Mac Hadoop2.6(CDH5.9.2)伪分布式集群安装
操作系统: MAC OS X
一、准备
1、 JDK 1.8
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
2、Hadoop CDH
下载地址:https://archive.cloudera.com/cdh5/cdh/5/
本次安装版本:hadoop-2.6.0-cdh5.9.2.tar.gz
二、配置SSH(免密码登录)
1、打开iTerm2 终端,输入:ssh-keygen -t rsa ,回车,next -- 生成秘钥
2、cat id_rsa_xxx.pub >> authorized_keys -- 用于授权你的公钥到本地可以无密码登录
3、chmod 600 authorized_keys -- 赋权限
4、ssh localhost -- 免密码登录,如果显示最后一次登录时间,则登录成功
三、配置Hadoop&环境变量
1、创建hadoop目录&解压
mkdir -p work/install/hadoop-cdh5.9.2 -- hadoop 主目录
mkdir -p work/install/hadoop-cdh5.9.2/current/tmp work/install/hadoop-cdh5.9.2/current/nmnode work/install/hadoop-cdh5.9.2/current/dtnode -- hadoop 临时、名称节点、数据节点目录
tar -xvf hadoop-2.6.0-cdh5.9.2.tar.gz -- 解压包
2、配置 .bash_profile 环境变量
HADOOP_HOME="/Users/kimbo/work/install/hadoop-cdh5.9.2/hadoop-2.6.0-cdh5.9.2" JAVA_HOME="/Library/Java/JavaVirtualMachines/jdk1.8.0_152.jdk/Contents/Home"
HADOOP_HOME="/Users/kimbo/work/install/hadoop-cdh5.9.2/hadoop-2.6.0-cdh5.9.2" PATH="/usr/local/bin:~/cmd:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH"
CLASSPATH=".:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar" export JAVA_HOME PATH CLASSPATH HADOOP_HOME
source .bash_profile -- 生效环境变量
3、修改配置文件(重点)
cd $HADOOP_HOME/etc/hadoop
- core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/Users/zhangshaosheng/work/install/hadoop-cdh5.9.2/current/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:8020</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>4320</value>
<description> 3 days = 60min*24h*3day </description>
</property>
</configuration>
- hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/Users/zhangshaosheng/work/install/hadoop-cdh5.9.2/current/nmnode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/Users/zhangshaosheng/work/install/hadoop-cdh5.9.2/current/dtnode</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>localhost:50075</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
- yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>Whether to enable log aggregation</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/Users/zhangshaosheng/work/install/hadoop-cdh5.9.2/current/tmp/yarn-logs</value>
<description>Where to aggregate logs to.</description>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>8192</value>
<description>Amount of physical memory, in MB, that can be allocated
for containers.</description>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
<description>Number of CPU cores that can be allocated
for containers.</description>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
<description>The minimum allocation for every container request at the RM,
in MBs. Memory requests lower than this won't take effect,
and the specified value will get allocated at minimum.</description>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
<description>The maximum allocation for every container request at the RM,
in MBs. Memory requests higher than this won't take effect,
and will get capped to this value.</description>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
<description>The minimum allocation for every container request at the RM,
in terms of virtual CPU cores. Requests lower than this won't take effect,
and the specified value will get allocated the minimum.</description>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>2</value>
<description>The maximum allocation for every container request at the RM,
in terms of virtual CPU cores. Requests higher than this won't take effect,
and will get capped to this value.</description>
</property>
</configuration>
- mapred-site.xml
<property>
<name>mapreduce.jobtracker.address</name>
<value>localhost:8021</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/Users/zhangshaosheng/work/install/hadoop-cdh5.9.2/current/tmp/job-history/</value>
<description></description>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>The runtime framework for executing MapReduce jobs.
Can be one of local, classic or yarn.
</description>
</property> <property>
<name>mapreduce.map.cpu.vcores</name>
<value>1</value>
<description>
The number of virtual cores required for each map task.
</description>
</property>
<property>
<name>mapreduce.reduce.cpu.vcores</name>
<value>1</value>
<description>
The number of virtual cores required for each reduce task.
