Lucene7.4学习和简单使用
简述:
前面从新回顾学习了Solr,正好也借此机会顺便学习一下Lucene。
一、什么是Lucene?
全文检索的一个实现方式,也是非结构化数据查询的方法。应用场景:在数据量大,数据结构不固定的时候,采用Lucene,比如百度、Google等搜索引擎,网站的站内搜索,电商平台的商品检索等。
二、Lucene实现全文检索的流程
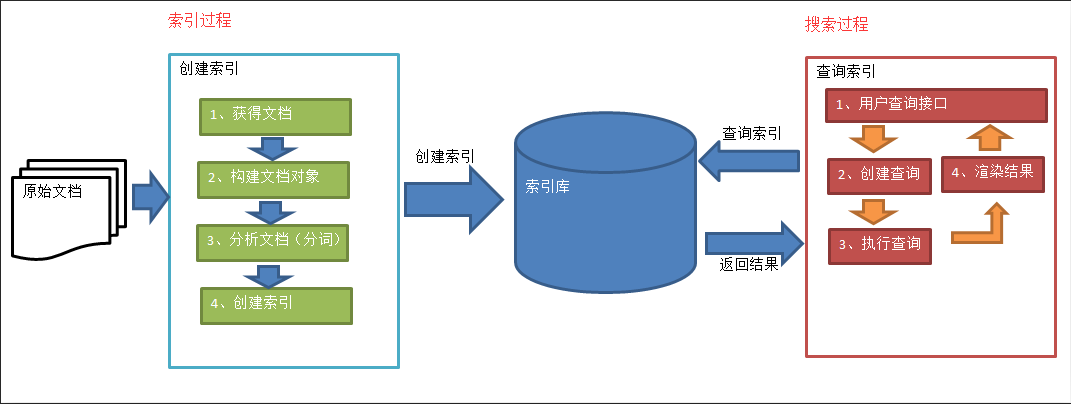
1、原始文档
原始文档是指要索引和搜索的内容。原始内容包括互联网上的网页、数据库中的数据、磁盘上的文件等。
2、创建文档对象
在构建索引之前,需要将原始内容构建成文档(Document),文档中包含一个一个的域(Field),域中存储内容。每个Document可以有多个Field,不同的Document可以有不同的Field,同一个Document可以有相同的Field(域名和域值都相同)。
3、分析文档
将原始内容创建为包含域(Field)的文档(document),需要再对域中的内容进行分析,分析的过程是经过对原始文档提取单词、将字母转为小写、去除标点符号、去除停用词等过程生成最终的语汇单元,可以将语汇单元理解为一个一个的单词。比如我是中国人,经过分析变成:我 是 中国人三个部分。每个语汇单元叫做一个Term,不同的域中拆分出来相同的单词是不同的Term。Term分为两部分一部分是文档的域名,另一部分是单词的内容。
4、创建索引
对所有的语汇单元进行索引,索引的目的就是为了搜索。通过索引找文档,这种索引的结构叫做倒排索引结构:倒排索引结构是根据索引找到文档,如下图:
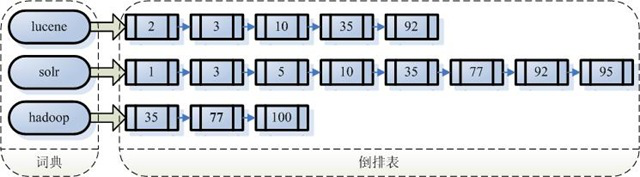
倒排索引结构也叫反向索引结构,包括索引和文档两部分,索引即词汇表,它的规模较小,而文档集合较大。
5、查询索引
查询之前需要先创建查询对象,查询对象中可以指定查询要搜索的Field文档域、查询关键字等,查询对象会生成具体的查询语法,例如:语法 “fileName:lucene”表示要搜索Field域的内容为“lucene”的文档。然后就是在索引上查找域为fileName,并且关键字为Lucene的term,并根据term找到文档id列表。最后将文档内容渲染给用户。可以提供高亮显示。
三、入门Demo
1、使用的包
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version></version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version></version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version></version>
</dependency>
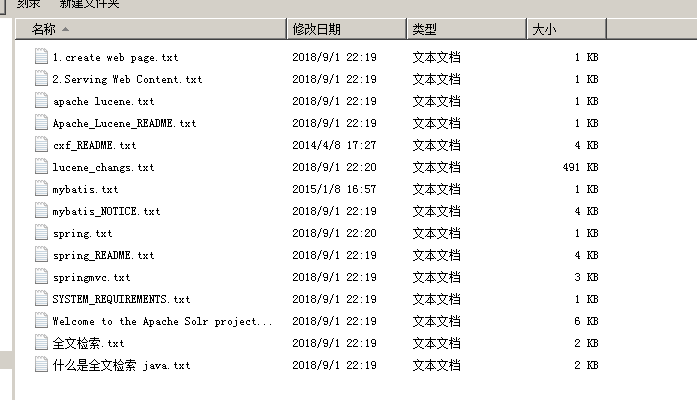
2、Demo需求
实现一个文件的搜索功能,通过关键字搜索文件,凡是文件名或文件内容包括关键字的文件都需要找出来。还可以根据中文词语进行查询,并且需要支持多个条件查询。本案例中的原始内容就是磁盘上的文件,如下图:
3、创建索引
@Test
public void createIndex() throws Exception {
// 1、创建一个Director对象,指定索引库保存的位置。
