HashSet、CopyOnWriteArraySet、ConcurrentSkipListSet源码解析(JDK1.8)
HashSet源码解析
HashSet简单使用的demo
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("中国");
set.add("你好");
set.add("中国");
System.out.println(set);
}
运行结果如下:
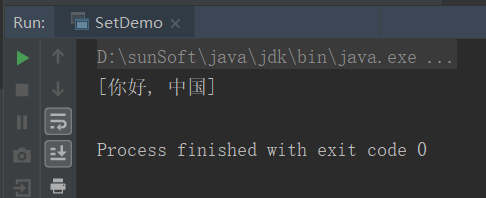
可以看到,两次add相同的值,最后只有一个添加成功了。
所以,set和list的主要区别就是不重复,而且set里面的元素是无序的,hashSet是线程不安全的
HashSet中的变量
//用来存放set进来的值
private transient HashMap<E,Object> map;
//PRESENT是每次add元素的时候,做为map的value值,
//这样的话,key是不一样的,可以保证不重复
//PRESENT做为value值,这样可以使得hashSet只用HashMap的key存储
private static final Object PRESENT = new Object();
hashSet底层是使用hashMap来存储元素的,hashMap是以键值对的方式存储,而set存储的是单个元素,所以PRESENT做为value值,是一个常量,这样可以保证set的存储是单个元素。
HashSet的构造函数
//构建一个空的hashSet,由于是基于hashMap实现的
//所以默认初始容量是16,负载因子是0.75
public HashSet() {
map = new HashMap<>();
}
/**
* 这个构造函数,是把一个集合放入HashSet中
* 默认初始容量是16,负载因子是0.75
* @param c 要放入HashSet的元素
* @throws NullPointerException 如果传入的集合是空的,就抛异常
*/
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
/**
* 构建一个指定初始容量和负载因子的HashSet
*
* @param initialCapacity 指定的初始容量
* @param loadFactor 指定的负载因子
* @throws IllegalArgumentException
* 如果传入的初始容量和负载因子的值不在正确的范围,就抛异常
*/
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
/**
* 构建一个指定初始容量的HashSet,负载因子是默认的0.75
*
* @param initialCapacity 指定的初始容量
* @throws IllegalArgumentException
* 如果传入的初始容量的值小于0,就抛异常
*/
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
/**
* 这个构造函数是构建一个LinkedHashMap
* 它只能够被LinkedHashSet使用
* @param initialCapacity 指定的初始容量
* @param loadFactor 指定的负载因子
* @param dummy 可以忽略这个参数,无具体意义
* @throws IllegalArgumentException
* 如果传入的初始容量和负载因子的值不在正确的范围,就抛异常
*/
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
HashSet的add方法
/**
* add方法,将一个元素添加到hashSet中
* 如果hashSet中没有这个元素,就添加成功
* 如果该元素在集合中已经存在了,就直接返回false
* 这里添加重复的元素不是去覆盖之前的元素,而是直接添加不成功
*
* @param e 将要添加到集合中的元素
* @return <tt>true</tt> 添加成功返回true
* element
*/
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
由于hashSet集合中的元素是无序的,所以不能像List一样通过get(int index)获取下标然后去获取元素的方式,所以hashSet没有get方法。
HashSet的iterator方法
/**
* 通过迭代器的方式返回该集合中的元素,元素的返回没有特定的顺序
*
* @return an Iterator over the elements in this set
* @see ConcurrentModificationException
*/
public Iterator<E> iterator() {
return map.keySet().iterator();
}
使用示例:
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("中国");
set.add("你好");
set.add("中国");
System.out.println(set);
Iterator<String> ite = set.iterator();
//判断下一个元素之后是否有值
while(ite.hasNext()){
System.out.println(ite.next());
}
}
返回结果:

可以看到,最后迭代出的元素,并没有按照一定的顺序返回,hashSet中的元素是无序的。
HashSet的size方法
size方法比较简单,就是直接返回HashSet集合中元素有多少个
/**
* 返回集合中元素的个数
*
* @return 元素的个数
*/
public int size() {
return map.size();
}
HashSet的isEmpty方法
isEmpty就是用来判断HashSet是否是个空的集合
/**
* 判断集合是否是空
* 如果该集合中没有元素,就返回true
* @return <tt>true</tt> if this set contains no elements
*/
public boolean isEmpty() {
return map.isEmpty();
}
HashSet的remove和clear方法
/**
* 移除集合中的元素,要是集合中有该元素,直接移除,返回true,不包含返回false
*
* @param o 需要移除的元素
* @return <tt>true</tt> if the set contained the specified element
*/
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
/**
* 移除集合中的所有元素
* The set will be empty after this call returns.
