Python爬虫下载酷狗音乐
1、Python下载酷狗音乐
1.1、前期准备
要有rquests、re、json包,如果不存在,先用pip install安装
1.2、分析
1.2.1、第一步
首先我们先进入首页并搜索你要查询的歌手,进入查询的页面,查看页面源代码,发现并没有这个列表数据,这里就不展示了,页面源代码没有发现想要的数据,那就来看network网络请求中的数据
1.2.2、第二步
打开网络请求,刷新页面,找到需要的请求
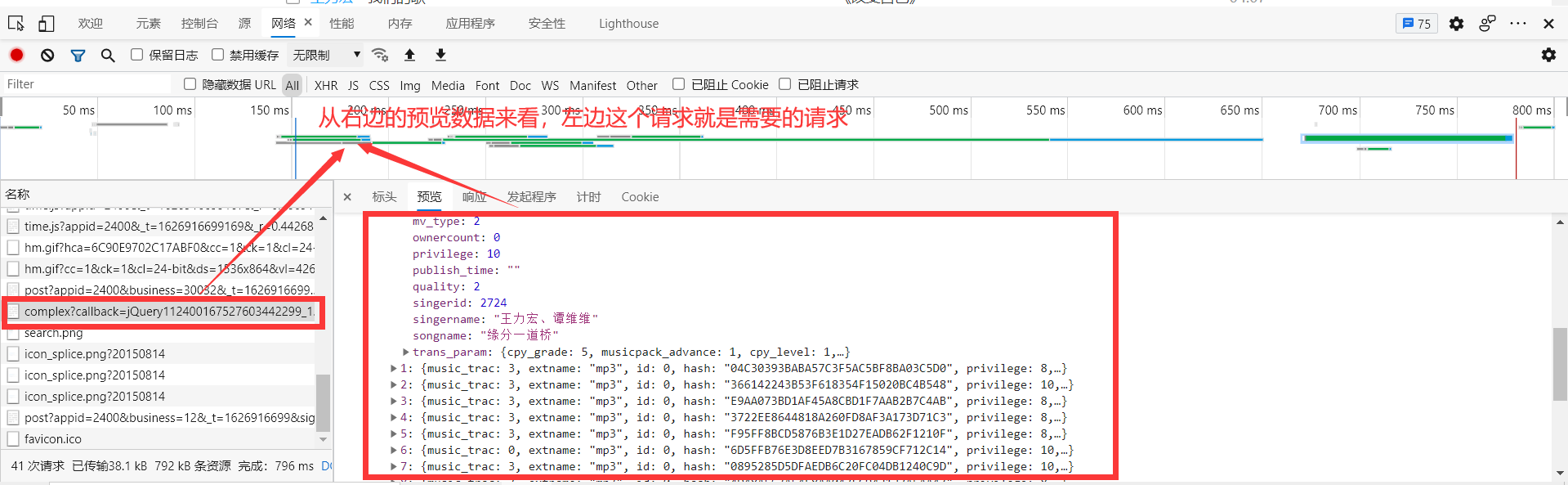
打开标头查看url中携带的数据
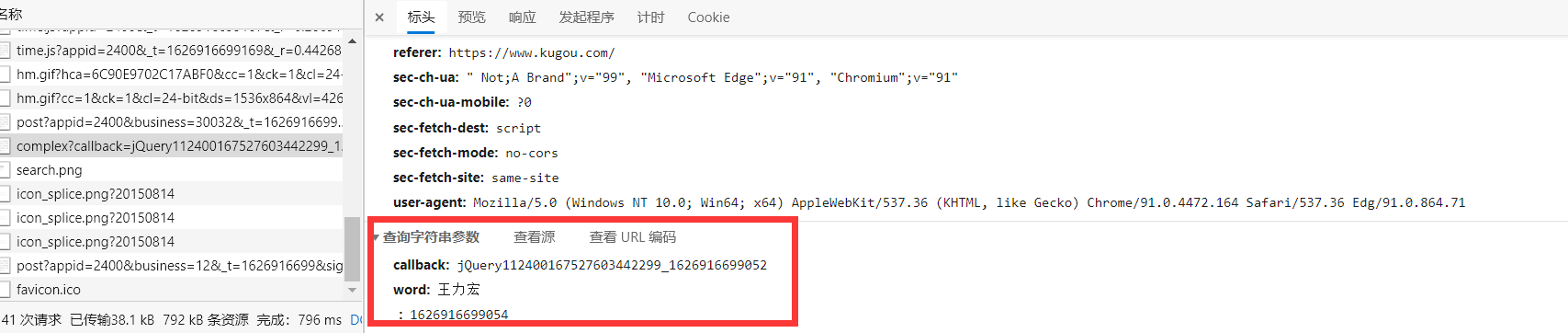
通过查看参数可知,不仅仅存在着我们搜索的内容,还有两个其它的参数callback 和 _ 两个参数,这乍一看还挺懵的,想着是不是有什么脚本进行了加密什么的,后面通过测试,发现这两给参数是一个随机给出的随机值,将这两个参数固定修改搜索的歌手,发现能够查询到我们需要的内容。所有接下来可以进行我们的第三步
