Hive(十一)【压缩、存储】
一.Hadoop的压缩配置
1.MR支持的压缩编码
| 压缩格式 | 算法 | 文件扩展名 | 是否可切分 |
|---|---|---|---|
| DEFLATE | DEFLATE | .deflate | 否 |
| Gzip | DEFLATE | .gz | 否 |
| bzip2 | bzip2 | .bz2 | 是 |
| LZO | LZO | .lzo | 是 |
| Snappy | Snappy | .snappy | 否 |
为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器,如下表所示:
| 压缩格式 | 对应的编码/解码器 |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
压缩性能的比较:
| 压缩算法 | 原始文件大小 | 压缩文件大小 | 压缩速度 | 解压速度 |
|---|---|---|---|---|
| gzip | 8.3GB | 1.8GB | 17.5MB/s | 58MB/s |
| bzip2 | 8.3GB | 1.1GB | 2.4MB/s | 9.5MB/s |
| LZO | 8.3GB | 2.9GB | 49.3MB/s | 74.6MB/s |
On a single core of a Core i7 processor in 64-bit mode, Snappy compresses at about 250 MB/sec or more and decompresses at about 500 MB/sec or more.
2.压缩参数配置
要在Hadoop中启用压缩,可以配置如下参数(mapred-site.xml文件中):
| 参数 | 默认值 | 阶段 | 建议 |
|---|---|---|---|
| io.compression.codecs (在core-site.xml中配置) | org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.BZip2Codec, org.apache.hadoop.io.compress.Lz4Codec | 输入压缩 | Hadoop使用文件扩展名判断是否支持某种编解码器 |
| mapreduce.map.output.compress | false | mapper输出 | 这个参数设为true启用压缩 |
| mapreduce.map.output.compress.codec | org.apache.hadoop.io.compress.DefaultCodec | mapper输出 | 使用LZO、LZ4或snappy编解码器在此阶段压缩数据 |
| mapreduce.output.fileoutputformat.compress | false | reducer输出 | 这个参数设为true启用压缩 |
| mapreduce.output.fileoutputformat.compress.codec | org.apache.hadoop.io.compress. DefaultCodec | reducer输出 | 使用标准工具或者编解码器,如gzip和bzip2 |
| mapreduce.output.fileoutputformat.compress.type | RECORD | reducer输出 | SequenceFile输出使用的压缩类型:NONE和BLOCK |
3.开启Mapper输出阶段压缩
启map输出阶段压缩可以减少job中map和Reduce task间数据传输量
案例实操
(1)开启hive中间传输数据压缩功能
hive (default)>set hive.exec.compress.intermediate=true;
(2)开启mapreduce中map输出压缩功能
hive (default)>set mapreduce.map.output.compress=true;
(3)设置mapreduce中map输出数据的压缩方式
hive (default)>set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
(4)执行查询语句
hive (default)> select count(ename) name from emp;
4.开启Reduceer输出阶段
当Hive将输出写入到表中时,输出内容同样可以进行压缩。属性hive.exec.compress.output控制着这个功能。用户可能需要保持默认设置文件中的默认值false,这样默认的输出就是非压缩的纯文本文件了。用户可以通过在查询语句或执行脚本中设置这个值为true,来开启输出结果压缩功能。
案例实操
(1)开启hive最终输出数据压缩功能
hive (default)>set hive.exec.compress.output=true;
(2)开启mapreduce最终输出数据压缩
hive (default)>set mapreduce.output.fileoutputformat.compress=true;
(3)设置mapreduce最终数据输出压缩方式
hive (default)> set mapreduce.output.fileoutputformat.compress.codec =org.apache.hadoop.io.compress.SnappyCodec;