*/
public void clear() {
map.clear();
}
CopyOnWriteArraySet源码解析
CopyOnWriteArraySet是基于于CopyOnWriteArrayList实现的,CopyOnWriteArrayList的源码请看list那篇文章,CopyOnWriteArraySet是线程安全的。
CopyOnWriteArraySet的构造函数
//用来存储元素
private final CopyOnWriteArrayList<E> al;
/**
* 构建一个空的集合
*/
public CopyOnWriteArraySet() {
al = new CopyOnWriteArrayList<E>();
}
/**
* 构建一个包含指定集合所有元素的集合
* collection.
*
* @param c 传入的集合
* @throws NullPointerException 集合为空,就抛异常
*/
public CopyOnWriteArraySet(Collection<? extends E> c) {
if (c.getClass() == CopyOnWriteArraySet.class) {
@SuppressWarnings("unchecked") CopyOnWriteArraySet<E> cc =
(CopyOnWriteArraySet<E>)c;
al = new CopyOnWriteArrayList<E>(cc.al);
}
else {
al = new CopyOnWriteArrayList<E>();
al.addAllAbsent(c);
}
}
CopyOnWriteArraySet的add方法
/**
* 添加元素:
* 如果集合中没有该元素,添加到集合
* 如果集合中有该元素,离开
*
* @param e element to be added to this set
* @return {@code true} 添加成功就返回true
*/
public boolean add(E e) {
return al.addIfAbsent(e);
}
接下来看下CopyOnWriteArrayList中的addIfAbsent方法:
/**
* 如果要加入的元素不存在,就添加到数组中
*
* @param e 需要添加的元素
* @return {@code true} 如果元素已经在数组中了,返回true
*/
public boolean addIfAbsent(E e) {
//获取数组
Object[] snapshot = getArray();
//这一步,是判断元素是否在数组中已经存在了
//如果已经存在了就返回false
//如果不存在就调用addIfAbsent添加元素
return indexOf(e, snapshot, 0, snapshot.length) >= 0 ? false :
addIfAbsent(e, snapshot);
}
/**
* 如果元素不存在就添加到数组
* recent snapshot does not contain e.
*/
private boolean addIfAbsent(E e, Object[] snapshot) {
//加锁
final ReentrantLock lock = this.lock;
lock.lock();
try {
//获取当前的数组
Object[] current = getArray();
//获取当前数组的长度
int len = current.length;
//如果两次获取的数组不一致,说明数组被修改了
if (snapshot != current) {
//再次检查,刚刚获取到的元素是否被修改了
int common = Math.min(snapshot.length, len);
for (int i = 0; i < common; i++)
//这一步,是说明元素不在addIfAbsent这个方法里面获取的数组里
//而在当前的数组里面,说明当前获取的数组里面,已经存在该元素了,那么返回false
if (current[i] != snapshot[i] && eq(e, current[i]))
return false;
//判断元素是否在数组中已经存在了,若存在返回false
if (indexOf(e, current, common, len) >= 0)
return false;
}
//copy一个新的数组,比原先的数组长度多一位
Object[] newElements = Arrays.copyOf(current, len + 1);
//然后把元素添加到新数组的尾部
newElements[len] = e;
//设置数组的引用是加入元素之后的数组
setArray(newElements);
//添加成功,返回true
return true;
} finally {
//释放锁
lock.unlock();
}
}
private static int indexOf(Object o, Object[] elements,
int index, int fence) {
//如果要加入的元素是null
if (o == null) {
for (int i = index; i < fence; i++)
//通过遍历查找之前的数组中是否有null的元素,有就直接返回下标
if (elements[i] == null)
return i;
//如果要加入的元素不是null
} else {
for (int i = index; i < fence; i++)