1.2.3、第三步
随便点击一首歌曲,进入听歌页面,发现还是老套路,在页面源代码中没有发现需要的MP3音乐文件,所有又需要看network网络请求中的数据
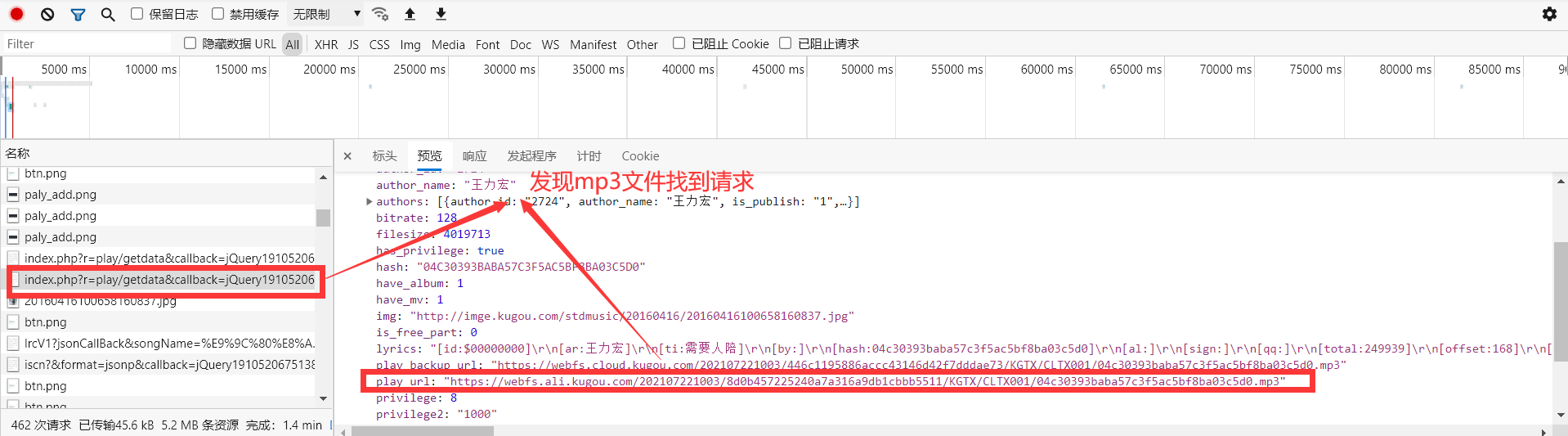
打开标头查看url中携带的数据
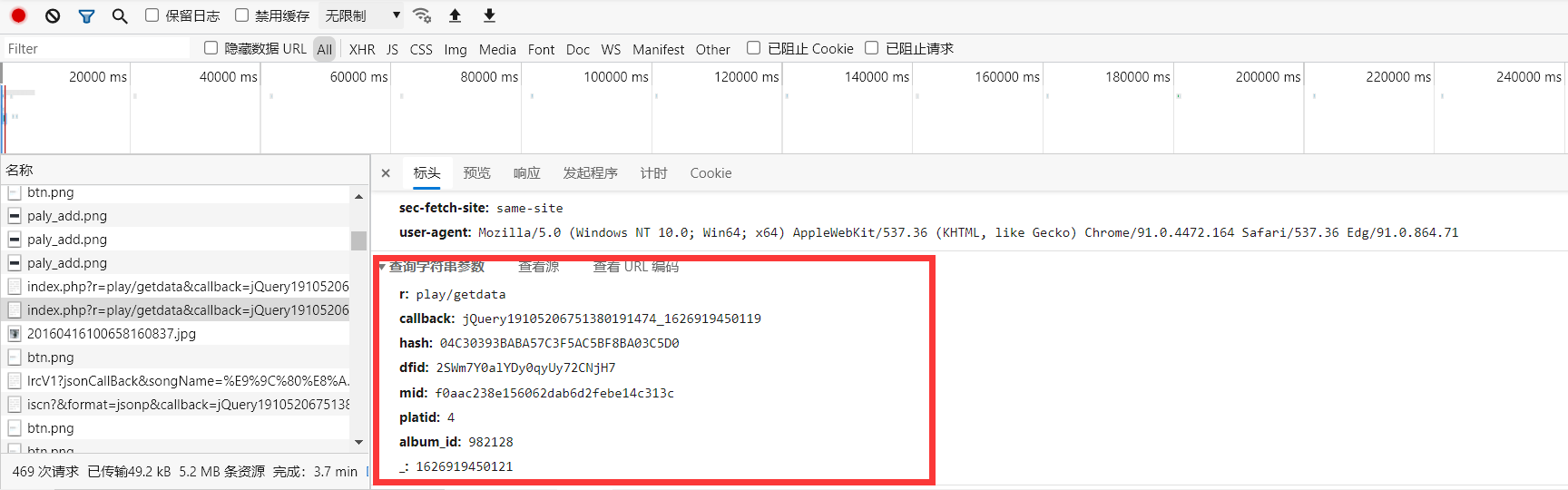
查看携带的参数,发现有很多,不过没事,通过分析可以发现只有hash和album_id是变值,其它的都是跟第二步中的callback 和 _ 这个参数一样,是可以固定下来的,我们只需关心hash和album_id这两个参数
通过分析可以知道,第二步中的请求中有我们需要的这两个参数,如下
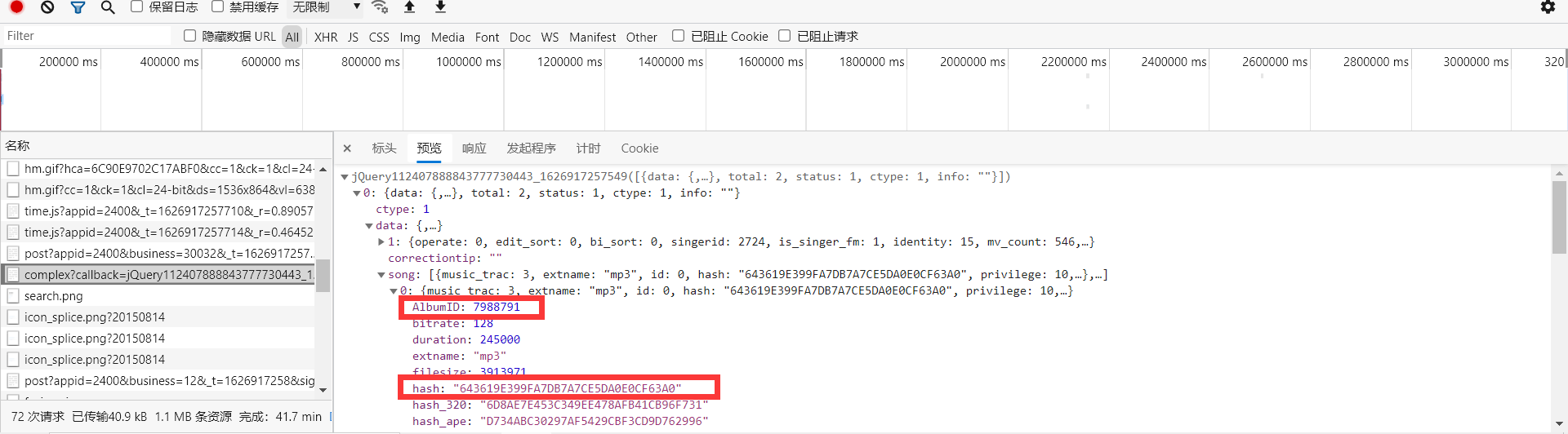
找到了要下载音乐的所有需要的东西,接下来可以进行我们的第四步
1.2.4、第四步
访问找的两个求,查看返回的数据信息
第二步的请求
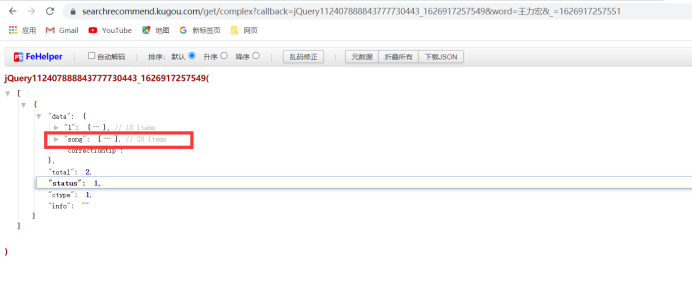
