一次完整的HTTP事务是怎样一个过程
当我们在浏览器的地址栏输入 www.linux178.com,然后回车,回车这一瞬间到看到页面到底发生了什么呢?
以下过程仅是个人理解:
域名解析 --> 发起TCP的3次握手 --> 建立TCP连接后发起http请求 --> 服务器响应http请求,浏览器得到html代码 --> 浏览器解析html代码,并请求html代码中的资源(如js、css、图片等) --> 浏览器对页面进行渲染呈现给用户
关于HTTP协议可以参考以下:
HTTP协议漫谈 http://kb.cnblogs.com/page/140611/
HTTP协议概览 http://www.cnblogs.com/vamei/archive/2013/05/11/3069788.html
了解HTTP Headers的方方面面 http://kb.cnblogs.com/page/55442/
以下就是上面过程的一一分析,我们就以Chrome浏览器为例:
1.域名解析
首先Chrome浏览器会解析 www.linux178.com 这个域名(准确的叫法应该是主机名)对应的IP地址。怎么解析到对应的IP地址?
① Chrome浏览器 会首先搜索浏览器自身的DNS缓存(缓存时间比较短,大概只有1分钟,且只能容纳1000条缓存),看自身的缓存中是否有www.linux178.com 对应的条目,而且没有过期,如果有且没有过期则解析到此结束。
注:我们怎么查看Chrome自身的缓存?可以使用 chrome://net-internals/#dns 来进行查看
② 如果浏览器自身的缓存里面没有找到对应的条目,那么Chrome会搜索操作系统自身的DNS缓存,如果找到且没有过期则停止搜索解析到此结束.
注:怎么查看操作系统自身的DNS缓存,以Windows系统为例,可以在命令行下使用 ipconfig /displaydns 来进行查看
③ 如果在Windows系统的DNS缓存也没有找到,那么尝试读取hosts文件(位于C:\Windows\System32\drivers\etc),看看这里面有没有该域名对应的IP地址,如果有则解析成功。
④ 如果在hosts文件中也没有找到对应的条目,浏览器就会发起一个DNS的系统调用,就会向本地配置的首选DNS服务器(一般是电信运营商提供的,也可以使用像Google提供的DNS服务器)发起域名解析请求(通过的是UDP协议向DNS的53端口发起请求,这个请求是递归的请求,也就是运营商的DNS服务器必须得提供给我们该域名的IP地址),运营商的DNS服务器首先查找自身的缓存,找到对应的条目,且没有过期,则解析成功。如果没有找到对应的条目,则有运营商的DNS代我们的浏览器发起迭代DNS解析请求,它首先是会找根域的DNS的IP地址(这个DNS服务器都内置13台根域的DNS的IP地址),找打根域的DNS地址,就会向其发起请求(请问www.linux178.com这个域名的IP地址是多少啊?),根域发现这是一个顶级域com域的一个域名,于是就告诉运营商的DNS我不知道这个域名的IP地址,但是我知道com域的IP地址,你去找它去,于是运营商的DNS就得到了com域的IP地址,又向com域的IP地址发起了请求(请问www.linux178.com这个域名的IP地址是多少?),com域这台服务器告诉运营商的DNS我不知道www.linux178.com这个域名的IP地址,但是我知道linux178.com这个域的DNS地址,你去找它去,于是运营商的DNS又向linux178.com这个域名的DNS地址(这个一般就是由域名注册商提供的,像万网,新网等)发起请求(请问www.linux178.com这个域名的IP地址是多少?),这个时候linux178.com域的DNS服务器一查,诶,果真在我这里,于是就把找到的结果发送给运营商的DNS服务器,这个时候运营商的DNS服务器就拿到了www.linux178.com这个域名对应的IP地址,并返回给Windows系统内核,内核又把结果返回给浏览器,终于浏览器拿到了www.linux178.com 对应的IP地址,该进行一步的动作了。
注:一般情况下是不会进行以下步骤的
如果经过以上的4个步骤,还没有解析成功,那么会进行如下步骤(以下是针对Windows操作系统):
⑤ 操作系统就会查找NetBIOS name Cache(NetBIOS名称缓存,就存在客户端电脑中的),那这个缓存有什么东西呢?凡是最近一段时间内和我成功通讯的计算机的计算机名和Ip地址,就都会存在这个缓存里面。什么情况下该步能解析成功呢?就是该名称正好是几分钟前和我成功通信过,那么这一步就可以成功解析。
