python 2.0 s12 day5 常用模块介绍
模块,用一砣代码实现了某个功能的代码集合。
类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合。而对于一个复杂的功能来,可能需要多个函数才能完成(函数又可以在不同的.py文件中),n个 .py 文件组成的代码集合就称为模块。
如:os 是系统相关的模块;file是文件操作相关的模块
模块分为三种:
- 自定义模块
- 内置模块
- 开源模块
自定义模块
1、定义模块
情景一:

情景二:

情景三:

2、导入模块
Python之所以应用越来越广泛,在一定程度上也依赖于其为程序员提供了大量的模块以供使用,如果想要使用模块,则需要导入。导入模块有一下几种方法:
import module
from module.xx.xx import xx
from module.xx.xx import xx as rename
from module.xx.xx import *
导入模块其实就是告诉Python解释器去解释那个py文件
- 导入一个py文件,解释器解释该py文件
- 导入一个包,解释器解释该包下的 __init__.py 文件
那么问题来了,导入模块时是根据那个路径作为基准来进行的呢?即:sys.path
import sys
print sys.path 结果:
['/Users/wupeiqi/PycharmProjects/calculator/p1/pp1', '/usr/local/lib/python2.7/site-packages/setuptools-15.2-py2.7.egg', '/usr/local/lib/python2.7/site-packages/distribute-0.6.28-py2.7.egg', '/usr/local/lib/python2.7/site-packages/MySQL_python-1.2.4b4-py2.7-macosx-10.10-x86_64.egg', '/usr/local/lib/python2.7/site-packages/xlutils-1.7.1-py2.7.egg', '/usr/local/lib/python2.7/site-packages/xlwt-1.0.0-py2.7.egg', '/usr/local/lib/python2.7/site-packages/xlrd-0.9.3-py2.7.egg', '/usr/local/lib/python2.7/site-packages/tornado-4.1-py2.7-macosx-10.10-x86_64.egg', '/usr/local/lib/python2.7/site-packages/backports.ssl_match_hostname-3.4.0.2-py2.7.egg', '/usr/local/lib/python2.7/site-packages/certifi-2015.4.28-py2.7.egg', '/usr/local/lib/python2.7/site-packages/pyOpenSSL-0.15.1-py2.7.egg', '/usr/local/lib/python2.7/site-packages/six-1.9.0-py2.7.egg', '/usr/local/lib/python2.7/site-packages/cryptography-0.9.1-py2.7-macosx-10.10-x86_64.egg', '/usr/local/lib/python2.7/site-packages/cffi-1.1.1-py2.7-macosx-10.10-x86_64.egg', '/usr/local/lib/python2.7/site-packages/ipaddress-1.0.7-py2.7.egg', '/usr/local/lib/python2.7/site-packages/enum34-1.0.4-py2.7.egg', '/usr/local/lib/python2.7/site-packages/pyasn1-0.1.7-py2.7.egg', '/usr/local/lib/python2.7/site-packages/idna-2.0-py2.7.egg', '/usr/local/lib/python2.7/site-packages/pycparser-2.13-py2.7.egg', '/usr/local/lib/python2.7/site-packages/Django-1.7.8-py2.7.egg', '/usr/local/lib/python2.7/site-packages/paramiko-1.10.1-py2.7.egg', '/usr/local/lib/python2.7/site-packages/gevent-1.0.2-py2.7-macosx-10.10-x86_64.egg', '/usr/local/lib/python2.7/site-packages/greenlet-0.4.7-py2.7-macosx-10.10-x86_64.egg', '/Users/wupeiqi/PycharmProjects/calculator', '/usr/local/Cellar/python/2.7.9/Frameworks/Python.framework/Versions/2.7/lib/python27.zip', '/usr/local/Cellar/python/2.7.9/Frameworks/Python.framework/Versions/2.7/lib/python2.7', '/usr/local/Cellar/python/2.7.9/Frameworks/Python.framework/Versions/2.7/lib/python2.7/plat-darwin', '/usr/local/Cellar/python/2.7.9/Frameworks/Python.framework/Versions/2.7/lib/python2.7/plat-mac', '/usr/local/Cellar/python/2.7.9/Frameworks/Python.framework/Versions/2.7/lib/python2.7/plat-mac/lib-scriptpackages', '/usr/local/Cellar/python/2.7.9/Frameworks/Python.framework/Versions/2.7/lib/python2.7/lib-tk', '/usr/local/Cellar/python/2.7.9/Frameworks/Python.framework/Versions/2.7/lib/python2.7/lib-old', '/usr/local/Cellar/python/2.7.9/Frameworks/Python.framework/Versions/2.7/lib/python2.7/lib-dynload', '/usr/local/lib/python2.7/site-packages', '/Library/Python/2.7/site-packages']
如果sys.path路径列表没有你想要的路径,可以通过 sys.path.append('路径') 添加。
通过os模块可以获取各种目录,例如:
import sys
import os pre_path = os.path.abspath('../')
sys.path.append(pre_path)
开源模块
一、下载安装
下载安装有两种方式:
yum
pip
apt-get
...
