spring整合kafka项目生产和消费测试结果记录(一)
使用spring+springMVC+mybatis+kafka做了两个web项目,一个是生产者,一个是消费者。
通过JMeter测试工具模拟100个用户并发访问生产者项目,发送json数据给生产者的接口,生产者将json数据发送到kafka集群,
消费者监听到kafka集群中的消息就开始消费,并将json解析成对象存到MySQL数据库。
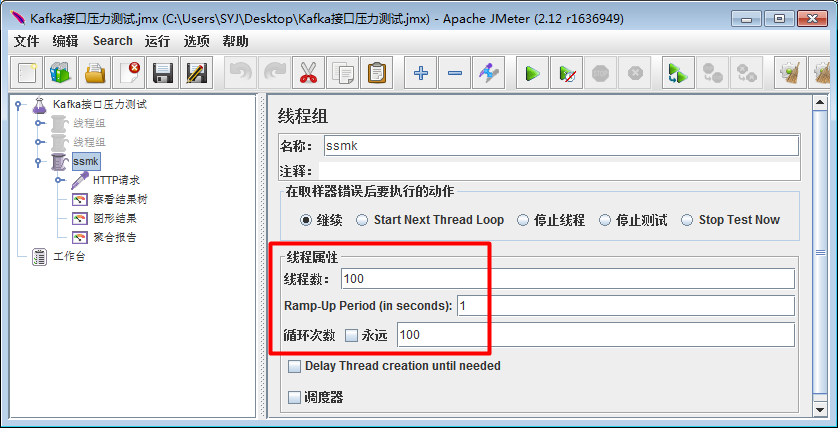
下面是使用JMeter测试工具模拟100个并发的线程设置截图:
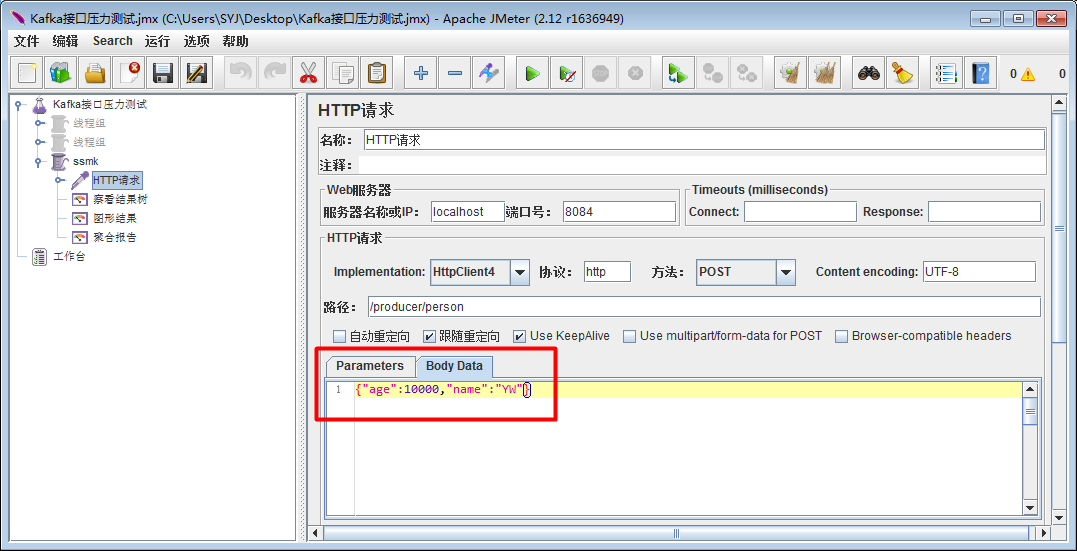
请求所发送的数据:
下面是100个用户10000个请求的聚合报告:

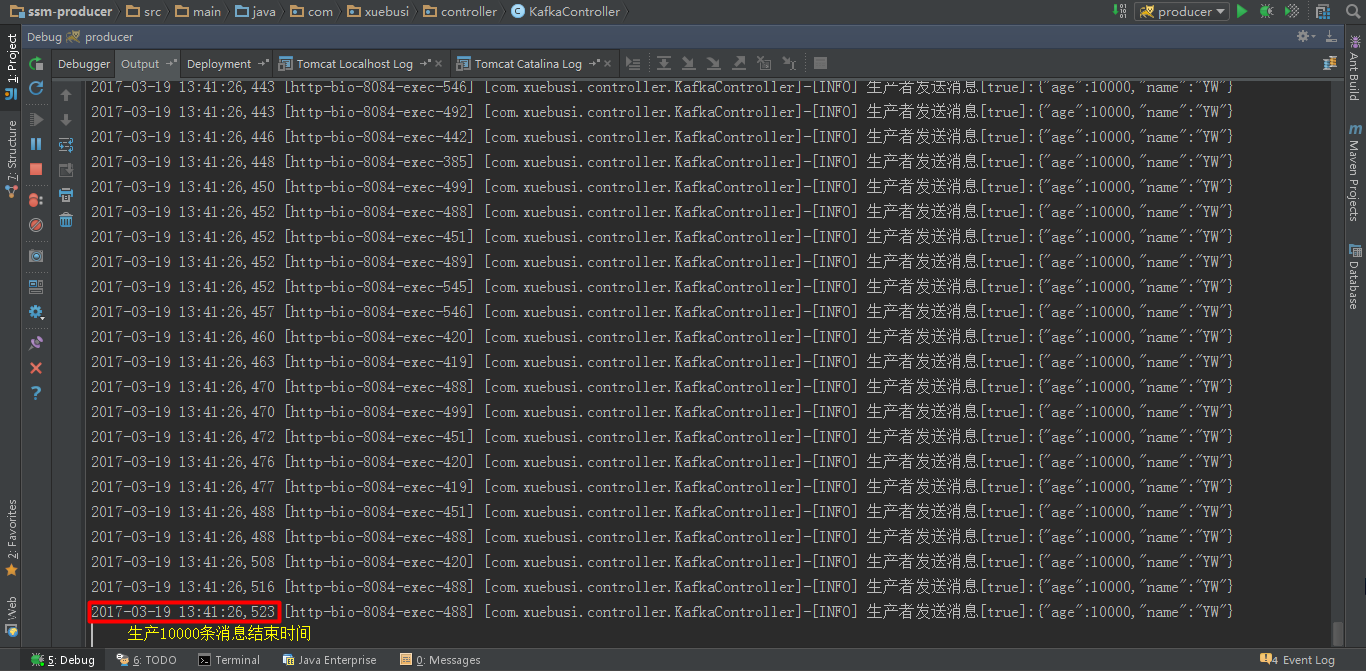
下面是生产者截图生产完10000条消息的时间截图:
下面是消费者项目消费入库的结束时间截图:
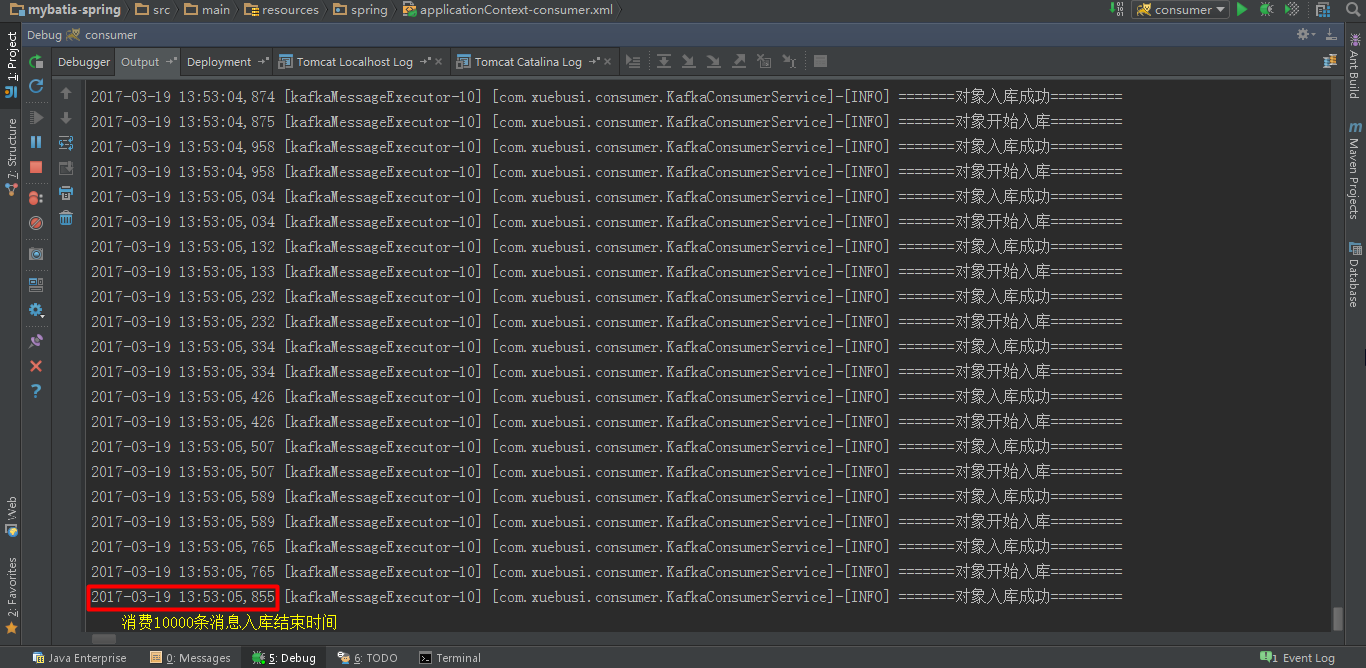
可见,10000条消息从生产完成到入库(消费完10000条消息的时间只是比生产完成的时间落后了几十秒,但是消费端真正入库完成所需要的时间很长)完成时间相差了10几分钟。
下面是MySQL数据库截图,数据全部入库成功:
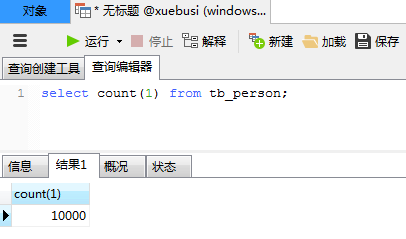
下面是消息对应的POJO:
package com.xuebusi.pojo;
public class TbPerson {
private Long id;
private String name;
private Integer age;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name == null ? null : name.trim();
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public String toString() {
return "TbPerson [id=" + id + ", name=" + name + ", age=" + age + "]";
}
}
下面是生产端的逻辑:
package com.xuebusi.controller; import com.alibaba.fastjson.JSON;
import com.xuebusi.pojo.TbPerson;
import com.xuebusi.service.KafkaService;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.ResponseBody; import javax.annotation.Resource; @Controller
@RequestMapping("/producer")
