Python菜鸟之路:Django 路由、模板、Model(ORM)
Django路由系统
Django的路由系统让Django可以根据URI进行匹配,进而发送至特定的函数去处理用户请求。有点类似nginx的location功能。
Django的路由关系分为三种:普通关系、动态关系、分组分发。这三种关系都记录在urls.py中。
路由-普通关系
普通关系表示一个url对应一个函数,例如:
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^login/', views.login),
url(r'^detail/', views.detail),
]
路由-动态关系
动态关系表示通过正则的方式去实现动态匹配。例如:
urlpatterns = [
url(r'^detail/(\d+)/', views.detail), # 动态路由之:单参数的路由
url(r'^detail2/(\d+)/', views.detail2), # 动态路由之:多参数的路由
url(r'^detail3/(?P<p1>\d+)/(?P<x2>\d+)/', views.detail3), # 动态路由之:命名参数,两个参数分别被命名为p1和x2
url(r'^index/(\d+)/', views.index), # 分页显示
]
动态路由,也是动态关系的一种,动态路由其实通过映射也可以实现,需要自己来实现
主要代码实现
1、url.py
配置url映射
2、activator.py
根据url中获取的参数,通过反射调用指定 app/view.py 中的函数 如: http://127.0.0.1:9000/app01/index/ ==》 执行app01/view.py文件中的index函数
http://127.0.0.1:9000/app02/index/ ==》 执行app02/view.py文件中的index函数
http://127.0.0.1:9000/app01/login/ ==》 执行app01/view.py文件中的login函数 # 具体代码:
# 总入口urls.py
from django.conf.urls import include, url
from django.contrib import admin
from DynamicRouter.activator import process urlpatterns = [
# Examples:
# url(r'^$', 'DynamicRouter.views.home', name='home'),
# url(r'^blog/', include('blog.urls')), url(r'^admin/', include(admin.site.urls)), ('^(?P<app>(\w+))/(?P<function>(\w+))/(?P<page>(\d+))/(?P<id>(\d+))/$',process),
('^(?P<app>(\w+))/(?P<function>(\w+))/(?P<id>(\d+))/$',process),
('^(?P<app>(\w+))/(?P<function>(\w+))/$',process),
('^(?P<app>(\w+))/$',process,{'function':'index'}),
] # activator.py代码
from django.shortcuts import render_to_response,HttpResponse,redirect def process(request,**kwargs):
'''接收所有匹配url的请求,根据请求url中的参数,通过反射动态指定view中的方法''' app = kwargs.get('app',None)
function = kwargs.get('function',None) try:
appObj = __import__("%s.views" %app)
viewObj = getattr(appObj, 'views')
funcObj = getattr(viewObj, function) #执行view.py中的函数,并获取其返回值
result = funcObj(request,kwargs) except (ImportError,AttributeError) as e:
#导入失败时,自定义404错误
return HttpResponse('404 Not Found')
except Exception as e:
#代码执行异常时,自动跳转到指定页面
return redirect('/app01/index/') return result
通过映射实现动态路由
路由-分组分发
什么是分组分发?一个Django项目里,通常会有很多的app,比如一些bbs论坛为例,他的项目里就有前端部分,供普通用户使用,这类url通常写作http://hostname/common/form.php 。 也有后端admin管理员部分,用来进行用户管理、帖子管理等功能。这类url通常有个特别,一般是http://hostname/admin/XXX。可以明显看到,这个论坛项目中,就有2个分组:common和admin。Django中也有这样的功能。
Django分组写法:
步骤1:导入include函数
from django.conf.urls import include
步骤2:创建url映射
urlpatterns = [
...
