Jetpack—LiveData组件的缺陷以及应对策略 转至元数据结尾
一、前言
为了解决Android-App开发以来一直存在的架构设计混乱的问题,谷歌推出了Jetpack-MVVM的全家桶解决方案。作为整个解决方案的核心-LiveData,以其生命周期安全,内存安全等优点,甚至有逐步取代EventBus,RxJava作为Android端状态分发组件的趋势。
官网商城app团队在深度使用LiveData的过程中,也遇到了一些困难,尤其是在LiveData的观察者使用上踩到了不少坑,我们把这些经验在这里做一次总结与分享。
二、Observer到底可以接收多少次回调
2.1 为什么最多收到2个通知
这是一个典型的案例,在调试消息总线的场景时,我们通常会在消息的接收者那里打印一些log日志方便我们定位问题,然而日志的打印有时候也会给我们的问题定位带来一定的迷惑性,可以看下面的例子。
我们首先定义一个极简的ViewModel:
public class TestViewModel extends ViewModel {
private MutableLiveData<String> currentName;
public MutableLiveData<String> getCurrentName() {
if (currentName == null) {
currentName = new MutableLiveData<String>();
}
return currentName;
}
}
然后看下我们的activity代码;
public class JavaTestLiveDataActivity extends AppCompatActivity {
private TestViewModel model;
private String test="12345";
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_java_test_live_data);
model = new ViewModelProvider(this).get(TestViewModel.class);
test3();
model.getCurrentName().setValue("3");
}
private void test3() {
for (int i = 0; i < 10; i++) {
model.getCurrentName().observe(this, new Observer<String>() {
@Override
public void onChanged(String s) {
Log.v("ttt", "s:" + s);
}
});
}
}
}
大家可以想一下,这段程序运行的结果会是多少?我们创建了一个Livedata,然后对这个Livedata Observe了10次,每次都是new出不同的Observer对象,看上去我们对一个数据源做了10个观察者的绑定。当我们修改这个数据源的时候,我们理应有10条通知。运行一下看看执行结果:
2021-11-21 15:20:07.662 27500-27500/com.smart.myapplication V/ttt: s:3
2021-11-21 15:20:07.662 27500-27500/com.smart.myapplication V/ttt: s:3
奇怪,为什么我明明注册了10个观察者,但是只收到了2个回调通知?换种写法试试?
我们在Log的代码里增加一部分内容比如打印下hashCode再看下执行结果:
2021-11-21 15:22:59.377 27912-27912/com.smart.myapplication V/ttt: s:3 hashCode:217112568
2021-11-21 15:22:59.377 27912-27912/com.smart.myapplication V/ttt: s:3 hashCode:144514257
2021-11-21 15:22:59.377 27912-27912/com.smart.myapplication V/ttt: s:3 hashCode:72557366
2021-11-21 15:22:59.377 27912-27912/com.smart.myapplication V/ttt: s:3 hashCode:233087543
2021-11-21 15:22:59.377 27912-27912/com.smart.myapplication V/ttt: s:3 hashCode:22021028
2021-11-21 15:22:59.377 27912-27912/com.smart.myapplication V/ttt: s:3 hashCode:84260109
2021-11-21 15:22:59.377 27912-27912/com.smart.myapplication V/ttt: s:3 hashCode:94780610
2021-11-21 15:22:59.377 27912-27912/com.smart.myapplication V/ttt: s:3 hashCode:240593619
2021-11-21 15:22:59.377 27912-27912/com.smart.myapplication V/ttt: s:3 hashCode:207336976
2021-11-21 15:22:59.378 27912-27912/com.smart.myapplication V/ttt: s:3 hashCode:82154761
这次结果就正常了,其实对于很多消息总线的调试都有类似的问题。
实际上对于Log系统来说,如果他判定时间戳一致的情况下,后面的Log内容也一致,那么他就不会重复打印内容了。这里一定要注意这个细节,否则在很多时候,会影响我们对问题的判断。再回到我们之前没有添加hashCode的代码,再仔细看看也就明白了:只是Log打印了两条而已,但是通知是收到了10次的,为啥打印两条?因为你的时间戳一致,后续的内容也一致。
2.2 奇怪的编译优化
事情到这还没结束,看下图:
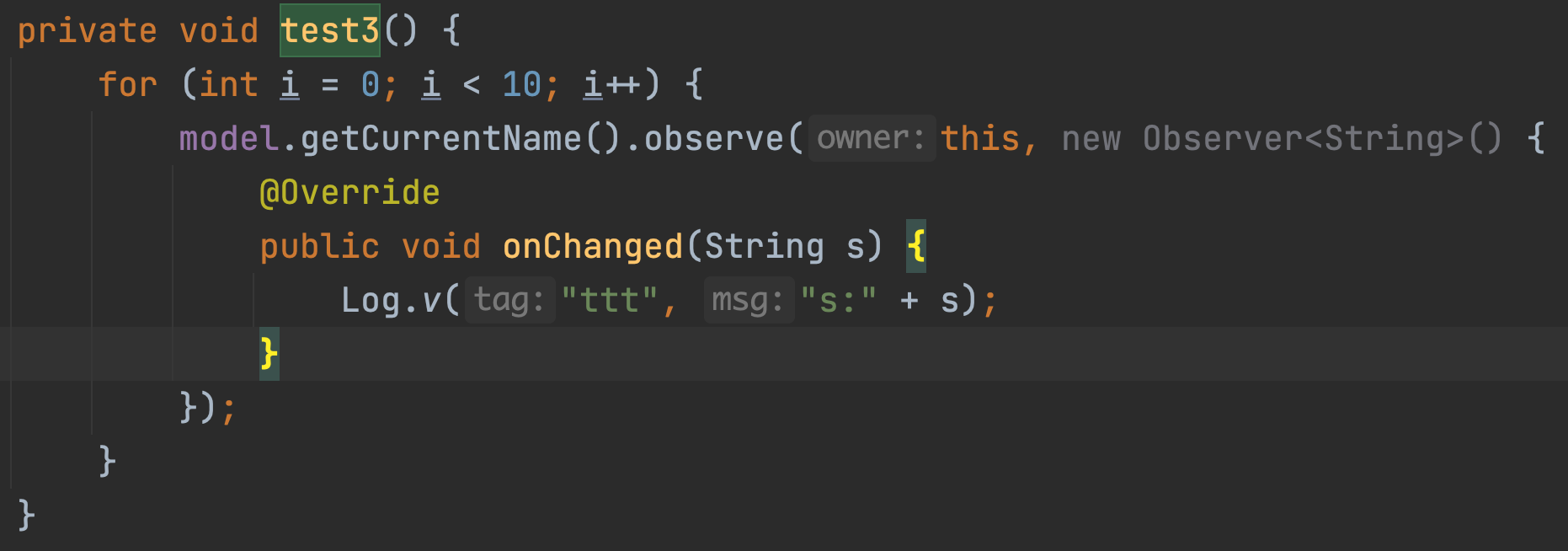
上述的代码跑在android studio里面会变灰,相信很多有代码洁癖的人一看就知道为啥,这不就是Java8的lambda嘛,ide自动给提示给我们让我们优化一下写法呗,而且鼠标一点就自动优化了,贼方便。

灰色没有了,代码变的简洁了,kpi在向我招手了,运行一下试试:
2021-11-21 15:31:50.386 29136-29136/com.smart.myapplication V/ttt: s:3
奇怪,为啥这次只有一个日志了?难道还是Log日志系统的原因?那我加个时间戳试试:

再看下执行结果:
2021-11-21 15:34:33.559 29509-29509/com.smart.myapplication V/ttt: s:3 time:1637480073559
奇怪,为什么还是只打印了一条log?我这里for循环add了10次观察者呀。难道是lambda导致的问题?嗯,我们可以把Observer的数量打出来看看,看看到底是哪里出了问题。看下源码,如下图所示:我们的观察者实际上都是存在这个map里面的,我们取出来这个map的size就可以知道原因了。
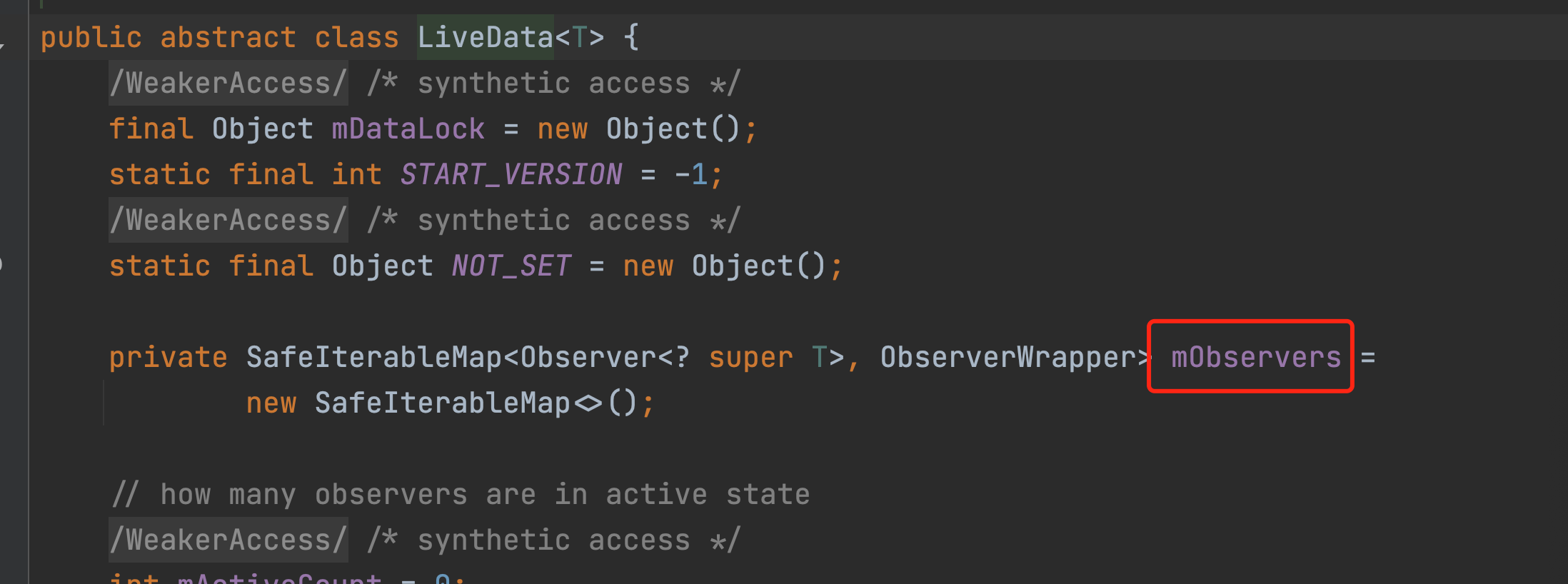
反射取一下这个size,注意我们平常使用的LiveData是MutableLiveData,而这个值是在LiveData里,所以是getSuperclass()。
private void hook(LiveData liveData) throws Exception {
Field map = liveData.getClass().getSuperclass().getDeclaredField("mObservers");
