快速定位oracle故障-恩墨
首先我们要明白一点,所谓的故障,意味着相对来讲比较严重。也就是可能比不同的问题要严重一些,比如锁等待。
要能够快速的定位和解决问题,恢复业务正常;首先我们需要了解Oracle的一些常见的故障有哪些。
这里我根据问题的严重性,或者说不同的维度,进行了几个分类。比如说,性能问题:
► 数据库连接缓慢
► 应用查询响应慢
► 中间层性能问题
► 应用读写性能很差
► 触发Oracle bug
这就是大家可能都比较熟悉和了解的一些情况。
很多时候,应用人员和开发人员是不懂数据库的,他们的第一反应就是慢。很多时候是不知道慢在什么地方的、作为DBA,大家都知道,从应用到DB,中间需要经过很多环节,比如网络,交换机等等。这些其实都有可能是导致问题的原因。之所以首先将性能问题,我认为性能问题,相对来讲,要好一些。起码应用还可以运行,只是跑的慢一些。说的直白一些,总比不能跑要好吧?这里提到的几种情况,实际上我都遇见过。例如第一种,应用的反应是连接数据库时快时慢。我只是在3个客户那里遇到这个问题。那么遇到类似的问题,我们如何去快递定位呢?
其次,其他方面,比如应用反应读写很慢,这种很多人的感觉是存储问题。比如认为存储性能很差导致Oracle读写很慢,响应时间被拉的很长。刚刚我也提到过,应用到db,其实要经过很多环节,不能贸然断定就是存储的问题。但是这种问题,极容易让dba产生错误的判断。更为详细的内容,我们稍后再展开。
还要有些更为严重的问题,比如
► 数据库hang (Oracle核心进程挂起)
► 数据库坏块(坏块数量不同,可能意味着不同的原因)
► 数据库crash,无法启动
数据库挂起了,导致应用无法处理了。这种是十分严重的故障了。最近我的客户也遇到过这个问题。当然,数据库hang,或者说挂起,可能分为几种情况,例如,可能是操作系统挂起了,导致db挂起,或者可能是Oracle的核心进程挂起了。还有一些大面积坏块的情况,等等。这些比较严重的故障,应用基本上是无法运行的。影响极大。
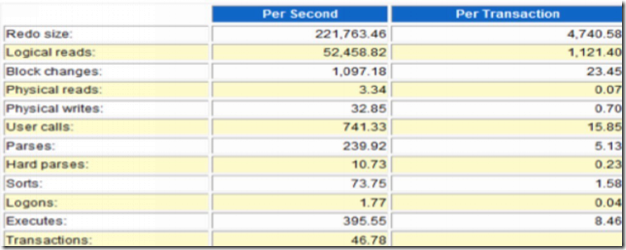
举个案例。这是故障期间的awr数据,当然,客户的反映是感觉应用提交有些慢。说道提交,那么就是意味着写。很多人第一感觉会是写的很慢?那那么是存储问题吗?这种疑惑很正常,那么如果看到top 5后呢?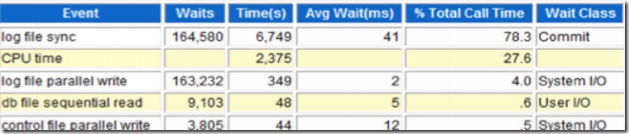
看到TOP 5 event后绝大多数DBA会认为问题的原因就是log file sync,因为其avg wait很高,超过了大家说认识的指标,比如心中所牢记的5ms的指标。对于log file sync太熟悉不过了。网上的文章页很多,大家都知道可能是commit过于频繁或者说存储性能差等等类似的原因。实际上这种理解有些片面了。根据我们的常规思路,我们可能通常会去awrddrpt.sql采集对比报告进行分析。看看差异在哪里。实际上,我认为很多时候我们应该了解本质,就拿这个问题来讲,我这里引用下一个大牛的图。
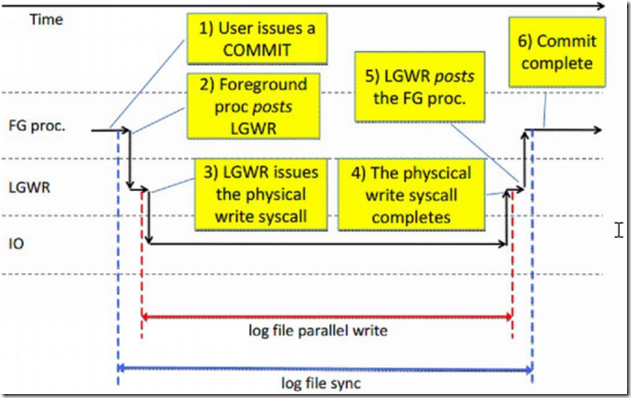
对于oracle中的log file sync实际上牵扯到很多的环境。大家也可以看到,从第1步到最后一步。中间的环境出问题,都会导致问题的出现。比如有可能是资源调度问题,或者存储写性能差,或者网络问题等等。
strace -fr /oracle/product/11.2/db_1/jdk/bin/java -jar a16_xxx.jar
……
[pid 17242] 0.000142 stat("/dev/random", {st_mode=S_IFCHR|0666, st_rdev=makedev(1, 8), …}) = 0
