笔记:Bridging the Gap Between Relevance Matching and Semantic Matching for Short Text Similarity Modeling
笔记:Bridging the Gap Between Relevance Matching and Semantic Matching for Short Text Similarity Modeling
发表情况:EMNLP2019
发表作者:Jinfeng Rao FaceBook
模型提出:HCAN
摘要:
信息检索(IR)的核心问题是相关性匹配,即通过与用户查询的相关性来对文档进行排名。另一方面,可以将许多NLP问题(例如QA和PI)都可以视为语义匹配的变相问题,语义匹配用于测量两个短文本之间在语义上的距离。但是两种类型的方法似乎无法混用,为了解决这一问题,作者提出了HCAN (Hybrid Co-Attention Network),同时消融研究表明,关联性和语义匹配信号在许多问题上是互补的,并且将它们组合可以提高数据效率。
引言:
尽管在语义和相关性匹配上都需要在成对的文本中建模相似,但是存在根本的区别。语义匹配通过利用词汇信息(例如单词,短语,实体)和组成结构(例如依赖树)来强调“含义”对应关系,而相关性匹配则侧重于关键字匹配。已经观察到,在NLP中用于文本相似性建模的现有方法对于IR任务可能会产生较差的结果(Guo等,2016),反之亦然(Htut等,2018)。
【reference】Jiafeng Guo, Yixing Fan, Qingyao Ai, and W. Bruce Croft. 2016. A deep relevance matching model for ad-hoc retrieval.
为了解释它们的区别,文中引用了一个对比:

表格中三句话,label是用来表示两句话是否相似、重复,第一个例子共享许多常用关键字,并被确定为相关;第二个例子,两句话共享除主题以外的所有单词,因此不被视为重复对;所以仅基于关键字匹配的方法不太可能区分,相反,第三个示例被判断为相关的QA对,因为不同的术语传达了相似的语义。
相关性匹配本质上是一项匹配任务,有一些基于交互的设计在顶部构建复杂的模块以捕获其他n元语法匹配和术语重要性信号,来完成此任务,而一些NLP的问题(例如问题回答和文本相似性度量)需要更多的语义理解和上下文推理,而不是特定的术语匹配。为此,我们研究了两个研究问题:
(1)现有的相关性匹配和语义匹配方法是否可以轻松地彼此适配?
(2)关联性和语义匹配的信号是否互补?
插曲:语义匹配和相关性匹配
语义匹配(Semantic Matching)
在这些语义匹配任务中,两个文本通常是同质的并且有很少的自然语言句子组成,如问答句子或对话。为了推断自然语言句子之间的语义关系,语义匹配强调以下3个因素:
- Similarity matching signals:不同的项表达着相似的意思或者具有推断关系等相关的意思。
