Spark Shuffle(一)ShuffleWrite:Executor如何将Shuffle的结果进行归并写到数据文件中去(转载)
转载自:https://blog.csdn.net/raintungli/article/details/70807376
当Executor进行reduce运算的时候,生成运算结果的临时Shuffle数据,并保存在磁盘中,被最后的Action算子调用,而这个阶段就是在ShuffleMapTask里执行的。
前面博客中也提到了,用什么ShuffleWrite是由ShuffleHandler来决定的,在这篇博客里主要介绍最常见的SortShuffleWrite的核心算法ExternalSorter.
2. 结构AppendOnlyMap
在前面博客中介绍了SortShuffleWriter调用ExternalSorter.insertAll进行数据插入和数据合并的,ExternalSorted里使用了PartitionedAppendOnlyMap作为数据的存储方式
先来看PartitionedAppendOnlyMap的结构
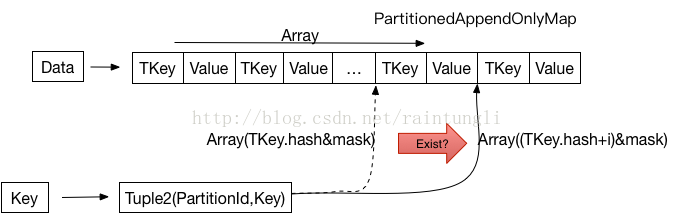
虽然名字为Map,但是在这里和常见的Map的结构并不太一样,里面并没有使用链表结果保存相同的hash值的key,当插入的key的hashcode相同的时但key不相同,会通过i的叠加一直找到数组里空闲的位置。
这里有几个注意点:
- Key 注意这里的Key并不是通过Map里拆分的Key, 而是Tuple2(PartitionId,Key),由分片的段和key组合的联合key
- 如何计算PartitionId? 这是由Partitioner来决定的
2.1 Partitioner
Partitioner的方法
abstract class Partitioner extends Serializable {
def numPartitions: Int
def getPartition(key: Any): Int
}
通过调用getPartition方法找到对应的partition相应的块,而常用的是HashPartitioner
def getPartition(key: Any): Int = key match {
case null =>
case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)
}
计算 key的hashCode,进行总的分片数求余,分配到对应的片区
3. Spill
在大数据的情况下进行归并,由于合并的数据量非常大,仅仅使用AppendOnlyMap进行数据的归并内存显然是不足够的,在这种情况下需要将内存里的已经归并的数据刷到磁盘上避免OOM的风险。
控制Spill到磁盘的阀值
- 内存:虽然Java的堆内存管理是由JVM虚拟机管控,但是Spark自己实现了一个简单的但不精准的内存管理,内存的申请在TaskMemoryManager里进行管理
if (elementsRead % == && currentMemory >= myMemoryThreshold) {
// Claim up to double our current memory from the shuffle memory pool
val amountToRequest = * currentMemory - myMemoryThreshold
val granted = acquireMemory(amountToRequest)
myMemoryThreshold += granted
// If we were granted too little memory to grow further (either tryToAcquire returned 0,
// or we already had more memory than myMemoryThreshold), spill the current collection
shouldSpill = currentMemory >= myMemoryThreshold
}
在每添加32个元素的时候,检查一下当前的内存状况,currentMemory是Map当前大概使用的内存,myMemoryThreshold是可以使用的内存址,初始的时候受参数控制:
spark.shuffle.spill.initialMemoryThreshold
- 数据的数量:有的时候每条数据量比较小,但是数据的数量非常大,为了避免在AppendOnlyMap里有大量的数据,在Spill的时候同时还可以使用数量的控制:
spark.shuffle.spill.numElementsForceSpillThreshold
3.1 如何Spill?
