Flink sql 之 TopN 与 StreamPhysicalRankRule (源码解析)
基于flink1.14的源码做解析
公司内有很多业务方都在使用我们Flink sql平台做TopN的计算,今天同事突然问到我,Flink sql 是怎么实现topN的 ?
蒙圈了,这块源码没看过啊 ,业务要问起来怎么办,赶快打开源码补一下
拿到这个问题先冷静分析一下范围
首先肯定属于Flink sql模块,源码里面肯定是在flink-table-planner包里面,接着topN那不就是ROW_NUMBER嘛,是个函数呀
既然如此那就从flink源码的系统函数作为线索开始找起来,来到 org.apache.calcite.sql.fun.SqlStdOperatorTable类
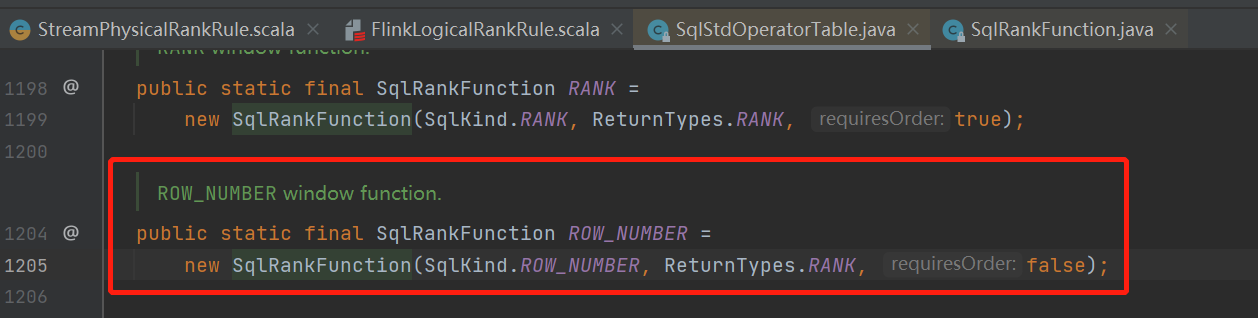
果然找到了,那calcite的某个rule肯定有个地方判断了它,继续查调用链