方式一
下载源码
解压源码
进入目录
编译源码 python setup.py build
安装源码 python setup.py install
方式二
注:在使用源码安装时,需要使用到gcc编译和python开发环境,所以,需要先执行:
yum install gcc
yum install python-devel
或
apt-get python-dev
安装成功后,模块会自动安装到 sys.path 中的某个目录中,如:
/usr/lib/python2.7/site-packages/
二、导入模块
同自定义模块中导入的方式
三、模块 paramiko
paramiko是一个用于做远程控制的模块,使用该模块可以对远程服务器进行命令或文件操作,值得一说的是,fabric和ansible内部的远程管理就是使用的paramiko来现实。
1、下载安装
# pycrypto,由于 paramiko 模块内部依赖pycrypto,所以先下载安装pycrypto # 下载安装 pycrypto
wget http://files.cnblogs.com/files/wupeiqi/pycrypto-2.6.1.tar.gz
tar -xvf pycrypto-2.6.1.tar.gz
cd pycrypto-2.6.1
python setup.py build
python setup.py install # 进入python环境,导入Crypto检查是否安装成功 # 下载安装 paramiko
wget http://files.cnblogs.com/files/wupeiqi/paramiko-1.10.1.tar.gz
tar -xvf paramiko-1.10.1.tar.gz
cd paramiko-1.10.1
python setup.py build
python setup.py install # 进入python环境,导入paramiko检查是否安装成功
2、使用模块
内置模块
一、os
用于提供系统级别的操作
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推比如os.removedirs('t2/t4')
先检查t4目录是否为空,为空则删除,紧接着判断t2目录是不是为空,为空则还删除。到t2为止,就不在往上找了。总得来说没啥用
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
OS模块,还有一个没讲:
我们大家都用户os.system()这个是再python的交互模式下,调用系统命令,如下:
>>> os.system('ls -l')
total 24
drwxr-xr-x 3 tedzhou staff 102 4 14 13:40 __pycache__
-rwxr-xr-x 1 tedzhou staff 538 4 15 17:58 mode.py
-rw-r--r-- 1 tedzhou staff 4401 5 11 11:14 test.txt
0 #这里我们看,最终获得了一个0 ,这个0是什么?这个0表示的你传入os.system()里的参数有没有执行成功.
#把这个命令赋值给一个变量
>>> a = os.system('ls -l')
total 24
drwxr-xr-x 3 tedzhou staff 102 4 14 13:40 __pycache__
-rwxr-xr-x 1 tedzhou staff 538 4 15 17:58 mode.py
-rw-r--r-- 1 tedzhou staff 4401 5 11 11:14 test.txt
>>> a
0
#我们看到变量a最终获得的值是0,但是我想把这个执行结果读出来,用os.system()能实现吗.
#答案是不能,因为os.system()函数最终return的是状态值,并不返回命令的执行结果.那么我们该如何获得呢.
只能通过os.popen()方法,相当于打开了一个临时的文件来存命令运行结果.如下:
>>> b = os.popen('ls -l') #相当于打开了一个临时的文件来存命令运行结果,所以想得到里面的内容,就得像读文件一样得方式
>>> b.read() #看到没,read()出来得时候是一个长字符串.
'total 24\ndrwxr-xr-x 3 tedzhou staff 102 4 14 13:40 __pycache__\n-rwxr-xr-x 1 tedzhou staff 538 4 15 17:58 mode.py\n-rw-r--r-- 1 tedzhou staff 4401 5 11 11:14 test.txt\n'
#我们打印看看
>>> print(b.read())
total 24
drwxr-xr-x 3 tedzhou staff 102 4 14 13:40 __pycache__
-rwxr-xr-x 1 tedzhou staff 538 4 15 17:58 mode.py
-rw-r--r-- 1 tedzhou staff 4401 5 11 11:14 test.txt
这个os.popen要记住.
还有一个常用到的,就是查看文件的大小,用os.stat('')如下:
>>> os.stat('test.txt')
os.stat_result(st_mode=33188, st_ino=12613921, st_dev=16777220, st_nlink=1, st_uid=501, st_gid=20, st_size=4401, st_atime=1462936914, st_mtime=1462936493, st_ctime=1462936493)
os.path.isdir() 判断是不是目录,返回True和False
其他的用的时候去查下
更多猛击这里
二、sys
用于提供对解释器相关的操作
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys.stdout.write('please:')
val = sys.stdin.readline()[:-1]
使用sys模块,输出最简单的进度条
import sys
import time
for i in range(10):
sys.stdout.write("#")
time.sleep(0.3) 打印结果:
##########
直接显示出来了.尼玛不是说好的一个一个显示出来吗?
原因:在屏幕打印和是其他什么都有一个缓冲区,缓冲区满了就会打印出来 那怎么解决呢,可以强制打印,可以加
sys.stdout.flush() import sys
import time
for i in range(10):
sys.stdout.write("#")
sys.stdout.flush()
time.sleep(0.3)
这样就可以显示进度条了
更多猛击这里
三、hashlib
用于加密相关的操作,代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
import md5
hash = md5.new()
hash.update('admin')
print hash.hexdigest()
MD5加密
import sha hash = sha.new()
hash.update('admin')
print hash.hexdigest()
sha加密
import hashlib # ######## md5 ######## hash = hashlib.md5()
hash.update('admin')
print hash.hexdigest() # ######## sha1 ######## hash = hashlib.sha1()
hash.update('admin')
print hash.hexdigest() # ######## sha256 ######## hash = hashlib.sha256()
hash.update('admin')
print hash.hexdigest() # ######## sha384 ######## hash = hashlib.sha384()
hash.update('admin')
print hash.hexdigest() # ######## sha512 ######## hash = hashlib.sha512()
hash.update('admin')
print hash.hexdigest()
以上加密算法虽然依然非常厉害,但时候存在缺陷,即:通过撞库可以反解。所以,有必要对加密算法中添加自定义key再来做加密。
import hashlib
# ######## md5 ########
hash = hashlib.md5('898oaFs09f')
hash.update('admin')
print hash.hexdigest()
还不够吊?python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密
import hmac
h = hmac.new('wueiqi')
h.update('hellowo')
print h.hexdigest()
不能再牛逼了!!!