</description>
</property> <property>
<name>mapreduce.map.memory.mb</name>
<value>1024</value>
<description>Larger resource limit for maps.</description>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>1024</value>
<description>Larger resource limit for reduces.</description>
</property>
<configuration>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx768m</value>
<description>Heap-size for child jvms of maps.</description>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx768m</value>
<description>Heap-size for child jvms of reduces.</description>
</property> <property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>1024</value>
<description>The amount of memory the MR AppMaster needs.</description>
</property>
</configuration>
- hadoop-env.sh
export JAVA_HOME=${JAVA_HOME} -- 添加 java环境变量
四、启动
1、格式化
hdfs namenode -format
如果hdfs命令识别不了, 检查环境变量,是否配置正确了。
2、启动
cd $HADOOP_HOME/sbin
执行命名:start-all.sh ,按照提示,输入密码
五、验证
1、在终端输入: jps
出现如下截图,说明ok了

2、登录web页面
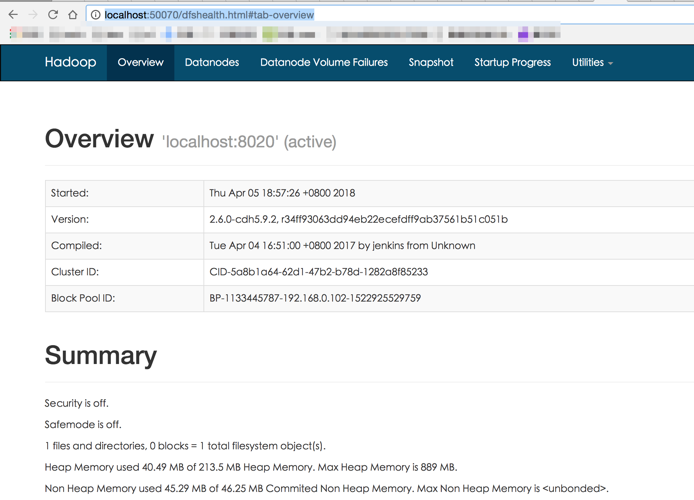
a)HDFS : http://localhost:50070/dfshealth.html#tab-overview
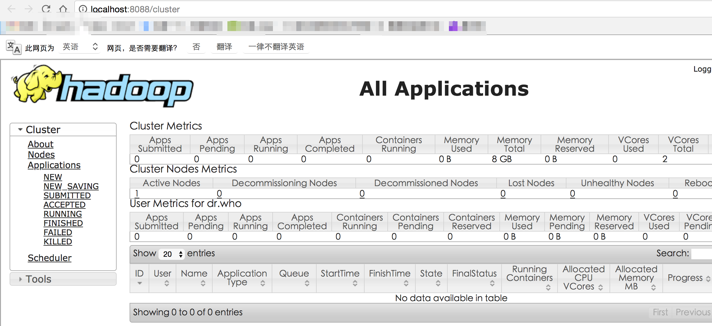
b)YARN Cluster: http://localhost:8088/cluster
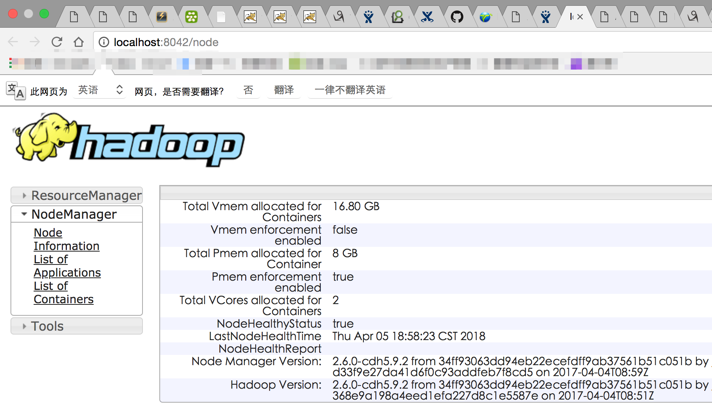
c)YARN ResourceManager/NodeManager: http://localhost:8042/node
Mac Hadoop2.6(CDH5.9.2)伪分布式集群安装的更多相关文章
- (转)ZooKeeper伪分布式集群安装及使用
转自:http://blog.fens.me/hadoop-zookeeper-intro/ 前言 ZooKeeper是Hadoop家族的一款高性能的分布式协作的产品.在单机中,系统协作大都是进程级的 ...
- ZooKeeper伪分布式集群安装及使用
ZooKeeper伪分布式集群安装及使用 让Hadoop跑在云端系列文章,介绍了如何整合虚拟化和Hadoop,让Hadoop集群跑在VPS虚拟主机上,通过云向用户提供存储和计算的服务. 现在硬件越来越 ...