⑥ 如果第⑤步也没有成功,那会查询WINS 服务器(是NETBIOS名称和IP地址对应的服务器)
⑦ 如果第⑥步也没有查询成功,那么客户端就要进行广播查找
⑧ 如果第⑦步也没有成功,那么客户端就读取LMHOSTS文件(和HOSTS文件同一个目录下,写法也一样)
如果第八步还没有解析成功,那么就宣告这次解析失败,那就无法跟目标计算机进行通信。只要这八步中有一步可以解析成功,那就可以成功和目标计算机进行通信。
看下图抓包截图:
Linux虚拟机测试,使用命令 wget www.linux178.com 来请求,发现直接使用chrome浏览器请求时,干扰请求比较多,所以就使用wget命令来请求,不过使用wget命令只能把index.html请求回来,并不会对index.html中包含的静态资源(js、css等文件)进行请求。

抓包分析:
① 号包,这个是那台虚拟机在广播,要获取192.168.100.254(也就是网关)的MAC地址,因为局域网的通信靠的是MAC地址,它为什么需要跟网关进行通信是因为我们的DNS服务器IP是外围IP,要出去必须要依靠网关帮我们出去才行。
② 号包,这个是网关收到了虚拟机的广播之后,回应给虚拟机的回应,告诉虚拟机自己的MAC地址,于是客户端找到了路由出口。
③ 号包,这个包是wget命令向系统配置的DNS服务器提出域名解析请求(准确的说应该是wget发起了一个DNS解析的系统调用),请求的域名www.linux178.com,期望得到的是IP6的地址(AAAA代表的是IPv6地址)
④ 号包,这个DNS服务器给系统的响应,很显然目前使用IPv6的还是极少数,所以得不到AAAA记录的
⑤ 号包,这个还是请求解析IPv6地址,但是www.linux178.com.leo.com这个主机名是不存在的,所以得到结果就是no such name
⑥ 号包,这个才是请求的域名对应的IPv4地址(A记录)
⑦ 号包,DNS服务器不管是从缓存里面,还是进行迭代查询最终得到了域名的IP地址,响应给了系统,系统再给了wget命令,wget于是得到了www.linux178.com的IP地址,这里也可以看出客户端和本地的DNS服务器是递归的查询(也就是服务器必须给客户端一个结果)这就可以开始下一步了,进行TCP的三次握手。
2.发起TCP的3次握手
拿到域名对应的IP地址之后,User-Agent(一般是指浏览器)会以一个随机端口(1024 < 端口 < 65535)向服务器的WEB程序(常用的有httpd,nginx等)80端口发起TCP的连接请求。这个连接请求(原始的http请求经过TCP/IP4层模型的层层封包)到达服务器端后(这中间通过各种路由设备,局域网内除外),进入到网卡,然后是进入到内核的TCP/IP协议栈(用于识别该连接请求,解封包,一层一层的剥开),还有可能要经过Netfilter防火墙(属于内核的模块)的过滤,最终到达WEB程序(本文就以Nginx为例),最终建立了TCP/IP的连接。
如下图:

1) Client首先发送一个连接试探,ACK=0 表示确认号无效,SYN = 1 表示这是一个连接请求或连接接受报文,同时表示这个数据报不能携带数据,seq = x 表示Client自己的初始序号(seq = 0 就代表这是第0号包),这时候Client进入syn_sent状态,表示客户端等待服务器的回复
2) Server监听到连接请求报文后,如同意建立连接,则向Client发送确认。TCP报文首部中的SYN 和 ACK都置1 ,ack = x + 1表示期望收到对方下一个报文段的第一个数据字节序号是x+1,同时表明x为止的所有数据都已正确收到(ack=1其实是ack=0+1,也就是期望客户端的第1个包),seq = y 表示Server 自己的初始序号(seq=0就代表这是服务器这边发出的第0号包)。这时服务器进入syn_rcvd,表示服务器已经收到Client的连接请求,等待client的确认。
3) Client收到确认后还需再次发送确认,同时携带要发送给Server的数据。ACK 置1 表示确认号ack= y + 1 有效(代表期望收到服务器的第1个包),Client自己的序号seq= x + 1(表示这就是我的第1个包,相对于第0个包来说的),一旦收到Client的确认之后,这个TCP连接就进入Established状态,就可以发起http请求了。
看抓包截图:

⑨ 号包 这个就是对应上面的步骤 1)
⑩ 号包 这个对应的上面的步骤 2)
号包 这个对应的上面的步骤 3)
TCP 为什么需要3次握手?
