MapReduce(一) mapreduce基础入门
一、mapreduce入门
1、什么是mapreduce
首先让我们来重温一下 hadoop 的四大组件:
HDFS:分布式存储系统
MapReduce:分布式计算系统
YARN: hadoop 的资源调度系统
Common: 以上三大组件的底层支撑组件,主要提供基础工具包和 RPC 框架等
Mapreduce 是一个分布式运算程序的编程框架,是用户开发“基于 hadoop 的数据分析 应用”的核心框架
Mapreduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的 分布式运算程序,并发运行在一个 hadoop 集群上
2、为什么需要mapreduce
为什么需要 MapReduce?
(1) 海量数据在单机上处理因为硬件资源限制,无法胜任
(2) 而一旦将单机版程序扩展到集群来分布式运行,将极大增加程序的复杂度和开发难度
(3) 引入 MapReduce 框架后,开发人员可以将绝大部分工作集中在业务逻辑的开发上,而将 分布式计算中的复杂性交由框架来处理

可见在程序由单机版扩成分布式版时,会引入大量的复杂工作。为了提高开发效率,可以将 分布式程序中的公共功能封装成框架,让开发人员可以将精力集中于业务逻辑。
Hadoop 当中的 MapReduce 就是这样的一个分布式程序运算框架,它把大量分布式程序都会
涉及的到的内容都封装进了,让用户只用专注自己的业务逻辑代码的开发。 它对应以上问题
的整体结构如下:

3、mapreduce程序运行实例
在 MapReduce 组件里, 官方给我们提供了一些样例程序,其中非常有名的就是 wordcount 和 pi 程序。这些 MapReduce 程序的代码都在 hadoop-mapreduce-examples-2.6.4.jar 包里, 这 个 jar 包在 hadoop 安装目录下的/share/hadoop/mapreduce/目录里
下面我们使用 hadoop 命令来试跑例子程序,看看运行效果
先看 MapReduce 程序求 pi 的程序:


那除了这两个程序以外,还有没有官方提供的其他程序呢,还有就是它们的源码在哪里呢?
我们打开 mapreduce 的源码工程,里面有一个 hadoop-mapreduce-project 项目:
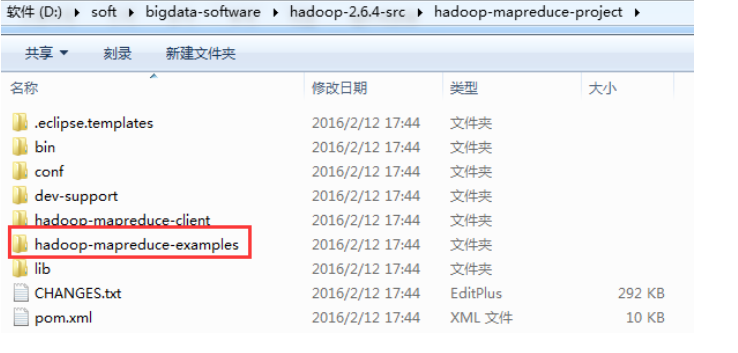
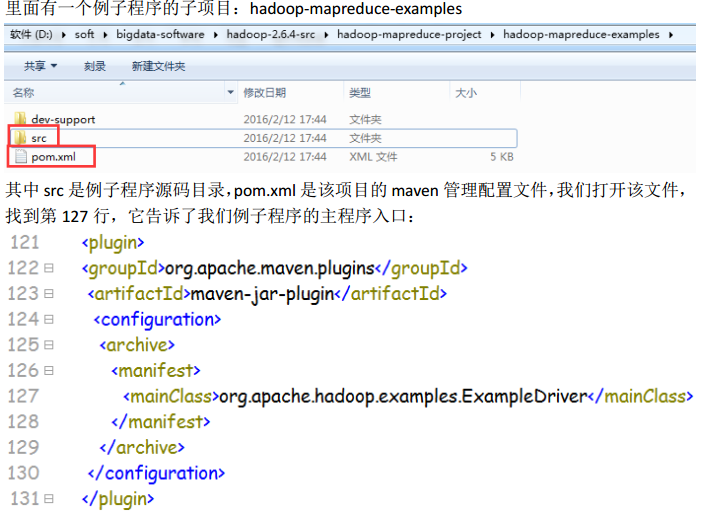
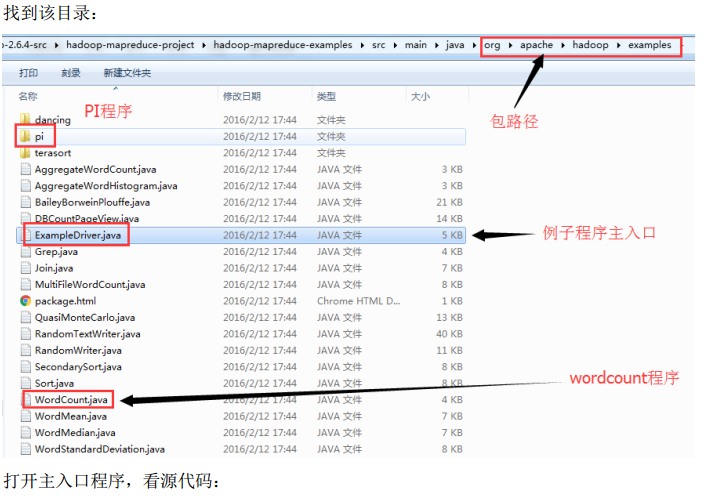