map.setAccessible(true);
SafeIterableMap safeIterableMap = (SafeIterableMap) map.get(liveData);
Log.v("ttt", "safeIterableMap size:" + safeIterableMap.size());
}
再看下执行结果:
2021-11-21 15:40:37.010 30043-30043/com.smart.myapplication V/ttt: safeIterableMap size:1
2021-11-21 15:40:37.013 30043-30043/com.smart.myapplication V/ttt: s:3 time:1637480437013
果然这里的map size是1,并不是10,那肯定只能收到1条通知了。那么问题来了,我明明是for循环添加了10个观察者啊,为啥一改成lambda的写法,我的观察者就变成1个了?遇事不决我们反编译(用jadx直接反编译我们的debug app)一下看看。
private void test3() {
for (int i = 0; i < 10; i++) {
this.model.getCurrentName().observe(this, $$Lambda$JavaTestLiveDataActivity$zcrCJYfWItRTy4AC_xWfANwZkzE.INSTANCE);
}
}
public final /* synthetic */ class $$Lambda$JavaTestLiveDataActivity$zcrCJYfWItRTy4AC_xWfANwZkzE implements Observer {
public static final /* synthetic */ $$Lambda$JavaTestLiveDataActivity$zcrCJYfWItRTy4AC_xWfANwZkzE INSTANCE = new $$Lambda$JavaTestLiveDataActivity$zcrCJYfWItRTy4AC_xWfANwZkzE();
private /* synthetic */ $$Lambda$JavaTestLiveDataActivity$zcrCJYfWItRTy4AC_xWfANwZkzE() {
}
public final void onChanged(Object obj) {
Log.v("ttt", "s:" + ((String) obj));
}
}
已经很清晰的看出来,这里因为使用了Java8 lambda的写法,所以编译器在编译的过程中自作聪明了一下,自动帮我们优化成都是添加的同一个静态的观察者,并不是10个,这就解释了为什么会出现map size为1的情况了。我们可以再把lambda的写法删除掉,再看看反编译的结果就正常了。
还剩最后一个问题,这个lamda的优化是不分任何场景一直生效的嘛?我们换个写法试试:
private String outer = "123456";
private void test3() {
for (int i = 0; i < 10; i++) {
model.getCurrentName().observe(this, s -> Log.v("ttt", "s:" + s + outer));
}
}
注意看,我们这种写法虽然也是用了lambda,但是我们引入了外部变量,和之前的lambda的写法是不一样的,看下这种写法反编译的结果;
private void test3() {
for (int i = 0; i < 10; i++) {
this.model.getCurrentName().observe(this, new Observer() {
public final void onChanged(Object obj) {
JavaTestLiveDataActivity.this.lambda$test33$0$JavaTestLiveDataActivity((String) obj);
}
});
}
}
看到new关键字就放心了,这种写法就可以绕过Java8 lambda编译的优化了。
1.3 Kotlin的lambda写法会有坑吗
考虑到现在大多数人都会使用Kotlin语言,我们也试试看Kotlin的lamda写法会不会也和Java8的lambda一样会有这种坑?
看下Kotlin中 lambda的写法:
fun test2() {
val liveData = MutableLiveData<Int>()
for (i in 0..9) {
liveData.observe(this,
{ t -> Log.v("ttt", "t:$t") })
}
liveData.value = 3
}
再看下反编译的结果:
public final void test2() {
MutableLiveData liveData = new MutableLiveData();
int i = 0;
do {
int i2 = i;
i++;
liveData.observe(this, $$Lambda$KotlinTest$6ZY8yysFE1G_4okj2E0STUBMfmc.INSTANCE);
} while (i <= 9);
liveData.setValue(3);
}
public final /* synthetic */ class $$Lambda$KotlinTest$6ZY8yysFE1G_4okj2E0STUBMfmc implements Observer {
public static final /* synthetic */ $$Lambda$KotlinTest$6ZY8yysFE1G_4okj2E0STUBMfmc INSTANCE = new $$Lambda$KotlinTest$6ZY8yysFE1G_4okj2E0STUBMfmc();
private /* synthetic */ $$Lambda$KotlinTest$6ZY8yysFE1G_4okj2E0STUBMfmc() {
}
public final void onChanged(Object obj) {
KotlinTest.m1490test2$lambda3((Integer) obj);
}
}
看来Kotlin的lambda编译和Java8 lambda的编译是一样激进的,都是在for循环的基础上 默认帮你优化成一个对象了。同样的,我们也看看让这个lambda访问外部的变量,看看还有没有这个“负优化”了。
val test="12345"
fun test2() {
val liveData = MutableLiveData<Int>()
for (i in 0..9) {
liveData.observe(this,
{ t -> Log.v("ttt", "t:$t $test") })
}
liveData.value = 3
}
看下反编译的结果:
public final void test2() {
MutableLiveData liveData = new MutableLiveData();
int i = 0;
do {
int i2 = i;
i++;
liveData.observe(this, new Observer() {
public final void onChanged(Object obj) {
KotlinTest.m1490test2$lambda3(KotlinTest.this, (Integer) obj);
}
});
} while (i <= 9);
liveData.setValue(3);
}
一切正常了。最后我们再看看 普通Kotlin的非lambda写法 是不是和Java的非lambda写法一样呢?