- Compositional meanings:更关注语法结构而非词的集合/词的序列,同时明确的语法结构对该NLP任务至关重要。
- Global matching requirement:考虑文本的整体信息。
相关性匹配(Relevance Matching)
在相关性匹配任务中,查询文本通常很短并且基于关键词,而文档的长度是变化的,从几十个词到上千上万个词。为了检验查询和文档之间的相关性,相关性匹配主要关注于以下三个:
Exact matching sigals:尽管词项的错误匹配在ad-hoc检索中是一个重要问题,并且已经用不同的语义相似度信号来处理。但由于现代搜索引擎中的索引和搜索范例,文档和查询中的精确匹配项仍然是最重要的信号。先前的研究表明原始查询项匹配的相关性得分总是不低于多次对语义相关的项进行匹配。这也解释了为什么一些传统的检索模型,例如BM25,可以完全基于精确匹配信号很好地工作。
Query term importance:在Ad-hoc检索中,通常比较短的query没有复杂的语法结构,主要包括一些关键词。所以query的term的重要性值得考虑。
Diverse matching requirement:Verbosity Hypothesis认为长文档和短文档类似,也包括一个相似的范围;Scope Hypothesis认为长文档是不相关的短文档的集合,所以文章不一定要整个与query相关。
其实总的来说:
(1)相关性匹配主要关注于关键词的对比,因此更关注低层级词法、语法结构层面的匹配性;
(2)语义匹配代表着文本的平均意义,需要获取上下文信息的表示,因此其关注更高、更抽象的语义层面的匹配性
模型组成:
为了解决上面的两个问题,作者提出了HCAN模型,主要包括三部分:
1.一种混合encoder模块
2.一个相关性匹配模块
3.一个语义匹配模块
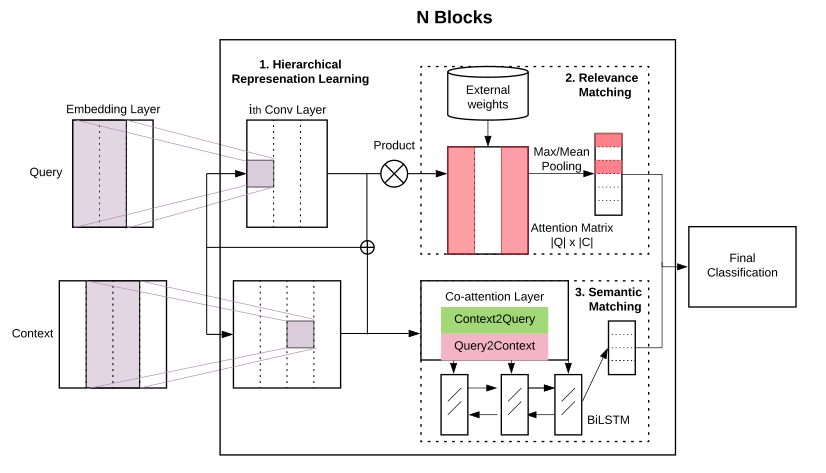
一、Hybrid Encoders
模型的输入为查询(query)和与之比较的文本(context),目标就是让模型判断两者间的匹配程度。为了捕获短语级的表示,这里使用了三种类型的encoder,作者将其称为deep、wide和contextual。
1.1 Deep Encoder:
堆叠N个CNN层对应于获得第h层的输出矩阵
\]
1.2 Wide Encoder:
并行地将输入向量通过N个卷积层,每个卷积层具有不同的窗口大小k以获得对应的
k-gram语法表示。给定N个卷积层,CNN层的窗口大小将为[k,k + 1,...,k + N-1]。
1.3 Contextual Encoder:
通过双向的LSTM来获取较长范围内的上下文特征,给定N个Bi-LSTM层,第h层的输出如下:
\]
至于这三种encoder哪一种更好,作者在实验部分具体结合不同的任务给出了比较。
二、相关性匹配