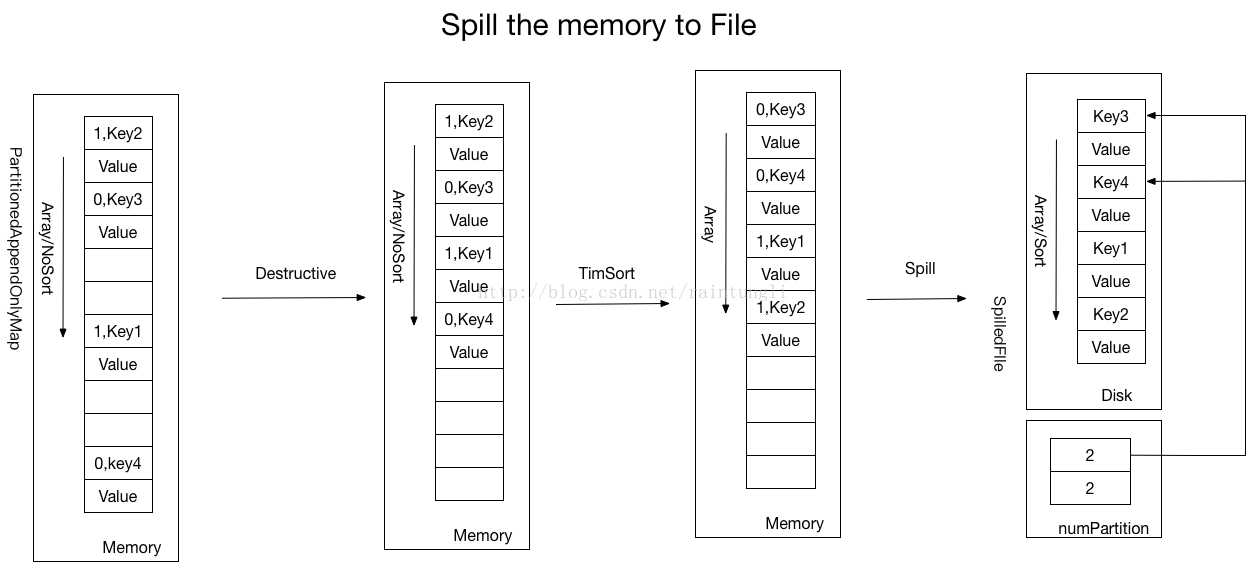
- 整理数组,将数组里的不存在KV的空间移除
- 按照区块排序,对同一区块里的Key使用TimeSort进行排序,TimeSort不在此处讨论
- Spill到文件的时候,只是保存了序列化了Key,Value并没有保存Key的区块信息,但在SpilledFile的对象中有记录每个partitionkey的数量的数组
4. 生成ShuffleWrite的数据文件
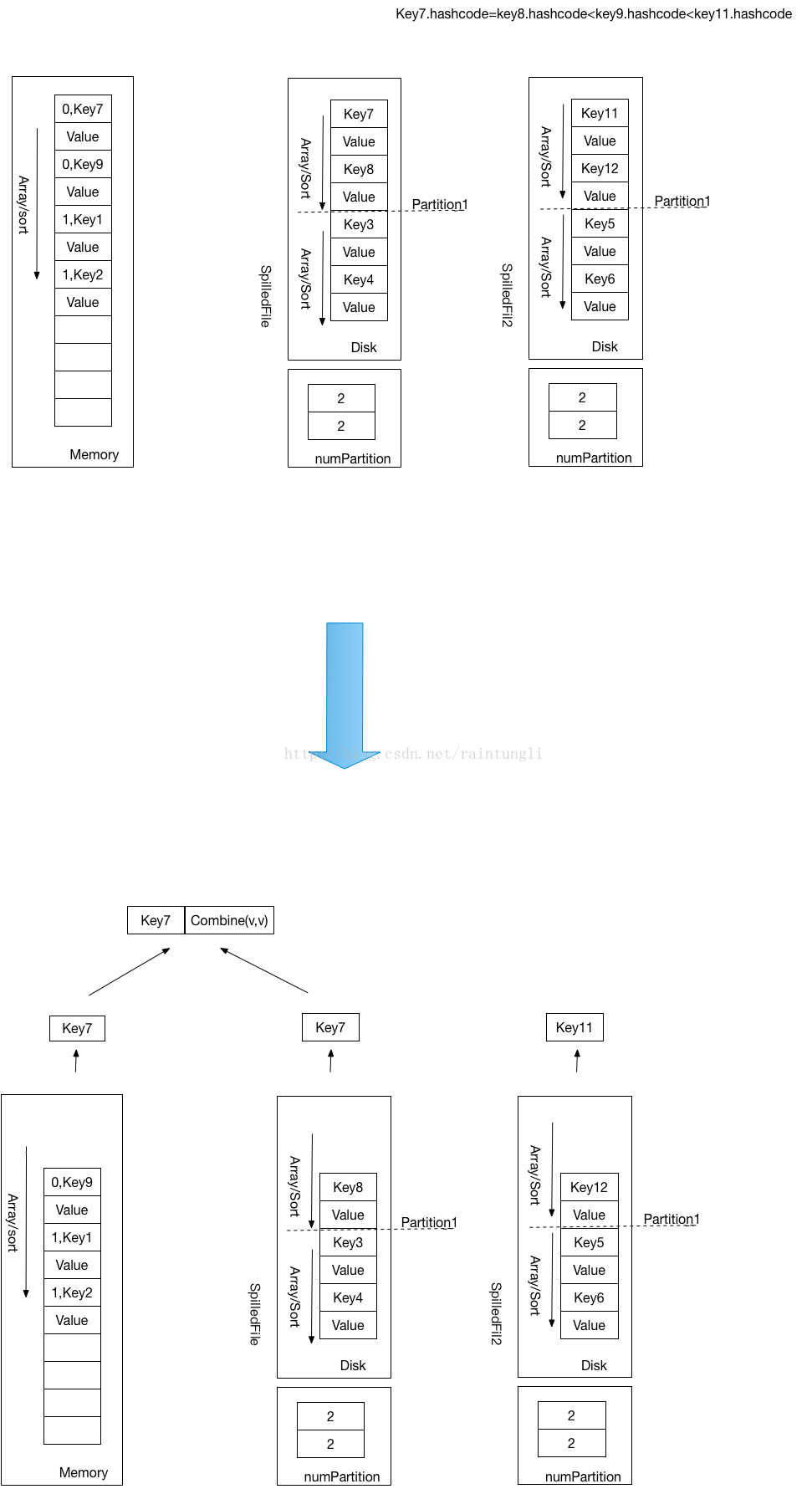
- 首先对AppendOnlyMap进行归并,排序
- 开始对同一区块的进行归并
- 将AppendOnlyMap,SpilledFile的文件进行优先级的Queue的迭代,每次迭代出所有Queue中一个最小的Key,最小的Key就是HashCode最小
private def mergeSort(iterators: Seq[Iterator[Product2[K, C]]], comparator: Comparator[K])
: Iterator[Product2[K, C]] =
{
val bufferedIters = iterators.filter(_.hasNext).map(_.buffered)
type Iter = BufferedIterator[Product2[K, C]]
val heap = new mutable.PriorityQueue[Iter]()(new Ordering[Iter] {
// Use the reverse of comparator.compare because PriorityQueue dequeues the max
override def compare(x: Iter, y: Iter): Int = -comparator.compare(x.head._1, y.head._1)
})
heap.enqueue(bufferedIters: _*) // Will contain only the iterators with hasNext = true
new Iterator[Product2[K, C]] {
override def hasNext: Boolean = !heap.isEmpty override def next(): Product2[K, C] = {