public class KafkaController { private static final Logger logger = LoggerFactory.getLogger(KafkaController.class); @Resource
private KafkaService kafkaService; /**
* 发消息到ssmk这个topic
* @param person
* @return
*/
@RequestMapping(value = "/person", method = RequestMethod.POST)
@ResponseBody
public String createPerson(@RequestBody TbPerson person) {
if (person == null){
return "fail, data can not be null.";
}
String json = JSON.toJSONString(person);
boolean result = kafkaService.sendInfo("ssmk", json);
logger.info("生产者发送消息[" + result + "]:" + json);
return "success";
}
}
下面是消费端的逻辑:
package com.xuebusi.consumer; import com.alibaba.fastjson.JSON;
import com.xuebusi.pojo.TbPerson;
import com.xuebusi.service.PersonService;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service; import java.util.List;
import java.util.Map; @Service
public class KafkaConsumerService {
private static final Logger logger = LoggerFactory.getLogger(KafkaConsumerService.class); @Autowired
private PersonService personService; public void processMessage(Map<String, Map<Integer, String>> msgs) {
/*for (Map.Entry<String, Map<Integer, String>> entry : msgs.entrySet()) {
String topic = entry.getKey();
Map<Integer, String> value = entry.getValue();
for (Map.Entry<Integer, String> entrySet : value.entrySet()) {
Integer partiton = entrySet.getKey();
String msg = entrySet.getValue();
logger.info("消费的主题:" + topic + ",消费的分区:" + partiton + ",消费的消息:" + msg);