url(r'^common/', include("frontweb.urls")), # 多app项目的分组匹配
url(r'^admin/', include("manager.urls")), # 多app项目的分组匹配
]
上面代码中,定义了2个app,一个是frontweb,一个是manager。
步骤3:在app中创建对应的url
# manager\urls.py中 代码
from manager import views urlpatterns = [
url(r'^assets', views.assets),
url(r'^userinfo', views.userinfo),
] # frontweb\urls.py中 代码
from frontweb import views urlpatterns = [
url(r'^index/(\d+)/', views.index),
url(r'^detail/(\d+)/', views.detail),
url(r'^userinfo', views.userinfo),
]
模板
模版的创建过程,对于模版,其实就是读取模版(其中嵌套着模版标签),然后将 Model 中获取的数据插入到模版中,最后将信息返回给用户。
模板的语法
1. 传普通字符串
# python中
return render(request, 'index.html', {'k1': 'v1'})
# html中引用k1的值
{{ k1 }}
2. 传入列表
# python中
return render(request, 'index.html', {'k2': [11,22,33,44]}) # html中引用k1的值
{{ k2 }} <!-- 取整个列表 -->
{{ k2.0 }} <!-- 取索引0的位置元素的值 -->
{{ k2.1 }} <!-- 取索引1的位置元素的值 -->
{{ k2.2 }} <!-- 取索引2的位置元素的值 -->
3. 传入字典
# python中
return render(request, 'index.html', {'k3': {'name': 'Bob', 'nid': 18}}) # html中引用k1的值
{{ k3 }} <!-- 取整个字典 -->
{{ k3.name }} <!-- 取键值为name的位置元素的值 -->
{{ k3.nid}} <!-- 取键值为age的位置元素的值 -->
4. 模板中的for循环,还是以上边的传入列表k2为例
{% for item in k2 %}
<p>
{{ item }},
{{ forloop.counter }}, <!--循环至第几个元素,从索引+1 开始 -->
{{ forloop.counter0 }}, <!--循环至第几个元素,从索引0 开始-->
{{ forloop.first }}, <!--判断是否是第一个元素 -->
{{ forloop.last }}, <!-- 判断是否是最后一个元素-->
{{ forloop.revcounter }} <!-- 倒叙显示是第几个元素 -->
</p>
{% endfor %}
5. 模板中的if循环,以上边传入的k1为例
{% if k1 == 'v1' %}
<h1>V1</h1>
{% elif k1 == 'v2' %}
<h1>V2</h1>
{% else %}
<h1>777777</h1>
{% endif %}
6. 模板中的继承语法
母板:{% block title %}{% endblock %}
子板:{% extends "base.html" %}
{% block title %}{% endblock %}
7. 模板内置的一些方法(可以理解为函数,而模板中的变量就是传入的值)
{{ item.event_start|date:"Y-m-d H:i:s"}}
{{ bio|truncatewords:"30" }}
{{ my_list|first|upper }}
{{ name|lower }}
8. 自定义模板方法
自定义模板方法,有两种方式,一种是filter,另外一种是simple_tag
8.1 filter
步骤1:创建指定文件夹,名称必须为templatetags,文件夹放在对应的app目录下。
步骤2:创建任意的py文件,比如xx.py
from django import template
from django.utils.safestring import mark_safe
from django.template.base import Variable, Node, TemplateSyntaxError register = template.Library()
#要点1: template.Library的返回值的变量,必须是register,不能是其他 #要点2:函数必须加装饰器register.filter,这样f1就是模板语言中的一个函数
@register.filter
def f1(value):
# 接收单个参数
return value + 'f111' @register.filter
def f2(value, value2):
# 接收两个参数
return value + value2
步骤3:使用函数,在html模板的头部,执行{% load xx %},xx表示创建的py文件的文件名
{% load xx %}
步骤4:使用函数
# html中代码
{{ k1|f1 }} {# filter自定义方法之:1个参数 #}
# 输出 v1f111 # 其中v1是k1本身的值,f111是函数后加的字符串
# html中代码
{{ k1|f2:'F2:XXX' }} <br /> {# filter自定义方法之:2个参数 #}
{% if k1|f1 == 'v1f111' %}
<h1>filter可以用作if语句的条件</h1>
{% endif %}
最终输出: v1F2:XXX 其中v1是k1的值, F2:XXX是前端传入的变量
Ps:从上边可以看出,filter方法构建的函数,默认不支持传入超过2个以上的参数,因此,如果需要传入多个参数,可以将"F2:XXX"写成 "F2:XXX,arg3,arg4",在python代码中,用split来拆分字符串,来获取参数。
