【热更新IK词典】ElasticSearch IK 自动热更新原理与实现
一、热更新原理
elasticsearch开启加载外部词典功功能后,会每60s间隔进行刷新字典。具体原理代码如下所示:
public void loadDic(HttpServletRequest req,HttpServletResponse response){
String eTag =req.getParameter("If-None-Match");
try {
OutputStream out= response.getOutputStream();
List<String> list=new ArrayList<String>();
list.add("中华人民共和国");
list.add("我爱你爱我");
String oldEtag = list.size() + "";
StringBuffer sb=new StringBuffer();
if (oldEtag != eTag) {
for (String str : list) {
if(StringUtils.isNotBlank(str)){
sb.append("\r\n");
}
sb.append(str+"\r\n");
}
}
String data=sb.toString();
response.setHeader("Last-Modified", String.valueOf(list.size()));
response.setHeader("ETag",String.valueOf(list.size()));
response.setContentType("text/plain; charset=gbk");
out.write(data.getBytes());
out.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
二、配置说明
我们公司以及用户常用的分词器为 IK 分词器,其中它有一个对应的核心配置文件名为:IKAnalyzer.cfg.xml,具体内容:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom/mydict.dic;custom/single_word_low_freq.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">custom/ext_stopword.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">location</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords">http://xxx.com/xxx.dic</entry>
</properties>
热更新 IK 分词使用方法,目前该插件支持热更新 IK 分词,通过上文在 IK 配置文件中提到的如下配置
<!--用户可以在这里配置远程扩展字典 --> <entry key="remote_ext_dict">location</entry> <!--用户可以在这里配置远程扩展停止词字典--> <entry key="remote_ext_stopwords">location</entry>
其中 location 是指一个 url,比如 http://yoursite.com/getCustomDict,该请求只需满足以下两点即可完成分词热更新。
该 http 请求需要返回两个头部(header)
1. 一个是 Last-Modified,
2. 一个是 ETag
这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。
该 http 请求返回的内容格式是一行一个分词,换行符用 \n 即可。
满足上面两点要求就可以实现热更新分词了,不需要重启 ES 实例。还需要注意的是获取词典的url,必须支持head访问
下面自己做的访问远程扩展词典的web api 服务接口(这一步可以直接忽略,看第三个即可,这里只是想说明也可以使用下面这种方式)
[HttpHead, HttpGet, HttpPost]
public async Task<HttpResponseMessage> GetDictionary(string path)
{
var response = this.Request.CreateResponse(HttpStatusCode.OK);
var content = File.ReadAllText(path);
response.Content = new StringContent(content, Encoding.UTF8);
response.Headers.Age = TimeSpan.FromHours(1);
response.Headers.ETag = EntityTagHeaderValue.Parse($"\"{content.ToMD5()}\"");
return response;
}
三、Tomcat 服务器自动更新
1、部署http服务
在这使用 tomcat8 作为 web 容器,先下载一个 tomcat8.5.16,然后上传到某一台服务器上(192.168.80.100)。
再执行以下命令
tar -zxvf apache-tomcat-8.5.16.tar.gz cd apache-tomcat-8.5.16/webapp/ROOT vim hot_ext.dic<br>智能移动机器人<br>vim hot_stopwords.dic<br>项目
之后验证一下这个文件是否可以正常访问 http://192.168.80.100:8080/hot.dic
通过tomcat访问词典,可以在不停用tomcat的情况下直接更新词典
2、修改ik插件的配置文件
修改 IK 核心配置文件 IKAnalyzer.cfg.xml 中的配置
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom/mydict.dic;custom/single_word_low_freq.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">custom/ext_stopword.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://192.168.80.100:8080/hot_ext.dic</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords">http://192.168.80.100:8080/hot_stopwords.dic</entry>
