第02讲:Flink 入门程序 WordCount 和 SQL 实现
我们右键运行时相当于在本地启动了一个单机版本。生产中都是集群环境,并且是高可用的,生产上提交任务需要用到flink run 命令,指定必要的参数。
本课时我们主要介绍 Flink 的入门程序以及 SQL 形式的实现。
上一课时已经讲解了 Flink 的常用应用场景和架构模型设计,这一课时我们将会从一个最简单的 WordCount 案例作为切入点,并且同时使用 SQL 方式进行实现,为后面的实战课程打好基础。
我们首先会从环境搭建入手,介绍如何搭建本地调试环境的脚手架;然后分别从DataSet(批处理)和 DataStream(流处理)两种方式如何进行单词计数开发;最后介绍 Flink Table 和 SQL 的使用。
Flink 开发环境
通常来讲,任何一门大数据框架在实际生产环境中都是以集群的形式运行,而我们调试代码大多数会在本地搭建一个模板工程,Flink 也不例外。
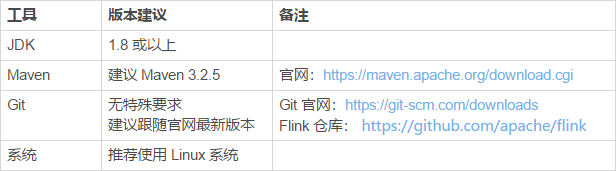
Flink 一个以 Java 及 Scala 作为开发语言的开源大数据项目,通常我们推荐使用 Java 来作为开发语言,Maven 作为编译和包管理工具进行项目构建和编译。对于大多数开发者而言,JDK、Maven 和 Git 这三个开发工具是必不可少的。
关于 JDK、Maven 和 Git 的安装建议如下表所示:
工程创建
一般来说,我们在通过 IDE 创建工程,可以自己新建工程,添加 Maven 依赖,或者直接用 mvn 命令创建应用:
复制代码
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.10.0
通过指定 Maven 工程的三要素,即 GroupId、ArtifactId、Version 来创建一个新的工程。同时 Flink 给我提供了更为方便的创建 Flink 工程的方法:
复制代码
curl https://flink.apache.org/q/quickstart.sh | bash -s 1.10.0
我们在终端直接执行该命令:
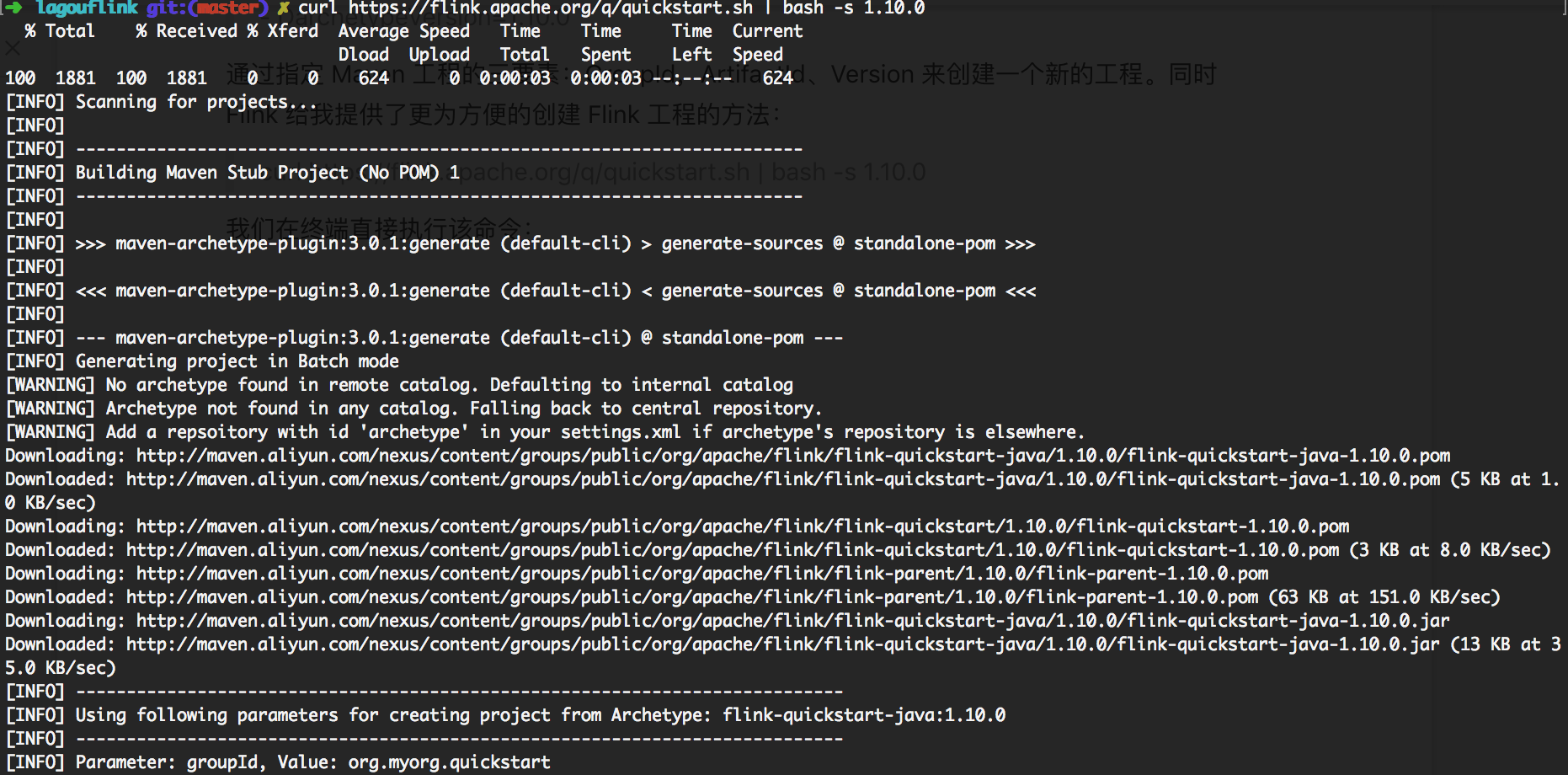
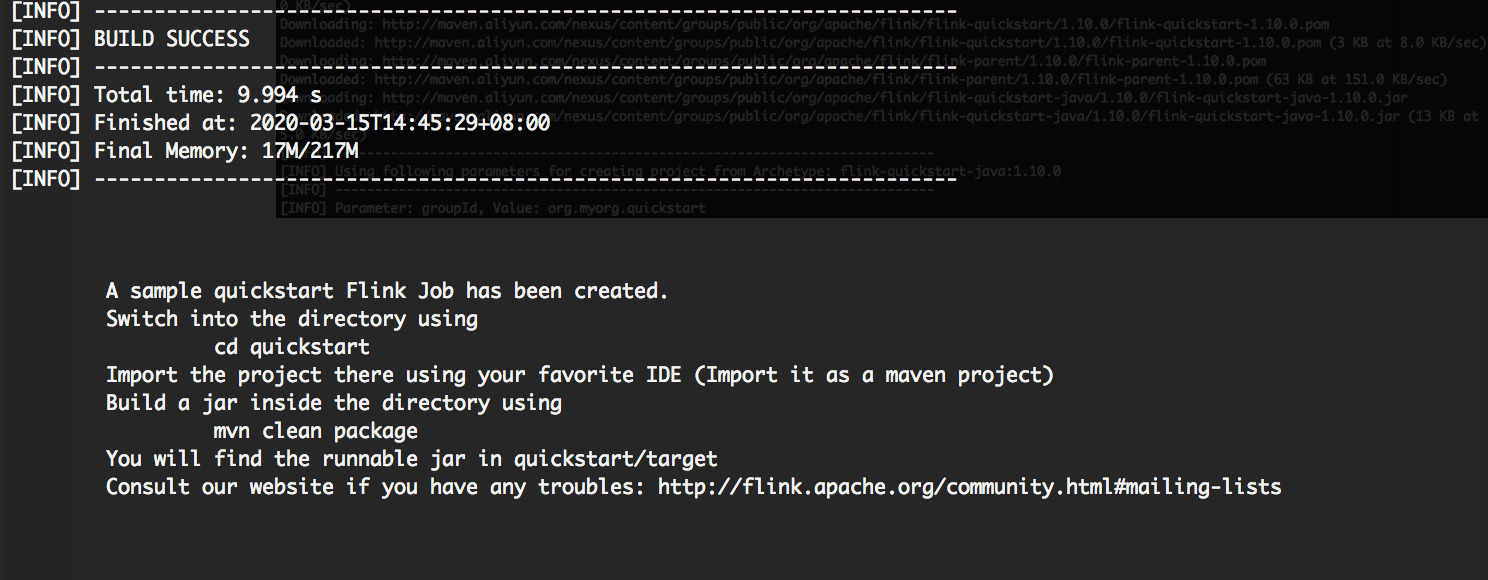
直接出现 Build Success 信息,我们可以在本地目录看到一个已经生成好的名为 quickstart 的工程。
这里需要的主要的是,自动生成的项目 pom.xml 文件中对于 Flink 的依赖注释掉 scope:
复制代码
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<!--<scope>provided</scope>-->
</dependency>