相关性匹配是将query表示\(Uq\)与doc表示\(Uc\)两个矩阵相乘(内积),得到一个相似性得分矩阵 \(S= U_{q}U_{c}^{T},S\in R^{n\times m}\),对q每个词的得分向量做softmax归一化,然后对每个得分向量做mean-pooling和max-pooling,\(Max(S) = [max(\tilde{S1},:), ...,max(\tilde{Sn},:)],Mean(S) = [mean(\tilde{S1},:), ..., mean(\tilde{Sn},:)],Max(S),Mean(S) ∈ R^n\),最终得到每一个词进行池化后的向量,即相关性匹配的信息,作者在文中提到term(词)的重要性建模对于某些搜索任务可能很重要,因此他们将外部权重作为先验知识来衡量不同查询词和短语的相对重要性,最终将之前的得到的相关匹配向量乘上各个词的权重(外部知识),得到二维的相关性匹配输出\(O_{RM}=\left\{wgt(q)\odot Max(S), wgt(q)\odot Mean(S)\right \},O_{RM}∈ 2 · R^n,\),\(wgt(q)^{i}\)表示查询query中第i个词或短语的权重。作者选择IDF作为权重函数,IDF权重越高,表示集合中出现的情况越少,因此,判别力就越大。加权方法还使我们能够减少对常见词(如停用词)的较大匹配分数的影响。
三. 语义匹配
首先利用下列公式计算双线性attention:\(A=REP\left (U_{q}W_{q} \right )+REP\left (U_{c}W_{c} \right )+U_{q}W_{b} U_{c}^{T}\),对接计算出来的bilinear attention矩阵按列归一化:\(A=softmax_{col}(A),A\epsilon R^{N\times M}\),其中REP函数适用于将\((U_{q}W_{q})、(U_{c}W_{c})\)得到的两个维度分别为n、m的向量,通过重复元素的方法来得到nxm的矩阵。
接下来从两个方向进行co-attention:query-to-context和context-to-query,如下所示:这里作者参考了ICLR2017的一篇论文计算biattention的方法:Bidirectional Attention Flow for Machine Comprehension(2017)。
query-to-context::\(\tilde{U}_{q}=A^{T}U_{q}\),前面的到了权重矩阵A,而且A是按照列进行了归一化的,所以直接对\(U_{q}\)进行加权求和,这样得到的应该是就得到了对每一个 query word 而言哪些 context words 和它最相关。
context-to-query:\(\tilde{U}_{c}= REP(max_{col}(A)U_{c})\),计算对每一个 cotex word 而言哪些 query words 和它最相关,取权重矩阵每列最大值,对其进行 softmax 归一化后对Uc加权和。