[pid 17242] 0.000084 stat("/dev/urandom", {st_mode=S_IFCHR|0666, st_rdev=makedev(1, 9), …}) = 0
[pid 17242] 0.000376 lseek(3, 46548757, SEEK_SET) = 46548757[pid 17242] 0.000037 read(3, "PK\3\4\n\0\0\0\0\0\201^8A\275}\357^K\16\0\0K\16\0\0/\0\0\0", 30) = 30
[pid 17242] 0.000046 lseek(3, 46548834, SEEK_SET) = 46548834
[pid 17242] 0.000032 read(3, "\312\376\272\276\0\0\0001\0\245\10\0\r\10\0\22\10\0)\10\0.\10\0:\10\0@\1\0\3("…, 3659) = 3659
[pid 17242] 0.000275 open("/dev/random", O_RDONLY) = 10
……
通过类似的strace跟踪,很容易找到问题的原因,当然这个case通过跟踪我们就可以看到,实际上就是因为11g里面,oracle对于jdbc做了安全增强。这可能会导致应用连接时,出现异常。至于处理方式,就很简单了。将file:/dev/random 改成file:/dev/./urandom就行。注意是,修改java配置。前面是针对性能方面的问题。
从操作系统层面来讲,也有很多方面的问题。操作系统故障
► 操作系统文件系统损坏
► 本地磁盘损坏
► 主机硬件故障导致操作系统crash
► 主机性能承载能力不足引发系统崩溃
► 操作系统挂起
► 其他
操作系统故障,通常来讲,我认为都是比较严重的,因为Oracle毕竟是立足于os。熟话说,皮之不存,毛将焉附?对于linux,aix或者hp-ux,我想大家都安装部署过很多环境了,应该都比较了解一些参数的设置。比如aix的swap参数设置。比如linux的内存配置,尤其是linux。因为目前x86越来越流行,大多数客户都开始考虑使用linux。linux的一些内存参数设置需要我们注意,包括大页的配置;例如内存的回收参数。说到这里,我见过很多这样的情况,很多时候内存可能是被fs的cache消耗了。前段时间,我还遇见过,客户通过部署脚本手工去释放cache导致数据库宕机的。这说明客户知道内存回收的重要性,可是他并不完全了解linux的内存回收机制。网上是一些内存回收方式,是很暴力的。当我们使用这些暴力的方式,你还得看看会不会触发bug。实际上我们遇到的这个就是遇到了bug。结果通过内存回收导致数据库crash了。当时这个并不是指的前面提的这个swap的问题,这是aix的环境。不是一回事。除了主机的问题,还要更为严重的问题。为什么这样讲呢?因为绝大多数用户的数据都存放在存储上,操作系统故障,最多导致业务停机,但是起码数据还在,一旦存储出现问题,那么就非常麻烦了。
存储故障
► 磁盘故障导致数据库损坏crash
► 控制器损坏
► 存储电池耗尽,导致cache关闭
► 光纤线异常例如松动
► 其他
关于存储故障,有很多可能的原因,比如磁盘坏了,控制坏了等各种问题。大家可能也都了解,恩墨做数据恢复是很多的。尤其是最近2年,数据库恢复基本上都是我做的或者参与的。这种十分严重的问题,我们要尽量去避免。这里不展开了。这里简单总结下,对于数据库故障或者问题,我们分为了几大类。那么如果真的出问题了,如何才能快速定位呢?这里可以分析我个人的经验,如何快速定位并最短时间内恢复业务,这可能是我们最为关心的一点。比如应用反应慢,那么我们应用如何着手?
