Scala编程实战
项目概述
需求
目前大多数的分布式架构底层通信都是通过RPC实现的,RPC框架非常多,比如前我们学过的Hadoop项目的RPC通信框架,但是Hadoop在设计之初就是为了运行长达数小时的批量而设计的,在某些极端的情况下,任务提交的延迟很高,所以Hadoop的RPC显得有些笨重。
Spark 的RPC是通过Akka类库实现的,Akka用Scala语言开发,基于Actor并发模型实现,Akka具有高可靠、高性能、可扩展等特点,使用Akka可以轻松实现分布式RPC功能。
Akka简介
友情链接: Actors介绍: https://www.iteblog.com/archives/1154.html
Akka基于Actor模型,提供了一个用于构建可扩展的(Scalable)、弹性的(Resilient)、快速响应的(Responsive)应用程序的平台。
Actor模型:在计算机科学领域,Actor模型是一个并行计算(Concurrent Computation)模型,它把actor作为并行计算的基本元素来对待:为响应一个接收到的消息,一个actor能够自己做出一些决策,如创建更多的actor,或发送更多的消息,或者确定如何去响应接收到的下一个消息。
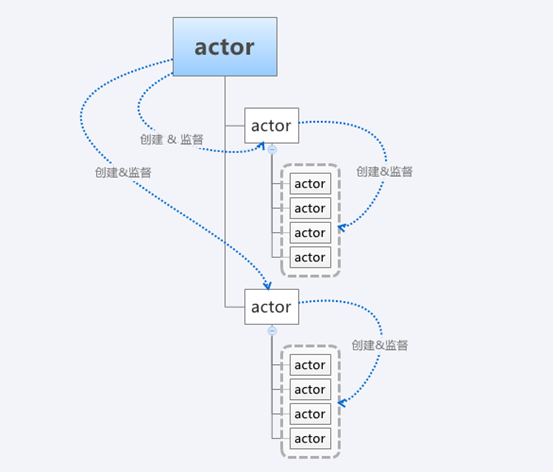
Actor是Akka中最核心的概念,它是一个封装了状态和行为的对象,Actor之间可以通过交换消息的方式进行通信,每个Actor都有自己的收件箱(Mailbox)。通过Actor能够简化锁及线程管理,可以非常容易地开发出正确地并发程序和并行系统,Actor具有如下特性:
(1)、提供了一种高级抽象,能够简化在并发(Concurrency)/并行(Parallelism)应用场景下的编程开发
(2)、提供了异步非阻塞的、高性能的事件驱动编程模型
(3)、超级轻量级事件处理(每GB堆内存几百万Actor)
项目实现
实战一:
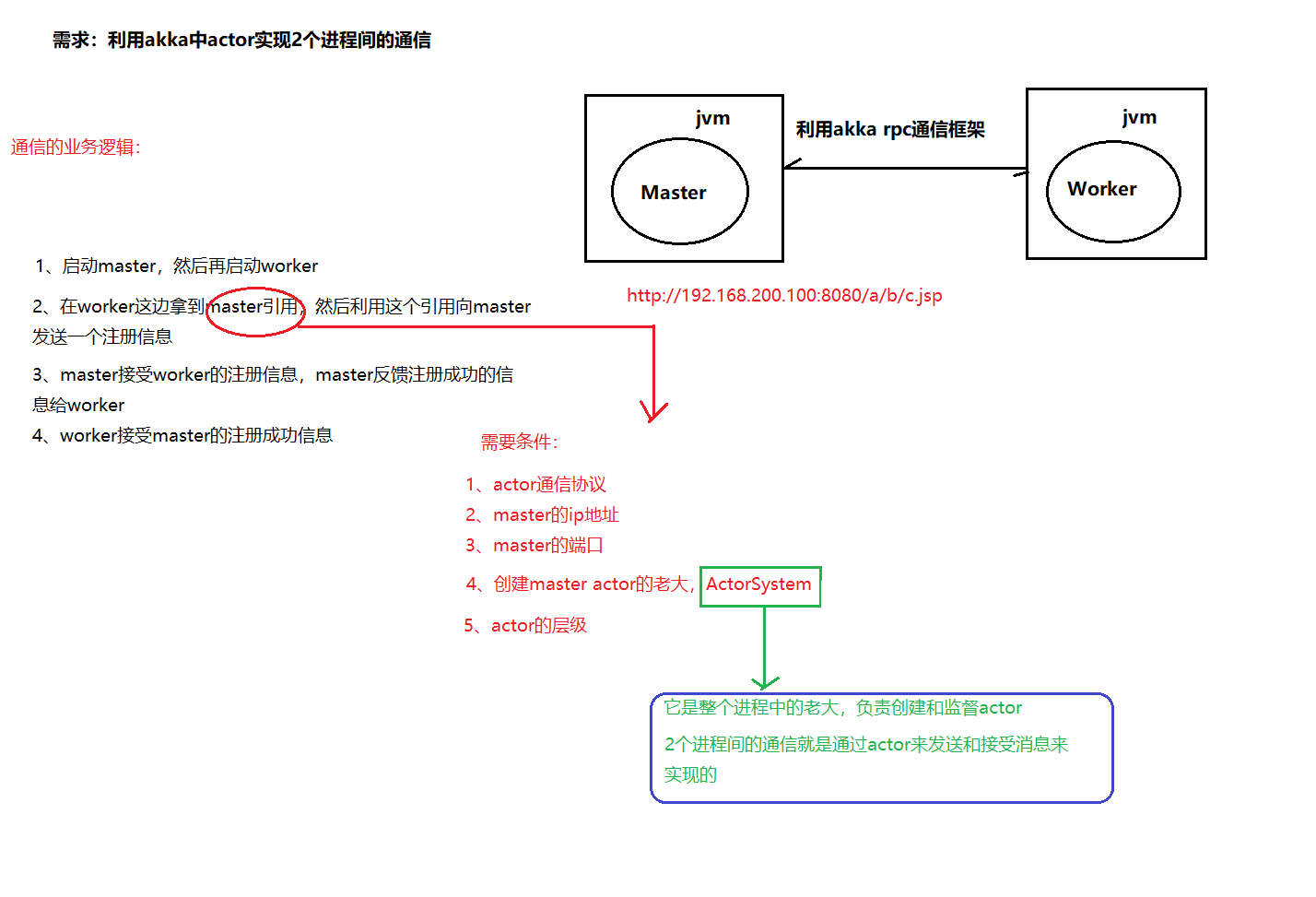
利用Akka的actor编程模型,实现2个进程间的通信。
架构图
重要类介绍
ActorSystem:在Akka中,ActorSystem是一个重量级的结构,他需要分配多个线程,所以在实际应用中,ActorSystem通常是一个单例对象,我们可以使用这个ActorSystem创建很多Actor。
注意:
(1)、ActorSystem是一个进程中的老大,它负责创建和监督actor
(2)、ActorSystem是一个单例对象
(3)、actor负责通信
Actor
在Akka中,Actor负责通信,在Actor中有一些重要的生命周期方法。
(1)preStart()方法:该方法在Actor对象构造方法执行后执行,整个Actor生命周期中仅执行一次。
(2)receive()方法:该方法在Actor的preStart方法执行完成后执行,用于接收消息,会被反复执行。
具体代码
① Master类
package cn.itcast.rpc
import akka.actor.{Actor, ActorRef, ActorSystem, Props}
import com.typesafe.config.ConfigFactory
//todo:利用akka的actor模型实现2个进程间的通信-----Master端
class Master extends Actor{
//构造代码块先被执行
println("master constructor invoked")
//prestart方法会在构造代码块执行后被调用,并且只被调用一次
override def preStart(): Unit = {
println("preStart method invoked")
}
//receive方法会在prestart方法执行后被调用,表示不断的接受消息
override def receive: Receive = {
case "connect" =>{