- Hadoop学习---CentOS中hadoop伪分布式集群安装
注意:此次搭建是在ssh无密码配置.jdk环境已经配置好的情况下进行的 可以参考: Hadoop完全分布式安装教程 CentOS环境下搭建hadoop伪分布式集群 1.更改主机名 执行命令:vi / ...
- Linux单机环境下HDFS伪分布式集群安装操作步骤v1.0
公司平台的分布式文件系统基于Hadoop HDFS技术构建,为开发人员学习及后续项目中Hadoop HDFS相关操作提供技术参考特编写此文档.本文档描述了Linux单机环境下Hadoop HDFS伪分 ...
- kafka2.9.2的伪分布式集群安装和demo(java api)测试
目录: 一.什么是kafka? 二.kafka的官方网站在哪里? 三.在哪里下载?需要哪些组件的支持? 四.如何安装? 五.FAQ 六.扩展阅读 一.什么是kafka? kafka是LinkedI ...
- ubuntu12.04+kafka2.9.2+zookeeper3.4.5的伪分布式集群安装和demo(java api)测试
博文作者:迦壹 博客地址:http://idoall.org/home.php?mod=space&uid=1&do=blog&id=547 转载声明:可以转载, 但必须以超链 ...
- 大数据学习之hadoop伪分布式集群安装(一)公众号undefined110
hadoop的基本概念: Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力进行高速运算和存储. Hadoo ...
- zookeeper伪分布式集群安装
1.安装3个zookeeper 1.1创建集群安装的目录 1.2配置一个完整的服务 这里不做详细说明,参考我之前写的 zookeeper单节点安装 进行配置即可,此处直接复制之前单节点到集群目录 创建 ...
- kafka系列一:单节点伪分布式集群搭建
Kafka集群搭建分为单节点的伪分布式集群和多节点的分布式集群两种,首先来看一下单节点伪分布式集群安装.单节点伪分布式集群是指集群由一台ZooKeeper服务器和一台Kafka broker服务器组成 ...
随机推荐
- MVC之路由
1.路由规则理解: 在MVC项目中,路由是一个独立的模块,需要引入System.Web.Routing ,路由的作用就是确定控制器和行为,同时确定其他的参数,然后将这些信息传递个相应的控制器和行为. ...
- vue报错 vue-cli 引入 stylus 失败
1.1.1. vue-cli 引入 stylus 失败 先通过vue-cli的webpack模板建立文件夹: vue init webpack test-stylus 然后安装依赖 npm ins ...
- SQL---->mySQl数据库1------表内容的增删改查
增: insert into user(id,username,birthday,entry_date,job,salary,resume) values(1,'aaaa','1995-12-10', ...
- SQL---->mySQl安装for mac
我安装是参考如下两篇博客,但是有些不同,这里写好参考来源: http://blog.csdn.net/li_huifeng/article/details/9449685 http://www.jia ...
- as modern frameworks have warmed people to the idea of using builder-type patterns and anonymous inner classes for such things
mybatis – MyBatis 3 | SQL语句构建器 http://www.mybatis.org/mybatis-3/zh/statement-builders.html SqlBuilde ...
- talib 中文文档(九):# Volatility Indicator Functions 波动率指标函数
Volatility Indicator Functions 波动率指标函数 ATR - Average True Range 函数名:ATR 名称:真实波动幅度均值 简介:真实波动幅度均值(ATR) ...
- 12.GIT多人协作
当你从远程仓库克隆时,实际上Git自动把本地的master分支和远程的master分支对应起来了,并且,远程仓库的默认名称是origin. 查看远程库的信息 $ git remote origin $ ...
- mysql 数据操作 单表查询 where约束 between and or
WHERE约束 where字句中可以使用: 比较运算符:>< >= <= != between 80 and 100 值在80到100之间 >=80 <= ...
- STL学习笔记--序列式容器
1.vector vector是一个线性顺序结构.相当于数组,但其大小可以不预先指定,并且自动扩展.故可以将vector看作动态数组. 在创建一个vector后,它会自动在内存中分配一块连续的内存空间 ...
- 远程终端登录软件MobaXterm
提到SSH.Telnet等远程终端登录,我相信很多人想到的都是PuTTY[注A]. PuTTY足够成熟.小巧.专注核心任务,并且对编码等常见坑的处理并不缺乏,这其实都是优点.但PuTTY在额外功能上就 ...