logger.info("=======使用JSON解析对象=========");
TbPerson person = JSON.parseObject(msg, TbPerson.class);
logger.info("=======对象开始入库=========");
personService.insert(person);
logger.info("=======对象入库成功=========");
}
}*/ for (Map.Entry<String, Map<Integer, String>> entry : msgs.entrySet()) {
String topic = entry.getKey();
Map<Integer, String> value = entry.getValue();
for (Map.Entry<Integer, String> entrySet : value.entrySet()) {
Integer partiton = entrySet.getKey();
String msg = entrySet.getValue();
logger.info("消费的主题:" + topic + ",消费的分区:" + partiton + ",消费的消息:" + msg);
msg = "[" + msg + "]";//注意这里要在前后都加上中括号,否则下面在解析json成对象的时候会报json格式不对的异常(spring会对多条json数据用逗号分隔)
logger.info("=======使用JSON解析对象=========");
List<TbPerson> personList = JSON.parseArray(msg, TbPerson.class);
//TbPerson person = JSON.parseObject(msg, TbPerson.class);
if (personList != null && personList.size() > 0) {
logger.info("消息中包含[" + personList.size() + "]个对象");
for (TbPerson person : personList) {
logger.info("=======对象开始入库=========");
personService.insert(person);
logger.info("=======对象入库成功=========");
}
} }
}
}
}
如果觉得本文对您有帮助,不妨扫描下方微信二维码打赏点,您的鼓励是我前进最大的动力:

spring整合kafka项目生产和消费测试结果记录(一)的更多相关文章
- c语言使用librdkafka库实现kafka的生产和消费实例(转)
关于librdkafka库的介绍,可以参考kafka的c/c++高性能客户端librdkafka简介,本文使用librdkafka库来进行kafka的简单的生产.消费 一.producer librd ...