4、mapreduce示例编写及编码规范
上一步,我们查看了 WordCount 这个 MapReduce 程序的源码编写,可以得出几点结论:
(1) 该程序有一个 main 方法,来启动任务的运行,其中 job 对象就存储了该程序运行的必要 信息,比如指定 Mapper 类和 Reducer 类
job.setMapperClass(TokenizerMapper.class);
job.setReducerClass(IntSumReducer.class);
(2) 该程序中的 TokenizerMapper 类继承了 Mapper 类
(3) 该程序中的 IntSumReducer 类继承了 Reducer 类
总结: MapReduce 程序的业务编码分为两个大部分,一部分配置程序的运行信息,一部分 编写该 MapReduce 程序的业务逻辑,并且业务逻辑的 map 阶段和 reduce 阶段的代码分别继 承 Mapper 类和 Reducer 类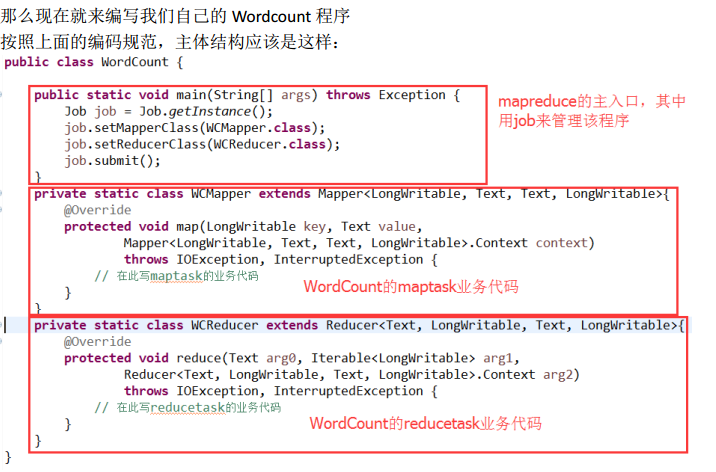
(1) 用户编写的程序分成三个部分: Mapper, Reducer, Driver(提交运行 MR 程序的客户端)
(2) Mapper 的输入数据是 KV 对的形式( KV 的类型可自定义)
(3) Mapper 的输出数据是 KV 对的形式( KV 的类型可自定义)
(4) Mapper 中的业务逻辑写在 map()方法中
(5) map()方法( maptask 进程)对每一个<K,V>调用一次
(6) Reducer 的输入数据类型对应 Mapper 的输出数据类型,也是 KV
(7) Reducer 的业务逻辑写在 reduce()方法中
(8) Reducetask 进程对每一组相同 k 的<k,v>组调用一次 reduce()方法
(9) 用户自定义的 Mapper 和 Reducer 都要继承各自的父类
(10) 整个程序需要一个 Drvier 来进行提交,提交的是一个描述了各种必要信息的 job 对象
WordCount 的业务逻辑:
1、 maptask 阶段处理每个数据分块的单词统计分析,思路是每遇到一个单词则把其转换成 一个 key-value 对,比如单词 hello,就转换成<’hello’,1>发送给 reducetask 去汇总
2、 reducetask 阶段将接受 maptask 的结果, 来做汇总计数

其次reduce



5、mapreduce运行方式与debug
运行方式:


二、mapreduce的核心程序运行机制
1、概述
一个完整的 mapreduce 程序在分布式运行时有两类实例进程:
(1) MRAppMaster:负责整个程序的过程调度及状态协调 (该进程在yarn节点上)
(2) Yarnchild:负责 map 阶段的整个数据处理流程
(3) Yarnchild:负责 reduce 阶段的整个数据处理流程
以上两个阶段 maptask 和 reducetask 的进程都是 yarnchild,并不是说这 maptask 和 reducetask 就跑在同一个 yarnchild 进行里
(Yarnchild进程在运行该命令的节点上)
2、mapreduce程序的运行流程(经典面试题)
(1) 一个 mr 程序启动的时候,最先启动的是 MRAppMaster, MRAppMaster 启动后根据本次 job 的描述信息,计算出需要的 maptask 实例数量,然后向集群申请机器启动相应数量的 maptask 进程
(2) maptask 进程启动之后,根据给定的数据切片(哪个文件的哪个偏移量范围)范围进行数 据处理,主体流程为:
A、 利用客户指定的 inputformat 来获取 RecordReader 读取数据,形成输入 KV 对
B、 将输入 KV 对传递给客户定义的 map()方法,做逻辑运算,并将 map()方法输出的 KV 对收 集到缓存
C、 将缓存中的 KV 对按照 K 分区排序后不断溢写到磁盘文件 (超过缓存内存写到磁盘临时文件,最后都写到该文件,ruduce 获取该文件后,删除 )
(3) MRAppMaster 监控到所有 maptask 进程任务完成之后(真实情况是,某些 maptask 进 程处理完成后,就会开始启动 reducetask 去已完成的 maptask 处 fetch 数据),会根据客户指 定的参数启动相应数量的 reducetask 进程,并告知 reducetask 进程要处理的数据范围(数据
分区)
(4) Reducetask 进程启动之后,根据 MRAppMaster 告知的待处理数据所在位置,从若干台 maptask 运行所在机器上获取到若干个 maptask 输出结果文件,并在本地进行重新归并排序, 然后按照相同 key 的 KV 为一个组,调用客户定义的 reduce()方法进行逻辑运算,并收集运
算输出的结果 KV,然后调用客户指定的 outputformat 将结果数据输出到外部存储
3、maptask并行度决定机制
maptask 的并行度决定 map 阶段的任务处理并发度,进而影响到整个 job 的处理速度 那么, mapTask 并行实例是否越多越好呢?其并行度又是如何决定呢?
一个 job 的 map 阶段并行度由客户端在提交 job 时决定, 客户端对 map 阶段并行度的规划
的基本逻辑为:
将待处理数据执行逻辑切片(即按照一个特定切片大小,将待处理数据划分成逻辑上的多 个 split),然后每一个 split 分配一个 mapTask 并行实例处理
这段逻辑及形成的切片规划描述文件,是由 FileInputFormat实现类的 getSplits()方法完成的。
该方法返回的是 List<InputSplit>, InputSplit 封装了每一个逻辑切片的信息,包括长度和位置 信息,而 getSplits()方法返回一组 InputSplit
4、切片机制

5、maptask并行度经验之谈
如果硬件配置为 2*12core + 64G,恰当的 map 并行度是大约每个节点 20-100 个 map,最好 每个 map 的执行时间至少一分钟。
(1)如果 job 的每个 map 或者 reduce task 的运行时间都只有 30-40 秒钟,那么就减少该 job 的 map 或者 reduce 数,每一个 task(map|reduce)的 setup 和加入到调度器中进行调度,这个 中间的过程可能都要花费几秒钟,所以如果每个 task 都非常快就跑完了,就会在 task 的开
始和结束的时候浪费太多的时间。
配置 task 的 JVM 重用可以改善该问题:
mapred.job.reuse.jvm.num.tasks,默认是 1,表示一个 JVM 上最多可以顺序执行的 task 数目(属于同一个 Job)是 1。也就是说一个 task 启一个 JVM。这个值可以在 mapred-site.xml 中进行更改, 当设置成多个,就意味着这多个 task 运行在同一个 JVM 上,但不是同时执行,
是排队顺序执行
(2)如果 input 的文件非常的大,比如 1TB,可以考虑将 hdfs 上的每个 blocksize 设大,比如 设成 256MB 或者 512MB
6、reducetask并行度决定机制