//遍历查找元素是否在数组中已经存在,有就直接返回下标
if (o.equals(elements[i]))
return i;
}
return -1;
}
通过上面的addIfAbsent方法,可以保证集合中的元素不重复
CopyOnWriteArraySet的remove方法
/**
* 如果元素存在,就移除
* @param o 将要移除的元素
* @return {@code true} 移除成功后返回true
*/
public boolean remove(Object o) {
return al.remove(o);
}
接下来看下CopyOnWriteArrayList中的remove方法:
/**
* 移除列表中的第一个匹配的元素
* 如果存在直接移除,如果不存在返回false
*
* @param o 需要移除的元素
* @return {@code true}
*/
public boolean remove(Object o) {
//获取数组
Object[] snapshot = getArray();
//判断数组中是否有该元素
//如果没有返回false,如果存在该元素,调用移除方法
int index = indexOf(o, snapshot, 0, snapshot.length);
return (index < 0) ? false : remove(o, snapshot, index);
}
/**
* 移除列表中的元素
*/
private boolean remove(Object o, Object[] snapshot, int index) {
//加锁
final ReentrantLock lock = this.lock;
lock.lock();
try {
//再次获取下当前数组
Object[] current = getArray();
//获取当前数组的长度
int len = current.length;
//判断数组是否被修改了
if (snapshot != current) findIndex: {
//再次检查,刚刚获取到的元素是否被修改了
int prefix = Math.min(index, len);
for (int i = 0; i < prefix; i++) {
//这一步,是说明元素不在addIfAbsent这个方法里面获取的数组里,而在当前的数组里面
if (current[i] != snapshot[i] && eq(o, current[i])) {
index = i;
break findIndex;
}
}
//如果该元素的下标大于或者等于数组的长度,返回false
if (index >= len)
return false;
//如果当前数组中有该元素,直接退出
if (current[index] == o)
break findIndex;
//判断元素是否在current里面
index = indexOf(o, current, index, len);
//不在就返回false
if (index < 0)
return false;
}
//创建一个比当前数组少一位的数组
Object[] newElements = new Object[len - 1];
//然后通过arraycopy的方式
//先把移除元素之前的元素copy出来
//然后把移除元素之后的元素左移
System.arraycopy(current, 0, newElements, 0, index);
System.arraycopy(current, index + 1,
newElements, index,
len - index - 1);
//设置当前数组的引用是移除之后的数组
setArray(newElements);
return true;
} finally {
//释放锁
lock.unlock();
}
}
CopyOnWriteArraySet的其他方法基本上实现都是和上述差不多的方式,就不一一赘述了。
ConcurrentSkipListSet源码解析
ConcurrentSkipListSet是基于ConcurrentSkipListMap实现的,线程安全,查询快,接下来直接说下ConcurrentSkipListMap的实现思想。
ConcurrentSkipListMap跳表,是使用链表和索引实现的:

上述图片画了个简单的跳表,可能不够准确,大致的思路也差不多是这样的。
HashSet、CopyOnWriteArraySet、ConcurrentSkipListSet源码解析(JDK1.8)的更多相关文章
- Java 集合系列16之 HashSet详细介绍(源码解析)和使用示例
概要 这一章,我们对HashSet进行学习.我们先对HashSet有个整体认识,然后再学习它的源码,最后再通过实例来学会使用HashSet.内容包括:第1部分 HashSet介绍第2部分 HashSe ...
- 【转】Java 集合系列16之 HashSet详细介绍(源码解析)和使用示例--不错
原文网址:http://www.cnblogs.com/skywang12345/p/3311252.html 概要 这一章,我们对HashSet进行学习.我们先对HashSet有个整体认识,然后再学 ...
- 源码解析JDK1.8-HashMap链表成环的问题解决方案
前言 上篇文章详解介绍了HashMap在JDK1.7版本中链表成环的原因,今天介绍下JDK1.8针对HashMap线程安全问题的解决方案. jdk1.8 扩容源码解析 public class Has ...