// 把索引库保存在内存中
// Directory directory = new RAMDirectory();
// 把索引库保存在磁盘
Directory directory = FSDirectory.open(new File("D:\\Lucene\\index").toPath());
// 2、基于Directory对象创建一个IndexWriter对象
IndexWriter indexWriter = new IndexWriter(directory, new IndexWriterConfig());
// 3、读取磁盘上的文件,对应每个文件创建一个文档对象。
File dir = new File("D:\\Lucene\\searchsource");
File[] files = dir.listFiles();
for (File f : files) {
// 取文件名
String fileName = f.getName();
// 文件的路径
String filePath = f.getPath();
// 文件的内容
String fileContent = FileUtils.readFileToString(f, "utf-8");
// 文件的大小
long fileSize = FileUtils.sizeOf(f);
// 创建Field
// 参数1:域的名称,参数2:域的内容,参数3:是否存储
Field fieldName = new TextField("name", fileName, Field.Store.YES);
Field fieldPath = new StoredField("path", filePath);
Field fieldContent = new TextField("content", fileContent, Field.Store.YES);
Field fieldSizeValue = new LongPoint("size", fileSize);
Field fieldSizeStore = new StoredField("size", fileSize);
// 创建文档对象
Document document = new Document();
// 向文档对象中添加域
document.add(fieldName);
document.add(fieldPath);
document.add(fieldContent);
// document.add(fieldSize);
document.add(fieldSizeValue);
document.add(fieldSizeStore);
// 5、把文档对象写入索引库
indexWriter.addDocument(document);
}
// 6、关闭indexwriter对象
indexWriter.close();
}
运行之后可以看到index文件里面生成了很多索引
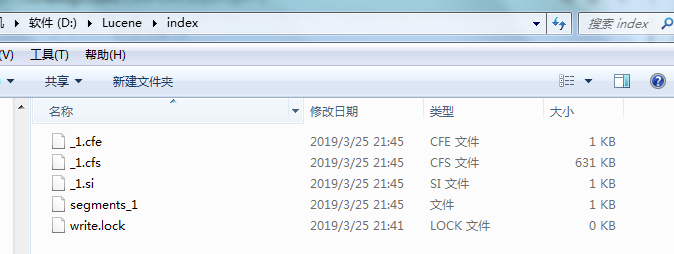
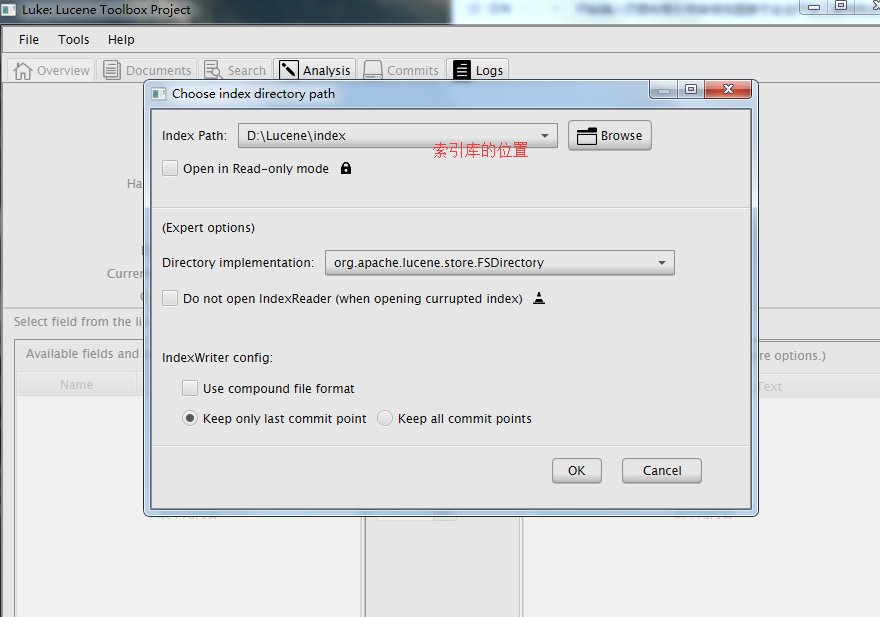
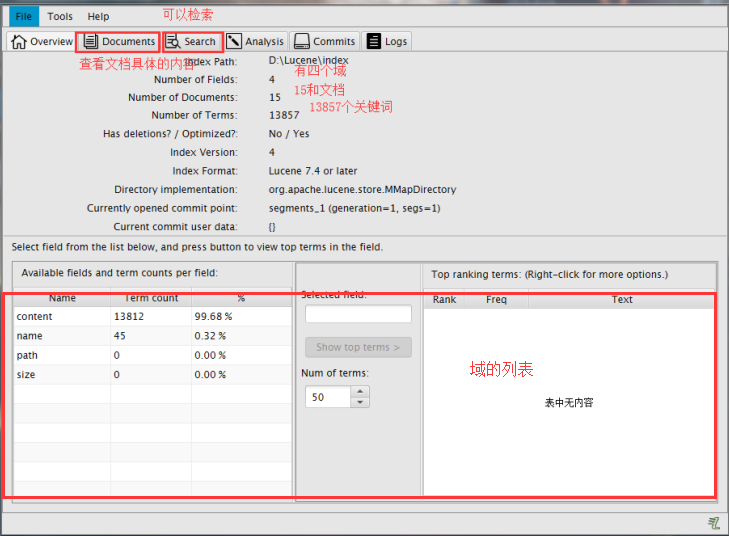
可以使用Luke工具查看索引文件
4、查询索引库
@Test
public void searchIndex() throws Exception {
