Selective Kernel Networks
摘要:在标准的卷积神经网络(CNNs)中,每一层的人工神经元的感受野被设计成具有相同的大小。众所周知,视觉皮层神经元的感受野大小受刺激的调节,但在构建cnn时却很少考虑到这一点。我们在神经网络中提出了一种动态选择机制,允许每个神经元根据输入信息的多个尺度自适应地调整其感受野大小。设计了一种被称为选择核单元(Selective Kernel, SK)的构件,该构件利用分支中信息引导的softmax注意力来融合不同核大小的多个分支。对这些分支的不同关注产生不同大小的融合层神经元的有效感受野。多个SK单元被堆叠到一个称为选择性内核网络(Selective Kernel Networks, SKNets)的深层网络中。在ImageNet和CIFAR基准测试上,我们的经验表明,SKNet以较低的模型复杂度优于现有的最先进的体系结构。详细的分析表明,SKNet中的神经元能够捕获不同尺度的目标,验证了神经元能够根据输入自适应地调整其感受野大小。
论文地址:1903.06586.pdf (arxiv.org)
1.引言
猫的初级视觉皮层(V1)中神经元的局部接受域(RFs)在上个世纪启发了卷积神经网络(CNNs)[26]的构建,并继续启发了现代CNN结构的构建。例如,众所周知,在视觉皮层中,同一区域(如V1区域)神经元的RF大小不同,使得神经元在同一处理阶段能够收集多尺度的空间信息。这种机制在近年来的卷积神经网络(CNNs)中被广泛采用。一个典型的例子是InceptionNets[42, 15, 43, 41],其中一个简单的连接被设计用来聚合来自“inception”构建块内的多尺度信息,例如3×3, 5×5, 7×7卷积内核。
然而,在设计神经网络时还没有强调皮质神经元的射频特性,其中一个特性就是射频大小的自适应变化。大量的实验证据表明,视觉皮层神经元的RF大小不是固定的,而是受刺激调节的。Hubel和Wiesel[14]发现了V1区神经元的经典RFs (CRFs),通过单定向条确定。后来很多研究(如[30])发现CRF外的刺激也会影响神经元的反应。神经元被称为非经典RFs (nCRFs)。此外,nCRF的大小与刺激的对比度有关:对比度越小,有效nCRF的大小[37]越大。令人惊讶的是,通过刺激nCRF一段时间,在去除这些刺激[33]后,神经元的CRF也会增大。所有这些实验表明,神经元的RF大小不是固定的,而是由刺激[38]调节的。不幸的是,在构建深度学习模型时,这一特性并没有得到足够的重视。那些在同一层中具有多尺度信息的模型,如InceptionNets,具有一种固有的机制,可以根据输入的内容调整下一个卷积层中神经元的RF大小,因为下一个卷积层线性聚合来自不同分支的多尺度信息。但这种线性聚集的方法可能不足以提供神经元强大的适应能力。
在本文中,我们提出了一种非线性的方法来聚合多个核的信息,以实现自适应的射频大小的神经元。我们引入了一个“选择核”(SK)卷积,它由一个三重算子:Split, Fuse和Select组成。Split算子生成不同核大小的多条路径,这些路径对应不同的RF神经元大小。Fuse算子结合并聚合来自多条路径的信息,以获得选择权重的全局和全面表示。Select运算符根据选择权聚合不同大小内核的特征映射。
SK卷积的计算量很轻,只会略微增加参数和计算成本。我们在ImageNet 2012数据集上证明了[35]SKNets在具有相似的模型复杂度时优于以前的先进模型。在SKNet50的基础上,我们找到了SK卷积的最佳设置,并显示了每个分量的贡献。为了展示它们的普遍适用性,我们还提供了更小的数据集(CIFAR-10和100[22])上引人注目的结果,并成功地将SK嵌入到小模型(例如ShuffleNetV2[27])中。
