表,日期(date),按照天分区;来源(source),三端app,m(mobile手机端页面,一般是分享页面),pc》——什么时候采用分区?主要是结合业务,经常要用到的分析条件(业内术语一般称“口径”)在where条件里面经常要被用到的,可以按照条件进行设计分区。(设计表之后也要尽量根据数据来优化业务表,提高数据使用效率!)
分区表实际上就是对应一个HDFS文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过 WHERE 子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
Bucket(分桶表)
在Hive中,table可以拆分成partition,而table和partition还可以通过‘CLUSTERED BY’进一步拆分,即分桶,bucket中的数据可以通过SORT BY排序;
set hive.enforce.bucketing = true可以自动控制上一轮的reduce的数量从而适配bucket的个数,当然,用户也可以自主设置mapred.reduce.tasks去适配bucket个数;分桶的原理就是对指定的列计算其hash,根据hash值切分数据,目的是为了并行,每一个桶对应一个文件(注意和分区的区别)。
比如将lin_test表start_time列分散至16个桶中,首先对id列的值计算hash,
对应hash值为0和16的数据存储的HDFS目录为:/user/hive/warehouse/lin_test/start_date=20191218/part-00000;
而hash值为2的数据存储的HDFS 目录为:/user/hive/warehouse/start_date=20191218/part-00002。
bucket的重要作用是:数据sampling(采样),提升某些查询操作的效率,例如mapside join。不过一般情况下不建议将分桶设置太大,以免小文件过多引起其它更多的问题,用好分桶才能真的有助于提高计算的效率。
hive>select * from student tablesample(bucket 1 out of 2 on id);
tablesample是抽样语句,语法:tablesample(bucket x out of y)
y一般是table总bucket数的倍数或者因子。hive根据y的大小决定抽样的比例,用总bucket数除y的值,即得到需要抽样的个数,x则代表从第几个bucket开始抽取,每次抽取间隔的bucket数就是y的值。
分区提供一一个隔离数据和优化查询的便利的方式。不过,并非所有的数据集都可形成合理的分区,特别是之前所提到过的要确定合适的划分大小这个疑虑。分桶是将数据集分解成更容易管理的若干部分的另一个技术。例如,假设有个表的一级分区是dt,代表日期,二级分区是user_ id, 那么这种划分方式可能会导致太多的小分区。回想下,如果用户是使用动态分区来创建这些分区的话,那么默认情况下,Hive会限制动态分区可以创建的最大分区数,用来避免由于创建太多的分区导致超过了文件系统的处理能力以及其他一些问题。因此,如下命令可能会执行失败:
hive> CREATE TABLE weblog (url STRING,source_ ip STRING)
hive> PARTITIONED BY (dt STRING, user_ id INT) ;
hive> FROM raw_ weblog
hive> INSERT OVERWRITE TABLE page_ view PARTITION(dt='2020-06-08', user_ id)
hive> SELECT server_ name, url, source_ ip, dt, user_ id;
不过,如果我们对表weblog进行分桶,并使用user_ id 字段作为分桶字段,则字段值会根据用户指定的值进行哈希分发到桶中。同一个user_ id下的记录通常会存储到同一个桶内。假设用户数要比桶数多得多,那么每个桶内就将会包含多个用户的记录:
hive> CREATE TABLE weblog (user_ id INT, url STRING, source_ ip STRING)
hvie> PARTITIONED BY (dt STRING)
hvie> CLUSTERED BY (user_ id) INTO 96 BUCKETS;
不过,将数据正确地插人到表的过程完全取决于用户自己。CREATE TABLE语句中所规定的信息仅仅定义了元数据,而不影响实际填充表的命令。下面介绍如何在使用INSERT ... TABLE语句时,正确地填充表。首先,我们需要设置一个属性来强制Hive 为目标表的分桶初始化过程设置-一个 正确的reducer 个数。然后我们再执行一个查询来填充分区。例如:
hive> SET hive. enforce .bucketing = true;
hive> FROM raw_ logs
hive> INSERT OVERWRITE TABLE weblog
hive> PARTITION (dt='2009-02-25' )
hive> SELECT user_ id, url, source_ ip WHERE dt='2020-02-25';
如果我们没有使用hive.enforce. bucketing属性,那么我们就需要自己设置和分桶个数相匹配的reducer个数,例如,使用set mapred.reduce.tasks=96,然后在INSERT语句中的SELECT语句后增加CLUSTER BY语句。
分桶优点
1、因为桶的数量是固定的,所以它没有数据波动。桶对于抽样再合适不过。如果两个表都是按照user_ id 进行分桶的话,那么Hive可以创建一个逻辑上正确的抽样。
2、分桶有利于执行高效的map-side JOIN:如果所有表中的数据是分桶的,那么对于大表,在特定的情况下同样可以使用这个优化。简单地说,表中的数据必须是按照ON语句中的键进行分桶的,而且其中一张表的分桶的个数必须是另一张表分桶个数的若干倍。当满足这些条件时,那么Hive可以在map阶段按照分桶数据进行连接。因此这种情况下,不需要先获取到表中所有的内容,之后才去和另一张表中每个分桶进行匹配连接。这个优化同样默认是没有开启的。需要设置参数hive.optimize.bucketmapJOIN为true才可以开启此优化:
set hive.opt imize.bucke tmapJOIN=true;
如果所涉及的分桶表都具有相同的分桶数,而且数据是按照连接键或桶的键进行排序的,那么这时Hive可以执行一个更快的分类-合并连接(sort-merge JOIN)。同样地,这个优化需要需要设置如下属性才能开启:
set hive.input. format=org.apache.hadoop. hive.ql.io.Bucketi zedHiveInputFormat;
set hive.optimi ze.bucketmapj oin=true;
set hive.optimize.bucketmapj oin. sortedmerge=true;
关于hive的基础的更多相关文章
- 揭秘FaceBook Puma演变及发展——FaceBook公司的实时数据分析平台是建立在Hadoop 和Hive的基础之上,这个根能立稳吗?hive又是sql的Map reduce任务拆分,底层还是依赖hbase和hdfs存储
在12月2日下午的“大数据技术与应用”分论坛的第一场演讲中,来自全球知名互联网公司——FaceBook公司的软件工程师.研发经理邵铮就带来了一颗重磅炸弹,他将为我们讲解FaceBook公司的实时数据处 ...