1)首先确认主机、数据库、中间层等是否经过调整。
2)观察主机资源使用是否异常
3)观察数据库资源使用是否正常
4)确认数据库是否存在异常等待
5)和应用确认是否存在变动
6)使用AWRDDRPT.SQL进行对比
7)如果是单个应用模块缓慢,则查看SQL执行计划,确认执行计划是否异常或是否存在变动
这可能是一种思路。当然,在进行问题判断时,要了解清楚,不要盲目下判断。我自己也经常遇到过,如果不了解清楚情况,很容易被用户误导。例如我们之前一个用户反应,一个邮件系统很慢。开始只说操作慢。最后多次确认发现是登陆后刷新某些选项时候,比较慢,而且是偶尔慢,这个词,很难讲。
这里再给大家来个案例,2年前处理的。一个客户反馈,数据迁移后系统几乎无法运行。根据我们刚刚的思路,首先肯定是分析awr。的确,客户开始联系我们,也是提供了awr数据。
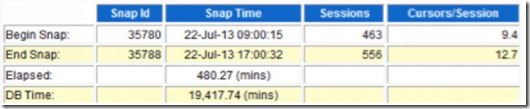
我们通常习惯于使用db time去衡量数据库负载的高低。
19417.74/(480.27*96) ≈ 0.42
如果我们这样去计算,你会发现小于1. 实际上,这个报告没有太大的价值。
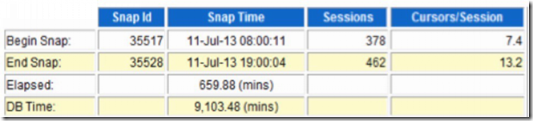
这里是正常时间段的数据。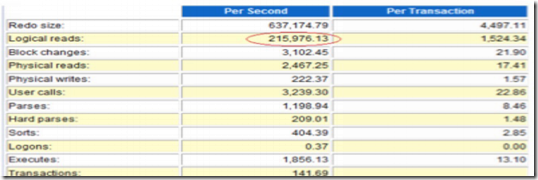
这里我们先不管快照时间太长的问题。可以大致上做个参考。你会发现,正常情况下,每秒141个事务,逻辑读每秒才21w。而故障期间呢?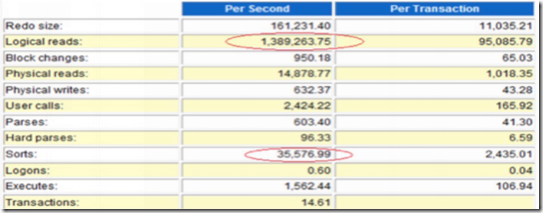
每秒才 14.6个事务,但是逻辑读确高达138w,事务相差10倍的情况之下,逻辑读反而相差了7倍。
这个大致上可以算下,故障期间的性能比平时慢了70倍。看到load profile,可能也难以确认问题到底在哪里,很多人可能还会看看top 5,ok,我们来看下top 5
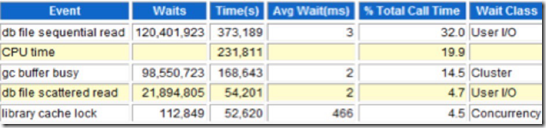
当你看到这个top 5event后,你会发现,没啥奇怪的。如果说稍微奇怪的地方,那么就是db file的读写waits 似乎有些高。实际上这些都是表象。从前面的load profile对比,我们可以看出。逻辑读平均相差了那么多,而且还是480分钟的快照对比。同时逻辑读明显偏高,但是db file sequential read的平均等待时间并不高。这说明了什么?说明存储性能是ok的。我们再来了解下这个问题的前后因果。故障前,该业务系统进行了迁移使用expdp方式进行跨平台数据迁移,应用用户数据量较大,近20TB,业务系统为报表应用(金融行业),SQL复杂,关联表较多,基本上都是数十张表进行关联,客户数据库工程师已经奋战超过10小时,且根据Oracle Support的意见进行了表的统计信息收集,到现场后,从用户角度了解了上述的信息。结合之前客户提供的awr数据,我们可以直接定位。应该是sql的问题。那么用户会问,难道我应用的这么多sql都有问题吗?那么如何去处理呢?因为这个问题客户已经急得不行了。这是重金悬赏的。很多人会说,sql问题,我们看执行计划不就行了么?实际上这里可能并不太好处理。我采取了大家都懂的技术,10046.十分古老的技术。
alter session set current_schema=ywdb;
oradebug setmypid
oradebug unlimit
oradebug event 10046 trace name context forever,level 12
执行业务SQL
oradebug event 10046 trace name context off
通过trace,我发现了一个很有意思的问题。客户提供测试验证的几个业务sql,其中一个,看上去是5表关联,实际上却是16个表的关联。因为有几个看上去是表的对象,实际上是view,那么问题又来了。sql问题,通常无非就是执行计划的问题,而执行计划主要跟统计信息有关。因为Oracle 9i开始,都是使用CBO了。而cbo主要依赖于统计信息。换句话讲,除开哪些特殊情况,只要统计信息是ok的,那么sql的执行计划都应该没什么问题。因为人家的业务sql,迁移之前是好的。而且我到现场后,也发现客户的几个dba在收集统计信息。而且是根据官方的建议在收集。只是可惜的是,他们的收集方式我认为有些问题。