为了验证所提模型确实具有调节神经元射频大小的能力,我们通过放大自然图像中的目标物体和缩小背景来模拟刺激,以保持图像大小不变。研究发现,当目标物体越来越大时,大部分神经元从较大的核路径中收集信息的次数也越来越多。这些结果表明,所提出的SKNet中的神经元具有自适应的射频大小,这可能是该模型在对象识别方面优越性能的基础。
2.相关工作
多分支卷积网络。公路网[39]引入了旁路路径和浇注单元。双分支体系结构减轻了数百层网络训练的难度。ResNet中也使用了这种思想[9,10],但是绕过的路径是纯粹的身份映射。除了身份映射外,抖动网络[7]和多残差网络[1]用更多相同的路径扩展了主要变换。深度神经决策森林[21]形成了树状结构的多分支原理,具有学习到的分裂函数。FractalNets[25]和Multilevel ResNets[52]的设计方式是可以分形和递归地扩展多条路径。InceptionNets[42, 15, 43, 41]小心地用定制的内核过滤器配置每个分支,以聚合更多的信息和多种特性。请注意,提议的SKNets遵循了InceptionNets的思想,为多个分支提供了各种过滤器,但至少在两个重要方面有所不同:1) SKNets方案简单得多,无需大量定制设计,2)利用这些多分支的自适应选择机制来实现自适应的神经元RF大小。
分组/深度卷积/扩张卷积。分组卷积由于其计算成本低而越来越流行。用G表示组的大小,那么参数的个数和计算代价都要除以G,与普通的卷积相比。它们首先在AlexNet[23]中被采用,目的是将模型分布在更多的GPU资源上。令人惊讶的是,使用分组卷积,ResNeXts[47]也可以提高准确率。这个G被称为“基数”,它与深度和宽度一起描述了模型。
在交叉分组卷积的基础上,开发了IGCV1[53]、IGCV2[46]和IGCV3[40]等紧凑模型。分组卷积的一种特殊情况是深度卷积,其中分组的数量等于通道的数量。Xception[3]和MobileNetV1[11]引入了深度可分离卷积,它将普通卷积分解为深度卷积和逐点卷积。深度卷积的有效性在随后的工作中得到了验证,如MobileNetV2[36]和ShuffleNet[54,27]。除了分组/深度卷积,扩展卷积[50,51]支持射频的指数级扩展而不丢失覆盖。例如,一个3×3与膨胀率为2的卷积可以近似覆盖5×5滤波器的RF,同时消耗不到一半的计算和内存。在SK卷积中,较大尺寸的内核(例如>1)被设计为与分组/深度/扩展卷积集成,以避免沉重的开销。
注意力机制。最近,从自然语言处理中的神经机器翻译[2]到图像理解中的图像字幕[49],注意机制的好处已经在一系列任务中得到了展示。它偏向信息最丰富的特征表达式的分配[16,17,24,28,31],同时抑制了不那么有用的特征表达式。注意力在最近的应用中得到了广泛的应用,如人脸识别[4]、图像恢复[55]、文本提取[34]和唇读[48]。为了提高图像分类的性能,Wang等人[44]提出了CNN中间阶段之间的trunk-and-mask注意。引入沙漏模块实现空间维度和通道维度的全局强调。此外,SENet[12]带来了一个有效的,轻量级的门机制,通过通道的重要性自我重新校准特征图。除了channel之外,BAM[32]和CBAM[45]也以类似的方式引入了空间注意力。相比之下,我们提出的SKNets是第一个明确关注自适应RF神经元大小通过引入注意力机制。
动态卷积。空间变换网络[18]学习参数变换来扭曲特征图,这被认为是难以训练的。动态卷积核[20]只能自适应修改过滤器参数,没有调整内核大小。主动卷积[19]通过偏移量增加了卷积中的采样位置。这些偏移量是端到端的学习,但训练后变成静态的,而在SKNet中,神经元的射频大小可以在推理过程中自适应地变化。可变形卷积网络[6]进一步使位置偏移是动态的,但它不像SKNet那样聚合多尺度信息。