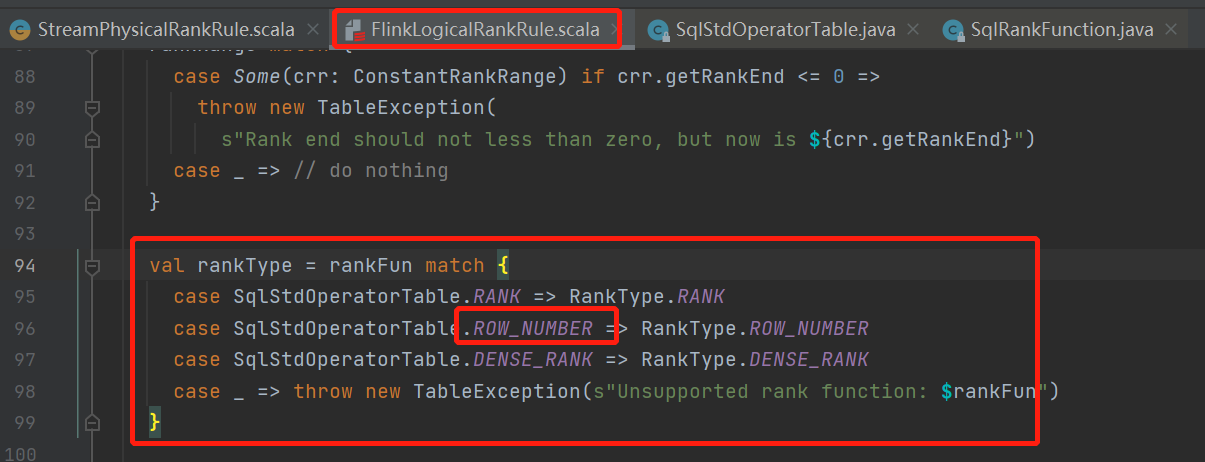
不出所料,FlinkLogicalRankRuleBase这个calcite的rule里面果然根据这个function的类型来确定rank的类型了
看下这个rule的匹配条件

这里也好理解,overAgg的时候会判断这个rank以及对应的类型
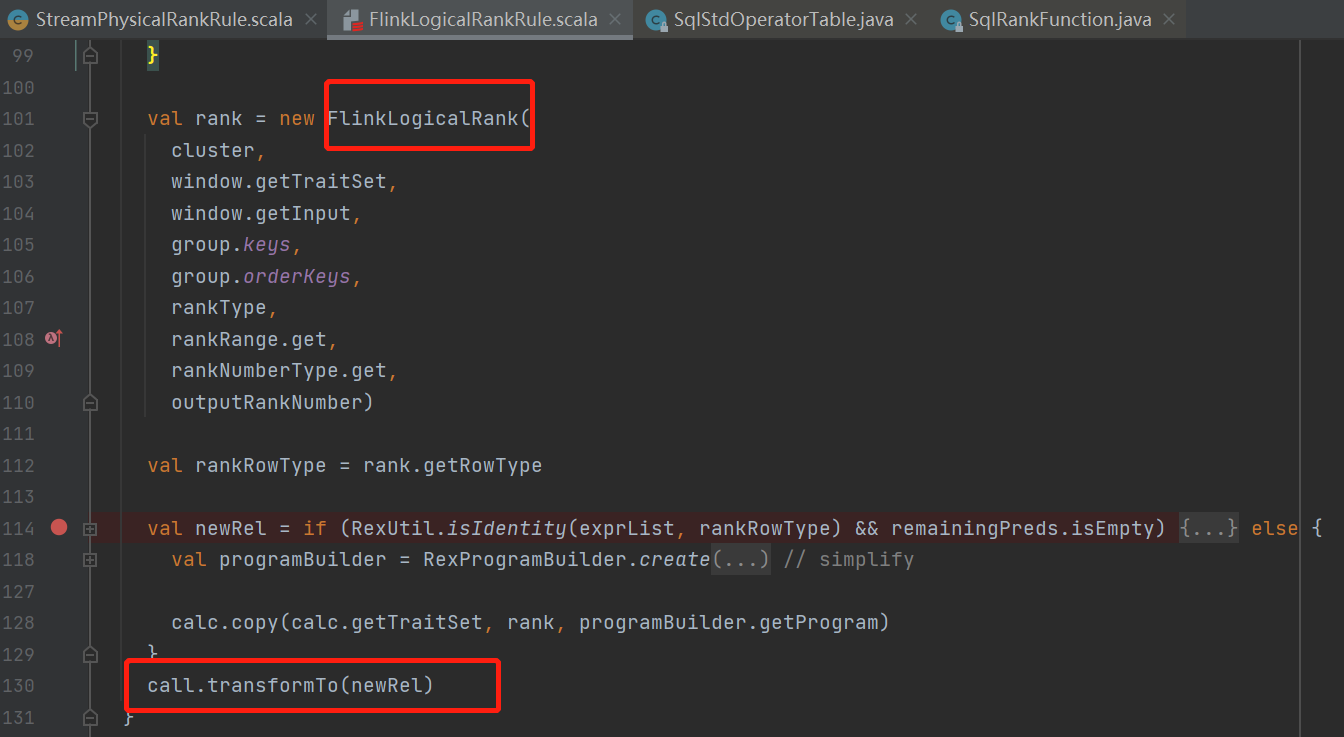
这是只是做了一下简单的提取了rank的字段啊,提取谓语啊,提取表达式啊这一些拿信息的操作
然后直接生成新的relNode叫FlinkLogicalRank通过transformTo直接返回了这个等价节点
既然是relNode那肯定又会有calcite的rule去处理它,来找一找
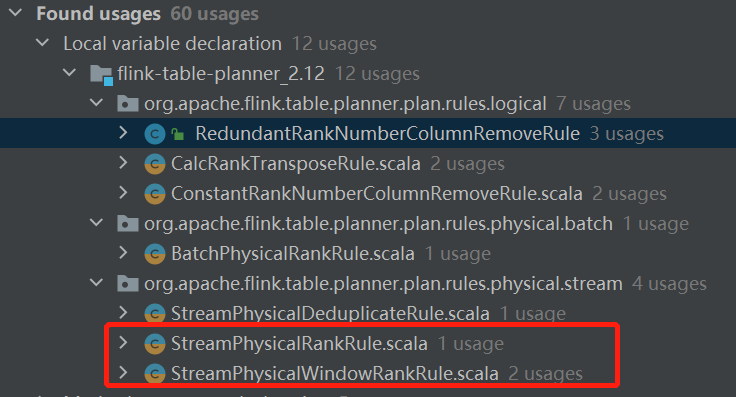
批处理的就不管了,从名字就可以看出来我们要找的类了
看个不带window的吧