DataSet WordCount
WordCount 程序是大数据处理框架的入门程序,俗称“单词计数”。用来统计一段文字每个单词的出现次数,该程序主要分为两个部分:一部分是将文字拆分成单词;另一部分是单词进行分组计数并打印输出结果。
整体代码实现如下:
复制代码
public static void main(String[] args) throws Exception {
// 创建Flink运行的上下文环境
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 创建DataSet,这里我们的输入是一行一行的文本
DataSet<String> text = env.fromElements(
"Flink Spark Storm",
"Flink Flink Flink",
"Spark Spark Spark",
"Storm Storm Storm"
);
// 通过Flink内置的转换函数进行计算
DataSet<Tuple2<String, Integer>> counts =
text.flatMap(new LineSplitter())
.groupBy(0)
.sum(1);
//结果打印
counts.printToErr();
}
public static final class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
// 将文本分割
String[] tokens = value.toLowerCase().split("\\W+");
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<String, Integer>(token, 1));
}
}
}
}
实现的整个过程中分为以下几个步骤。
首先,我们需要创建 Flink 的上下文运行环境:
复制代码
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
然后,使用 fromElements 函数创建一个 DataSet 对象,该对象中包含了我们的输入,使用 FlatMap、GroupBy、SUM 函数进行转换。
最后,直接在控制台打印输出。
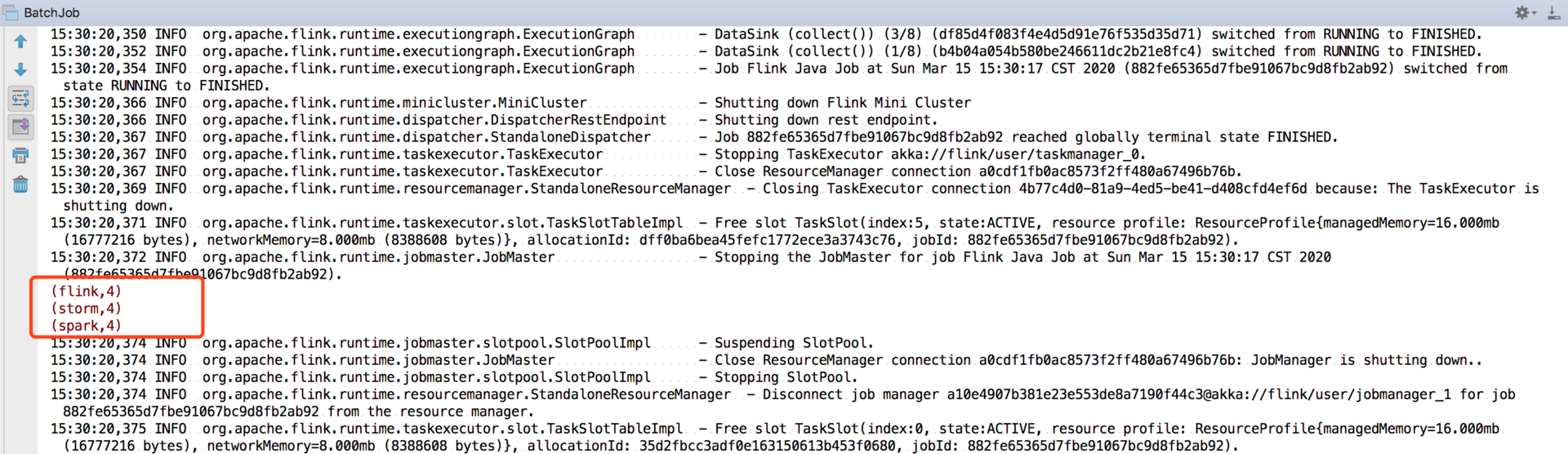
我们可以直接右键运行一下 main 方法,在控制台会出现我们打印的计算结果:
DataStream WordCount
为了模仿一个流式计算环境,我们选择监听一个本地的 Socket 端口,并且使用 Flink 中的滚动窗口,每 5 秒打印一次计算结果。代码如下:
复制代码
public class StreamingJob {