3.思想
3.1. 选择核卷积
为了使神经元能够自适应地调整它们的RF大小,我们提出了一个自动选择操作,“选择核”(SK)卷积,在多个不同核大小的核之间。具体来说,我们通过三个操作符—split, Fuse和Select来实现SK卷积,如图1所示,其中显示了一个两分支的情况。因此,在本例中,只有两个具有不同内核大小的内核,但是很容易扩展到多个分支的情况。
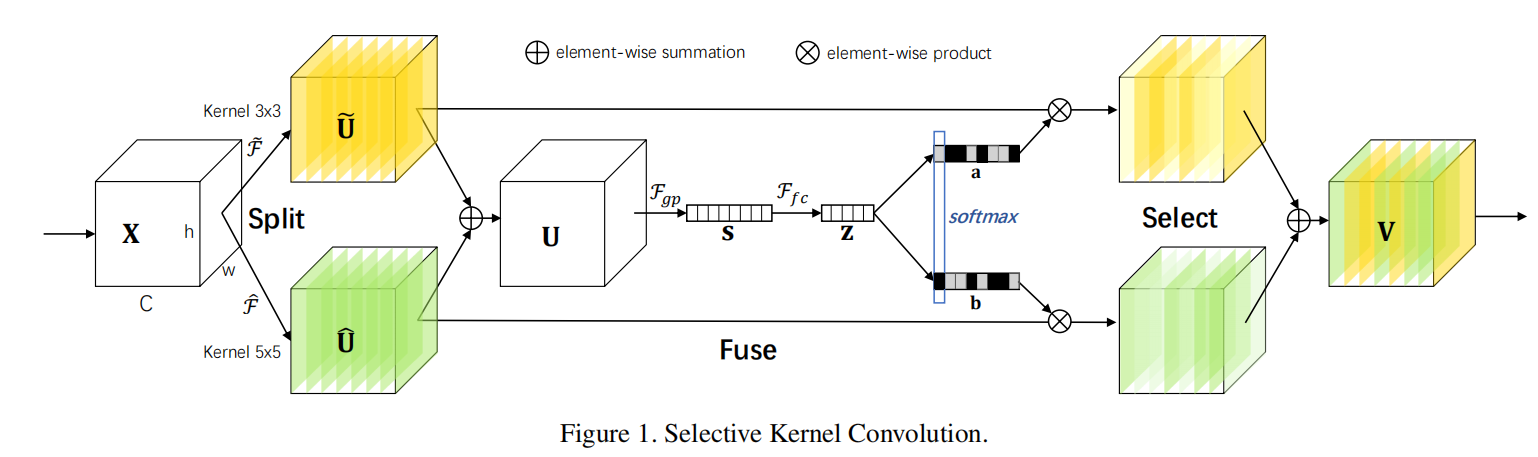
分割:对于任何给定的特征映射,默认我们首先进行两个变换:核大小分别为3和5。注意,f和bf都是由高效的分组/深度卷积、批归一化[15]和ReLU[29]函数顺序组成的。为了进一步提高效率,将与5×5内核的常规卷积替换为与3×3内核的扩展卷积,扩展大小为2。
融合:如引言所述,我们的目标是使神经元能够根据刺激内容自适应地调整它们的射频大小。其基本思想是使用“门”来控制来自多个分支的信息流,这些分支携带不同规模的信息进入下一层的神经元。为了实现这个目标,这些门需要集成来自所有分支的信息。我们首先将多个分支(图1中为两个)的结果通过元素求和进行融合:
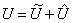 (1)
(1)
然后,我们通过简单地使用全局平均池化生成的信道统计信息来嵌入全局信息。具体来说,s的第c个元素是通过空间维度H × W收缩U来计算的:
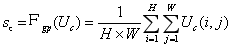 (2)
(2)
此外,创建了一个紧凑的特征z∈Rd×1,以实现精确和自适应选择的指导。这是通过一个简单的全连接(fc)层实现的,通过降低维度来提高效率:
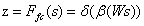 (3)
(3)
其中,δ为ReLU函数[29],B表示批标准化[15],W∈Rd×C。为了研究d对模型效率的影响,我们用一个缩减比r来控制它的值:
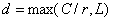 (4)
(4)
其中L表示d的最小值(L = 32是我们实验中的典型设置)。
选择:一个跨通道的软注意被用来自适应地选择信息的不同空间尺度,它由紧凑的特征描述符z引导。具体来说,一个softmax算子被应用于基于通道的数字:
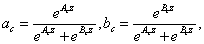 (5)
(5)
其中,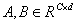 ,a,b分别表示
,a,b分别表示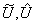 的软注意向量。注意,是A的第c行,ac是A的第c个元素,同样Bc和bc。在两个分支的情况下,矩阵B是冗余的,因为ac+ bc= 1。通过各核上的关注权值得到最终的特征图V:
的软注意向量。注意,是A的第c行,ac是A的第c个元素,同样Bc和bc。在两个分支的情况下,矩阵B是冗余的,因为ac+ bc= 1。通过各核上的关注权值得到最终的特征图V:
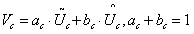 (6)
(6)
式中V = [V1,V2,…, VC], VC∈RH×W。注意,这里我们为两个分支的情况提供了一个公式,通过扩展Eqs可以很容易地推导出有更多分支的情况。(1)(5)(6)。
3.2. 网络架构