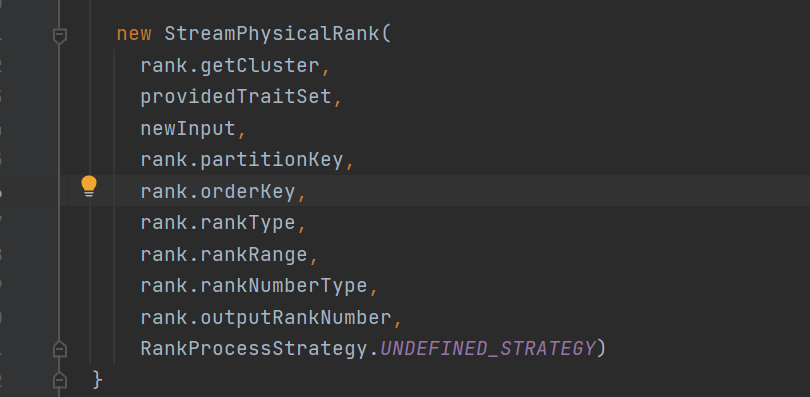
返回StreamPhysicalRank
这个类是一个FlinkPhysicalRel是可以转换成execNode的
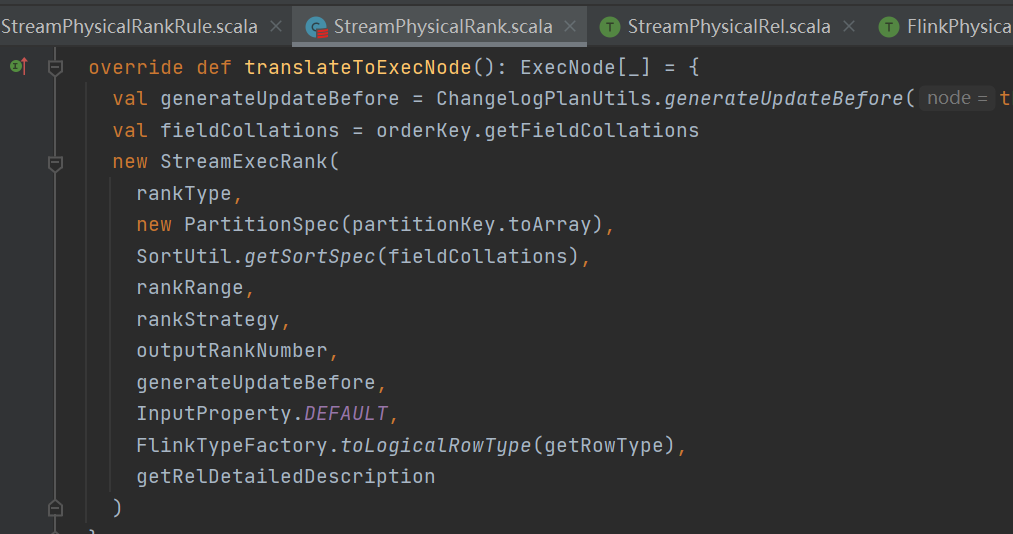
返回的这个StreamExecRank就是可以转换成具体的Flink的算子了,具体逻辑就在里面了
接下来看下row_number的具体逻辑,找到方法translateToPlanInternal
根据策略主要分为三种类型
AppendFastStrategy (输入仅包含插入时)
RetractStrategy (输入包含update和delete)
UpdateFastStrategy (输入不应包含删除且输入有给定的primaryKeys且按字段排序时)
来看个retractStrategy的吧
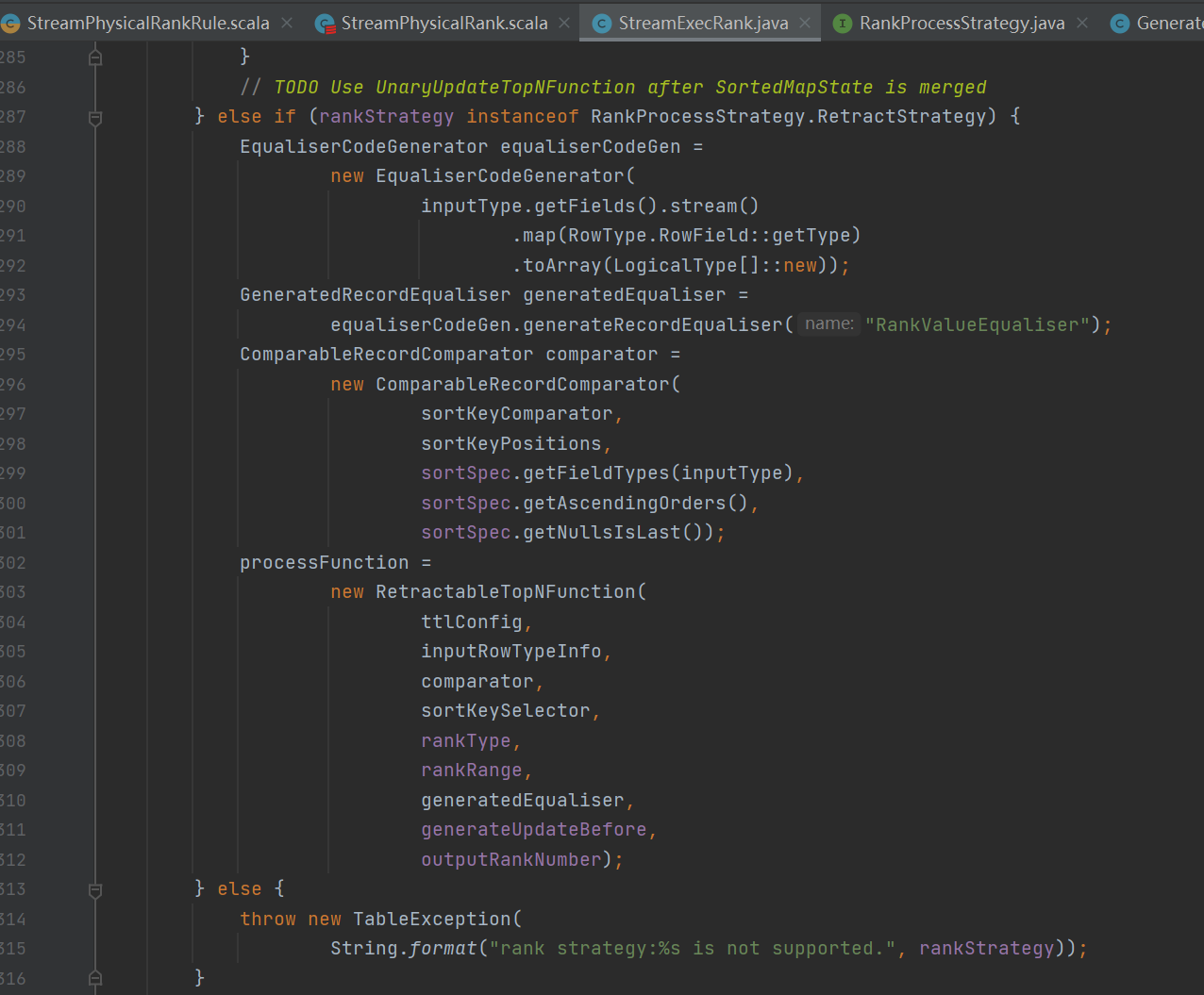