public static void main(String[] args) throws Exception {
// 创建Flink的流式计算环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 监听本地9000端口
DataStream<String> text = env.socketTextStream("127.0.0.1", 9000, "\n");
// 将接收的数据进行拆分,分组,窗口计算并且进行聚合输出
DataStream<WordWithCount> windowCounts = text
.flatMap(new FlatMapFunction<String, WordWithCount>() {
@Override
public void flatMap(String value, Collector<WordWithCount> out) {
for (String word : value.split("\\s")) {
out.collect(new WordWithCount(word, 1L));
}
}
})
.keyBy("word")
.timeWindow(Time.seconds(5), Time.seconds(1))
.reduce(new ReduceFunction<WordWithCount>() {
@Override
public WordWithCount reduce(WordWithCount a, WordWithCount b) {
return new WordWithCount(a.word, a.count + b.count);
}
});
// 打印结果
windowCounts.print().setParallelism(1);
env.execute("Socket Window WordCount");
}
// Data type for words with count
public static class WordWithCount {
public String word;
public long count;
public WordWithCount() {}
public WordWithCount(String word, long count) {
this.word = word;
this.count = count;
}
@Override
public String toString() {
return word + " : " + count;
}
}
}
整个流式计算的过程分为以下几步。
首先创建一个流式计算环境:
复制代码
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