举个例子:
假设一个老外在故宫里面迷路了,看到了小明,于是就有下面的对话:
老外: Excuse me,Can you Speak English?
小明: yes 。
老外: OK,I want ...
在问路之前,老外先问小明是否会说英语,小明回答是的,这时老外才开始问路
2个计算机通信是靠协议(目前流行的TCP/IP协议)来实现,如果2个计算机使用的协议不一样,那是不能进行通信的,所以这个3次握手就相当于试探一下对方是否遵循TCP/IP协议,协商完成后就可以进行通信了,当然这样理解不是那么准确。
为什么HTTP协议要基于TCP来实现?
目前在Internet中所有的传输都是通过TCP/IP进行的,HTTP协议作为TCP/IP模型中应用层的协议也不例外,TCP是一个端到端的可靠的面向连接的协议,所以HTTP基于传输层TCP协议不用担心数据的传输的各种问题。
3.建立TCP连接后发起http请求
进过TCP3次握手之后,浏览器发起了http的请求(看第包),使用的http的方法 GET 方法,请求的URL是 / ,协议是HTTP/1.0

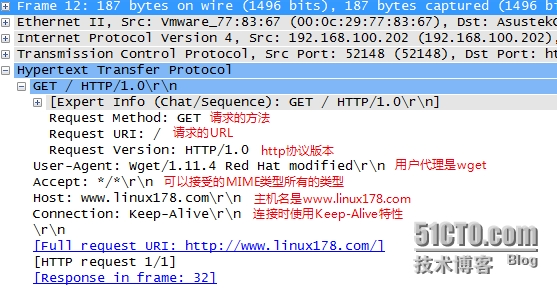
以上的报文是HTTP请求报文。
那么HTTP请求报文和响应报文会是什么格式呢?
起始行:如 GET / HTTP/1.0 (请求的方法 请求的URL 请求所使用的协议)
头部信息:User-Agent Host等成对出现的值
主体
不管是请求报文还是响应报文都会遵循以上的格式。
那么起始行中的请求方法有哪些种呢?
GET: 完整请求一个资源 (常用)
HEAD: 仅请求响应首部
POST:提交表单 (常用)
PUT: (webdav) 上传文件(但是浏览器不支持该方法)
DELETE:(webdav) 删除
OPTIONS:返回请求的资源所支持的方法的方法
TRACE: 追求一个资源请求中间所经过的代理(该方法不能由浏览器发出)
那什么是URL、URI、URN?
URI Uniform Resource Identifier 统一资源标识符
URL Uniform Resource Locator 统一资源定位符
格式如下: scheme://[username:password@]HOST:port/path/to/source
http://www.magedu.com/downloads/nginx-1.5.tar.gz
URN Uniform Resource Name 统一资源名称
URL和URN 都属于 URI
为了方便就把URL和URI暂时都通指一个东西
请求的协议有哪些种?
有以下几种:
http/0.9: stateless
http/1.0: MIME, keep-alive (保持连接), 缓存
http/1.1: 更多的请求方法,更精细的缓存控制,持久连接(persistent connection) 比较常用
下面是Chrome发起的http请求报文头部信息
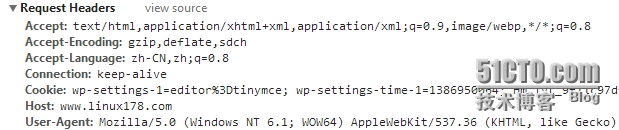
其中
Accept 就是告诉服务器端,我接受那些MIME类型
Accept-Encoding 这个看起来是接受那些压缩方式的文件
Accept-Lanague 告诉服务器能够发送哪些语言
Connection 告诉服务器支持keep-alive特性
Cookie 每次请求时都会携带上Cookie以方便服务器端识别是否是同一个客户端
Host 用来标识请求服务器上的那个虚拟主机,比如Nginx里面可以定义很多个虚拟主机
那这里就是用来标识要访问那个虚拟主机。
User-Agent 用户代理,一般情况是浏览器,也有其他类型,如:wget curl 搜索引擎的蜘蛛等
条件请求首部:
If-Modified-Since 是浏览器向服务器端询问某个资源文件如果自从什么时间修改过,那么重新发给我,这样就保证服务器端资源
文件更新时,浏览器再次去请求,而不是使用缓存中的文件
安全请求首部:
Authorization: 客户端提供给服务器的认证信息;
什么是MIME?
