spark中资源调度任务调度
在spark的资源调度中
1、集群启动worker向master汇报资源情况
2、Client向集群提交app,向master注册一个driver(需要多少core、memery),启动一个driver
3、Driver将当前app注册给master,(当前app需要多少资源),并请求启动对应的Executor
4、driver分发任务给Executor的Thread Pool。
根据Spark源码可以知道:
1、一个worker默认为一个Application启动一个Executor
2、启动的Executor默认占用这个worker的全部资源
3、如果要在一个worker上启动多个Executor,(前提:在内存充足的情况下)需要设置--executor-cores num 参数
宽依赖、窄依赖
窄依赖:父RDD与子RDD,partition之间是一对一的关系,或者多对一的关系。
宽依赖:父RDD与子RDD,partition之间是一对多,多对多的关系。
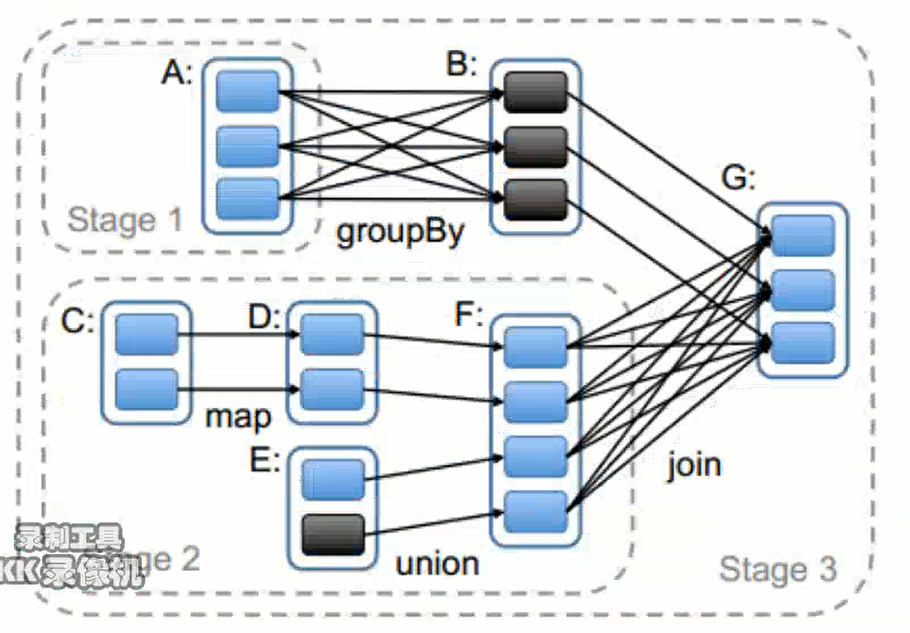
注意:
1、Stage的划分是根据宽窄依赖进行的,Satge与Satge之间是根据宽依赖划分的,每个Satge内部是窄依赖的。
2、窄依赖内部父RDD与子RDD之间的Partition是一对一的关系。
3、一个Satge内部是由多个RDD组成,在运行的过程中,会形成一个个并行的task,每个task形成一个pipeline。
4、在pipeline的运行过程中,数据不会落地,只有在右侧的join阶段的shuffle write才会数据落地。
Spark任务调度
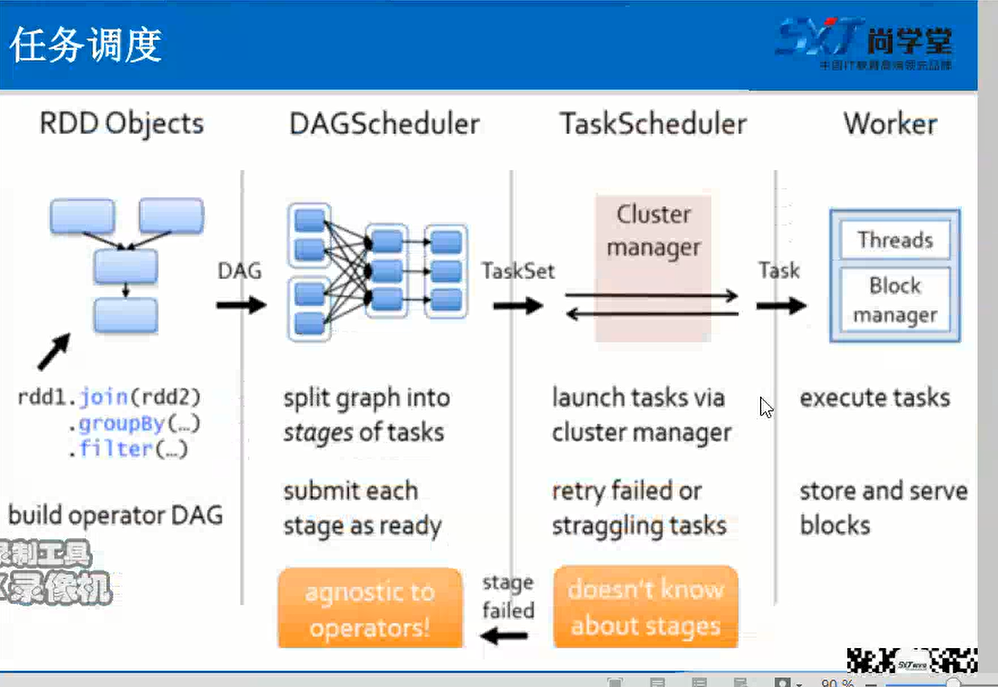
Spark的任务调度过程
RDD之间有依赖关系,所以可以根据依赖关系倒推回去,寻找到RDD的所有依赖关系,形成DAG(有向无环图)
由RDD Object将DAG传递给DAGScheduler
DAGScheduler会根据宽依赖将有向无环图划分为一个个的Satge
DAGScheduler将taskSet传递给TaskScheduler(实际上taskScheduler和Stage是相同的,只是叫法不同)
TaskScheduler会将TaskSet划分为一个个的task,传递给worker
worker会将task放入反序列化放入自己的线程池中,进行执行。
注意:
默认情况下TaskScheduler会对计算失败的task重试3次
默认情况下DAGScheduler会对计算失败的Stage重试4次
一共重试3*4=12次
未避免在对数据库操作时,操作一半失败,重试导致数据重复插入问题,可以采取两个办法
(1)设置主键
(2)关闭推测执行(默认是关闭的)
特殊情况:
如果task在执行的过程中报错shuffle file not find错误信息,此时TaskScheduler是不负责重试的,直接抛出对应的Satge运行失败,由DAGScheduler负责重试,如果DAGScheduler4次重试失败,则直接显示Job运行失败。
spark中资源调度任务调度的更多相关文章
- Spark中资源调度和任务调度
Spark比MR快的原因 1.Spark基于内存的计算 2.粗粒度资源调度 3.DAG有向无环图:可以根据宽窄依赖划分出可以并行计算的task 细粒度资源调度 MR是属于细粒度资源调度 优点:每个ta ...