使用SK卷积,表1列出了整个SKNet体系结构。我们从ResNeXt[47]开始,有两个原因:1)它具有较低的计算成本,广泛使用分组卷积;2)它是在目标识别方面具有高性能的最先进的网络架构之一。与ResNeXt[47]类似,所提出的SKNet主要由一堆重复的瓶颈块组成,这些瓶颈块被称为“SK单元”。每个SK单元由1×1卷积序列、SK卷积序列和1×1卷积序列组成。一般情况下,ResNeXt中原始瓶颈块中的所有大核卷积都被所提出的SK卷积所替代,使得网络能够自适应地选择合适的接受域大小。由于SK卷积在我们的设计中非常高效,与ResNeXt-50相比,SKNet-50只增加了10%的参数数量和5%的计算成本。
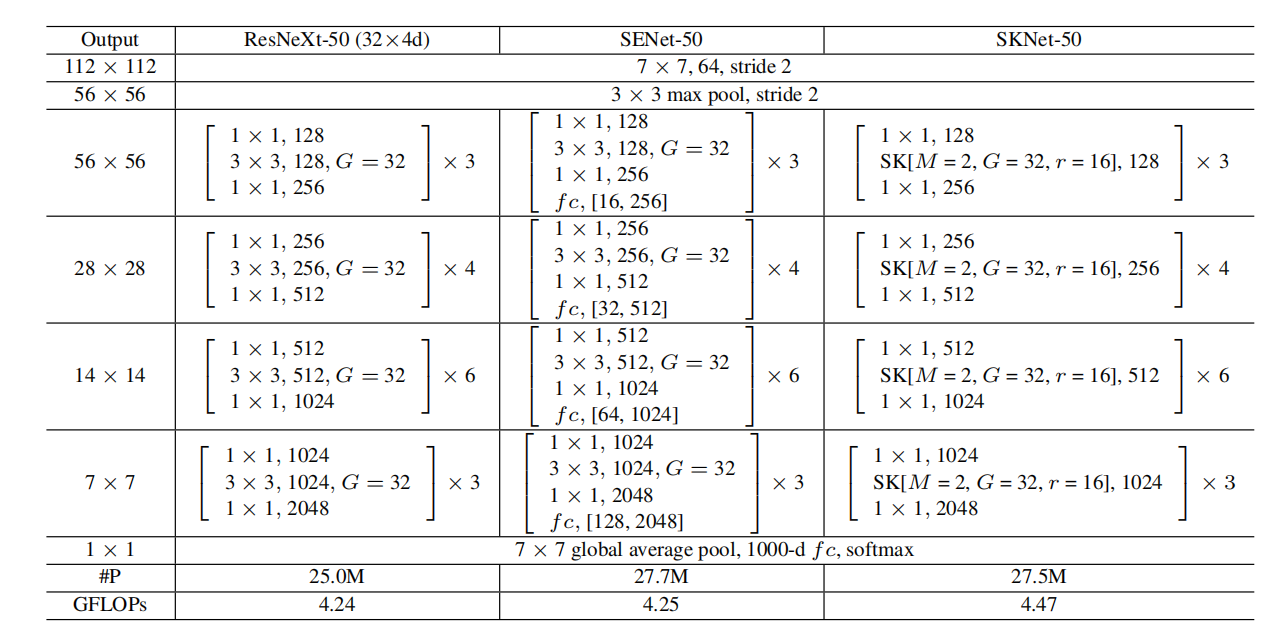
表1:这三列分别是带有32×4d模板的ResNeXt-50、基于ResNeXt-50骨干的SENet-50和相应的SKNet-50。括号内是剩余块的一般形状,包括过滤器大小和特征维度。每个阶段的堆叠块的数量在括号外显示。“G = 32”表示分组卷积。f c后面的内括号表示SE模块中两个全连接层的输出尺寸。#P表示参数的个数,后跟[54]的是FLOPs的定义,即乘法加的个数。
在SK单元中,有三个重要的超参数决定了SK卷积的最终设置:路径数M(决定要聚合的不同内核的选择数),组数G(控制每条路径的基数),以及减少比率r(控制fuse算子中的参数数)(见Eq.(4))。在表1中,我们将SK卷积SK[M, G, r]的一个典型设置表示为SK[2,32,16]。这些参数的选择和影响将在第4.3节中讨论。
表1显示了一个50层SKNet的结构,它有四个阶段,分别使用{3,4,6,3}SK单元。通过改变每个阶段SK单元的数量,可以获得不同的架构。在本研究中,我们对另外两个体系结构SKNet-26(具有{2,2,2,2}SK单元)和SKNet-101(具有{3,4,23,3}SK单元)分别进行了四个阶段的实验。
需要注意的是,所提出的SK卷积可以应用于其他轻量级网络,例如,MobileNet [11,36], ShuffleNet[54,27],其中3×3深度卷积被广泛使用。通过将这些卷积替换为SK卷积,我们也可以在紧凑的体系结构中获得非常吸引人的结果(见4.1节)。
4.实验
4.1. ImageNet分类
ImageNet 2012数据集[35]包含128万张训练图像和来自1000个类的50K验证图像。我们在训练集中训练网络,并在验证集中报告排名前1的错误。对于数据扩充,我们遵循标准实践并执行随机大小裁剪到224 ×224和随机水平翻转[42]。采用实际的平均信道减法对输入图像进行归一化处理,进行训练和测试。训练中使用标签平滑正则化[43]。对于大型模型,我们使用动量0.9的同步SGD,小批量大小为256,重量衰减为1e-4。初始学习速率设置为0.1,并每30个时点减少10倍。使用[8]中的权重初始化策略,所有模型在8个gpu上从零开始训练100个epoch。对于训练轻量级模型,我们将权重衰减设置为4e-5,而不是1e-4,并且我们还使用稍微不那么积极的尺度增强来进行数据预处理。类似的修改也可以参考[11,54],因为这样的小网络通常是欠拟合而不是过拟合。为了进行基准测试,我们在验证集上应用中心裁剪,其中224×224或320×320像素被裁剪以评估分类精度。ImageNet上报告的结果是默认情况下3次运行的平均值。