先通过sort的字段获取一个用于排序RowData的比较器 ComparableRecordComparator
根据比较器创建 RetractableTopNFunction
这个类还有两个主要的状态数据结构
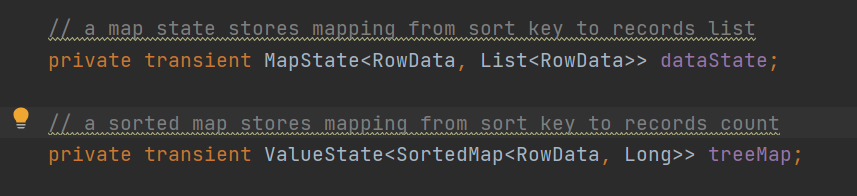
dataState这个map用来存放当key相同的所有数据会放在同一个list里面
treeMap这个可排序的map就是通过上面我们sql里面定义的sort by 来排序数据的,Long是指这个相同的key有多少个record
!!!!!!!!!!! 那就是用java的treeMap排序呗
继续往下看
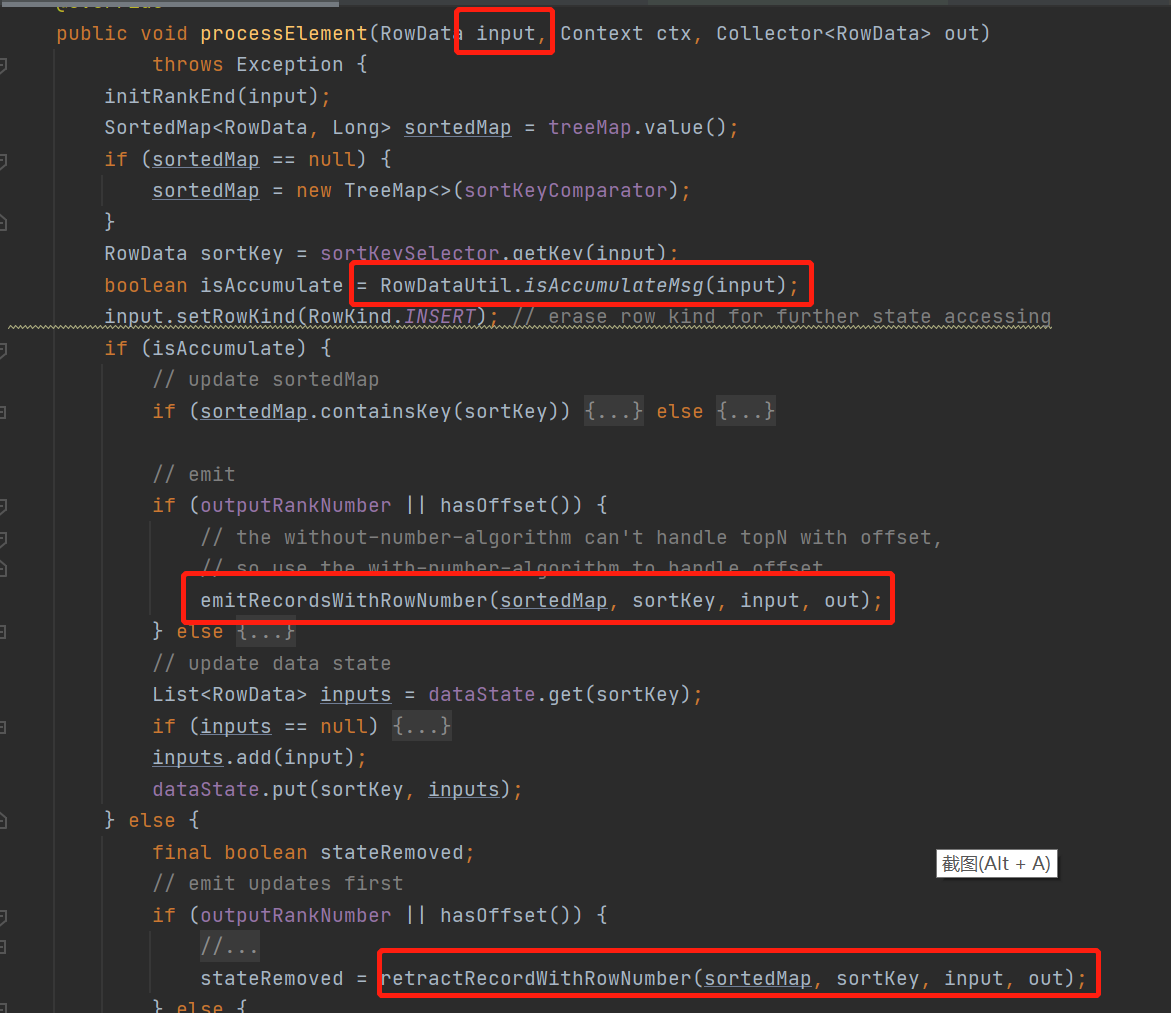
主逻辑就是这个了
每进入一条数据,会根据这条数据的类型划分
当数据是Insert , UPDATE_AFTER类型是会走 emitRecordsWithRowNumber()方法