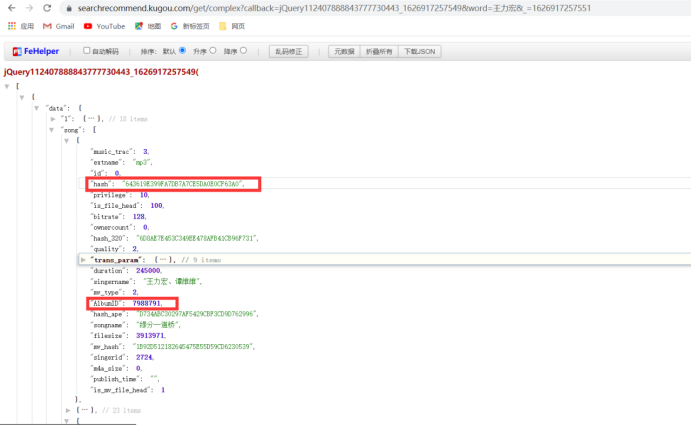
通过分析发现hash和album_id这两个参数存在song中所有我们需要将这个song给取出来
第三步的请求
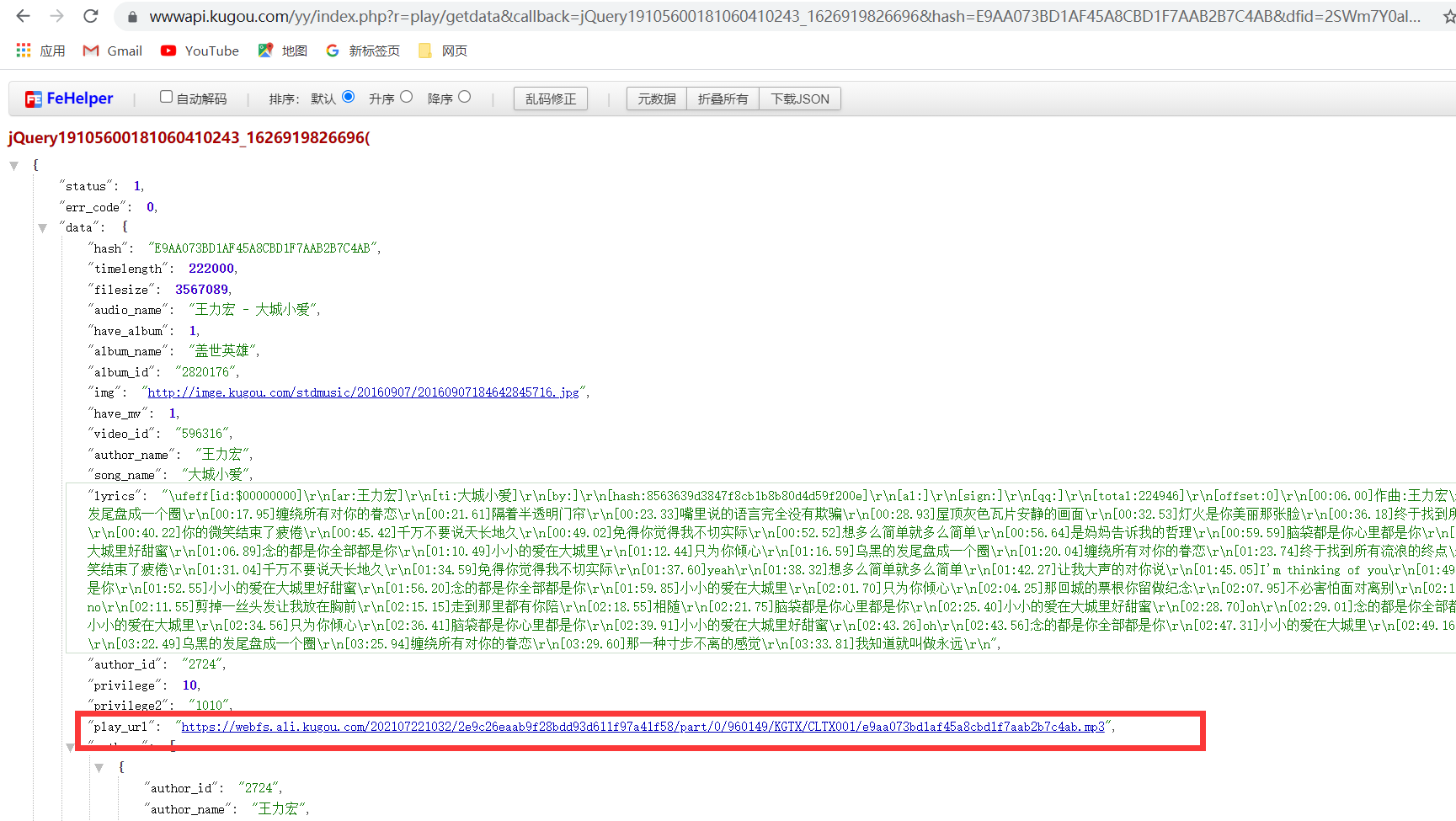
通过分析发现mp3文件在data中,所有需要将data提取出来
至此所有的分析都完成了,可以直接上代码了
1.3、代码实现
import requests
import json
import re
url = "https://searchrecommend.kugou.com/get/complex?callback=jQuery112409589811716312686_1626852436130&word=周杰伦&_=1626852436132"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.70",
"referer": "https://www.kugou.com/"
}
resp = requests.get(url, headers=headers)
p1 = re.compile(r'jQuery.*?[({].*?"data":.*?"song":(.*?),"correctiontip"', re.S)
songs = re.findall(p1, resp.text)[0]
songs = json.loads(songs)
for song in songs:
title = song['songname']
AlbumID = song['AlbumID']
song_hash = song['hash']
child_url = f"https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery191053318263960215_1626866592344&hash={song_hash}&dfid=1tXkst0i97Rq4RW0pz15GjrP&mid=3196606d7d3ff0207a473da58e0b44b3&platid=4&album_id={AlbumID}&_=1626866592346"
child_resp = requests.get(child_url, headers=headers)
child_resp.encoding="utf-8"
obj = re.compile(r'jQuery.*?[({].*?"data":(.*?)}[)]', re.S)
child_song = re.findall(obj, child_resp.text)[0]
child_song = child_song.replace("\\", "")
child_song_src = json.loads(child_song)["play_url"]
child_song_resp = requests.get(child_song_src)
with open("音乐/"+title+".mp3", mode="wb") as f:
f.write(child_song_resp.content)
print(title+"下载完成!!!")