MIME(Multipurpose Internet Mail Extesions 多用途互联网邮件扩展)是一个互联网标准,它扩展了电子邮件标准,使其能够支持非ASCII字符、二进制格式附件等多种格式的邮件消息,这个标准被定义在RFC 2045、RFC 2046、RFC 2047、RFC 2048、RFC 2049等RFC中。 由RFC 822转变而来的RFC 2822,规定电子邮件标准并不允许在邮件消息中使用7位ASCII字符集以外的字符。正因如此,一些非英语字符消息和二进制文件,图像,声音等非文字消息都不能在电子邮件中传输。MIME规定了用于表示各种各样的数据类型的符号化方法。 此外,在万维网中使用的HTTP协议中也使用了MIME的框架,标准被扩展为互联网媒体类型。
MIME 遵循以下格式:major/minor 主类型/次类型 例如:
|
1
2
3
4
5
|
image/jpgimage/giftext/htmlvideo/quicktimeappliation/x-httpd-php |
4.服务器端响应http请求,浏览器得到html代码
看下图 第12号包是http请求包,第32包是http响应包
服务器端WEB程序接收到http请求以后,就开始处理该请求,处理之后就返回给浏览器html文件。
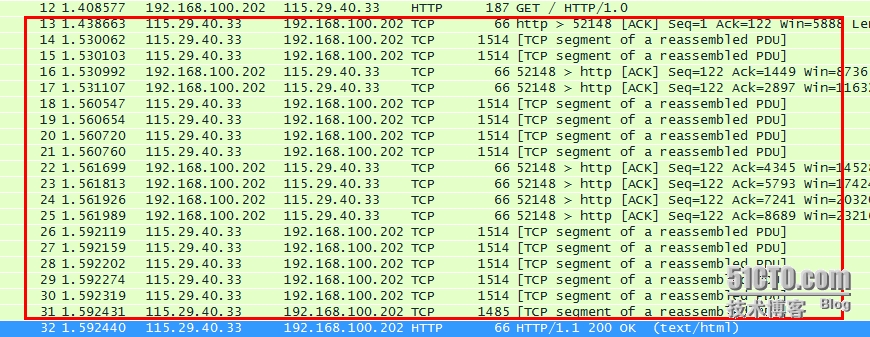
第32号包 是服务器返回给客户端http响应包(200 ok 响应的MIME类型是text/html),代表这一次客户端发起的http请求已成功响应。200 代表是的 响应成功的状态码,还有其他的状态码如下:
1xx: 信息性状态码
100, 101
2xx: 成功状态码
200:OK
3xx: 重定向状态码
301: 永久重定向, Location响应首部的值仍为当前URL,因此为隐藏重定向;
302: 临时重定向,显式重定向, Location响应首部的值为新的URL
304:Not Modified 未修改,比如本地缓存的资源文件和服务器上比较时,发现并没有修改,服务器返回一个304状态码,
告诉浏览器,你不用请求该资源,直接使用本地的资源即可。
4xx: 客户端错误状态码
404: Not Found 请求的URL资源并不存在
5xx: 服务器端错误状态码
500: Internal Server Error 服务器内部错误
502: Bad Gateway 前面代理服务器联系不到后端的服务器时出现
504:Gateway Timeout 这个是代理能联系到后端的服务器,但是后端的服务器在规定的时间内没有给代理服务器响应
用Chrome浏览器看到的响应头信息:

Connection 使用keep-alive特性
Content-Encoding 使用gzip方式对资源压缩
Content-type MIME类型为html类型,字符集是 UTF-8
Date 响应的日期
Server 使用的WEB服务器
Transfer-Encoding:chunked 分块传输编码 是http中的一种数据传输机制,允许HTTP由网页服务器发送给客户端应用(通常是网页浏览器)的数据可以分成多个部分,分块传输编码只在HTTP协议1.1版本(HTTP/1.1)中提供
Vary 这个可以参考(http://blog.csdn.NET/tenfyguo/article/details/5939000)
X-Pingback 参考(http://blog.sina.com.cn/s/blog_bb80041c0101fmfz.html)
那到底服务器端接收到http请求后是怎么样生成html文件?