if (!hasNext) {
throw new NoSuchElementException
}
val firstBuf = heap.dequeue()
val firstPair = firstBuf.next()
if (firstBuf.hasNext) {
heap.enqueue(firstBuf)
}
firstPair
}
}
}
- 当找到一个最小的Key的时候,并不能保存到ShuffleWrite文件中,因为有可能存在相同的最小的key,所以还需要在迭代找到下一个最小的Key,如果key的hashcode相同的时候,要进行相同的Key进行合并(因为Key的排序是依赖于HashCode的大小,所以相同的最小的Key代表的是HashCode相同的Key),如果不同则保存成相同HashCode的数组,进行下一次的优先queue的查找,直到找到的Key的hashcode大于最小的Key结束
if (!hasNext) {
throw new NoSuchElementException
}
keys.clear()
combiners.clear()
val firstPair = sorted.next()
keys += firstPair._1
combiners += firstPair._2
val key = firstPair._1
while (sorted.hasNext && comparator.compare(sorted.head._1, key) == ) {
val pair = sorted.next()
var i =
var foundKey = false
while (i < keys.size && !foundKey) {
if (keys(i) == pair._1) {
combiners(i) = mergeCombiners(combiners(i), pair._2)
foundKey = true
}
i +=
}
if (!foundKey) {
keys += pair._1
combiners += pair._2
}
}
- 将k,v内容写到shufflewrite的文件Shuffle_shuffleId_mapId_reduceId.data中去