四、json 和 pickle
用于序列化的两个模块
我们知道文件只能存储字符类型的数据,你写入的字典、列表和数字都会报错。虽然你打开文件发现文件有字典的样式,其实还是字符串。
f = open(“user_acc.txt”,”wb”)
f.write(b”test”)
f.write(123)报错
现在有一个字典
info = {
“alex”:’123’
‘jack’:’234'
}
在一个程序里写入了账户信息,另外一台机器想使用这个信息怎么办?
我们可能会想到使用import,然后调用里面的方法。但是两个程序不是一台机器你怎么import,比如说,你用atm机登录你的银行账户,假设不用数据库存储用户信息,就用程序存储。
你用import导入的前提是atm客户端要导入你的账户信息,是不是要导入服务器端程序中的账户信息文件。我们不可能在atm客户端拷贝一份银行系统程序,专门用来导入吧。也就是说用导入是不切实际的。那怎么办?如何将这些账户信息传递给atm客户端。
我门用传统的方法就是将用户文件拷贝到atm客户端。怎么拷贝呢,这个数据信息是程序生成的,程序生成的数据是不是在内存中,想拷贝是不是要写入文件。
写入文件,我们都学过,但是我们知道文件只能存字符串,也就是说,你存入文件应该是将上面的字典转换成字符串格式。所以写入时应该是
f_w = open(‘user_acc.txt’,’wb’)
f_w.write(str(info))
这样是写入了,我们异想天开的认为,我写入时转换成字符串。为了方便操作我读出来的时候在通过 dict(f.read())就会把它恢复成字典的格式了:
info = {
“alex”:’123’
‘jack’:’234'
}
no,当我们转换成字符串格式写入文件时,是这个样子的
‘info={\n“alex”:”123”\n”jack”:”234”}’
那么使用
f = open(‘user_acc.txt’,’rb’)
f.read()
读出来的样子也肯定是
‘info={\n“alex”:”123”\n”jack”:”234”}’
这J8字符串前面加dict()转换肯定失败。你也可以使用for循环一行一行的读,在配合正则表达式把这个字符串恢复成字典,如下:
info = {
“alex”:’123’
‘jack’:’234'
}
但是这是一个简单的一级字典,那如果有个10层20层,并且每一层还有列表和元组等呢,你这还怎么转换。
这J8怎么办,有没有可以把程序生成的数据类型能直接打个标记,然后到下一个程序中读这个内容到内存时在根据这个标记恢复成原来的数据类型呢。
答案是有:json和pickle两个模块就可以完成这个功能。打标记这个操作专业名词叫做序列化,解析序列化的过程又叫做反序列化
json和pickle区别在于:
1.json适用于所有语言,而pickle只适用于python
2.json仅能对一些常见的内存数据类型进行序列化和反序列化,而pickle可以对多种类型进行序列化和反序列化比如对对象和函数也可以,而json不行。 json和pickle的具体用法: 使用json进行序列化和反序列化
序列化
>>> a #a是一个字典
{'k2': 'v2', 'k1': 'v1'}
>>> data = json.dumps(a) #将a序列化,得到序列化后的数据data
>>> data
'{"k2": "v2", "k1": "v1”}’ #这是序列化后的数据,看起来差不多,其实不是字典
>>> f = open('1.txt','w’)
>>> f.write(data) #将序列化后的字符串加入到文件。 反序列化:
>>> f = open('1.txt','r’) #文件句柄
>>> data = f.read() #讲文件读出来
>>> data_from_json = json.loads(data) 反序列化 使用pickle进行序列化和反序列
pickle和json使用上唯一区别是,读写文件要用二进制模式。 >>> a #a是一个字典
{'k2': 'v2', 'k1': 'v1'}
>>> data = pickle.dumps(a) #将a序列化,得到序列化后的数据data
>>> data
b'\x80\x03}q\x00(X\x02\x00\x00\x00k2q\x01X\x02\x00\x00\x00v2q\x02X\x02\x00\x00\x00k1q\x03X\x02\x00\x00\x00v1q\x04u.' #这是序列化后的数据,都是二进制数据
>>> f = open('1.txt','wb’)
>>> f.write(data) #将序列化后的字符串加入到文件。 反序列化:
>>> f = open('1.txt','rb’) #文件句柄
>>> data = f.read() #讲文件读出来
>>> data_from_pickle = pickle.loads(data) 反序列化 以上就是json和pickle的用法了,还有一对
json.dump()
json.load() pickle.dump()
pickle.load() dump()和dumps()区别
dump()是简化了dumps()
比如前面我们
>>> a #a是一个字典
{'k2': 'v2', 'k1': 'v1'}
>>> data = json.dumps(a) #将a序列化,得到序列化后的数据data
>>> data
'{"k2": "v2", "k1": "v1”}’ #这是序列化后的书籍,看起来差不多,其实不是字典
>>> f = open('1.txt','w’)
>>> f.write(data) # 用dump()直接就写成:
>>> a #a是一个字典
{'k2': 'v2', 'k1': 'v1’}
>>> f = open('1.txt','w’)
>>> json.dump(a,f) load()也是对loads()过程简化
反序列化:
>>> f = open('1.txt','r’) #文件句柄
>>> data = f.read() #讲文件读出来
>>> data_from_json = json.loads(data) 反序列化 用load()就可以写成:
>>> f = open('1.txt','r’) #文件句柄
>>> data_from_json = json.load(f) 反序列化
五、shelve 模块
shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式.