然后进行监听本地 9000 端口,将接收的数据进行拆分、分组、窗口计算并且进行聚合输出。代码中使用了 Flink 的窗口函数,我们在后面的课程中将详细讲解。
我们在本地使用 netcat 命令启动一个端口:
复制代码
nc -lk 9000
然后直接运行我们的 main 方法:
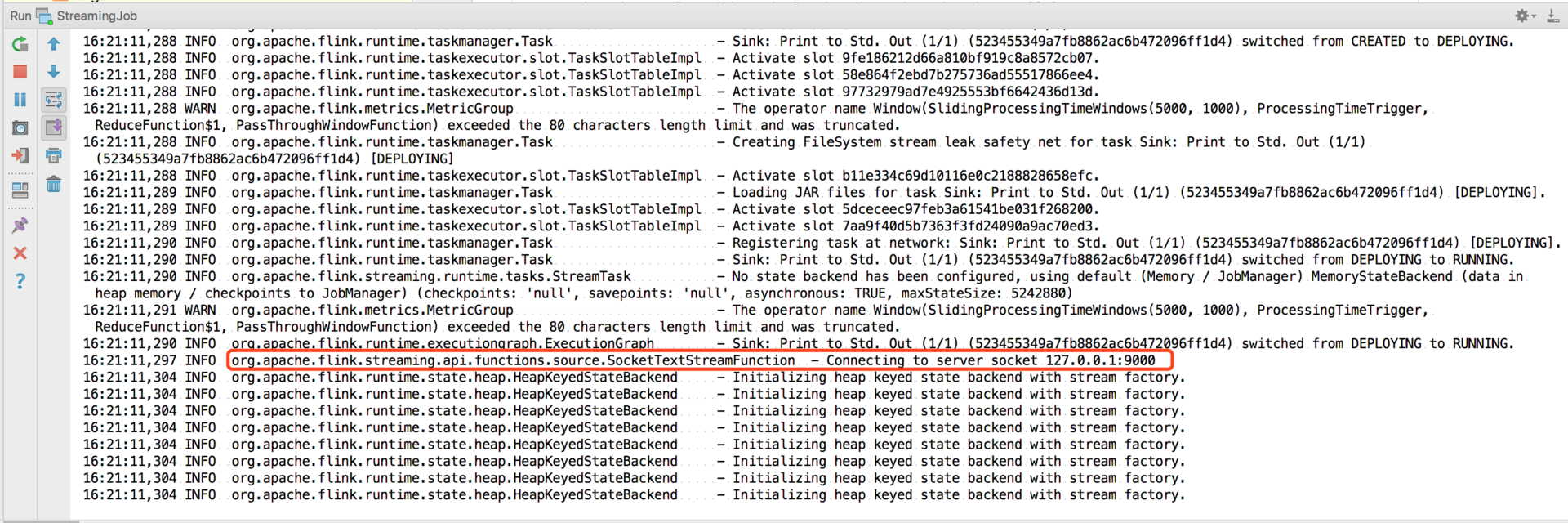
可以看到,工程启动后开始监听 127.0.0.1 的 9000 端口。
在 nc 中输入:
复制代码
$ nc -lk 9000
Flink Flink Flink
Flink Spark Storm
可以在控制台看到:
复制代码
Flink : 4
Spark : 1
Storm : 1
Flink Table & SQL WordCount
Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合标准 SQL 语义的开发语言。
一个完整的 Flink SQL 编写的程序包括如下三部分。
- Source Operator:是对外部数据源的抽象, 目前 Apache Flink 内置了很多常用的数据源实现,比如 MySQL、Kafka 等。
- Transformation Operators:算子操作主要完成比如查询、聚合操作等,目前 Flink SQL 支持了 Union、Join、Projection、Difference、Intersection 及 window 等大多数传统数据库支持的操作。
- Sink Operator:是对外结果表的抽象,目前 Apache Flink 也内置了很多常用的结果表的抽象,比如 Kafka Sink 等。
我们也是通过用一个最经典的 WordCount 程序作为入门,上面已经通过 DataSet/DataStream API 开发,那么实现同样的 WordCount 功能, Flink Table & SQL 核心只需要一行代码:
复制代码
//省略掉初始化环境等公共代码
SELECT word, COUNT(word) FROM table GROUP BY word;
首先,整个工程中我们 pom 中的依赖如下图所示:
复制代码
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.11</artifactId>
<version>1.10.0</version>
</dependency>
第一步,创建上下文环境:
复制代码
ExecutionEnvironment fbEnv = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment fbTableEnv = BatchTableEnvironment.create(fbEnv);