fun test1() {
val liveData = MutableLiveData<Int>()
for (i in 0..9) {
liveData.observe(this, object : Observer<Int> {
override fun onChanged(t: Int?) {
Log.v("ttt", "t:$t")
}
})
}
liveData.value = 3
}
看下反编译的结果:
public final void test11() {
MutableLiveData liveData = new MutableLiveData();
int i = 0;
do {
int i2 = i;
i++;
liveData.observe(this, new KotlinTest$test11$1());
} while (i <= 9);
liveData.setValue(3);
}
一切正常,到这里我们就可以下一个结论了。
对于for循环中间使用lambda的场景,当你的lambda中没有使用外部的变量或者函数的时候,那么不管是Java8的编译器还是Kotlin的编译器都会默认帮你优化成使用同一个lambda。
编译器的出发点是好的,for循环中new不同的对象,当然会导致一定程度的性能下降(毕竟new出来的东西最后都是要gc的),但这种优化往往可能不符合我们的预期,甚至有可能在某种场景下造成我们的误判,所以使用的时候一定要小心。
二、LiveData为何会收到Observe之前的消息
2.1 分析源码找原因
我们来看一个例子:
fun test1() {
val liveData = MutableLiveData<Int>()
Log.v("ttt","set live data value")
liveData.value = 3
Thread{
Log.v("ttt","wait start")
Thread.sleep(3000)
runOnUiThread {
Log.v("ttt","wait end start observe")
liveData.observe(this,
{ t -> Log.v("ttt", "t:$t") })
}
}.start()
}
这段代码的意思是我先更新了一个livedata的值为3,然后3s之后我livedata 注册了一个观察者。这里要注意了,我是先更新的livedata的值,过了一段时间以后才注册的观察者,那么此时,理论上我应该是收不到livedata消息的。因为你是先发的消息,我后面才观察的,但程序的执行结果却是:
2021-11-21 16:27:22.306 32275-32275/com.smart.myapplication V/ttt: set live data value
2021-11-21 16:27:22.306 32275-32388/com.smart.myapplication V/ttt: wait start
2021-11-21 16:27:25.311 32275-32275/com.smart.myapplication V/ttt: wait end start observe
2021-11-21 16:27:25.313 32275-32275/com.smart.myapplication V/ttt: t:3
这个就很诡异了,而且不符合一个我们常见的消息总线框架的设计。来看看源码到底是咋回事?
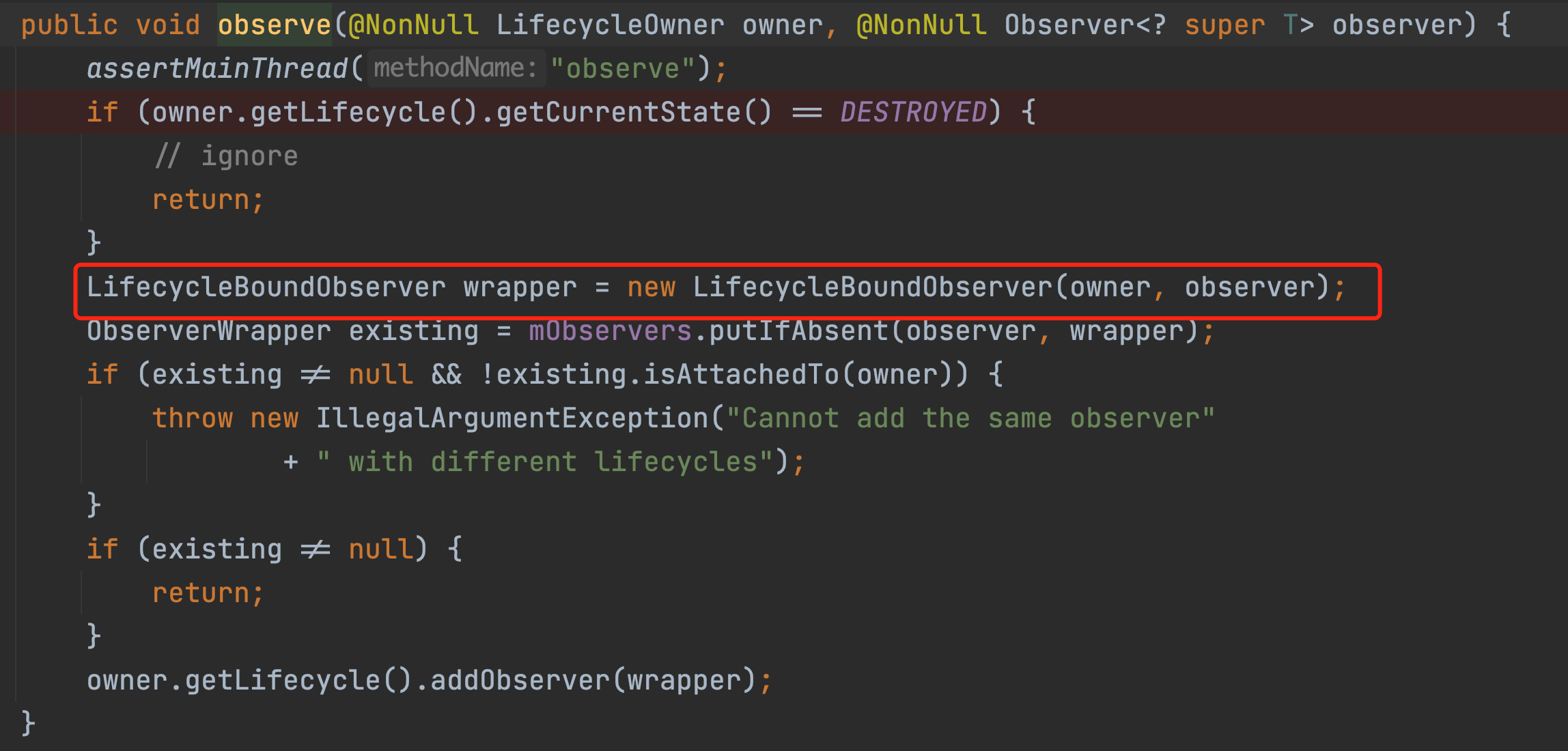
每次observe的时候我们会创建一个wrapper,看下这个wrapper是干啥的。
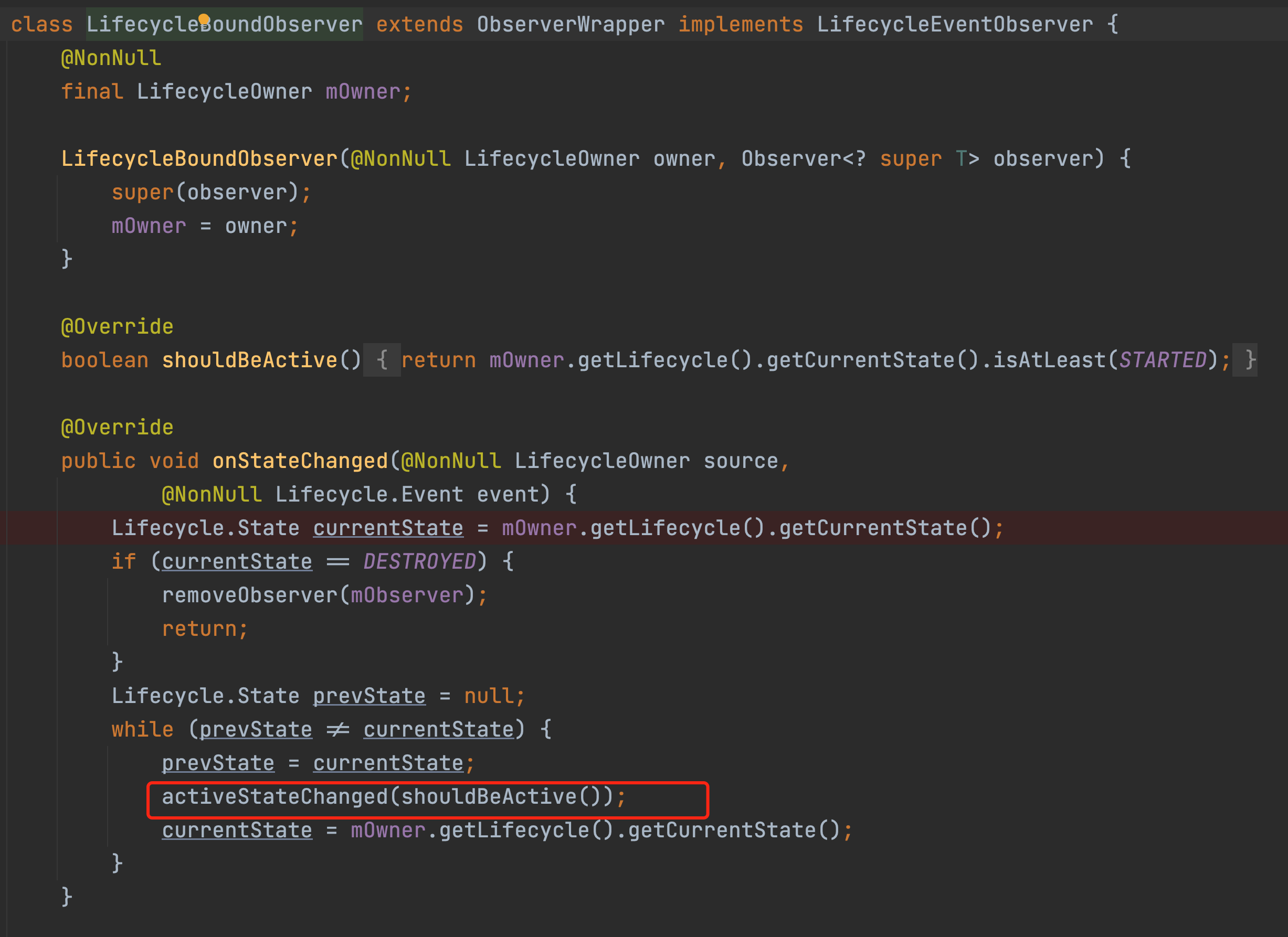
注意这个wrapper有一个onStateChanged方法,这是整个事件分发的核心,我们暂且记住这个入口,再回到我们之前的observe方法,最后一行是调用了addObserver方法,我们看看这个方法里做了啥。
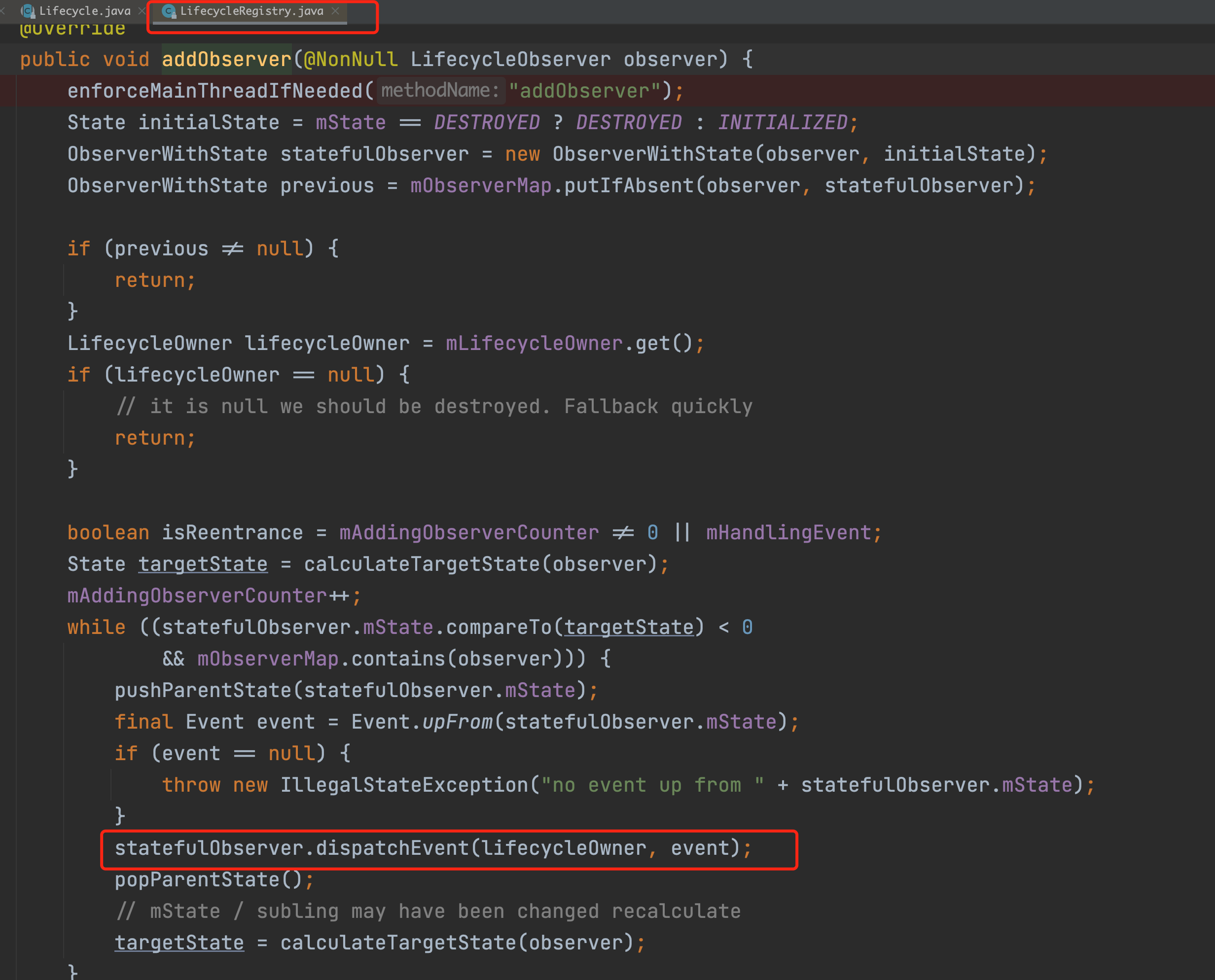
最终流程会走到这个dispatchEvent方法里,继续跟。
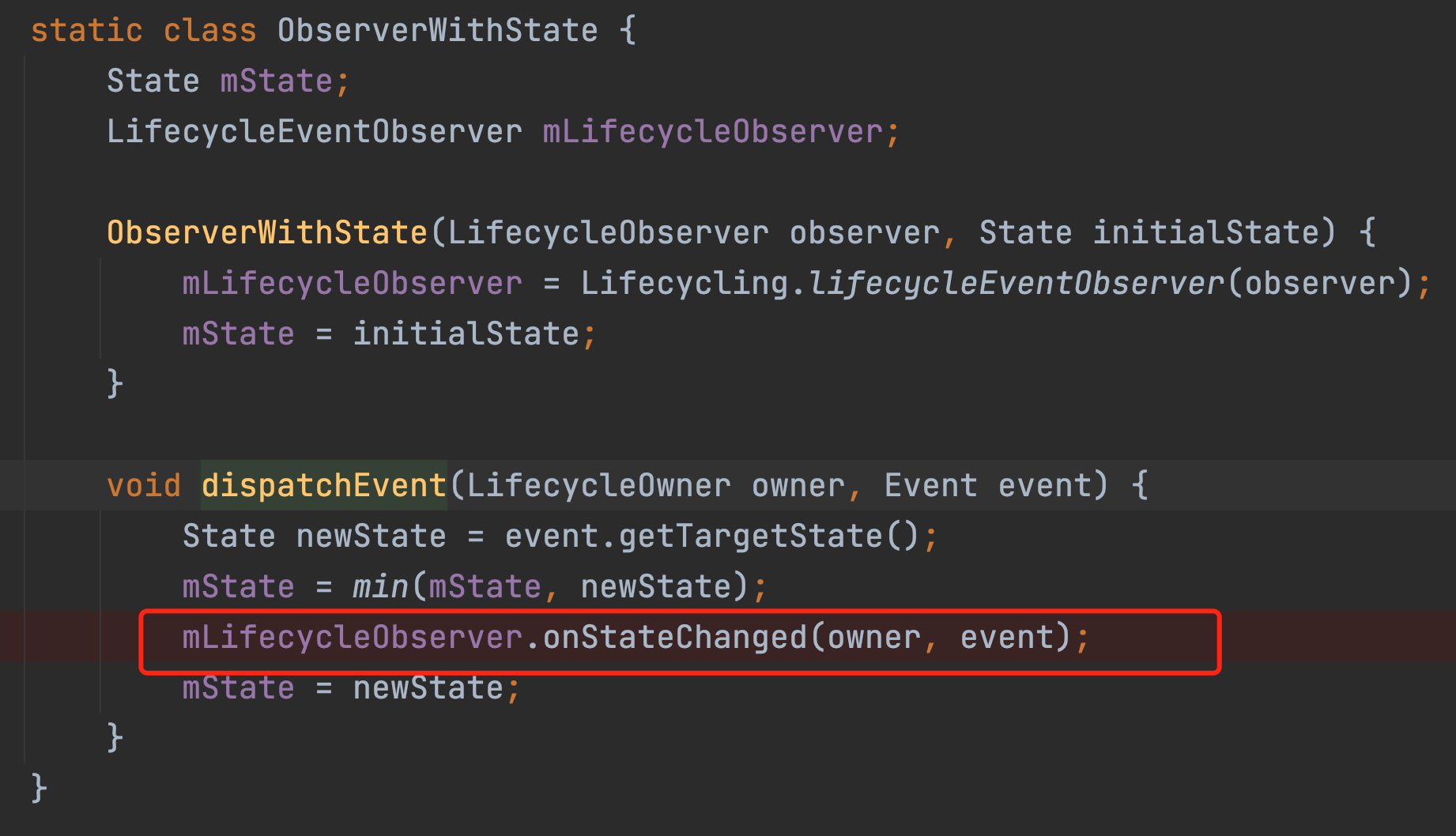