当数据是UPDATE_BEFORE,DELETE类型会走 retractRecordWithRowNumber ()方法
来看下具体逻辑先看INSERT的
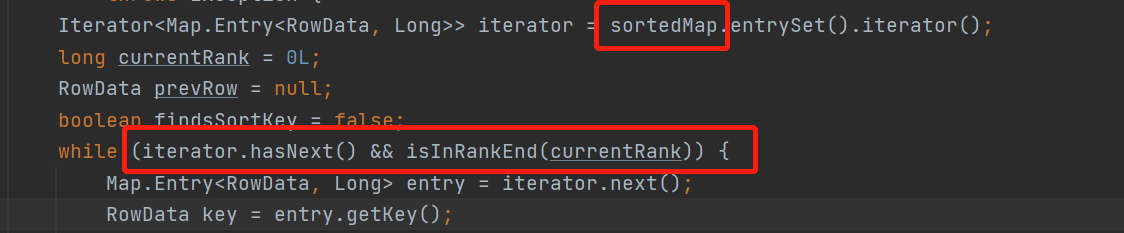
遍历treeMap
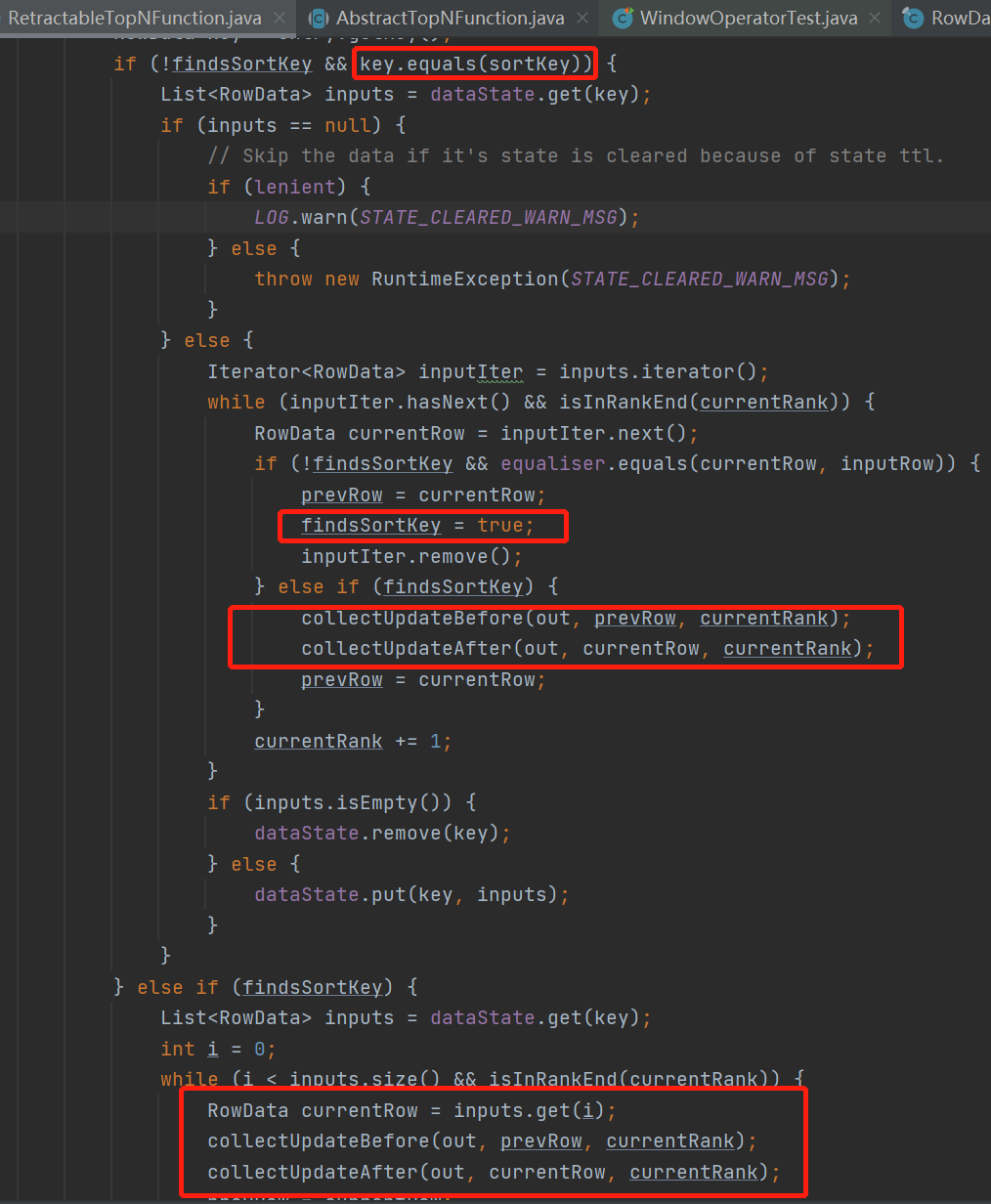
解读一下,当数据是insert数据的时候
按顺序遍历treeMap
当遍历过程中发现遍历的key与当前数据的key相同时,和当前数据key相同的所有数据数据(dataState中的LIST),全部撤回并且更新他们的rowNumber+1
继续遍历treeMap
之后的数据全部撤回UpdateBefore,并且向下游发送UpdateAfter使rowNumber+1,遍历直到已经到第TopN个数据循环结束
当数据是DELETE类型的时候,会和Insert反过来,当前key之后的数据全部撤回,然后rowNumber-1