假设服务器端使用nginx+PHP(fastcgi)架构提供服务
① nginx读取配置文件
我们在浏览器的地址栏里面输入的是 http://www.linux178.com (http://可以不用输入,浏览器会自动帮我们添加),其实完整的应该是http://www.linux178.com./ 后面还有个点(这个点代表就是根域,一般情况下我们不用输入,也不显示),后面的/也是不用添加,浏览器会自动帮我们添加(且看第3部那个图里面的URL),那么实际请求的URL是http://www.linux178.com/,那么好了Nginx在收到 浏览器 GET / 请求时,会读取http请求里面的头部信息,根据Host来匹配 自己的所有的虚拟主机的配置文件的server_name,看看有没有匹配的,有匹配那么就读取该虚拟主机的配置,发现如下配置:
|
1
|
root /web/echo |
通过这个就知道所有网页文件的就在这个目录下 这个目录就是/ 当我们http://www.linux178.com/时就是访问这个目录下面的文件,例如访问http://www.linux178.com/index.html,那么代表/web/echo下面有个文件叫index.html
|
1
|
index index.html index.htm index.php |
通过这个就能得知网站的首页文件是那个文件,也就是我们在入http://www.linux178.com/ ,nginx就会自动帮我们把index.html(假设首页是index.php 当然是会尝试的去找到该文件,如果没有找到该文件就依次往下找,如果这3个文件都没有找到,那么就抛出一个404错误)加到后面,那么添加之后的URL是/index.php,然后根据后面的配置进行处理
|
1
2
3
4
5
6
7
|
location ~ .*\.php(\/.*)*$ { root /web/echo; fastcgi_pass 127.0.0.1:9000; fastcgi_index index.php; astcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; include fastcgi_params;} |
这一段配置指明凡是请求的URL中匹配(这里是启用了正则表达式进行匹配) *.php后缀的(后面跟的参数)都交给后端的fastcgi进程进行处理。
② 把php文件交给fastcgi进程去处理
于是nginx把/index.php这个URL交给了后端的fastcgi进程处理,等待fastcgi处理完成后(结合数据库查询出数据,填充模板生成html文件)返回给nginx一个index.html文档,Nginx再把这个index.html返回给浏览器,于是乎浏览器就拿到了首页的html代码,同时nginx写一条访问日志到日志文件中去。
注1:nginx是怎么找index.php文件的?
当nginx发现需要/web/echo/index.php文件时,就会向内核发起IO系统调用(因为要跟硬件打交道,这里的硬件是指硬盘,通常需要靠内核来操作,而内核提供的这些功能是通过系统调用来实现的),告诉内核,我需要这个文件,内核从/开始找到web目录,再在web目录下找到echo目录,最后在echo目录下找到index.php文件,于是把这个index.php从硬盘上读取到内核自身的内存空间,然后再把这个文件复制到nginx进程所在的内存空间,于是乎nginx就得到了自己想要的文件了。
注2:寻找文件在文件系统层面是怎么操作的?
比如nginx需要得到/web/echo/index.php这个文件
每个分区(像ext3 ext3等文件系统,block块是文件存储的最小单元 默认是4096字节)都是包含元数据区和数据区,每一个文件在元数据区都有元数据条目(一般是128字节大小),每一个条目都有一个编号,我们称之为inode(index node 索引节点),这个inode里面包含 文件类型、权限、连接次数、属主和数组的ID、时间戳、这个文件占据了那些磁盘块也就是块的编号(block,每个文件可以占用多个block,并且block不一定是连续的,每个block是有编号的),如下图所示:

还有一个要点:目录其实也普通是文件,也需要占用磁盘块,目录不是一个容器。你看默认创建的目录就是4096字节,也就说只需要占用一个磁盘块,但这是不确定的。所以要找到目录也是需要到元数据区里面找到对应的条目,只有找到对应的inode就可找到目录所占用的磁盘块。
那到底目录里面存放着什么,难道不是文件或者其他目录吗?