说白了它就是对pickle再做了一层封装,使你的调用非常简单.
前面我们知道pickle的dump方法
1.有一个要序列化的数据.数据可以是列表\字典\对象等
2.以2进制写的模式打开一个文件.
3.用pickle模块将数据dump进文件.
实例:
>>> a = {'k1': 'v1', 'k3': 'v3', 'k2': 'v2'}
>>> f = open('1.txt','wb')
>>> pickle.dump(a,f)
>>> f.close() #这时你再去看1.txt文件里就有二进制文件信息了.
那么读取步骤:
1.用二进制的模式打开一个文件.
2.使用pickle.load()方法将文件内容load出来,并赋值给变量.
实例:
>>> f.close()
>>> f = open('1.txt','rb')
>>> a = pickle.load(f)
>>> a
{'k1': 'v1', 'k3': 'v3', 'k2': 'v2'}
以上是pickle方法.前面说shelve模块是对pickle再做了一层封装,我们想pickle就是将内存里的不同类型数据存储到文件的方法.再外面封装一层到底要优化什么呢?
我们看,上面我们只是将一个变量a 使用pickle.dump()方法存到1.txt文件了.那么我如果有2个变量或者10个变量如何存储呢.
pickle也是 可以完成的,当文件句柄没有f.close()之前都可以进行pickle.dump()的,如下:
>>> a = {'k1': 'v1', 'k3': 'v3', 'k2': 'v2'}
>>> b = [1,2,3,4,]
>>> c = ('x','y','sb')
>>> f = open('1.txt','wb')
>>> pickle.dump(a,f)
>>> pickle.dump(b,f)
>>> pickle.dump(c,f)
那么我们才想,我现在f.close()到底存的是a呢还是b呢还是c呢.还是所有都有呢.
我们pickle.load()看下结果,我们来多次执行load操作看下结果
>>> f = open('1.txt','rb')
>>> pickle.load(f) # 第一次load
{'k1': 'v1', 'k3': 'v3', 'k2': 'v2'}
>>> pickle.load(f) # 第二次load
[1, 2, 3, 4]
>>> pickle.load(f) # 第三次load
('x', 'y', 'sb')
>>> pickle.load(f) # 第四次load
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
EOFError: Ran out of input
>>>
从上面结果我们可以看到前三次都是按顺序将前面dump进去的内容都读出来了,第四次直接报错.可以得出结论:
pickle可以再文件未f.close()之前可以多次dump,文件关闭后f.close(),将把之前dunp的内容按顺序进行保存到1.txt文件.
对这种多次dump的文件,我们可以通过多次load进行获取,只是不能获取指定想要的内容,而是按顺序来的.
那么问题来了如何获得指定的dump内容呢.能不能像列表一样通过下标,或者像字典一样获取内容呢.
答案是否定的,pickle.load()是不支持下标或者字典的方式,那实际需求又有这些需求,那么改怎么办呢.
这时候就该 shelve 模块出场了.shelve对pickle封装就是为了实现这个功能.
shelve实例:
1.使用 d = shelve.open()打开一个文件
2.使用 d['k'] = value 的方式将要存储的数据类型,序列化进文件.
3.使用d.close() 关闭文件句柄
实例:
使用shelve模块将数据序列化进文件
>>> import shelve >>> a = {'k1': 'v1', 'k3': 'v3', 'k2': 'v2'}
>>> b = [1, 2, 3, 4]
>>> c = ('x', 'y', 'sb' >>> d = shelve.open('shelve_test')) # 第一步 ,注意这里并没有指定打开文件的模式如:'wb' >>> d['dict_test'] = a # 第二步 又叫持久化列表
>>> d['list_test'] = b ...
>>> d['tuple_test'] = c ...
>>> d.close() # 第三步
使用shelve模块 将数据从文件反序列化出来:
1.先用d = shelve.open()方法打开文件
2.使用 d.get("k")获得之前传入进去的数据
如下:
>>> import shelve
>>> d = shelve.open('shelve_test')
>>> d.keys() #尝试像获得字典的形式获得字典的keys,我们看到得到的是封装后的数据类型
KeysView(<shelve.DbfilenameShelf object at 0x10181c080>)
>>> d.items() #尝试像获得字典的形式获得字典的items,我们看到得到的是封装后的数据类型
ItemsView(<shelve.DbfilenameShelf object at 0x10181c080>)
>>> d.values() #尝试像获得字典的形式获得字典的values,我们看到得到的是封装后的数据类型
ValuesView(<shelve.DbfilenameShelf object at 0x10181c080>)
>>> d.get('dict_test') #只能用get方式获得.
{'k1': 'v1', 'k3': 'v3', 'k2': 'v2'}
>>> d.get('list_test')
[1, 2, 3, 4]
>>> d.get('tuple_test')
('x', 'y', 'sb')
总结: shelve模块是想把多个数据序列化保存到同一个文件时,使用这个模块.但要求,都是python环境.