println("a client connected")
//master发送注册成功信息给worker
sender ! "success"
}
}
}
object Master{
def main(args: Array[String]): Unit = {
//master的ip地址
val host=args(0)
//master的port端口
val port=args(1)
//准备配置文件信息
val configStr=
s"""
|akka.actor.provider = "akka.remote.RemoteActorRefProvider"
|akka.remote.netty.tcp.hostname = "$host"
|akka.remote.netty.tcp.port = "$port"
""".stripMargin
//配置config对象 利用ConfigFactory解析配置文件,获取配置信息
val config=ConfigFactory.parseString(configStr)
// 1、创建ActorSystem,它是整个进程中老大,它负责创建和监督actor,它是单例对象
val masterActorSystem = ActorSystem("masterActorSystem",config)
// 2、通过ActorSystem来创建master actor
val masterActor: ActorRef = masterActorSystem.actorOf(Props(new Master),"masterActor")
// 3、向master actor发送消息
//masterActor ! "connect"
}
}
② Worker类
package cn.itcast.rpc
import akka.actor.{Actor, ActorRef, ActorSelection, ActorSystem, Props}
import com.typesafe.config.ConfigFactory
//todo:利用akka中的actor实现2个进程间的通信-----Worker端
class Worker extends Actor{
println("Worker constructor invoked")
//prestart方法会在构造代码块之后被调用,并且只会被调用一次
override def preStart(): Unit = {
println("preStart method invoked")
//获取master actor的引用
//ActorContext全局变量,可以通过在已经存在的actor中,寻找目标actor
//调用对应actorSelection方法,
// 方法需要一个path路径:1、通信协议、2、master的IP地址、3、master的端口 4、创建master actor老大 5、actor层级
val master: ActorSelection = context.actorSelection("akka.tcp://masterActorSystem@172.16.43.63:8888/user/masterActor")
//向master发送消息
master ! "connect"
}
//receive方法会在prestart方法执行后被调用,不断的接受消息
override def receive: Receive = {
case "connect" =>{
println("a client connected")
}
case "success" =>{
println("注册成功")
}
}
}
object Worker{
def main(args: Array[String]): Unit = {
//定义worker的IP地址
val host=args(0)
//定义worker的端口
val port=args(1)
//准备配置文件