限制:传参个数有限制,多个参数需要自行split进行切割
支持:可以作为模板中if语句的if条件
步骤5:注册app。最后一步非常重要,否则django会不知道去哪个路径下查找xx.py。
# 在settings.py中注册app
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app01', # 新注册的app目录名称
]
8.2 用simple_tag 来自定义模板方法
创建simple_tag的步骤基本一致,唯独不同的有2个地方
不同点1: 函数的装饰器需要写为register.simple_tag
@register.simple_tag
def f3(value):
return value + 'f3333' @register.simple_tag
def f4(value, arg1, arg2):
return value + arg1 + arg2
不同点2:前端html传参的时候
# html中的代码
{% f3 'simple_tag' %}<br /> {# simple_tag自定义方法之:1个参数 #}
{% f4 'simple_tag' 'arg2' 'arg3' %}<br /> {# simple_tag自定义方法之:多个参数 #} # 输出
simple_tagf3333
simple_tagarg2arg3
Ps:用simple_tag来创建函数,不支持作为if语句中的条件
模板的渲染过程
看一张图就明白,

模板继承
母版页面
母版页面通常用来定义网页的基本框架结构,同时空出部分内容块来供子页面来自定义式的填充
# 母版的代码
{% block css %}{% endblock %} # 空出名为css的代码块部分,供子版来填充
{% block body %}{% endblock %} # 同上,只是名称不同而已
{% block js %}{% endblock %} #同上,只是名称不同而已
完整代码示例如下图:
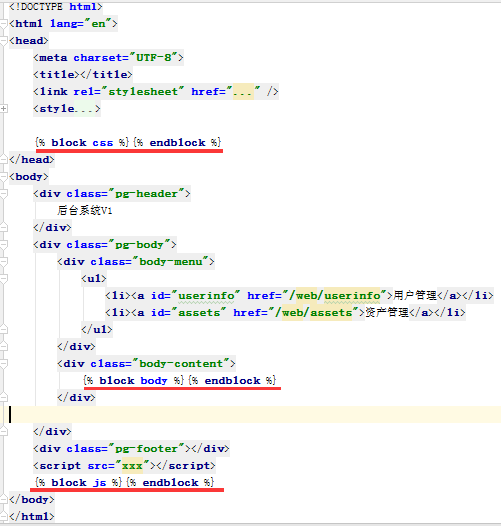
子页面
{% extends 'layout.html' %} # 表示继承layoout.html母版页面
{% block css %} #自定义样式
<style>
...
</style>
{% endblock %}
{% block body %} # 填充html内容
<table>
{% for item in assets_list %}
<tr>
<td>{{ item.hostname }}</td>
<td>{{ item.port }}</td>
</tr>
{% endfor %}
</table>
{% endblock %}
{% block js %} # 自定义js
<script>
...
</script>
{% endblock %}
重复利用的小插件
一般情况下,在页面中,会有一些元素是相似度很高的,或许只有装饰文件不同而已。比如京东首页中,家电数码、个性美妆、手机通讯等部分。通常的做法是把这些相似的部分,做成类似小插件一样的html代码,在使用的时候引用即可。
{% include "xx.html" %}
Django中的Model
在Django的model中,提供了两类操作,一种是创建数据库表(CURD),一种是操作数据库的数据
Django数据库表间的三种关系
Django的数据库表中,有三种关系:一对一,一对多,多对多。
假设有两张表userinfo和user_type 。
class userinfo(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=30, verbose_name='用户名',editable=TabError)
email = models.EmailField(db_index=True)
memo = models.TextField() # 普通用户,超级用户
class UserType(models.Model):
name = models.CharField(max_length=32) def __str__(self):
return self.name
一对一
即 user_type = OneToOneField("另外一张表")
这种情况下,每次创建一条userinfo数据,就需要userType表中一条数据与之对应。即,usertype表中的数据,只能被对应一次。
一对多
即 user_type = models.ForeignKey("UserType")
这是很常见的一种对应关系。比如一个usertype有两种用户,超级用户和普通用户,那么在这两种用户组中,可以分别存在很多人。
多对多
即 user_type = models.ManyToManyField("UserType")。
比如,一个user可以属于多个usergroup,一个usergroup可以包含多个user,这就是典型的多对多关系。
创建数据库表
步骤1:在app的models.py中写类,来创建表的每个字段
1、models.AutoField 自增列 = int(11)
如果没有的话,默认会生成一个名称为 id 的列,如果要显示的自定义一个自增列,必须将给列设置为主键 primary_key=True。
2、models.CharField 字符串字段
必须 max_length 参数
3、models.BooleanField 布尔类型=tinyint(1)
不能为空,Blank=True
4、models.ComaSeparatedIntegerField 用逗号分割的数字=varchar
继承CharField,所以必须 max_lenght 参数
5、models.DateField 日期类型 date
对于参数,auto_now = True 则每次更新都会更新这个时间;auto_now_add 则只是第一次创建添加,之后的更新不再改变。
6、models.DateTimeField 日期类型 datetime
同DateField的参数
7、models.Decimal 十进制小数类型 = decimal