补充:
package com.ghgj.mr.wordcount; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCountMR { /**
* 该main方法是该mapreduce程序运行的入口,其中用一个Job类对象来管理程序运行时所需要的很多参数:
* 比如,指定用哪个组件作为数据读取器、数据结果输出器
* 指定用哪个类作为map阶段的业务逻辑类,哪个类作为reduce阶段的业务逻辑类
* 指定wordcount job程序的jar包所在路径
* ....
* 以及其他各种需要的参数
*/
public static void main(String[] args) throws Exception {
// 指定hdfs相关的参数
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://hadoop02:9000");
System.setProperty("HADOOP_USER_NAME", "hadoop"); // conf.set("mapreduce.framework.name", "yarn");
// conf.set("yarn.resourcemanager.hostname", "hadoop04"); Job job = Job.getInstance(conf); // 设置jar包所在路径
job.setJarByClass(WordCountMR.class); // 指定mapper类和reducer类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class); // 指定maptask的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); // 指定reducetask的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); // Path inputPath = new Path("d:/wordcount/input");
// Path outputPath = new Path("d:/wordcount/output"); // 指定该mapreduce程序数据的输入和输出路径
Path inputPath = new Path("/wordcount/input");
Path outputPath = new Path("/wordcount/output");
FileSystem fs = FileSystem.get(conf);
if(fs.exists(outputPath)){
fs.delete(outputPath, true);
}
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath); // job.submit();
// 最后提交任务
boolean waitForCompletion = job.waitForCompletion(true);
System.exit(waitForCompletion?0:1);
} /**
* Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
*
* KEYIN 是指框架读取到的数据的key的类型,在默认的InputFormat下,读到的key是一行文本的起始偏移量,所以key的类型是Long
* VALUEIN 是指框架读取到的数据的value的类型,在默认的InputFormat下,读到的value是一行文本的内容,所以value的类型是String
* KEYOUT 是指用户自定义逻辑方法返回的数据中key的类型,由用户业务逻辑决定,在此wordcount程序中,我们输出的key是单词,所以是String
* VALUEOUT 是指用户自定义逻辑方法返回的数据中value的类型,由用户业务逻辑决定,在此wordcount程序中,我们输出的value是单词的数量,所以是Integer
*
* 但是,String ,Long等jdk中自带的数据类型,在序列化时,效率比较低,hadoop为了提高序列化效率,自定义了一套序列化框架
* 所以,在hadoop的程序中,如果该数据需要进行序列化(写磁盘,或者网络传输),就一定要用实现了hadoop序列化框架的数据类型
*
* Long ----> LongWritable
* String ----> Text
* Integer ----> IntWritable
* Null ----> NullWritable
*/
static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException { String[] words = value.toString().split(" ");
for(String word: words){
context.write(new Text(word), new IntWritable(1));
}
}
} /**
* 首先,和前面一样,Reducer类也有输入和输出,输入就是Map阶段的处理结果,输出就是Reduce最后的输出
* reducetask在调我们写的reduce方法,reducetask应该收到了前一阶段(map阶段)中所有maptask输出的数据中的一部分
* (数据的key.hashcode%reducetask数==本reductask号),所以reducetaks的输入类型必须和maptask的输出类型一样
*
* reducetask将这些收到kv数据拿来处理时,是这样调用我们的reduce方法的:
* 先将自己收到的所有的kv对按照k分组(根据k是否相同)
* 将某一组kv中的第一个kv中的k传给reduce方法的key变量,把这一组kv中所有的v用一个迭代器传给reduce方法的变量values
*/
static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException { int sum = 0;