第二步,读取一行模拟数据作为输入:
复制代码
String words = "hello flink hello lagou";
String[] split = words.split("\\W+");
ArrayList<WC> list = new ArrayList<>();
for(String word : split){
WC wc = new WC(word,1);
list.add(wc);
}
DataSet<WC> input = fbEnv.fromCollection(list);
第三步,注册成表,执行 SQL,然后输出:
复制代码
//DataSet 转sql, 指定字段名
Table table = fbTableEnv.fromDataSet(input, "word,frequency");
table.printSchema();
//注册为一个表
fbTableEnv.createTemporaryView("WordCount", table);
Table table02 = fbTableEnv.sqlQuery("select word as word, sum(frequency) as frequency from WordCount GROUP BY word");
//将表转换DataSet
DataSet<WC> ds3 = fbTableEnv.toDataSet(table02, WC.class);
ds3.printToErr();
整体代码结构如下:
复制代码
public class WordCountSQL {
public static void main(String[] args) throws Exception{
//获取运行环境
ExecutionEnvironment fbEnv = ExecutionEnvironment.getExecutionEnvironment();
//创建一个tableEnvironment
BatchTableEnvironment fbTableEnv = BatchTableEnvironment.create(fbEnv);
String words = "hello flink hello lagou";
String[] split = words.split("\\W+");
ArrayList<WC> list = new ArrayList<>();
for(String word : split){
WC wc = new WC(word,1);
list.add(wc);
}
DataSet<WC> input = fbEnv.fromCollection(list);
//DataSet 转sql, 指定字段名