与最先进的模型进行比较。我们首先将SKNet-50和SKNet-101与具有相似模型复杂度的公开竞争模型进行比较。结果表明,在类似的预算下,SKNets与最先进的基于注意力的cnn相比,性能不断提高。值得注意的是,SKNet-50比ResNeXt-101的性能高出绝对的0.32%,尽管ResNeXt-101在参数上比它大60%,在计算上比它大80%。与InceptionNets相当或更少的复杂性,SKNets实现超过1.5%的绝对性能增益,这是演示了多内核自适应聚合的优越性。我们还注意到,使用更少的参数,SKNets可以在224×224和320×320的评估中获得约0.3 ~ 0.4%的收益。
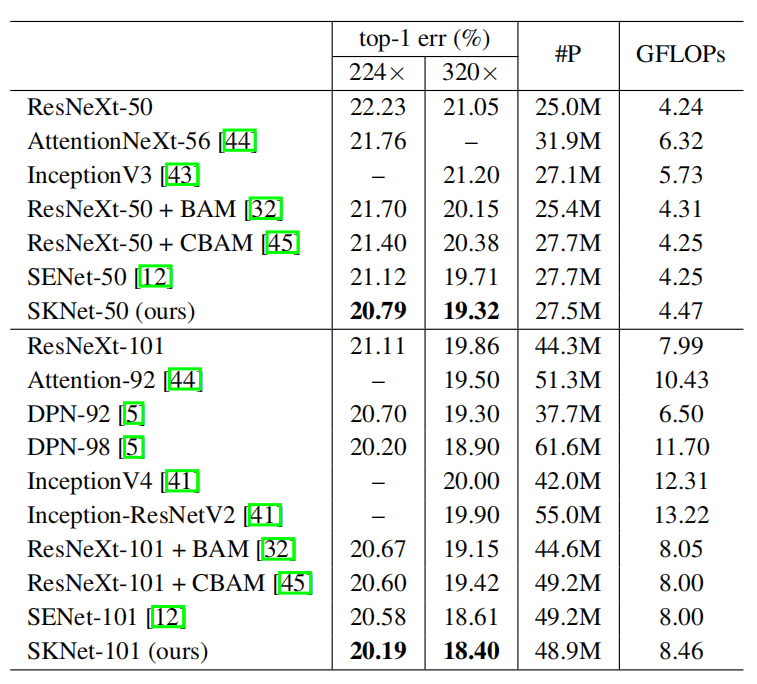
表2:在大致相同的复杂性下与先进技术进行比较。224×表示单批224×224, 320×表示单批224×224。注意,senet /SKNets都基于相应的ResNeXt骨干。
选择性内核vs.深度/宽度/基数。与ResNeXt(使用32×4d设置)相比,由于不同内核的额外路径和选择过程,SKNets不可避免地略微增加了参数和计算量。为了进行公平比较,我们通过改变其深度、宽度和基数来增加ResNeXt的复杂性,以匹配SKNets的复杂性。表3显示,复杂性的增加确实会带来更好的预测精度。
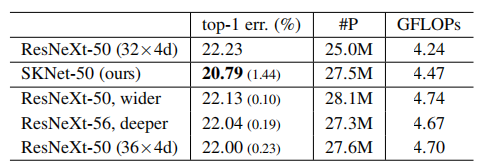
表3:当具有更多深度/宽度/基数的模型的计算成本增加到与SKNet相匹配时,对ImageNet验证集的比较。括号中的数字表示性能的收益。
但是,当进一步(从ResNeXt-50到ResNeXt-53为0.19%)或更宽(从ResNeXt-50到ResNeXt-50为0.1%),或基数略高(从ResNeXt-50 (32×4d)到ResNeXt-50 (36×4d)为0.23%)时,改进是微不足道的。
相比之下,SKNet-50比基线ResNeXt-50获得了1.44%的绝对改进,表明SK卷积是非常有效的。
性能与参数的数量有关。我们绘制了所提出的SKNet相对于其参数个数的top-1错误率(图2)。图中显示了三个架构,SK-26, SKNet-50和SKNet-101(详见3.2节)。为了比较,我们在图中绘制了一些最先进的模型的结果,包括ResNets[9]、ResNeXts[47]、DenseNets[13]、DPNs[5]和SENets[12]。每个模型都有多个变体。对比建筑的细节在补充材料中提供。参考文献中报告了所有排名前1的错误。可以看出,SKNets比这些模型更有效地利用参数。例如,为了实现约20.2个top-1错误,SKNet-101需要的参数比DPN-98少22%。
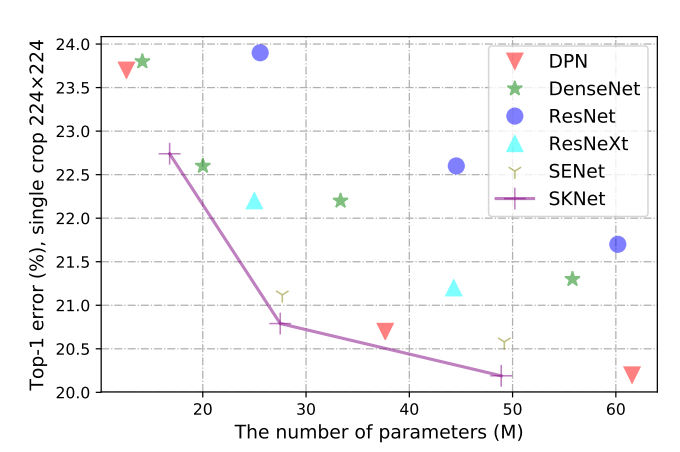
图2:SKNet的性能与其中的参数数量的关系,与最新的技术进行比较。
轻量级模型。最后,我们选择了具有代表性的紧凑结构- ShuffleNetV2[27],这是最强的光模型之一,来评估SK卷积的泛化能力。通过探索表4中模型的不同尺度,我们可以看到SK卷积不仅可以显著提高基线的精度,而且还可以显著提高基线的精度表现优于SE[12](实现约1%的绝对收益)。这表明了SK卷积在低端设备应用中的巨大潜力。
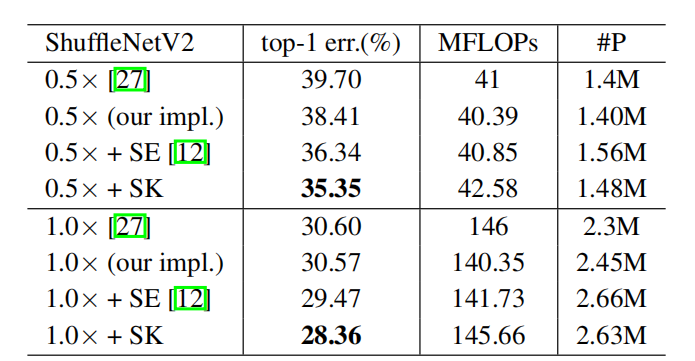
表4:单一224×224作物top-1错误率(%)由轻量级模型的变体在ImageNet验证集。
4.2. CIFAR分类
为了评估SKNets在较小数据集上的性能,我们在CIFAR-10和100[22]上进行了更多的实验。两个CIFAR数据集[22]由彩色自然场景图像组成,每个像素为32×32。训练集和测试集分别包含50k幅图像和10k幅图像。CIFAR-10有10个类,CIFAR-100有100个类。我们参照[47]中的架构:我们的网络只有一个3×3卷积层,然后是3个阶段,每个阶段有3个残差块,进行SK卷积。我们还在同一主干上应用SE块(ResNeXt29, 16×32d)以进行更好的比较。更多的建筑和培训细节在补充材料中提供。值得注意的是,SKNet-29获得了比ResNeXt-29, 16×64d更好或类似的性能,且参数更少60%,它在CIFAR-10和100上的性能始终优于SENet-29,参数更少22%。