// 1、创建一个Director对象,指定索引库的位置
Directory directory = FSDirectory.open(new File("D:\\Lucene\\index").toPath());
// 2、创建一个IndexReader对象
IndexReader indexReader = DirectoryReader.open(directory);
// 3、创建一个IndexSearcher对象,构造方法中的参数indexReader对象。
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
// 4、创建一个Query对象,TermQuery
Query query = new TermQuery(new Term("name", "spring"));
// 5、执行查询,得到一个TopDocs对象
// 参数1:查询对象 参数2:查询结果返回的最大记录数
TopDocs topDocs = indexSearcher.search(query, );
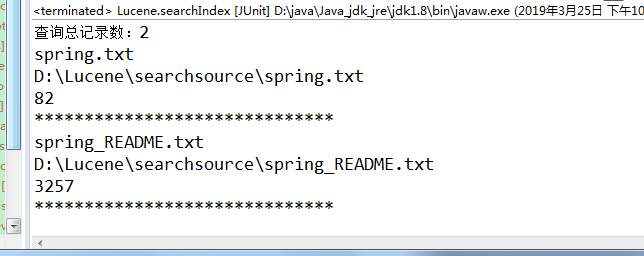
// 6、取查询结果的总记录数
System.out.println("查询总记录数:" + topDocs.totalHits);
// 7、取文档列表
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
// 8、打印文档中的内容
for (ScoreDoc doc : scoreDocs) {
// 取文档id
int docId = doc.doc;
// 根据id取文档对象
Document document = indexSearcher.doc(docId);
System.out.println(document.get("name"));
System.out.println(document.get("path"));
System.out.println(document.get("size"));
// System.out.println(document.get("content"));
System.out.println("******************************");
}
// 9、关闭IndexReader对象
indexReader.close();
}
5、自定义分词器(IK分词器)
之前在创建索引的时候没有使用分词器,其实是使用了默认的标准分词器
IndexWriter indexWriter = new IndexWriter(directory, new IndexWriterConfig());

但是这种分词器对中文处理的很不好,所以这里选择使用IK分词器。网上找到的maven坐标导入报错,所以就找了一个jar手动导入
自定义分词器词汇
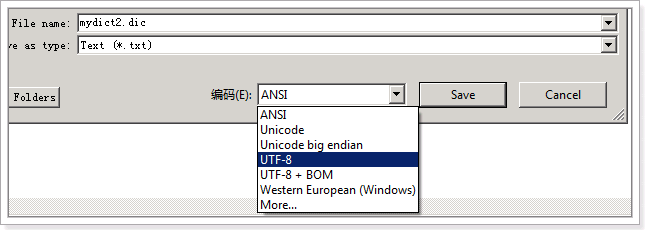
把配置文件和扩展词典和停用词词典添加到classpath下 。注意:hotword.dic和stopword.dic文件的格式为UTF-8,注意是无BOM 的UTF-8 编码。也就是说禁止使用windows记事本编辑扩展词典文件使用EditPlus.exe保存为无BOM 的UTF-8 编码格式,如下图:
测试IK分词器
@Test