Table table = fbTableEnv.fromDataSet(input, "word,frequency");
table.printSchema();
//注册为一个表
fbTableEnv.createTemporaryView("WordCount", table);
Table table02 = fbTableEnv.sqlQuery("select word as word, sum(frequency) as frequency from WordCount GROUP BY word");
//将表转换DataSet
DataSet<WC> ds3 = fbTableEnv.toDataSet(table02, WC.class);
ds3.printToErr();
}
public static class WC {
public String word;
public long frequency;
public WC() {}
public WC(String word, long frequency) {
this.word = word;
this.frequency = frequency;
}
@Override
public String toString() {
return word + ", " + frequency;
}
}
}
我们直接运行该程序,在控制台可以看到输出结果:
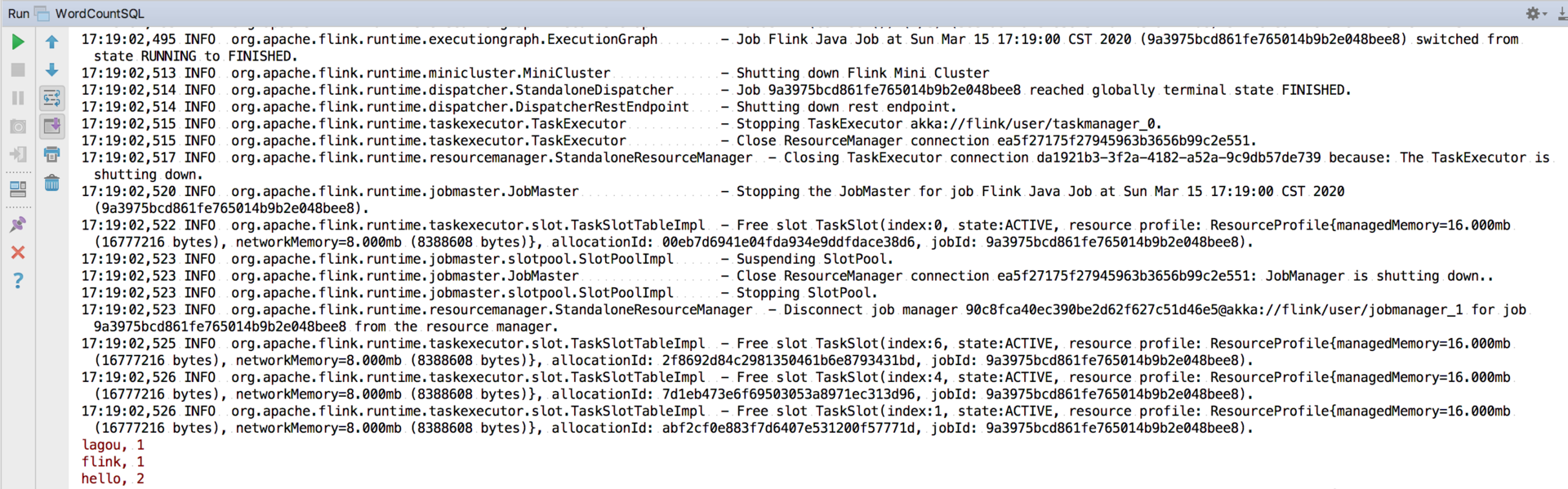
总结
本课时介绍了 Flink 的工程创建,如何搭建调试环境的脚手架,同时以 WordCount 单词计数这一最简单最经典的场景用 Flink 进行了实现。第一次体验了 Flink SQL 的强大之处,让你有一个直观的认识,为后续内容打好基础。
第02讲:Flink 入门程序 WordCount 和 SQL 实现的更多相关文章
- 2、flink入门程序Wordcount和sql实现
一.DataStream Wordcount 代码地址:https://gitee.com/nltxwz_xxd/abc_bigdata 基于scala实现 maven依赖如下: <depend ...
- Hadoop入门程序WordCount的执行过程
首先编写WordCount.java源文件,分别通过map和reduce方法统计文本中每个单词出现的次数,然后按照字母的顺序排列输出, Map过程首先是多个map并行提取多个句子里面的单词然后分别列出 ...
- Lucene 02 - Lucene的入门程序(Java API的简单使用)
目录 1 准备环境 2 准备数据 3 创建工程 3.1 创建Maven Project(打包方式选jar即可) 3.2 配置pom.xml, 导入依赖 4 编写基础代码 4.1 编写图书POJO 4. ...