并且通过shelve模块序列化又叫做持久化列表,可以反复调用,不像pickle load一次后就不能再load了
六、shutil
高级的 文件、文件夹、压缩包 处理模块
shutil模块:
shutil模块可以进行一些文件\文件夹的拷贝\压缩\删除
shutil.copyfileobj(fsrc,fdst[,length]) 这里的fsrc和fdst不是文件名,而是已经打开了的文件对象
比如 a = open('1.txt','r') b = open('2.txt','w')
这个就是在 python 中拷贝文件的方法.记住参数是文件对象. shutil.copyfile(src,dst) #内部拷贝的时候还是调用copyfileobj()
这个就是拷贝文件了.如果src不存在报错,如果是特殊文件也报错. shutil.copymode(src,dst) 仅拷贝权限.内容\组\用户均不变
从源码中查看到,先获取源文件权限再调用os.chmod()改权限
shutil.copystat(src,dst) 拷贝文件的状态信息. shutil.copy拷贝文件和权限,前面shutil.copyfiles()只拷贝文件
shutil.copy2 拷贝文件和状态信息.
shutil.ignore_patterns(*patterns)
shutil.copytree()递归去拷贝文件
shutil.move递归的去移动目录
shutil.rmtree()递归删除目录
shutil.make_archive(base_name,format,...) 创建一个压缩包,参数介绍
:format 压缩包种类,'zip','tar','bztar','gztar'
:base_name文件名类似name.tar.gz
:root_idr 要压缩的文件夹路径(默认是当前目录)
:owner 用户,默认当前用户
:group 组,默认当前组
:logger 用于记录日志,通常是logging.Logger对象
使用实例:
>>> shutil.make_archive('/Users/tedzhou/www','gztar',root_dir = '/Users/tedzhou/test')
'/Users/tedzhou/www.tar.gz' #再这个目录下生成了一个压缩包为www.tar.gz
#我们以后会经常的通过python写一些备份,就涉及到压缩,如果没有这个模块,就得通过os.system()用shell了,这样又low了
如果不用shutil,我们能不能完成压缩呢?可以,使用zipfile模块,只是麻烦些: zipfile模块
import zipfile
压缩
z = zipfile.ZipFile('lianxi.zip','w')
z.write('a.log')
z.write('data.data')
z.close()
解压
z = zipfile.ZipFile('lianxi.zip','r')
z.extractall()
z.close()
tarfile模块 # 压缩
tar = tarfile.open('your.tar','w')
tar.add('lianxi.zip',src)
更多猛击这里
七、ConfigParser
用于对特定的配置进行操作,当前模块的名称在 python 3.x 版本中变更为 configparser。
八、logging
用于便捷记录日志且线程安全的模块
logging模块
简介:做日志的.很多程序都有记录日志的需求,并且日志中包含的信息即有正常的程序访问日志,还可能又错误\调试\正常\警告\错误等不同级别的日志.
如果你的日志同时打印到屏幕上又写到文件里又写到数据库里.另外,日志得格式,是不是也得标准化.比如不用这个模块你就得分开处理.
python得logging模块就题哦那个了标准得日志接口.你可以通过它存储各种格式得日志,logging得日志可以分为debug(),info(),warning(),error()和critical() 5个级别.下面我们看一下怎么用.
级别说明:
debug 调试信息非常详细
info 正常得
warning 警告
error 错误
critical 非常严重得
使用说明:
默认格式举例: (默认是打印到屏幕上)
我们举例下warning(),critical()级别得日志.
>>> import logging
>>> logging.warning('user [ted] attempted wrong password more than 3 times ')
WARNING:root:user [ted] attempted wrong password more than 3 times >>> logging.critical("server is down")
CRITICAL:root:server is down
#我们可以看得到会打印出: 级别:用户:日志信息 (这里得用户是当前python文件所属得用户) 将日志写入文件举例:
>>> import logging
>>> logging.basicConfig(filename='test.log',level = logging.INFO)
>>> logging.debug("This message is denug's")
>>> logging.info("this message is info's")
>>> logging.warning("this message is warning's")
WARNING:root:this message is warning's 我们看到logging.basicConfig()里设置了两个参数filename 和 level ,filename指定了日志保存得文件名,可以是绝对路径得名称,
level参数设置得是logging.INFO,这个设置得意思记录 info级别以及info以上级别的日志会记录在文件里.如果想要debug级别的就把level参数改成logging.DEBUG
于是我们可以查看下我们的指定的日志文件里的内容:
$ more test.log
INFO:root:this message is info's
WARNING:root:this message is warning's
可以看到日志已经记录. 给写入文件的日志添加时间字段:
>>> logging.basicConfig(filename='test.log',level = logging.INFO)
上面已经实现了将日志写入文件,但是是不是没有日志生成的时间,一般日志都会有时间字段,不然日志就没有意义了.
你不会说 我在生成日志信息的时候就把时间加上,不是不行,既然logging能够帮你把日志信息加上时间,干嘛还要自己加.
如何添加时间字段,举例如下:
>>> import logging
>>> logging.basicConfig(format='%(asctime)s %(message)s',datefmt='%m/%d/%Y %I:%M%S %p')
#format参数就指定了我们通过 "时间" "日志信息"的方式记录.datefmt设置了时间的格式.
%(sactime)s 指时间,这里只能这么写,我们可以想想成 "%s"%sactime 这里sactime是变量,只是logging模块把这种写法封装成%(sactime)s的写法了.
%(message)s 同样理解成 "%s"%message 添加时间举例:
>>> import logging
>>> logging.basicConfig(format='%(asctime)s %(message)s',datefmt='%m/%d/%Y %I:%M:%S %p')
>>> logging.warning('is hwn')
05/12/2016 01:58:19 PM is hwn 把日志同时打印在屏幕和写入到日志:
要想实现打印到屏幕的同时写入文件,需要了解下logging模块的知识了.
logging模块功能是由4个分类logger,handlers,filters,and formatters 功能模块共同组成了logging模块.
logger 负责对外暴露它的接口,供其他程序调用,并生成日志
handlers 把log日志发送给合适的目标,比如文件,屏幕,数据库
filters 过滤,用的比较少
formatters 输出格式的设置 了解了上面的4个分类功能,我们接下来用4个分类功能来实现将日志同时打印到屏幕和文件中的需求:
#使用logger分类功能创建生成日志的对象.