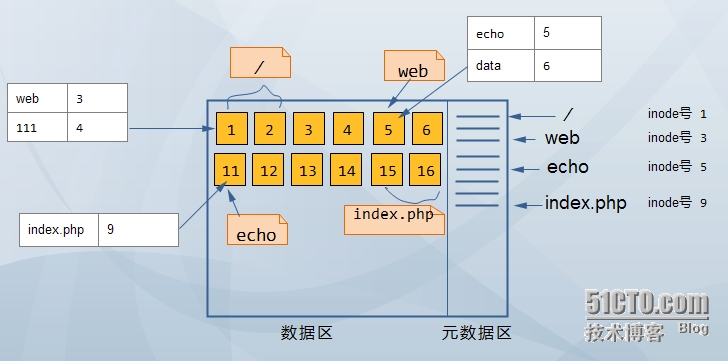
其实目录存着这么一张表(姑且这么理解),里面放着 目录或者文件的名称和对应的inode号(暂时称之为映射表),如下图:

假设
/ 在数据区占据 1、2号block ,/其实也是一个目录 里面有3个目录 web 111
web 占据 5号block 是目录 里面有2个目录 echo data
echo 占据 11号 block 是目录 里面有1个文件 index.php
index.php 占据 15 16号 block 是文件
其在文件系统中分布如下图所示
那么内核究竟是怎么找到index.php这个文件的呢?
内核拿到nginx的IO系统调用要获取/web/echo/index.php这个文件请求之后
① 内核读取元数据区 / 的inode,从inode里面读取/所对应的数据块的编号,然后在数据区找到其对应的块(1 2号块),读取1号块上的映射表找到web这个名称在元数据区对应的inode号
② 内核读取web对应的inode(3号),从中得知web在数据区对应的块是5号块,于是到数据区找到5号块,从中读取映射表,知道echo对应的inode是5号,于是到元数据区找到5号inode
③ 内核读取5号inode,得到echo在数据区对应的是11号块,于是到数据区读取11号块得到映射表,得到index.php对应的inode是9号
④ 内核到元数据区读取9号inode,得到index.php对应的是15和16号数据块,于是就到数据区域找到15 16号块,读取其中的内容,得到index.php的完整内容
5. 浏览器解析html代码,并请求html代码中的资源
浏览器拿到index.html文件后,就开始解析其中的html代码,遇到js/css/image等静态资源时,就向服务器端去请求下载(会使用多线程下载,每个浏览器的线程数不一样),这个时候就用上keep-alive特性了,建立一次HTTP连接,可以请求多个资源,下载资源的顺序就是按照代码里的顺序,但是由于每个资源大小不一样,而浏览器又多线程请求请求资源,所以从下图看出,这里显示的顺序并不一定是代码里面的顺序。
浏览器在请求静态资源时(在未过期的情况下),向服务器端发起一个http请求(询问自从上一次修改时间到现在有没有对资源进行修改),如果服务器端返回304状态码(告诉浏览器服务器端没有修改),那么浏览器会直接读取本地的该资源的缓存文件。

详细的浏览器工作原理请看:http://kb.cnblogs.com/page/129756/
6.浏览器对页面进行渲染呈现给用户
最后,浏览器利用自己内部的工作机制,把请求到的静态资源和html代码进行渲染,渲染之后呈现给用户。
自此一次完整的HTTP事务宣告完成.
本文出自 “雷纳科斯的博客” 博客,请务必保留此出处http://linux5588.blog.51cto.com/65280/1351007
一次完整的HTTP事务是怎样一个过程的更多相关文章
- 一次完整的HTTP事务是怎样一个过程?
一次完整的HTTP事务是怎样一个过程? 声明:本文章中的说法仅是个人理解总结,不一定完全正确,但是可以有助于理解. 关于HTTP协议可以参考以下: HTTP协议漫谈 http://kb.cnblog ...