</properties>
3、验证
重启es,会看到如下日志信息,说明远程的词典加载成功了。
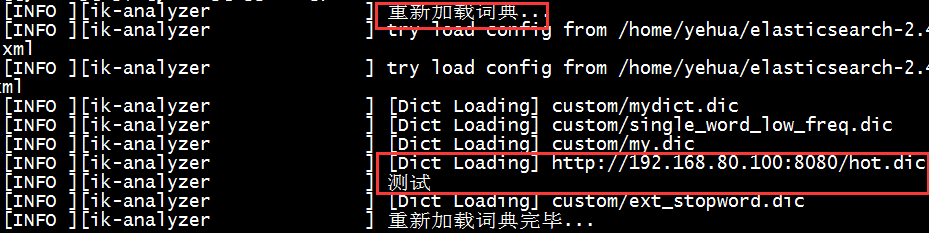
在浏览器中输入如下命令:http://localhost:9200/patent/_analyze?analyzer=ik_smart&text=智能移动机器人
正常情况下会分出很多次,这次发现只有这一个词,不会被分词,说明刚才配置远程的词库生效了,那么我们再换一个:北京雾霾,正常情况下可能会被分成两个词:北京、雾霾,如果我直接修改 tomcat 下的 hot_ext.dic 词库文件,增加一个关键词:北京雾霾,文件保存之后,查看es的日志会看到如下日志信息:
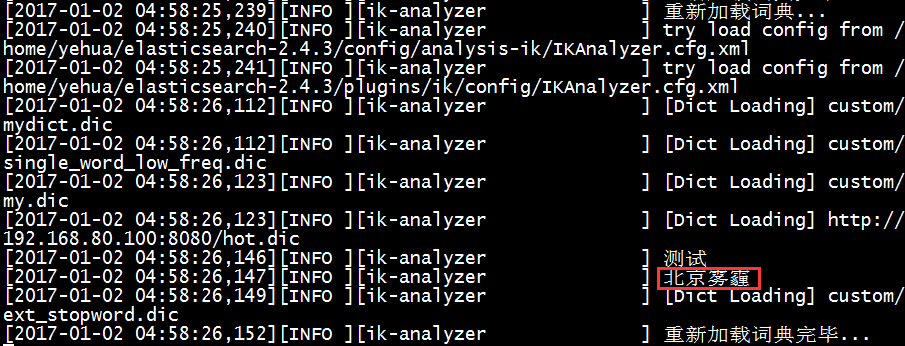
此时,再执行下面命令查看分词效果:http://localhost:9200/patent/_analyze?analyzer=ik_smart&text=北京雾霾
结果就是只有一个词,不会被分词了。
到这为止,可以实现动态添加自定义词库实现词库热更新。~~
代码实现
1.首先将di词典放在tomcat目录下
2.通过url读取配置文件
/**
* @Description 加载远程词典内容
* @param menuId 菜单id
* @param request http请求
* @return String 词典内容*/
@RequestMapping(value = "/loadDictionary", produces = "text/html;charset=UTF-8")
@ResponseBody
public String loadDictionary(Integer menuId, HttpServletRequest request) {
String filePath = getFilePath(request);
String context = readDictionary(filePath);
return context;
}
/**
* @Description 获取词典路径
* @param request HTTP请求
* @return String 词典路径*/
private String getFilePath(HttpServletRequest request) {
return "http://" + request.getServerName() + ":" + request.getServerPort() + "/" + "RemoteDictionary.dic";
}
/**
* @Description 读取远程词典
* @param filePath 词典路径
* @return String 词典内容*/
private String readDictionary(String filePath) {
StringBuffer document = new StringBuffer();
try {
URL url = new URL(filePath);
URLConnection conn = url.openConnection();
BufferedReader reader = new BufferedReader(new InputStreamReader(conn.getInputStream()));
String line = null;
while ((line = reader.readLine()) != null) {
document.append(line + System.getProperty("line.separator"));
}
reader.close();
} catch (MalformedURLException e) {
System.out.println("Unable to connect to URL: " + filePath);
} catch (IOException e) {
System.out.println("IOException when connecting to URL: " + filePath);
}
return document.toString();
}
3.将修改好的词典内容保存
/**
* @Description 保存词典
* @param menuId 菜单id
* @param context 词典内容
* @param request HTTP请求
* @return boolean 是否成果能够*/
@RequestMapping(value = "/saveDictionary")
@ResponseBody
public boolean saveDictionary(Integer menuId, String context, HttpServletRequest request) { //获取tomcat的路径
String filePath = System.getProperty("catalina.home")+"\\webapps\\ROOT\\RemoteDictionary.dic";
boolean result = writeDictionary(filePath, context);
return result;
}
/**
* @Description 上传词典
* @param filePath 词典路径
* @param content 修改的内容
* @return boolean 是否上传成功*/
private boolean writeDictionary(String filePath, String content) {
try {
File f = new File(filePath);
if (!f.exists()) {
return false;
}
OutputStreamWriter write = new OutputStreamWriter(new FileOutputStream(f), "UTF-8");
BufferedWriter writer = new BufferedWriter(write);
writer.write(content);
writer.close();
return true;
} catch (Exception e) {
return false;
}
}
【热更新IK词典】ElasticSearch IK 自动热更新原理与实现的更多相关文章
- 【自定义IK词典】Elasticsearch之中文分词器插件es-ik的自定义词库
Elasticsearch之中文分词器插件es-ik 针对一些特殊的词语在分词的时候也需要能够识别 有人会问,那么,例如: 如果我想根据自己的本家姓氏来查询,如zhouls,姓氏“周”. 如 ...