public void testTokenStream() throws Exception {
// 1)创建一个Analyzer对象,StandardAnalyzer对象
// 标准分词器
Analyzer analyzer = new StandardAnalyzer();// 2)使用分析器对象的tokenStream方法获得一个TokenStream对象
TokenStream tokenStream = analyzer.tokenStream("","我就是想测试一下Lucene的中文分词器而已,没有别的意思了");
// 3)向TokenStream对象中设置一个引用,相当于数一个指针
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
// 4)调用TokenStream对象的rest方法。如果不调用抛异常
tokenStream.reset();
// 5)使用while循环遍历TokenStream对象
while (tokenStream.incrementToken()) {
System.out.println(charTermAttribute.toString());
}
// 6)关闭TokenStream对象
tokenStream.close();
}
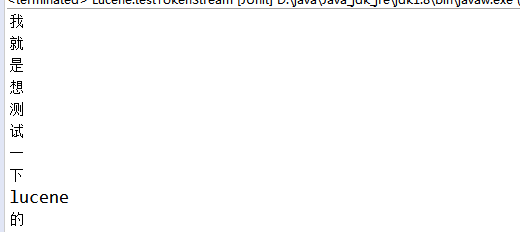
结论:在这里可以看到标准分词器对中文并不友好
@Test
public void testTokenStream() throws Exception {
// 1)创建一个Analyzer对象,StandardAnalyzer对象 //IK分词器
Analyzer analyzer = new IKAnalyzer();
// 2)使用分析器对象的tokenStream方法获得一个TokenStream对象
TokenStream tokenStream = analyzer.tokenStream("","我就是想测试一下Lucene的中文分词器而已,没有别的意思了");
// 3)向TokenStream对象中设置一个引用,相当于数一个指针
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
// 4)调用TokenStream对象的rest方法。如果不调用抛异常
tokenStream.reset();
// 5)使用while循环遍历TokenStream对象
while (tokenStream.incrementToken()) {
System.out.println(charTermAttribute.toString());
}
// 6)关闭TokenStream对象
tokenStream.close();
}
//IK分词器
Analyzer analyzer = new IKAnalyzer();
// 2)使用分析器对象的tokenStream方法获得一个TokenStream对象
TokenStream tokenStream = analyzer.tokenStream("","我就是想测试一下Lucene的中文分词器而已,没有别的意思了");
// 3)向TokenStream对象中设置一个引用,相当于数一个指针
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