必须指定整数位max_digits和小数位decimal_places
8、models.EmailField 字符串类型(正则表达式邮箱) =varchar
对字符串进行正则表达式
9、models.FloatField 浮点类型 = double
10、models.IntegerField 整形
11、models.BigIntegerField 长整形
integer_field_ranges = {
'SmallIntegerField': (-32768, 32767),
'IntegerField': (-2147483648, 2147483647),
'BigIntegerField': (-9223372036854775808, 9223372036854775807),
'PositiveSmallIntegerField': (0, 32767),
'PositiveIntegerField': (0, 2147483647),
}
12、models.IPAddressField 字符串类型(ip4正则表达式,在1.10的django版本中,可能会被替换掉,统一使用models.GenericIPAddressField)
13、models.GenericIPAddressField 字符串类型(ip4和ip6是可选的)
参数protocol可以是:both、ipv4、ipv6
验证时,会根据设置报错
14、models.NullBooleanField 允许为空的布尔类型
15、models.PositiveIntegerFiel 正Integer
16、models.PositiveSmallIntegerField 正smallInteger
17、models.SlugField 减号、下划线、字母、数字
18、models.SmallIntegerField 数字
数据库中的字段有:tinyint、smallint、int、bigint
19、models.TextField 字符串=longtext
20、models.TimeField 时间 HH:MM[:ss[.uuuuuu]]
21、models.URLField 字符串,地址正则表达式
22、models.BinaryField 二进制
23、models.ImageField 图片(以字符串形式保存,存储文件路径)
24、models.FilePathField 文件(以字符串形式保存,存储文件路径)
models中的字段类型
1、null=True
数据库中字段是否可以为空
2、blank=True
django的 Admin 中添加数据时是否可允许空值
3、primary_key = False
主键,对AutoField设置主键后,就会代替原来的自增 id 列
4、auto_now 和 auto_now_add
auto_now 自动创建---无论添加或修改,都是当前操作的时间
auto_now_add 自动创建---永远是创建时的时间
5、choices
GENDER_CHOICE = (
(u'M', u'Male'),
(u'F', u'Female'),
)
gender = models.CharField(max_length=2,choices = GENDER_CHOICE)
6、max_length
7、default 默认值
8、verbose_name Admin中字段的显示名称
9、name|db_column 数据库中的字段名称
10、unique=True 不允许重复
11、db_index = True 数据库索引
12、editable=True 在Admin里是否可编辑
13、error_messages=None 错误提示
14、auto_created=False 自动创建
15、help_text 在Admin中提示帮助信息
16、validators=[]
17、upload-to
models中字段类型的可选参数
步骤2:执行python manager.py makemigrations && python manager.py migrate初始化数据库结构
操作数据库表-基本操作
基本数据访问
运行python manage.py shell并使用Django提供的高级Python API
# 导入student模型类,通过这个类我们可以与student数据表进行交互
>>> from app01.models import UserType
# 创建一个student类的实例并设置了字段name的值
>>> data_1 = UserType(name='外围人员')
# 调用该对象的save()方法,将对象保存到数据库中,Django会在后台执行一条INSERT语句
>>> s1.save() # 再插入一条数据
>>> data_2 = UserType(name='核心人员')
>>> data_2 .save()
# 使用UserType.objects属性从数据库取出UserType表的记录集,这个属性有许多方法,UserType.objects.all()方法获取数据库中UserType类的所有对象,实际上Django执行了一条SQL SELECT语句
>>> usertype_list = UserType.objects.all()
>>> usertype_list
Out[6]: <QuerySet [<UserType: 普通用户>, <UserType: 超级用户>, <UserType: 外围人员>]>
在代码中进行数据访问基本操作
增
方法1:
models.Tb1.objects.create(c1='xx', c2='oo') 增加一条数据,可以接受字典类型数据 **kwargs
方法2:
obj = models.Tb1(c1='xx', c2='oo')
obj.save()
删
models.Tb1.objects.filter(name='seven').delete() # 删除指定条件的数据
改
方法1:
models.Tb1.objects.filter(name='seven').update(gender='0') # 将指定条件的数据更新,均支持 **kwargs 方法2:
obj = models.Tb1.objects.get(id=1)
obj.c1 = '111'
obj.save() # 修改单条数据
查
models.Tb1.objects.get(id=123) # 获取单条数据,不存在则报错(不建议)
models.Tb1.objects.all() # 获取全部
models.Tb1.objects.filter(name='seven') # 获取指定条件的数据 obj = model.UserInfo.objects.filter(name='alex').values('id','email')
#sql: select id,email from userinfo where name = 'alex'
# 结果是个字典:[{'id':1 , 'email':'xxq@qq.com'}, {'id':2 , 'email':'qqqq@qq.com'},...] obj = model.UserInfo.objects.filter(name='alex').value_list('id','email')
#sql: select id,email from userinfo where name = 'alex'
#结果是个元祖 [('1', 'xxq@qq.com'), ('2', 'qqq@qq.com'), (),....]
说明
执行models.Tb1.objects.all()等查询的结果,是一个queryset对象,而queryset是Django中定义的一个类
操作数据库单表-进阶操作
# 获取个数
#
# models.Tb1.objects.filter(name='seven').count() # 大于,小于---gt lt语句
#
# models.Tb1.objects.filter(id__gt=1) # 获取id大于1的值
# models.Tb1.objects.filter(id__lt=10) # 获取id小于10的值
# models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值 # in
#
# models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据
# models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in # contains---like语句
#
# models.Tb1.objects.filter(name__contains="ven") # contains就是like
# models.Tb1.objects.filter(name__icontains="ven") # icontains 表示对大小写不敏感
# models.Tb1.objects.exclude(name__icontains="ven") # range ---between and语句
#
# models.Tb1.objects.filter(id__range=[1, 2]) # 范围bettwen and # 其他类似
#
# startswith,istartswith, endswith, iendswith, # order by
#
# models.Tb1.objects.filter(name='seven').order_by('id') # asc
# models.Tb1.objects.filter(name='seven').order_by('-id') # desc 加上负号表示倒序 # limit 、offset
#
# models.Tb1.objects.all()[10:20] # 分页获取 # group by
from django.db.models import Count, Min, Max, Sum
# models.Tb1.objects.filter(c1=1).values('id').annotate(c=Count('num')) # 这里的value表示要根据id 进行groupby, 获取num列的个数
# SELECT "app01_tb1"."id", COUNT("app01_tb1"."num") AS "c" FROM "app01_tb1" WHERE "app01_tb1"."c1" = 1 GROUP BY "app01_tb1"."id"
单表进阶操作-了不起的双下划线
操作数据库连表-进阶操作
双下划线的主要功能:1)大于小于等操作,参照上面的单表进阶操作 2)跨表操作
数据库结构说明:
class UserProfile(models.Model):
user_info = models.OneToOneField('UserInfo')
username = models.CharField(max_length=64)
password = models.CharField(max_length=64) def __unicode__(self):
return self.username class UserInfo(models.Model):
user_type_choice = (
(0, u'普通用户'),
(1, u'高级用户'),
)
user_type = models.IntegerField(choices=user_type_choice)
name = models.CharField(max_length=32)
email = models.CharField(max_length=32)
address = models.CharField(max_length=128) def __unicode__(self):
return self.name class UserGroup(models.Model): caption = models.CharField(max_length=64) user_info = models.ManyToManyField('UserInfo') def __unicode__(self):
return self.caption class Host(models.Model):