- c# .net 使用Confluent.Kafka针对kafka进行生产和消费
首先说明一点,像Confluent.Kafka这种开源的组件,三天两头的更新.在搜索引擎搜索到的结果往往用不了,浪费时间.建议以后遇到类似的情况直接看官网给的Demo. 因为搜索引擎搜到的文章,作者基 ...
- spring 整合kafka监听消费
前言 最近项目里有个需求,要消费kafka里的数据.之前也手动写过代码去消费kafka数据.但是转念一想.既然spring提供了消费kafka的方法.就没必要再去重复造轮子.于是尝试使用spring的 ...
- spring整合kafka(配置文件方式 消费者)
Kafka官方文档有 https://docs.spring.io/spring-kafka/reference/htmlsingle/ 这里是配置文件实现的方式 先引入依赖 <depend ...
- spring整合hibernate之买书小测试
spring来整合hibernate就是用spring来管理hibernate的sessionFactory和让hibernate来使用spring的声明式事务. 一:加入相应的jar包. 二:写hi ...
- spring整合kafka(配置文件方式 生产者)
Kafka官方文档有 https://docs.spring.io/spring-kafka/reference/htmlsingle/ 这里是配置文件实现的方式 先引入依赖 <depend ...
- spring整合web项目
Web项目如何初始化SpringIOC容器 :思路:当服务启动时(tomcat),通过监听器将SpringIOC容器初始化一次(该监听器 spring-web.jar已经提供),web项目启动时 ,会 ...
- 关闭spring整合kafka时,消费者一直打印kafka日志
在log4j.properties中添加如下代码 log4j.logger.org.apache.kafka.common.metrics.Metrics=OFF log4j.logger.org.a ...
- Spring整合Web项目原理-理解不了,忽略
随机推荐
- The Web Sessions List
The Web Sessions list contains the list of HTTP Requests that are sent by your computer. You can res ...
- webpack entry和output配置属性
1.entry entry的三种配置方式: (1)传递字符串: 单个入口语法:传递一个字符串 entry: './src/js/main.js', (2)传递数组 将创建“多个主入口(multi-ma ...
- SettingsPLSQLDeveloper
迁移时间:2017年5月21日10:12:23Author:Marydon 一.常用配置项UpdateTime--2017年3月15日13:55:46注:没有安装Oracle数据库的情况下,前两步 ...
- SettingsEclipse
迁移时间--2017年5月20日08:45:07 CreateTime--2016年11月15日11:07:44Author:Marydon --------------------------- ...
- 【Oracle】事务处理
名词解释 DML:Data Manipulation Language (数据库操纵语言) 例如:DELETE.INSERT.UPDATE.SELECT DDL:Data Definition Lan ...
- imp与impdp比较
impdp和expdp是oracle 10g及以上版本才带的命令,目的是替换imp和exp命令,但为了向后兼容,故后面命令在高版本中依然可以使用. 但imp和exp在处理跨版本的导入导出时很麻烦,而i ...
- raise语句
# -*- coding: utf-8 -*- #python 27 #xiaodeng #Python学习手册 868 #raise语句 res=[IndexError,TypeError] #ra ...
- java 新创建的类要重写的方法
重写toString方法,可以控制println打印的结构. 如果需要往hashSet或者HashMap中存,需要重写hashCode和equals方法,因为hashSet执行添加,以对象为参数删除, ...
- Oracle的PLSQL别名中文出现乱码解决方法
乱码之乱,乱在心里.行而上,眼迷茫! 01.查询oracle服务端默认语言 select * from nls_database_parameters NLS_LANGUAGE AMERICAN ...
- RabbitMQ消息队列生产者和消费者
概述 生产者生产数据至 RabbitMQ 队列,消费者消费 RabbitMQ 队列里的数据. 详细 代码下载:http://www.demodashi.com/demo/10723.html 一.准备 ...