- Hive框架基础(二)
* Hive框架基础(二) 我们继续讨论hive框架 * Hive的外部表与内部表 内部表:hive默认创建的是内部表 例如: create table table001 (name string , ...
- Hive框架基础(一)
* Hive框架基础(一) 一句话:学习Hive有毛用? 那么解释一下 毛用: * 操作接口采用类SQL语法,提供快速开发的能力(不会Java也可以玩运算) * 避免了去写MapReduce,减少开发 ...
- Hive 这些基础知识,你忘记了吗?
Hive 其实是一个客户端,类似于navcat.plsql 这种,不同的是Hive 是读取 HDFS 上的数据,作为离线查询使用,离线就意味着速度很慢,有可能跑一个任务需要几个小时甚至更长时间都有可能 ...
- Hive HiveQL基础知识及常用语句总结
基础语句 CREATE DROP 建表.删表 建表 -------------------------------------- -- 1. 直接建表 ------------------------ ...
- Hive[2] 基础介绍
2.3 Hive 内部介绍: P44 $HIVE_HOME/lib 下的 jar 文件是具体的功能部分:(CLI模块) 其它组件,Thrift 服务,可以远程访问其他进程功能:也有使用 JDBC 和 ...
- Hive SQL基础操作
创建表 hive 查看本地的文件#Can execute local commands within CLI, place a command in between ! and ;!cat data/ ...
- [hive] hiveql 基础操作
1. 显示当前的数据库信息 直接修改hive.site.xml ,永久显示 2. 建表,模糊显示表信息 drop table 表名称: --删除表 show tables ;--显示所有表 sh ...
- Hive(一)基础知识
一.Hive的基本概念 (安装的是Apache hive 1.2.1) 1.hive简介 Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表, 并提供类 SQ ...
随机推荐
- IOS IAP 自动续订 之 利用rabbitmq延时队列自动轮询检查是否续订成功
启用针对自动续期订阅的服务器通知: - 官方地址: - https://help.apple.com/app-store-connect/#/dev0067a330b - 相关字段, 相关类型地址: ...
- SQL Server 将两行或者多行拼接成一行数据
一个朋友,碰到一个问题. 就是查询出来的结果集,需要每隔三行.就将这三行数据以此拼接为一行显示.起初我想着用ROW_NUMBER加CASE WHEN去做,发现结果并非我预期那样. 结果如下: 由于别人 ...
- TVM如何训练TinyML
TVM如何训练TinyML 机器学习研究人员和从业人员对"裸机"(低功耗,通常没有操作系统)设备产生了广泛的兴趣.尽管专家已经有可能在某些裸机设备上运行某些模型,但是为各种设备优化 ...
- OpenCV读写视频文件解析
OpenCV读写视频文件解析 一.视频读写类 视频处理的是运动图像,而不是静止图像.视频资源可以是一个专用摄像机.网络摄像头.视频文件或图像文件序列. 在 OpenCV 中,VideoCapture ...
- 『动善时』JMeter基础 — 41、使用JMeter连接数据库(MySQL)
目录 1.为什么要使用JMeter连接数据库 2.JMeter连接数据库的前提 3.JDBC连接配置组件界面介绍 4.JMeter连接数据库演示 (1)测试计划内包含的元件 (2)测试计划中添加链接数 ...
- 04:CSS(02)
溢出属性 p { height: 100px; width: 50px; border: 3px solid red; /*overflow: visible; !*默认就是可见 溢出还是展示*!*/ ...
- 惊呆了,Spring Boot居然这么耗内存!
Spring Boot总体来说,搭建还是比较容易的,特别是Spring Cloud全家桶,简称亲民微服务,但在发展趋势中,容器化技术已经成熟,面对巨耗内存的Spring Boot,小公司表示用不起.如 ...
- csp-s模拟测试42「世界线·时间机器·密码」
$t3$不会 世界线 题解 题目让求的就是每个点能到点的数量$-$出度 设每个点能到的点为$f[x]$ 则$f[x]=x \sum\limits_{y}^{y\in son[x]} U f[y]$ 用 ...
- Serverless Web Function 实践教程(一):快速部署 Node.js Web 服务
作为目前广受欢迎的 Web 服务开发语言,Node.js 提供了众多支持 HTTP 场景的相关功能,可以说是为 Web 构建而生.因此,基于 Node.js,也诞生了多种 Web 服务框架,它们对 N ...
- 整合Spring Cloud Stream Binder与GCP Pubsub进行消息发送与接收
我最新最全的文章都在南瓜慢说 www.pkslow.com,欢迎大家来喝茶! 1 前言 之前的文章<整合Spring Cloud Stream Binder与RabbitMQ进行消息发送与接收& ...