深度学习(十六) ReLU为什么比Sigmoid效果好
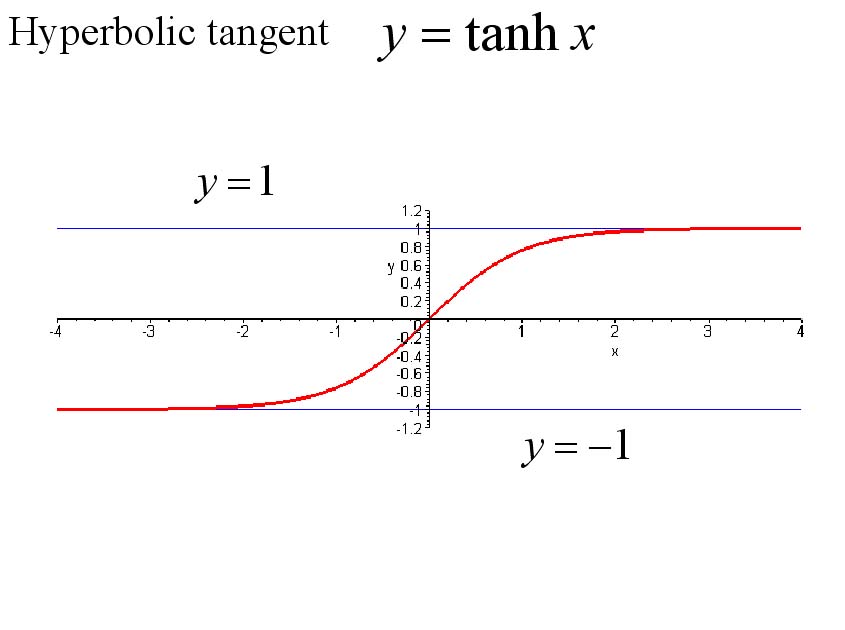
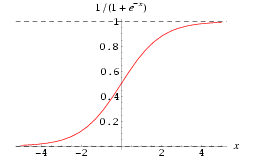
sigmoid:
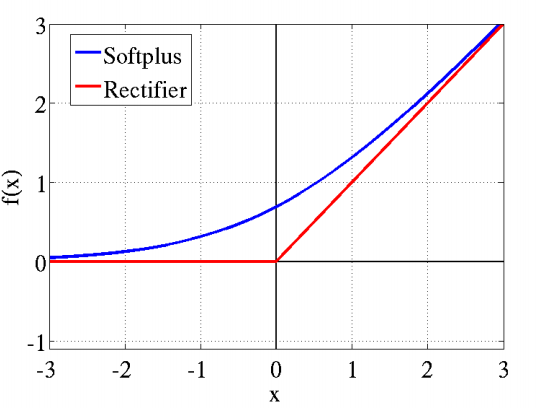
Relu:
为什么通常Relu比sigmoid和tanh强,有什么不同?
主要是因为它们gradient特性不同。
1.sigmoid和tanh的gradient在饱和区域非常平缓,接近于0,很容易造成vanishing gradient的问题,减缓收敛速度。vanishing gradient在网络层数多的时候尤其明显,是加深网络结构的主要障碍之一。相反,Relu的gradient大多数情况下是常数,有助于解决深层网络的收敛问题。
2.Relu的另一个优势是在生物上的合理性,它是单边的,相比sigmoid和tanh,更符合生物神经元的特征。
3.而提出sigmoid和tanh,主要是因为它们全程可导。还有表达区间问题,sigmoid和tanh区间是0到1,或着-1到1,在表达上,尤其是输出层的表达上有优势。
4.Relu输出更具稀疏性。
5.ReLU更容易学习优化。因为其分段线性性质,导致其前传,后传,求导都是分段线性。而传统的sigmoid函数,由于两端饱和,在传播过程中容易丢弃信息:
第一个问题:为什么引入非线性激励函数?
如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层输出都是上层输入的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了。
正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)。最早的想法是sigmoid函数或者tanh函数,输出有界,很容易充当下一层输入(以及一些人的生物解释balabala)。
第二个问题:为什么引入Relu呢?
第一,采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
第二,对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失,参见 @Haofeng Li 答案的第三点),从而无法完成深层网络的训练。
第三,Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生(以及一些人的生物解释balabala)。
当然现在也有一些对relu的改进,比如prelu,random relu等,在不同的数据集上会有一些训练速度上或者准确率上的改进,具体的大家可以找相关的paper看。
多加一句,现在主流的做法,会在做完relu之后,加一步batch normalization,尽可能保证每一层网络的输入具有相同的分布[1]。而最新的paper[2],他们在加入bypass connection之后,发现改变batch normalization的位置会有更好的效果。大家有兴趣可以看下。
深度学习(十六) ReLU为什么比Sigmoid效果好的更多相关文章
- 推荐系统遇上深度学习(十)--GBDT+LR融合方案实战
推荐系统遇上深度学习(十)--GBDT+LR融合方案实战 0.8012018.05.19 16:17:18字数 2068阅读 22568 推荐系统遇上深度学习系列:推荐系统遇上深度学习(一)--FM模 ...