(4)设置mapreduce最终数据输出压缩为块压缩
hive (default)> set mapreduce.output.fileoutputformat.compress.type=BLOCK;
(5)测试一下输出结果是否是压缩文件
hive (default)> insert overwrite local directory '/opt/module/hive/datas/compress/' select * from emp distribute by deptno sort by empno desc;
二.文件存储
Hive支持的存储数据的格式主要有:TEXTFILE 、SEQUENCEFILE、ORC、PARQUET。
1.列式存储和行式存储
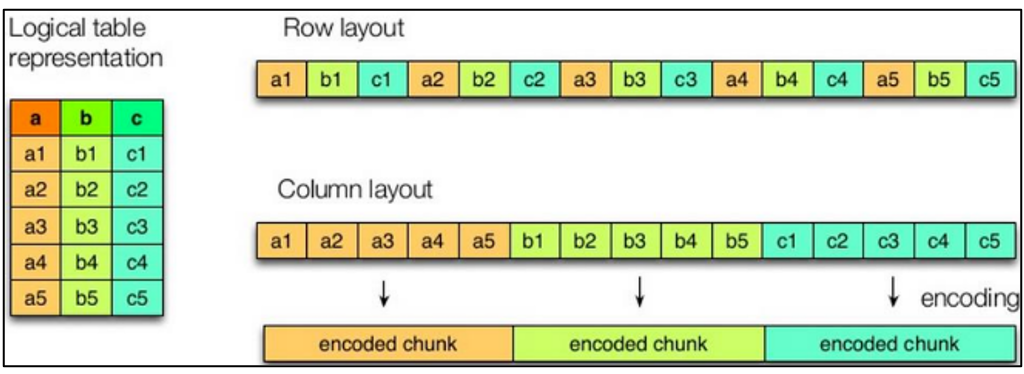
如图所示左边为逻辑表,右边第一个为行式存储,第二个为列式存储。
行存储的特点
查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
列存储的特点
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
行式存储:TEXTFILE,SEQUENCEFILE
列式存储:ORC,PARQUET
2.TextFile,Orc,Parquet比较
TextFile
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用,但使用Gzip这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
Orc
Orc (Optimized Row Columnar)是Hive 0.11版里引入的新的存储格式。
如下图所示可以看到每个Orc文件由1个或多个stripe组成,每个stripe一般为HDFS的块大小,每一个stripe包含多条记录,这些记录按照列进行独立存储,对应到Parquet中的row group的概念。每个
Stripe里有三部分组成,分别是Index Data,Row Data,Stripe Footer:
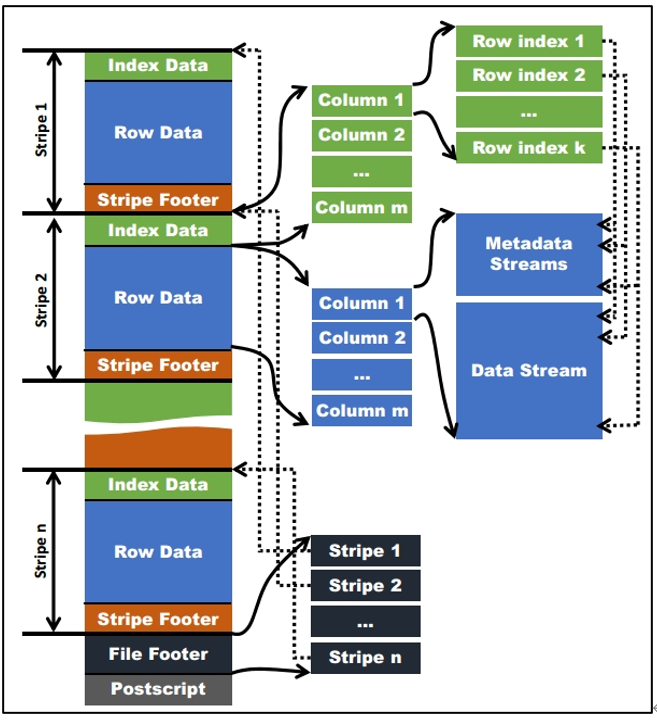
1)Index Data:一个轻量级的index,默认是每隔1W行做一个索引。这里做的索引应该只是记录某行的各字段在Row Data中的offset。
2)Row Data:存的是具体的数据,先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成多个Stream来存储。
3)Stripe Footer:存的是各个Stream的类型,长度等信息。
每个文件有一个File Footer,这里面存的是每个Stripe的行数,每个Column的数据类型信息等;每个文件的尾部是一个PostScript,这里面记录了整个文件的压缩类型以及FileFooter的长度信息等。在读取文件时,会seek到文件尾部读PostScript,从里面解析到File Footer长度,再读FileFooter,从里面解析到各个Stripe信息,再读各个Stripe,即从后往前读
Parquet
Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
(1)行组(Row Group):每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,类似于orc的stripe的概念。
(2)列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。一个列块中的值都是相同类型的,不同的列块可能使用不同的算法进行压缩。
(3)页(Page):每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。
通常情况下,在存储Parquet数据的时候会按照Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。Parquet文件的格式。

上图展示了一个Parquet文件的内容,一个文件中可以存储多个行组,文件的首位都是该文件的Magic Code,用于校验它是否是一个Parquet文件,Footer length记录了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量,文件的元数据中包括每一个行组的元数据信息和该文件存储数据的Schema信息。除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据,在Parquet中,有三种类型的页:数据页、字典页和索引页。数据页用于存储当前行组中该列的值,字典页存储该列值的编码字典,每一个列块中最多包含一个字典页,索引页用来存储当前行组下该列的索引,目前Parquet中还不支持索引页。
3.应用总结
在实际的项目开发当中,hive表的数据的压缩存储选择
存储格式选择:orc或parquet。(MR对orc支持较好,spark对parquet支持较好,存储选择决定于hive的执行引擎)
压缩方式选择:snappy,lzo。
Hive(十一)【压缩、存储】的更多相关文章
- Hive的压缩存储和简单优化
一.Hive的压缩和存储 1,MapReduce支持的压缩编码 压缩格式 工具 算法 文件扩展名 是否可切分 对应的编码/解码器 DEFLATE 无 DEFLATE .deflate 否 org.ap ...