val configStr=
s"""
|akka.actor.provider = "akka.remote.RemoteActorRefProvider"
|akka.remote.netty.tcp.hostname = "$host"
|akka.remote.netty.tcp.port = "$port"
""".stripMargin
//通过configFactory来解析配置信息
val config=ConfigFactory.parseString(configStr)
// 1、创建ActorSystem,它是整个进程中的老大,它负责创建和监督actor
val workerActorSystem = ActorSystem("workerActorSystem",config)
// 2、通过actorSystem来创建 worker actor
val workerActor: ActorRef = workerActorSystem.actorOf(Props(new Worker),"workerActor")
//向worker actor发送消息
workerActor ! "connect"
}
}
③ 运行
使用idea开发工具,配置参数时,多个参数之间用空格隔开


启动Master

启动Worker

实战二
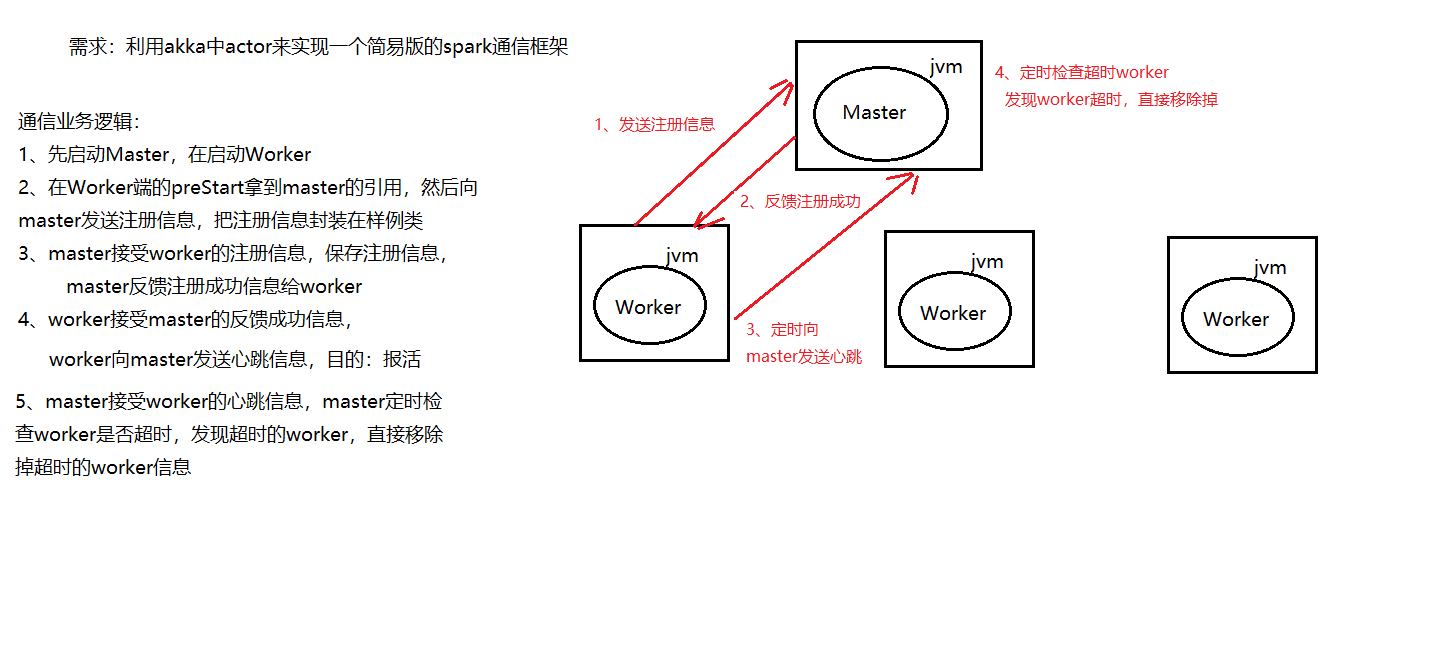
使用Akka实现一个简易版的spark通信框架
架构图
具体代码
① Master类
package cn.itcast.spark
import akka.actor.{Actor, ActorRef, ActorSystem, Props}
import com.typesafe.config.ConfigFactory
import scala.collection.mutable
import scala.collection.mutable.ListBuffer
import scala.concurrent.duration._
//todo:利用akka实现简易版的spark通信框架-----Master端
class Master extends Actor{
//构造代码块先被执行
println("master constructor invoked")
//定义一个map集合,用于存放worker信息
private val workerMap = new mutable.HashMap[String,WorkerInfo]()
//定义一个list集合,用于存放WorkerInfo信息,方便后期按照worker上的资源进行排序
private val workerList = new ListBuffer[WorkerInfo]
//master定时检查的时间间隔
val CHECK_OUT_TIME_INTERVAL=15000 //15秒
//prestart方法会在构造代码块执行后被调用,并且只被调用一次
override def preStart(): Unit = {
println("preStart method invoked")
//master定时检查超时的worker
//需要手动导入隐式转换
import context.dispatcher
context.system.scheduler.schedule(0 millis,CHECK_OUT_TIME_INTERVAL millis,self,CheckOutTime)
}
//receive方法会在prestart方法执行后被调用,表示不断的接受消息
override def receive: Receive = {
//master接受worker的注册信息
case RegisterMessage(workerId,memory,cores) =>{
//判断当前worker是否已经注册
if(!workerMap.contains(workerId)){