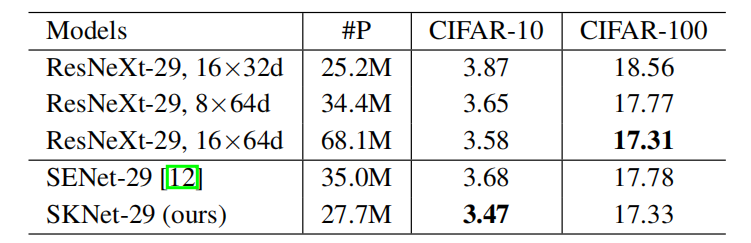
表5所示:CIFAR上排名前1的错误(%,平均10次运行)。SENet-29和SKNet-29均基于ResNeXt-29, 16×32d。
4.3. 消融实验
在本节中,我们报告了对ImageNet数据集的消融术研究,以调查SKNet的有效性。
膨胀率D和分组数G。膨胀D和G组数是控制射频大小的两个关键因素。为了研究它们的影响,我们从两个分支的情况出发,在SKNet-50的第一个内核分支中固定了扩展D = 1和组G = 32的3×3过滤器设置。
在总体复杂度相似的约束下,增加第二个核分支的RF有两种方法:1)在固定组数G的同时增加膨胀D; 2)同时增加滤波器大小和组数G。
表6显示了其他分支的最佳设置是那些内核大小为5×5(最后一列)的设置,它比第一个固定内核大小为3×3的设置大。结果表明,使用不同大小的内核是有益的,其原因是多尺度信息的聚集。

表6所示:SKNet-50在第二个分支中使用不同设置的结果,而第一个内核的设置是固定的。最后一列中的“结果内核”是指经过卷积扩展后的近似内核大小。
有两种最优配置:内核大小5×5 (D = 1)和内核大小3×3 (D = 2),后者的模型复杂度略低。一般来说,我们通过经验发现,具有各种膨胀的3×3系列内核在性能和复杂性方面都要比具有相同RF(没有膨胀的大内核)的相应内核要好一些。
不同卷积核的组合。接下来我们研究了不同籽粒组合的效果。有些内核的大小可能大于3×3,并且可能有两个以上的内核。为了限制搜索空间,我们只使用三种不同的内核,称为“K3”(标准3×3卷积内核)、“K5”(3×3卷积与膨胀2近似于5×5内核大小)和“K7”(3×3与膨胀3近似于7×7内核大小)。请注意,我们只考虑如表6所建议的大型内核的扩展版本(5×5和7×7)。G固定为32。如果“SK”在表7是赊销,这意味着我们使用SK注意力在相应的内核中打钩同一行(每个SK的输出单元是V图1),否则我们简单总结结果与这些内核(当时每个SK的输出单位U在图1)作为一个天真的基准模型。
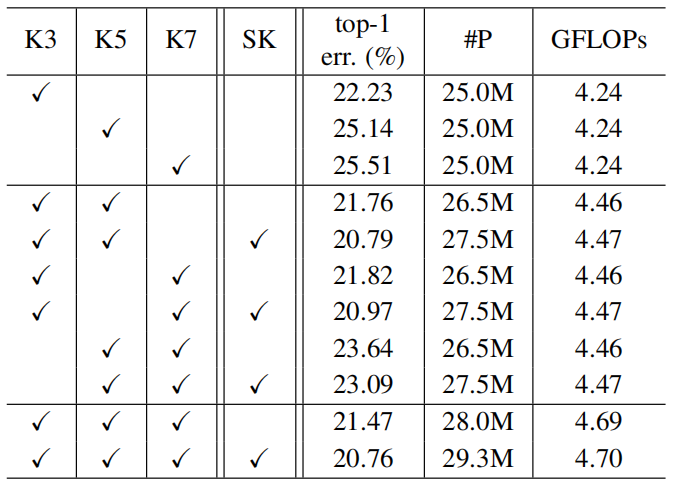
表7所示:SKNet-50不同卷积核组合的结果。单一224×224裁剪用于评价。
表7的结果表明,SKNets的优异性能可以归因于多内核的使用和其中的自适应选择机制。由表7可知:(1)当路径数M增加时,识别误差总体上减小。表中第一个块(M = 1)的top-1错误普遍高于第二个块(M = 2),第二个块的错误普遍高于第三个块(M = 3)。(2)无论M = 2还是3,基于SK的多路径注意力聚合总是比简单聚合方法(朴素基线模型)获得更低的top-1误差。(3)使用SK注意,模型从M = 2到M = 3的绩效增益是边际的(top-1误差从20.79%下降到20.76%)。为了更好地平衡性能和效率,M = 2是首选。
4.4. 分析和解释
为了理解自适应核选择是如何工作的,我们通过输入相同的目标对象但不同的尺度来分析注意力权重。我们从ImageNet验证集中获取所有图像实例,通过中央裁剪和随后的大小调整,逐步将中心对象从1.0×扩大到2.0×(见图3a,b左上角)。