\(\tilde{U}_{q}\epsilon R^{m×F},\tilde{U}_{c}\epsilon R^{m×F}\),其中\(max_{col}(A)\)表示将A按列求max,得到一个m维(1xm)的向量。
最后,作者进行了一个拼接: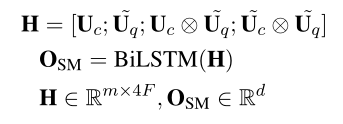 ,并将拼接后的向量送入一个双向的LSTM,以此来捕获序列中的上下文依赖,最终获得语义匹配模块的输出\(O_{SM}\)。
,并将拼接后的向量送入一个双向的LSTM,以此来捕获序列中的上下文依赖,最终获得语义匹配模块的输出\(O_{SM}\)。
四.最终分类
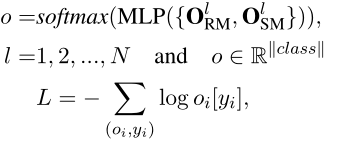
损失函数采用的是NLL,负对数似然函数,N是编码器层数。
实验部分
本文作者选择了三个NLP任务和两个信息检索的数据集进行实验:
| Task | 描述 | 数据集 | 评价指标 |
|---|---|---|---|
| Answer Selection | 根据相似性对候选的句子进行排序 | TrecQA | MAP、MRR |
| Paraphrase Identification | 判断两个句子是否互为释义(是否描述同一个意思) | TwitterURL | macro-F1 |
| Semantic Textual Similarity (STS) | 测量文本对之间的语义等效程度 | Quora | Accuracy |
| Tweet Search | 根据与简短查询的相关性对候选推文进行排名 | TREC Microblog 2013 | MAP、P@30 |
| Tweet Search | 根据与简短查询的相关性对候选推文进行排名 | TREC Microblog 2014 | MAP、P@30 |
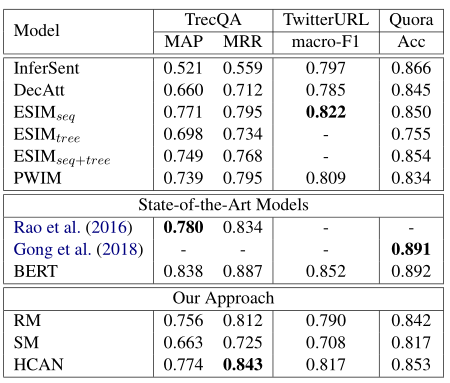
实验结果效果展示:
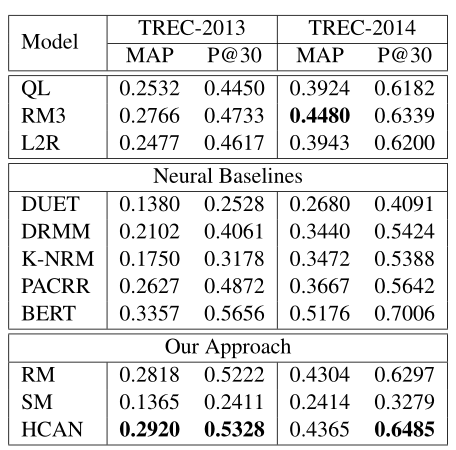
实验细节:
300d word2vec (Mikolov et al., 2013) embeddings、SGD 优化器、对于词表外单词,使用[0,0.1]的均匀分布来初始化其单词嵌入、CNN层N=4,滤波器大小:2,隐藏层维度: 150,滤波器数量F: [128, 256, 512]、学习率:[0.05, 0.02, 0.01]、batch_size: [64, 128, 256]、drop_out: 0.1~0.5
三种编码器的效果对比
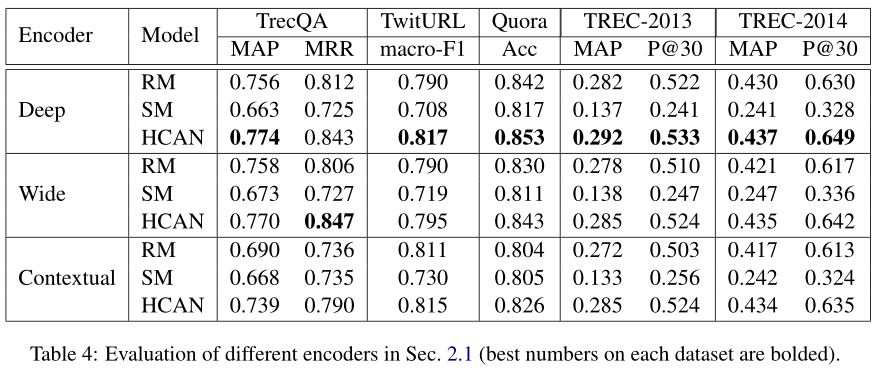
从实验中可以看出Deep Encoder效果和Wide Encoder的效果是最为接近的,Context Encoder在TrecQA上的性能比另外两个差,但在所有其他数据集上是具有可比性的。