// 4)调用TokenStream对象的rest方法。如果不调用抛异常
tokenStream.reset();
// 5)使用while循环遍历TokenStream对象
while (tokenStream.incrementToken()) {
System.out.println(charTermAttribute.toString());
}
// 6)关闭TokenStream对象
tokenStream.close();
}

结论:可以看到IK中文分词器效果明显比标准分词器好。
如何使用IK分词器
在创建索引的第二步里面加上IK分词器就可以使用了

IndexWriter indexWriter = new IndexWriter(directory, new IndexWriterConfig(new IKAnalyzer()));
5、索引库的维护
Field(域)有很多类型。下面就介绍Field(域的属性)
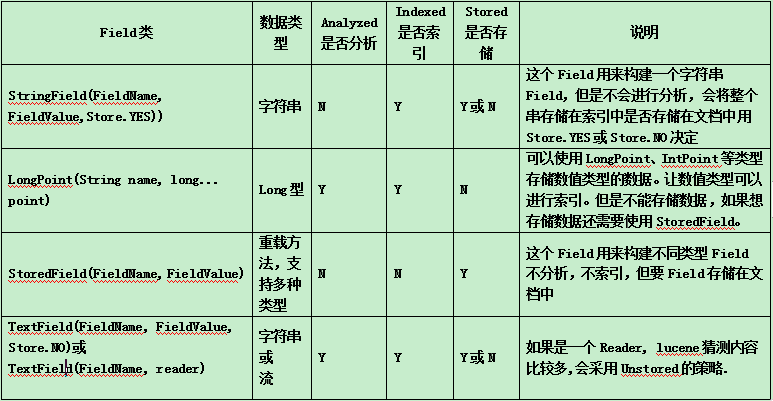
结论:根据不同的类型使用不同的域
新增索引
@Test
public void addDocument() throws Exception {
// 创建一个IndexWriter对象,需要使用IKAnalyzer作为分析器
IndexWriter indexWriter = new IndexWriter(FSDirectory.open(new File("D:\\Lucene\\index").toPath()),
new IndexWriterConfig(new IKAnalyzer()));
// 创建一个Document对象
Document document = new Document();
// 向document对象中添加域
document.add(new TextField("name", "新增加的域", Field.Store.YES));
document.add(new TextField("content", "新家域的内容", Field.Store.NO));
document.add(new StoredField("path", "D:/temp/helo"));
// 把文档写入索引库
indexWriter.addDocument(document);
// 关闭索引库
indexWriter.close();
}
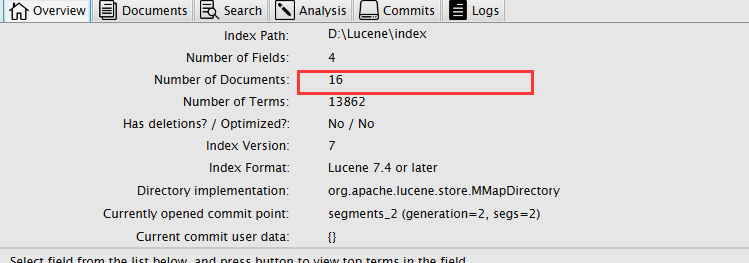
可以看到文档域变成了16个
删除索引
@Test
public void deleteAllDocument() throws Exception {
// 创建一个IndexWriter对象,需要使用IKAnalyzer作为分析器
IndexWriter indexWriter = new IndexWriter(FSDirectory.open(new File("D:\\Lucene\\index").toPath()),
new IndexWriterConfig(new IKAnalyzer()));
//删除全部索引
indexWriter.deleteAll();//关闭索引库
indexWriter.close();
}
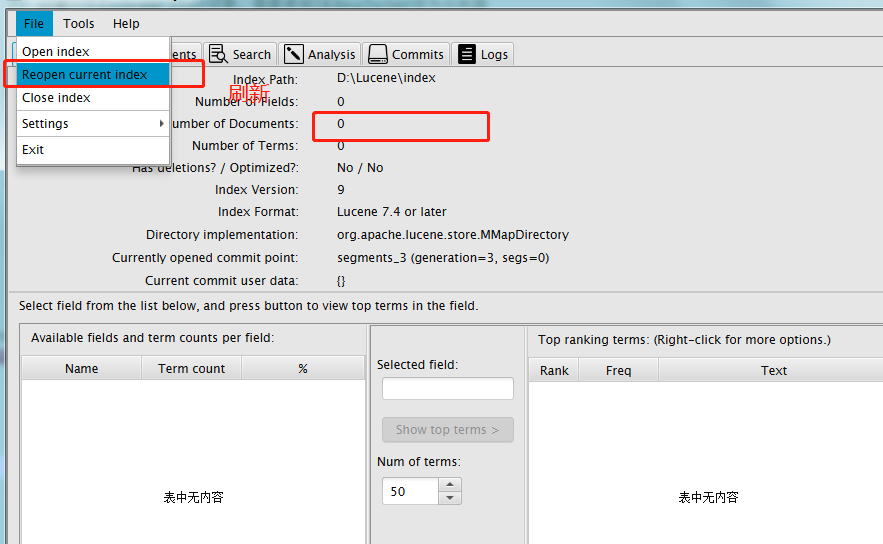