//保存信息到map集合中
val workerInfo = new WorkerInfo(workerId,memory,cores)
workerMap.put(workerId,workerInfo)
//保存workerinfo到list集合中
workerList +=workerInfo
//master反馈注册成功给worker
sender ! RegisteredMessage(s"workerId:$workerId 注册成功")
}
}
//master接受worker的心跳信息
case SendHeartBeat(workerId)=>{
//判断worker是否已经注册,master只接受已经注册过的worker的心跳信息
if(workerMap.contains(workerId)){
//获取workerinfo信息
val workerInfo: WorkerInfo = workerMap(workerId)
//获取当前系统时间
val lastTime: Long = System.currentTimeMillis()
workerInfo.lastHeartBeatTime=lastTime
}
}
case CheckOutTime=>{
//过滤出超时的worker 判断逻辑: 获取当前系统时间 - worker上一次心跳时间 >master定时检查的时间间隔
val outTimeWorkers: ListBuffer[WorkerInfo] = workerList.filter(x => System.currentTimeMillis() -x.lastHeartBeatTime > CHECK_OUT_TIME_INTERVAL)
//遍历超时的worker信息,然后移除掉超时的worker
for(workerInfo <- outTimeWorkers){
//获取workerid
val workerId: String = workerInfo.workerId
//从map集合中移除掉超时的worker信息
workerMap.remove(workerId)
//从list集合中移除掉超时的workerInfo信息
workerList -= workerInfo
println("超时的workerId:" +workerId)
}
println("活着的worker总数:" + workerList.size)
//master按照worker内存大小进行降序排列
println(workerList.sortBy(x => x.memory).reverse.toList)
}
}
}
object Master{
def main(args: Array[String]): Unit = {
//master的ip地址
val host=args(0)
//master的port端口
val port=args(1)
//准备配置文件信息
val configStr=
s"""
|akka.actor.provider = "akka.remote.RemoteActorRefProvider"
|akka.remote.netty.tcp.hostname = "$host"
|akka.remote.netty.tcp.port = "$port"
""".stripMargin
//配置config对象 利用ConfigFactory解析配置文件,获取配置信息
val config=ConfigFactory.parseString(configStr)
// 1、创建ActorSystem,它是整个进程中老大,它负责创建和监督actor,它是单例对象
val masterActorSystem = ActorSystem("masterActorSystem",config)
// 2、通过ActorSystem来创建master actor