exec dbms_stats.gather_table_stats(ownname=> 'SHCJ', tabname=> 'SCH_XXXX', estimate_percent=>100, method_opt=>'for all columns size skewonly',cascade=>true, degree=>8);
类似这样,大家都知道,这是报表类型的系统,这些表都是很大的,最小的几个G,稍微大点的都是几十GB,这样的收集方式效率很低,当然,收集方式本身本没有问题,只是用错的地方。对于大表,收集统计信息时,通常比例维持在1%甚至更小;而且很多时候,我们根本就不需要直方图。除非数据倾斜,否则你收集直方图有多大的用处?再说了,客户这里的目的是要快点恢复业务。我要明确的告诉他,就是统计信息的问题,怎么验证这个问题?实际上很简单。将trace中的表grep 过滤出来,然后通过类似方收集下即可验证。
dbms_stats.gather_table_stats(…estimate_percent=>1, method_opt=>'for all columns size 1',…);
当然,收集之后,再次运行客户提供的sql,妙级就出结果了。困扰客户1天多的问题,1个小时内就迎刃而解了。问题本身并不复杂 只是当你面临这样高压的情况之下,数十个甲方领导围着你,看着你,压力还是比较大的。所以我们需要良好的抗压能力啊!
刚提到存储的问题,这里也可以跟大家简单分享一个存储故障的案例。也有人提到存储一般都是有镜像,不过很多时候也难以避免不出问题,这种我们也遇到太多了。最让你想不到的是之前见过一个客户的数据库,主库坏掉了,3个备库也同时坏掉了。因为DataGuard把坏块也同步过去了。如果你身临其境,你可能难以理解。
背景: 11gR2 RAC ASM,EMC存储,其中一块硬盘异常
现象: Oracle数据级别无法对该block设备进行读写。最后导致ASM实例Crash,DiskGroup无法mount。
其他:最近一次数据库全备为1周之前,目前数据库归档日志都存在ASM DiskGroup中。数据库容量在1.5TB 左右,NBU备份通过网络,每秒10m左右。
这又是我们另外一个客户曾经面临的问题。这种案例很多,就以这个为例吧。asm的磁盘,无法读取,导致数据库宕机了。然后客户重启操作系统,存储,交换机等各种手段,反正一个数据盘就是无法读。oracle的kfed都无法读取这个盘。比较怪异,当然最后我通过分析asm元数据,同时结合odu恢复了业务。比较庆幸的是,没有业务数据丢失。通过KFED 读取ASM Alias Directory元数据,并输出到文本asm_dict.txt,Shell scripts匹配asm_dict.txt中的File Name,并保持脚本,使用ODU copy 数据文件到文件系统中。使用ODU copy Oracle REDO文件,新建数据库实例,Recover DataBase 并起动数据库即可。大致的方式是这样:
时间关系,这里不展开讲。只是希望大家要重视。客户也有备份,可是备份用不了。前后折腾了好多天,导致业务长时间中断,这是很可怕的。数据库hang的几种可能性,数据库锁争用严重,例如DX分布式事务锁,系统资源使用极高,比如CPU消耗,Oracle核心进程无法获得Latch,Oracle DRM,Oracle Bug,还有一些情况,例如。
数据库极慢,甚至快到挂起的地步。这个时候你看到的现象,通常是是资源耗尽或者异常等待事件很高。对于这些场景 我一般习惯这样去快速处理
1) 操作系统资源监控,确认资源高消耗进程
ps aux |head -1 ;
ps aux |sort -rn +2 |head –10
2) hang analyze分析
oradebug setmyid
oradebug hanganalyze 3
oradebug close_trace
oradebug tracefile_name
如果SQLPLUS不能正常登陆Oracle数据库,那么使用pre方式登陆:
sqlplus -prelim / as sysdba
oradebug setmypid
oradebug dump processstate 10
oradebug close_trace