- Node.js + gulp 合并静态页模版,文件更新自动热重载。浏览器可预览
github地址:https://github.com/Liaozhenting/template 使用的是ejs的语法.其实你用什么文件后缀都可以,都是按ejs来解析. 模板文件放在componen ...
- solr6.3.0升级与IK动态词库自动加载
摘要:对于中文的搜索来说,词库系统是一个很比较重要的模块,本篇以IK分词器为例子,介绍如何让分词器从缓存或文件系统中自动按照一定频次进行加载扩展词库 Lucene.Solr或ElasticStack如 ...
- 另类Unity热更新大法:代码注入式补丁热更新
对老项目进行热更新 项目用纯C#开发的? 眼看Unity引擎热火朝天,无数程序猿加入到了Unity开发的大本营. 一些老项目,在当时ulua/slua还不如今天那样的成熟,因此他们选择了全c#开发:也 ...
- Elasticsearch IK+pinyin
如何在Elasticsearch中安装中文分词器(IK+pinyin) 如果直接使用Elasticsearch的朋友在处理中文内容的搜索时,肯定会遇到很尴尬的问题——中文词语被分成了一个一个的汉字 ...
- Unity3D热更新之LuaFramework篇[09]--资源热更新与代码热更新的具体实现
前言 在上一篇文章 Unity3D热更新之LuaFramework篇[08]--热更新原理及热更服务器搭建 中,我介绍了热更新的基本原理,并且着手搭建一台服务器. 本篇就做一个实战练习,真正的来实现热 ...
- Windows10安装Elasticsearch IK分词插件
安装插件 cmd切换到Elasticsearch安装目录下 C:\Users\Administrator>D: D:\>cd D:\Program Files\Elastic\Elasti ...
- elasticsearch ik分词
elasticsearch 默认并不支持中文分词,默认将每个中文字切分为一个词,这明显不符合我们的业务要求.这里就需要用到ik分词插件. 本文主要囊括了以下几部分,ik插件安装.ik用法介绍.自定义词 ...
- 使用 Elasticsearch ik分词实现同义词搜索(转)
1.首先需要安装好Elasticsearch 和elasticsearch-analysis-ik分词器 2.配置ik同义词 Elasticsearch 自带一个名为 synonym 的同义词 fil ...
- android游戏的增量更新(资源及代码的热更新)
需求当游戏需要更新时,不必让用户下载新的完整包,只需要通过游戏内部的更新系统自动更新差异包,达到节约用户流量和时间的目的. 大体思路:1.(游戏逻辑用lua等脚本编写的情况)这种方式的增量更新非常简单 ...
随机推荐
- Python 如何引入自定义模块
Python 中如何引用自己创建的源文件(*.py)呢? 也就是所谓的模块. 假如,你有一个自定义的源文件,文件名:saySomething.py .里面有个函数,函数名:sayHello.如下图: ...
- FileInputStream与FileOutputStream类 Reader类和Writer类 解析
FileInputStream和FileOutputStream类分别用来创建磁盘文件的输入流和输出流对象,通过它们的构造函数来指定文件路径和文件名. 创建FileInputStream实例对象时,指 ...
- Fluent Nhibernate Mapping for Sql Views
Views are mapped the same way tables are mapped except that you should put Readonly() in the mapping ...
- ssh-keygen 不是内部或外部命令解决办法!
在使用 git 的远程仓库的时候,生成秘钥的使用,会遇到ssh-keygen不是内部命令也不是外部命令的问题: 具体解决: 第一步:找到:Git/usr/bin目录下的ssh-keygen.exe(一 ...
- 微信小程序 --- 设置app.js/page.js参数的方法
设置 app.js 文件: //app.js App({ globalData: { is_login:false, userInfo:{} } }) 设置gloabalData的方法: // 定义a ...
- 2-sat+二分搜索hdu(3622)
hdu3622 Bomb Game Time Limit: 10000/3000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) ...
- lampp and testrail
https://wyzx.testrail.net szllq2000 http://129.0.1.228/testrail/ http://docs.gurock.com/testrail-adm ...
- Django - CBV、FBV
一.FBV FBV(function base views) 就是在视图里使用函数处理请求. 在之前django的学习中,我们一直使用的是这种方式. 二.CBV CBV(class base view ...
- Mysql EXPLAIN 相关疑问: Using temporary ; Using filesort
一.什么是Using temporary ; Using filesort 1. using filesort filesort主要用于查询数据结果集的排序操作,首先MySQL会使用sort_buff ...
- 【云安全与同态加密_调研分析(7)】安全技术在云计算中的安全应用分析——By Me
我司安全技术在云计算中的安全应用分析 1. 基于云计算参考模型,分析我司安 ...