这样就会删除全部,当然也可以根据条件删除。我们先把之前增加的索引全部再增加一次。然后查询文档中有包含spring的有几个。


@Test
public void deleteAllDocument() throws Exception {
// 创建一个IndexWriter对象,需要使用IKAnalyzer作为分析器
IndexWriter indexWriter = new IndexWriter(FSDirectory.open(new File("D:\\Lucene\\index").toPath()),
new IndexWriterConfig(new IKAnalyzer()));
//根据条件删除
indexWriter.deleteDocuments(new Term("name", "spring"));
//关闭索引库
indexWriter.close();
}
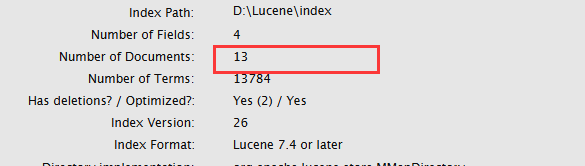
原始文档有15个,删除2个包含spring的
修改索引
在Lucene中修改的原理是先删除在新增。步骤:先删除全部索引,再增加全部索引。然后替换包换spring的
@Test
public void updateDocument() throws Exception {
IndexWriter indexWriter = new IndexWriter(FSDirectory.open(new File("D:\\Lucene\\index").toPath()),
new IndexWriterConfig(new IKAnalyzer()));
//创建一个新的文档对象
Document document = new Document();
//向文档对象中添加域
document.add(new TextField("name", "测试索引修改", Field.Store.YES));//更新操作
indexWriter.updateDocument(new Term("name", "spring"), document);
//关闭索引库
indexWriter.close();
}
这时候在查询包含spring的文档
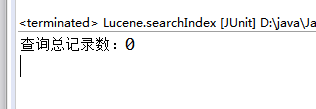
然后查询包含测试的文档
从这个结论就可以看出,更新就是先删除,然后在增加。、
本文中所需要的jar包和资料:链接:https://pan.baidu.com/s/1UU0e5_fnh8bZ1y85U4Ibqw 提取码:bxdp
目前主要就是学到这里。后面如果用到或者再学习到了。在继续补充。这个案例只是搭建一个简单Demo。里面难免会有错误的地方。欢迎指正
Lucene7.4学习和简单使用的更多相关文章
- JMeter学习工具简单介绍
JMeter学习工具简单介绍 一.JMeter 介绍 Apache JMeter是100%纯JAVA桌面应用程序,被设计为用于测试客户端/服务端结构的软件(例如web应用程序).它可以用来测试静态 ...
- (java)selenium webdriver学习---实现简单的翻页,将页面内容的标题和标题链接取出
selenium webdriver学习---实现简单的翻页,将页面内容的标题和标题链接取出: 该情况适合能能循环page=1~n,并且每个网页随着循环可以打开的情况, 注意一定是自己拼接的url可以 ...