这个mLifeCycleObserver其实就是我们一开始observe那个方法里new出来的LifecycleBoundObserver对象了,也就是那个wrapper的变量。这个onStateChanged方法经过一系列的调用最终会走到如下图所示的considerNotify方法。
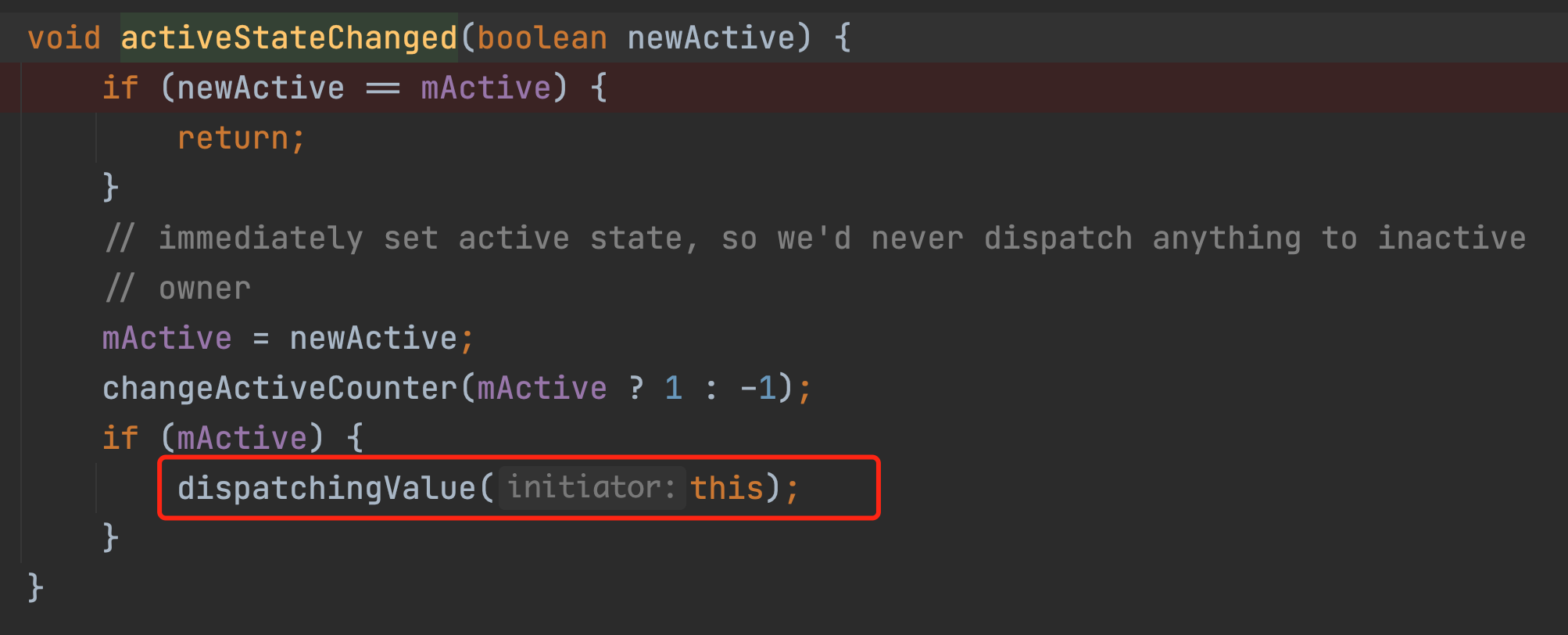
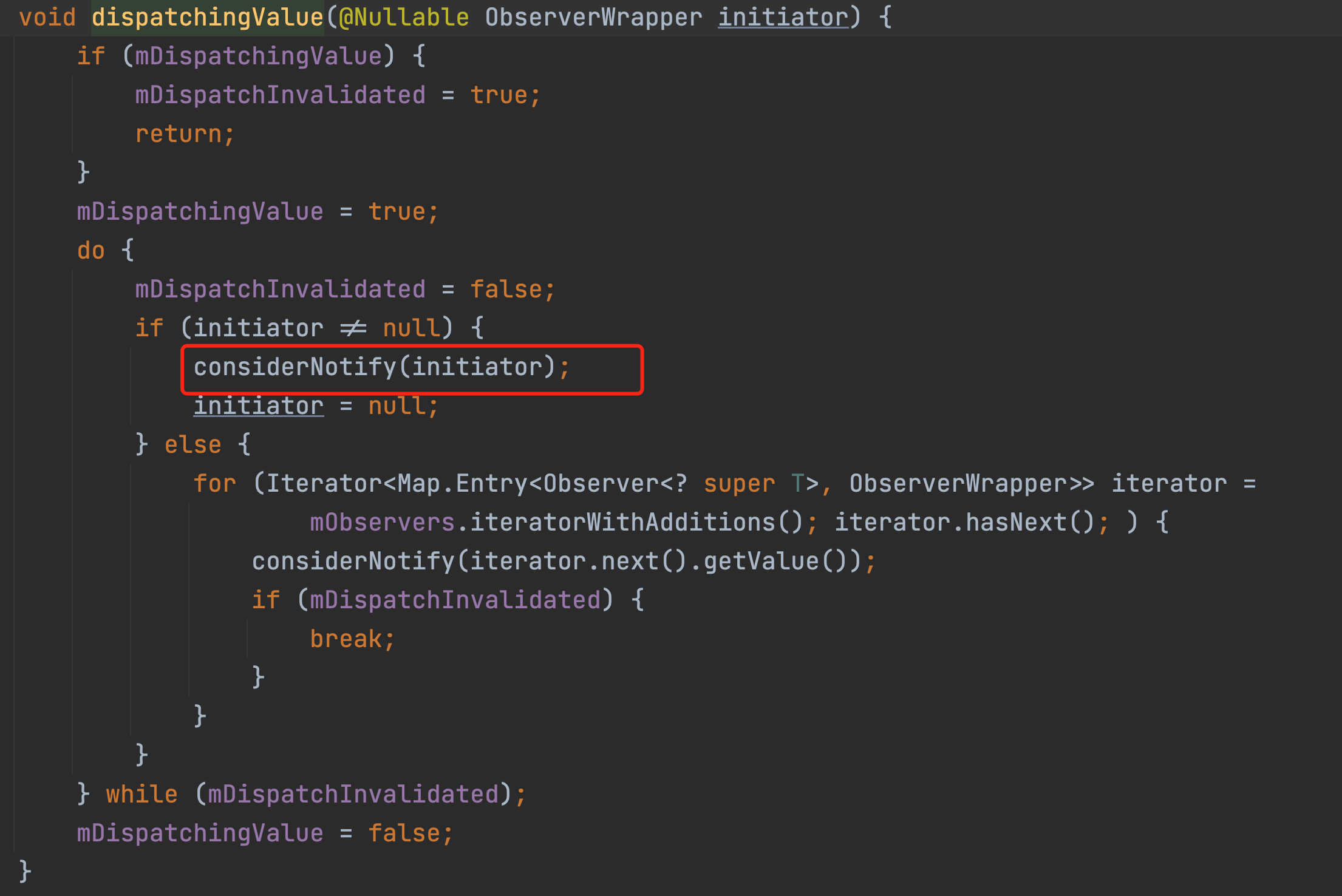
而整个considerNotify方法的作用只有一个。
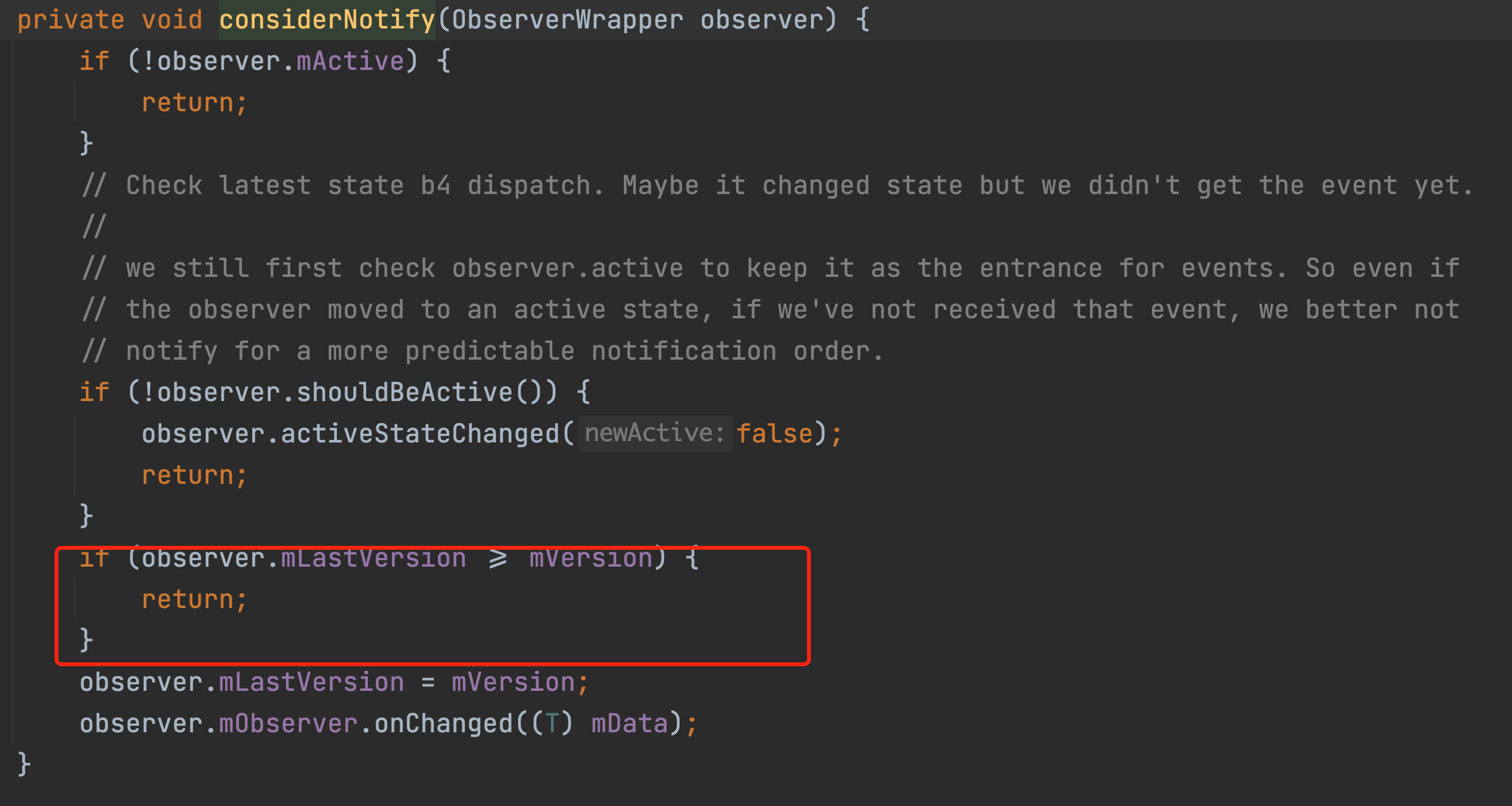
就是判断mLastVersion和mVersion的值,如果mLastVersion的值<mversion的值,那么就会触发observer的onchaged方法了,也就是会回调到我们的观察者方法里面<strong="">。
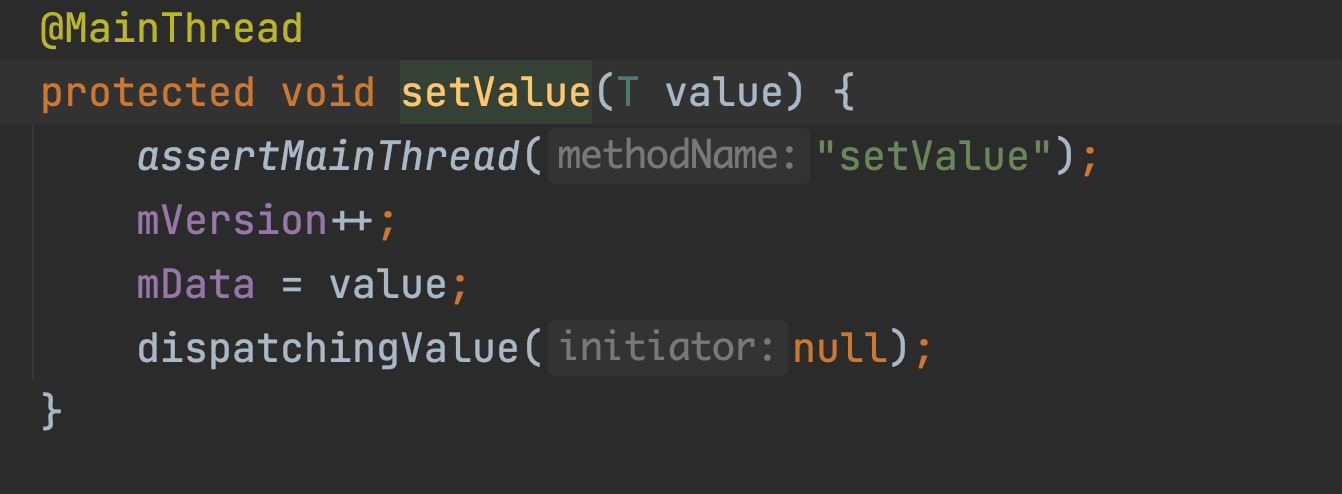
我们来看看这2个值咋变化的。首先看这个mVersion;

可以看出来这个值默认值就是start_version也就是-1。但是每次setValue的时候这个值都会加1。
而我们observer里面的mLastVersion 它的初始值就是-1。
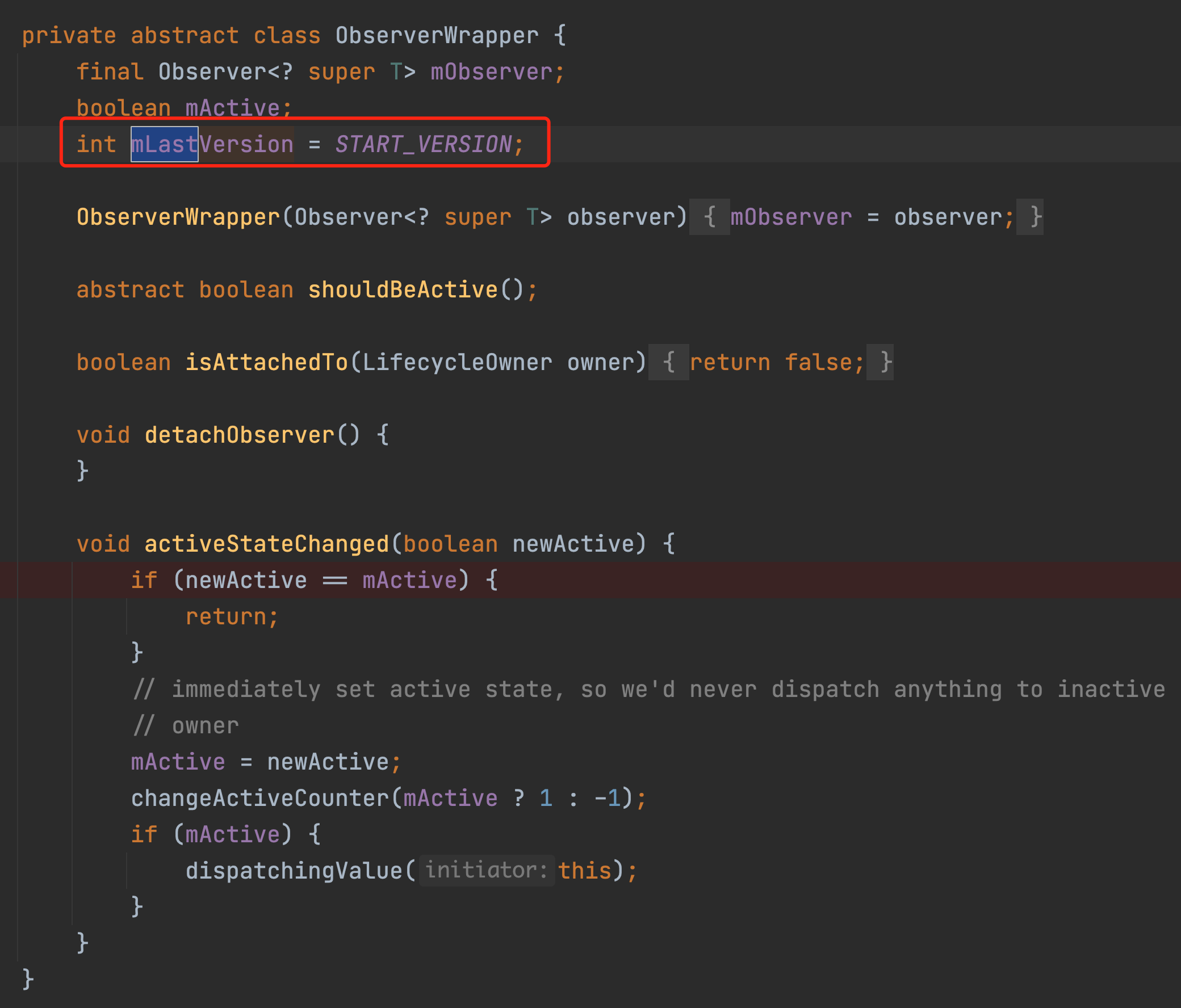
最后总结一下:
Livedata的mVersion初始值是-1。
经过一次setValue以后她的值就变成了0。
后续每次observe的时候会创建一个ObserverWrapper。
Wrapper她里面有一个mLastVersion 这个值是-1,observe的函数调用最终会经过一系列的流程走到considerNotify方法中此时 LiveData的mVersion是0。
0显然是大于observer的mLastVersion-1的,所以此时就一定会触发observer的监听函数了。
2.2 配合ActivityViewModels要小心
Livedata的这种特性,在某些场景下会引发灾难性的后果,比如说,单Activity多Fragment的场景下,在没有Jetpack-mvvm组件之前,要让Activity-Fragment 实现数据同步是很不方便的 ,但是有了Jetpack-mvvm组件之后,要实现这套机制会变的非常容易。可以看下官网上的例子:
class SharedViewModel : ViewModel() {
val selected = MutableLiveData<Item>()
fun select(item: Item) {
selected.value = item
}
}
class MasterFragment : Fragment() {
private lateinit var itemSelector: Selector
private val model: SharedViewModel by activityViewModels()
override fun onViewCreated(view: View, savedInstanceState: Bundle?) {
super.onViewCreated(view, savedInstanceState)
itemSelector.setOnClickListener { item ->
// Update the UI
}
}
}
class DetailFragment : Fragment() {
private val model: SharedViewModel by activityViewModels()
override fun onViewCreated(view: View, savedInstanceState: Bundle?) {
super.onViewCreated(view, savedInstanceState)
model.selected.observe(viewLifecycleOwner, Observer<Item> { item ->
// Update the UI
})
}
}
只要让2个fragment之间共享这套 ActivityViewModel 即可。使用起来很方便,但是某些场景下却会导致一些严重问题。来看这个场景,我们有一个activity默认显ListFragment,点击了ListFragment以后我们会跳转到DetailFragment,来看下代码:
class ListViewModel : ViewModel() {
private val _navigateToDetails = MutableLiveData<Boolean>()
val navigateToDetails : LiveData<Boolean>
get() = _navigateToDetails
fun userClicksOnButton() {
_navigateToDetails.value = true
}
}
再看下核心的ListFragment;
class ListFragment : Fragment() {
private val model: ListViewModel by activityViewModels()
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
}
override fun onViewCreated(view: View, savedInstanceState: Bundle?) {
super.onViewCreated(view, savedInstanceState)
model.navigateToDetails.observe(viewLifecycleOwner, { t ->
if (t) {
parentFragmentManager.commit {
replace<DetailFragment>(R.id.fragment_container_view)
addToBackStack("name")
}
}
})
}
override fun onCreateView(
inflater: LayoutInflater, container: ViewGroup?,
savedInstanceState: Bundle?
): View? {
// Inflate the layout for this fragment
return inflater.inflate(R.layout.fragment_list, container, false).apply {
findViewById<View>(R.id.to_detail).setOnClickListener {
model.userClicksOnButton()
}
}
}
}
可以看出来我们的实现机制就是点击了按钮以后我们调用viewModel的userClicksOnButton方法将navigateToDetails这个livedata的值改成true,然后监听这个LiveData值,如果是true的话就跳转到Detail 这个详情的fragment。
这个流程初看是没问题的,点击以后确实能跳转到DetailFragment,但是当我们在DetailFragment页面点击了返回键以后,理论上会回到ListFragment,但实际的执行结果是回到ListFragment以后马上又跳到DetailFragment了。
这是为啥?问题其实就出现在Fragment生命周期这里,当你按了返回键以后,ListFragment的onViewCreated又一次会被执行,然后这次你observe了,Livedata之前的值是true,于是又会触发跳转到DetailFragment的流程。导致你的页面再也回不到列表页了。
2.3 解决方案一:引入中间层
俗话说的好,计算机领域中的所有问题都可以通过引入一个中间层来解决。这里也一样,我们可以尝试“一个消息只被消费一次”的思路来解决上述的问题。例如我们将LiveData的值包一层:
class ListViewModel : ViewModel() {
private val _navigateToDetails = MutableLiveData<Event<Boolean>>()
val navigateToDetails : LiveData<Event<Boolean>>
get() = _navigateToDetails
fun userClicksOnButton() {
_navigateToDetails.value = Event(true)
}
}
open class Event<out T>(private val content: T) {
var hasBeenHandled = false