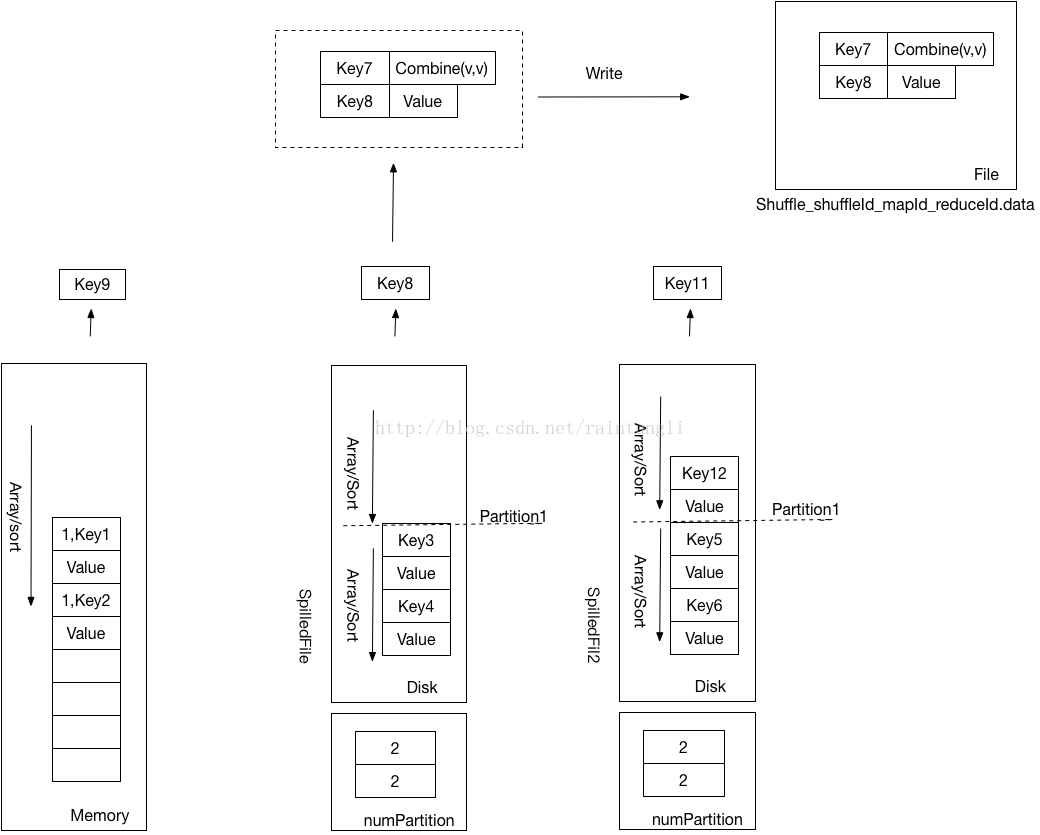
- 重复前面的行为直到所有的key被迭代结束
- 前面的归并是以区块(Partition)为单位的,而data的文件里并没有保存区块的相关信息,但在每迭代完一个Partition的时候(SpilledFile文件里面也没有Partition的信息,但是是通过SpilledFile结构中的numPartition的数量来判断Partition的数据是否已经读完),会生成一个Segement,Segement 里记录了这个块保存在data文件里的长度
- 最后生成Shuffle_shuffleId_mapId_reduceId.index文件,文件里记录了每个Partition在data文件中的位移
这样一个完整的Shuffle结果写入data的逻辑执行完了
5 总结
- 使用AppendOnlyMap数据结构进行输入数据的合并计算
- 输入的数据是进行分区合并计算,分区的方式是由Partitioner决定的
- 当内存不够的时候,会进行相同区块下的数据整理排序,Spill到临时文件temp_shuffle_UUID
- 最后对所有的数据集合(AppendOnlyMap里的数据和多个Spill的临时文件)进行区块的数据合并
- 生成Shuffle_shuffleId_mapId_reduceId.data 分区的数据文件,Shuffle_shuffleId_mapId_reduceId.index记录分区的位置
Spark Shuffle(一)ShuffleWrite:Executor如何将Shuffle的结果进行归并写到数据文件中去(转载)的更多相关文章
- Spark Shuffle(三)Executor是如何fetch shuffle的数据文件(转载)
1. 前言 在前面的博客中讨论了Executor, Driver之间如何汇报Executor生成的Shuffle的数据文件,以及Executor获取到Shuffle的数据文件的分布,那么Executo ...
- Spark源码系列(六)Shuffle的过程解析
Spark大会上,所有的演讲嘉宾都认为shuffle是最影响性能的地方,但是又无可奈何.之前去百度面试hadoop的时候,也被问到了这个问题,直接回答了不知道. 这篇文章主要是沿着下面几个问题来开展: ...