整个处理流程差不多就结束了,可以看到rowNumber当N较大且排序变化频繁的时候,性能消耗还是非常大的,极端情况下游的数据会翻很多倍
这个还需要注意在其他两个策略中还有一个参数,table.exec.topn.cache-size

影响下面这个本地lruCache的大小

调大可以减少状态的访问,可以按需要添加
Flink sql 之 TopN 与 StreamPhysicalRankRule (源码解析)的更多相关文章
- [源码解析] GroupReduce,GroupCombine 和 Flink SQL group by
[源码解析] GroupReduce,GroupCombine和Flink SQL group by 目录 [源码解析] GroupReduce,GroupCombine和Flink SQL grou ...
- Flink 源码解析 —— 源码编译运行
更新一篇知识星球里面的源码分析文章,去年写的,周末自己录了个视频,大家看下效果好吗?如果好的话,后面补录发在知识星球里面的其他源码解析文章. 前言 之前自己本地 clone 了 Flink 的源码,编 ...
- Flink 源码解析 —— 如何获取 ExecutionGraph ?
https://t.zsxq.com/UnA2jIi 博客 1.Flink 从0到1学习 -- Apache Flink 介绍 2.Flink 从0到1学习 -- Mac 上搭建 Flink 1.6. ...
- Flink 源码解析 —— 深度解析 Flink 是如何管理好内存的?
前言 如今,许多用于分析大型数据集的开源系统都是用 Java 或者是基于 JVM 的编程语言实现的.最着名的例子是 Apache Hadoop,还有较新的框架,如 Apache Spark.Apach ...
- Flink 源码解析 —— 如何获取 JobGraph?