hostname = models.CharField(max_length=64)
ip = models.GenericIPAddressField()
user_group = models.ForeignKey('UserGroup') def __unicode__(self):
return self.hostname
数据库表结构
操作数据库联表-双下划线跨表查询
两种表的联表查询案例
#表结构
class UserInfo(models.Model):
user = models.CharField(max_length=32)
pwd = models.CharField(max_length=32) class UserInfo(models.Model):
user = models.CharField(max_length=32)
pwd = models.CharField(max_length=32)
user_type = models.ForignKey('UserType') # 创建UserInfo
1、UserInfo.objects.create(user='alex',pwd='',user_type=UserType.objects.get(id=2)) # 这种方法不推荐,实际查询了2次
2、 UserInfo.objects.create(user='alex',pwd='',user_type_id=2) #推荐这种方法!!!这种是进阶用法 # 普通查询:
UserInfo.objects.filter(user='alex')
1、查询所有用户类型等于 普通用户 的所有用户名和密码(普通查询方法)
uid = UserType.objects.get(caption='普通用户').id # uid是一个对象
UserInfo.objects.filter(user_type_id=uid) # 进阶跨表查询方法及取值方法
querset = UserInfo.objects.filter(user_type__caption='普通用户')
querset = UserInfo.objects.filter(user_type__id__gt=2)
【UserInfo对象,UserInfo对象,UserInfo对象,】
row = querset[0]
row.user
row.pwd
row.user_type.id
row.user_type.caption
#在进行models.object.xxx查询时,使用: objects __
#获取到某一样的对象后使用: row.外键字段.外键表的字段 # 使用values和value_list跨表查询方法及取值
querset = UserInfo.objects.filter(user_type__caption='普通用户').values('user','user_type__caption')
【{'user': 'alex','user_type__caption': '普通用户'},{'user': 'eric','user_type__caption': '普通用户'},】 结果是一个字典对象形成的列表
# 取出单值
row = querset[0]
row['user']
row['user_type__caption']
2张表的联表创建及查询
三张表跨表操作
class Somthing(models.Model):
name = models.CharField(max_length=32) class UserType(models.Model):
catption = models.CharField(max_length=32)
s = models.ForignKey('Somthing') # 超级管理员,普通用户,游客,黑河 class UserInfo(models.Model): user = models.CharField(max_length=32)
pwd = models.CharField(max_length=32)
user_type = models.ForignKey('UserType') # 通过Userinfo表,查询Something表中name是xx
UserInfo.objects.filter(user_type__s__name='xx')
# 多个下滑连通过外键__ 则可以
3张表的联表查询
Model中的多对多操作补充
Django中创建多对多关系有两种方式:
方式1:手动创建第三张表,与其他两张表建立外键关系
class B2G(models.Model):
b_id = models.ForeignKey('Boy')
g_id = models.ForeignKey('Girl') class Boy(models.Model):
username = models.CharField(max_length=16) def __str__(self):
return str(self.id) class Girl(models.Model):
name = models.CharField(max_length=16) def __str__(self):
return str(self.id)
方式2:利用models.ManyToManyField来让django自动创建第三张表
class Boy(models.Model):
username = models.CharField(max_length=16) def __str__(self):
return str(self.id) class Girl(models.Model):
name = models.CharField(max_length=16)
b = models.ManyToManyField('Boy')
def __str__(self):
return str(self.id)
多对多基本操作
建立两张表的关系:即向第三张表中增加数据-获取两个对象,通过add方法建立关系
########### 增加数据 ###########
# 获取一个女孩对象
g1 = models.Girl.objects.get(id=1) # 获取一个男孩对象