- Spark 源码系列(六)Shuffle 的过程解析
Spark 大会上,所有的演讲嘉宾都认为 shuffle 是最影响性能的地方,但是又无可奈何.之前去百度面试 hadoop 的时候,也被问到了这个问题,直接回答了不知道. 这篇文章主要是沿着下面几个问 ...
- Apache Spark源码走读之24 -- Sort-based Shuffle的设计与实现
欢迎转载,转载请注明出处. 概要 Spark 1.1中对spark core的一个重大改进就是引入了sort-based shuffle处理机制,本文就该处理机制的实现进行初步的分析. Sort-ba ...
- Spark原始码系列(六)Shuffle的过程解析
问题导读: 1.shuffle过程的划分? 2.shuffle的中间结果如何存储? 3.shuffle的数据如何拉取过来? Shuffle过程的划分 Spark的操作模型是基于RDD的,当调用RD ...
- spark动态资源(executor)分配
spark动态资源调整其实也就是说的executor数目支持动态增减,动态增减是根据spark应用的实际负载情况来决定. 开启动态资源调整需要(on yarn情况下) 1.将spark.dynamic ...
- spark异常篇-Removing executor 5 with no recent heartbeats: 120504 ms exceeds timeout 120000 ms 可能的解决方案
问题描述与分析 题目中的问题大致可以描述为: 由于某个 Executor 没有按时向 Driver 发送心跳,而被 Driver 判断该 Executor 已挂掉,此时 Driver 要把 该 Exe ...
- spark SQL读取ORC文件从Driver启动到开始执行Task(或stage)间隔时间太长(计算Partition时间太长)且产出orc单个文件中stripe个数太多问题解决方案
1.背景: 控制上游文件个数每天7000个,每个文件大小小于256M,50亿条+,orc格式.查看每个文件的stripe个数,500个左右,查询命令:hdfs fsck viewfs://hadoop ...
- Spark性能调优篇八之shuffle调优
1 task的内存缓冲调节参数 2 reduce端聚合内存占比 spark.shuffle.file.buffer map task的内存缓冲调节参数,默认是3 ...
随机推荐
- ChemDraw Std 14如何标记同位素
ChemDraw软件是一款专业高效的化学绘图工具,能够绘制各种复杂的结构方程式,在基础化学.有机化学.材料化学等领域得到广泛应用.而ChemDraw Std 14 作为ChemDraw 的最新版本,增 ...
- nginx配置语法
http://baijiahao.baidu.com/s?id=1604485941272024493&wfr=spider&for=pc http://blog.csdn.net/h ...
- tiny6410移植opencv
1.错误1, 解决办法:取消一下两个选项: 2.错误2, 解决办法: 原因是找不到pthread链接库,打开文件夹下的CmakeCache.txt进行修改 3.错误3, 解决办法:
- SQLServer------存储过程的使用
转载: http://www.cnblogs.com/hoojo/archive/2011/07/19/2110862.html 例子: 1.学生表 CREATE TABLE [dbo].[Stude ...
- docker search 详解
docker search 用于从 Docker Hub(https://hub.docker.com)中搜索指定的镜像,用法如下: [root@localhost ~]$ docker search ...
- U3D关于message的使用
Message相关有3条指令: SendMessage ("函数名",参数,SendMessageOptions) //GameObject自身的Script BroadcastM ...
- Python做简单爬虫(urllib.request怎么抓取https以及伪装浏览器访问的方法)
一:抓取简单的页面: 用Python来做爬虫抓取网站这个功能很强大,今天试着抓取了一下百度的首页,很成功,来看一下步骤吧 首先需要准备工具: 1.python:自己比较喜欢用新的东西,所以用的是Pyt ...
- JavaIO再回顾
File类 JavaIO访问文件名和文件检测相关操作 分隔符最好是使用File类提供的File.separator,使程序更加的健壮. File类提供的方法基本上是见名知意,例如getName()就是 ...
- 手机QQ会员H5加速方案——sonic技术内幕
版权声明:本文由况鹰原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/141 来源:腾云阁 https://www.qclou ...
- chrome单步调试代码
单步调试代码 所有步骤选项均通过边栏中的可点击图标 表示,但也可以通过快捷键触发(鼠标悬停在操作图标上就可以看到快捷键).下面是简要介绍: 图标/按钮 操作 描述 Resume 继续执行直到下一个断点 ...