JobGraph https://t.zsxq.com/naaMf6y 博客 1.Flink 从0到1学习 -- Apache Flink 介绍 2.Flink 从0到1学习 -- Mac 上搭建 F ...
- Flink 源码解析 —— Flink JobManager 有什么作用?
JobManager 的作用 https://t.zsxq.com/2VRrbuf 博客 1.Flink 从0到1学习 -- Apache Flink 介绍 2.Flink 从0到1学习 -- Mac ...
- Flink 源码解析 —— JobManager 处理 SubmitJob 的过程
JobManager 处理 SubmitJob https://t.zsxq.com/3JQJMzZ 博客 1.Flink 从0到1学习 -- Apache Flink 介绍 2.Flink 从0到1 ...
- Flink Metrics 源码解析
Flink Metrics 有如下模块: Flink Metrics 源码解析 -- Flink-metrics-core Flink Metrics 源码解析 -- Flink-metrics-da ...
- Flink 源码解析 —— 深度解析 Flink 序列化机制
Flink 序列化机制 https://t.zsxq.com/JaQfeMf 博客 1.Flink 从0到1学习 -- Apache Flink 介绍 2.Flink 从0到1学习 -- Mac 上搭 ...
随机推荐
- 记一次 .NET 某机械臂智能机器人控制系统MRS CPU爆高分析
一:背景 1. 讲故事 这是6月中旬一位朋友加wx求助dump的故事,他的程序 cpu爆高UI卡死,问如何解决,截图如下: 在拿到这个dump后,我发现这是一个关于机械臂的MRS程序,哈哈,在机械臂这 ...
- Leetcode 146. LRU 缓存机制
前言 缓存是一种提高数据读取性能的技术,在计算机中cpu和主内存之间读取数据存在差异,CPU和主内存之间有CPU缓存,而且在内存和硬盘有内存缓存.当主存容量远大于CPU缓存,或磁盘容量远大于主存时,哪 ...
- Linux下SSH以及SSH秘钥
一.基于秘钥方式实现远程连接 第一步:创建密钥对(在管理端服务器上操作) 中间的输入项可以直接回车 ssh-keygen -t dsa 第二步:分发公钥(在管理端服务器执行) 这个步骤需要输入一个ye ...
- noip模拟测试18
打开比赛第一眼--超级树? 点开--原题 百感交集-- 欣喜于发现是半年前做过两遍的原题 紧张于如果A不了比较尴尬 绝望于发现根本不会做了 瞟了一眼t1,瞅了一眼t2,嗯--开始搞t3 10分钟打完暴 ...
- WEB安全性测试之拒绝服务攻击
1,认证 需要登录帐号的角色 2,授权 帐号的角色的操作范围 3,避免未经授权页面直接可以访问 使用绝对url(PS:绝对ur可以通过httpwatch监控每一个请求,获取请求对应的页面),登录后台的 ...
- Linux网络编程:原始套接字简介
Linux网络编程:原始套接字编程 一.原始套接字用途 通常情况下程序员接所接触到的套接字(Socket)为两类: 流式套接字(SOCK_STREAM):一种面向连接的Socket,针对于面向连接的T ...
- Java链表练习题小结
链表 链表(Linked List)是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的指针(Pointer).一个链表节点至少包含一个 数据域和 ...
- 测试平台系列(55) 引入AceEditor(代码编辑器)
大家好,我是米洛,求三连!求关注测试开发坑货! 回顾 我们上一节已经写好了左侧数据表目录,今天继续完成sql编辑器的部分. 调研组件 monaco 因为我们的项目用的是React,市面上很多编辑器都是 ...
- 使用python实现xls批量转为xlsx
利用win32库来实现 # -*- coding:utf-8 -*- import os import win32com.client as win32 #需要转换的数据目录 inputdir = u ...
- 【简单数据结构】链表--洛谷P1160
题目描述 一个学校里老师要将班上NN个同学排成一列,同学被编号为1\sim N1∼N,他采取如下的方法: 先将11号同学安排进队列,这时队列中只有他一个人: 2-N2−N号同学依次入列,编号为i的同学 ...