首先,我们计算了每个SK单元中每个通道上的大内核(5×5)的注意值。图3a、b(左下)显示了SK 3 4中两个随机样本在所有通道中的注意值,图3c(左下)显示了所有验证图像中所有通道的平均注意值。可以看出,在大多数通道中,随着目标对象的增大,对大核(5×5)的注意权重增大,这说明神经元的接受域会自适应地变大,这与我们的预期一致。
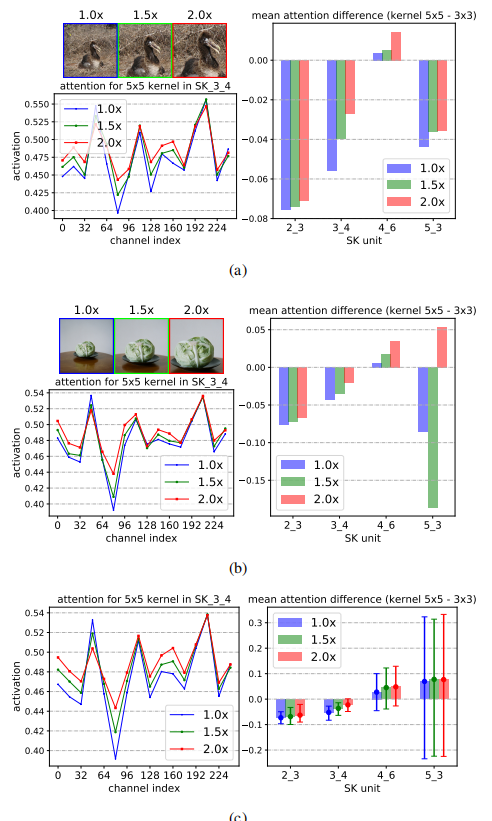
图3:(a)和(b):两个随机采样图像的注意结果,三个不同大小的目标(1.0x, 1.5x和2.0x)。左上角:样本图像。左下:在SK 3 4中,5×5内核跨通道的注意值。绘制的结果是便于查看的16个连续通道的平均值。右:内核5×5的关注值减去内核3×3在不同SK单位下的关注值。(c): ImageNet验证集中所有图像实例的平均结果。标准差也被绘制出来。
然后,我们计算在每个SK单位的所有通道上,与两个玉米粒相关的平均注意力权重(大减去小)的差值。图3a、图b(右)为两个随机样本在不同SK单位下的结果,图3c(右)为所有验证图像的平均值。我们发现了关于自适应选择在深度上的作用的一个令人惊讶的模式:目标对象越大,关注的焦点就越大。但是,在更高的层次上(例如,SK 5 3),所有的规模信息都丢失了,这样的模式消失了。
进一步,我们从类的角度深入研究选择分布。对于每个类别,我们绘制了所有属于该类别的50幅图像中,1.0×和1.5×目标在代表SK单位上的平均注意差异。我们在图4中展示了1000个类的统计数据。我们观察到前面的模式对所有1000个类别都是成立的,如图4所示,当目标的规模增加时,内核5×5的重要性一致且同时增加。这说明在网络的早期,可以根据对物体大小的语义感知来选择合适的核大小,从而有效地调整这些神经元的RF大小。但是,这种模式在非常高的层中不存在,比如SK 5 3,因为在高级表示中,“scale”部分编码在特征向量中,内核大小与较低层的情况相比更不重要。
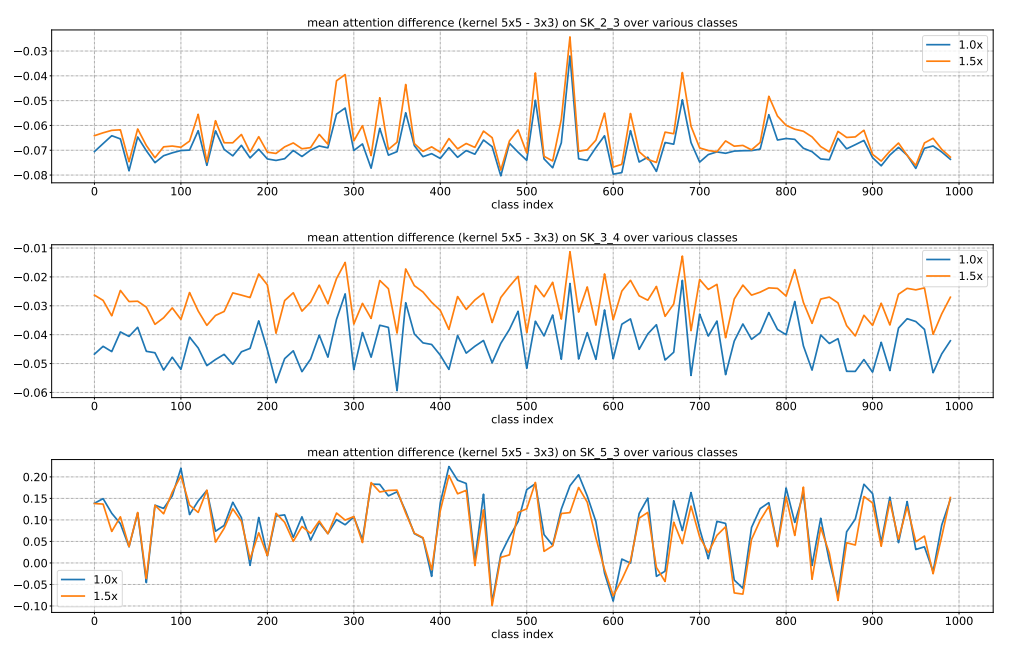
图4:使用ImageNet上的所有验证样本,对1000个类别中的每一个类别,在SKNet-50的SK单位上的平均平均注意差异(内核5×5的平均注意值减去内核3×3的注意值)。在较低或中等水平的SK单元(例如,SK 2 3, SK 3 4),如果目标对象变得更大(1.0x→1.5x), 5×5内核显然会被更加强调。图4。使用ImageNet上的所有验证样本,对1000个类别中的每一个类别,在SKNet-50的SK单位上的平均平均注意差异(内核5×5的平均注意值减去内核3×3的注意值)。在较低或中等水平的SK单元(例如,SK 2 3, SK 3 4),如果目标对象变得更大(1.0x→1.5x), 5×5内核显然会被更加强调。
5.结论
受视觉皮层神经元的自适应接受域(RF)大小的启发,我们提出了一种新的选择核(SK)卷积的electivekernelnetworks (SKNets),以软注意方式通过自适应核选择来提高目标识别的效率和有效性。SKNets演示了各种基准测试的最先进性能,从大型模型到小型模型。此外,我们还发现了一些跨信道、深度和类别的内核选择行为,并实证验证了射频大小对SKNets的有效适应,这有助于更好地理解其机制。希望能对今后的建筑设计研究和探索有所启发。
Selective Kernel Networks的更多相关文章
- 论文阅读笔记六十一:Selective Kernel Networks(SKNet CVPR2019)
论文原址:https://arxiv.org/pdf/1903.06586.pdf github: https://github.com/implus/SKNet 摘要 在标准的卷积网络中,每层网络中 ...