print("okok")
1.4、运行结果
下载周杰伦的歌,改变url去查询你喜欢的歌手
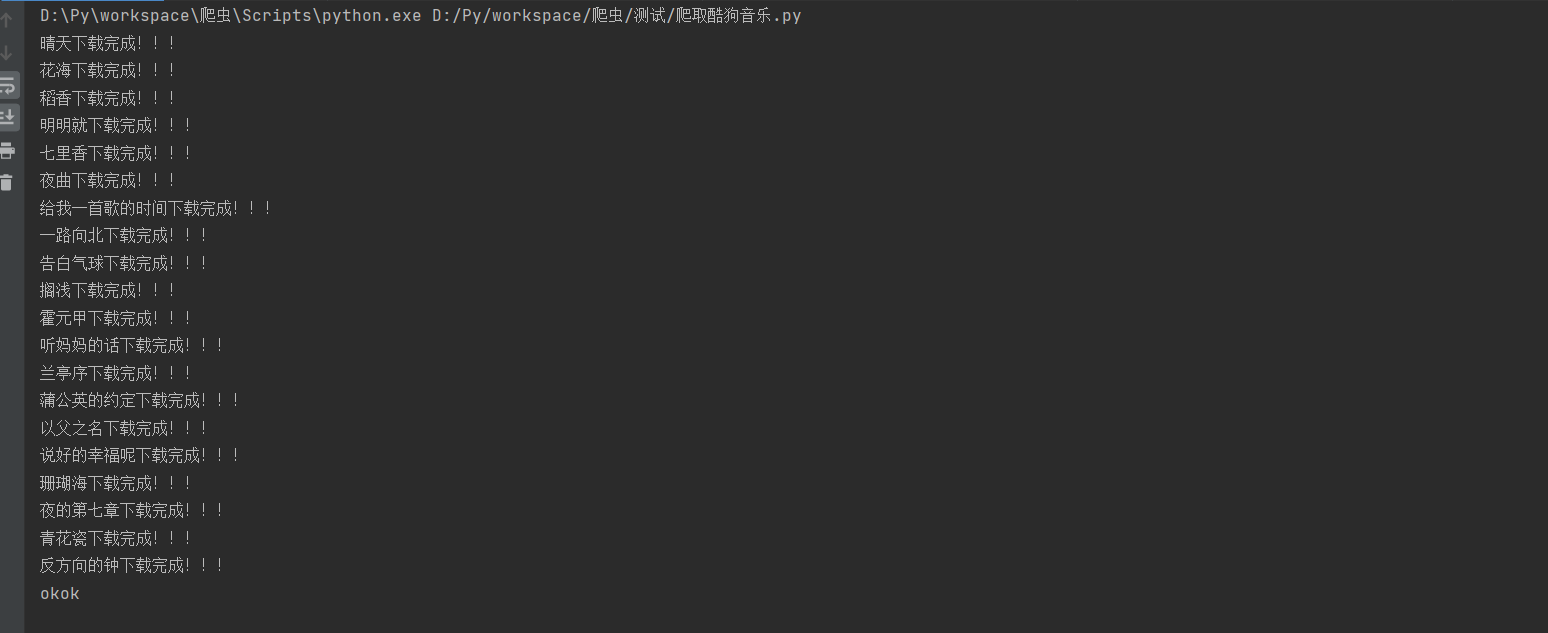
因为网页版只有20首歌,所以就只有这么多
在本地文件中查看
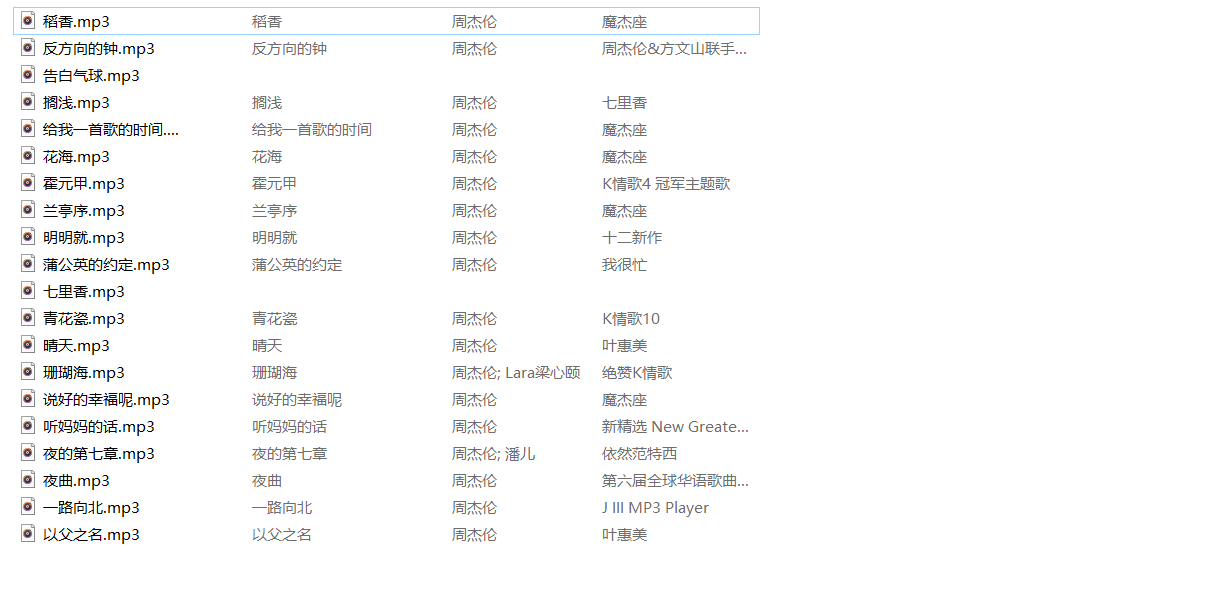
测试完成,歌曲下载成功
Python爬虫下载酷狗音乐的更多相关文章
- Python 应用爬虫下载酷狗音乐
应用爬虫下载酷狗音乐 首先我们需要进入到这个界面 想要爬取这些歌曲链接,然而这个是一个假的网站,虽然单机右键进行检查能看到这些歌曲的链接,可进行爬取时,却爬取不到这些信息. 这个时候我们就应该换一种思 ...
- python爬取酷狗音乐排行榜
本文为大家分享了python爬取酷狗音乐排行榜的具体代码,供大家参考,具体内容如下
- 【Python3爬虫】下载酷狗音乐上的歌曲
经过测试,可以下载要付费下载的歌曲(n_n) 准备工作:Python3.5+Pycharm 使用到的库:requests,re,json,time,fakeuseragent 步骤: 打开酷狗音乐的官 ...
- Java爬取并下载酷狗音乐
本文方法及代码仅供学习,仅供学习. 案例: 下载酷狗TOP500歌曲,代码用到的代码库包含:Jsoup.HttpClient.fastJson等. 正文: 1.分析是否可以获取到TOP500歌单 打开 ...
- python爬取酷狗音乐
url:https://www.kugou.com/yy/html/rank.html 我们随便访问一个歌曲可以看到url有个hash https://www.kugou.com/song/#hash ...