- IIC驱动学习笔记,简单的TSC2007的IIC驱动编写,测试
IIC驱动学习笔记,简单的TSC2007的IIC驱动编写,测试 目的不是为了编写TSC2007驱动,是为了学习IIC驱动的编写,读一下TSC2007的ADC数据进行练习,, Linux主机驱动和外设驱 ...
- CSS学习------之简单图片切换
最近一直在重温纯CSS,学习的时候真的才发现,css真的博大精深啊! 所以趁着学习的劲头,谢了个最简单的CSS图片切换! 先整理下思路: 首先我希望图片居中间,两边有个切换按钮,点击按钮的时候,可以实 ...
- CMake学习(1)---简单程序与库
cmake是linux平台下重要的工具,可以方便的组织makefile.之前一直在windows平台下进行软件开发,在vs2010的IDE里,只要一点run程序就能跑出结果.但是程序的编译并没有那么简 ...
- Ajax学习(1)-简单ajax案例
1.什么是Ajax? Ajax是Asynchronous JavaScript and XML 的缩写,即异步的Javascript和XML. 可以使用Ajax在不加载整个网页的情况下更新部分网页信息 ...
- [Struts2学习笔记] -- 简单的类型转换
接下来学习一下Struts2简单的类型转换,Struts2基于ognl.jar实现了简单类型的数据转换.比如jsp页面中的form值与字段值的转换,下面写一个例子. 1.创建一个jsp页面,编写一个f ...
- JavaScript学习笔记——简单无缝循环滚动展示图片的实现
今天做了一个简单的无缝循环滚动的实例,这种实例在网页中其实还挺常见的,下面分享一下我的学习收获. 首先,无缝滚动的第一个重点就是——动.关于怎么让页面的元素节点动起来,这就得学明白关于JavaScri ...
- OpenGL学习-------绘制简单的几何图形
本次课程所要讲的是绘制简单的几何图形,在实际绘制之前,让我们先熟悉一些概念. 一.点.直线和多边形我们知道数学(具体的说,是几何学)中有点.直线和多边形的概念,但这些概念在计算机中会有所不同.数学上的 ...
随机推荐
- 286被围绕的区域 · Surrounded Regions
[抄题]: 给一个二维的矩阵,包含 'X' 和 'O', 找到所有被 'X' 围绕的区域,并用 'X' 填充满. 样例 给出二维矩阵: X X X X X O O X X X O X X O X X ...
- JavaScript stringObject.replace() 方法
定义和用法: replace() 方法用于在字符串中用一些字符替换另一些字符,或替换一个与正则表达式匹配的子串. 语法: stringObject.replace(RegExp/substr,reol ...
- JAVA定时关机小程序
大一刚学java时候做的小程序.由于当时迅雷还没有下载完成关机,晚上要下很多学习资料.只有自己算时间然后通过shutdown命令设置时间关机. 当时通过shutwodn命令,想到能否通过java做一个 ...
- popupWindow自适应大小
// popupWindow自适应大小 popupWindow = new PopupWindow(view, LayoutParams.WRAP_CONTENT, LayoutParams.WRAP ...
- 数据结构(c语言版)文摘
第一章 绪论 数据结构:是一门研究非数值计算的程序设计问题中计算机的操作对象以及它们之间的关系和操作等的学科. 数据:是对客观事物的符号表示,在计算机科学中是指所有能输入到计算机中并被计算机程序处理 ...
- redis cluster 使用中出现的问题
问题一 redis.clients.jedis.exceptions.JedisClusterMaxRedirectionsException: Too many Cluster redirectio ...
- 看图说说class文件结构(部分)
- swift - 动画学习
// // ViewController.swift // MapAnimation // // Created by su on 15/12/10. // Copyright © 2015年 ...
- 测试用数据库表设计和SessionFactory
本篇为struts-2.5.2和spring-3.2.0以及hibernate-4.2.21的整合开篇. 一.测试的数据库表. 用户.角色和权限关系表.数据库是Mysql5.6.为了考虑到一些特殊数据 ...
- struts2 动态Action
1.java 2.struts.xml struts2.5,默认关闭动态Action,着色的是开启和使用动态action 3.JSP 小结:访问时,用!后跟方法名的方法,方法返回值----->r ...