val masterActor: ActorRef = masterActorSystem.actorOf(Props(new Master),"masterActor")
// 3、向master actor发送消息
//masterActor ! "connect"
}
}
② Worker类
package cn.itcast.spark import java.util.UUID
import akka.actor.{Actor, ActorRef, ActorSelection, ActorSystem, Props}
import com.typesafe.config.ConfigFactory
import scala.concurrent.duration._ //todo:利用akka实现简易版的spark通信框架-----Worker端
class Worker(val memory:Int,val cores:Int,val masterHost:String,val masterPort:String) extends Actor{
println("Worker constructor invoked") //定义workerId
private val workerId: String = UUID.randomUUID().toString //定义发送心跳的时间间隔
val SEND_HEART_HEAT_INTERVAL=10000 //10秒 //定义全局变量
var master: ActorSelection=_ //prestart方法会在构造代码块之后被调用,并且只会被调用一次
override def preStart(): Unit = {
println("preStart method invoked")
//获取master actor的引用
//ActorContext全局变量,可以通过在已经存在的actor中,寻找目标actor
//调用对应actorSelection方法,
// 方法需要一个path路径:1、通信协议、2、master的IP地址、3、master的端口 4、创建master actor老大 5、actor层级
master= context.actorSelection(s"akka.tcp://masterActorSystem@$masterHost:$masterPort/user/masterActor") //向master发送注册信息,将信息封装在样例类中,主要包含:workerId,memory,cores
master ! RegisterMessage(workerId,memory,cores)
} //receive方法会在prestart方法执行后被调用,不断的接受消息
override def receive: Receive = {
//worker接受master的反馈信息
case RegisteredMessage(message) =>{
println(message) //向master定期的发送心跳
//worker先自己给自己发送心跳
//需要手动导入隐式转换
import context.dispatcher
context.system.scheduler.schedule(0 millis,SEND_HEART_HEAT_INTERVAL millis,self,HeartBeat)
} //worker接受心跳
case HeartBeat =>{
//这个时候才是真正向master发送心跳
master ! SendHeartBeat(workerId)
}
}
} object Worker{
def main(args: Array[String]): Unit = {
//定义worker的IP地址
val host=args(0)
//定义worker的端口
val port=args(1)
//定义worker的内存
val memory=args(2).toInt
//定义worker的核数
val cores=args(3).toInt