- ArrayList、CopyOnWriteArrayList源码解析(JDK1.8)
本篇文章主要是学习后的知识记录,存在不足,或许不够深入,还请谅解. 目录 ArrayList源码解析 ArrayList中的变量 ArrayList构造函数 ArrayList中的add方法 Arra ...
- Java集合-ArrayList源码解析-JDK1.8
◆ ArrayList简介 ◆ ArrayList 是一个数组队列,相当于 动态数组.与Java中的数组相比,它的容量能动态增长.它继承于AbstractList,实现了List, RandomAcc ...
- Map集合类(一.hashMap源码解析jdk1.8)
java集合笔记一 java集合笔记二 java集合笔记三 jdk 8 之前,其内部是由数组+链表来实现的,而 jdk 8 对于链表长度超过 8 的链表将转储为红黑树 1.属性 //节点数组,第一次使 ...
- java集合 源码解析 学习手册
学习路线: http://www.cnblogs.com/skywang12345/ 总结 1 总体框架 2 Collection架构 3 ArrayList详细介绍(源码解析)和使用示例 4 fai ...
- 给jdk写注释系列之jdk1.6容器(6)-HashSet源码解析&Map迭代器
今天的主角是HashSet,Set是什么东东,当然也是一种java容器了. 现在再看到Hash心底里有没有会心一笑呢,这里不再赘述hash的概念原理等一大堆东西了(不懂得需要先回去看下Has ...
- 给jdk写注释系列之jdk1.6容器(8)-TreeSet&NavigableMap&NavigableSet源码解析
TreeSet是一个有序的Set集合. 既然是有序,那么它是靠什么来维持顺序的呢,回忆一下TreeMap中是怎么比较两个key大小的,是通过一个比较器Comparator对不对,不过遗憾的是,今天仍然 ...
随机推荐
- redux-devtools-extend
如果不打算用redux-thunk import { createStore, compose} from 'redux'; import reducer from './reducer' const ...
- spring-ioc注解-理解2 零配置文件
没有xml配置文件下的对象注入,使用到一个Teacher类,Config配置类,Test测试类. 1.Teacher类 import lombok.Data; import org.springfra ...
- CentOS7安装Mysql并配置远程访问
(su root登录到root账户) 下载repo源 wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm 安装rpm ...
- vue项目配置 `webpack-obfuscator` 进行代码加密混淆
背景 公司代码提供给第三方使用,为了不完全泄露源码,需要对给出的代码进行加密混淆,前端代码虽然无法做到完全加密混淆,但是通过使用 webpack-obfuscator 通过增加随机废代码段.字符编码转 ...
- vue子组件的样式没有加scoped属性会影响父组件的样式
scoped是一个vue的指令,用来控制组件的样式生效区域,加上scoped,样式只在当前组件内生效,不加scoped,这个节点下的样式会全局生效. 需要注意的是:一个组件的样式肯定是用来美化自己组件 ...
- JVisualVM监控JVM-外网服务器
环境说明: a:阿里云服务器Centos8.2 b:JDK1.8 1:增加JMV运行参数 java -jar 启动时添加一下参数: -Djava.rmi.server.hostname=外网IP地址 ...
- CentOS7安装ZooKeeper3.4.14
1:下载安装包 wget https://downloads.apache.org/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz 点击进入官网下 ...
- Go的结构体
目录 结构体 一.什么是结构体? 二.结构体的声明 三.创建结构体 1.创建有名结构体 2.结构体初始化 2.1 按位置传参 2.2 按关键字传 3.创建匿名结构体 四.结构体的类型 五.结构体的默认 ...
- wxWidgets源码分析(1) - App启动过程
目录 APP启动过程 wxApp入口定义 wxApp实例化准备 wxApp的实例化 wxApp运行 总结 APP启动过程 本文主要介绍wxWidgets应用程序的启动过程,从app.cpp入手. wx ...
- Java数据持久层
一.前言 1.持久层 Java数据持久层,其本身是为了实现与数据源进行数据交互的存在,其目的是通过分层架构风格,进行应用&数据的解耦. 我从整体角度,依次阐述JDBC.Mybatis.Myba ...