b1 = models.Boy.objects.get(id=1) # 利用多对多字段“b”将男孩和女孩建立关系--一对一建立关系
g1.b.add(models.Boy.objects.get(id=1))
g1.b.add(1) # 也可以传入数字或者 数字列表*【1,2,3】 # 添加和女孩1和 男孩1,2,3,4关联--一对多建立关系
g1 = models.Girl.objects.get(id=1)
g1.b.add(*[1,2,3,4]) # 将多个boy与女孩1建立关联
# boys = models.Boy.objects.all()
# g1.b.add(*boys)
查询数据
# 获取一个女孩对象
g1 = models.Girl.objects.get(id=1) # 获取和当前女孩有关系的所有男孩
boy_list = g1.b.all()
print(boy_list)
删除数据
# 删除第三张表中和女孩1关联的所有关联信息
g1 = models.Girl.objects.get(id=1)
g1.b.clear()
# 删除女孩1和男孩2,3的关联
g1 = models.Girl.objects.get(id=1)
g1.b.remove(*[2,3])
特别补充——反向添加:由于manytomany的存在,在Boy表中,还有一个隐含字段girl_set,他的作用与Gril中的b字段是一样的功能。
b1 = models.Boy.objects.get(id=1)
b1.girl_set.add(1)
b1.girl_set.add(models.Girl.objects.all())
b1.girl_set.add(*[1,2,3,4])
多对多跨表操作
首先要明白一点,通过第三张表进行跨表操作,是通过left outer join的形式进行查询的,on的条件就是A表的id与B表的id相等。
# 两张表关联查询
models.Girl.objects.all().values('id','name', 'b')
# 查询 第三张表b的 girl.id==b.id的 b.boy_id列
SQL:
SELECT "app01_girl"."id", "app01_girl"."name", "app01_girl_b"."boy_id" FROM "app01_girl" LEFT OUTER JOIN "app01_girl_b" ON ("app01_girl"."id" = "app01_girl_b"."girl_id") # 三张表关联查询-跨表查询
models.Girl.objects.all().values('id','name', 'b__username') SQL:
SELECT "app01_girl"."id", "app01_girl"."name", "app01_boy"."username" FROM "app01_girl" LEFT OUTER JOIN "app01_girl_b" ON ("app01_girl"."id" = "app01_girl_b"."girl_id") LEFT OUTER JOIN "app01_boy" ON ("app01_girl_
b"."boy_id" = "app01_boy"."id")
r = models.Boy.objects.exclude(girl__name=None).values('id','username', 'girl__name')
print(r)
print(r.query)
#SELECT "app01_boy"."id", "app01_boy"."username", "app01_girl"."name" FROM "app01_boy" LEFT OUTER JOIN "app01_girl_b" ON ("app01_boy"."id" = "app01_girl_b"."boy_id") LEFT OUTER JOIN "app01_girl" ON ("app01_girl_b".
#"girl_id" = "app01_girl"."id") WHERE NOT ("app01_boy"."id" IN (SELECT U0."id" AS Col1 FROM "app01_boy" U0 LEFT OUTER JOIN "app01_girl_b" U1 ON (U0."id" = U1."boy_id") LEFT OUTER JOIN "app01_girl" U2 ON (U1."girl_i
#d" = U2."id") WHERE U2."name" IS NULL))
原生SQL操作-更新
在Django的SQL ORM框架中,对于更新操作的支持并不好,因此需要借助原生的sql语句来完成更新操作
from django.db import connection
cursor = connection.cursor()
cursor.execute("""SELECT * from tb where name = %s""", ['Lennon'])
row = cursor.fetchone()
Python菜鸟之路:Django 路由、模板、Model(ORM)的更多相关文章
- Python菜鸟之路:Django 路由补充1:FBV和CBV - 补充2:url默认参数
一.FBV和CBV 在Python菜鸟之路:Django 路由.模板.Model(ORM)一节中,已经介绍了几种路由的写法及对应关系,那种写法可以称之为FBV: function base view ...
- Python菜鸟之路:Django Admin后台管理功能使用
前言 用过Django框架的童鞋肯定都知道,在创建完Django项目后,每个app下,都会有一个urls.py文件,里边会有如下几行: from django.contrib import admin ...
- Python菜鸟之路:Django 信号
Django中提供了“信号调度”,用于在框架执行操作时解耦.通俗来讲,就是一些动作发生的时候,信号允许特定的发送者去提醒一些接受者. 相当于我们创建了一个hook. 1. Django的内置信号 Mo ...