private set // 只允许外部读 不允许外部写这个值
/**
* 通过这个函数取的value 只能被消费一次
*/
fun getContentIfNotHandled(): T? {
return if (hasBeenHandled) {
null
} else {
hasBeenHandled = true
content
}
}
/**
* 如果想消费之前的value 那就直接调用这个方法即可
*/
fun peekContent(): T = content
}
这样我们在做监听的时候只要调用getContentIfNotHandled()这个方法即可:
model.navigateToDetails.observe(viewLifecycleOwner, { t ->
t.getContentIfNotHandled()?.let {
if (it){
parentFragmentManager.commit {
replace<DetailFragment>(R.id.fragment_container_view)
addToBackStack("name")
}
}
}
})
2.4 解决方案二:Hook LiveData的observe方法
前文我们分析过,每次observe的时候,mLastVersion的值小于 mVersion的值 是问题产生的根源,那我们利用反射,每次observer的时候将mLastVersion的值设置成与version相等不就行了么。
class SmartLiveData<T> : MutableLiveData<T>() {
override fun observe(owner: LifecycleOwner, observer: Observer<in T>) {
super.observe(owner, observer)
//get livedata version
val livedataVersion = javaClass.superclass.superclass.getDeclaredField("mVersion")
livedataVersion.isAccessible = true
// 获取livedata version的值
val livedataVerionValue = livedataVersion.get(this)
// 取 mObservers Filed
val mObserversFiled = javaClass.superclass.superclass.getDeclaredField("mObservers")
mObserversFiled.isAccessible = true
// 取 mObservers 对象
val objectObservers = mObserversFiled.get(this)
// 取 mObservers 对象 所属的class SafeIterableMap
val objectObserversClass = objectObservers.javaClass
val methodGet = objectObserversClass.getDeclaredMethod("get", Any::class.java)
methodGet.isAccessible = true
//LifecycleBoundObserver
val objectWrapper = (methodGet.invoke(objectObservers, observer) as Map.Entry<*, *>).value
//ObserverWrapper
val mLastVersionField = objectWrapper!!.javaClass.superclass.getDeclaredField("mLastVersion")
mLastVersionField.isAccessible = true
//将 mVersion的值 赋值给 mLastVersion 使其相等
mLastVersionField.set(objectWrapper, livedataVerionValue)
}
}
2.5 解决方案三:使用Kotlin-Flow