- Hive(八)Hive的Shell操作与压缩存储
一.Hive的命令行 1.Hive支持的一些命令 Command Description quit Use quit or exit to leave the interactive shell. s ...
- 一文彻底搞懂Hive的数据存储与压缩
目录 行存储与列存储 行存储的特点 列存储的特点 常见的数据格式 TextFile SequenceFile RCfile ORCfile 格式 数据访问 Parquet 测试 准备测试数据 存储空间 ...
- 配置Hive 支持 JSON 存储
1.说明 hive默认使用分隔符如空格,分号,"|",制表符\t来格式化数据记录,对于复杂数据类型如json,nginx日志等,就没有办法拆分了,这时候需要更加强大的SerDe来处 ...
- Hive 表操作(HIVE的数据存储、数据库、表、分区、分桶)
1.Hive的数据存储 Hive的数据存储基于Hadoop HDFS Hive没有专门的数据存储格式 存储结构主要包括:数据库.文件.表.试图 Hive默认可以直接加载文本文件(TextFile),还 ...
- 三元组表压缩存储稀疏矩阵实现稀疏矩阵的快速转置(Java语言描述)
三元组表压缩存储稀疏矩阵实现稀疏矩阵的快速转置(Java语言描述) 用经典矩阵转置算法和普通的三元组矩阵转置在时间复杂度上都是不乐观的.快速转置算法在增加适当存储空间后实现快速转置具体原理见代码注释部 ...
- hadoop笔记之Hive的数据存储(视图)
Hive的数据存储(视图) Hive的数据存储(视图) 视图(view) 视图是一种虚表,是一个逻辑概念:可以跨越多张表 既然视图是一种虚表,那么也就是说用操作表的方式也可以操作视图 但是视图是建立在 ...
- hadoop笔记之Hive的数据存储(桶表)
Hive的数据存储(桶表) Hive的数据存储(桶表) 桶表 桶表是对数据进行哈希取值,然后放到不同文件中存储. 比如说,创建三个桶,而创建桶的原则可以按照左边表中学生的名字来创建对应的桶.这样子把左 ...
- hadoop笔记之Hive的数据存储(外部表)
Hive的数据存储(外部表) Hive的数据存储(外部表) 外部表 指向已经在HDFS中存在的数据,可以创建Partition 它和内部表在元数据的组织上是相同的,而实际数据的存储则有较大的差异 外部 ...
随机推荐
- 用STM32定时器中断产生PWM控制步进电机
控制步进电机可以使用PWM.定时器中断.延时,这里用的就是定时器中断来让它转动. 一.硬件部分1.使用的硬件板子用的是正点原子的STM32F103 mini板,驱动器是DM420(DM420驱动器资料 ...
- Web实时通信,SignalR真香,不用愁了
前言 对于B/S模式的项目,基础的场景都是客户端发起请求,服务端返回响应结果就结束了一次连接:但在很多实际应用场景中,这种简单的请求和响应模式就显得很吃力,比如消息通知.监控看板信息自动刷新等实时通信 ...
- ELK集群之elasticsearch(3)
Elasticsearch-基础介绍及索引原理分析 介绍 Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引 ...
- Jmeter分布式 (三)
一.什么是分布式测试 分布式测试是指通过局域网和Internet,把分布于不同地点.独立完成特定功能的测试计算机连接起来,以达到测试资源共享.分散操作.集中管理.协同工作.负载均衡.测试过程监控等目的 ...
- JMeter学习笔记--并发登录测试
账号密码读取文件 1.设置线程数为30,并发用户量就是30个用户同时登录 2.添加同步定时器 添加 Synchronizing Timer 同步定时器,为了阻塞线程,当线程数达到指定数量,再同时释放, ...
- Linux usb 1. 总线简介
文章目录 1. USB 发展历史 1.1 USB 1.0/2.0 1.2 USB 3.0 1.3 速度识别 1.4 OTG 1.5 phy 总线 1.6 传输编码方式 2. 总线拓扑 2.1 Devi ...
- es聚合查询语法
{ "size": 0, "query": { "bool": { "filter ...
- PCB各层介绍
在PCB设计中用得比较多的图层: mechanical 机械层 keepout layer 禁止布线层 Signal layer 信号层 Internal plane layer 内部电源/接地层 t ...
- 快速排序平均时间复杂度O(nlogn)的推导
快速排序作为随机算法的一种,不能通过常规方法来计算时间复杂度 wiki上有三种快排平均时间复杂度的分析,本文记录了一种推导方法. 先放快速排序的伪代码,便于回顾.参考 quicksort(int L, ...
- 问题 K: 找点
题目描述 上数学课时,老师给了LYH一些闭区间,让他取尽量少的点,使得每个闭区间内至少有一个点.但是这几天LYH太忙了,你们帮帮他吗? 输入 多组测试数据. 每组数据先输入一个N,表示有N个闭区间(N ...