- http--一次完整的HTTP事务是怎样一个过程?【转】
一次完整的HTTP事务是怎样一个过程? 如有收获请给作者点赞 --> 原文链接 声明:本文章中的说法仅是个人理解总结,不一定完全正确,但是可以有助于理解. 当我们在浏览器的地址栏输入 www.l ...
- 一次完整的HTTP事务是怎样一个过程?(转)
(转自http://www.linux178.com/web/httprequest.html)写的太好了,转一个. 关于HTTP协议可以参考以下: HTTP协议漫谈 http://kb.cnblog ...
- 一次完整的HTTP事务是怎样一个过程?(转)
HTTP协议 关于HTTP协议可以参考以下: HTTP协议漫谈 http://kb.cnblogs.com/page/140611/ HTTP协议概览 http://www.cnblogs.com/v ...
- 一次完整的http事务
一次完整的http事务 https://www.processon.com/view/link/56c6679ce4b0f0c4285e69c0 规范把 HTTP 请求分为三个部分:状态行.请求头.消 ...
- 一次完整的HTTP事务的过程、从输入URL到网页展示,浏览器都经历了什么?
详细介绍:老生常谈-从输入url到页面展示到底发生了什么 (1)一次完整的HTTP事务的过程 基本流程: a. 域名解析 b. 发起TCP的3次握手 c. 建立TCP连接后发起http请求 d. 服务 ...
- 完整的一次 HTTP 请求响应过程(二)
上篇文章 我们完整的描述了计算机五层模型中的『应用层』和『运输层』,阐述了较为复杂的 TCP 协议的相关原理,相信大家一定也有所收获,那么本篇将继续五层模型的学习. 网络层 『网络层』其实解决的就是一 ...
- 不作伪分享者决定完整分享我自学Python3的全部过程细节
不作伪分享者决定完整分享我自学Python3的全部过程细节 我不要作伪分享者 十六年前我第一次见到了电脑,并深深地爱上了它: 十二年前我第一次连上了网络,并紧紧地被它爱上. 十年前的网络是田园美景 ...
- 一次完整的http事务的过程
1.域名解析 2.发起TCP三次握手 3.建立TCP连接以后发起http请求 4.服务器端响应请求,浏览器得到html代码 5.浏览器解析html代码并请求html中的资源 6.浏览器对页面进行渲染呈 ...
随机推荐
- vector容器建图
#pragma comment(linker, "/STACK:1024000000,1024000000") #include"stdio.h" #inclu ...
- 借助HTML5 Blob实现文本信息文件下载
原理其实很简单,我们可以将文本或者JS字符串信息借助Blob转换成二进制,然后,作为<a>元素的href属性,配合download属性,实现下载. 代码也比较简单,如下示意(兼容Chrom ...
- 焦作网络赛K-Transport Ship【dp】
There are NN different kinds of transport ships on the port. The i^{th}ith kind of ship can carry th ...
- Pycharm一直报ImportError: No module named requests
1.首先检查是否安装了requests l 安装命令:pip install requests如果出现了Requirement already satisfied 代表安装成功 2.系统含有多个版本的 ...
- Sum It Up---poj1564(dfs)
题目链接:http://poj.org/problem?id=1564 给出m个数,求出和为n的组合方式:并按从大到小的顺序输出: 简单的dfs但是看了代码才会: #include <cstdi ...
- vue.js(三)
这里该记到vue的组件了,组件基础篇 1.vue组件的基本书写方式 Vue.component('button-counter', { data: function () { return { cou ...
- 用tsunami-udp加速网络传输
概述 tsunami-udp是一款专为网络加速诞生的小工具. 思路很简单,使用TCP进行传输控制.UDP进行数据传输. 这样可以无状态的进行数据传输,然后中间加一些文件校验和重传机制,达到加速传输的目 ...
- python之threading.local
简述: threading.local是全局变量但是它的值却在当前调用它的线程当中 作用: 在threading module中,有一个非常特别的类local.一旦在主线程实例化了一个local,它会 ...
- Hadoop NameNode 高可用 (High Availability) 实现解析
转载自:http://reb12345reb.iteye.com/blog/2306818 在 Hadoop 的整个生态系统中,HDFS NameNode 处于核心地位,NameNode 的可用性直接 ...
- springboot的相关信息
Maven的配置:zzp_settings.xml <?xml version="1.0" encoding="UTF-8"?> <setti ...