//定义master的ip地址
val masterHost=args(4)
//定义master的端口
val masterPort=args(5) //准备配置文件
val configStr=
s"""
|akka.actor.provider = "akka.remote.RemoteActorRefProvider"
|akka.remote.netty.tcp.hostname = "$host"
|akka.remote.netty.tcp.port = "$port"
""".stripMargin //通过configFactory来解析配置信息
val config=ConfigFactory.parseString(configStr)
// 1、创建ActorSystem,它是整个进程中的老大,它负责创建和监督actor
val workerActorSystem = ActorSystem("workerActorSystem",config)
// 2、通过actorSystem来创建 worker actor
val workerActor: ActorRef = workerActorSystem.actorOf(Props(new Worker(memory,cores,masterHost,masterPort)),"workerActor") //向worker actor发送消息
workerActor ! "connect"
}
}
③ WorkerInfo类
package cn.itcast.spark //封装worker信息
class WorkerInfo(val workerId:String,val memory:Int,val cores:Int) {
//定义一个变量用于存放worker上一次心跳时间
var lastHeartBeatTime:Long=_ override def toString: String = {
s"workerId:$workerId , memory:$memory , cores:$cores"
}
}
④ 样例类
package cn.itcast.spark
trait RemoteMessage extends Serializable{}
//worker向master发送注册信息,由于不在同一进程中,需要实现序列化
case class RegisterMessage(val workerId:String,val memory:Int,val cores:Int) extends RemoteMessage
//master反馈注册成功信息给worker,由于不在同一进程中,也需要实现序列化
case class RegisteredMessage(message:String) extends RemoteMessage
//worker向worker发送心跳 由于在同一进程中,不需要实现序列化
case object HeartBeat
//worker向master发送心跳,由于不在同一进程中,需要实现序列化
case class SendHeartBeat(val workerId:String) extends RemoteMessage
//master自己向自己发送消息,由于在同一进程中,不需要实现序列化
case object CheckOutTime
⑤ 运行
配置参数时,多个参数之间用空格隔开


首先启动Master_Spark
启动work_spark-01

启动work_spark-02,然后关闭
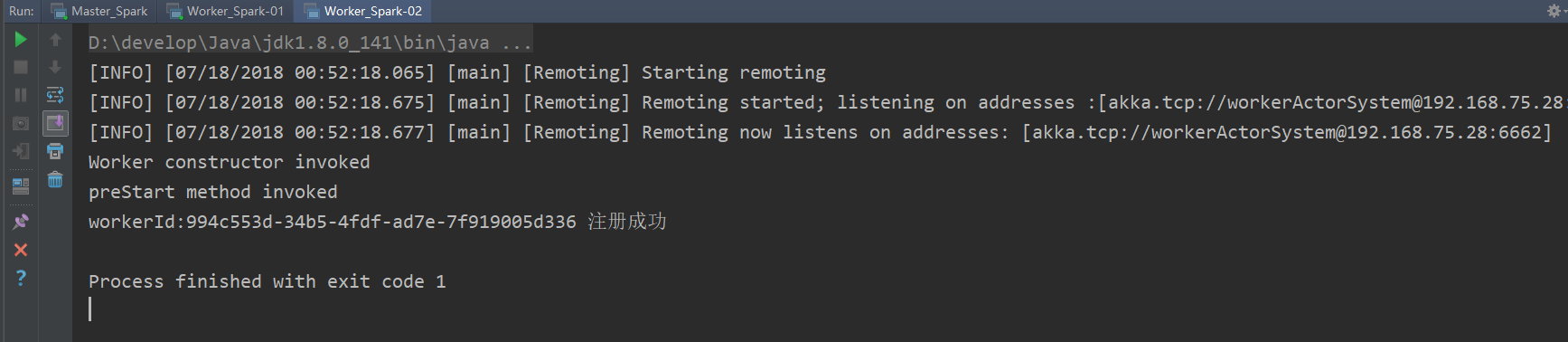
观察Master_Spark 输出

Scala编程实战的更多相关文章
- 03.Scala编程实战
Scala编程实战 1. 课程目标 1.1. 目标:使用Akka实现一个简易版的spark通信框架 2. 项目概述 2.1. 需求 Hivesql----------> sel ...