- Selective Kernel Network
senet: https://arxiv.org/abs/1709.01507 sknet: http://arxiv.org/abs/1903.06586 TL, DR Selective Kern ...
- (转)Awsome Domain-Adaptation
Awsome Domain-Adaptation 2018-08-06 19:27:54 This blog is copied from: https://github.com/zhaoxin94/ ...
- TensorFlow Lite demo——就是为嵌入式设备而存在的,底层调用NDK神经网络API,注意其使用的tf model需要转换下,同时提供java和C++ API,无法使用tflite的见后
Introduction to TensorFlow Lite TensorFlow Lite is TensorFlow’s lightweight solution for mobile and ...
- 深度学习笔记(十一)网络 Inception, Xception, MobileNet, ShuffeNet, ResNeXt, SqueezeNet, EfficientNet, MixConv
1. Abstract 本文旨在简单介绍下各种轻量级网络,纳尼?!好吧,不限于轻量级 2. Introduction 2.1 Inception 在最初的版本 Inception/GoogleNet, ...
- Theories of Deep Learning
https://stats385.github.io/readings Lecture 1 – Deep Learning Challenge. Is There Theory? Readings D ...
- CVPR2018资源汇总
CVPR 2018大会将于2018年6月18~22日于美国犹他州的盐湖城(Salt Lake City)举办. CVPR2018论文集下载:http://openaccess.thecvf.com/m ...
- 论文阅读-(CVPR 2017) Kernel Pooling for Convolutional Neural Networks
在这篇论文中,作者提出了一种更加通用的池化框架,以核函数的形式捕捉特征之间的高阶信息.同时也证明了使用无参数化的紧致清晰特征映射,以指定阶形式逼近核函数,例如高斯核函数.本文提出的核函数池化可以和CN ...
- 目标检测--Spatial pyramid pooling in deep convolutional networks for visual recognition(PAMI, 2015)
Spatial pyramid pooling in deep convolutional networks for visual recognition 作者: Kaiming He, Xiangy ...
随机推荐
- PHP + JQuery 实现多图上传并预览
简述 PHP + JQuery实现 前台:将图片进行base64编码,使用ajax实现上传 后台:将base64进行解码,存储至文件夹,将文件名称入库 效果图 功能实现 html <!DOCTY ...
- vmware vpshere 安装完的必备工作
1:例如:vCenter计算机地址为:192.168.0.200, 访问地址:https://192.168.0.200,安装证书: 参考教程:https://blog.csdn.net/cooljs ...
- Java对象内存分布
[deerhang] 创建对象的四种方式:new关键字.反射.Object.clone().unsafe方法 new和反射是通过调用构造器创建对象的,创建对象的时候使用invokespecial指令 ...
- 最优运输(Optimal Transfort):从理论到填补的应用
目录 引言 1 背景 2 什么是最优运输? 3 基本概念 3.1 离散测度 (Discrete measures) 3.2 蒙日(Monge)问题 3.3 Kantorovich Relaxation ...
- java设计模式之单例模式你真的会了吗?(懒汉式篇)
java设计模式之单例模式你真的会了吗?(懒汉式篇) 一.什么是单例模式? 单例模式(Singleton Pattern)是 Java 中最简单的设计模式之一.这种类型的设计模式属于创建型模式,它提供 ...
- 图扑软件正式加入腾讯智维生态发展计划,智能 IDC 开启数字经济新征程
4 月 23 日,主题为<智汇科技,维新至善>的腾讯数据中心智维技术研讨会在深圳胜利召开,发布了腾讯智维 2.0 技术体系,深度揭秘了智维 2.0 新产品战略和技术规划.图扑软件(High ...
- pip;python包管理工具
刚开始学习Python时,在看文档和别人的blog介绍安装包有的用easy_install, setuptools, 有的使用pip,distribute,那麽这几个工具有什么关系呢,看一下下面这个图 ...
- mysql开启远程访问和oracl用户锁定问题
开启mysql远程访问 Grant all privileges on *.* to 'root'@'%' identified by 'root'; Flush privileges; oracl锁 ...
- STM32F1移植UCOSII
作者:珵旭媛 下载对应版本的UCOSII https://www.micrium.com/downloadcenter/,你会少修改很多东西: 下载下来后是这样的文件夹,并且Software里面的才是 ...
- 『动善时』JMeter基础 — 26、使用txt文件实现JMeter参数化
目录 1.测试计划中的元件 2.数据文件内容 3.线程组元件内容 4.HTTP信息头管理器组件内容 5.CSV数据文件设置组件内容 6.HTTP请求组件内容 7.脚本运行结果 之前我们都是使用.csv ...