- Python代码搜索并下载酷狗音乐
运行环境: Python3.5+Pycharm 实例代码: import requests,re keyword = input("请输入想要听的歌曲:") url = " ...
- Python爬虫:通过做项目,小编了解了酷狗音乐的加密过程
1.前言 小编在这里讲一下,下面的内容仅供学习参考,切莫用于商业活动,一经被相关人员发现,本小编概不负责!读者切记切记. 2.获取音乐播放列表 其实,这就是小编要讲的重点,因为就是这部分用到了加密. ...
- python使用beautifulsoup4爬取酷狗音乐
声明:本文仅为技术交流,请勿用于它处. 小编经常在网上听一些音乐但是有一些网站好多音乐都是付费下载的正好我会点爬虫技术,空闲时间写了一份,截止4月底没有问题的,会下载到当前目录,只要按照bs4库就好, ...
- 【python3】酷狗音乐及评论回复下载
新年快乐,上班第一天分享一个python源码,功能比较简单,就是实现酷狗音乐的音乐文件(包含付费音乐)和所有评论回复的下载. 以 米津玄師 - Lemon 为例, 以下为效果图: 1.根据关键词搜索指 ...
随机推荐
- HiCar SDK概述
HiCar SDK概述 HUAWEI HiCar SDK 是 HUAWEI HiCar(以下简称 HiCar )为汽车硬件设备提供的软件开发工具包,为汽车硬件厂商接入 HiCar 提供应用 API 接 ...
- MindSpore网络模型类
MindSpore网络模型类 Q:使用MindSpore进行模型训练时,CTCLoss的输入参数有四个:inputs, labels_indices, labels_values, sequence_ ...
- 自监督学习(Self-Supervised Learning)多篇论文解读(下)
自监督学习(Self-Supervised Learning)多篇论文解读(下) 之前的研究思路主要是设计各种各样的pretext任务,比如patch相对位置预测.旋转预测.灰度图片上色.视频帧排序等 ...
- 有了Java8的“+”真的可以不要StringBuilder了吗
最近在头条上看到一篇帖子,说Java8开始,字符串拼接时,"+"会被编译成StringBuilder,所以,字符串的连接操作不用再考虑效率问题了,事实真的是这样吗?要搞明白,还是要 ...
- csp-c模拟测试43「A·B·C」
B 题解 $f[i][(gcd(prime[j]*prime[k]\%P,P))]=\sum\limits_{k=1}^{k<=num} f[i-1][k]*phi(\frac{P}{prime ...
- 透彻详解(3)旁路电容100nF_0.1uF的由来计算
原文地址点击这里: 前一节我们已经详细解释了旁路电容在数字电路系统中所起的基本且重要作用,即储能与为高频噪声电流提供低阻抗路径,尽管还并未给旁路电容的这些功能概括一个"高大上"的名 ...
- 『心善渊』Selenium3.0基础 — 6、Selenium中使用XPath定位元素
目录 1.Selenium中使用XPath查找元素 (1)XPath通过id,name,class属性定位 (2)XPath通过标签中的其他属性定位 (3)XPath层级定位 (4)XPath索引定位 ...
- 学会使用Python的threading模块、掌握并发编程基础
threading模块 Python中提供了threading模块来实现线程并发编程,官方文档如下: 官方文档 添加子线程 实例化Thread类 使用该方式新增子线程任务是比较常见的,也是推荐使用的. ...
- Python UI自动化
Python3--Uiautomator2--Pytest--Alure使用 官方源码GitHub地址:https://github.com/openatx/uiautomator2 介绍 uiaut ...
- 浅读tomcat架构设计和tomcat启动过程(1)
一图甚千言,这张图真的是耽搁我太多时间了: 下面的tomcat架构设计代码分析,和这张图息息相关. 使用maven搭建本次的环境,贴出pom.xml完整内容: <?xml version=&qu ...