如果你还在使用Kotlin,那么此问题的解决方案则更加简单,甚至连过程都变的可控。在今年的谷歌I/O大会中,Yigit 在Jetpack的 AMA 中明确指出了 Livedata的存在就是为了照顾Java的使用者,短期内会继续维护(含义是什么大家自己品品),作为Livedata的替代品Flow会在今后渐渐成为主流(毕竟现在Kotlin渐渐成为主流),那如果使用了Flow,上述的情况则可以迎刃而解。
改写viewModel
class ListViewModel : ViewModel() {
val _navigateToDetails = MutableSharedFlow<Boolean>()
fun userClicksOnButton() {
viewModelScope.launch {
_navigateToDetails.emit(true)
}
}
}
然后改写下监听的方式即可;
override fun onViewCreated(view: View, savedInstanceState: Bundle?) {
super.onViewCreated(view, savedInstanceState)
lifecycleScope.launch {
model._navigateToDetails.collect {
if (it) {
parentFragmentManager.commit {
replace<DetailFragment>(R.id.fragment_container_view)
addToBackStack("name")
}
}
}
}
}
我们重点看SharedFlow这个热流的构造函数;

他的实际作用就是:当有新的订阅者collect的时候(可以理解为collect就是Livedata中的observe),发送几个(replay)collect之前已经发送过的数据给它,默认值是0。所以我们上述的代码是不会收到之前的消息的。大家在这里可以试一下 把这个replay改成1,即可复现之前Livedata的问题。相比于前面两种解决方案,这个方案更加优秀,唯一的缺点就是Flow不支持Java,仅支持Kotlin。
三、总结
整体上来说,即使现在有了Kotlin Flow,LiveData也依旧是目前Android客户端架构组件中不可缺少的一环,毕竟它的生命周期安全和内存安全实在是太香,可以有效降低我们平常业务开发中的负担,在使用他的时候我们只要关注3个方面即可避坑:
谨慎使用Android Studio给出的lambda智能提示
多关注是否真的需要Observe 在注册监听之前的消息
Activity与Fragment之间使用ActivityViewModel时要小心处理。
作者:vivo互联网前端团队-Wu Yue
Jetpack—LiveData组件的缺陷以及应对策略 转至元数据结尾的更多相关文章
- Jetpack架构组件学习(2)——ViewModel和Livedata使用
要看本系列其他文章,可访问此链接Jetpack架构学习 | Stars-One的杂货小窝 原文地址:Jetpack架构组件学习(2)--ViewModel和Livedata使用 | Stars-One ...
- 高并发&高可用系统的常见应对策略 秒杀等-(阿里)
对于一个需要处理高并发的系统而言,可以从多个层面去解决这个问题. 1.数据库系统:数据库系统可以采取集群策略以保证某台数据库服务器的宕机不会影响整个系统,并且通过负载均衡策略来降低每一台数据库服务器的 ...
- 软考论文的六大应对策略V1.0
软考论文的六大应对策略V1.0 短短2个小时,要写3000字的文章,对习惯了用电脑敲字.办公的IT从业人员而言,难度不小.尤其,大家会提笔忘字.笔者的应试策略,就是勤学苦练,考试前的一个星期,摸清套路 ...
- 触发JVM进行Full GC的情况及应对策略
堆内存划分为 Eden.Survivor 和 Tenured/Old 空间,如下图所示: 从年轻代空间(包括 Eden 和 Survivor 区域)回收内存被称为 Minor GC,对老年代GC称为M ...
- GC之八--GC 触发Full GC执行的情况及应对策略
目录: GC之一--GC 的算法分析.垃圾收集器.内存分配策略介绍 GC之二--GC日志分析(jdk1.8)整理中 GC之三--GC 触发Full GC执行的情况及应对策略 gc之四--Minor G ...
- 系列文章(一):探究电信诈骗的关键问题与应对策略——By Me