- Python菜鸟之路:Django 中间件
前言 在正式说Django中间件之前需要先了解Django一个完整的request的处理流程.我从其他网站扒了几张图过来. 图片一: 文字流程说明:如图所示,一个 HTTP 请求,首先被转化成一个 H ...
- Python菜鸟之路:Django ModelForm的使用
一.简单使用案例 #views.py #views.py from django.shortcuts import render,HttpResponse from app01 import mode ...
- Python菜鸟之路:Django 数据验证之钩子和Form表单验证
一.钩子功能提供的数据验证 对于数据验证,django会执行 full_clean()方法进行验证.full_clean验证会经历几个步骤,首先,对于model的每个字段进行正则验证,正则验证通过后, ...
- Python菜鸟之路:Django 分页
Django的分页没有多少需要说的,有一点需要关注,在自定制分页功能的时候,需要通过python代码来生成每一页的a标签链接,这个时候需要关注一点:默认情况下,为了安全考虑,防范XSS攻击,Djang ...
- Python菜鸟之路:Django 缓存
Django中提供了6种缓存方式: 开发调试 内存 文件 数据库 Memcache缓存(python-memcached模块) Memcache缓存(pylibmc模块) 1. 开发调试 # 此为开始 ...
- Python菜鸟之路:Django 数据库操作进阶F和Q操作
Model中的F F 的操作通常的应用场景在于:公司对于每个员工,都涨500的工资.这个时候F就可以作为查询条件 from django.db.models import F models.UserI ...
随机推荐
- VS2010/MFC编程入门之二十八(常用控件:列表视图控件List Control 上)
前面一节中,鸡啄米讲了图片控件Picture Control,本节为大家详解列表视图控件List Control的使用. 列表视图控件简介 列表视图控件List Control同样比较常见, ...
- 20145336张子扬 《网络对抗》逆向及bof基础
20145336张子扬 <网络对抗>逆向及bof基础 学习知识点 缓冲区溢出 缓冲区溢出 一种非常普遍.非常危险的漏洞,在各种操作系统.应用软件中广泛存在.利用缓冲区溢出攻击,可以导致程序 ...
- FromBottomToTop第十三周项目博客
FromBottomToTop第十三周项目博客 本周项目计划 完成游戏核心算法以及界面相关类和怪物类 项目进展 用户可选择游戏模式,共有20张不同的地图. 炮台的建立和升级. 小怪的路径算法. 参考资 ...
- Javaworkers团队第四周项目总结
本周项目进展 本周是我们的项目开发的第四周,在之前的一周,我们小组在合作的情况下基本完成了项目代码的框架编写,我们组的项目课题,小游戏--贪吃蛇以及可以运行,可以进行简单的游戏,但是我们在思考之后发现 ...
- 利用ES6中的Array.find/ Array.findIndex来判断数组中已存在某个对象
前端开发过程中,我们会经常遇到这样的情景:比如选中某个指标obj,将其加入到数组checkedArr中({id: 1234, name: 'zzz', ...}),但是在将其选中之前要校验该指标是否已 ...
- Today's harvest !!!
今天将Mybatis的视频看到了第60集,其之前讲解了自表的主外键查询.例如一个新闻表中,有一级栏目,二级栏目,三级栏目,其中二级栏目的pid为一级栏目的id,如此种种. 而今天做的小项目中使用了 e ...
- HDU 1166 敌兵布阵(线段树 or 二叉索引树)
http://acm.hdu.edu.cn/showproblem.php?pid=1166 题意:第一行一个整数T,表示有T组数据. 每组数据第一行一个正整数N(N<=50000),表示敌人有 ...
- hdu 3792 Twin Prime Conjecture 前缀和+欧拉打表
Twin Prime Conjecture Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Ot ...
- python 输出环境变量
import os # Access all environment variables print('*---------------ENVIRON-------------------*') pr ...
- js的数组与对象关系
有的时候总犯糊涂,不理解对象和数组的关系,转载一篇文章,深刻记忆一下 http://hi.baidu.com/samdan/item/05179313d1ee4b9e99ce3371 比如有一个数组a ...