- 对比深度学习十大框架:TensorFlow 并非最好?
http://www.oschina.net/news/80593/deep-learning-frameworks-a-review-before-finishing-2016 TensorFlow ...
- 强化学习(十六) 深度确定性策略梯度(DDPG)
在强化学习(十五) A3C中,我们讨论了使用多线程的方法来解决Actor-Critic难收敛的问题,今天我们不使用多线程,而是使用和DDQN类似的方法:即经验回放和双网络的方法来改进Actor-Cri ...
- 深度学习(六)keras常用函数学习
原文作者:aircraft 原文链接:https://www.cnblogs.com/DOMLX/p/9769301.html Keras是什么? Keras:基于Theano和TensorFlow的 ...
- 深度学习之逻辑回归的实现 -- sigmoid
1 什么是逻辑回归 1.1逻辑回归与线性回归的区别: 线性回归预测的是一个连续的值,不论是单变量还是多变量(比如多层感知器),他都返回的是一个连续的值,放在图中就是条连续的曲线,他常用来表示的数学方法 ...
- 《神经网络和深度学习》系列文章三:sigmoid神经元
出处: Michael Nielsen的<Neural Network and Deep Leraning>,点击末尾“阅读原文”即可查看英文原文. 本节译者:哈工大SCIR硕士生 徐伟 ...
- SIGAI深度学习第六集 受限玻尔兹曼机
讲授玻尔兹曼分布.玻尔兹曼机的网络结构.实际应用.训练算法.深度玻尔兹曼机等.受限玻尔兹曼机(RBM)是一种概率型的神经网络.和其他神经网络的区别:神经网络的输出是确定的,而RBM的神经元的输出值是不 ...
- Tensorflow2 深度学习十必知
博主根据自身多年的深度学习算法研发经验,整理分享以下十条必知. 含参考资料链接,部分附上相关代码实现. 独乐乐不如众乐乐,希望对各位看客有所帮助. 待回头有时间再展开细节说一说深度学习里的那些道道. ...
- 深度学习基础系列(三)| sigmoid、tanh和relu激活函数的直观解释
常见的激活函数有sigmoid.tanh和relu三种非线性函数,其数学表达式分别为: sigmoid: y = 1/(1 + e-x) tanh: y = (ex - e-x)/(ex + e-x) ...
随机推荐
- 4、Docker的安装
docker官方安装文档 Mac上安装Docker Install Docker for Mac | Docker Documentation Windows安装Docker Instal ...
- spring获取webapplicationcontext,applicationcontext几种方法详解(转载)
转载自 http://www.blogjava.net/Todd/archive/2010/04/22/295112.html 方法一:在初始化时保存ApplicationContext对象 代码: ...
- linux系统上查看硬件信息
一:查看CPU more /proc/cpuinfo | grep "model name" grep "model name" /proc/cpuinfo 如 ...
- Javascript Object.defineProperty()
转载声明: 本文标题:Javascript Object.defineProperty() 本文链接:http://www.zuojj.com/archives/994.html,转载请注明转自Ben ...
- [Oracle]Oracle数据库CPU利用率很高解决方案
Oracle数据库经常会遇到CPU利用率很高的情况,这种时候大都是数据库中存在着严重性能低下的SQL语句,这种SQL语句大大的消耗了CPU资源,导致整个系统性能低下.当然,引起严重性能低下的SQL语句 ...
- C# 使用ProcessStartInfo调用exe获取不到重定向数据的解决方案
emmmmm,最近在研究WFDB工具箱,C语言写的,无奈本人C语言功底不够,只想直接拿来用,于是打算通过ProcessStartInfo来调取编译出来的exe程序获取输出. 一开始就打算偷懒,从园子里 ...
- [uwp]自定义图形裁切控件
开始之前,先上一张美图.图中的花叫什么,我已经忘了,或者说从来就不知道,总之谓之曰“野花”.只记得花很美,很香,春夏时节,漫山遍野全是她.这大概是七八年前的记忆了,不过她依旧会很准时的在山上沐浴春光, ...
- MyBatis入门及CRUD
MyBatis是一个ORM的数据操作框架 myBatis的基本配置 首先创建一个普通 java项目,引入响应jar包,然后引入mybatis的xml配置, <?xml version=" ...
- Neutron FWaaS 原理
理解概念 Firewall as a Service(FWaaS)是 Neutron 的一个高级服务.用户可以用它来创建和管理防火墙,在 subnet 的边界上对 layer 3 和 layer 4 ...
- java中-的流-与操作
/* 字节输出流 OutputStrema: * OutputStream抽象类 * write(int b); 将指定的字节写入此流中 * write(byte[] b); ...