导读:伴随着互联网与移动网的融合,移动互联网变得更加开放.与此同时,伴随着新型的移动互联网服务模式的出现,移动互联网的安全问题也出现了新的形式及特点. 如今,移动互联网遭受到的攻击已严重影响了人们的隐 ...
- Jetpack架构组件学习(1)——LifeCycle的使用
原文地址:Jetpack架构组件学习(1)--LifeCycle的使用 | Stars-One的杂货小窝 要看本系列其他文章,可访问此链接Jetpack架构学习 | Stars-One的杂货小窝 最近 ...
- Jetpack架构组件学习(3)——Activity Results API使用
原文地址:Jetpack架构组件学习(3)--Activity Results API使用 - Stars-One的杂货小窝 技术与时俱进,页面跳转传值一直使用的是startActivityForRe ...
- Jetpack架构组件学习(4)——APP Startup库的使用
最近在研究APP的启动优化,也是发现了Jetpack中的App Startup库,可以进行SDK的初始化操作,于是便是学习了,特此记录 原文:Jetpack架构组件学习(4)--App Startup ...
随机推荐
- LuoguP6850 NOI 题解
Content 小 L 参加了 \(\texttt{NOI}\),现在他告诉你九个数 \(a,b,c,d,e,f,g,h,i\),分别表示--笔试作对的题数.D1T1.D1T2.D1T3.D2T1.D ...
- windows使用natapp教程
这种免费的 有个缺点 过段时间就会连接不上,需要不定时更换域名地址 Linux系统参考:https://www.cnblogs.com/pxblog/p/10549847.html 官网地址:http ...
- 逆波兰(加、减、乘、除、括号)表达式原理及C++代码实现
当我们输入一个数学表达式,是中缀表达式,我们首先转换为后缀表达式(逆波兰表达式),然后再进行求值. 代码思路: (1)首先对输入的中缀表达式合法性进行判断,bool isStringLegal(con ...
- nanogui源码编译+下载
MAC 没电了,哎..... 只能使用windows10将就了. 截至目前,我已经找到了两个nanogui项目,都是大佬. 分别为: A.https://github.com/dalerank/ ...
- 【LeetCode】536. Construct Binary Tree from String 解题报告(C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客:http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 统计字符串出现的次数 日期 题目地址:https:// ...
- 【LeetCode】455. Assign Cookies 解题报告(Java & Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 Java解法 Python解法 日期 [LeetCo ...
- 【因果推断经典论文】Direct and Indirect Effects - Judea Pearl
Direct and Indirect Effects Author: Judea Pearl UAI 2001 加州大学洛杉矶分校 论文链接:https://dl.acm.org/doi/pdf/1 ...
- Linux_at任务调度
基本介绍 一次性定时计划任务,由守护进程atd以后台模式执行,检查作业队列来进行 默认情况下,atd每60s检查一次作业队列 在使用at命令时,要确保atd进程的启动,用指令来查看 ps -ef | ...
- 【MySQL作业】sum、max 和 min 聚合函数——美和易思聚合函数应用习题
点击打开所使用到的数据库>>> 1.统计商品最高单价和最低单价. -- 获取所有商品的最高单价和最低单价: select max(unitPrice) 最高单价 , min(unit ...
- 【MySQL作业】连接查询——美和易思内连接查询应用习题
点击打开所使用到的数据库>>> 1.使用内连接获取客户"王传华"所有的订单信息和客户信息. 使用内连接获取客户"王传华"所有的订单信息和客户信 ...