for(IntWritable v: values){
sum += v.get();
}
context.write(key, new IntWritable(sum));
}
}
}
MapReduce(一) mapreduce基础入门的更多相关文章
- js学习笔记:webpack基础入门(一)
之前听说过webpack,今天想正式的接触一下,先跟着webpack的官方用户指南走: 在这里有: 如何安装webpack 如何使用webpack 如何使用loader 如何使用webpack的开发者 ...
- 「译」JUnit 5 系列:基础入门
原文地址:http://blog.codefx.org/libraries/junit-5-basics/ 原文日期:25, Feb, 2016 译文首发:Linesh 的博客:JUnit 5 系列: ...
- .NET正则表达式基础入门
这是我第一次写的博客,个人觉得十分不容易.以前看别人写的博客文字十分流畅,到自己来写却发现十分困难,还是感谢那些为技术而奉献自己力量的人吧. 本教程编写之前,博主阅读了<正则指引>这本入门 ...
- 从零3D基础入门XNA 4.0(2)——模型和BasicEffect
[题外话] 上一篇文章介绍了3D开发基础与XNA开发程序的整体结构,以及使用Model类的Draw方法将模型绘制到屏幕上.本文接着上一篇文章继续,介绍XNA中模型的结构.BasicEffect的使用以 ...
- 从零3D基础入门XNA 4.0(1)——3D开发基础
[题外话] 最近要做一个3D动画演示的程序,由于比较熟悉C#语言,再加上XNA对模型的支持比较好,故选择了XNA平台.不过从网上找到很多XNA的入门文章,发现大都需要一些3D基础,而我之前并没有接触过 ...
- Shell编程菜鸟基础入门笔记
Shell编程基础入门 1.shell格式:例 shell脚本开发习惯 1.指定解释器 #!/bin/bash 2.脚本开头加版权等信息如:#DATE:时间,#author(作者)#mail: ...
- [Spring框架]Spring AOP基础入门总结二:Spring基于AspectJ的AOP的开发.
前言: 在上一篇中: [Spring框架]Spring AOP基础入门总结一. 中 我们已经知道了一个Spring AOP程序是如何开发的, 在这里呢我们将基于AspectJ来进行AOP 的总结和学习 ...
- [Spring框架]Spring AOP基础入门总结一.
前言:前面已经有两篇文章讲了Spring IOC/DI 以及 使用xml和注解两种方法开发的案例, 下面就来梳理一下Spring的另一核心AOP. 一, 什么是AOP 在软件业,AOP为Aspect ...
- RobotFramework - 基础入门
Robot Framework Wiki HomePage Robot Framework User Guide Robot Framework documentation Robot Framewo ...
- .NET ORM 的 “SOD蜜”--零基础入门篇
PDF.NET SOD框架不仅仅是一个ORM,但是它的ORM功能是独具特色的,我在博客中已经多次介绍,但都是原理性的,可能不少初学的朋友还是觉得复杂,其实,SOD的ORM是很简单的.下面我们就采用流行 ...
随机推荐
- 基础SQL语句学习
(注:sql对大小写不敏感,附:命令行操作:cd 目录名 可进入文件,cd .. 可返回上级木目录) 下载MySQL,并配置环境变量: 使用命令行操作数据库(也可下载navicat操作),输入mysq ...
- [原创软件]PC端与移动端文件信息互通工具
一个不小心,花了几个小时,就做出来了一个专利,这不科学啊... 软件主要功能: 跨平台(已适配Mac.Windows)远程连接手机端和PC端 远程执行shell命令 远程和本地文件实现互通传输共享 显 ...
- mysql数据导到本地
需求: 把mysql查询结果导出到txt(其他格式亦可),放在本地,供下一步使用 首先网上查了下,select * from driver into outfile 'a.txt'; 前面是你的sql ...
- ovs源码阅读--流表查询原理
背景 在ovs交换机中,报文的处理流程可以划分为一下三个步骤:协议解析,表项查找和动作执行,其中最耗时的步骤在于表项查找,往往一个流表中有数目巨大的表项,如何根据数据报文的信息快速的查找到对应的流表项 ...
- 实现属于自己的TensorFlow(二) - 梯度计算与反向传播
前言 上一篇中介绍了计算图以及前向传播的实现,本文中将主要介绍对于模型优化非常重要的反向传播算法以及反向传播算法中梯度计算的实现.因为在计算梯度的时候需要涉及到矩阵梯度的计算,本文针对几种常用操作的梯 ...
- ES6的新特性(6)——正则的扩展
正则的扩展 RegExp 构造函数 在 ES5 中,RegExp构造函数的参数有两种情况. 第一种情况是,参数是字符串,这时第二个参数表示正则表达式的修饰符(flag). var regex = ne ...
- python实现中文验证码识别方法(亲测通过)
验证码截图如下: # coding:utf-8from PIL import Image,ImageEnhanceimport pytesseract#上面都是导包,只需要下面这一行就能实现图片文字识 ...
- 王者荣耀交流协会第二次Scrum立会
会议时间:2017年10月21号 17:00-17:22,时长22分钟. 会议地点:首尔名家里面的大桌子(PS:感谢组长大大请我们吃饭~)立会内容:每位同学汇报了今日工作(高远博与王超同学在今日有 ...
- 周总结<7>
这周和3位朋友一起完成了系运动会的视频,感受很多,也学到很多. 周次 学习时间 新编代码行数 博客量 学到知识点 14 20 100 1 Html页面设计:虚拟机:(C语言)最小生成树与最短路径 Ht ...
- Linux下查看apache连接数
1.查看apache当前并发访问数: netstat -an | grep ESTABLISHED | wc -l 对比httpd.conf中MaxClients的数字差距多少. 2.查看有多少个进程 ...