- Scala实战高手****第17课:Scala并发编程实战及Spark源码阅读
package com.wanji.scala.test import javax.swing.text.AbstractDocument.Content import scala.actors.Ac ...
- Scala 深入浅出实战经典 第68讲:Scala并发编程原生线程Actor、Cass Class下的消息传递和偏函数实战解析
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-87讲)完整视频.PPT.代码下载: 百度云盘:http://pan.baidu.com/s/1c0noOt ...
- Scala 深入浅出实战经典 第67讲:Scala并发编程匿名Actor、消息传递、偏函数解析
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-87讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- Scala 深入浅出实战经典 第66讲:Scala并发编程实战初体验
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-87讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
- Scala 深入浅出实战经典 第41讲:List继承体系实现内幕和方法操作源码揭秘
Scala 深入浅出实战经典 第41讲:List继承体系实现内幕和方法操作源码揭秘 package com.parllay.scala.dataset /** * Created by richard ...
- Scala编程基础
Scala与Java的关系... 4 安装Scala. 4 Scala解释器的使用... 4 声明变量... 5 数据类型与操作符... 5 函数调用与apply()函数... 5 if表达式... ...
- 【Spark】编程实战之模拟SparkRPC原理实现自定义RPC
1. 什么是RPC RPC(Remote Procedure Call)远程过程调用.在Hadoop和Spark中都使用了PRC,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的 ...
随机推荐
- Windows Git Bash命令行下创建git仓库并更新到github
大二的时候就听过老师说有一个叫git的版本管理工具,当时只是听老师说说而已,也没有去使用它,因为当时用过svn,就感觉自己没多少东西需要git管理. 最近几天,我经常在开源中国看别人的帖子,看到别人对 ...
- ../../build/debug/codegen/libCodeGen.a(llvm-codegen.cc.o ):( data.rel.ro_ZTIN4llvm18ValueMapCallbackVHIPKNS_5ValueENS_6WeakVHENS_14ValueMapConfigIS3_EEEE[_ZTIN4llvm18ValueMapCallbackVHIPKNS_5ValueENS_
解决方式如下: wget http://llvm.org/releases/3.3/llvm-3.3.src.tar.gz tar xvzf llvm-3.2.src.tar.gz cd ...
- java多线程---------java.util.concurrent并发包
所有已知相关的接口 1.BlockingDeque<E> 2.BlockingQueue<E> 3.Callable<V> 4.CompletionService& ...
- POJ 3481 Double Queue(set实现)
Double Queue The new founded Balkan Investment Group Bank (BIG-Bank) opened a new office in Buchares ...
- JAVA基于权重的抽奖
https://blog.csdn.net/huyuyang6688/article/details/50480687 如有4个元素A.B.C.D,权重分别为1.2.3.4,随机结果中A:B:C:D的 ...
- ASP.NET 中HttpRuntime.Cache缓存数据
最近在开始一个微信开发,发现微信的Access_Token获取每天次数是有限的,然后想到缓存,正好看到微信教程里面推荐HttpRuntime.Cache缓存就顺便看了下. 写了(Copy)了一个辅助类 ...
- Cookie写入之path的坑
问题 我在/page/index/index.html中向浏览器添加了一个useid的cookie(这里没有指定path), 然后试着从/page/demo/demo.html中取值,发现无法取到, ...
- java技术秘籍 转摘
- bat批处理中如何获取前一天日期
网上找了好久在批处理中生成前一日期的代码段 但网上找到的代码对 每个月的1号和每年的1号计算前一日期时,总会报错,然后要加很多的逻辑判断 想了想,可以用.net写个EXE程序,用.net实现获取前一日 ...
- Java 集合:List(ArrayList,LinkedList)