>>> import logging
>>> logger = logging.getLogger('TEST-LOG')
>>> logger.setLevel(logging.DEBUG) 指定level
#创造一个handler对象,这个对象负责屏幕输出
>>> ch = logging.StreamHandler()
>>> ch.setLevel(logging.DEBUG) 这里又指定了level #创建一个handler对象,负责将日志输出到文件
>>> fh = logging.FileHandler('access.log')
>>> fh.setLevel(logging.WARNING) 这里又指定了level #创建格式,设置日志的格式
>>> formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') 接下来把这个格式应用到 负责屏幕输出的对象和负责文件输出的对象
>>> ch.setFormatter(formatter)
>>> fh.setFormatter(formatter) 最终,把我创建的两个输出handler应用到logger对象,告诉它你生成的日志,用这两个handler进行输出
>>> logger.addHandler(ch)
>>> logger.addHandler(fh) 下面我们就可以调用这个logger处理日志了
>>> logger.debug('debug message')
2016-05-12 14:43:22,075 - TEST-LOG - DEBUG - debug message
>>> logger.info('info message')
2016-05-12 14:43:43,932 - TEST-LOG - INFO - info message
>>> logger.warn('warn message')
2016-05-12 14:43:54,444 - TEST-LOG - WARNING - warn message
>>> logger.error('error message')
2016-05-12 14:44:09,090 - TEST-LOG - ERROR - error message
>>> logger.critical('critical message')
2016-05-12 14:44:28,119 - TEST-LOG - CRITICAL - critical message
#这里的TEST-LOG是创建logger时定义的logger = logging.getLogger('TEST-LOG')
#同时说明了 logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')中的 %(name)s 参数指的是logger的名字. 这时我们可以查看下fh中指定的文件中的内容:
$ more access.log
2016-05-12 14:43:54,444 - TEST-LOG - WARNING - warn message
2016-05-12 14:44:09,090 - TEST-LOG - ERROR - error message
2016-05-12 14:44:28,119 - TEST-LOG - CRITICAL - critical message
#因为fh我们指定的level是warning级别,所以只有三条日志
但是我们 前面一共设置了3个level级别,一个logger和两个handler都设置了level级别.那么他们的优先级是怎样的.
这里我们要注意:一般我们都认为 本地的要比全局的优先级高,但这里logger里设置的优先级为全局的level,它是最高的.(这里是错误的结论)
后期验证不是全局优先级高,而是哪个level级别高( Debug < INFO < WARNING < ERROR < CRITICAL ),就用哪个!
>>> import logging
>>> logger1 = logging.getLogger('Test-log')
>>> logger1.setLevel(logging.ERROR)
>>> ch = logging.StreamHandler()
>>> ch.setLevel(logging.INFO)
>>> formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
>>> ch.setFormatter(formatter)
>>> logger1.addHandler(ch)
>>> logger1.warning('')
>>> logger1.error('')
2016-05-13 23:43:49,559 - Test-log - ERROR - 111
>>>
至此日志logging模块我们就暂时讲完了.
对于格式,有如下属性可是配置:

九、time
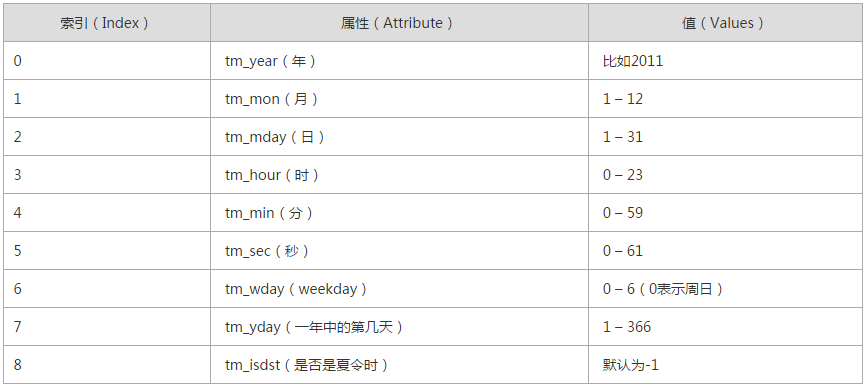
时间相关的操作,时间有三种表示方式:
三种表达方式
1.时间戳
import time
print time.time()
执行结果
1453443231.22
老师:在你处理nginx日志时,想截取1小时内的日志,将nginx日志里的时间戳转换成这种方式计算比较简单。
当然也可以用正则表达式,但是经验告诉你,使用time()方法将比正则表达式检索要简单得多,并且效率也高的多。 2. 元组形式 也称结构化的形式
print time.gmtime() 3.格式化字符串形式
print time.strftime('%Y-%m-%d %H:%M:%S’) import time
time.time() #得到当前时间的时间戳格式
1453445139.2
time.ctime() #得到当前时间的字符串格式。默认以系统定义的格式输出
>>> time.ctime(1352234223) #如果后面加参数,是将时间戳格式转换成系统格式
'Wed Nov 7 04:37:03 2012’
同样可以用时间戳减去86640就可以得到昨天的时间。比如:
print(time.ctime(time.time() - 86400))
Fri May 6 23:05:02 2016 print(time.gmtime()) #得到当前格林威治时间的数组形式也称struct_time格式如下:
time.struct_time(tm_year=2016, tm_mon=5, tm_mday=7, tm_hour=15, tm_min=6, tm_sec=31, tm_wday=5, tm_yday=128, tm_isdst=0)
好处是可以通过可命名元组访问的方式来访问你想要的值比如:
>>> a = time.gmtime()
>>> a.tm_year
2016
>>> a.tm_mon
5 time.localtime() #同time.gmtime,区别是time.gmtime得到格林威治时间的time.localtime得到本地时间:
time.struct_time(tm_year=2016, tm_mon=5, tm_mday=7, tm_hour=23, tm_min=11, tm_sec=8, tm_wday=5, tm_yday=128, tm_isdst=0) time.localtime和time.gmtime得到的时间格式统称为struct_time格式。
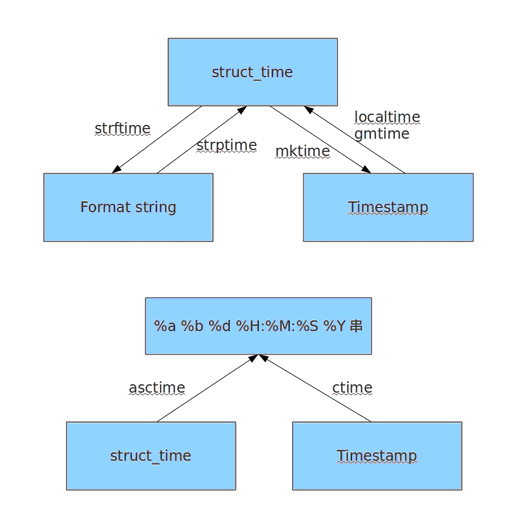
这两个函数都是将时间戳转换成struct_time格式。那么怎么将struct_time转换成时间戳呢。
time.mktime()可以将struct_time格式转换成为时间戳,如下:
>>> time.mktime(time.gmtime())
1462605454.0 time.strftime('%Y-%m-%d %H:%M:%S’) #得到当前时间的指定字符串格式,和time.ctime相比,此函数可以指定格式,time.ctime()获得系统默认格式。