- 【Spark篇】---Spark中资源和任务调度源码分析与资源配置参数应用
一.前述 Spark中资源调度是一个非常核心的模块,尤其对于我们提交参数来说,需要具体到某些配置,所以提交配置的参数于源码一一对应,掌握此节对于Spark在任务执行过程中的资源分配会更上一层楼.由于源 ...
- Spark Core_资源调度与任务调度详述
转载请标明出处http://www.cnblogs.com/haozhengfei/p/0593214ae0a5395d1411395169eaabfa.html Spark Core_资源调度与任务 ...
- Spark Core 资源调度与任务调度(standalone client 流程描述)
Spark Core 资源调度与任务调度(standalone client 流程描述) Spark集群启动: 集群启动后,Worker会向Master汇报资源情况(实际上将Worker的资 ...
- Spark中的编程模型
1. Spark中的基本概念 Application:基于Spark的用户程序,包含了一个driver program和集群中多个executor. Driver Program:运行Applicat ...
- Tachyon在Spark中的作用(Tachyon: Reliable, Memory Speed Storage for Cluster Computing Frameworks 论文阅读翻译)
摘要: Tachyon是一种分布式文件系统,能够借助集群计算框架使得数据以内存的速度进行共享.当今的缓存技术优化了read过程,可是,write过程由于须要容错机制,就须要通过网络或者 ...
- Spark中资源与任务的关系
在介绍Spark中的任务和资源之前先解释几个名词: Dirver Program:运行Application的main函数(用户提交的jar包中的main函数)并新建SparkContext实例的程序 ...
- Spark中的术语图解总结
参考:http://www.raincent.com/content-85-11052-1.html 1.Application:Spark应用程序 指的是用户编写的Spark应用程序,包含了Driv ...
- Spark中常用工具类Utils的简明介绍
<深入理解Spark:核心思想与源码分析>一书前言的内容请看链接<深入理解SPARK:核心思想与源码分析>一书正式出版上市 <深入理解Spark:核心思想与源码分析> ...
随机推荐
- 我读《大数据时代的IT架构设计》
架构设计是一门艺术,对架构的掌握要通过多看,多学,多交流,多积累,从实战架构上总能吸收到很好的营养,这边书虽然 (一).hadoop技术处理电信行业的上网日志 根据上网的url或未知url爬取内容,进 ...
- Oracle GoldenGate 二、配置和使用
Oracle GoldenGate 二.配置和使用 配置和使用GoldenGate的步骤 1 在源端和目标端配置数据库支持GoldenGate 2 在源端和目标端创建和配置GoldenGate实例 3 ...
- oj 1002题 (大数题)
#include <stdio.h> #include <string.h> int main(void) { int q,j,h,k,l; int d; ],s2[];//题 ...
- alter table导致的mysql事务回滚失败
今天做数据迁移, 发现事务有时候可以回滚, 有时候不可以回滚, 最后一点点调试发现中间有段修改表结构的语句, 最终导致回滚失败. 1.MySQL最常用的两个表类型: InnoDB和MyISAM.MyI ...
- Oracle学习笔记(十三)
十四.触发器(监听数据操作的工具) 1.什么是触发器? 数据库触发器是一个与表相关联的.存储的PL/SQL程序 作用: 每当一个特定的数据操作语句(insert.update.delete)在指定的表 ...
- break,continue以及pass的使用
1.break是提前结束循环 for i in range(1,100): if i%2 == 0: print("wrong") break#直接结束循环,并且不打印下面的pri ...
- loadrunner - Run time Settings 的详细说明
本文主要讲解一下run-time settings(如图1所示)里各设置项的具体含义(注:标红色的选项卡是比较值得关注的,可重点看一下): 图1 1.General / Run Logic 选项卡 ...
- CORS 跨域请求
一.简介 CORS需要浏览器和服务器同时支持.目前,所有浏览器都支持该功能,IE浏览器不能低于IE10. 整个CORS通信过程,都是浏览器自动完成,不需要用户参与.对于开发者来说,CORS通信与同源的 ...
- css选择器与DOM'匹配的关系
一道面试题 css 选择器匹配时,只考察是否包含有对应的class,而与class的顺序无关 而css的定义是后面的覆盖前面的定义 原理:http://www.w3.org/html/ig/zh/wi ...
- c# 后台GET、POST、PUT、DELETE传输发送json数据
一.Get 方式传输 //url为请求的网址,param参数为需要查询的条件(服务端接收的参数,没有则为null) //返回该次请求的响应 public string HttpGet(string u ...