通过oradebug 可以快速的定位和解决很多问题,尤其是锁问题,latch争用等等。这里要注意的是,当我们定位到异常进程后,不要盲目kill,或者起码kill之前应该dump下进程的状态,便于后面分析原因。之前也遇到很多这样的情况。客户dba发现问题之后,一阵kill最后去分析原因,发现什么数据都没有,监控没有,awr数据没有产生甚至他操作的日志都没有保留,如果说你发现某个进程异常了,可以进行db的dump,如果db层面无法进行dump,甚至你还可以进行os层的dump。
比如,对于个别进程消耗极高的情况,甚至还可以进行操作系统级别的dump:
dbx -a PID
dbx() print ksudss(10)
dbx() detach
通过保留现场数据,我们可以后续分析,预防再次发现类似的问题。
==============
HANG ANALYSIS:
==============
Found 54 objects waiting for <cnode/sid/sess_srno/proc_ptr/ospid/wait_event>
<0/5210/10419/0x99d0a88/11215038/No Wait>
……省略部分内容
[16]/0/17/154/0x24617be0/26800/IN_HANG/29/32/[185]/19
这是一个oradebug的例子。通过oradebug,我们可以发现5210这个session阻塞了54个会话,这是比较严重的。而且还有个别的进程可能已经hang了。比如session 17.这种锁问题要快速解决很简单,通过kill就能很快恢复业务正常。讲了这么多,那么针对前面的种种问题,我们如何去快递定位问题呢?
这里可以简单总结下:
1)对于性能问题,很多时候可能是sql问题,我们应该关注sql执行计划,比如执行计划是否稳定。当然,这是一方面。我们要了解应用是否存在变更,是否有做过调整。这些很关键,因为可能左右我们的判断方向。
2)其次,很多时候,我们首先应该检查是操作系统,而不是数据库。
3)当确认操作系统正常的情况之下,再从数据库本身出发,比如是否存在异常等等,进行故障期间和正常时间段的数据比较等等。对于操作系统问题,存储问题,更多的时候我们要做的是,如果去预防。
例如
1)监控操作系统日志
2)监控数据库主机资源使用情况,包括CPU,IO,MEMORY
3)监控数据库Alert log
4)监控数据库会话连接数
5)监控event平均响应时间
6)监控数据库event变化趋势
7)监控重点SQL语句的执行情况
8)进行数据库SQL审计,防止新业务上线引发性能问题
9)部署自动化脚本,以便于快速解决问题
通过系统监控来辅助。很多用户都部署了系统监控,可惜没有真正的发挥作用。主机监控,数据库监控,我们需要关注不同的指标。作为dba,我认为,你自己管理的数据库,你应该要对其非常了解,知道事务的量级,业务的增强,响应时间等等。心中应该有一个标尺。作为运维dba,可能我们还需要一个有力的工具或者脚本,我个人之前也有一个shell工具,集成了数十个脚本,处理问题很快。只是最近这些年,作为第三方,几乎不用了。其次之外,我们还应该考虑到系统的容灾方面,这里我们展开了。下次有机会再分享吧。最近处理了很多案例,有机会可以将案例展开来讲。今天就到这里了哈,下次有机会拿具体的案例,展开讲。
快速定位oracle故障-恩墨的更多相关文章
- 转://云和恩墨的两道Oracle面试题
真题1. 对于一个NUMBER(1)的列,如果查询中的WHERE条件分别是大于3和大于等于4,那么这二者是否等价? 答案:首先对于查询结果而言,二者没有任何区别.从这一点上讲无论是指定大于3还是指定大 ...
- 【风哥干货】快速解决Oracle数据库故障必备的20个脚本与命令
1.操作系统性能(通常故障出现时最先检查的内容)top.topas.vmstat.iostat.free.nmon 2.万能重启方法 如应急情况,需要重启数据库:tail -100f <对应路径 ...
- 【云和恩墨】性能优化:Linux环境下合理配置大内存页(HugePage)
原创 2016-09-12 熊军 [云和恩墨]性能优化:Linux环境下合理配置大内存页(HugePage) 熊军(老熊) 云和恩墨西区总经理 Oracle ACED,ACOUG核心会员 PC S ...