>>> time.strftime( '%Y-%m-%d %H:%M:%S')
'2016-05-07 23:25:46’
后面可以跟一个struct_time作为参数,此函数可以将struct_time格式转换成字符串格式,如下:
>>> time.strftime('%Y-%m-%d %H:%M:%S',time.localtime())
'2016-05-07 23:39:02'
那么struct_time格式可以转换成字符串格式,有没有将字符串格式转换成struct_time格式的方法呢,有time.strptime函数!如下:
>>> a= time.strftime('%Y-%m-%d %H:%M:%S',time.localtime())
>>>time.strptime(a,'%Y-%m-%d %H:%M:%S') time.struct_time(tm_year=2016, tm_mon=5, tm_mday=7, tm_hour=23, tm_min=40, tm_sec=46, tm_wday=5, tm_yday=128, tm_isdst=-1) 三种形式相互转换方法:
首先我们知道通过time模块,我们可以获得3种格式的时间:
1.时间戳格式 这种格式常用来做时间间隔
2.struct_time格式(即数组格式,访问时也可以像可命名数组一样访问。)这种格式常用来做筛选。
3.字符串格式,这种格式常用来记录日志
其次我们要知道,3种格式互相转化要通过struct_time作为桥梁。
比如:
时间戳转成struct_time可以用
time.localtime(time.time())
时间戳转成字符串,1.先转换成struct_time在转换成字符串格式
a = time.localtime(time.time())
time.strftime('%Y-%m-%d %H:%M:%S’,a) 同理将字符串转换成时间戳,也是先转换成struct_time,在转换成时间戳
>>> b = time.strptime(a,'%Y-%m-%d %H:%M:%S’)
>>> time.mktime(b)
1462635646.0
十、re
re模块用于对python的正则表达式的操作。
字符:
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或下划线或汉字
\s 匹配任意的空白符
\d 匹配数字
\b 匹配单词的开始或结束
^ 匹配字符串的开始
$ 匹配字符串的结束
次数:
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
IP:
^(25[0-5]|2[0-4]\d|[0-1]?\d?\d)(\.(25[0-5]|2[0-4]\d|[0-1]?\d?\d)){3}$
手机号:
^1[3|4|5|8][0-9]\d{8}$
1、match(pattern, string, flags=0)
从起始位置开始根据模型去字符串中匹配指定内容,匹配单个
- 正则表达式
- 要匹配的字符串
- 标志位,用于控制正则表达式的匹配方式
import re
obj = re.match('\d+', '123uuasf')
if obj:
print obj.group()
2、search(pattern, string, flags=0)
根据模型去字符串中匹配指定内容,匹配单个
import re
obj = re.search('\d+', 'u123uu888asf')
if obj:
print obj.group()
3、group和groups

a = "123abc456"
print re.search("([0-9]*)([a-z]*)([0-9]*)", a).group() print re.search("([0-9]*)([a-z]*)([0-9]*)", a).group(0)
print re.search("([0-9]*)([a-z]*)([0-9]*)", a).group(1)
print re.search("([0-9]*)([a-z]*)([0-9]*)", a).group(2) print re.search("([0-9]*)([a-z]*)([0-9]*)", a).groups()
4、findall(pattern, string, flags=0)
上述两中方式均用于匹配单值,即:只能匹配字符串中的一个,如果想要匹配到字符串中所有符合条件的元素,则需要使用 findall。
import re
obj = re.findall('\d+', 'fa123uu888asf')
print obj
5、sub(pattern, repl, string, count=0, flags=0)
用于替换匹配的字符串
content = "123abc456"
new_content = re.sub('\d+', 'sb', content)
# new_content = re.sub('\d+', 'sb', content, 1)
print new_content
相比于str.replace功能更加强大
6、split(pattern, string, maxsplit=0, flags=0)
根据指定匹配进行分组
content = "'1 - 2 * ((60-30+1*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2) )'"
new_content = re.split('\*', content)
# new_content = re.split('\*', content, 1)
print new_content
content = "'1 - 2 * ((60-30+1*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2) )'"
new_content = re.split('[\+\-\*\/]+', content)
# new_content = re.split('\*', content, 1)
print new_content
inpp = '1-2*((60-30 +(-40-5)*(9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2))'
inpp = re.sub('\s*','',inpp)
new_content = re.split('\(([\+\-\*\/]?\d+[\+\-\*\/]?\d+){1}\)', inpp, 1)
print new_content
相比于str.split更加强大
实例:计算器源码
十一、random
随机数
|
1
2
3
4
|
mport randomprint random.random()print random.randint(1,2)print random.randrange(1,10) |
随机验证码实例:
|
1
2
3
4
5
6
7
8
9
10
|
import randomcheckcode = ''for i in range(4): current = random.randrange(0,4) if current != i: temp = chr(random.randint(65,90)) else: temp = random.randint(0,9) checkcode += str(temp)print checkcode |
python 2.0 s12 day5 常用模块介绍的更多相关文章
- python基础31[常用模块介绍]
python基础31[常用模块介绍] python除了关键字(keywords)和内置的类型和函数(builtins),更多的功能是通过libraries(即modules)来提供的. 常用的li ...