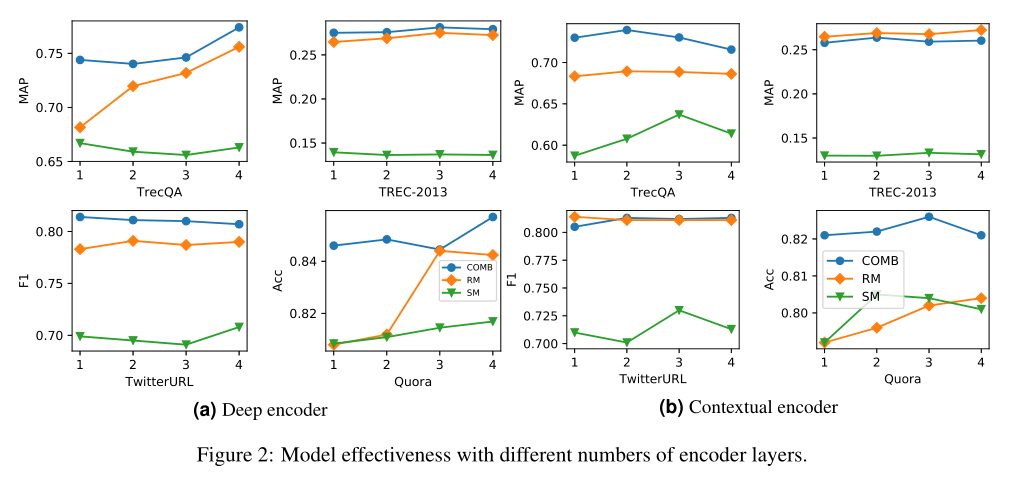
此外,因为deep和wide编码器效果接近,为了更好的比较与上下文编码器的对比效果,作者还观察了不同层数的一个效果,结果显示联合的匹配要比单独的SM、RM有效果,此外从图2b上下文编码器的效果可以看出,增加LSTM的层数并不能提升效果,因为单个BiLSTM层(N = 1)已经可以捕获长距离的上下文信息,并且增加层数可以引入更多参数并导致过度拟合。
学习效率
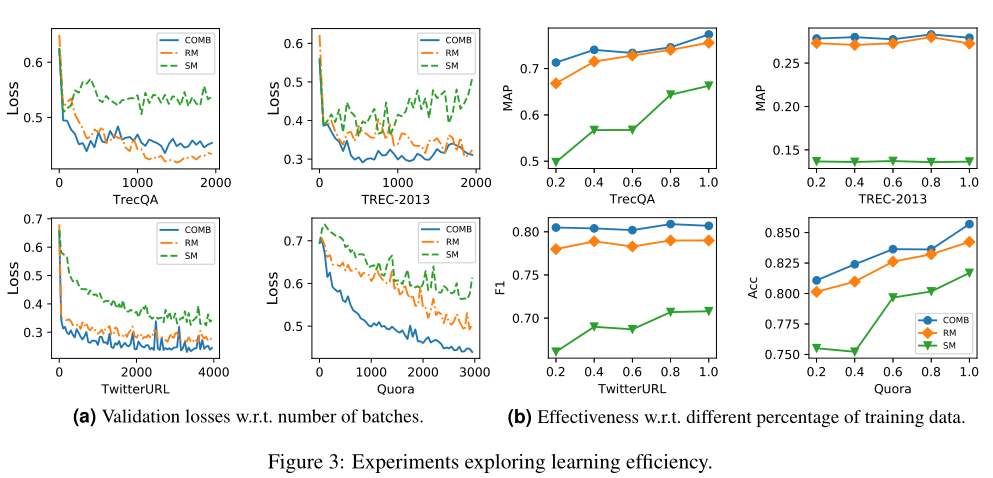
作者同样对比了联合、单独使用SM、RM的效果,(a)展示了不同批次的损失、(b)展示了不同数据大小也就是不同比例的训练数据的效果,可以看出联合的模型损失下降的速度是最快的,此外在使用更多数据训练的时候会获得更好的效果。
样例展示
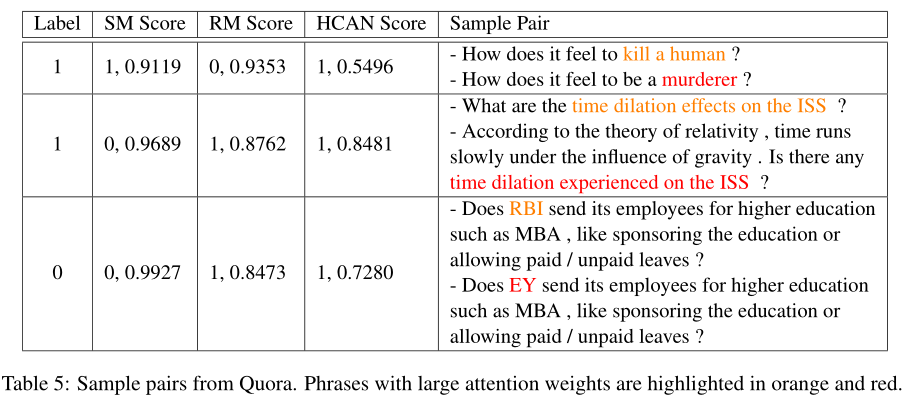
其中,label列 1表示匹配,0表示不匹配,对于每个模型,给出了输出其预测标签以及其置信度分数,注意权重较大的词组用橙色和红色突出显示。从图中可以看出,在第一个示例中,SM能够正确地识别出这两个句子具有高置信度传达相同的含义,而RM则失败了,因为SM是注重低层次语法的匹配,而这两个短语IDF权重很高,但是却不匹配。第二个示例中的句子对具有较大的文本重叠。毫不奇怪,RM会预测出较高的相关性得分,而SM无法捕获它们的相关性。在两个示例中,HCAN都可以集成SM和RM来做出正确的预测。由于第三个示例显示了类似的模式,因此我们省略了详细说明。总体而言,我们的定量和定性分析表明,RM匹配在捕获基于重叠的信号方面更好,而组合SM匹配信号则可以改善表示学习。
其他
IR中的评价指标
P@N:前N个结果的准确率
MAP(mean average precision)平均准确率:假设有两个主题,主题1有4个相关网页,主题2有5个相关网页。某系统对于主题1检索出4个相关网页,其rank分别为1, 2, 4, 7;对于主题2检索出3个相关网页,其rank分别为1,3,5。对于主题1,平均准确率为(1/1+2/2+3/4+4/7)/4=0.83。对于主题 2,平均准确率为(1/1+2/3+3/5+0+0)/5=0.45。则MAP=(0.83+0.45)/2=0.64。
笔记:Bridging the Gap Between Relevance Matching and Semantic Matching for Short Text Similarity Modeling的更多相关文章
- Elasticsearch学习笔记(十四)relevance score相关性评分的计算(1)
一.多shard场景下relevance score不准确问题 1.问题描述: 多个shard下,如果每个shard包含指定搜索条件的document数量不均匀的情况下, ...