- 不一样的Flink入门教程
前言 微信搜[Java3y]关注这个朴实无华的男人,点赞关注是对我最大的支持! 文本已收录至我的GitHub:https://github.com/ZhongFuCheng3y/3y,有300多篇原创 ...
- 大数据学习day32-----spark12-----1. sparkstreaming(1.1简介,1.2 sparkstreaming入门程序(统计单词个数,updateStageByKey的用法,1.3 SparkStreaming整合Kafka,1.4 SparkStreaming获取KafkaRDD的偏移量,并将偏移量写入kafka中)
1. Spark Streaming 1.1 简介(来源:spark官网介绍) Spark Streaming是Spark Core API的扩展,其是支持可伸缩.高吞吐量.容错的实时数据流处理.Sp ...
- flink入门实战总结
随着大数据技术在各行各业的广泛应用,要求能对海量数据进行实时处理的需求越来越多,同时数据处理的业务逻辑也越来越复杂,传统的批处理方式和早期的流式处理框架也越来越难以在延迟性.吞吐量.容错能力以及使用便 ...
- Flink入门(三)——环境与部署
flink是一款开源的大数据流式处理框架,他可以同时批处理和流处理,具有容错性.高吞吐.低延迟等优势,本文简述flink在windows和linux中安装步骤,和示例程序的运行,包括本地调试环境,集群 ...
- Flink入门(五)——DataSet Api编程指南
Apache Flink Apache Flink 是一个兼顾高吞吐.低延迟.高性能的分布式处理框架.在实时计算崛起的今天,Flink正在飞速发展.由于性能的优势和兼顾批处理,流处理的特性,Flink ...
- Flink入门-第一篇:Flink基础概念以及竞品对比
Flink入门-第一篇:Flink基础概念以及竞品对比 Flink介绍 截止2021年10月Flink最新的稳定版本已经发展到1.14.0 Flink起源于一个名为Stratosphere的研究项目主 ...
随机推荐
- Add File as a Link on Visual Studio
https://stackoverflow.com/questions/18963750/add-file-as-a-link-on-visual-studio-debug-vs-publish Ev ...
- JAVAWEB项目报"xxx响应头缺失“漏洞处理方案
新增一个拦截器,在拦截器doFilter()方法增加以下代码 public void doFilter(ServletRequest request, ServletResponse response ...
- jquery gantt 的使用
1.引入css与js文件 <link rel="stylesheet" href="css/style.css" /> <script src ...
- DevOps实战(Docker+Jenkins+Git)
基于Docker+Jenkins+Git的CI/CD实战 与上一篇随笔:基于 Jenkins+Docker+Git 的CI流程初探 有所不同,该内容更偏向于实际业务的基础需求. 有几点需要注意: 该实 ...
- C语言补漏-逗号运算符与逗号表达式
1. 新名词? 今天看到一个新名词: 逗号表达式. C语言就有.额,怎么当时学习C没见过,一头雾水. 对我来说是新名词,其实它早就存在了,只是我还不知道. 2. 逗号表达式 C语言提供了逗号运算符-- ...
- 【九度OJ】题目1056:最大公约数 解题报告
[九度OJ]题目1056:最大公约数 解题报告 标签(空格分隔): 九度OJ 原题地址:http://ac.jobdu.com/problem.php?pid=1056 题目描述: 输入两个正整数,求 ...
- 【LeetCode】88. Merge Sorted Array 解题报告(Java & Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 新建数组 日期 题目地址:https://leetc ...
- 【LeetCode】373. Find K Pairs with Smallest Sums 解题报告(Python)
[LeetCode]373. Find K Pairs with Smallest Sums 解题报告(Python) 标签: LeetCode 题目地址:https://leetcode.com/p ...
- 【jvm】04-我偷偷改了你编译后的class文件
[jvm]04-我偷偷改了你编译后的class文件 欢迎关注b站账号/公众号[六边形战士夏宁],一个要把各项指标拉满的男人.该文章已在github目录收录. 屏幕前的大帅比和大漂亮如果有帮助到你的话请 ...
- Web前端浏览器默认样式重置(CSS Tools: Reset CSS)
/* http://meyerweb.com/eric/tools/css/reset/ v2.0 | 20110126 License: none (public domain) */ html, ...