- 关联与下钻:快速定位MySQL性能瓶颈的制胜手段
本文根据DBAplus社群[2018年1月6日北京开源与架构技术沙龙]现场演讲内容整理而成. 讲师介绍 李季鹏 新炬网络数据库专家 专注于MySQL数据库性能管理及相关解决方案,目前主要从事MySQL ...
- 快速定位隐蔽的sql性能问题及调优【转载】
在前几天,有个开发同事问我一个问题,其实也算是技术救援,他说在有个job数据处理的频率比较高,在测试环境中很难定位出在哪有问题,而且速度也还能接 受,但是在生产环境中总是会慢一些,希望我能在测试环境中 ...
- 快速熟悉Oracle索引
一.索引 1.1 什么是索引? 一种用于提升查询效率的数据库对象: 通过快速定位数据的方法,减少磁盘的输入输出操作: 索引信息与表独立存放: Oracle数据库自动使用和维护索引. 1.2 索引分类 ...
- 转帖 云和恩墨 http://www.eygle.com/archives/2015/06/sql_version_count.html
SQL多版本控制 - _CURSOR_OBSOLETE_THRESHOLD 作者:eygle |English [转载时请标明出处和作者信息]|[恩墨学院 OCM培训传DBA成功之道]链接:htt ...
- 如何利用快照( snapshot )功能快速定位性能问题
我们常常会遇到这样的困惑,收到用户或者客服的反馈,平台使用有问题,但是测试人员搭建环境后又没办法复现故障,最后导致问题没法解决,眼睁睁地看着用户流失. 这是因为线上生产环境非常复杂.很多时候是偶发性 ...
- 企业IT管理员IE11升级指南【16】—— 使用Compat Inspector快速定位IE兼容性问题
企业IT管理员IE11升级指南 系列: [1]—— Internet Explorer 11增强保护模式 (EPM) 介绍 [2]—— Internet Explorer 11 对Adobe Flas ...
随机推荐
- C#代理多样性
一.代理 首先我们要弄清代理是个什么东西.别让一串翻译过来的概念把大家搞晕了头.有的文章把代理称委托.代表等,其实它们是一个东西,英文表述都是“Delegate”.由于没有一本权威的书来规范这个概念, ...
- tiny210V2开发板hdmi输出到10.1寸LCD,无图像
tiny210V2开发板hdmi输出到10.1寸LCD,无图像... 用tiny210V2开发板的HDMI接口输出到的10.1寸LCD,LCD无任何现象.说明一下我的情况,我的10.1寸屏LCD是HD ...
- bootstrap -- css -- 按钮
本文中提到的按钮样式,适用于:<a>, <button>, 或 <input> 元素上 但最好在 <button> 元素上使用按钮 class,避免跨浏 ...
- Qt 定时器Timer使用
From: http://dragoon666.blog.163.com/blog/static/107009194201092602326598/ 1.新建Gui工程,在主界面上添加一个标签labe ...
- jquery获取html元素的绝对位置和相对位置的方法
绝对位置坐标: 代码如下: $("#elem").offset().top$("#elem").offset().left 相对父元素的位置坐标: 代码如下: ...
- ubuntu-12.04.5-desktop-amd64.iso:ubuntu-12.04.5-desktop-amd64:安装Oracle11gR2
ubuntu 桌面版的安装不介绍. 如何安装oracle:核心步骤和关键点. ln -sf /bin/bash /bin/sh ln -sf /usr/bin/basename /bin/basena ...
- ftp命令行工具如何 连接 非标准21端口(其他端口)的ftp服务器
windows: step1:ftp命令进入ftp交互环境 step2:ftp>open ip空格port 然后...
- error C2275: 'SOCKET' : illegal use of this type as an expression
在VC中编译xxx.c文件出现错误error C2275 illegal use of this type as an expression 问题在于C99之前要求所有的声明必须放在函数块的起始部分, ...
- mysql中根据一个字段相同记录写递增序号,如序号结果,如何实现?
mysql中根据一个字段相同记录写递增序号,如序号结果,如何实现? mysql中实现方式如下: select merchantId, NameCn, send_date, deliver_name ...
- python2.0_day18_django_ORM
Django_ORMday15\16我们学到的ORM都是最基本的增删改查.下面我们稍作升级,学习下高级点的增删改查.先创建一个新的APP项目 python3. manage.py startapp b ...