- LeetCode 笔记28 Maximum Gap
Given an unsorted array, find the maximum difference between the successive elements in its sorted f ...
- 论文笔记 — MatchNet: Unifying Feature and Metric Learning for Patch-Based Matching
论文:https://github.com/ei1994/my_reference_library/tree/master/papers 本文的贡献点如下: 1. 提出了一个新的利用深度网络架构基于p ...
- 论文笔记系列-Auto-DeepLab:Hierarchical Neural Architecture Search for Semantic Image Segmentation
Pytorch实现代码:https://github.com/MenghaoGuo/AutoDeeplab 创新点 cell-level and network-level search 以往的NAS ...
- 论文笔记:Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells
Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells 2019-04- ...
- 论文笔记:Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation
Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation2019-03-18 14:4 ...
- 论文阅读笔记三:R2CNN:Rotational Region CNN for Orientation Robust Scene Text Detection(CVPR2017)
进行文本的检测的学习,开始使用的是ctpn网络,由于ctpn只能检测水平的文字,而对场景图片中倾斜的文本无法进行很好的检测,故将网络换为RRCNN(全称如题).小白一枚,这里就将RRCNN的论文拿来拜 ...
- 论文阅读笔记: Multi-Perspective Sentence Similarity Modeling with Convolution Neural Networks
论文概况 Multi-Perspective Sentence Similarity Modeling with Convolution Neural Networks是处理比较两个句子相似度的问题, ...
- 【阅读笔记】Ranking Relevance in Yahoo Search (一)—— introduction & background
ABSTRACT: 此文在相关性方面介绍三项关键技术:ranking functions, semantic matching features, query rewriting: 此文内容基于拥有百 ...
随机推荐
- 【LeetCode】389. Find the Difference 解题报告(Java & Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 方法一:字典统计次数 方法二:异或 方法三:排序 日 ...
- 【九度OJ】题目1153:括号匹配问题 解题报告
[九度OJ]题目1153:括号匹配问题 解题报告 标签(空格分隔): 九度OJ http://ac.jobdu.com/problem.php?pid=1153 题目描述: 在某个字符串(长度不超过1 ...
- hdu-3833 YY's new problem(数组标记)
http://acm.hdu.edu.cn/showproblem.php?pid=3833 做这题时是因为我在网上找杭电的数论题然后看到说这道题是数论题就点开看了以下. 然后去杭电上做,暴力,超时了 ...
- A1. 道路修建 Small(BNUOJ)
A1. 道路修建 Small Time Limit: 1000ms Memory Limit: 131072KB 64-bit integer IO format: %lld Java cl ...
- 第二十六个知识点:描述NAF标量乘法算法
第二十六个知识点:描述NAF标量乘法算法 NAF标量乘法算法是标量乘法算法的一种增强,该算法使用了非邻接形式(Non-Adjacent Form)表达,减少了算法的期望运行时间.下面是具体细节: 让\ ...
- Chapter 13 Standardization and The Parametric G-formula
目录 13.1 Standardization as an alternative to IP weighting 13.2 Estimating the mean outcome via model ...
- Going Deeper with Convolutions (GoogLeNet)
目录 代码 Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[C]. computer vision and pattern ...
- Typec转HDMI+VGA+PD3.0+USB3.0扩展坞四合一芯片方案|CS5268替代AG9321
CS5268是一种高度集成的单芯片,适用于多个细分市场和显示应用,如拓展坞.扩展底座等. 2.CS5268参数说明 总则 USB Type-C规范1.2 HDMI规范v2.0b兼容发射机,数据速率高达 ...
- gogs安装与说明(docker)
作为一个开发,少不了和git打交道,像github,gitee是很流行的git线上托管平台,而我们也搭建自己的git托管平台,有条件的可以使用gitlab,它对硬件有要求,像博主这种没条件用虚拟机的, ...
- CGO快速入门
1. 通过`improt "C"`语句开启CGO特性2. `/**/`中间是C代码,之后接 import "C" 如果存在空行 就会报错.could not d ...