- 学习Python必须要知道的常用模块
在程序设计中,为完成某一功能所需的一段程序或子程序:或指能由编译程序.装配程序等处理的独立程序单位:或指大型软件系统的一部分.本文为你介绍了Python中的两种常用模块. os: 这个模块包含普遍的操 ...
- Ansible常用模块介绍及使用(week5_day1_part2)--技术流ken
Ansible模块 在上一篇博客<Ansible基础认识及安装使用详解(一)--技术流ken>中以及简单的介绍了一下ansible的模块.ansible是基于模块工作的,所以我们必须掌握几 ...
- Ansible常用模块介绍及使用(2)
Ansible模块 在上一篇博客<Ansible基础认识及安装使用详解(一)–技术流ken>中以及简单的介绍了一下ansible的模块.ansible是基于模块工作的,所以我们必须掌握几个 ...
- Python 之路 Day5 - 常用模块学习
本节大纲: 模块介绍 time &datetime模块 random os sys shutil json & picle shelve xml处理 yaml处理 configpars ...
- [Python Day5] 常用模块
目录: 1.模块介绍 2.time & datetime 3.random 4.OS 5.sys 6.shutil 7.json & pickle 8.shelve 9.xml 处理 ...
- Python之路,Day5 - 常用模块学习 (转载Alex)
本节大纲: 模块介绍 time &datetime模块 random os sys shutil json & picle shelve xml处理 yaml处理 configpars ...
- python 之路 day5 - 常用模块
模块介绍 time &datetime模块 random os sys shutil json & picle shelve xml处理 yaml处理 configparser has ...
- Python学习-day5 常用模块
day5主要是各种常用模块的学习 time &datetime模块 random os sys shutil json & picle shelve xml处理 yaml处理 conf ...
随机推荐
- C#集合概述
C#集合概述 2016-11-29 集合 顺序排列 连顺存储 直接访问方式 访问时间 操作时间 备注 Dictionary 是 Key Key:O(1) O(1) 访问性能最快,不支持排序 Sorte ...
- SOCKET编程需要注意的问题
1.socket编程首先要做的就是加载库,有两种方法: 1.不需要加载库文件 if(!AfxSocketInit()) { AfxMessageBox("加载套接字库失败!"); ...
- Python中的相对文件路径的调用
先让我们来看看一个用到相对文件路径的函数调用的问题.假设现在有两个脚本文件main.py和func.py,他们的路径关系是: . |--dir1 |--main.py |--dir2 |--func. ...
- java 日期获取时间戳
SimpleDateFormat df = new SimpleDateFormat("yyyy/MM/dd hh:mm:ss"); String dateS ...
- 基于jQuery带进度条全屏图片轮播代码
基于jQuery带进度条全屏图片轮播代码.这是一款基于jQuery实现的oppo手机官网首页带进度条全屏图片轮播特效.效果图如下: 在线预览 源码下载 实现的代码. html代码: <div ...
- nginx 405 not allowed问题的解决
转载自: http://www.linuxidc.com/Linux/2012-07/66761.htm Apache.IIS.Nginx等绝大多数web服务器,都不允许静态文件响应POST请求,否 ...
- 【WPF】XAML引入资源和在C#代码中动态添加样式
转载自: http://blog.csdn.net/honantic/article/details/48781543 XAML引入资源参考这里: http://blog.csdn.net/qq_18 ...
- Tomcat配置 设置启动参数,点击startup.bat启动
catalina.batrem ---------------------------------------------------------------------------rem Set J ...
- MySQL做为手动开启事务用法
START TRANSACTION;INSERT INTO `t1` (t, t1) VALUES('124', NOW());ROLLBACK;COMMIT;
- dubbo 常见错误 通配符的匹配很全面, 但无法找到元素 'dubbo:application' java.lang.reflect.MalformedParameterizedTypeException 通配符的匹配很全面, 但无法找到元素 'dubbo:application' 的声明。 Unsupported major.minor version 52.0 (unable to l
dubbo 常见错误 1. Caused by: java.lang.reflect.MalformedParameterizedTypeException 启动时报错,原因是dubbo 依赖 spr ...